基于多示例多標記的抽油機故障診斷①
2016-02-20 06:52:34許少華
計算機系統(tǒng)應(yīng)用 2016年12期
陳 妍, 許少華,2
1(東北石油大學 計算機與信息技術(shù)學院, 大慶 163318)2(山東科技大學 信息科學與工程學院, 青島 266000)
基于多示例多標記的抽油機故障診斷①
陳 妍1, 許少華1,2
1(東北石油大學 計算機與信息技術(shù)學院, 大慶 163318)2(山東科技大學 信息科學與工程學院, 青島 266000)
針對抽油機工況數(shù)據(jù)可從位移、載荷、電流等多個方面進行描述, 若僅僅使用一個特征向量來描述抽油機工況數(shù)據(jù)會使其信息過于簡化, 丟失一部分有效信息的問題, 以及工況數(shù)據(jù)具有多義性的特征, 提出基于多示例多標記的抽油機故障診斷. 該學習方法中, 用抽油機的位移、載荷、電流數(shù)據(jù)作為抽油機工況樣本包的多個示例, 使用k-medoids聚類算法對樣本包進行聚類, 將多個樣本包轉(zhuǎn)換為若干示例, 新示例的每一維表示樣本包到樣本各聚類中心的距離, 再利用MLSVM算法對轉(zhuǎn)換后的多標記問題進行求解. 實驗結(jié)果表明, 多示例多標記學習能夠及時、準確地診斷出抽油機故障問題.
多示例多標記; 抽油機; 故障診斷
1 引言
在現(xiàn)代采油工藝技術(shù)中, 油井停止自噴后通常使用機械采油方式進行采油, 螺桿泵便是眾多機械采油方式中應(yīng)用最為普遍的一種[1]. 而油井所處地理環(huán)境惡劣、井下條件復(fù)雜、不明因素眾多, 這些不利因素導(dǎo)致無法實時判斷抽油機運行狀態(tài), 從而不能及時進行故障診斷和處理, 嚴重影響了抽油機的抽油效率、增加了采油成本. 因此及時準確地了解有桿抽油系統(tǒng)的工作情況并進行故障診斷, 對提高油田生產(chǎn)效率和緊急效益具有中要的意義[2].
示功圖是分析抽油機工作狀況的重要依據(jù), 技術(shù)人員主要通過觀察示功圖的上載荷、下載和、加載帶、卸載帶來判斷示功圖是否處于正常工作狀態(tài), 這樣的分析更多的依賴于技術(shù)人員的工作經(jīng)驗和技術(shù)水平,人為影響因素較大. 也有研究人員利用機器學習進行抽油機故障診斷操作.
文獻[2]采用了半監(jiān)督競爭過程元網(wǎng)絡(luò), 將離散Fréchet距離與歐氏距離相結(jié)合利用了示功圖的時間細節(jié)特征對其進行分類識別; 文獻[3]將示功圖識別看作動態(tài)系統(tǒng)連續(xù)曲線(位移-時間曲線和載荷-時間曲線)的模式識別問題, 將一個周期內(nèi)的位移-時間曲線和載荷-時間曲線直接作為模型輸入; 文獻[4]采用一種矩特征和傅里葉描述子相結(jié)合的方式進行的示功圖故障診斷; 文獻[5]通過兩個分類支持向量機的組合來實現(xiàn)支持向量機的多分類算法, 應(yīng)用支持向量機的多分類算法來實現(xiàn)示功圖診斷操作; 文獻[6]利用最小二乘法對示功圖進行自動分類識別.
上述識別方法都取得了不錯的識別效果, 但都是針對單示例或是單標記的學習. 而抽油機工況數(shù)據(jù)是具有多義性的, 只使用一個特征向量來進行描述會丟失很多有用信息, 因此本文提出利用多示例多標記方法對抽油機故障進行診斷.
2 各模塊的算法設(shè)計與實現(xiàn)
多示例多標記學習主要用于對多義性對象進行學習, 需要給予對象適合的類別標記, 這里的類別標記不再是單一的類別標記了, 而是一個類別標記子集.同樣, 對多義性對象的描述也不再是采用單一示例進行表達, 而是使用示例集合表示[7,8].
