基于節點相似度的個人網絡社交圈發現算法改進研究
2016-02-06 06:09:22顧益軍張大瀚
網絡安全技術與應用 2016年9期
◆劉 巖 顧益軍 張大瀚
(中國人民公安大學網絡安全保衛學院 北京 102623)
基于節點相似度的個人網絡社交圈發現算法改進研究
◆劉 巖 顧益軍 張大瀚
(中國人民公安大學網絡安全保衛學院 北京 102623)
隨著互聯網和在線社交平臺的飛速發展,社會網絡開始發展壯大起來,針對社會網絡的研究也變得越來越熱門。特別是在大數據時代,社會網絡研究的價值和意義也將越來越大。個人網絡是一種特殊的社會網絡,針對個人網絡的社交圈發現算法研究意義重大。各種社交平臺基本都允許用戶將其朋友手動劃分到不同的社交圈中,但是對個人網絡社交圈進行自動劃分的方法研究十分稀少,不斷變龐大、變復雜的個人網絡致使對其社交圈發現算法研究的難度也在不斷提高。Julian等人于2012年首先提出了基于概率模型的個人網絡社交圈發現算法(DSCEN算法),實驗證明該算法可以有效發現個人網絡中的社交圈,并允許社交圈存在重疊、嵌套。本文在研究DSCEN算法的基礎上,加入節點相似度因素對算法進行改進,并同時考慮屬性相似度和拓撲相似度保證節點相似度的準確性。通過實驗驗證,改進后的算法具有更好的效果。
個人網絡;社交圈發現;DSCEN算法;節點相似度
0 引言
在現實生活中,人與人之間進行著各種各樣的活動,產生多種多樣的聯系,并且通過這些活動和聯系形成了復雜多樣的社交網絡。我們將社會個體通過活動和聯系形成的相對穩定的網絡稱為社會網絡[1]。隨著互聯網的發展,特別是以Facebook、Twitter、QQ、微博、微信等為代表的在線社交平臺的興起,使得社會網絡變得復雜多變,動輒成千上萬的網絡節點和連接給社會網絡的分析帶來了巨大的挑戰[2]。
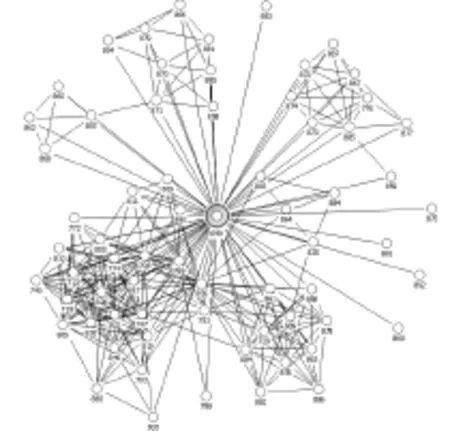
圖1 個人網絡示意圖
個人網絡是指以一個獨立的節點(即個人)為中心,包含其所有相鄰節點和他們之間的連接,由此形成的網絡為個人網絡。個人網絡的特點就是在網絡中有一個節點為中心,網絡中的其他所有節點都與該節點存在連接,如圖1所示即為一個個人網絡(其中698號節點為中心節點)。現實社會中,每個人都不是一個孤立的個體,而是總會與其他人保持關聯,這樣每個人都會有自己的社交網絡,并且隨著人類活動的推進,個人網絡也在時刻發生著改變。特別是在互聯網已經深入到人類生活方方面面的信息時代,隨著各種在線社交平臺的興起、壯大,傳統的社交模式正經歷著翻天覆地式的變革,個人網絡開始變得越來越復雜。
雖然各種在線社交平臺基本都會提供社交圈的劃分功能,對用戶維護自己的社交圈和個人網絡起到了巨大的作用。但其社交圈的劃分基本上是由用戶手工劃定,費時費力,并且在個人網絡不斷變化的同時,社交圈的劃分不能做到及時自動更新。同時,個人網絡的社交圈發現具有很大的研究價值,主要有以下幾點:[3]
