基于聚類的非中心化工作流的適應性切片方法
2015-12-23 01:07:44梁繼偉尹智剛
計算機工程與設計 2015年10期
葉 鑫,李 佳,梁繼偉,尹智剛
(大連理工大學 信息與決策技術研究所,遼寧 大連116024)
0 引 言
非中心化工作流如何進行切片,以實現工作流片段在多個服務器間的調度問題已成為理論研究與實踐中的熱點問題[1]。非中心化的工作流根據其特點主要可分為計算和數據密集型[2-5]和實例密集型[6-9]兩類。區別于計算和數據密集型工作流,實例密集型工作流的最大特點是實例中活動所需的計算能力較低、數據量較小,但存在大量需要運行的工作流實例,對響應時間和執行效率提出了嚴峻的挑戰。文獻 [10]指出該類工作流廣泛存在于連鎖經營、在線零售、電子政務和醫療保險等行業中,由大量分散在不同服務器上的服務集之間復雜的交互來組成,最終將被數以萬計的工作流實例來實現。
當前,一些學者為提升非中心化工作流的響應時間和執行效率,提出了相應工作流的切片方法,主要可以分為靜態和動態的工作流切片方法兩類。
靜態工作流切片方法是在設計時而非工作流執行時進行切片的[11,12],雖然可相對提高工作流執行效率,但是由于其主觀性較強,而且沒有考慮工作流的執行環境,因此無法根據執行環境的改變做出動態調整,而動態工作流切片方法可彌補這些不足[7,13]。如文獻 [13]提出一種基于流程挖掘的工作流分布方法,該方法根據流程日志,利用apriori算法挖據工作流中最相關的活動,并將這些活動封裝在同一個代理上去執行;文獻 [14]提到了另外一種針對客戶行為的工作流中頻繁路徑的挖據方法-GSP算法,以提升挖據效率;文獻 [8]在文獻 [13]的基礎之上提出了HIPD (分層智能流程非中心化)方法,該方法將工作流的頻繁路徑挖掘和流程樹分層結合起來進行工作流片段的切分,最后將頻繁交互的活動封裝為一個工作流片段,并分配在相同的代理中執行,從而減少活動間的通信時間,并使得工作流切片更具靈活性,以適應工作流執行環境的變化。
綜上所述,動態的工作流切片方法為本文的研究提供了良好的基礎與借鑒,但還主要存在以下問題:①部分方法主要考慮了活動的執行頻次,忽視了活動間的依賴關系;②考慮因素不全面,缺少對工作流活動間的通信量的關注;③不能很好適應工作流的執行環境。這些問題的存在將會影響到工作流執行的響應時間和吞吐量。因此,本文針對這些問題的改進進行研究,旨在減少工作流的響應時間,提高工作流的執行效率。
1 基于層次聚類法的非中心化工作流的切片方法
為減少實例密集型非中心化工作流的響應時間并提升其執行效率,應在綜合考慮活動執行頻次等因素的前提下,盡可能的將通信頻繁且通信量大的活動分配在同一臺服務器上執行,亦即將這些活動劃分到一個工作流片段中。而聚類分析是數據挖掘中的一種數據劃分或分組處理的重要手段和方法。如果將通信頻繁且通信量大的活動看作為相似,則可將聚類分析中的類別看作為工作流片段。因此,可應用聚類分析對工作流進行切片,但須對其類間距離的定義進行修訂。另外,由于執行環境的不確定性等因素,因此借鑒凝聚層次聚類法的思路對工作流進行切片,以提高切片結果對執行環境的適應性。
1.1 基本定義
基于BPMN 規范,一個工作流模型可被抽象為一個有向無環圖 (DAG)。圖中的節點可分為活動和網關兩類。相關的基本定義如下。
定義1 活動 (或任務)。活動是工作流中的最基本的元素,也是工作流切片的基本單元,令ai表示工作流中的第i個活動,則A={ai|i=1,2…,n}表示工作流中所有活動的集合。
定義2 工作流片段 (或類)。工作流片段表示切片過程中所產生的活動集合,亦可看作為聚類分析中的類。令ci表示第i 個工作流片段,則ciA。特別的,當某工作流片段只包含1 個活動時,該工作流片段等價與活動。令clusterk= {ci|i=1,2…,l},k=1,2…m 表示第k次聚類時的所有工作流片段的集合。
定義3 活動間的偏序關系與工作流片段間的偏序關系。其中,如果在DAG 圖中存在一條從ai指向aj的路,且除ai和aj外,路上無其它節點或只包含網關類型的節點,則稱ai和aj之間存在偏序關系<ai,aj>。類似的,如果工作流片段ci中的活動和工作流片段cj中的活動存在偏序關系,則ci和cj之間存在偏序關系<ci,cj>。
定義4 活動間的依賴概率。基于工作流的結構和歷史日志數據,如果ai和aj之間存在偏序關系<ai,aj>,則paiaj表示ai和aj之間的依賴概率,即ai被執行后aj被執行的概率,其計算公式如式 (1)所示

