基于車聯網大數據的UBI系統研究
2016-02-23 12:12:00韓家群劉南杰趙海濤
計算機技術與發展 2016年12期
關鍵詞:系統
韓家群,劉南杰,黃 波,趙海濤
(1.南京郵電大學 通信與信息工程學院,江蘇 南京 210003;2.南京郵電大學 網絡基因工程研究所,江蘇 南京 210003)
基于車聯網大數據的UBI系統研究
韓家群1,2,劉南杰1,2,黃 波1,2,趙海濤1,2
(1.南京郵電大學 通信與信息工程學院,江蘇 南京 210003;2.南京郵電大學 網絡基因工程研究所,江蘇 南京 210003)
在大數據和車聯網時代背景下,提出了基于大數據的車聯網保險系統的研究,即基于駕駛行為的車輛保險系統(Usage-Based Insurance,UBI)。該系統在智能車載終端OBD的應用、車輛數據收集、駕駛行為信息存儲及處理、數據分析建模的基礎上給出了合理的車險預測方案,并針對用戶個性化服務進行了模塊化的系統分析和處理。此外,在駕駛行為分析研究的基礎上,給出了車險預測模型和UBI車險定價策略。系統的分析結果表明,在車聯網大數據時代下的UBI系統在車險行業有很好的應用前景。
車聯網;大數據;車輛保險系統;車保險
0 引 言
2013年國內的財險行業突破了億萬元大關,比2009年增加了21.3%,盡管如此,但保險行業的盈利仍然不理想[1]。由于傳統的機動車輛保險只考慮車輛購置價、購車類型等,車輛保險模式極其單一,沒有考慮駕駛行為對機動車輛保險的影響,導致大部分優質的車險用戶為少數因惡劣的駕駛行為造成高額理賠的用戶買單,因而使得投保人的車險保費設定存在嚴重不合理的現象[2]。
相比之下,國外的保險費率更為靈活。例如,美國未婚低齡保險費率最高(缺乏責任感,易出現車輛事故);德國新手費率高(出險概率高);加拿大周末用車比上班用車費率低(出險概率低)。國外積極推廣的UBI保險[3],取得了一定的成效,未來UBI的車聯網保險模式也將被持續推廣與應用。
隨著互聯網時代的到來和技術全球化的發展,移動互聯網正在不斷滲透到社會、經濟各個領域,同樣地互聯網下的車聯網也正向著汽車保險行業滲透,因而基于車聯網的汽車保險行業有巨大的發展前景。其中,車聯網技術、大數據技術等是未來保險行業發展的核心驅動力[4]。在這樣的時代背景下,對車聯網保險進行了研究,并創新性提出了大數據時代下的UBI系統研究。該系統從車主的駕駛行為習慣、行車里程、購置價格及車輛類型等方面進行綜合分析,在車聯網保險的第一代基于按里程付費(Pay As You Drive,PAYD)的車保險到第二代考慮駕駛安全(Pay How You Drive,PHYD)的車保險基礎上,提出車和人相結合多模式厘定車險方案,打破傳統的只對車或者人單一的分析模式。文中分析處理的數據均是由車載終端OBD收集的真實駕駛行為數據[5-6]。
1 智能車載終端
