基于MapReduce海量視頻數據并行計算系統的設計
2016-01-19 02:46:07李虎俊張天凡
湖北工程學院學報 2015年6期
李 哲,李虎俊,張天凡
(1.湖北工程學院 新技術學院,湖北 孝感 432000; 2. 湖北職業技術學院 繼續教育學院,湖北 孝感 432000;
3.西北工業大學 自動化學院,陜西 西安 710072)
基于MapReduce海量視頻數據并行計算系統的設計
李哲1,3,李虎俊2,張天凡1,3
(1.湖北工程學院 新技術學院,湖北 孝感 432000; 2. 湖北職業技術學院 繼續教育學院,湖北 孝感 432000;
3.西北工業大學 自動化學院,陜西 西安 710072)
摘要:在總結視頻圖像數據處理現狀的基礎上,針對海量視頻數據的并行化處理問題,提出一種基于MapReduce的并行計算系統設計方法。該系統使用NVIDIA JETSON TK1搭建并行計算集群,在此基礎上利用Hadoop實現了MapReduce。 在此平臺上設計基于CUDA的并行數據處理算法對千萬條文本數據進行處理,分析了其數據裝載時間、處理時間和全部任務處理時間。結果表明,該系統當前加速比約為4.73,與C/S單機相比,處理速度有較大程度的提高,為實現實時海量視頻圖像處理奠定了良好基礎。
關鍵詞:并行計算;海量視頻數據;MapReduce;Hadoop
中圖分類號:TP311.11
文獻標志碼:碼:A
文章編號:號:2095-4824(2015)06-0026-06
收稿日期:2015-09-17
基金項目:湖北工程學院自然科學基金(2013016,201515);湖北工程學院新技術學院自然科學基金(Hgxky14);湖
作者簡介:李哲(1986-),男,湖北漢川人,湖北工程學院新技術學院講師,博士研究生。
Abstract:On the summary of the status of video image processing, this paper proposes a parallel processing method for the parallel processing of massive video data which is based on parallel processing system by using the MapReduce technique. This system utilizes the NVIDIA JETSON TK1 to build parallel computation clusters and employs the Hadoop