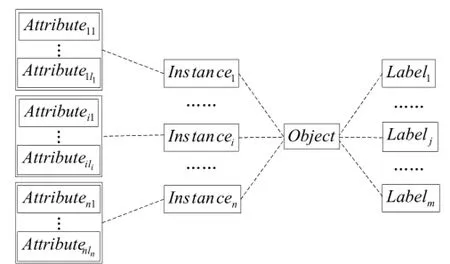
圖1 系統(tǒng)總體框圖
3 多示例多標記算法描述
3.1 MIML框架學習策略
傳統(tǒng)監(jiān)督學習可以看做是多示例學習或者多標記學習的一種特殊情況, 而多示例學習或者多標記學習有可以看成是多示例多標記學習的單標記情況或者單示例情況, 因此, 多示例多標記問題可以先轉(zhuǎn)換成為多示例問題或者多標記問題, 再轉(zhuǎn)化為單示例單標記問題, 也就是傳統(tǒng)監(jiān)督問題, 基于這種思想, Zhou Z-H等提出了MIMLBOOST算法和MIMLSVM算法[7,9].基于最大間隔策略以及正則化機制, 提出了D-MIMLSVM算法[8]和M3MIML[10]算法. 在本文中,使用的是MIMLSVM算法.
3.2 MIMLSVM學習算法
MIMLSVM算法針對每個多示例多標記樣本(Xi,Yi)都會給出一個中間變量zi=φ(Xi), 函數(shù)φ將每一個多示例子集Xi轉(zhuǎn)化成為一個示例zi, 即2x→Z,其中, 對于任意的y∈Y, 若y∈Yi, 則令φ(zi,y)=+1, 否則,φ(zi,y)=-1. 將Xi轉(zhuǎn)換成為zi后,再利用MLSVM[11]算法對通過轉(zhuǎn)換獲得的多標記問題進行學習. MIMLSVM算法的整體思想如圖2所示.
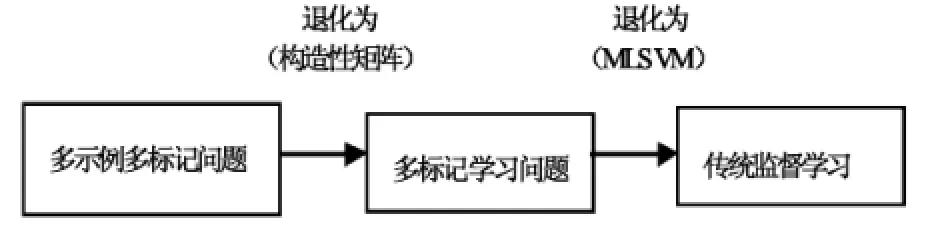
圖2 MIMLSVM算法整體思想
3.3 算法描述
步驟2. 在數(shù)據(jù)集Γ的基礎(chǔ)上運用k-medoids聚類算法, 得到初始化的聚類中心點對于每一個示例
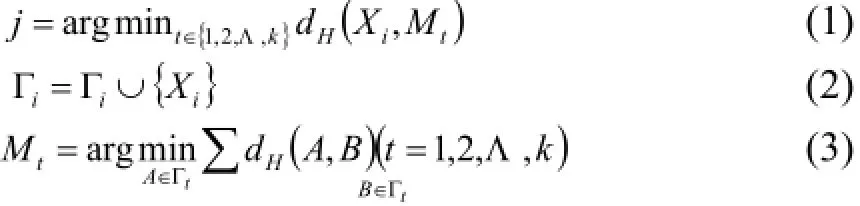
重復(fù)計算公式(1)(2)(3), 直至中心點Mt不再改變.其中,dH(A,B)表示包A={a1,a2,Λ,anA}和包之間的距離, 采用Hausdroff[12]距離進行度量:其中a-b表示的就是使用Hausdroff距離計算出的a與b之間的距離.
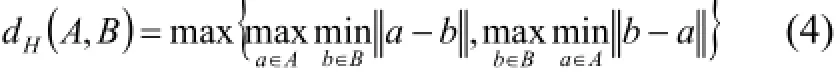
步驟3. 將多示例多標記樣本(Xi,Yi)轉(zhuǎn)換成為多標記樣本(zi,Yi)(i=1,2,Λ,m), 其中:
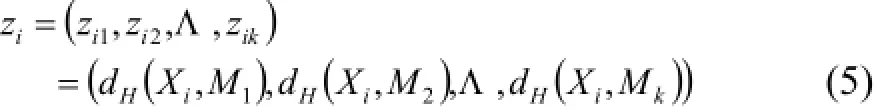
步驟4. 建立數(shù)據(jù)集Dy:
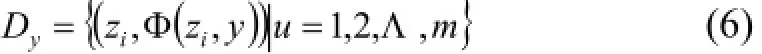
針對數(shù)據(jù)集Dy使用MLSVM算法來進行SVM訓練:

對于任意的y∈Y, 與標記集Y有關(guān)的示例都被認為是正例, 而對任意的y?Y, 與標記集Y無關(guān), 被認為是反例.
