基于LDA 模型的稀疏消息傳遞算法
2015-11-25 09:36:14屠雄剛嚴建峰
電工技術學報 2015年1期
屠雄剛 陳 軍 楊 璐 嚴建峰
(1.浙江工業職業技術學院設計與藝術學院 紹興 312000 2.蘇州大學計算機科學與技術學院 蘇州 215006 3.蘇州大學江蘇省計算機信息處理技術重點實驗室 蘇州 215006)
1 引言
潛在狄利克雷分配(Latent Dirichlet Allocation,LDA)[1]是識別大規模文本集或語料庫中潛在主題信息的概率主題模型,它能夠將單詞空間中的文檔變換到主題空間,得到文檔在低維空間中的表達。LDA 假定每篇文檔是主題的一個概率組合,而主題是單詞表中單詞的多項分布。文檔-主題分布可以看作是文檔在主題空間的表示,能夠被用來分類以及檢索,而主題在單詞的分布能被用來表示主題的意義。然而這樣的LDA 模型不能直接控制推理參數的后驗稀疏度。
在文本模型中語義空間的稀疏表示具有實際的應用價值,通常每篇文檔或每個單詞只有幾個突出的主題意義,而不是在每個主題上都有非0 的值。單詞的主題分布越稀疏就能越清晰的反映出單詞的主題意義,在模型參數估計和推理的過程中增加稀疏限定可以提高模型的精度。稀疏主題編碼(Sparse Topical Coding,STC)[2]是發現大規模文本集隱藏表示的非概率主題模型,與概率主題模型不同,STC松弛了混合比例和最大似然函數的標準化限定,使用稀疏規則化的方法直接控制推斷表示的稀疏性,無縫地結合凸誤差函數到監督學習中,有效地學習半監督結構化的條件下降算法。稀疏編碼的潛在狄利克雷分配(SCLDA)[3]是一個加入稀疏限定的基于連續特征的主題模型,假定連續單詞的概率分布是拉普拉斯分布,該分布的參數依賴于主題,使用期望最大化(Expectation Maximization,EM)算法估計模型參數,該模型在計算機視覺問題中取得了不錯的效果。稀疏隱藏語義分析(Sparse Latent Semantic Analysis,SLSA)[4]在L1范數約束的條件下產生了一個稀疏投影矩陣。與傳統的LSA 相比,SLSA 緊緊選擇每個主題的少數幾個單詞,提高了主題-單詞分布的可解釋性,在內存和效率上也有相應改進。變分貝葉斯(Variational Bayes,VB)[1]、塌陷吉布斯采樣法(Collapsed Gibbs Sampling,GS)[5]以及消息傳遞算法(Belief Propagation,BP)[6]是LDA 的三種近似推理算法。BP 算法把計算全局積分的過程分散到各個節點的信息傳遞,而各個節點和鄰近節點交互信息,它在效率和準確率上都明顯優于VB 和GS 算法。本文的研究是在消息傳遞算法的基礎上進行的。
LDA 模型的先驗參數可以在一定程度上控制文檔-主題分布和主題-單詞分布的稀疏度,然而因概率主題模型的標準化操作而很難獲得稀疏的主題表示。稀疏非負矩陣分解[7]提供了一個在原來算法基礎上獲得向量稀疏表示的基本框架。本文在前人研究的基礎上,提出了稀疏限定的消息傳遞算法(sparseBP),用基于L1范數和L2范數的方法度量向量的稀疏度,在算法的迭代過程中投影單詞在主題上的概率分布到稀疏空間,從而得到特定稀疏度的單詞在主題上的分布。本文也探索了sparseBP 的聚類性能,并把sparseBP 看作是一種降維算法,把文檔在主題上的分布作為libsvm 分類器的輸入探索文本分類準確率。