車聯網(Internet of Vehicles,IOV)是通過OBD、GPS等裝置,完成車自身狀態和環境信息數據的采集[7],通過互聯網將采集的數據傳輸到中央處理器并對數據進行分析處理,并對不同需求的車輛進行有效監管和提供綜合服務的系統,實現車輛的智能化控制。
車載診斷(On-Board Diagnostics,OBD)是車聯網的核心技術,融合了汽車智能感知模塊、汽車與互聯網的連接模塊、汽車系統和部件(發動機、排放控制系統等)的監測模塊,實現車輛狀況的實時記錄和報告。OBD模式的車聯網系統是由OBD終端、后臺系統、手機APP這三個主要部分組成。圖1為OBD模式下的車聯網模型,車輛內置的傳感器具有智能感知功能,車載診斷OBD通過控制局部網(Controller Aver Network,CAN)與總線相連,獲取電控單元(Engine Control Unit,ECU)中的車輛狀態信息。該模式系統與物聯網的邏輯組成類似,由數據采集、數據分析處理、數據報告等組成。

圖1 OBD模式下的車聯網模型
2 大數據
大數據是來源于人類活動,通過記錄人類某些行為而得到的數據。在人類發現數據其他價值以前,數據只是一個數量上的理解,由于互聯網的快速發展,數據出現井噴式發展,使任何數據背后都有其自身的信息價值。文中提出的UBI系統研究正是在大數據分析和處理的基礎上,針對車保用戶專業化和個性化服務給出了合理的車險模式。
大數據是指新一代對大量的各種樣式的數據進行高速捕獲、提取、分析和處理后得到數據規律,從而取得額外價值的技術。它具有海量性(Volume)、快速變動(Variety)、多樣化(Velocity)、信息價值(Value)和真實性(Veracity)五大特征。大數據不在于數據本身的信息意義,而是它能衍生出多維度潛在的信息價值[8-9]。
大數據處理的生命周期包含數據源、收集、存儲、分析處理和預測等過程,生命周期體現了不同階段對數據實施不同的處理策略。
3 車聯網大數據時代的UBI系統
如圖2所示,大數據時代的UBI系統主要由數據源、數據的處理、數據的分析和預測模型等部分組成。
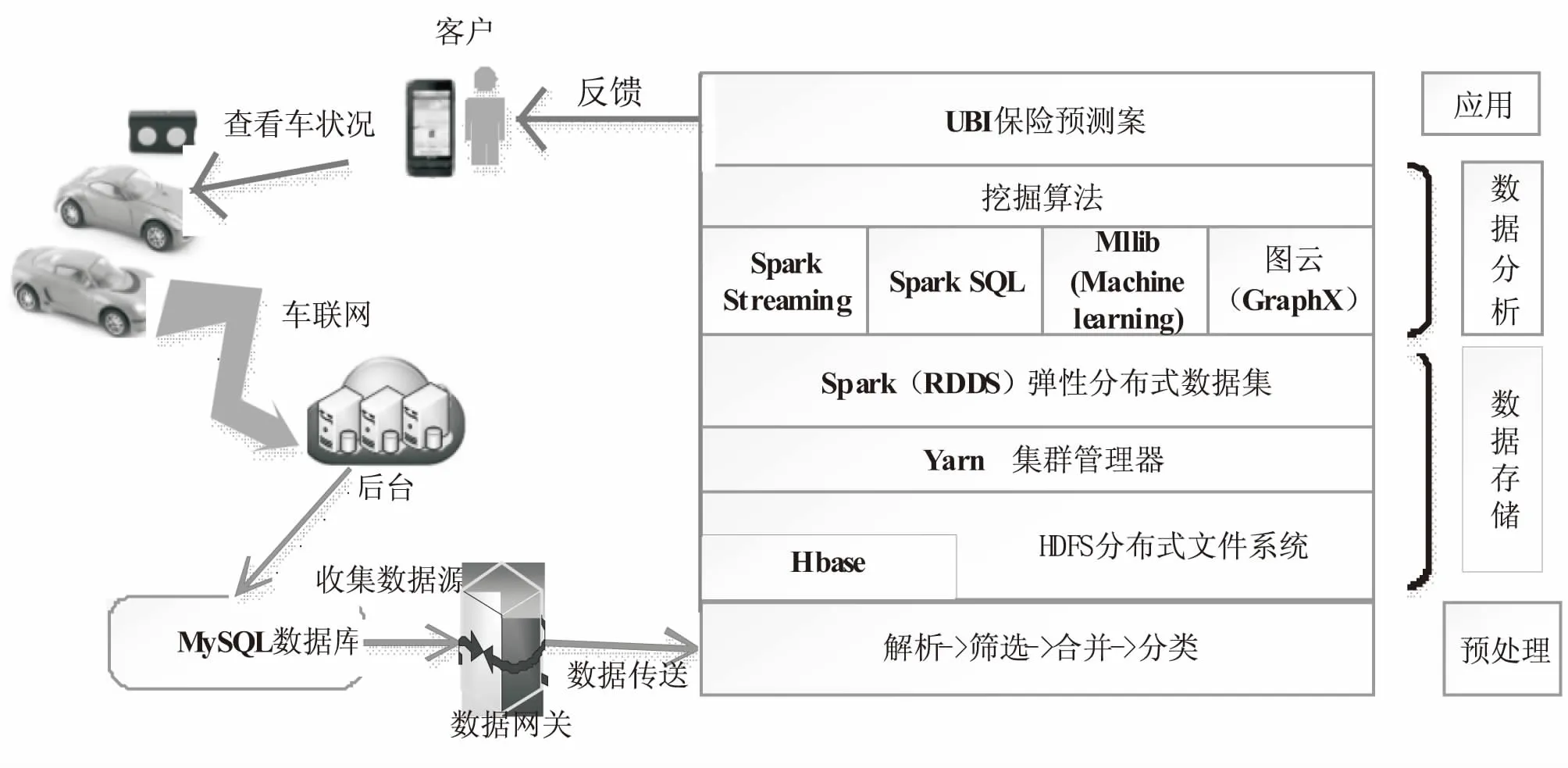
圖2 基于大數據的UBI車險系統
3.1 數據源
機動車輛中安裝的OBD對車輛的各個系統進行實時監測,車聯網的應用實現了從客戶端-服務器(Client/Server)成功連接,服務器是整個應用系統的資源中心,客戶端發送的數據傳送到數據庫服務器,客戶端也可以對數據庫進行訪問。文中數據源存儲在關系數據庫MySQL中,通過數據網關傳輸到分布式數據庫管理系統中。MySQL具有體積小、速度快、成本低等特點,適用于車況中快速產生數據,及時更新數據庫中的數據,去除了冗余的數據信息,減少了網絡資源的浪費。
3.2 數據處理
