基于語(yǔ)義的XML關(guān)鍵字查詢
2015-12-17 05:56:20賈穎
大眾科技 2015年8期
關(guān)鍵詞:語(yǔ)義
賈 穎
(山東工商學(xué)院計(jì)算機(jī)基礎(chǔ)教學(xué)部,山東 煙臺(tái) 264005)
基于語(yǔ)義的XML查詢
賈 穎
(山東工商學(xué)院計(jì)算機(jī)基礎(chǔ)教學(xué)部,山東 煙臺(tái) 264005)
針對(duì)XML數(shù)據(jù)的
查詢問題,考查了已有的查詢技術(shù)的優(yōu)勢(shì)和不足,提出了基于語(yǔ)義的XML
檢索算法。對(duì)用戶輸入的
進(jìn)行分類,分為條件
和結(jié)果
。條件
只用于限定查詢范圍,不出現(xiàn)在結(jié)果集中。給出了語(yǔ)義相關(guān)節(jié)點(diǎn)對(duì)的概念和判定方法,并提出了基于
分類和語(yǔ)義相關(guān)節(jié)點(diǎn)對(duì)的XML數(shù)據(jù)查詢算法。
XML
查詢;
分類;語(yǔ)義相關(guān)節(jié)點(diǎn)對(duì)
XML數(shù)據(jù)一種介于HTML網(wǎng)頁(yè)數(shù)據(jù)和傳統(tǒng)關(guān)系數(shù)據(jù)庫(kù)數(shù)據(jù)之前的一種形式,它是在Web數(shù)據(jù)激增的背景下產(chǎn)生的一種新的數(shù)據(jù)描述形式。XML能有效地存儲(chǔ)和管理Web上的數(shù)據(jù)(文檔),使其既能被高效地操作和維護(hù),又能在 Internet平臺(tái)上方便地表示和交換。它比HTML網(wǎng)頁(yè)上的數(shù)據(jù)多了語(yǔ)義信息。HTML標(biāo)簽是用來描述數(shù)據(jù)顯示格式的,數(shù)據(jù)的語(yǔ)義信息靠數(shù)據(jù)自身表達(dá);而XML數(shù)據(jù)用自定義的標(biāo)簽標(biāo)明了數(shù)據(jù)的語(yǔ)義。XML是純文本數(shù)據(jù),不受操作系統(tǒng)和軟件平臺(tái)的限制,比關(guān)系數(shù)據(jù)庫(kù)又多了靈活性,所以非常適合于電子數(shù)據(jù)交換、電子商務(wù)等Web領(lǐng)域。
隨著互聯(lián)網(wǎng)上XML數(shù)據(jù)的增多,XML數(shù)據(jù)檢索問題一直是一個(gè)研究熱點(diǎn),其中XML數(shù)據(jù)檢索又是其中的一個(gè)重要的研究方向。它與傳統(tǒng)的HTML
檢索有所不同,HTML
檢索要經(jīng)歷如下過程:爬網(wǎng),通過網(wǎng)頁(yè)中包含的超鏈接搜集網(wǎng)頁(yè);從搜集到的網(wǎng)頁(yè)中提取