2 消息傳遞算法
消息傳遞(Belief propagation,BP)最初被機器學習專家用于樹狀結構的統計推斷,后來這種算法忽略掉它本來對樹狀結構的要求而應用與帶環的模型。文獻[1]在馬爾科夫隨機場的框架下證明了在主題模型意義下LDA 是一種特殊的因子圖,并提出用消息傳遞算法近似求解LDA 模型。本文中用到的符號見表1。

表1 符號標簽Tab.1 Symbol labels
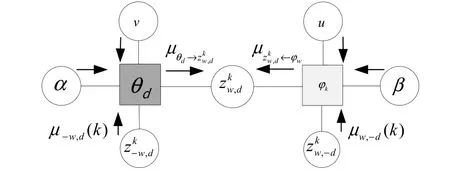
圖1 基于因子圖的消息傳遞Fig.1 Message passing based on factor graph
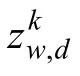
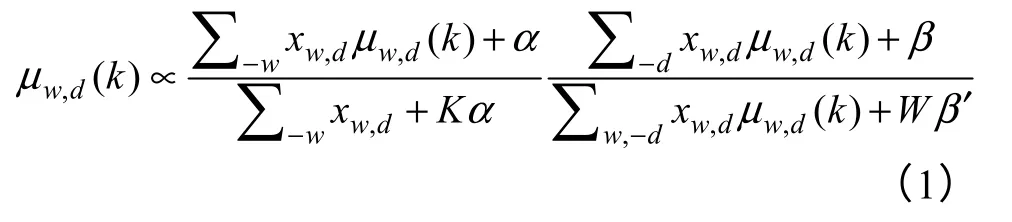
這里 -w 表示除了單詞w 以外的所有單詞,-d表示除了文檔d 以外的所有文檔。信息更新式(1)取決于除了當前信息μw,d以外的所有其他鄰接信息μ-(w,d)。文檔-主題分布θ 和主題-單詞分布φ 的計算公式為
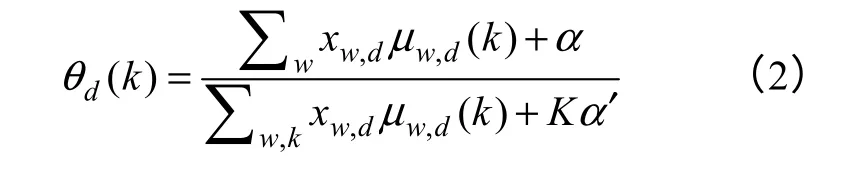
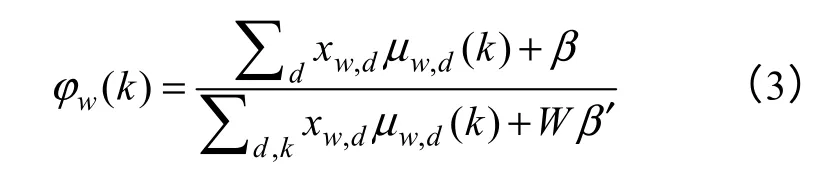
信息更新過程將通過迭代公式(1),直到信息收斂于一個固定的點。算法的執行過程如圖2 所示,算法的迭代過程分為兩個步驟,第一步更新每個單詞的主題分布μw,d,第二步用更新的消息μw,d估計參數dθ 和wφ 。
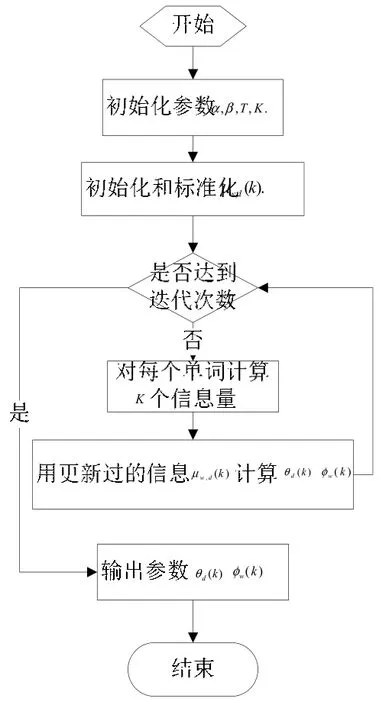
圖2 消息傳遞算法Fig.2 Message passing algorithm
3 稀疏消息傳遞算法
本節首先描述稀疏度的概念,然后介紹如何把稀疏度結合進LDA 模型的消息傳遞中,最后介紹算法具體執行過程。
3.1 稀疏度
向量稀疏度的度量可以用向量中0 元素的數目與向量維度的比值來計算。對于大部分元素取值接近與0 而只有幾個有意義的非0 值的向量會有一個較低的稀疏度,然而在實際應用中,這樣的向量被認為有一個較高的稀疏度。本文使用基于L1_norm和L2_norm的稀疏度度量方式[7]
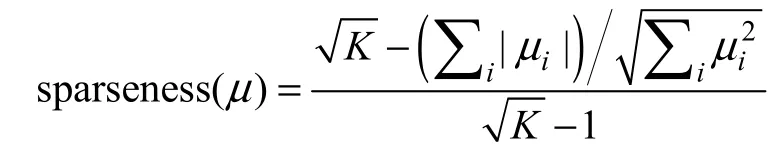
其中K 表示μ 的維度,當向量μ 只有一個非0的元素時稀疏度為1,當向量μ 的所有元素都相等時稀疏度為0。
3.2 稀疏限定的消息傳遞
消息傳遞算法可以看作是對語料庫中的單詞分配標簽的過程,通常每個單詞的主題集合只有小部分是活躍的。在消息傳遞算法的迭代過程中對于單詞-文檔矩陣中的非0 元素都需要通過公式1 來得到單詞的主題分布,這個分布往往是很稀疏的。稀疏度隨著迭代次數的增加而不斷增加。像“learning,paper,algorithm”這樣的常用詞往往有一個較低的稀疏度,而像“network neural genetic”這樣的關鍵詞有較高的稀疏度。主題模型中主題數目K 通常是啟發性的設置或者是通過非參數的貝葉斯模型學習得到,當K 初始設置的數目比較大時,常用詞和關鍵詞的主題分布的稀疏度可能有更大的差距。本文中我們固定主題在單詞分布上的稀疏度,每次迭代得到μw,d后把它投影到與它距離最近的稀疏空間中去,而向量的稀疏度可以自由設定,通常越稀疏的向量越能清晰的反應單詞的主題分布。然后整合出LDA 模型的兩個輸出文檔-主題分布和主題-單詞分布。這種增加稀疏度限定的消息傳遞算法稱為稀疏消息傳遞算法(sparseBP),算法的具體執行過程如圖3 所示。