式中:countai、countaj——工作流歷史日志信息中ai、aj的執行次數合計。
定義5 活動的預計執行頻次。若令fai表示活動ai的預計執行頻次,給定時間段內工作流實例的數量記為instanceNumber,則工作流中第一個活動 (即初始活動)的預計執行頻次fa1=instanceNumber,其余活動的預計執行頻次的計算公式如式 (2)所示,并可通過遍歷DAG 圖計算得到

定義6 活動間的依賴頻次。令faiaj表示活動ai和aj之間的依賴頻次,即ai被執行后aj被執行的頻次,其計算公式如式 (3)所示

定義7 活動間的距離和類間的距離。若令commaiaj表示活動ai和aj之間的通信量,daiaj表示活動ai和aj之間的距離,則daiaj可由式 (4)計算得到。即活動ai和aj之間的依賴頻次越大,通信量越大,則二者之間的距離越小
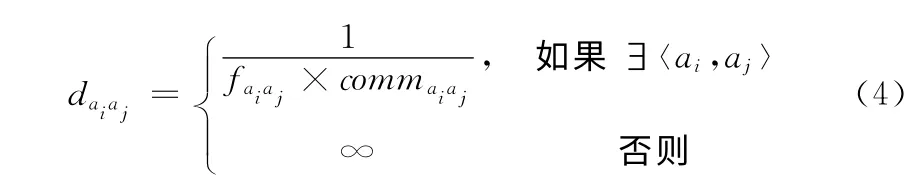
若令dcicj表示類ci到cj之間的距離,可由式 (5)計算得到。若令Dcicj表示類ci和cj之間的距離,則可由式(6)計算得到
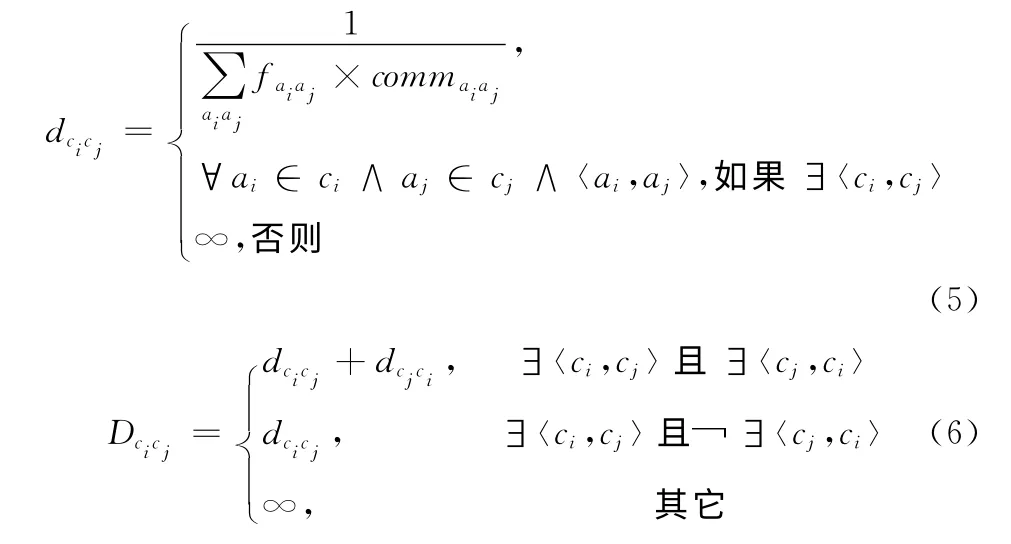
1.2 基于聚類的工作流切片算法
基于聚類的工作流切片算法如下:
輸入:DAG,instanceNumber,Paiaj,comaiaj
輸出:每次聚類的最小距離min(diatance)和相應的聚類結果clusterk