,建立詞典;建立單詞到文檔映射關(guān)系的倒排索引;根據(jù)某種檢索模型來計(jì)算用戶查詢與網(wǎng)頁(yè)內(nèi)容的相關(guān)性(相似性),例如向量空間模型;對(duì)檢索結(jié)果進(jìn)行排序,返回最相關(guān)的Top-K個(gè)結(jié)果。XML
查詢是一種介于HTML
查詢和數(shù)據(jù)庫(kù)結(jié)構(gòu)化查詢之間的一種查詢形式。因?yàn)?XML是一種半結(jié)構(gòu)化、自描述的數(shù)據(jù),它定義的標(biāo)簽包含了語(yǔ)義信息,它的樹形結(jié)構(gòu)提供了結(jié)構(gòu)信息。所以對(duì)于XML數(shù)據(jù)的查詢比HTML查詢更為快速,結(jié)果也更精確。
1 研究現(xiàn)狀
XRank搜索引擎:XRank[1]是Connell大學(xué)的的研究者提出的XML搜索引擎。XRank的缺點(diǎn)是對(duì)用戶輸入關(guān)鍵字的格式?jīng)]有要求,是單純的文本格式關(guān)鍵字,也不要求返回類型,雖然可以兼容HTML檢索,但也造成查詢準(zhǔn)確度不高[4]。并且,XRank返回以結(jié)果集中節(jié)點(diǎn)為根節(jié)點(diǎn)的整個(gè)子樹,里面包換了大量對(duì)用戶無用的信息。優(yōu)點(diǎn)是Xrank利用Dewey編碼的特性,提出了改進(jìn)版的倒排索引DIL、RDIL和HDIL,存儲(chǔ)空間大大節(jié)省。Xrank借鑒了PageRank算法的思想提出了用于計(jì)算元素重要性的ElemRank算法,該算法考慮了沿包含邊的正向傳播、反向傳播以及元素間引用的影響。
XSEarch[2]搜索引擎是支持語(yǔ)義的XML搜索引擎,它要求用戶輸入的包含返回結(jié)果的標(biāo)簽。XSEarch試圖從語(yǔ)義的角度去解決查詢結(jié)果中存在無效結(jié)果的問題。它通過判斷兩個(gè)元素是否關(guān)聯(lián)來解決無效結(jié)果問題。判斷元素是否關(guān)聯(lián)的標(biāo)準(zhǔn)是,如果兩個(gè)節(jié)點(diǎn)的最小公共子樹除了這兩個(gè)節(jié)點(diǎn)之外,不包含其他同名節(jié)點(diǎn),那么認(rèn)為這兩個(gè)節(jié)點(diǎn)是關(guān)聯(lián)的。
Xseek[3]最主要的貢獻(xiàn)是將用戶輸入的分類,分為謂詞回結(jié)果為以SLCA為根節(jié)點(diǎn)的子樹。SLCA(Smallest Lowest Common Ancestor)是指包含所有
的節(jié)點(diǎn)集,而且這個(gè)節(jié)點(diǎn)集中的任一節(jié)點(diǎn)的子孫節(jié)點(diǎn)都不能再包含所有查詢
。Xseek從一定程度上限制了結(jié)果集的大小,但因?yàn)榉祷氐慕Y(jié)果集中每一個(gè)邏輯單元都包含全部的