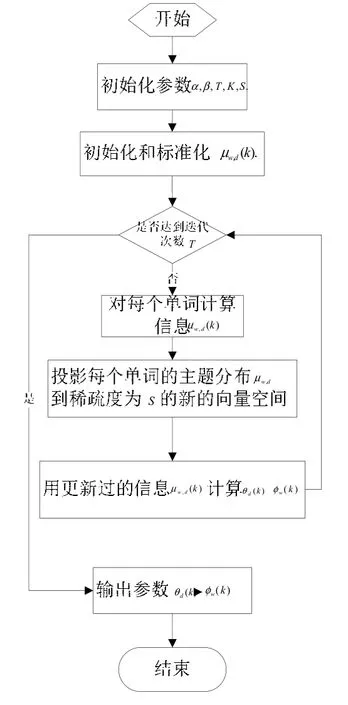
圖3 稀疏消息傳遞算法Fig.3 Sparse message transfer algorithm
投影向量到稀疏度為S 的空間的具體操作如算法3 所示,該算法首先投影給定的向量到L1的空間中,然后投影到與之最接近的由L1和L2聯合限定的空間中。如果投影結果完全是非負的,就退出循環,而如果有負值,把負值設置為0,然后在額外限定的條件下去尋找一個新的點。原則上,算法的迭代次數和向量的維度是相等的,因為算法的一次迭代過程或者是收斂,或者是增加一個值為0 的元素。而事實上,算法可以收斂的更快。
3.3 復雜度分析
消息傳遞算法需要存儲單詞的主題概率分布,在存儲和計算方面都要乘以主題數目K 的倍數,消息傳遞算法的時間復雜度 O (KDWdT),sparseBP 在BP 算法的基礎上增加了投影操作,sparseBP 的時間復雜度為 O (K2DWdT)。sparseBP 在投影的過程中增加了幾個維度為K 的向量,然而它的空間復雜度與消息傳遞算法相同,均為 O (K * NNZ),其中D 是輸入文檔-單詞共現矩陣的列數,Wd是共現矩陣每一列中非零單元 xw,d≠ 0的個數,T 是算法的迭代次數,NNZ 為單詞-文檔共現矩陣中非0 元素的總數目。
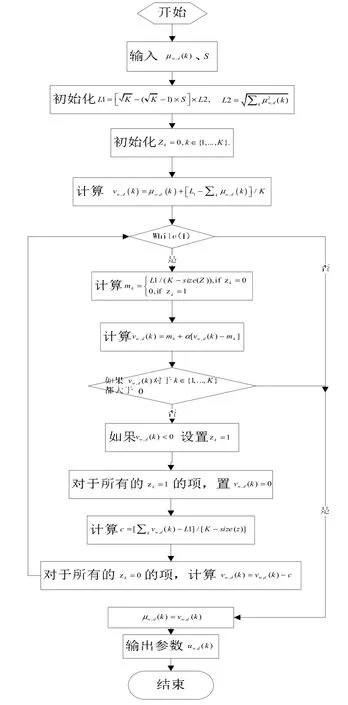
圖4 投影向量到稀疏度為s 的空間的算法Fig.4 projection vector to the sparse degree s of space algorithm
4 實驗分析
本文的實驗在Matlab C/C++MEX 平臺上進行,這個平臺在文獻[8]中已經被使用。先驗參數初始化設置為 α=2/K, β=0.01,這里K 是主題的數目,對于所有的算法分別做300 次迭代并運行5 次計算其均值。每篇文檔中單詞的概率分布μw,d的稀疏度S 在0.7~0.9 之間變化時,效果基本一致,這里固定S 為0.8。本文采用標準化互信息來評估文檔聚類的準確率,并使用常用的聚類方法BP,GS,非負矩陣分解(Non-negative Matrix Factorization,NMF)[9],譜聚類(Spectral Clustering,SC)[10]來進行對比。此外,使用消息傳遞算法對文檔-單詞共現矩陣進行降維,并借助于libsvm 測量文本的分類準確率,使用BP,GS 和NMF 來和sparseBP 進行對比。在評價sparseBP 在文檔聚類和分類中相比其它算法提高的百分比時本文采用的計算公式為:

4.1 數據集選擇