to perform the MapReduce. With the developed platform, a CUDA based parallel processing algorithm is designed to process tens of millions of text data for the analysis of the data loading time, the processing time of each task and the processing time of all tasks. The test results indicate that the acceleration rate of the system is about 4.73, which is much higher than the C/S mode in a single computer and offers a good foundation for the implementation of real-time massive video data processing.
當今,世界范圍的信息化變革幾乎使每個行業都面臨著大數據(Big Data)問題[1]。大數據及其應用也一直是學術界關注的熱點問題。由于大數據具有體量大、速度快和異構性的特點,給數據的存儲、管理和分析帶來了巨大挑戰。特別在處理視頻圖像等非結構化數據方面上述問題尤為突出。因此,如何處理好視頻圖像數據對于大數據應用具有相當重要的意義。
1視頻圖像數據處理的現狀分析
(1)數據存儲密度不強,圖像壓縮算法適用性低。由于圖像和視頻屬于非結構化數據,因此無法采用類似結構化數據的方法進行壓縮。特別是視頻數據帶有時間三維結構,在某些應用必須保證足夠的數據有效性[2]。如視頻監控數據必須保證足夠的清晰度,以便后期對監控內容和細節信息(如車牌號、人物特征等)進行追蹤挖掘。因此,如何在保證足夠清晰度及時間維度的前提下,高效存儲海量視頻數據一直是人們的研究熱點。盡管出現了MPEG等動態圖像壓縮算法,但面對如“天網”工程所涉及的公共安全視頻數據而言,常規的數據壓縮算法仍存在明顯不足。
(2)數據運算量巨大,常規CPU計算不足。圖像視頻數據量巨大,常規CPU面向的是通用性任務處理[3],其在處理圖像視頻這樣密集性浮點運算時表現遠不如GPU。根據文獻[1]的分析表明,早在2012年,GPU的計算能力已經達到了3 gigaFLOPS,遠遠超出CPU的計算能力。因此,當前及未來圖像數據處理的發展向著CPU-GPU混合計算方向發展。CPU與GPU計算能力的發展如圖1所示。