步驟5. 當訓練后的SVM得分中含有正分時, 測試用例被標記為擁有最高正得分的類別, 若SVM訓練后所有類別的得分都是負分, 則測試用例被標記為擁有最少負分的類別.
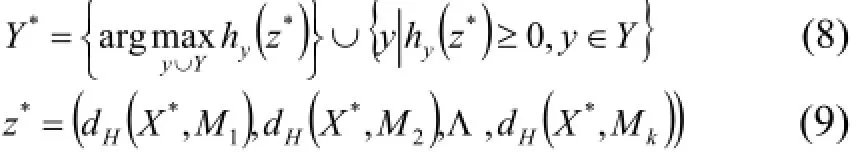
3.4 算法表現(xiàn)評價
算法在實驗中表現(xiàn)的好壞主要由5個指標進行評價, 分別是HammingLoss、RankingLoss、OneError、Coverage、Average_Precision[13]. 其中, HammingLoss表示的是對象分類錯誤的次數(shù), 其數(shù)值越小, 算法的表現(xiàn)越好; RankingLoss表示對象錯亂標記平均值, 越小表示學習效果越好; OneError表示排名第一的標記并不是該對象正確的標記的次數(shù), 同樣, 該值越小越好; Coverage代表覆蓋對象所有標記的距離, 數(shù)值越小表示覆蓋精度越高; Average_Precision代表標記排名平均分高于一個特定的標記y∈Yi, Average_Precision為1時, 是算法表現(xiàn)最好的時刻.
4 抽油機故障診斷應(yīng)用舉例
本文中對抽油機正常工作、地層出砂、泵漏失前期、泵漏失共四種工作狀態(tài)進行診斷, 四種工作狀態(tài)對應(yīng)的示功圖曲線如圖3所示.
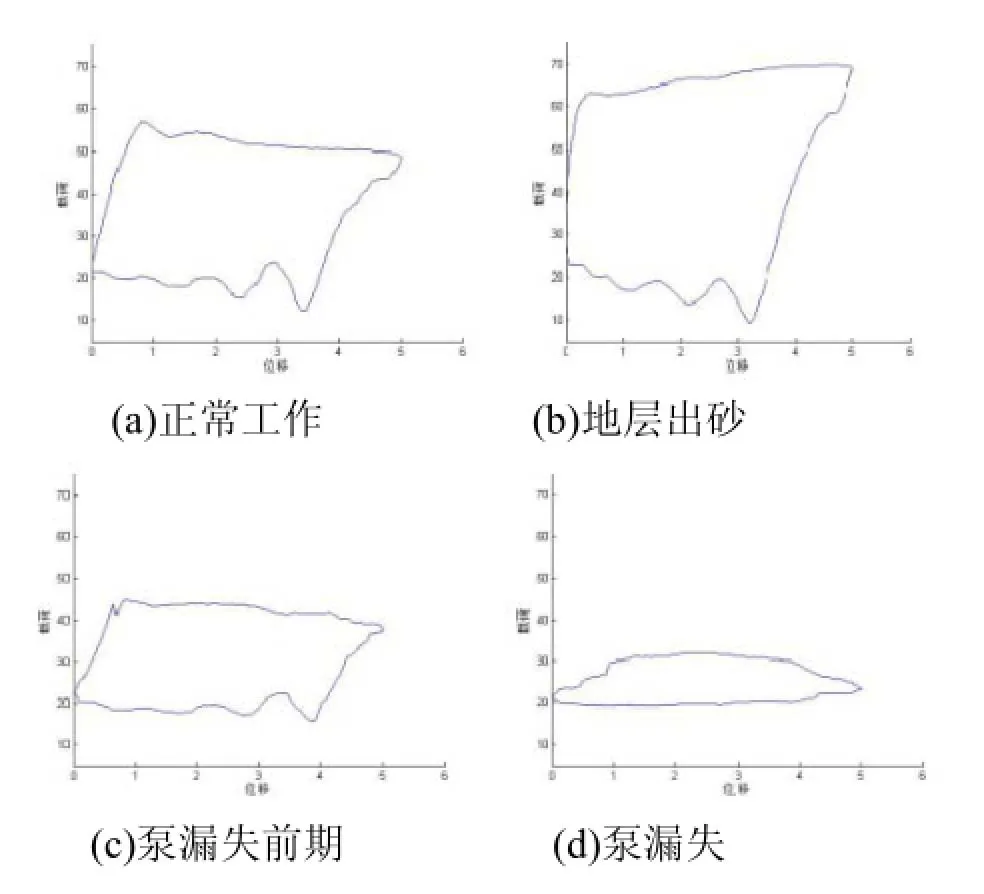
圖3 抽油機示功圖曲線
本次試驗共使用了173條抽油機工作數(shù)據(jù)作為樣本數(shù)據(jù), 其中123個樣本最為訓練數(shù)據(jù)集(trainbags), 50個樣本作為測試數(shù)據(jù)集(testbags). 