首先基于工作流的歷史日志信息,根據式 (1)計算得到活動間的依賴概率,并基于工作流執行環境如instanceNumber等信息,執行上述算法。該算法的主要步驟解釋如下:
步驟1 數據預處理。根據給定時間段內的工作流實例數量instanceNumber與式 (2)計算每個活動的預計執行頻次,根據式 (3)計算活動間的依賴頻次。
步驟2 聚類初始化。令每個活動自成一類,初始化clusterk且k=1。
步驟3 根據式 (5)和式 (6)計算clusterk中兩兩類間距離,找出類間距離的最小值,然后將類間距離最小的類聚合在同一個類中,k遞增,更新clusterk后執行步驟4。
步驟4 判斷所有活動是否在同一個類中,如是,則聚類 (即切片)過程結束;否則,執行步驟3。
1.3 算例
以圖1 所示的工作流為例,說明并驗證算法。其中,活動間的關系包括:a1與a2、a2與a3構成順序關系,a3與a4、a5、a6之間為Xor-split關系,a4、a5、a6與a7之間為Xor-join關系。假設從工作流的歷史日志信息中計算得到活動間的依賴概率,如圖1中各邊上的權數所示。
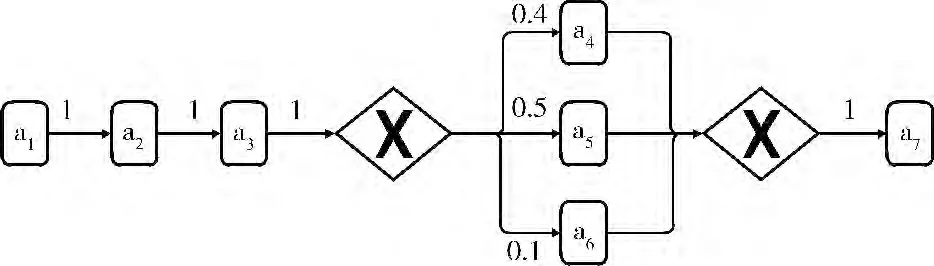
圖1 工作流
另假設已知即將要到達的工作流實例數目為10000,各活動間的通信量見表1。具體的切片過程如下:
步驟1 基于活動間的依賴概率、式(2)和式(3),可計算活動間的依賴頻次見表1,如:fa1a2=fa1×pa1a2=10000。
步驟2 初始化:令k=1,則cluster1= {ci|i=1,2,…7}。其中,c1= {a1},c2= {a2},c3= {a3},c4={a4},c5= {a5},c6= {a6},c7= {a7}。
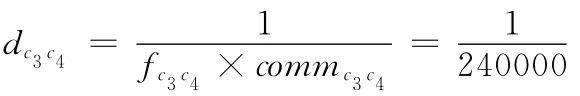
步驟4 重復步驟3直至所有活動都聚合在一個類中。

表1 活動間的依賴頻次和通信量
最終的切片結果見表2。
2 模擬實驗與分析
2.1 實驗設計
為了體現切片方法的適應性,考慮了工作流執行環境的兩個維度:①單位時間內實例的到達數目;②可執行資源 (服務器)的數目。由于篇幅有限,設計了2 組實驗,見表3。其中,每一組實驗均考慮HIPD 方法和本文所提出的方法,實驗所使用的工作流如圖1所示。
為了便于和HIPD 方法比較,效果指標包括響應時間和吞吐量。文獻 [8]中定義的響應時間是指從第一個工作流實例到達直到最后一個工作流實例獲得響應的時間;吞吐量是指單位時間內,已執行結束的工作流實例數目占所請求執行的工作流實例數目的百分比。

表2 聚類過程與結果
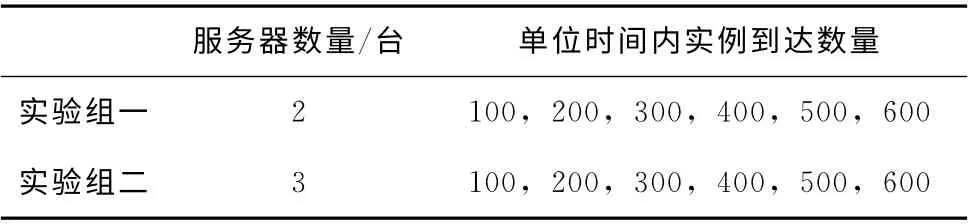
表3 分組實驗設計
另外,在所有的實驗中,為使方法對比效果更加明顯,假定每個服務器的執行能力相同,每個活動在服務器上的執行時間為0.005s,同一時間一個服務器只能執行一個活動,且單位時間內工作流實例均勻到達,服務器之間的網絡帶寬為10Mb/s,則根據相應公式可得活動間的通信時間見表4。