本文在英文語料上進行測試,采用CORA[11]和TEUTERS[12]兩個通用的文本數據集進行實驗。實驗所用文本數據如表1 所示,這里D 是文檔的總數目,W 是單詞表的大小,N 是文檔中單詞的總數目,Ave( d) 是文檔的平均長度,classes 是文檔集中文檔的類別數目。文檔去除了停用詞以及單詞的后綴,采用1-Gram 的表示法,使用單詞在文檔中出現的次數作為文檔的特征。

表2 數據集Tab.2 Data sets
4.2 文檔聚類分析
稀疏消息傳遞算法可以用來做文本聚類,算法得到文檔在主題的分布 θd(k)是文檔在主題上的概率分布,在模型的訓練過程中不使用數據真實的類別標簽,得到 θd(k)后選出每篇文檔最可能的主題,并使用標準化互信息評估算法的聚類準確率。
4.2.1 聚類評價標準
標準化互信息(Normalized Mutual Information,NMI)[13]是一種被廣泛應用的外部聚類評價標準,通過比較數據集的聚類結果和該數據集的真實劃分的相似程度來實現,而在聚類過程中不使用文檔的類別標簽。NMI 可以在預測類別和真實類別不同時利用互信息進行評測,NMI 的計算公式為:
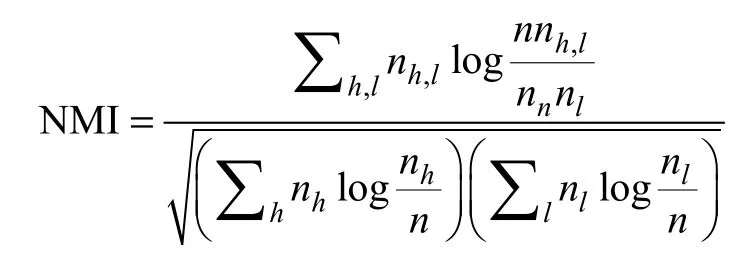
式中,hn 是類別為h 的文檔的總數目,ln 是類別為l的文檔的總數目,nh,l是同時為類別h 和l 的文檔的總數目,n 是數據集中文檔的總數目,h 是真實的類別標簽,l 是用聚類算法得到的預測類別標簽。NMI 是介于0~1之間的值,當聚類標簽和外部真實標簽完全一致時NMI 值為1,而當隨機劃分時NMI值為0,NMI 值越大表示有越好的聚類準確率。
4.2.2 聚類實驗結果
圖5 和圖6 分別表示了當主題數目K={50,75,100,125,150}時5 種算法在CORA 和TEUTERS 數據集上的NMI。從圖中可以看出,在兩個數據集上sparseBP 的NMI 都是最好的,勝過了其它的文本聚類方法,例如,在CORA 數據集上,當主題數目為100 時,sparseBP 勝過其它四種方法分別為3.67%,9.68%,32.21%和60.18%。結果表明稀疏消息傳遞算法提高了文檔聚類的準確率。
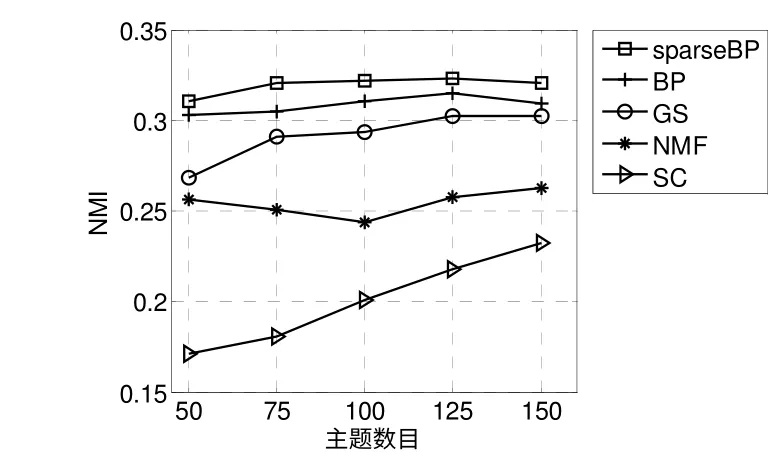
圖5 CORA 數據集上的NMI 比較Fig.5 NMI comparison on CORA data sets
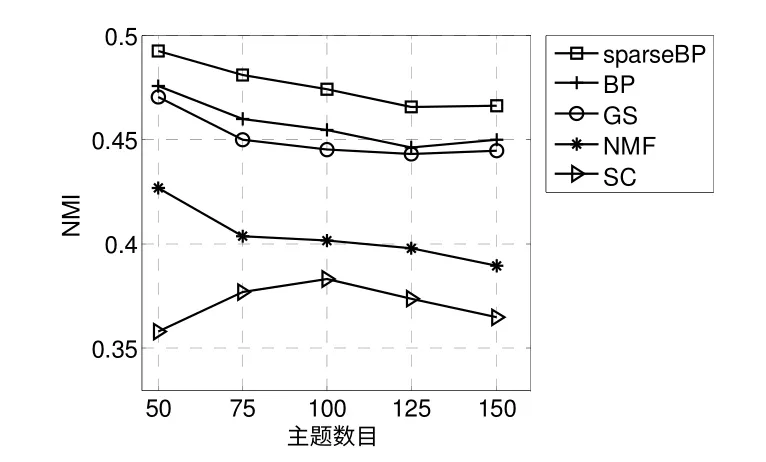
圖6 TEUTERS 數據集上的NMI 比較Fig.6 NMI comparison on TEUTERS data sets
4.3 文檔分類分析
首先使用sparseBP 把語料庫中的文檔-單詞矩陣投影到隱藏主題空間當中得到文擋-主題分布,然后以4:1 的比例隨機劃分低維的文檔特征數據為訓練集和測試集,最后根據已知文檔的類別標簽使用libsvm 分類器去分類文檔。在使用libsvm 分類時,采用網格搜索法學習參數C 和G。
4.3.1 分類評價標準
準確率(Accuracy)是評價文本分類結果優劣的一種常用評價標準,其計算公式為:

Accuracy 是介于0%~100%之間的值,越高的類別準確率暗示基于主題的低維特征具有越好的區分能力,即在降維的過程中提取到了高質量的文檔特征。
4.3.2 分類實驗結果