173個樣本數(shù)據(jù)中49個樣本數(shù)據(jù)的上載荷穩(wěn)定在55KN左右, 且功圖曲線光滑平穩(wěn), 滿足正常工況數(shù)據(jù)特征; 35個樣本數(shù)據(jù)的上載荷下降, 重復(fù)度降低, 為泵漏失前期的特征; 42個樣本數(shù)據(jù)幾乎不見上載荷, 為泵漏失數(shù)據(jù)的特征; 35個樣本數(shù)據(jù)加載線的斜率明顯增大, 為地層出砂的典型特征. 173個樣本數(shù)據(jù)對應(yīng)的功圖見圖4, 與圖3進行比較, 可看出樣本數(shù)據(jù)很好的代表了本文中進行診斷的4種抽油機工作狀態(tài).

圖4 樣本數(shù)據(jù)疊加示功圖
訓練中使用的SVM核函數(shù)為RBF核函數(shù),γ值分別取0.25、0.5、3. 另外, 輸入?yún)?shù)ratio*樣本包個數(shù)即為聚類數(shù)目, 在本次試驗中ratio取值為0.0325; 另一個輸入?yún)?shù)cost設(shè)置為1. 具體實驗結(jié)果見表1.
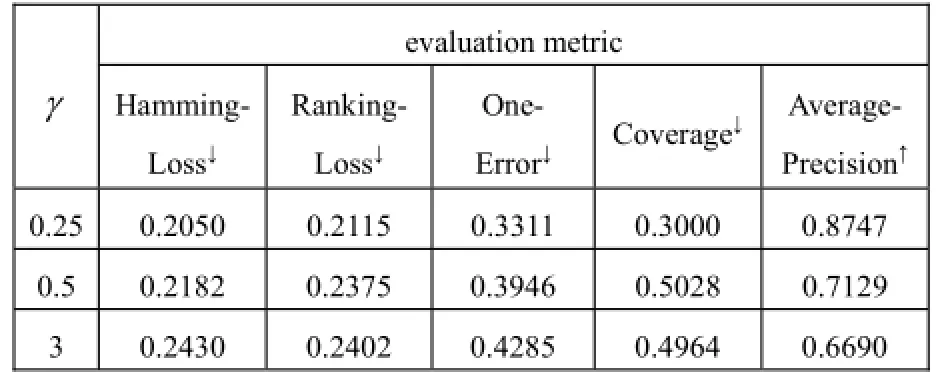
表1 MIMLSVM實驗表現(xiàn)
從表1中可以看出, 當γ值為0.25時, 各項算法評價指標體現(xiàn)出最好的結(jié)果, 此時聚類數(shù)目為4, 即當γ=1/k(k為聚類數(shù)目)時, 算法MIMLSVM能夠取得最佳效果.
5 結(jié)語
本文利用多示例多標記學習模型來解決抽油機故障診斷問題, 診斷結(jié)果能夠使人滿意. 由于抽油機是一個連續(xù)工作的機器, 其工況數(shù)據(jù)同樣也是隨時間連續(xù)的, 因此, 使用連續(xù)曲線之間距離度量方法代替Hausdroff距離計算兩包之間的距離一個今后值得研究的方面.