表4 活動間通信時間
2.2 工作流切片與服務器分配
針對圖1所示的工作流,基于本文所提出的切片方法所得到的切片結果如1.3 節中的表2 所示。為了便于與HIPD 方法比較,令min_support=4000,則基于HIPD 對圖1所示的工作流的切片結果見表5。

表5 基于HIPD 的工作流算例的切片結果
在模擬實驗進行之前,仍需基于切片結果,將工作流片段分配到相應的服務器上。針對基于HIPD 所得到的切片結果,利用文獻 [8]中所使用的Round Robin算法將工作流片段分配到相應的服務器上。針對基于本文所提出的切片方法所得到的切片結果,在進行服務器的分配時,盡可能地將在后續聚類步驟中先被聚合的工作流片段分配在同一個服務器上,并同時考慮服務器的負載均衡等因素。例如,將表2中k=2時所得聚類結果分配在2臺服務器上時,因為首先 {a3}和 {a4}被聚合在一個類中,所以將片段 {a3,a4}分配在同一臺服務器上。然后針對剩余的工作流片段 {a1}、{a2}、{a5}、{a6}、{a7},考慮k=3時{a2}、{a3}和 {a4}被聚合在一個類中,所以將 {a2}和{a3,a4}分配在同一臺服務器上。進一步的,考慮到服務器的負載均衡因素,將剩余的 {a1}、{a5}、{a6}、{a7}分配在另一臺服務器上。這種分配方式既考慮了活動間的通信時間和偏序關系,也同時考慮了服務器的負載均衡。針對兩組實驗的工作流片段的分配結果,見表6和表7。

表6 實驗組一的工作流片段分配

表7 實驗組二的工作流片段分配
2.3 實驗執行與結果分析
實驗的軟件環境為AnyLogic Professional 7.0.0。Any-Logic是一款應用廣泛的,對離散,連續和混合系統建模和仿真的工具[15],圖1 所示的工作流在AnyLogic流程模型庫中建模結果界面如圖2所示。
實驗結果如圖3、圖4所示。
基于以上兩組實驗結果,從以下幾個方面進行比較分析:
(1)本文所提出的切片方法在響應時間和吞吐量兩方面均優于HIPD 方法。
(2)當服務器數目為2時,由圖3 可以看出,本文提出的切片方法明顯優于HIPD 方法。并且當單位時間內工作流實例到達數目為600時,聚類2-6-2 (基于本文所提出的切片方法的最優方案)的響應時間為9.79s,相比于HIPD2-7-2 (基于HIPD 方法的最優方案)的響應時間13.77s,減少了31%。由此可見,在工作流切片時,考慮活動間的通信量比不考慮活動間的通信量更能減少工作流執行的響應時間。

