基于hadoop的大規模查詢日志分析模型設計
2015-12-12 02:04:25馬憲敏
電子測試 2015年11期
馬憲敏
(黑龍江外國語學院,黑龍江哈爾濱,150025)
基于hadoop的大規模查詢日志分析模型設計
馬憲敏
(黑龍江外國語學院,黑龍江哈爾濱,150025)
日志分析對于在用戶搜索領域有著很重要的意義,目前的日志分析系統有著不少弊端,比如:海量數據無法處理、離線處理模式、處理時延長等。對日志數據采用分級歸檔,可以實現大數據的分級優化處理。本文通過提出在一種基于Hadoop的大數據日志分析模型,并對其業務處理流程以及功能架構進行深入分析,實驗結果反映出該系統擴展性強、海量數據處理能力卓越、滿足在線處理等,具有良好的可行性和有效性。
Hadoop;海量日志處理;查詢;模型設計
0 引言
查詢日志是記錄搜索引擎用戶查詢詞和返回的網頁等相關信息的文件。通過分析用戶查詢日志,提取用戶搜索行為特征,對搜索引擎檢索結果進行處理,可以使搜索引擎返回更加準確的檢索。
用戶查詢日志分析是信息檢索領域的一個熱點,也是研究搜索引擎效率和用戶行搜索行為的重要手段。近年來,國內外的學者對搜索引擎查詢日志分析已經做了很多研究。隨著網頁信息量的增加,要進行大規模日志分析,將面臨系統擴展性,并發性,數據穩定性等諸多問題,因此本文提出了一種基于hadoop的大規模用戶查詢日志分析模型。其中hadoop是一個分布式處理框架,該模型借助Hadoop框架下的HDFS實現了查詢日志的分布式存儲,利用分布式數據倉庫Hive實現了海量數據的并行查詢與分析。
1 hadoop相關技術
1.1 hadoop框架
Hadoop是一個分布式系統基礎架構。hadoop框架的核心包括:分布式文件系統HDFS,大規模并行計算編程模型Mapreduce。
HDFS是hadoop下實現的分布式文件系統,由一個命名節點Namenode和若干個數據節點Datanode組成。采用主/從(Master/Slave)工作模式,由Namenode作為主節點(Master),負責數據的管理,由Datanode作為從節點(Slave),負責數據的分布式存放與備份。HDFS有著高容錯性的特點,非常適合超大規模數據集的應用。
Mapreduce是hadoop框架下的分布式編程模型,由map和reduce兩個階段組成,使得開發分布式并行計算程序的難度降低。輸入文件通過map階段將原始數據映射到用戶自定義的key/value鍵值對集合中,reduece階段將鍵值對集合進行處理后輸出最終結果。
1.2 Hive
Hive是一個分布式的數據倉庫工具。有以下4層結構:①用戶接口形式;②元數據的存儲方式與格式;③解釋器、編譯器、優化器、執行器;④HDFS。
用戶接口分為3個部分:CLI, Client和WUI。其中CLI是比較常用的,啟動CLI會同時有一個Hive副本產生。Hive的客戶端是Client,Hive Server作為服務器供用戶連接。客戶端模式啟動的時候,Hive Server應該指定所在節點并同時在此節點來啟動服務器。Hive是通過WUI用瀏覽器訪問的。
數據庫被Hive用來存放元數據,如mysql、derby。Hive中的元數據有如下結構:表的名字;表的列和分區及其屬性;表的屬性;表的數據所在目錄等。
在HQL查詢語句中,解釋器用于詞法分析,編譯器用于語法分析,優化器用于編譯、優化同時生成行查詢計劃并存儲在HDFS中,然后通過Mapreduce調用并執行。
Hive的數據存儲在HDFS中,大部分的查詢由Mapreduce完成。
2 查詢日志分析模型
2.1 數據集與數據格式
搜索引擎日志分為用戶點擊日志和用戶查詢日志,本文采用的是實驗室提供的搜索引擎用戶查詢日志,為期一個月,共計21426940條。與用戶點擊日志不同的是用戶查詢日志更加簡潔。
2.2 模型整體設計與工作流程
利用hadoop框架下HDFS安全可靠的存儲性能,根據大規模數據分布式存儲的需求,并結合分布式數據倉庫Hive下HQL編程簡潔易懂,日志分析模型如圖1所示,該模型包括三個模塊:并行ETL模塊,并行分析模塊,結果處理模塊。
首先,并行ETL模塊從日志服務器得到用戶查詢日志后,對日志進行預處理操作,并加載到分布式的HDFS上,由hadoop框架自動實現備份。然后,并行分析模塊根據具體的分析方法,并行加載HDFS上的文件到Hive所建立的表中,通過HQL語言進行統計分析,Hive會將HQL語言轉化為Mapreduce,Mapreduce由各個節點并行執行。最后返回分析結果并存儲。
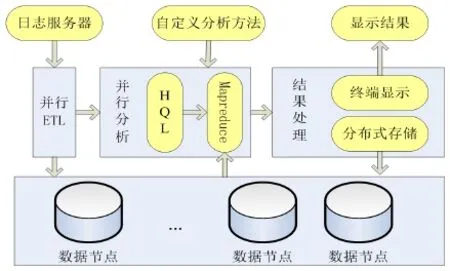
圖1 模型整體框架設計
2.2.1 并行ETL模塊
ETL(Extraction-Transformation-Loading)是數據提取、轉換和加載的簡稱,是數據倉庫技術中數據預處理必不可少的一步。將日志進行了如圖2所示的ETL處理。

圖2 并行ETL模塊
(1)數據提取
實驗室提供了一個月的用戶查詢日志,以一天為單位,共計一個月的日志信息量。
(2)數據轉換
首先,用戶查詢日志的編碼格式是GBK,我們需要將GBK轉化為Hive中采用UTF-8格式,防止查詢詞出現亂碼的情況。其次,各個字段之間的分隔符不一樣。采用自定義Hive的輸入格式inputformat來控制輸入。