數據處理包含數據預處理和數據存儲兩部分,數據預處理可以獲取對車保險預測方案有價值的數據信息。通過對駕駛行為有關的數據解析,篩選出文中提出的UBI系統所需的數據,如每日四急(急剎車、急加速、急減速、急轉彎)次數、行駛里程、出行時間、超速次數等數據,然后對這些數據進行分類、合并,并存儲到分布式數據庫HBase中。HBase是一種基于Hadoop的項目,也稱Hadoop分布式文件系統(Hadoop Distributed File System,HDFS)[10]。它是一個非結構化數據存儲的分布式數據庫,使用Zookeeper管理集群,在架構層面上分為Master(Zookeeper中的leader)和多個區域服務器(Region Server,RS)。基本架構如圖3所示。其中,RS是集群中的一個節點,每個RS可以負責管理多個Region,每個Region只能由一個RS提供服務。HBase中需要多個Region存儲數據,HBase給每個Region定義一定的范圍,落在規定范圍的數據,就會分配給規定的Region,從而把負載分到各個節點上,這就是分布式存儲的過程及優點。

圖3 HBase基本架構
YARN(Yet Another Resource Negotiator)是分布式集群的資源管理器。MapReduce1架構在整個集群上執行Map和Reduce任務并報告結果,但在大型集群中,當集群節點超過一定量時,就會出現級聯故障,級聯故障通過網絡泛洪形式導致整個集群嚴重惡化。為了克服MapReduce1的這種缺陷,采用YARN分層集群管理框架的技術,能使集群共享、可伸縮和更可靠。YARN分層結構是資源管理程序(ResourceManager)將各部分資源傳給基礎節點代理程序(NodeManager),NodeManager啟動和監視基礎應用程序執行和資源管理(CPU、內存等資源分配)。
Spark是一個基于內存計算的集群計算系統,它的核心是彈性分布式數據集(Resilient Distributed Datasets,RDD)。Spark的所有操作基于RDD,RDD是容錯的、并行的數據結構,RDD是一個不可修改的分布的對象集合。每個RDD由多個分區組成,每個分區可以同時在集群中的不同節點上計算。RDD的分區特性與并行計算能力,使得Spark可以更好地利用可伸縮的硬件資源。若將分區與持久化二者結合起來,就能更加高效地處理海量數據[11]。
文中收集了1 000輛汽車數據,并分析處理駕駛行為相關數據信息,如四急、行駛里程、最大瞬時速度和出行的時間。圖4是基于駕駛行為分別從每天駕駛的距離、每天四急的次數總和、最大速度和最晚出行時間四個方面所得數據的柱狀圖。通過這些數據的分析,得出相應的駕駛行為處理結果,為文中大數據時代下的UBI車保險方案提供有力證據。

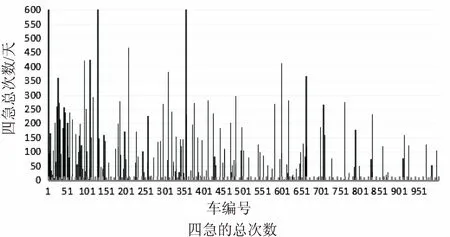
