多模式情感識別特征參數融合算法研究
2016-02-24 03:45:06韓志艷
計算機技術與發(fā)展 2016年5期
韓志艷,王 健
(渤海大學 工學院,遼寧 錦州 121000)
多模式情感識別特征參數融合算法研究
韓志艷,王 健
(渤海大學 工學院,遼寧 錦州 121000)
為了克服單模式情感識別存在的局限性,文中以語音信號和面部表情信號為研究對象,提出了一種新型的多模式情感識別算法。首先,將提取的語音信號和面部表情信號特征進行融合,然后通過有放回地抽樣獲得各訓練樣本集,并利用Adaboost算法訓練獲得各子分類器。再采用雙誤差異性選擇策略來度量兩兩分類器之間的差異性。最后運用多數投票原則進行投票,得到最終識別結果。實驗結果表明,該方法充分發(fā)揮了決策層融合與特征層融合的優(yōu)點,使整個情感信息的融合過程更加接近人類情感識別,情感識別率達91.2%。
多模式;情感識別;語音信號;面部表情信號
1 概 述
近年來,情感識別的研究工作在人機交互領域中已經成為一個熱點問題。國內外情感識別的研究主要有兩大類:一類是單模式情感識別;另一類是多模式情感識別。所謂單模式情感識別,為只從單一信息通道中獲得當前對象的情感狀態(tài),如從語音信號、面部表情信號或生理信號(血壓、體溫、脈搏、心電、腦電、皮膚電阻等)等。
對于語音情感識別,1990年麻省理工大學多媒體實驗室構造了一個“情感編輯器”對外界各種情感信號進行采樣來識別各種情感,并讓機器對各種情感做出適當的反應[1]。顏永紅等[2]采用非均勻子帶濾波器來挖掘對語音情感有益的信息,加大了各類情感之間的鑒別性,提高了情感識別的性能。毛峽等[3]通過用相關密度和分形維數作為情感特征參數來進行語音情感識別,獲得了較好的性能。鄒采榮等[4]提出了一種基于改進模糊矢量量化的語音情感識別方法,有效地改善了現有模糊矢量量化方法的情感識別率。Attabi等[5]將錨模型的思想應用到了語音情感識別中,改進了識別系統(tǒng)的性能。Zheng等[6]通過對傳統(tǒng)的最小二乘回歸算法進行改進,提出了不完稀疏最小二乘回歸算法,能同時對標記和未標記語音數據進行情感識別。Mao等[7]通過使用卷積神經網絡來選擇對情感有顯著影響的特征,取得了很好的效果。
雖然單一地依靠語音信號、面部表情信號和生理參數來進行情感識別的研究取得了一定的成果,但卻存在著很多局限性,因為人類是通過多模式的方式表達情感信息的,它具有表達的復雜性和文化的相對性[16]。比如,在噪聲環(huán)境下,當某一個通道的特征受到干擾或缺失時,多模式方法能在某種程度上產生互補的效應,彌補了單模式的不足,所以研究多模式情感識別的方法十分必要。例如,Kim等[17]融合了肌動電流、心電、皮膚電導和呼吸4個通道的生理參數,并采用聽音樂的方式來誘發(fā)情感,實現了對積極和消極兩大類情感的高效識別。黃程韋等[18]通過融合語音信號與心電信號進行了多模式情感識別,獲得較高的融合識別率。但是上述方法均為與生理信號相融合,而生理信號的測量必須與身體接觸,因此對于此通道的信號獲取有一定的困難,所以語音和面部表情作為兩種最為主要的表征情感的方式,得到了廣泛研究。例如,Busso等[19]分析了單一的語音情感識別與人臉表情識別在識別性能上的互補性。Hoch等[20]通過融合語音與表情信息,在車載環(huán)境下進行了正面(愉快)、負面(憤怒)與平靜共3種情感狀態(tài)的識別。Sayedelahl等[21]通過加權線性組合的方式在決策層對音視頻信息中的情感特征進行融合識別。
從一定意義上說,不同信道信息的融合是多模式情感識別研究的瓶頸問題,它直接關系到情感識別的準確性。因此,文中以語音信號和面部表情信號為基礎,提出了一種多模式情感識別算法,對高興、憤怒、驚奇、悲傷和恐懼五種人類基本情感進行識別。
2 系統(tǒng)結構框架
系統(tǒng)結構框架如圖1所示。首先對情感數據進行一系列預處理,然后提取語音情感特征和面部表情特征,最后進行融合識別。

圖1 系統(tǒng)結構框架