圖7 和圖8 分別顯示了當主題數目K={50,75,100,125,150}時5 種算法在CORA 和TEUTERS 數據集上的Accuracy。從圖中可以看出sparseBP 總是有最好的分類準確率,例如,在CORA 數據集上,當主題數目為100 時,sparseBP 勝過BP,GS 和NMF分別為3.81%,8.21%和14.03%。在RETURE 數據集上,當主題數目為100 時,sparseBP 勝過BP,GS 和NMF 分別為1.83%,1.73%和0.18%。譜聚類不能獲得文檔-主題這樣的分布,于是這里沒有相關對比結果。
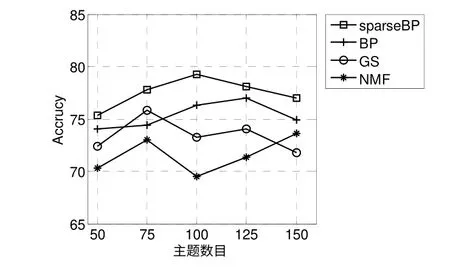
圖7 CORA 數據集上的Accuracy 比較Fig.7 Accuracy comparison on CORA data sets
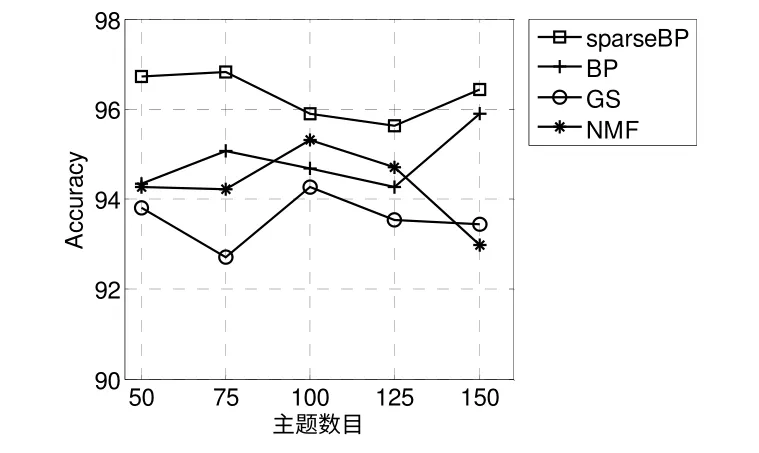
圖8 TEUTERS 數據集上的Accuracy 比較Fig.8 Accuracy comparison on TEUTERS data sets
5 結束語
本文提出了把稀疏限定加入到消息傳遞算法中,在迭代的過程中將向量投影到稀疏空間中去,同時也探索該方法對文本聚類以及分類準確率的影響。豐富的實驗結果表明本文提出的加入基于 L1范數和L2 范數的稀疏消息傳遞算法提高了文本的聚類以及分類準確率。進一步的研究工作將主要圍算法在其它方面的應用以及時間效率的因素開展,以便使算法適應于更多的應用并提高算法的執行效率。
[1]David M.Blei,Andrew Ng and Michael Jordan,Latent Dirichlet Allocation[C].Neural Information Processing Systems,2001:601-608.
[2]Jun Zhu and Eric P.Xing.Sparse Topical Coding[C].Uncertainty in Artificial Intelligence,2011:267-286.
[3]Wenjun Zhu,Liqing Zhang and Qianwei Bian.A hierarchical latent topic model based on sparse coding[J].Neuro Computing,2012,76(1):28-35.
[4]Xi Chen,Yanjun Qi,Bing Bai,Qihang Lin and Jaime G.Carbonell.Sparse latent semantic analysis[C].SIAM International Conference on Data Mining,2011:474-485.
[5]Gregor Heinrich.Parameter Estimation for Text Analysis[R]. Fraunhofer IGD,2004.
[6]Jia Zeng,William K.Cheung,Jiming Liu,Learning topic models by belief Propagation[J],IEEE Transactions on Pattern Analysis and Machine Intelligence,2013,33(5):1121-1134.