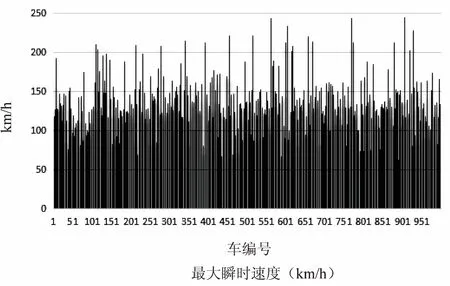
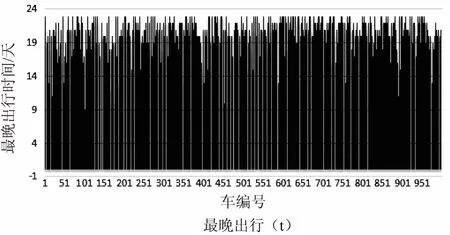
圖4 基于駕駛行為的數據分析
3.3 數據建模分析
數據建模分析是針對預處理提取的數據特征,得到想要的結果。在數據提取后,常使用的是Spark算法。Spark常用的應用有Spark SQL、Spark Streaming、MLLib、Graph等。Spark SQL使用RDD實現SQL查詢;Spark Streaming流式計算,提供實時計算功能;GraphX圖計算框架,實現了基本的圖計算功能,常用圖算法和pregel圖編程框架;MLLib機器學習庫,提供常用分類、聚類、回歸、交叉檢驗等機器學習算法并行實現,如樸素貝葉斯、邏輯回歸、決策樹、神經網絡、TFIDF、協同過濾等算法,在MLLib中已經存在,只需將數據帶入,調用比較方便。
3.4 車保險的預測方案
文中提出的UBI系統對不同的駕駛行為給予不同的保險費率,并提供個性化的增值服務。在大數據分析處理后,該系統提供的機動車輛保險的實施方案如下:
給每個用戶每天設置一個基總分數值(如100分),四急/每日行駛總里程/每日超速次數/每日夜間行駛時間按5:2:2:1分配總分值,即50分/20分/20分/10分。
表1是根據駕駛行為制定的評分規則,通過累計的分數,判斷一個人的駕駛行為的優良性[12]。

表1 評分規則
根據方案累計一年的得分情況記為Sum,駕駛的天數即算入計算分數的天數為Day,平均得分記為Avg:
Avg=Sum/Day
為了防止惡意做假行為,天數Day有一定的規定:若Day<100,視為最低等級,100≤Day<250,則在原來的Sum上乘一定比例50%,若Day≥250則按照原Sum計算。
根據Avg分析將不同客戶分為不同的等級,Avg≥80為五星級客戶,60≤Avg<80為四星級客戶,40≤Avg<60為三星級客戶,20≤Avg<40為二星級客戶,0≤Avg<20為一星級客戶。
4 結束語
不同星級的客戶可以承擔不同車保險費率,保險公司應獎勵優質客戶(即星級高的客戶),在下一年的保險中給予優惠活動,同時,懲罰劣質用戶(即星級低的客戶),可以提高來年投保車輛的保險費率。此外,獲取的數據還可以為客戶提供個性化服務,如根據駕駛習慣和經常去的地方,適時為其推薦地方特色和商店活動信息,對于駕駛行為不良的用戶給予及時提醒等服務。
大數據時代下的UBI系統從大數據的獲取、存儲、分析、建模等方面進行了詳細的描述,以四急、駕駛里程等為依據制定了合理的UBI的車險費率模型。該系統具有真實性和實際價值意義,在車險行業具有很好的應用前景[3,13]。
[1] 迪納科技.保險行業車聯網解決方案白皮書[EB/OL].[2014-04-01].http://www.cpsdna.com/article-545.html.
