B樣條函數(shù)在大壩變形數(shù)據(jù)分析中的應(yīng)用
2016-02-17 06:55:07王江榮袁維紅任泰明
水力發(fā)電 2016年12期
王江榮,袁維紅,趙 睿,任泰明
(蘭州石化職業(yè)技術(shù)學(xué)院,甘肅蘭州730060)
B樣條函數(shù)在大壩變形數(shù)據(jù)分析中的應(yīng)用
王江榮,袁維紅,趙 睿,任泰明
(蘭州石化職業(yè)技術(shù)學(xué)院,甘肅蘭州730060)
用參數(shù)回歸模型分析處理大壩變形數(shù)據(jù)時存在著變量之間的函數(shù)關(guān)系需要預(yù)先設(shè)定的問題,而對于一些波動性大、規(guī)律性和整體性較差的大壩變形數(shù)據(jù),預(yù)選設(shè)定函數(shù)關(guān)系是困難的。為能較好地解決這類問題,建立了一種基于三次B樣條函數(shù)的非參數(shù)回歸模型。該模型是一種完全受觀測數(shù)據(jù)驅(qū)動的數(shù)學(xué)模型,具有建模簡單、適用強、精確度高和易于程序?qū)崿F(xiàn)的特點。對出現(xiàn)的模型的系數(shù)采用遺傳算法求解。實例分析表明,基于三次B樣條函數(shù)的非參數(shù)模型具有較高的擬合預(yù)測精度,能夠較好地解決實際問題。
變形數(shù)據(jù);非參數(shù)模型 ;B樣條函數(shù);遺傳算法;插值預(yù)測
0 引 言
大壩變形數(shù)據(jù)處理模型大多采用了參數(shù)回歸模型[1-4],這類回歸模型存在著變量之間(變形值—時間)的函數(shù)關(guān)系需要預(yù)先設(shè)定的問題,如果設(shè)定的函數(shù)關(guān)系與實際情況吻合,則統(tǒng)計推斷精度會比較高;反之,模型的統(tǒng)計推斷就會出現(xiàn)較大偏差,擬合預(yù)測效果會非常差,甚至沒有什么實際意義。但在實際問題中,變形實測數(shù)據(jù)之間的變量關(guān)系往往難以確定,因此利用參數(shù)回歸模型處理這類數(shù)據(jù)難以取得理想效果。而非參數(shù)回歸模型是一種不依賴于總體樣本分布,僅受數(shù)據(jù)驅(qū)動以及不受變量分布約束的模型,和參數(shù)模型相比,這類模型是更符合實際問題的一種回歸模型。