1 張楠.基于示功圖分析的抽油機故障診斷系統(tǒng)[碩士學位論文].大連:大連理工大學,2009.
2 王兵,許少華,孟耀華.基于半監(jiān)督競爭過程神經(jīng)網(wǎng)絡(luò)的抽油機故障診斷.信息與控制,2014,43(2):235–240.
3 張強,許少華,李盼池.對傳過程神經(jīng)網(wǎng)絡(luò)在油井故障診斷中的應(yīng)用.計算機工程與應(yīng)用,2013,49(2):9–12.
4 付光杰,周昕奇,王磊,牟海維.基于矩特征傅里葉描述的示功圖故障診斷研究.化工自動化及儀表,2015,42(4):401–405.
5 魏軍.基于支持向量機的抽油機故障診斷模型研究.計算機與數(shù)字工程,2014,42(11):2094–2098.
6 檀朝東,曾霞光,檀革勤,張杰.基于最小二乘法的抽油機示功圖自動分類及故障診斷.數(shù)據(jù)采集與處理,2010,25(增刊): 157–159.
7 Zhou ZH, Zhang ML. Multi-instance multi-label learning with application to scene classification. In: Sch?lkopf B, Platt J, Hofmann T, eds. Advances in Neural Information Processing Systems 19 (NIPS’06), Cambridge, MA: MITPress, 2007: 1609–1616.
8 Zhou ZH, Zhang ML, Huang SJ, Li YF. MIML: A framework for learning with ambiguous objects. CORRabs/ 0808.3231, 2008.
9 Chang CC, Lin CJ. Libsvm: A library for support vector machines [Technical Report]. Department of Computer Science and Information Engineering, Taiwan University, Taipei, 2001.
10 Zhang ML, Zhou ZH. A maximum margin method for multi-instance multi-label learning. Proc. of the 8th IEEE International Conference on Data Mining (ICDM’08). Pisa, Italy. 2008. 688–697.
11 Boutell MR, Luo J, Shen X, Brown CM. Learning multi-label scene classification. Pattern Recognition, 2004, 37(9): 1757–1771.
12 Edgar GA. Measure, Topology, and Fractal Geometry. Springer, Berlin, 1990.
13 Zhou ZH, Zhang ML, Huang SJ, Li YF. Multi-instance multi-label learning. Artificial Intelligence, 2008, 176(1): 2291–2320.
Pumping Unit Diagnose Based on Muli-Instance and Multi-Label
CHEN Yan1, XU Shao-Hua1,212
(School of Computer and Information Technology, Northeast Petroleum University, Daqing 163318, China) (The College of Information Science and Engineering, Shandong University of Science and Technology, Qingdao 266000, China)
The operating condition data of pumping unit can be described from the aspects of displacement, load and electric current. If only one feature vector is used to describe the operating condition of the pumping unit, the information will be too simplified, and it will lost some effective information. In view of the above problems and polysemy which is the essential characteristics of operating condition data, the fault diagnosis of pumping unit based on multi-instance and multi-label is presented. In this study, the displacement, load and current data of the pumping unit are used as multiple instances of pumping unit working condition data bags. Using k-medoids clustering algorithm cluster the bags and convert bags into several instances. Each dimension of the new instance indicates the distance from the bags to each cluster center, and then the MLSVM algorithm is used to solve the multi label problem. Experimental results show that multi-instance and multi-label learning can diagnose the trouble of oil pumping machine timely and accurately.
muli-instance multi-label; pumping unit; fault diagnosis
2015-11-18;收到修改稿時間:2016-01-04
10.15888/j.cnki.csa.005255
猜你喜歡
石油石化節(jié)能(2022年12期)2022-12-30 04:45:02
設(shè)備管理與維修(2022年21期)2022-12-28 07:35:42
裝備制造技術(shù)(2020年3期)2020-12-25 05:22:30
計算機測量與控制(2017年6期)2017-07-01 16:24:20
北京航空航天大學學報(2016年6期)2016-11-16 01:50:43
重慶工商大學學報(自然科學版)(2015年10期)2015-12-28 07:43:58
中國煤層氣(2014年6期)2014-08-07 03:07:05
振動、測試與診斷(2014年5期)2014-03-01 01:14:21
機械與電子(2014年1期)2014-02-28 02:07:31
河南科技(2014年16期)2014-02-27 14:13:19