3 參數提取
3.1 語音情感參數提取
以往對情感特征參數的有效提取主要以韻律特征為主,然而近年來通過深入研究發(fā)現,音質特征和韻律特征相互結合才能更準確地識別情感。Tato等[22]研究發(fā)現,音質類特征對于區(qū)分激活維接近的情感有較好的效果,證實了共振峰等音質類特征與效價維度的相關性較強。
為了盡可能地利用語音信號中所包含的有關情感方面的信息,文中選取了語句發(fā)音持續(xù)時間與相應的平靜語句持續(xù)時間的比值、基音頻率平均值、基音頻率最大值、基音頻率平均值與相應平靜語句的基音頻率平均值的差值、基音頻率最大值與相應平靜語句的基音頻率最大值的差值、振幅平均能量、振幅能量的動態(tài)范圍、振幅平均能量與相應平靜語句的振幅平均能量的差值、振幅能量動態(tài)范圍與相應平靜語句的振幅能量動態(tài)范圍的差值、第一共振峰頻率的平均值、第二共振峰頻率的平均值、第三共振峰頻率的平均值、諧波噪聲比的均值、諧波噪聲比的最大值、諧波噪聲比的最小值、諧波噪聲比的方差,作為情感識別用的特征參數。
對全市排灌泵站相關信息進行統(tǒng)一管理,實現排灌泵站信息的錄入、增加、刪除、修改等操作,并可按給定條件(尺寸、流量、河道、圩區(qū)、功率、區(qū)域范圍、建設日期等)進行信息搜索,同時根據需求形成相應報表實現導出及打印功能。
3.2 面部表情參數提取
目前面部表情特征的提取根據圖像性質的不同可分為靜態(tài)圖像特征提取和序列圖像特征提取,靜態(tài)圖像中提取的是表情的形變特征,而序列圖像特征是運動特征。文中以靜態(tài)圖像為研究對象,采用Gabor小波變換來提取面部表情參數。具體過程如下:
(1)將預處理后的人臉圖像網格化為25×25像素,所以每張臉共有4行3列共12個網格。
(2)用Gabor小波和網格化后的圖像進行卷積,公式如下:
r(x,y)=?I(ε,η)g(x-ε,y-η)dεdη
(1)

(3)取卷積結果的模‖r(x,y)‖的均值和方差作為面部表情參數。
(4)用主成分分析法(PCA)對上述特征進行降維處理,獲得的面部表情特征參數作為特征融合的特征參數。
4 算法描述
具體實施步驟如下:
第一步:通過噪聲刺激和觀看影視片段等誘發(fā)方式,采集相應情感狀態(tài)下的語音信號和面部表情信號,并將二者綁定存儲。對于語音數據,在提取特征之前要進行一階數字預加重、分幀、加漢明窗和端點檢測等預處理。對于面部表情數據,在提取特征之前要首先用膚色模型進行臉部定位,然后進行圖像幾何特性歸一化處理和圖像光學特性的歸一化處理。其中,圖像幾何特性歸一化主要以兩眼位置為依據,而圖像光學特性的歸一化處理包括先用直方圖均衡化方法對圖像灰度做拉伸,以改善圖像的對比度,然后對圖像像素灰度值進行歸一化處理,使標準人臉圖像的像素灰度值為0,方差為1,如此可以部分消除光照對識別結果的影響。
第二步:根據3.1節(jié)和3.2節(jié)的方法提取語音情感參數和面部表情參數。
第三步:將提取的語音情感參數和面部表情參數順序組合起來,獲得多模式特征向量u1,以此類推,獲得了原始訓練樣本集中所有的多模式特征向量u2,…,ur,…,uW。其中,r=1,2,…,W,W為原始訓練樣本集中語音信號樣本數,即面部表情信號樣本數。
第四步:通過對多模式特征向量集有放回地抽樣N次獲得訓練樣本集S1,然后依次繼續(xù)抽取樣本獲得訓練樣本集S2,…,SM,即獲得M個訓練樣本集。
第五步:利用Adaboost算法對上述M個訓練樣本集Sk,k=1,2,…,M,分別進行訓練,獲得每個訓練樣本集上的強分類器。其中,以三層BP神經網絡作為弱分類器。
第六步:采用雙誤差異性選擇策略來度量兩兩強分類器之間的差異性,并挑選出大于平均差異性的強分類器作為識別分類器,其強分類器Hi和Hj(i≠j)之間的差異性公式如下:
(2)
其中,numab表示兩兩強分類器分類正確/錯誤的樣本數,a=1和a=0分別表示強分類器Hi分類正確和錯誤,b=1和b=0分別表示強分類器Hj分類正確和錯誤。