選擇什么樣的非參數(shù)模型是解決問題的關(guān)鍵。樣條函數(shù),尤其是三次B樣條函數(shù)是一種非參數(shù)模型,具有良好的分段光滑性和全局逼近能力[5]。因此,本研究擬采用三次B樣條函數(shù)擬合變形數(shù)據(jù),并采用外插值延拓方法對建模以外的變形數(shù)據(jù)進行預(yù)測。由于三次B樣條函數(shù)擬合存在著矩陣求逆的問題,當(dāng)觀測數(shù)據(jù)越多時,矩陣的階就越高,求逆就越繁瑣。為了解決這個問題,本文采用遺傳算法( Genetic algorithms,GA )求解三次B樣條函數(shù)的擬合系數(shù)。
1 基于三次B樣條函數(shù)的非參數(shù)回歸模型
基于B樣條函數(shù)的非參數(shù)回歸模型是由B樣條基函數(shù)[6]通過線性組合而構(gòu)成的,它可以任意逼近連續(xù)函數(shù)[7]。為便于研究,本文采用均勻(任意相鄰節(jié)點間距離相等)三次B樣條基函數(shù)構(gòu)建非參數(shù)回歸模型。
1.1 均勻三次B樣條基函數(shù)
均勻三次B樣條基函數(shù)參考文獻[8]。即
(1)
式中,ti(i=0,1,2,…,n-1)為節(jié)點(它是時間t所屬區(qū)間的n等分點),常量h=ti+1-ti(i=0,1,2,…,n-1)。
由式(1)可知,Bi,3(t)的形狀僅與ti及h的選擇有關(guān)(形狀由節(jié)點和步長唯一確定),而其他的B樣條Bj,3(t)可由Bi,3(t)平移變換得到,即Bj,3(t)=Bi,3(t-(j-i)h)。
1.2 三次B樣條回歸模型
由式(1)可知,欲確定第i個三次(即4階)B樣條Bi,3(t),需要用ti,ti+1,ti+2,ti+3,ti+4共5個節(jié)點,稱區(qū)間[ti,ti+4]為Bi,3(t)的支撐區(qū)間。t0t1t2…tn+4為三次B樣條函數(shù)的節(jié)點序列(即數(shù)據(jù)擬合中共需n+1個三次B樣條基函數(shù)Bi,3(t))。用三次B樣條函數(shù)可以將非參數(shù)模型m(t)(m(t)是未知回歸函數(shù))近似地表示為