,同樣會(huì)造成返回結(jié)果集不必要的增大。
和結(jié)果
,并提出了分類的規(guī)則:如果一個(gè)輸入
和一個(gè)名稱節(jié)點(diǎn)相匹配,并且不存在一個(gè)輸入
和這個(gè)名稱節(jié)點(diǎn)的子孫值節(jié)點(diǎn)相配,那么這個(gè)輸入
就是結(jié)果
,其余的
是謂詞
。Xseek的返
文獻(xiàn)[4]提出了借鑒Xseek中把查詢分類的思想,把查詢
分為謂詞
和結(jié)果
;定義了相似節(jié)點(diǎn)對(duì)(SNP)的概念,提出了發(fā)現(xiàn)SNP的算法和有效相似節(jié)點(diǎn)對(duì)(MSNP)的判定方法,用于尋找
的匹配節(jié)點(diǎn);提出了構(gòu)建名稱節(jié)點(diǎn)、值節(jié)點(diǎn)和主Dewey碼節(jié)點(diǎn)的索引結(jié)構(gòu),以加快節(jié)點(diǎn)和其Dewey碼之間的相互查找。
2 基于語(yǔ)義的XML查詢
將輸入分類,是提高檢索精度的最經(jīng)濟(jì)和高效的途徑。借鑒數(shù)據(jù)庫(kù)結(jié)構(gòu)化查詢的方法,把查詢
分為結(jié)果
和條件
。然后在XML數(shù)據(jù)集的索引中找到所有與結(jié)果
的匹配節(jié)點(diǎn)。通過條件
的限定,篩選出滿足條件的節(jié)點(diǎn),得到一個(gè)節(jié)點(diǎn)集。返回以節(jié)點(diǎn)集中的每一個(gè)節(jié)點(diǎn)為根節(jié)點(diǎn)的子樹作為結(jié)果樹。
2.1 數(shù)據(jù)描述
圖1是一個(gè)包含節(jié)點(diǎn)Dewey編碼的XML文檔片段,Q1,Q2是查詢示例,見圖2。
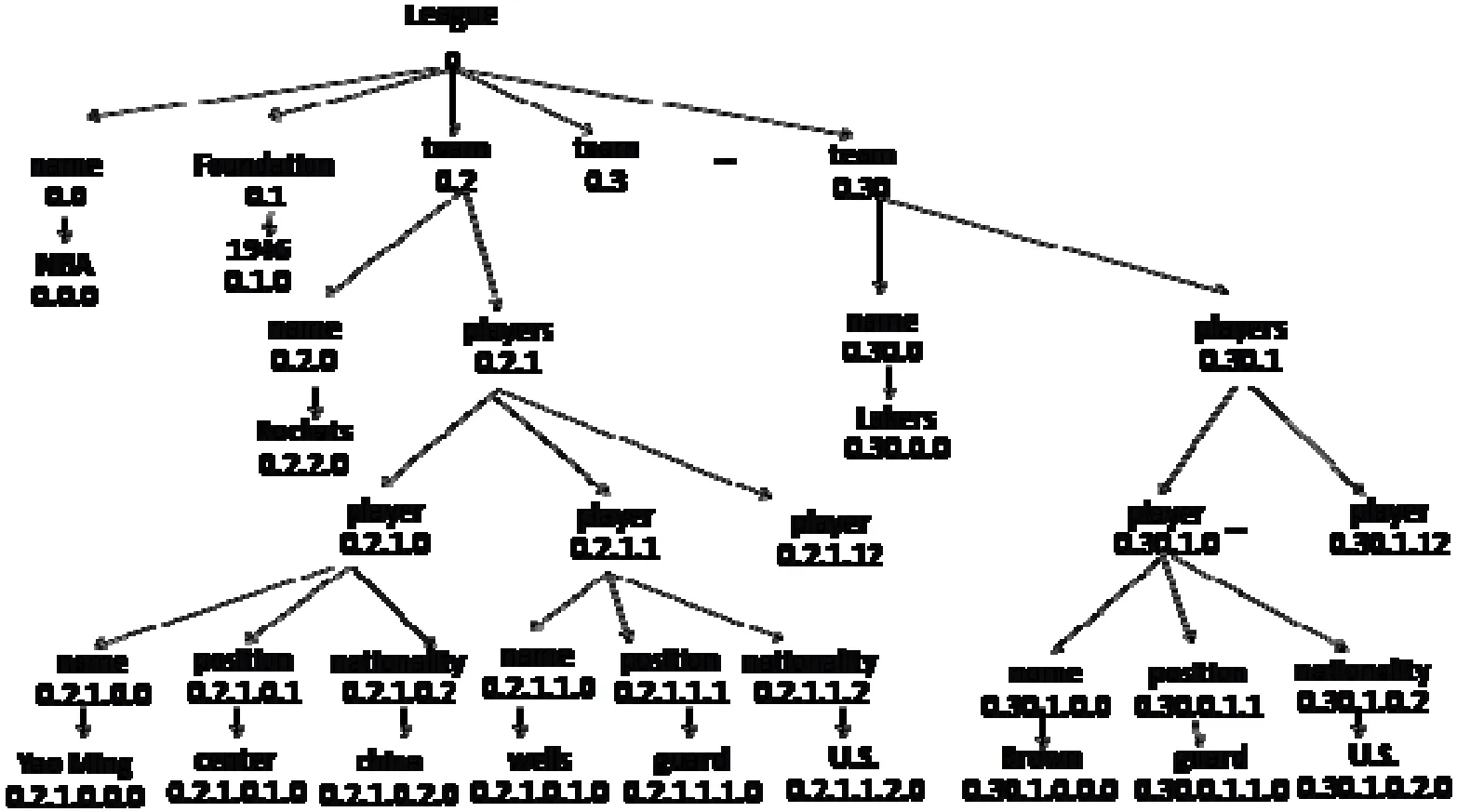
圖1 XML文檔片段圖

圖2 查詢示例
2.2 查詢表達(dá)式描述
首先,借鑒XSeek對(duì)查詢進(jìn)行分類的思想。文獻(xiàn)[4]提出讓用戶在輸入時(shí)指明
的類型,也就是按照Result_keywords_expression,predicate_kewords_expression的語(yǔ)法格式輸入,其中 Result_keywords_expression的形式為“[keywords.{[keywords]}”;predicate_kewords_expression的形式為“[keywords].or &{[keywords]}”;其中keywords的形式為“keyword ‘keyword’”,前面是標(biāo)簽名稱,后面是對(duì)應(yīng)的值。按照上面的格式,語(yǔ)句Q1、Q2應(yīng)改寫為:
Q1 [position],[name ‘Yao Ming’]
Q2 [name],[position ‘guard’] & [nationality ‘U.S.’]