[7]Patrik O.Hoyer.Non-negative Matrix Factorization with Sparseness Constraints[J].Journal of Machine Learning Research,2004,5(1):1457-1469.
[8]Jia Zeng.A topic modeling toolbox using belief propagation[J],Journal of Machine Learning Research,2012,13(1) 2233-2236.
[9]Daniel D.Lee and H.Sebastian Seung.Algorithms for non-negative matrix factorization[C],Neural Information Processing Systems,2002:556-562.
[10]Ulrike Luxburg.A Tutorial on Spectral Clustering[J].Journal Statistics and Computing,2007,17(4):395-416.
[11]Andrew McCallum,Kamal Nigam,Jason Rennie and Kristie Seymore.Automating the construction of internet portals with machine learning[J].Information Retrieval,2000,3(2):127-163.
[12]Deng Cai,Xiaofei He,Jiawei Han.Document clustering using locality preserving indexing[J].IEEE Transactions on Knowledge and Data Engineering,2005,17(12):1624-1637
[13]Shi Zhong and Joydeep Ghosh.Generative modelbased document clustering:a comparative study[J].Knowledge and Information Systems,2005,8(3):374-384.
猜你喜歡
閱讀(快樂英語中年級)(2024年9期)2024-10-23 00:00:00
時代英語·高三(2024年3期)2024-09-03 00:00:00
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
閱讀(快樂英語高年級)(2020年8期)2020-01-08 02:21:16
智慧少年·故事叮當(2018年11期)2018-05-14 11:48:18
意林(繪英語)(2017年5期)2017-05-15 02:17:23
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