(2)
式中,xi為觀測時間點;模型系數(shù),Φ={θj|j=0,1,2,…,n},采用遺傳算法求解。
2 工程實例
某大壩變形監(jiān)測數(shù)據(jù)[9]見表1。在前32期數(shù)據(jù)中等間隔地取期數(shù)為3、7、11、15、19、23、27對應(yīng)的7個數(shù)據(jù)為測試數(shù)據(jù),其余25個數(shù)據(jù)為建模數(shù)據(jù),后4期即33、34、35、36對應(yīng)的數(shù)據(jù)用于外插預(yù)測檢驗數(shù)據(jù)。
前32期的觀測數(shù)據(jù)點如圖1所示。從圖1可以看出,數(shù)據(jù)點波動性較大,規(guī)律性和整體較差,故難以用參數(shù)模型(需事先選定)來擬合此類數(shù)據(jù)點,而選用基于B樣條函數(shù)的非參數(shù)模型能夠較好地解決此類問題。
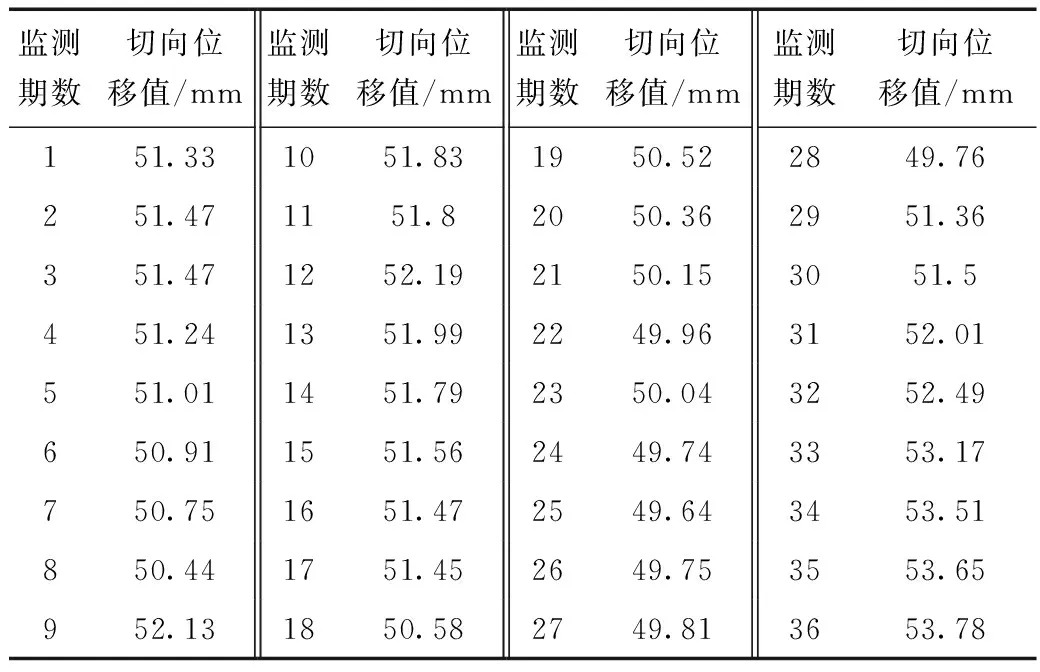
表1 大壩變形監(jiān)測數(shù)據(jù)
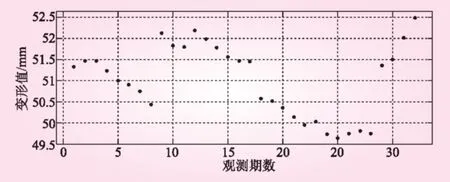
圖1 原始大壩切向位移監(jiān)測數(shù)據(jù)
3 三次B樣條擬合系數(shù)估算
按表1中1~32期觀測數(shù)據(jù)點設(shè)定均勻控制節(jié)點L=[0,4,8,12,16,20,24,28,32,36,40]。按式(1)每5個節(jié)點確定一個三次B樣條基函數(shù),共確定7個三次B樣條基函數(shù),分別記作B0,3(t),B1,3(t),…,B6,3(t)(具體表達式及圖形在此略去),由此構(gòu)建的非參數(shù)回歸模型為
(3)
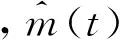
下面采用遺傳算法估算模型系數(shù)Φ=[m0,θ0,θ1,θ2,…,θ6]。定義目標(biāo)函數(shù)
(4)
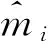