(3)常規系統建設成本高,功耗大,使用率低。雖然如美國橡樹嶺實驗室的“泰坦”以及我國的“天河二號”是世界最強超級計算機的代表,具有
北省公安廳自主科研項目(鄂公傳發【2015】70號)
李虎俊(1958-),男,湖北漢川人,湖北職業技術學院繼續教育學院副教授。
張天凡(1982-),男,湖北孝感人,湖北工程學院新技術學院講師,博士研究生。
無與倫比的運算能力,能夠滿足海量數據的處理要求,但是這類超算系統往往建造成本巨大(僅“泰坦”二期升級就花費了9 000萬美元),而且功耗巨大(“泰坦”全速運轉功耗約為900 MW)[4],一般企業及個人用戶不太可能承受如此高昂的建造和運行成本。
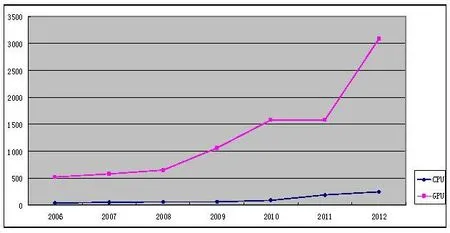
圖1 CPU&&GPU計算能力發展
針對典型視頻格式主要有三種處理平臺,分別是Intel的Quick Sync Video,ADM的APP和NVIDIA的CUDA。對這三個平臺進行基礎的性能測試,測試結果如表1所示。
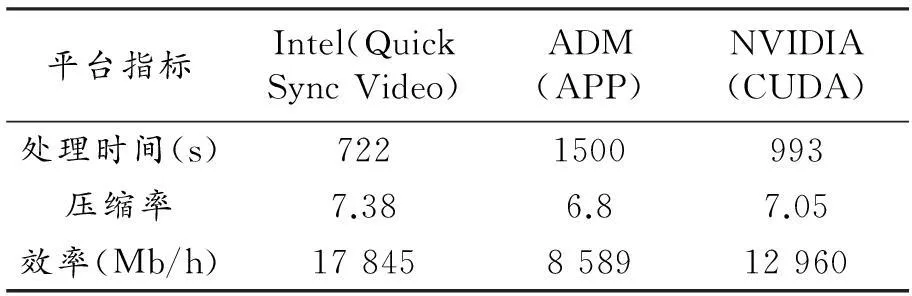
表1 視頻處理加速平臺常規指標測試表
注:視頻源規格:1080P、H.263、碼率28 Mbps、文件大小3579 MB,目標格式MP4、H.264碼率4 Mbps
根據對某市“天網工程”視頻監控系統的詳細調查,發現每天產生的數據峰值為33TB,按上述三個方案分別需要77套、106套和160套系統以并行方式處理才能滿足實時處理的要求,而所需建造系統的成本分別為37、30、75萬元,總功耗方面分別為12 kW.h、9 kW.h和27 kW.h。不難看出Intel和NVIDIA具有較明顯的優勢,但從實際中Intel的報價來看,其建造成本相比TK1系統要高出不少,這也是本項目選用NVIDIA JETSON TK1構建計算集群的重要原因。
根據以上問題,本文研究海量數據(圖像/視頻)的存儲和管理,為后期研究基于視頻的內容分析與挖掘建立相應的技術平臺。其中并行計算模型系統軟件部分選擇MapReduce,具體計算框架為Hadoop,硬件部分選用NVIDIA JETSON TK1(ARM處理器+NVIDIA GPU)構建并行計算集群。最后,利用CUDA技術優化海量視頻數據的壓縮過程。經過測試,該系統與C/S單機處理相比,能明顯提高海量數據的處理速度,為后期實現實時海量視頻圖像處理奠定了良好基礎。
2MapReduce相關技術
2.1MapReduce并行計算模型