第七步:運用多數優(yōu)先投票原則進行投票,得到最終識別結果。
5 仿真實驗及結果分析
為證明文中方法的識別效果,將單模式條件下與多模式條件下的識別結果進行對比。原始訓練樣本集包含每種情感的200條語音數據樣本與200條面部表情數據樣本,測試集包含每種情感的100條語音數據樣本和100條面部表情數據樣本。
在單模式條件下,僅通過語音信號進行識別的情感識別正確率如表1所示,僅通過面部表情信號進行識別的情感識別正確率如表2所示。

表1 僅通過語音信號進行識別的正確率 %

表2 僅通過面部表情信號進行識別的正確率 %
由表1和表2可知,僅通過語音信號進行識別的平均識別正確率是81.4%;僅通過面部表情信號進行識別的平均識別正確率是77.8%。因此,單純依靠語音信號或面部表情信號進行識別在實際應用中會遇到一定的困難,因為人類是通過多模式的方式表達情感信息的,所以研究多模式情感識別的方法十分必要。
在多模式條件下,通過簡單組合文中的語音信號和面部表情信號特征進行識別的情感識別正確率如表3所示,通過文中方法進行識別的情感識別正確率如表4所示。
注:表中第i行第j列的元素表示真實情感狀態(tài)是i的樣本被判別成j的比例。
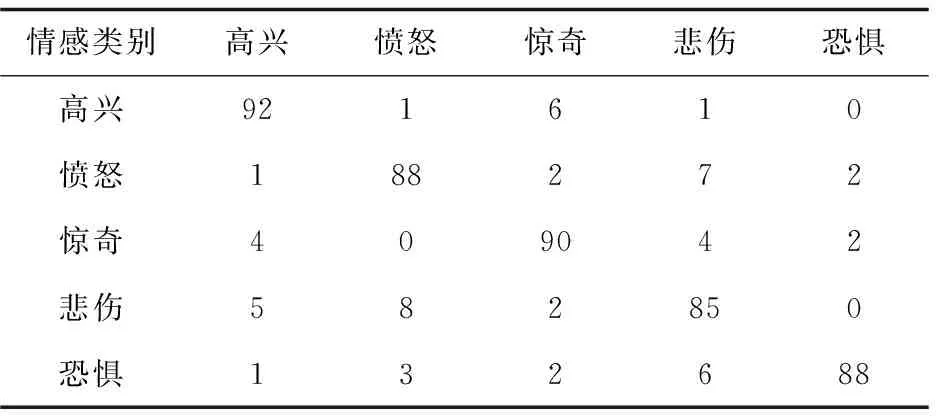
表3 通過簡單組合語音信號和面部表情信號進行識別的正確率 %

表4 文中方法進行識別的情感識別正確率 %
從表3可以看出,通過簡單組合語音信號和面部表情信號進行識別的正確率有所提高,但是提高的并不太明顯,因此不同模式信息的融合是多模式情感識別研究的瓶頸問題,它直接關系到情感識別的準確性。從表4可以看出,情感識別的平均正確率達到了91.2%,因此文中方法充分發(fā)揮了決策層融合與特征層融合的優(yōu)點,使整個融合過程更加接近人類情感識別,從而提高了情感識別的平均正確率。
6 結束語
文中充分發(fā)揮了決策層融合與特征層融合的優(yōu)點,提出了一種新型的多模式情感識別算法,從而提高了情感識別的正確率。但是文中只是針對特定文本的語音情感進行識別,要達到實用的程度尚需一定距離,所以非特定文本的語音情感識別將是下一步的研究方向。
[1] 余伶俐,蔡自興,陳明義.語音信號的情感特征分析與識別研究綜述[J].電路與系統(tǒng)學報,2007,12(4):76-84.
[2] 顏永紅,周 瑜,孫艷慶,等.一種用于語音情感識別的語音情感特征提取方法:中國,2010102729713[P].2010.
[3]MaoX,ChenLJ.Speechemotionrecognitionbasedonparametricfilterandfractaldimension[J].IEICETransonInformationandSystems,2010,93(8):2324-2326.
[4] 鄒采榮,趙 力.一種基于改進模糊矢量量化的語音情感識別方法:中國,2008101228062[P].2008.
[5]AttabiY,DumouchelP.Anchormodelsforemotionrecognitionfromspeech[J].IEEETransonAffectiveComputing,2013,4(3):280-290.
[6]ZhengWM,XinMH,WangXL,etal.Anovelspeechemotionrecognitionmethodviaincompletesparseleastsquareregression[J].IEEESignalProcessingLetters,2014,21(5):569-572.
[7]MaoQR,DongM,HuangZW,etal.Learningsalientfeaturesforspeechemotionrecognitionusingconvolutionalneuralnetworks[J].IEEETransonMultimedia,2014,16(8):2203-2213.