在MATLAB工作窗口利用gatool命令打開遺傳算法的GUI,在Fitnessfunction窗口輸入@finess,在Numberofvariables窗口輸入待估參數(shù)個數(shù)8,在邊界約束Lower輸入-80*ones(1,8),在Upper輸入 80*ones(1,8),種群規(guī)模為50,迭代次設(shè)為1 000,其他參數(shù)選用缺省值,然后單擊Start按鈕執(zhí)行遺傳算法。迭代400次后輸出的最優(yōu)模型系數(shù)為:m0=51.387 9,θ0=-0.904 2,θ1=1.426 6,θ2=-0.145 9,θ3=-1.077 9,θ4=-1.698 4,θ5=-1.893 3,θ6=2.196 7。將這些估算值代入模型(3),得
(5)
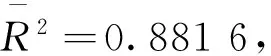
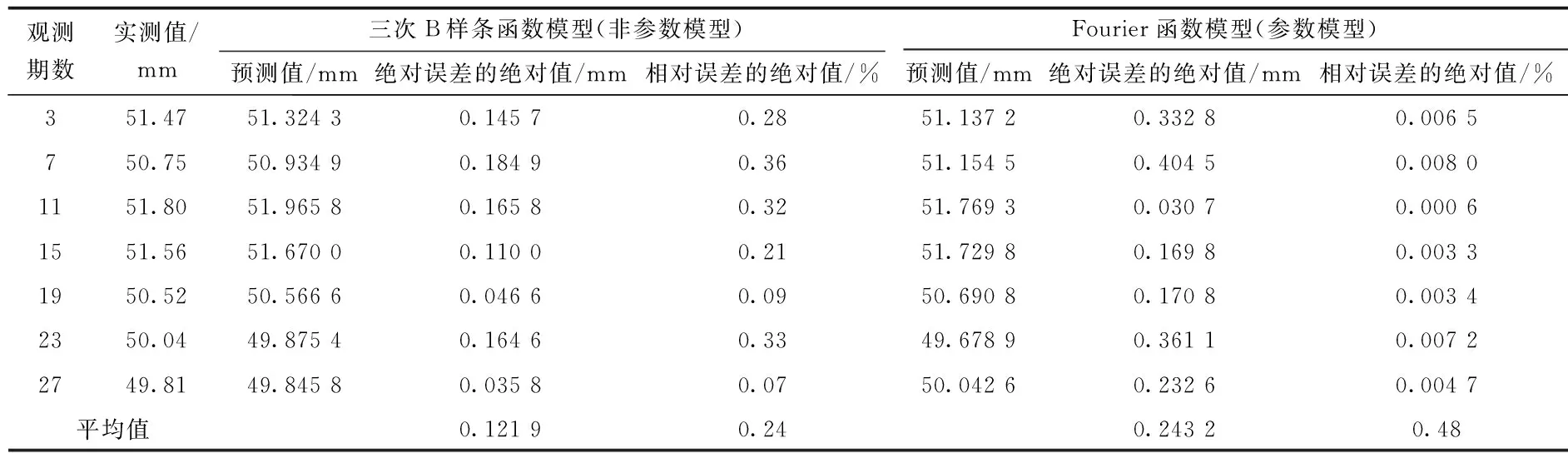
表2 模型預(yù)測值比較
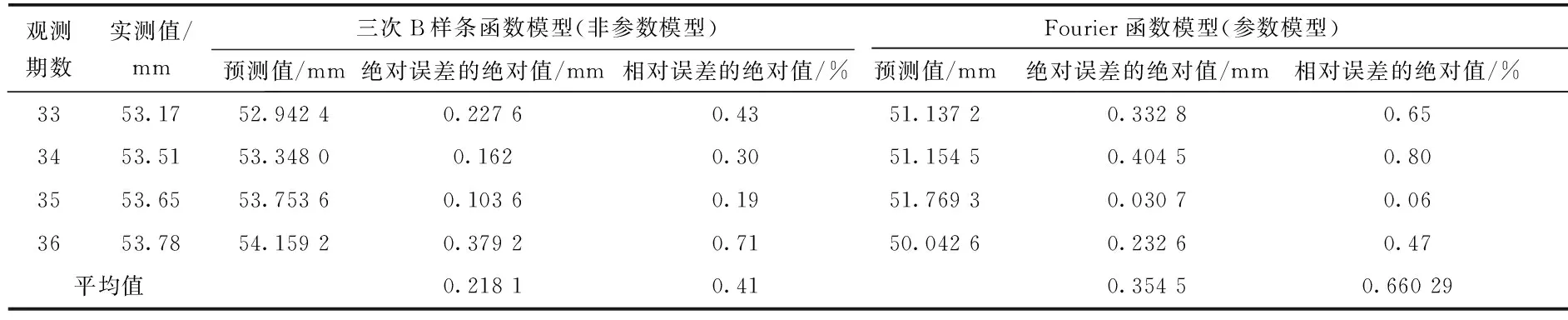
表3 均勻三次B樣條函數(shù)外插預(yù)測值
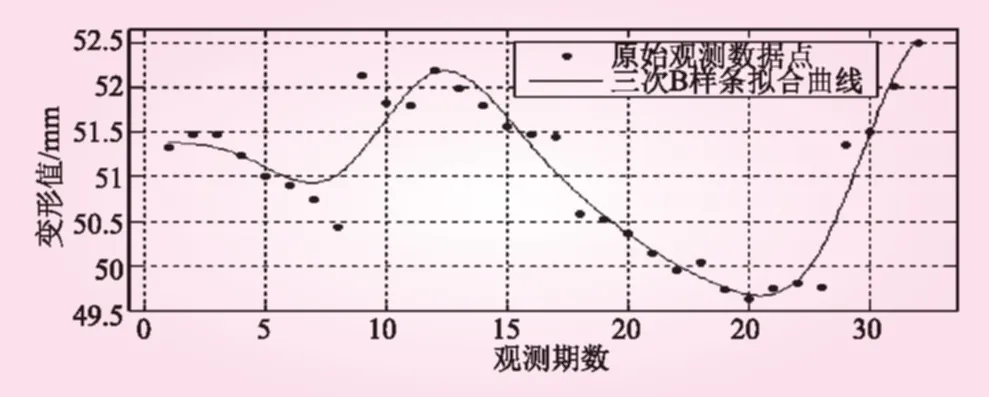
圖2 均勻三次B樣條函數(shù)的擬合預(yù)測曲線
作為對比,采用傅里葉函數(shù)建模(參數(shù)模型)如下
y=51.93+1.18cos(0.133 5t)-1.21sin(0.133 5t)-
1.123cos(0.133 5t)-0.871 9sin(0.133 5t)
(6)
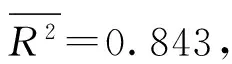
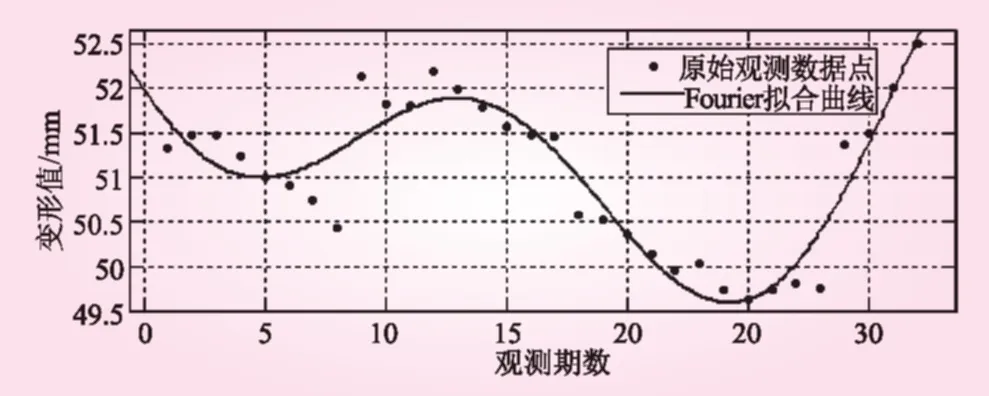
圖3 傅里葉函數(shù)擬合效果
從表2可以看出,基于三次B樣條的非參數(shù)模型具有較高的預(yù)測精度(最大絕對誤差不超過0.1849,相對誤差最大不超過0.33%),預(yù)測效果好于Fourier函數(shù)模型,預(yù)測精度提高近一倍,預(yù)測結(jié)果值得信賴。由于三次B樣條曲線是連續(xù)變化的,所以可通過該模型得到觀測時間段內(nèi)任意時間點的大壩變形值,這對研究大壩變形規(guī)律是非常有益的。利用前32期的擬合預(yù)測值對表1中后4期的變形值進行預(yù)測,計算過程采用MATLAB一維外插運算函數(shù)[10],即Y=interp1(),預(yù)測結(jié)果見表3。