(3)數據加載
用HQL語言在Hive中為每天的查詢日志建立表:CREATE EXTERNAL TABLE Sogou_query_log (字段1,字段2……) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' LINES TERMINATED BY ' ', 表的字段和日志的字段相同。Hive并行地加載本地日志文件到表中,表被保存到hadoop下的HDFS上,并實現自動備份。
2.2.2 并行分析模塊
經過ETL操作,得到了可用于直接查詢的日志信息。日志分析模塊提供了統計查詢詞長,查詞頻分析,URL排名與點擊量關系的分析,高級搜索比例等分析功能,并允許用戶添加自定義的分析方法。分析模塊使用編程難度低的HQL語言實現。根據分析請求,Hive將HQL語句解釋成為相應的Mapreduce程序,讀取分布式文件系統HDFS保存的日志表文件,各個數據節點并行執行,計算出相應分析結果。
2.2.3 結果處理模塊
該模塊包括了存儲和顯示兩個操作,將分析模塊輸出結果自動保存到HDFS中,數據節點相互備份,安全穩定地存儲日志文件和分析結果文件,并提供到終端予以顯示。
3 結果分析和模型優化
3.1 實驗結果分析
使用4臺PC機搭建hadoop分布式計算模型, 分別為pc1~ pc4, 其中pc1作NameNode,并在pc1上配置Hive,pc2~ pc4作DataNode和TaskTracker。每臺PC機具體配置如下:硬件環境: Intel( R) Core(TM)2 Duo CPU 2.20GHz; 2GB內存; 100G硬盤; 100Mbps網口。軟件環境: Ubuntu 10; JDK1.6.0_27; hadoop 0.20.3; Hive 0.10.0。
3.1.1 查詢詞長分析
查詢詞長是對查詢詞包含中文字個數的度量。查詢詞的長度能在一定程度上影響返回的查詢結果,并反映用戶查詢習慣。經實驗數據分析,在用戶查詢日志中的平均查詢詞長為9.5個字節,約為4個漢字。查詢詞長為2個字節到32個字節的用戶占了所有查詢的96.5%。文獻在Excite和AltaVista搜索引擎上所測得英文查詢詞平均長度為2.25個英文單詞。說明中文和英文查詢用戶的查詢詞都比較短,搜索引擎要準確地檢索結果存在一定困難。所以這要求中文搜索引擎需要對查詢用戶的需求有更好的理解和分析,才能更好地提供查詢結果。
3.1.2 查詢詞頻分析
查詢詞頻分析也稱為熱榜排名分析,查詢詞頻是指同一查詢詞重復查詢次數。經統計,排名前100的查詢詞查詢次數占總查詢次數的69.13%。
結果分析表明搜索引擎查詢詞出現頻率和頻率的排名存反比關系。所以搜素引擎每天處理的工作有大部分是相同的,少部分的查詢能夠滿足大部分查詢用戶的需求。為此,引入緩存機制和建立多級索引機制能夠很好的適應用戶的重復查詢特性。
3.1.3 用戶首次點擊與URL排名關系
用戶提交一次查詢,搜索引擎根據提交的查詢詞,檢索算法和排序算法返回相關聯的網頁,用戶根據個人喜好和檢索特點,選取合適的網頁點擊。為了研究用戶對返回網頁的點擊行為,我們對URL排名和用戶的點擊量的關系進行了分析。根據實驗結果,我們將實驗結果分為兩組:排名前20的網頁和排名100到1100的網頁,兩組結果分別如圖3和圖4所示。
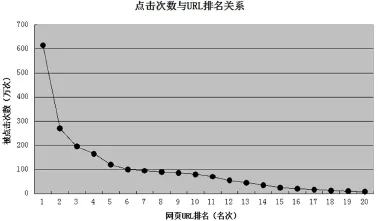
圖3 點擊量與URL排名(排名前20)
在第一組實驗結果中,點擊量前10的網頁點擊次數總共約為1763萬條,占總查詢數的82.29%,這說明約80%的用戶只關注查詢結果排名前10的網頁,即返回結果首頁的網頁。分析結果要求搜索引擎采用的排序算法能將與查詢詞相關度高的網頁盡可能地顯示在前面。
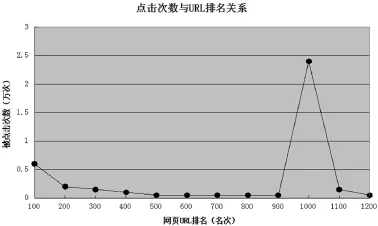
圖4 點擊量與URL排名(排名100-1100)
在第二組分析結果中,可以看出排名1000的網頁點擊量約達到22000次,如圖4所示。排名靠后卻點擊量巨大,這似乎不合常理,但是進一步分析,我們發現該類網頁屬于搜索引擎推廣網頁。該類網頁的查詢詞均屬于醫療,就業,培訓等。在進行頁面顯示時,檢索算法將這些排名較低的網頁人為的顯示到靠前頁,從而獲取商業價值。這說明在考慮搜索結果精確度的同時,商業搜索引擎會在一定程度上有目的地將一些排名低的網頁顯示在首頁。平衡好推廣網頁和用戶查詢網頁關系,才能更好地滿足用戶查詢需求。
3.1.4 高級搜索比例
搜索引擎的高級搜索是通過限定查詢范圍,將關鍵詞用邏輯連接詞連接起來進行查詢的一種方法。本文中,我們對搜索引擎用戶高級搜索行為進行了分析,在約為2200萬條查詢中,使用site:、link:等關鍵詞和+、-等邏輯連接詞進行查詢的記錄數為約18萬條,占總查詢條數的0.84%。結果表明在使用搜索引擎時,國內查詢用戶更加喜歡簡單的查詢方式。所以,在高級搜索設計上,中文搜索引擎應該從國內用戶的查詢習慣和簡便性出發,在提供準確查詢的前提下,降低高級搜索的復雜度。
3.2 效率分析以及模型優化