應(yīng)該說這種方法是可行的,因?yàn)?XML雖然是自描述語(yǔ)言,但它的標(biāo)簽命名規(guī)則已經(jīng)有了很多行業(yè)標(biāo)準(zhǔn)[5],例如對(duì)數(shù)學(xué)符號(hào)進(jìn)行編碼的MahtML、化學(xué)領(lǐng)域的標(biāo)記語(yǔ)言CML、W3C推薦的用于描述二維圖形的標(biāo)記語(yǔ)言 SVG、金融領(lǐng)域的XBRL(可擴(kuò)展商業(yè)報(bào)告語(yǔ)言)等。對(duì)于熟悉本領(lǐng)域知識(shí)的人,給出符合規(guī)范的查詢條件是可以做到的,而這樣做的好處是大大提高了查詢精度。
2.3 創(chuàng)建高效索引
為XML數(shù)據(jù)建立高效的索引,是影響XML數(shù)據(jù)查詢速度的重要因素。我們用哈希表來為XML數(shù)據(jù)的名稱節(jié)點(diǎn)和值節(jié)點(diǎn)分別建立索引,鏈地址法處理沖突,記錄每個(gè)標(biāo)簽和值出現(xiàn)在哪些節(jié)點(diǎn)和這些節(jié)點(diǎn)的Dewey碼。筆者通過查找哈希表,可以得到與關(guān)鍵字匹配的節(jié)點(diǎn)的dewey碼集合。
另外為了能快速進(jìn)行Dewey碼到的反推,筆者建立主Dewey碼索引,將XML文檔中所有的節(jié)點(diǎn)以Dewey碼為主鍵存儲(chǔ)到B+樹中,存儲(chǔ)的形式是(Dewey,keyword)。
2.4 查找語(yǔ)義相關(guān)節(jié)點(diǎn)對(duì)(SRNP)
判斷兩個(gè)節(jié)點(diǎn)語(yǔ)義相關(guān)的方法有:MLCA[6]認(rèn)為,XML文檔中的節(jié)點(diǎn)只與某個(gè)節(jié)點(diǎn)集合中與其最近的節(jié)點(diǎn)語(yǔ)義相關(guān)。而XSEarch提出了Interconnection的概念,指出對(duì)于XML文檔中的兩個(gè)節(jié)點(diǎn),若在連接這兩個(gè)節(jié)點(diǎn)的路徑上沒有出現(xiàn)相同標(biāo)簽的節(jié)點(diǎn),則認(rèn)為它們語(yǔ)義相關(guān)的。文獻(xiàn)[4]提出了基于Dewey碼的相似節(jié)點(diǎn)對(duì)(SNP)的概念,是通過比較兩個(gè)
集合S1,S2中的任意兩個(gè)節(jié)點(diǎn)ni,nj的公共最長(zhǎng)前綴predewey來的到SNP。
定義1 兩個(gè)節(jié)點(diǎn)ni和nj,ni∈S1 ,nj∈S2,它們的最長(zhǎng)公共前綴記為predewey,其中由點(diǎn)號(hào)分隔的整數(shù)個(gè)數(shù)為ni和nj的相似度,記為S(ni,nj)。
定義2 節(jié)點(diǎn)集S1和S2中節(jié)點(diǎn)個(gè)數(shù)分別為m、n,?ni∈S1,?nj∈S2滿足條件:
S(ni,nj)≥S(ni,nk) nk∈S,k=0,1,…j-1,J+1,…,n-1,那么稱ni、nj為節(jié)點(diǎn)集S1、S2的一對(duì)SNP。