從表3可看出,三次B樣條函數(shù)模型的預(yù)測精度高于傅里葉函數(shù)模型,最大絕對誤差不超過0.379 2,相對誤差最大不超過0.43%,能夠滿足工程需要。但是,需要指出的是,不管用哪種插值方法,當(dāng)插值點位于已知數(shù)據(jù)集合外時,插值運算對該處函數(shù)值的估計都很可能與實際函數(shù)值相比會有較大的偏差,從這點上講,本文得出的預(yù)測結(jié)果是令人滿意的。
4 結(jié) 論
(1)當(dāng)變形數(shù)據(jù)呈現(xiàn)出波動性大、整體性差且無規(guī)律狀態(tài)時,就難以選擇合適的參數(shù)模型作數(shù)據(jù)擬合預(yù)測,選擇不當(dāng)時就會出現(xiàn)較大誤差。而非參數(shù)模型是一種僅受數(shù)據(jù)驅(qū)動的模型,更適合實際問題的解決。B樣條函數(shù)能夠任意逼近連續(xù)函數(shù)(大壩變形是連續(xù)變化的),利用B樣條函數(shù)構(gòu)建的非參數(shù)模型具有較高的精確度,適合波動大、無規(guī)律數(shù)據(jù)建模。
(2)基于B樣條函數(shù)的非參數(shù)模型非常適合內(nèi)插值預(yù)測,這對研究時間區(qū)間內(nèi)的大壩變形規(guī)律具有重要的意義。其缺點是其外插預(yù)測能力較差,這是今后需要改進的地方。另外,B樣條函數(shù)擬合存在著矩陣求逆的問題,觀測數(shù)據(jù)越多,矩陣的階就越高,求逆就越繁瑣。為了解決這個問題,可采用遺傳算法求解B樣條擬合系數(shù)。
(3) B樣條基函數(shù)形狀僅與討論域(區(qū)間)上的節(jié)點(控制節(jié)點)有關(guān),這些基函數(shù)的線性組合構(gòu)成了的非參數(shù)回歸模型,該模型具有良好性的適用性、通用性,且容易通過程序?qū)崿F(xiàn),為解決大壩變形問題提供了一種新思路、新方法。
[1]王江榮. 高斯函數(shù)模型在變形監(jiān)測數(shù)據(jù)處理中的應(yīng)用[J]. 金屬礦山,2015(4):178-181.