Google于2004年提出了MapReduce,用于在大規模計算機集群上處理海量數據的并行計算[5-6]。MapReduce是一種基于鍵/值對的數據模型,該模型將復雜的分布式計算歸結為兩個階段:Map階段和Reduce階段。Map階段通常在數據存放本地進行計算,然后將Map輸出結果按鍵值映射到相應的Reduce 任務中。Reduce 階段對Map 階段結果匯總計算,從而得出最終計算結果。MapReduce 模型優勢在于簡單易用,靈活性高,獨立于云數據庫系統,且容錯能力強[7]。MapReduce設計了分布式文件系統DFS(Distributed File System),將數據分割成特定大小的數據塊,計算節點則處理距離其最近的數據塊,從而能獲得更高的數據可靠性和更快的數據訪問速度。MapReduce典型應用流程圖如圖2所示。
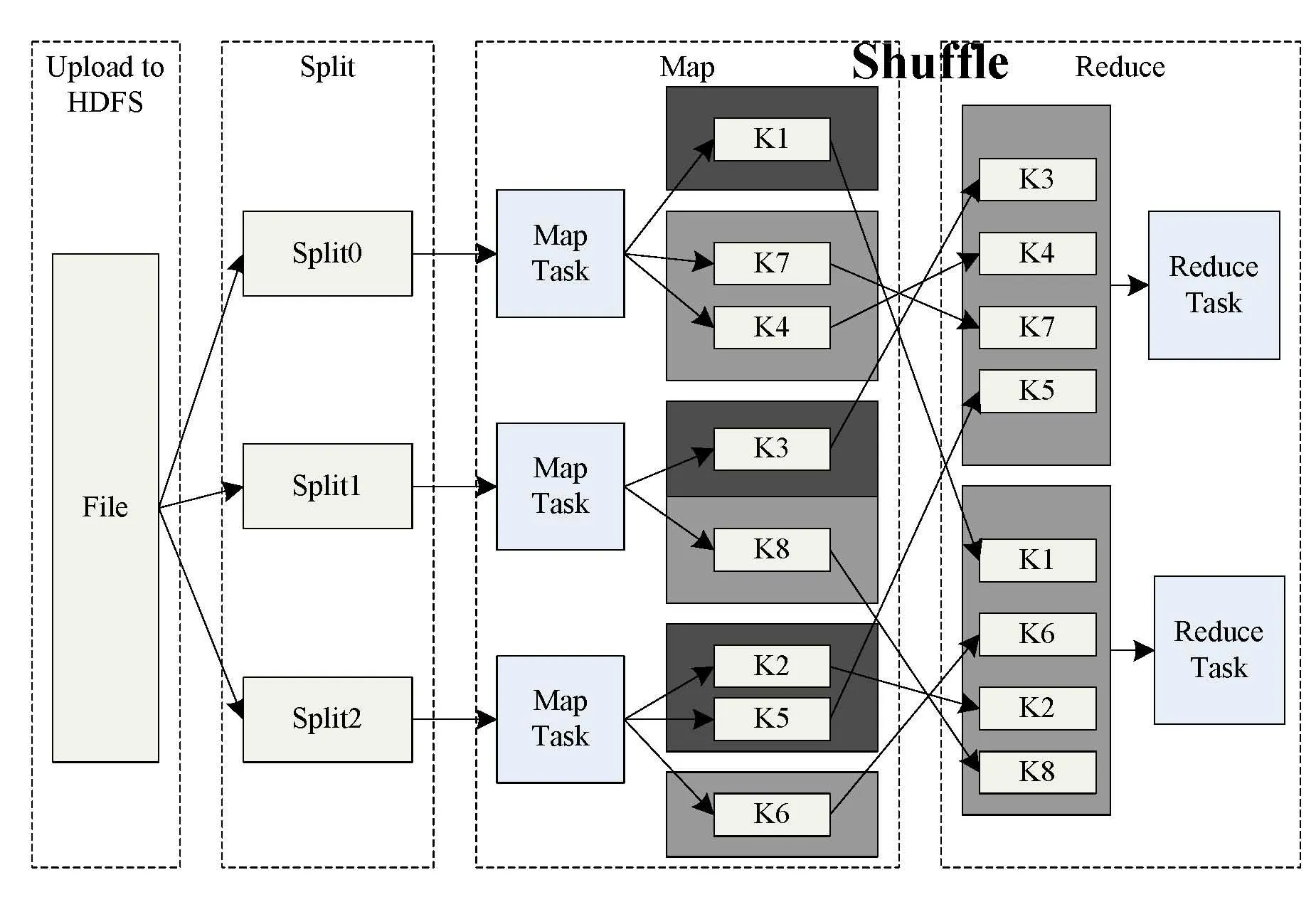
圖2 典型的MapReduce應用流程圖
2.2HDFS分布式存儲系統
作為MapReduce的具體實現,Hadoop分別實現了分布式文件管理系統對應的Google文件系統(Google File System)、映射/規約模型、混合性大數據庫系統。Hadoop的實現得到廣大開源用戶的支持,本系統選用了Hadoop作為MapReduce的具體實現。
盡管Hadoop實現了MapReduce,并且能夠將數據和任務進行分布式部署,但分布后的任務與具體算法實現仍然需要程序員編寫,因此需要在“微觀“層面開發具體的數據處理程序。由于典型的處理程序要么是單線程的,要么利用多線程技術發揮多核CPU的運算能力。但面對如視頻等數據密集型的非結構化數據處理,CPU的處理效率明顯降低。在圖像處理領域NVIDIA推出了統一計算設備架構(Compute Unified Device Architecture,CUDA),這是一種通用并行計算架構,該架構使得GPU能夠解決類似圖像處理等復雜的計算問題。因此在CUDA的基礎上優化海量視頻數據的壓縮過程,能夠有效應對海量視頻數據的管理和壓縮存儲要求。
3系統設計
3.1系統框架設計
選用NVIDIA JETSON TK1搭建并行計算集群,系統硬件結構總體框架圖如圖3所示。
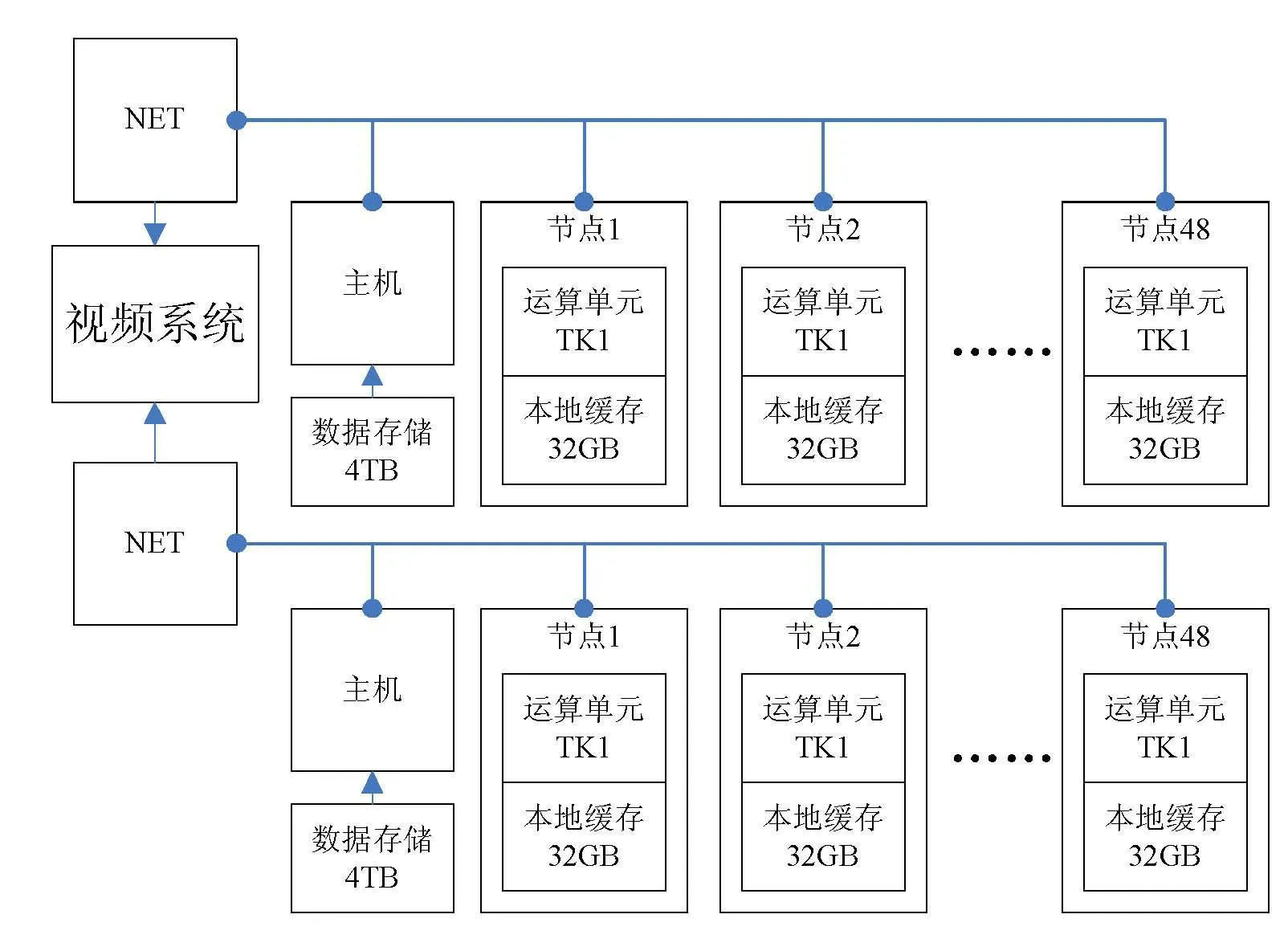
圖3 系統硬件結構總體框架圖
在系統硬件結構中,每個節點的核心TK1處理器部分包含四個ARM-A15內核,而GPU部分由192個CUDA組成,并且使用了與“泰坦”相同的“Kepler”超算架構。而單個TK1節點的零售價格僅為1600元,功耗低至10 W,完全滿足系統設定的視頻數據處理與分析的基本要求。多個節點配合監控主機和網絡通訊設備構成并行計算集群,最終系統由兩個子集群構成,每個集群擁有48個節點,其部署示意圖如圖4所示。