圖2 基于AnyLogic的圖1所示的工作流算例的建模界面
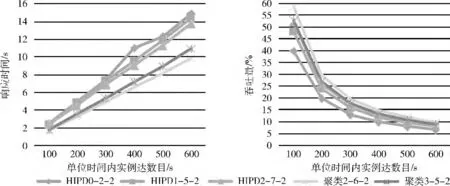
圖3 實驗組一的實驗結果
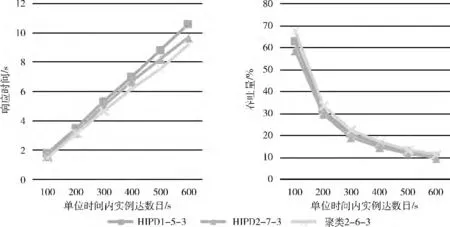
圖4 實驗組二的實驗結果
(3)當服務器數目增加時,由圖3和圖4可以看出,本文所提出的切片方法和HIPD 方法在響應時間上均減少,在吞吐量上均提高。這是因為當服務器數目增加時,提高了工作流執行的并發性,減少了等待時間。但是本文所提出的切片方法在響應時間和吞吐量方面的改善程度均優于HIPD。
(4)縱觀所有實驗,隨著單位時間內工作流實例數目的增加,本文提出的方法較之HIPD 方法在響應時間方面的優勢越來越大,由此可以說明當實例數目越多時,通信量越大,本文提出的方法較HIPD 更能較少通信時間,從而減少響應時間。
綜上,本文所提出的方法更能適應工作流執行環境。
3 結束語
本文針對當前非中心化工作流的切片方法中存在的問題,提出一種基于聚類的非中心化工作流的適應性切片方法。該方法是對經典的凝聚層次聚類法的改進,雖然思路上與經典方法相似,但是在類間距離的計算上區別于傳統聚類方法。而且,該方法不僅考慮了工作流中活動間的偏序關系與依賴頻次,還充分考慮了活動間的通信量與通信時間。通過模擬實驗,與當前最好的動態流程切片方法HIPD 相比,所提出的方法在不同的工作流執行環境下,響應時間與吞吐量均有不同程度的優勢,且更能適應工作流執行環境的動態變化。
該方法尚有不足,如切片結果與服務器的分配方面,尚未形成完整的方法體系;又如實驗時做了若干假設,不能完全體現實際工作流執行環境的各種場景等。上述局限性將有待在未來的研究工作進一步完善。
[1]WANG Wenli.Event-based distributed workflow technology in cloud environment[D].Harbin:Harbin Institute of Technology,2013 (in Chinese).[王文莉.云環境下基于事件的分布式工作流技術 [D].哈爾濱:哈爾濱工業大學,2013.]
[2]Wan Cong,Wang Cuirong,Pei Jianxun.A QoS-awared scientific workflow scheduling schema in cloud computing [C]//IEEE International Conference on Information Science and Technology,2012:634-639.
[3]Tram Truong Huu,Guilherme Koslovski,Fabienne Anhalt,et al.Joint elastic cloud and virtual network framework for application performance-cost optimization [J].Journal of Grid Computing,2011,9 (1):27-47.
[4]Eun-Kyu Byun,Yang-Suk Kee,Jin-Soo Kim,et al.BTS:Resource capacity estimate for time-targeted science workflows[J].Journal of Parallel and Distributed Computing,2011,71(6):848-862.
[5]Simon Ostermann,Radu Prodan.Impact of variable priced cloud resources on scientific workflow scheduling [G].LNCS 7484:Euro-Par 2012Parallel Processing,2012:350-362.
[6]LI Wenhao.The study on instance-intensive workflow schedule in algorithms in community cloud [D].Jinan:Shandong University,2010 (in Chinese).[李文浩.面向社區云的實例密集型工作流調度方法研究 [D].濟南:山東大學,2010.]
[7]Liu K,Jin H,Chen J,et al.A compromised-time-cost scheduling algorithm in SwinDeW-C for instance-intensive cost-constrained workflows on a cloud computing platform [J].International Journal of High Performance Computing Applications,2010,24 (4):445-456.
[8]Faramarz Safi Esfahani,Masrah Azrifah Azmi Murad,Md Nasir B Sulaimanb,et al.Adaptable decentralized service oriented architecture[J].Journal of Systems and Software,2011,84(10):1591-1617.
[9]YANG Chengwei,MENG Xiangxu.Research on issues of dynamic process optimization scheduling under cloud computing environment [D].Jinan:Shandong University,2012 (in Chinese).[楊成偉,孟祥旭.云計算環境下動態流程優化調度問題研究 [D].濟南:山東大學,2012.]
[10]Li G,Muthusamy V,Jacobsen HA.A distributed service oriented architecture for business process execution [J].ACM Transactions on the Web,2010,4 (1):1-33.
[11]Muthusamy V,Jacobsen HA,Chau T,et al.SLA-driven business process management in SOA [C]//Conference of the Center for Advanced Studies on Collaborative Research,2009:86-100.
[12]Daniel Wutke,Frank Leymann,Daniel Martin.A method for partitioning BPEL processes for decentralized execution [C]//Erster Zentraleurop ischer Workshop,2009:109-114.
[13]Faramarz Safi Esfahani,Masrah Azrifah Azmi Murad,Md Nasir Sulaiman,et al.Using process mining to business process distribution [C]//ACM Symposium on Applied Computing,2009:2140-2145.
[14]Alex Seret,Seppe KLM vanden Broucke,Bart Baesens,et al.A dynamic understanding of customer behavior processes based on clustering and sequence mining [J].Expert Systems with Applications,2014,41 (10):4648-4657.
[15]Zhang Debin.Teaching case:Implementation of discrete event simulation using anylogic[C]//Proceedings of International Symposium on Modeling and Simulation of Complex Management Systems,2013:98-101.
猜你喜歡
少先隊活動(2022年5期)2022-06-06 03:45:04
家庭科學·新健康(2022年3期)2022-05-10 00:32:13
中老年保健(2021年2期)2021-08-22 07:31:10
少先隊活動(2021年1期)2021-03-29 05:26:36
快樂語文(2020年30期)2021-01-14 01:05:38
兒童故事畫報(2019年5期)2019-05-26 14:26:14
海峽姐妹(2018年3期)2018-05-09 08:20:40
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