(1)有助于用戶對自己的社交圈和個人網絡的維護和及時更新;
(2)有助于深入理解個人網絡的拓撲結構和本質,發現其中的隱藏規律,預測網絡行為,分析網絡的發展過程,從而對個人網絡的內部結構有更深刻直觀的了解;
(3)有助于深入探索個人網絡中節點之間的邏輯關系,展現網絡中節點的聚集情況;
(4)公安機關對個人網絡中社交圈的分析和發現可以充分準確的挖掘社會個體尤其是犯罪嫌疑人的個人信息和社交網絡,進而發現犯罪團伙的組織架構,給破案帶來極大的幫助。
為此,本文將在前人的研究基礎上,提出一種針對個人網絡的社交圈發現算法,并利用該算法有效的得到個人網絡中的各個社交圈。該算法發現的社交圈模型應具有以下三點性質:[4]
(1)同一社交圈內的各個節點必須有相似的性質或屬性;
(2)不同社交圈應該是由不同的性質或屬性形成的;
(3)社交圈應該允許重疊、嵌套現象發生。
1 DSCEN算法
目前,社區發現算法的研究比較多,但針對個人網絡的社交圈發現算法研究相對較少,個人網絡是一種特殊的社會網絡,有著其特有的性質,在社交圈發現過程中需要進行特定的研究。Julian等人于2012年提出了個人網絡的社交圈發現算法(DSCEN算法)[4],首先關注并研究了個人網絡的社交圈發現算法。2014年,Julian等人采用MCMC方法對DSCEN算法進行改進,提出MCMCS_SCD算法[5],大大降低了時間復雜度。黃佳鑫等人在MCMCS_SCD算法的基礎上提出SCD_MCMCS_LCD算法[6],加入局部模塊度和節點間緊密度因素,降低了算法時間復雜度的同時也提高了算法的準確度。本文將著重研究DSCEN算法,在該算法的基礎上加入節點相似度因素,提高算法的準確度。
在DSCEN算法中,首先定義個人網絡),(EVG=,其中V指節點的集合,E指邊的集合。接著定義G中任意兩個節點x、y之間存在連接的概率,公式如下:
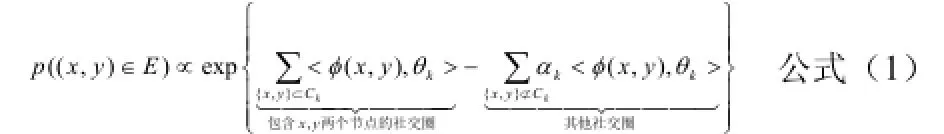
其中kθ表示社交圈kC的特征向量,),(yxφ表示節點x、y之間的屬性向量。由公式(1),可得到在社交圈集為C情況下關于G的對數似然函數,即公式(2):
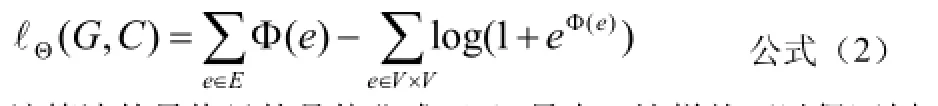
該算法的最終目的是使公式(2)最大,這樣就可以保證劃分的社交圈集C最優。從而將個人網絡G的社交圈識別問題轉化為求對數似然函數即公式(2)的最大值問題。
在社交圈識別過程中,為了求得公式(2)的最優值,通常在給定社交圈集kCC(即除kC外的其他社交圈集)條件下,求kC的最優值,公式如下:
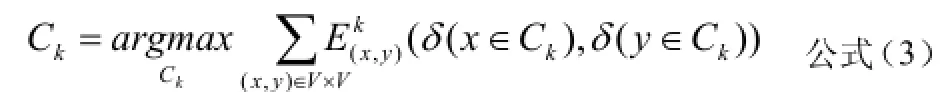
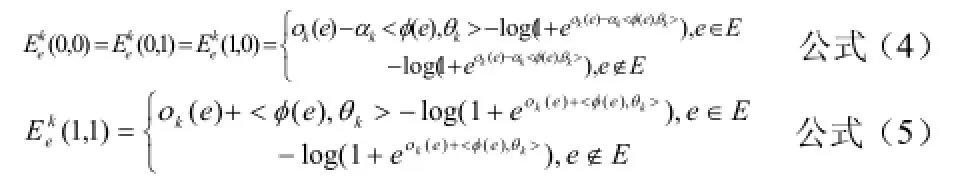
在對社交圈kC的kα值和特征向量kθ進行優化時采用了L-BFGS算法,這是一種典型的擬牛頓法[10],分別對kθ和kα進行求偏導,公式如下:

2 對DSCEN算法的改進
在DSCEN算法中,根據公式(1)我們可以看出,在定義G中兩個節點間存在邊的概率時,僅考慮了G的社交圈劃分以及節點間的屬性向量、社交圈的特征向量三方面的因素,而對兩個節點間的其他屬性考慮較少,特別是對節點間存在邊的概率影響較大的節點相似度因素并未考慮在內。
在社會網絡分析中,節點相似度是用來衡量節點與節點之間相似程度一個重要指標,我們認為,兩個節點的相似度越高,節點之間存在連接的可能性也就越大,即節點間存在連接的概率應與節點相似度成正比[11]。所以公式(1)可以進行如下改進:

其中,),(yxs表示節點x與節點y的相似度。在社會網絡分析中,兩節點的相似度不僅與這兩個節點的屬性相關,還與這兩個節點所處的局部網絡環境相關,因此,在分析兩個節點的相似度時,不能單一地考慮節點屬性或節點所處的環境因素,而應該將能影響節點相似度的因素進行綜合考慮,這樣得出的節點相似度才能越接近真實值。根據節點屬性和局部網絡環境因素,定義公式如下:

其中),(yxfs表示節點x和y之間的屬性相似度,),(yxts表示節點x和y的拓撲相似度[12]。在計算兩節點的屬性相似度時,用余弦相似度來計算[13]。在計算兩個節點之間的拓撲相似度時,用Jaccard相似度來計算[14]。
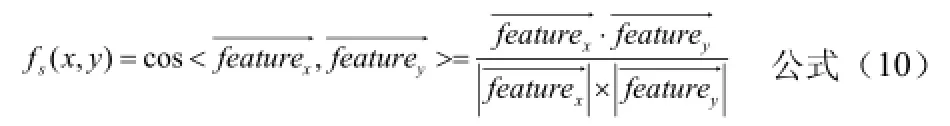

其中N(x)和N(y)表示節點x和y的鄰居節點,Jaccard相似度表明,當兩個節點擁有的共同鄰居在兩節點所有鄰居中所占的比重越大時,這兩個節點的相似度就越高[15]。通常情況下,節點x的鄰居節點不包含節點本身x,這就導致那些相連但沒有公共鄰居節點的節點相似度為0,可以將節點本身包括在它們的鄰居節點中來進行糾正。
由以上的分析,可推導出在DSCEN算法中公式(2)改進如下:
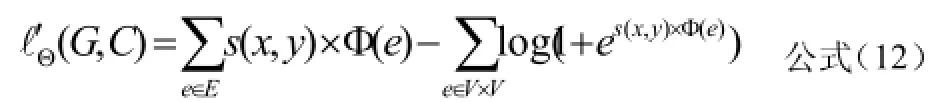
公式(4)、(5)可改進如下:
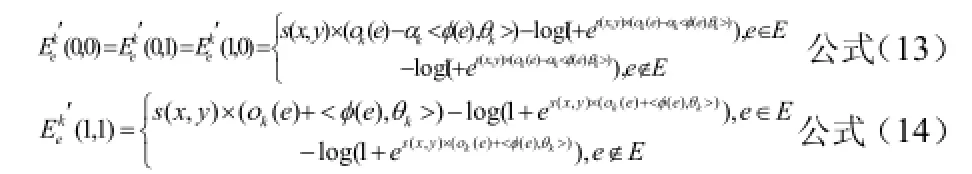
公式(3)改進如下:
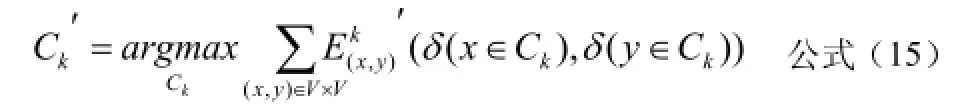
對公式(6)、(7)的改進如下:
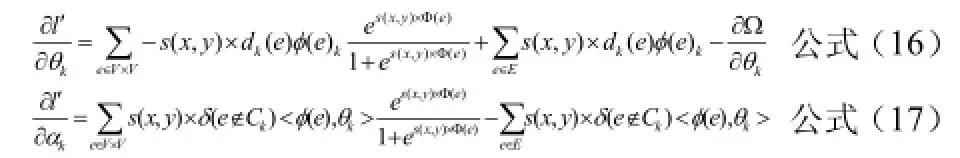
3 實驗結果與分析
3.1 算法的評估指標
在DSCEN算法中,用平衡誤差率[4](Balanced Error Rate,BER)和1F分數[4]作為指標來評估算法的準確度,當算法預測的社交圈集為,真實社交圈集為時,平衡誤差率和1F分數的公式分別如下:

由于預測的社交圈個數與真實的社交圈個數之間可能存在差異,在進行實驗評估時,首先需要對預測的社交圈和真實的社交圈進行線性匹配,找到預測社交圈集C和真實社交圈集的一個映射f,通過公式(20)和公式(21)來分別計算預測社交圈集C和真實社交圈集的(1-BER)值和F1分數。