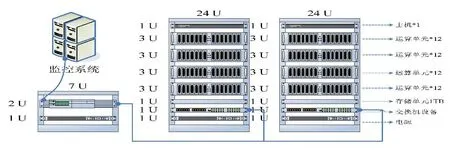
圖4 “天網”工程雙集群系統部署示意圖
該系統能夠有效地對視頻任務進行處理,根據示范應用單位具體需求,該系統原型機已于2015年5月裝配完畢,系統實物如圖5所示。

圖5 嵌入式并行計算系統“Medusa”原型機
為了對海量數據以及并行計算系統集群進行有效管理,該系統上選用了Google的MapReduce作為全局分布式任務管理框架,使用Hadoop的HDFS分布式文件管理系統實現海量數據的可靠存儲,在該基礎上編寫了基于CUDA的并行數據處理算法,系統文件存儲框架圖如圖6所示。
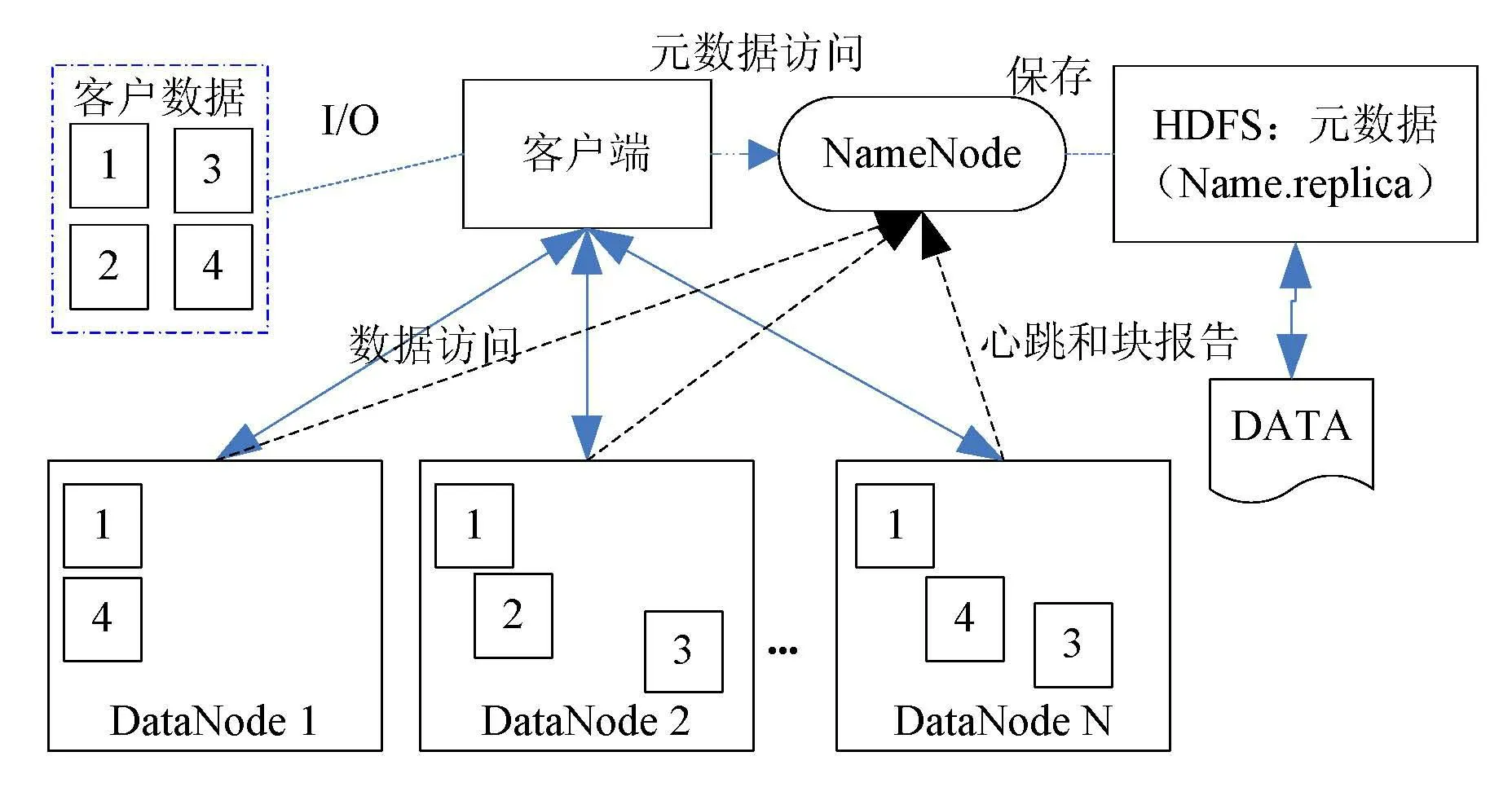
圖6 基于HDFS的分布式數據存儲框架圖
3.2系統處理流程
對系統原型機基本功能進行測試,測試數據選用20 GB文本數據進行排序,排序過程在嵌入式系統上部署Hadoop的方式來進行處理。
首先,通過NameNode或者外部分發數據,將數據分發到各個處理單元。從邏輯上而言,采用從NameNode上傳數據到虛擬的共享空間HDFS中;從物理上而言,實際的文件存儲機器為Slave l~Slave N,namenode僅負責對整個HDFS邏輯空間的維護,并不參與存儲。數據的分發存儲如圖7所示。
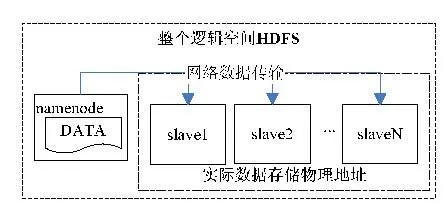
圖7 數據分發存儲
在數據分發過程中,將會產生兩個方面的時間損耗。一是傳輸時間,另一個是將數據寫入到每個Node的時間。但在傳輸的第一個時間周期過后,傳輸與數據寫入是并行的,之后利用MapReduce框架對數據進行排序。
在Map端,結果文件優先存儲在默認大小為100 MB的內存緩沖區,通過減少磁盤IO提高整體性能,直到該區溢出后才將溢出數據存放到磁盤中(見圖9中雙緩存機制是該機制的擴展)。當整個map過程完成后,緩沖區與磁盤中的所有臨時文件將合并生成最終的結果文件,而reduce task則負責對這些以key-value形式組織的結果文件進行最終匯總。
每當緩沖區收集默認為100 MB的數據時,緩沖區的數據將會寫入磁盤,然后重新利用這塊緩沖區進行,這個過程被稱為Spill(也叫做溢寫)。該過程是一個新的線程,與原有的Map線程并行進行。默認的溢寫閥值為0.8,即在默認配置下當緩沖區寫入80 MB數據后,就由溢寫線程將該組數據進行排序,而map task則繼續使用剩余的空間。MapReduce提供了默認的排序算法,在后正理中本文將利用如Apriori算法和并行SON算法提高系統相關性能。