這里的SNP就是語(yǔ)義相關(guān)的節(jié)點(diǎn)對(duì)SRNP。針對(duì)圖1所示的XMl文檔,以Q2為例,演示基于語(yǔ)義相關(guān)節(jié)點(diǎn)對(duì)的查詢算法,如圖3所示:
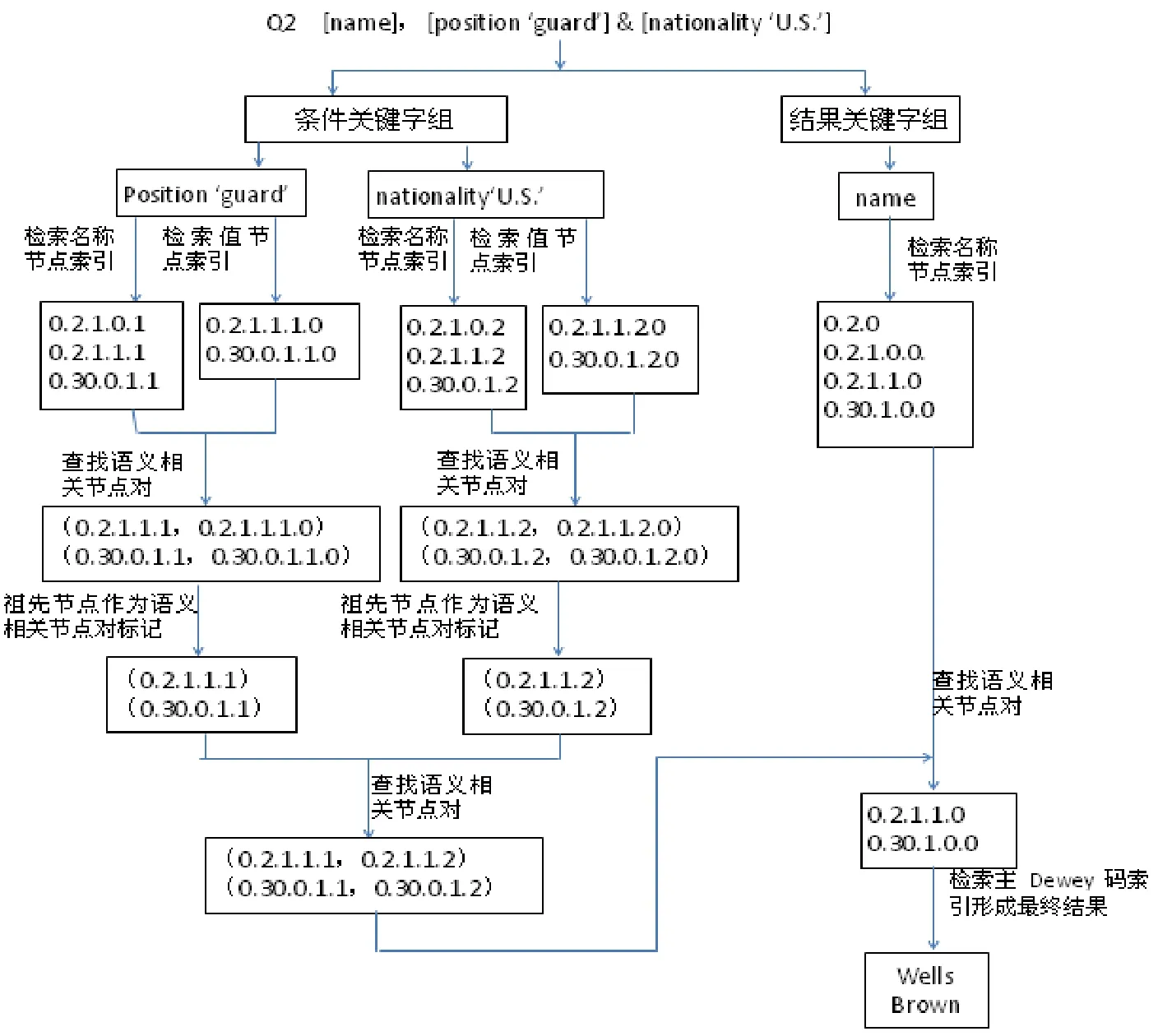
圖3 基于語(yǔ)義相關(guān)節(jié)點(diǎn)對(duì)的查詢算法
2.5 返回結(jié)果集
最后,返回以結(jié)果集(0.2.1.1.0,0.30.1.0.0)中每個(gè)節(jié)點(diǎn)為根節(jié)點(diǎn)的子樹,即
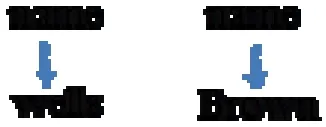
可以看到,基于分類和語(yǔ)義相關(guān)節(jié)點(diǎn)對(duì)查找的算法可以得到用戶關(guān)心的最小XML片段。
3 結(jié)束語(yǔ)
在考查了目前主要的XML查詢技術(shù)的基礎(chǔ)上,提出了基于
分類和語(yǔ)義相關(guān)節(jié)點(diǎn)對(duì)(SRNP)的查詢算法。該算法對(duì)用戶輸入
的模式進(jìn)行了限定,并將查詢
劃分為條件
和結(jié)果
。條件
只用于限定查詢范圍,而不出現(xiàn)在結(jié)果集中。定義了語(yǔ)義相關(guān)節(jié)點(diǎn)對(duì)的概念和發(fā)現(xiàn)方法。通過在
對(duì)應(yīng)的節(jié)點(diǎn)集中查找語(yǔ)義相關(guān)節(jié)點(diǎn)對(duì),最后得到結(jié)果集。返回以結(jié)果集中節(jié)點(diǎn)為根節(jié)點(diǎn)的子樹,即為查詢結(jié)果。實(shí)踐證明,該算法在查詢速度和精度方面都有較好的表現(xiàn),但在查詢語(yǔ)法的擴(kuò)展,索引結(jié)構(gòu)的優(yōu)化,查詢處理的優(yōu)化方面還需要進(jìn)一步的提高。
[1] L.Guo,F.Shao,C.Botev,J.Shanmugasundaram. XRank: Ranked keyword search over xml documents[C].Proceeding of the ACM SIGMOD International Conference on Management of Data,2003:16-27.
[2] S.Cohen,J.Mamou,Y.Kanza and Y.Sagiv. XSEarch:.semantic search engine for XML[C].Proceedings of International Conference on Very Large DataBases, 2003: 45-56.
[3] C.Botev,J.Shanmugasundaram.Context-Sensitive Keyword search and ranking for XML[C].Proceeding Of the International Workshop on the Web and Database,2005: 115-120.
[4] 孔令磊.面向 XML文檔的查詢研究[D].北京:北京交通大學(xué),2006.
[5] 周軍峰,孟小峰.XML查詢處理研究[J].計(jì)算機(jī)學(xué)報(bào),2012,35(12):2459-2479.