結合hadoop分布式框架的特點和實驗過程中發現的問題,可以從四個方面進行了模型優化:
(1)數據傾斜:使用Hive提供的通用負載均衡算法,優化模型整體性能。
(2)數據拷貝:Hive提供了combiner機制,可以使數據在map端部分聚合,相當于Mapreduce編程模型下的combiner層。
(3)Jion操作:單個日志文件小于1G,用map join語句代替join。map join操作在map階段完成,不再需要reduce,節約了系統的開銷。
(4)連接順序:位于Join操作符左邊的表會被加載進內存,將條目少的表放在左邊,可以有效減少發生內存溢出錯誤的幾率。
通過以上方法優化后,在不同數據集大小的條件下,分別測試偽分布式環境,以及分布式優環境化前后的運行時間,結果如圖5所示。由實驗結果可以看出在數據集較小的時候,分布式日志分析模型沒有體現出優勢。因為在分布式環境下,各數據節點之間的相互拷貝,I/O通信,消耗了大量時間,所以該模型不適合小文件處理。隨著數據集的增大,分布式日志分析模型表現出了良好的性能,在經過上述優化操作后,系統運行時間減少,在數據集較大的情況下,系統優化效率最高能夠達到6%。
4 結束語
用戶查詢日志分析是研究用戶查詢行為的前提和技術,本文設計和實現了基于hadoop的大規模用戶查詢日志分析模型,將分布式技術運用于大規模數據處理,解決了大規模數據分析的擴展性和并發性瓶頸。對檢索算法、排序算法、緩存機制等方面的研究給出了建議,對于搜索引擎的優化有一定的指導意義。
[1] White T.Hadoop:The Definitive Guide[M].O'Reilly Media,Inc,2012:755-795.
[2] Ghemawat S,Gobioff H.The Google File System[C]. ACM Symposium on Operating Systems Principles, 2003.
[3] Thusoo,Sarma.Hive - a petabyte scale data warehouse usinghadoop[C].Long Beach,CA:International Conference on Data Engineering,2010:996-1005
馬憲敏,女,1979.12-,山東省日照市,碩士,副教授,研究方向:軟件工程。
Design of massive query log analysis model based hadoop
Ma Xianmin
(Heilongjiang international university,HeilongjiangHarbin,150025)
Log analysis has a very important significance for the field in the user search,the current log analysis system has a lot of disadvantages,such as:massive data cannot be processed,off-line processing mode,processing delay and other. the classification of log data archiving, in order to achieve big data classification optimization of growing demand.It puts on a large Hadoop log data based on the analysis model,and the business processing process and functional structure of the in-depth analysis,experimental results show the system expansion and strong, massive data processing ability of excellence,online processing,with good feasibility and effectiveness.
Hadoop;log processing;query;model design
猜你喜歡
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
電子制作(2018年18期)2018-11-14 01:48:24
商用汽車(2016年11期)2016-12-19 01:20:16
山東工業技術(2016年15期)2016-12-01 05:31:22
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
中國衛生(2015年12期)2015-11-10 05:13:38
創業家(2015年5期)2015-02-27 07:53:25
新疆大學學報(自然科學版)(中英文)(2014年2期)2014-11-06 07:49:12
技術經濟與管理研究(2014年11期)2014-03-11 17:02:44