當Map端任務完成且將結果存放于Slave中指定的目錄后,所有的reduce task將通過Job Tracker進行map task的完整性驗證。如果完整,則執行merge文件合并過程,如果驗證失敗,則要求該Map將該任務分配給其他節點重新執行任務,直到所有任務完成。整個map-shuffer過程如圖8所示。
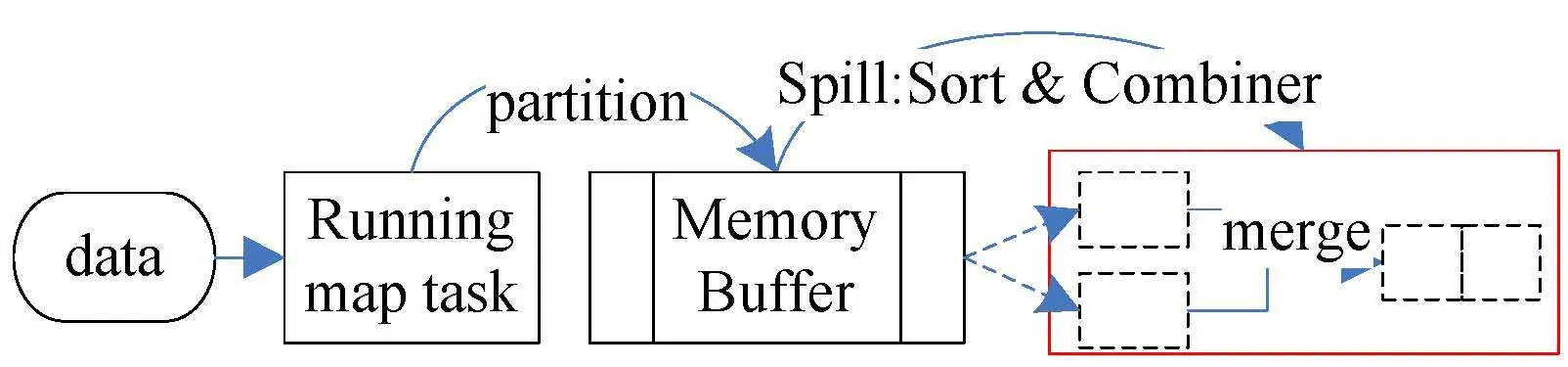
圖8 map shuffer過程
4系統測試及結果分析
4.1系統測試
(1)準備數據。原型機完成后使用千萬條文本數據(約20 GB)進行全文分析。編寫基于MapReduce框架下分布式數據處理程序。該程序的算法由RandomSelectMapper和RandomSelectReducer完成數據抽取,由ReudcerPatition完成數據劃分,由SortMapper和SortReducer用于數據結果的輸出。并行處理模型與基礎模型最大的區別在于并行處理模型在接收數據的同時,就可以開始(在雙緩沖數據處理功能支持下)排序(內部排序),其結構如圖9所示。
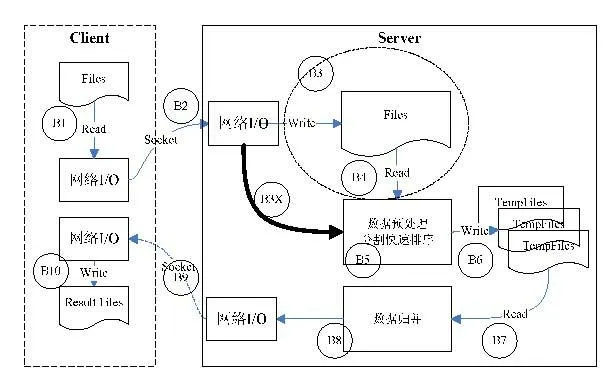
圖9 并行處理模型
由圖9可以看出,將原有的B3、B4步驟去掉,轉而將B2通過B3X直接鏈接到B5過程,那么B1~B3X~B6就構成一個新處理步驟,此部分速率關系為B3X=B5>B1>B6>B2,時間基準為B2,也可以得到該模型的整體時間公式為:
TD=B2+B9
(1)
根據數學模型定義式(1)可改寫為:
(2)
(2)搭建嵌入式系統集群環境。當主機啟動后,需在主機端使用start-all.sh命令開啟hadoop分布式集群系統,當節點初始化完畢后,將逐個加入到主節點中監管,當有31個節點接入集群中時,主節點監管結果如圖10所示。
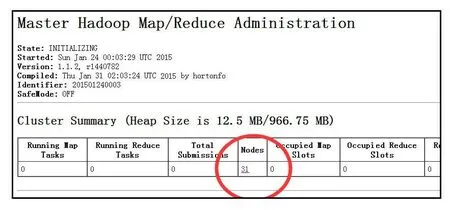
圖10 Hadoop Master Map/Reduce Administration
每個節點剩余外部存儲空間映射到的Linux系統/usr/hadoop/tmp/dfs路徑下,以分布式方式構成了56.26 GB的全局訪問空間,如圖11所示。
(3)任務運行監視。使用活動任務監視工具(Running Job)在主節點或監控終端的瀏覽器中查看當前任務執行的狀態(在瀏覽器192.168.1.132:50070上運行Running Job),如圖12所示。