[6] Y.Li,C.Yu,H.VJagadish.Schema-free XQuery[C].Proceeding of the International Conference on Very Large Data Bases, 2004:72-83.
XML keyword query based on semantic relevancy
Concerning the keyword search on XML Data, analyzed the advantages and the shortage of the keyword search method and put forward.new algorithm for keyword search on XML data. We classified keywords into conditional keyword and result keyword. Conditional keyword is used to restrict the range of querying and will not appear in the results sets. Defined the Semantics relevant Node pair (SRNP) and brought forward the SRNP finding method. And then gave the XML Data keyword search algorithm based keywords classify and SRNP.
XML keyword query; keyword classify; SRNP
TP311.13..
A....
1008-1151(2015)08-0005-03
2015-07-10
山東省科技發(fā)展計(jì)劃項(xiàng)目(2014GGX101044);山東工商學(xué)院青年基金項(xiàng)目(2013QN093)。
賈穎(1979-),女,山東工商學(xué)院計(jì)算機(jī)基礎(chǔ)教學(xué)部講師,碩士,研究方向?yàn)榫W(wǎng)絡(luò)安全與數(shù)據(jù)檢索。
猜你喜歡
小學(xué)時(shí)代·科學(xué)小問號(hào)(2024年10期)2024-10-31 00:00:00
開放教育研究(2020年2期)2020-03-31 01:54:14
中國(guó)社會(huì)歷史評(píng)論(2016年2期)2016-06-27 07:11:52
現(xiàn)代語(yǔ)文(2016年21期)2016-05-25 13:13:44
長(zhǎng)江學(xué)術(shù)(2016年4期)2016-03-11 15:11:31
中學(xué)語(yǔ)文·大語(yǔ)文論壇(2015年1期)2015-05-30 22:02:35
大連民族大學(xué)學(xué)報(bào)(2015年2期)2015-02-27 08:28:11
語(yǔ)言與翻譯(2014年2期)2014-07-12 15:49:25
語(yǔ)文知識(shí)(2014年2期)2014-02-28 21:59:18
當(dāng)代修辭學(xué)(2011年6期)2011-01-29 02:49:50