3.2 實驗數據
實驗數據采用斯坦福大學SNAP(Stanford Network Analysis Project)小組提供的Facebook數據集,該數據集共包含了10個用戶的個人網絡,總共4039個用戶和193個社交圈,平均每個用戶擁有19個社交圈,每個社交圈平均有22個好友。本文中的實驗選取了其中4個規模不同的個人網絡,其中1號個人網絡中有348個用戶節點,2號個人網絡中有228個用戶節點,3號個人網絡中有160個用戶節點,4號個人網絡中有171個用戶節點。
3.3 實驗方案
本論文將采取對比實驗的方法。實驗中,首先進行兩組對比實驗,用以確定相似度公式中參數β的值。這兩組實驗分別設置K=3和K=5,然后取}1,75.0,5.0,25.0,0{=β這五個數值進行實驗,比較各組實驗結果,確定最優β值。
在確定β值后,接下來就需要進行實驗分析改進后的DSCEN算法的效果。對這4個不同的個人網絡,分別取}15,10,3{=K進行實驗,將改進后算法的實驗結果與原DSCEN算法的實驗結果進行分析比較。在實驗中,除進行對比分析需要修改的實驗參數外,其他的實驗參數均采用原DSCEN算法中的推薦參數。
3.4 實驗結果和分析
圖2和圖3是當K=3,β取不同值時,對不同的個人網絡進行社交圈識別后的1F分數和(1-BER)的結果。圖4和圖5是當K=5,β取不同值時,各網絡的1F分數和(1-BER)的結果。從這四個圖中,可以明顯地看出當β取不同值時對實驗結果將產生重要的影響,并且對于不同的個人網絡,不同的β值對算法準確性的影響也是各不相同的。例如當K=5時,對于3號個人網絡來說,β=0.75時算法的準確性更高,而對于4號個人網絡而言β=0.25時算法準確性更高。
綜合考慮實驗中不同的個人網絡,計算各個網絡的平均1F分數和平均(1-BER)值,可以發現:對于K=3和K=5這兩組實驗,當β=0.25或0.75時,實驗結果中的平均1F分數和(1-BER)都比較高,即算法的準確性更高。需要注意的是,這并不是肯定的結果,由于個人網絡千差萬別,針對特定個人網絡的社交圈劃分,都應有一個最優的β值,這里采取平均效果較好的β=0.25和0.75進行接下來的對比實驗。

圖2 β取不同值時1F分數比較(K=3)

圖3 β取不同值時(1-BER)比較(K=3)