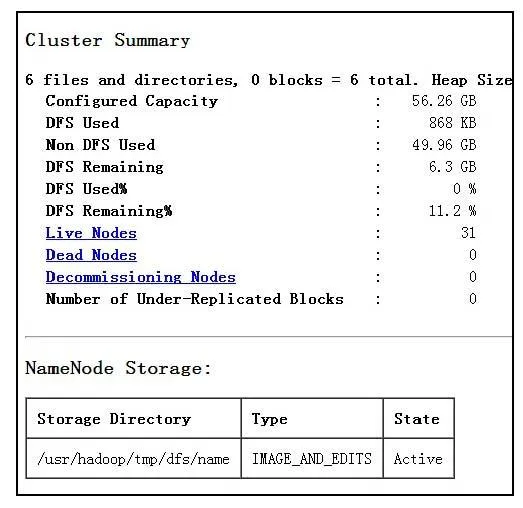
圖11 NameNode’Master.Hadoop:9000’
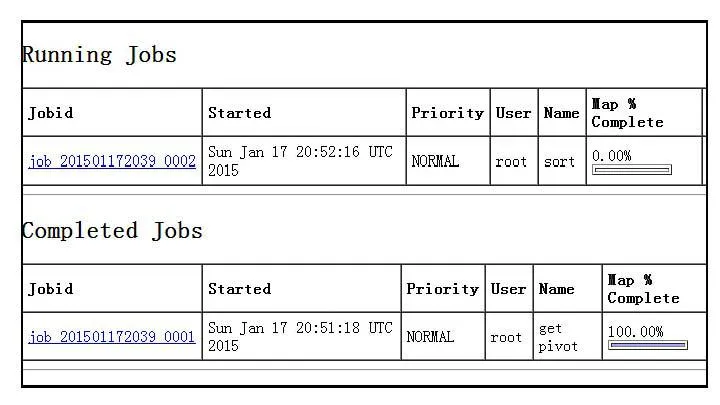
圖12 主節點(Master)上查看任務執行狀態
最后,當數據處理完畢后,從節點將退出處理過程并在監視終端中顯示其執行結果,當Map-Reduce過程完畢后,分節點的結果數據將會匯總到主節點的output目下,如圖13所示。
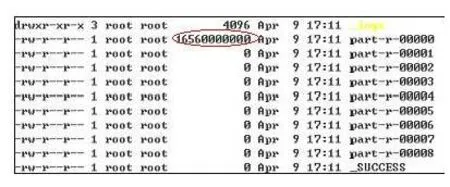
圖13 從節點運行結果在主節點匯聚為一個結果文件
在圖13中part-r-00000文件為最終結果匯總文件,而part-r-00001~00008文件是從節點文件,當數據匯總完成后從節點文件將清空,顯示為0 Byte。
4.2結果分析
在C/S構架和Hadoop集群兩種模型下測試,分別對三類測試數據進行測試,并通過比較數據裝載時間、處理時間和全部任務處理時間進行性能分析,其中測試數據如表2所示。
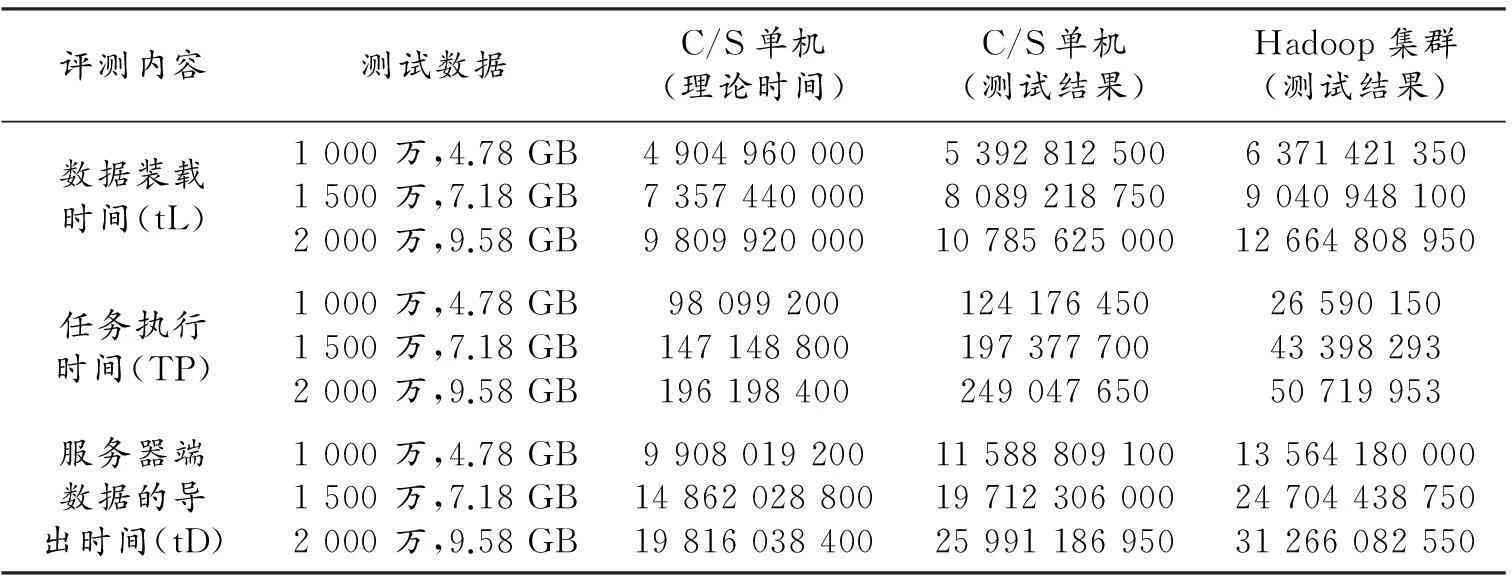
表2 兩類系統模型測試結果一覽表
圖14是數據裝載時間、處理時間以及全部任務耗時對比結果。
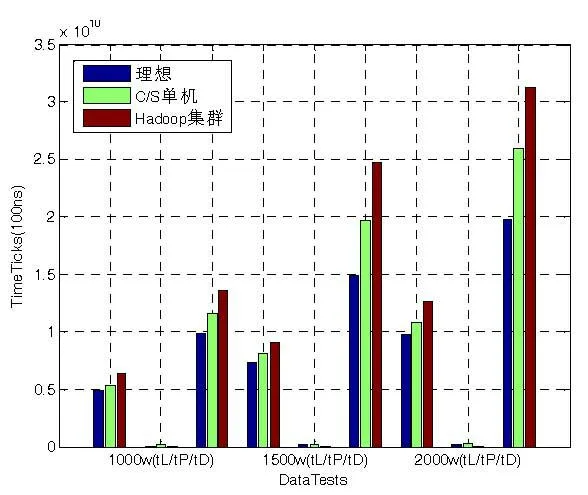
圖14 數據裝載時間對比圖
由圖14的對比結果可知:
1)兩種模式在數據傳輸上消耗的時間均比理想時間要多,其中C/S模型消耗的時間主要開銷為網絡帶寬及傳輸控制協議的損失,而Hadoop集群在數據分割和任務分派方面消耗了較多時間;
2)在數據處理過程中,由于Hadoop采用的是并行結構,而C/S模型是單機四核四線程并行方式,Hadoop總體上要比C/S單機方式運行速度快,根據測試數據表2可得加速比如表3所示。采用Hadoop集群處理平均加速比約為4.73,與理論加速比為31/4=7.75仍有較大差距,這也是未來對算法進行改進的重要性能指標。
3)任務處理所占時間非常小,僅為整個任務處理的1%左右,因此將數據駐留在節點重復利用,可大幅度提高系統的運行效率。
4)在進行視頻處理時,在任務級并行處理模式下無需將處理后的數據回傳給監控主節點,從而減少數據回傳給主節點造成的通信擁塞。
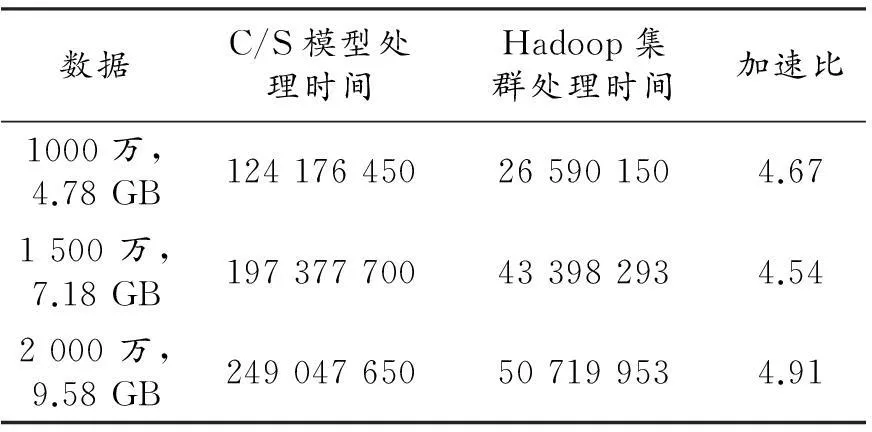
表3 C/S模型與Hadoop集群的加速比
5總結