[2] 彭江琴,劉南杰,趙海濤,等.智能UBI系統研究[J].計算機技術與發展,2016,26(1):142-146.
[3] Kusek G,Kilic I.Project-based application on big data usage[C]//2015 fourth international conference on agro-geoinformatics.[s.l.]:[s.n.],2015:89-92.
[4] 劉文鵬.大數據時代的汽車保險[J].經營者,2015(2):166-167.
[5] 喬 木.大數據語境下UBI發展現狀及趨勢研究[J].現代商業,2015(1):53-54.
[6] 梁小英,朱園麗,趙一衡.科技引領未來,專業創造價值——大數據時代下的UBI產品探索[J].金融電子化,2014(9):28-29.
[7] 劉南杰.崛起的車聯網[J].音響改裝技術,2013(11):50.
[8] Demchenko Y,de Laat C,Membrey P.Defining architecture components of the Big Data Ecosystem[C]//2014 international conference on collaboration technologies and systems.[s.l.]:[s.n.],2014:104-112.
[9] Tekiner F,Keane J A.Big data framework[C]//2013 IEEE international conference on systems,man and cybernetics.[s.l.]:IEEE,2013:1494-1499.
[10] Pandey S,Tokekar V.Prominence of MapReduce in big data processing[C]//2014 fourth international conference on communication systems and network technologies.[s.l.]:[s.n.],2014:555-560.
[11] Riggins F J,Wamba S F.Research directions on the adoption,usage,and impact of the internet of things through the use of big data analytics[C]//2015 48th Hawaii international conference on system sciences.[s.l.]:[s.n.],2015:1531-1540.
[12] 彭江琴,劉南杰,仲 浩,等.基于GID的UBI系統研究[J].微型機與應用,2014,33(22):51-53.
[13] 郁佳敏.車聯網大數據時代汽車保險業的機遇和挑戰[J].南方金融,2013(12):89-95.
Research on UBI System Based on Big Data in IOV
HAN Jia-qun1,2,LIU Nan-jie1,2,HUANG Bo1,2,ZHAO Hai-tao1,2
(1.College of Telecommunications & Information Engineering,Nanjing University of Posts and Telecommunications,Nanjing 210003,China;2.Network Gene Engineering Research Institute,Nanjing University of Posts and Telecommunications,Nanjing 210003,China)
Under the era background of Big Data and IOV (Internet of Vehicle),the research on the insurance system for IOV based on Big Data is carried out and the UBI (Usage-Based Insurance) system is proposed.The proper scheme of forecasting automobile insurance is presented through equipping the vehicle with OBD (On-Board Diagnostics),collecting the vehicle data,storing and processing the information about driving behavior,modeling the analysis on data by UBI system.The modular system is analyzed and processed in terms of personalized service of users.In addition,on the basis of analyzing the driving behavior,the model of forecasting the automobile insurance and the pricing policy of UBI are proposed.The analysis results show that the UBI system is of broad and potential application prospects in the field of automobile insurance in the era of Big Data.
IOV;Big Data;UBI;automobile insurance
2016-01-19
2016-05-11
時間:2016-11-22
國家(青年)自然科學基金(61201162);政策引導類計劃(產學研合作)—前瞻性聯合研究項目(BY2015011-01)
韓家群(1991-),女,碩士研究生,研究方向為車聯網大數據;劉南杰,博士,教授,研究方向為泛在通信、車聯網、智能交通。
http://www.cnki.net/kcms/detail/61.1450.TP.20161122.1231.048.html
TN911
A
1673-629X(2016)12-0026-04
10.3969/j.issn.1673-629X.2016.12.006
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
裝備制造技術(2019年12期)2019-12-25 03:06:46
制造技術與機床(2019年10期)2019-10-26 02:47:06
中國洗滌用品工業(2019年4期)2019-05-11 09:27:34
鐵道通信信號(2018年5期)2018-06-28 03:06:24
家庭影院技術(2017年9期)2017-09-26 03:41:45
知識經濟·中國直銷(2017年5期)2017-06-15 20:28:19
通信電源技術(2016年6期)2016-04-20 06:21:32