[2]王江榮. Richards生長曲線模型在大壩變形監(jiān)測數(shù)據(jù)處理中的應(yīng)用[J]. 礦山測量,2015(5):59-61.
[3]王鳴,易武,鄧永煌. 基于自適應(yīng)搜索權(quán)重的滑坡位移組合預(yù)測[J]. 水力發(fā)電,2016,42(2):26-28,37.
[4]魏迎奇,孫玉蓮. 大壩沉降變形的灰色預(yù)測分析研究[J]. 中國水利水電科學(xué)研究院學(xué)報,2010,8(1):25-29.
[5]馮玉瑜,曾芳玲,鄧建松. 樣條函數(shù)與逼近論[M]. 合肥:中國科學(xué)技術(shù)大學(xué)出版社,2013.
[6]溫偉斌. 基于B樣條插值的數(shù)值流形方法與時間積分方法的研究[D]. 重慶:重慶大學(xué),2014.
[7]解其昌. 分位數(shù)回歸方法及其在金融市場風(fēng)險價值預(yù)測中的應(yīng)用[M]. 北京:中國農(nóng)業(yè)科學(xué)技術(shù)出版社,2014.
[8]劉昕明. 兩類非參數(shù)分位數(shù)回歸模型的研究[D]. 北京:北京化工大學(xué),2013.
[9]張安兵. 動態(tài)變形監(jiān)測數(shù)據(jù)混沌特性分析及預(yù)測模型研究[D]. 北京:中國礦業(yè)大學(xué),2009.
[10]王正林,龔純,何倩. 精通MATLAB科學(xué)計算[M]. 北京:電子工業(yè)出版社,2012.
(責(zé)任編輯 焦雪梅)
Application of B-Spline Function in Dam Deformation Data Analysis
WANG Jiangrong, YUAN Weihong, ZHAO Rui, REN Taiming
(Lanzhou Petrochemical College of Vocational Technology, Lanzhou 730060, Gansu, China)
There is a problem that the functional relationship between variables is necessary to be pre-set when processing dam deformation data by using parameter regression analysis. For the dam deformation data with large fluctuation, poor regularity and poor integrity, the pre-set of function relationship is difficult. In order to better solve this kind of problem, a nonparametric regression model based on Cubic B-spline function is established. The model is a mathematical model of complete observation data driven with the features of simple modeling, strong application, high accuracy and easy programming. The coefficient of model is solved by genetic algorithm. The empirical analysis shows that the new model has high prediction accuracy and can better solve practical problem.
deformation data; nonparametric model; B-Spline function; genetic algorithm; interpolation prediction
2016-03-17
蘭州市科學(xué)技術(shù)局計劃項目(蘭財建發(fā)[2015]85號);蘭州石化職業(yè)技術(shù)學(xué)院科技資助項目(院發(fā)〔2015〕69號);甘肅省科技廳計劃項目(1204GKCA004);甘肅省財政廳專項資金立項資助(甘財教[2013]116號)
王江榮(1966—),男,甘肅靜寧人,教授,碩士,主要從事數(shù)據(jù)挖掘、數(shù)值分析、控制理論與應(yīng)用方面的研究.
TV698.1
A
0559-9342(2016)12-0115-04
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
中華詩詞(2020年1期)2020-09-21 09:24:52
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
小學(xué)生作文(中高年級適用)(2018年5期)2018-06-11 01:22:56
數(shù)學(xué)小靈通·3-4年級(2017年10期)2017-11-08 08:42:59
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2017年11期)2017-04-23 07:18:00
數(shù)學(xué)大王·中高年級(2016年12期)2016-12-26 21:37:36
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