本文詳細闡述了組建基于MapReduce計算框架并通過Hadoop具體實現并行計算集群的過程,實現了HDFS有效將數據和數據程序分布到各節點進行處理并將處理結果反饋給主機并行處理算法,通過海量文本數據全文分析對該分布式處理模型的有效性進行了驗證。結果表明,該系統加速比約為4.73,與單機處理方式相比,處理速度有較大程度的提高,為后期實現實時海量圖像處理奠定了基礎。
[參考文獻]
[1]CCF 大數據專家委員會. 大數據熱點問題與2013 年發展趨勢分析[J].中國計算機學會通訊, 2012, 8(12): 40-44.
[2]于戈, 谷峪, 鮑玉斌, 等. 云計算環境下的大規模圖數據處理技術[J].計算機學報, 2011, 34 (10): 1753-1767.
[3]孟小峰,余力.用社會化方法計算社會[J].中國計算機學會通訊, 2011, 7(12): 25-30.
[4]李哲,慕德俊,郭藍天,等.嵌入式多處理器系統混合調度機制的研究[J].西北工業大學學報,2014,33(1):50-56.
[5]Lee K H, Lee Y J, Choi H, et al. Parallel data processing with MapReduce: a survey[C]//Proceedings of the ACM SIGMOD Record, 2012, 40(4): 11-20.
[6]肖韜.基于MapReduce的信息檢索相關算法[D].南京:南京大學,2012.
[7]覃雄派, 王會舉, 杜小勇, 等. 大數據分析——RDBMS 與 MapReduce 的競爭與共生[J].軟件學報, 2012, 23(1): 32-45.
Research and Design of MapReduce Based Massive
Video Data Parallel Processing System
Li Zhe1,3,Li Hujun2,Zhang Tianfan1,3
(1.CollegeofTechnology,HubeiEngineeringUniversity,Xiaogan,Hubei432000,China;
2.SchoolofContinuingEducation,HubeiPolytechnicInstitute,Xiaogan,Hubei432000,China;
3.SchoolofAutomation,NorthwesternPolytechnicalUniversity,Xi'an,Shaanxi710072,China)
Key Words:parallel computing; massive video data; MapReduce; Hadoop
(責任編輯:張凱兵)