圖4 β取不同值時1F分數比較(K=5)
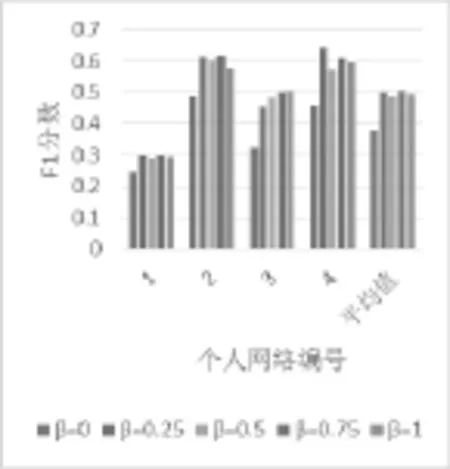
圖5 β取不同值時(1-BER)比較(K=5)
確定了β值后,接下來需要進行實驗比較分析改進后的DSCEN算法的性能。根據實驗方案,分別取}15,10,3{=K,進行實驗,將改進后算法的實驗結果與原DSCEN算法的實驗結果進行比較。圖6、圖7、圖8為實驗結果圖。從圖中,可以明顯地觀察到對于大部分的個人網絡而言,改進后的算法的不論是在1F分數還是在(1-BER)上都有了一定的提升,但由于改進后的算法準確度很大程度上需要依賴于β值的設置和優化。同時由于考慮到個人隱私問題,用戶在社交平臺上注冊的屬性信息往往是不完整并存在虛假信息情況,致使在計算節點的屬性相似度時存在誤差,進而影響了整個算法的準確度。所以,在個別網絡中也存在改進后的算法準確度低于原算法的情況。但是從總體上來看,即從平均結果來看,改進后的算法準確度較原算法還是有一定提升的。
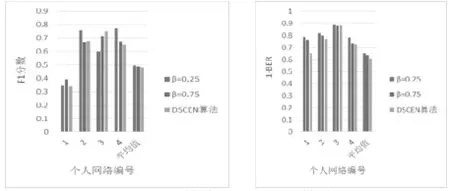
圖6 K=3時改進后算法與DSCEN算法的性能比較
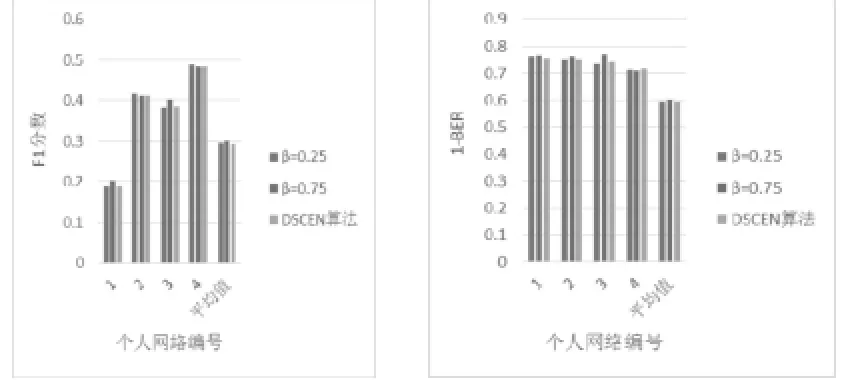
圖7 K=10時改進后算法與DSCEN算法的性能比較
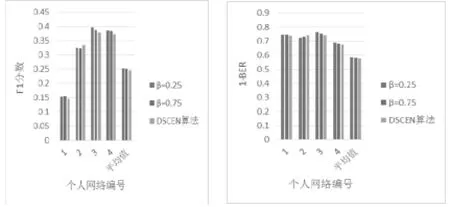
圖8 K=15時改進后算法與DSCEN算法的性能比較
4 結束語
隨著互聯網的快速發展,在線社交平臺的不斷壯大,個人網絡已經發生了翻天覆地的變化,從線下到線上,個人網絡變得越來越龐大,也越來越復雜,但是針對個人網絡的研究甚少,尤其是對個人網絡的社交圈發現的研究更少。
本文主要研究了針對個人網絡的社交圈發現算法——DSCEN算法,并在此基礎上提出了改進方案,綜合考慮了節點間的相似度因素。通過實驗,驗證了改進后的算法在社交圈發現的準確性上比原算法有所提高。
在實驗中,改進后的算法準確度很大程度上依賴于β的取值情況,而對于不同的個人網絡,最優β值往往又是不相同的,以后還需要對最優β值的確定做進一步的研究討論。
[1]劉軍.社會網絡分析導論[M].社會科學文獻出版社,2004.
[2]孫迎友.復雜動態網絡的狀態估計方法研究[D].南京郵電大學,2014.
[3]辛佰惠.基于MMSB的加權社交網絡社團發現算法研究[D].電子科技大學,2014.
[4]McAuley J J,Leskovec J.Learning to Discover Social Circles in Ego Networks[C]//NIPS,2012.
[5]Mcauley J,Leskovec J.Discovering social circles in egonetworks[J].ACM Transactions on Knowledge Discovery from Data(TKDD),2014.
[6]黃佳鑫,郭紅,郭昆.基于影響簇選擇模型和 MCMC采樣的社交圈子識別算法[J].福州大學學報(自然科學版),2015.
[7]班艷麗,柴喬林,王琛.基于能量均衡的 ZigBee 網絡樹路由算法[J].計算機應用,2008.
[8]Kolmogorov V,Rother C.Minimizing nonsubmodular functions with graph cuts-a review[J].Pattern Analysis and Ma chine Intelligence,IEEE Transactions on,2007.
[9]Boros E,Hammer P L.Pseudo-boolean optimization[J].Discrete applied mathematics,2002.
[10]Nocedal J.Updating quasi-Newton matrices with limit ed storage[J].Mathematics of computation,1980.
[11]張健沛,姜延良.一種基于節點相似性的鏈接預測算法[J].中國科技論文,2013.
[12]王玙,高琳.基于社交圈的在線社交網絡朋友推薦算法[J].計算機學報,2014.
[13]張滬寅,溫春艷,劉道波,等.改進的基于本體的語義相似度計算[J].計算機工程與設計,2015.
[14]王林澍.社會網絡中的鏈接分析與預測研究[D].哈爾濱工程大學,2013.
[15]張宏志.社會網絡中社團發現算法研究[D].湘潭大學,2013.
[16]趙一甲.社會網絡中社團發現算法研究[D].電子科技大學,2013.
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
天津外國語大學學報(2021年3期)2021-08-13 08:32:18
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
科技傳播(2019年22期)2020-01-14 03:06:54
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
汽車工程學報(2017年2期)2017-07-05 08:13:02
發明與創新(2016年38期)2016-08-22 03:02:52