[8]EkmanP,FriesenW.Facialactioncodingsystem:atechniqueforthemeasurementoffacialmovement[M].PaloAlto:ConsultingPsychologistsPress,1978.
[9] 梁路宏,艾海舟,徐光祐,等.人臉檢測研究綜述[J].計算機學報,2002,25(5):449-458.
[10]RahulamathavanY,PhanRCW,ChambersJA,etal.Facialexpressionrecognitionintheencrypteddomainbasedonlocalfisherdiscriminantanalysis[J].IEEETransonAffectiveComputing,2013,4(1):83-92.
[11] 文 沁,汪增福.基于三維數據的人臉表情識別[J].計算機仿真,2005,22(7):99-103.
[12]ZhengWM.Multi-viewfacialexpressionrecognitionbasedongroupsparsereduced-rankregression[J].IEEETransonAffectiveComputing,2014,5(1):71-85.
[13]PetrantonakisPC,HadjileontiadisLJ.EmotionrecognitionfromEEGusinghigherordercrossings[J].IEEETransonInformationTechnologyinBiomedicine,2010,14(2):186-197.
[14] 林時來,劉光遠,張慧玲.蟻群算法在呼吸信號情感識別中的應用研究[J].計算機工程與應用,2011,47(2):169-172.
[15]ZacharatosH,GatzoulisC,ChrysanthouYL.Automaticemotionrecognitionbasedonbodymovementanalysis:asurvey[J].IEEEComputerGraphicsandApplications,2014,34(6):35-45.
[16]ZengZ,PanticM,RoismanGI,etal.Asurveyofaffectrecognitionmethods:audio,visual,andspontaneousexpressions[J].IEEETransonPatternAnalysisandMachineIntelligence,2009,31(1):39-58.
[17]KimJ,AndreE.Emotionrecognitionbasedonphysiologicalchangesinmusiclistening[J].IEEETransonPatternAnalysisandMachineIntelligence,2008,30(12):2067-2083.
[18] 黃程韋,金 赟,王青云,等.基于語音信號與心電信號的多模態(tài)情感識別[J].東南大學學報:自然科學版,2010,40(5):895-900.
[19] Busso C,Deng Z,Yildirim S,et al.Analysis of emotion recognition using facial expressions,speech and multimodal information[C]//Proc of the sixth international conference on multimodal interfaces.USA:IEEE,2004:205-211.
[20] Hoch S,Althoff F,Mcglaun G,et al.Bimodal fusion of emotional data in an automotive environment[C]//Proc of IEEE international conference on acoustics,speech,and signal processing.USA:IEEE,2005:1085-1088.
[21] Sayedelahl A,Araujo R,Kamel M S.Audio-visual feature-decision level fusion for spontaneous emotion estimation in speech conversations[C]//Proc of 2013 IEEE international conference on multimedia and expo workshops.USA:IEEE,2013:1-6.
[22] Tato R,Santos R,Kompe R,et al.Emotion space improves emotion recognition[C]//Proceedings of the 2002 international conference on speech and language processing.USA:IEEE,2002:2029-2032.
Research on Feature Fusion Algorithm for Multimodal Emotion Recognition
HAN Zhi-yan,WANG Jian
(College of Engineering,Bohai University,Jinzhou 121000,China)
In order to overcome the limitation of single mode emotion recognition,a novel multimodal emotion recognition algorithm is proposed,taking speech signal and facial expression signal as the research subjects.First,the speech signal feature and facial expression signal feature is fused,and sample sets by putting back sampling are obtained,and then sub-classifiers are acquired by Adaboost algorithm.Second,the difference is measured between two classifiers by double error difference selection strategy.Finally,the recognition result is obtained by the majority voting rule.Experiments show the method improves the accuracy of emotion recognition by giving full play to the advantages of decision level fusion and feature level fusion,and makes the whole fusion process close to human emotion recognition more,with a recognition rate 91.2%.
multimodal;emotion recognition;speech signal;facial expression signal
2015-08-14
2015-11-22
時間:2016-04-
國家自然科學基金資助項目(61403042,61503038);遼寧省教育廳項目(L2013423)
韓志艷(1982-),女,博士,副教授,研究方向為情感識別、語音識別。
http://www.cnki.net/kcms/detail/61.1450.TP.20160505.0828.080.html
TP391.4
A
1673-629X(2016)05-0027-04
10.3969/j.issn.1673-629X.2016.05.006
猜你喜歡
今日農業(yè)(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
鴨綠江(2021年35期)2021-04-19 12:24:18
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
現代出版(2020年3期)2020-06-20 07:10:34
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年11期)2018-08-04 03:25:42
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
