基于Neo4j處理大數據中元數據溯源的研究
2015-09-28 06:11:02靳永超吳懷谷
現代計算機 2015年8期
靳永超,吳懷谷
(1.西華大學數學與計算機學院,成都 610039;2.成都大學信息科學與技術學院,成都 610106)
基于Neo4j處理大數據中元數據溯源的研究
靳永超1,2,吳懷谷2
(1.西華大學數學與計算機學院,成都610039;2.成都大學信息科學與技術學院,成都610106)
0 引言
隨著信息技術的高速發展和大量數據以各種形式的出現,企業的需求也在不斷地改變。如何構建一個隨著需求改變而平滑變化的大數據平臺,是大數據領域面臨的一個重大考驗。一個平臺擴展N個應用,將是未來大數據平臺擴展性的重要體現,傳統的各種信息系統往往是通過文檔來適應需求的變化,但是僅僅依靠文檔還是遠遠不夠的。所以在大數據平臺中元數據管理將是其核心的一部分,成功的元數據管理系統必須把整個平臺業務的工作流、數據流和信息流有效地管理起來,使得系統不依賴特定的開發人員[1],從而提高系統的擴展性和全局性。在大數據平臺中,像數據模型、任務模型、需求模型等模型池的定時調度,以及ETL中大量的數據源定義、映射規則、轉換規則、裝載策略等這些元數據都需要一個完整的管理。一個項目,從數據源到最終目標表,多則達上百個ETL過程,少則也十幾個。這些過程之間的依賴關系、出錯控制以及恢復的流程處理,都需要一個追根溯源的功能,通過最終形態的數據結構,追溯到整個大數據處理中,元數據的更改歷史記錄。所以大數據的元數據管理系統如何設計已經關系到大數據平臺能否高效推送數據變更,任務變更和大數據平臺突破瓶頸能否進一步發展的問題。
1 大數據平臺中的元數據
大數據處理中,尤其是大數據平臺構建中,結構化數據、半結構化數據和非結構化在整個平臺中遷移、轉換和裝載。例如像關系型數據向數據倉庫Hive、HBase、HDFS之間轉換,列族HBase數據庫向Hive,分布式文件存儲HDFS向Hive相互之間數據遷移,而傳統的ETL只針對關系型數據庫之間轉換,根本滿足不了現有的各種需求,在海量數據面前查詢、統計、更新效率很低,異構數據源的管理的利用效率低。所以,針對大數據平臺需求,必須設計一個滿足各種結構數據之間相互遷移,異構數據源之間高效利用的元數據管理系統,并且能夠對元數據進行追蹤溯源和版本管理。
1.1構建大數據平臺中元數據模型池
數據建模是一個發現數據元素、探尋面向數據的結構的過程,探索當前關聯方式及定義方式來進行需求調用,而其建立的模型稱為數據模型。數據模型可用于各種目的,從高層的概念數據模型到物理數據模型。從面向對象的角度來看,在概念上,數據模型是指采用“實體.關系”方法描述數據及其數據之間關系的模型,即指用實體、屬性及其關系對企業運營和管理中涉及的業務概念和邏輯規則進行統一定義、命名和編碼。數據模型是一組概念的集合,這些概念描述了系統的數據結構、動態特征和完整約束條件,這就是數據模型的三要素。數據結構是組成數據庫的對象的集合,是對象和對象間聯系的表達和實現,是對系統靜態特征的描述。數據操作是數據庫中數據可執行的操作集合,是對系統動態特性的描述。數據完整性約束是一組完整性規則的集合,規定了數據庫狀態以及狀態變化所滿足的條件,以保證數據的正確性、有效性和數據模型建模方法的基本原理相容性。而在大數據平臺中,我們構建一個元數據模型池,以供整個平臺按照需求進行模型設計和模型調用。
模型池:預測模型算法、Sqoop數據遷移、Storm數據模型算法、spark數據模型、數據庫連接管理模型。Sqoop基于MapReduce計算框架,支持Hive、MySQL、Oracle、HDFS、Impala、HBase之間相互數據遷移。每種數據模型,保存入模型池以啟動數據同步進行增量抽取任務。
1.2異構數據源連接管理
傳統的數據源的元數據主要有:源系統地址、網絡連接、訪問方式;計算機系統、操作系統;源數據庫鏈接說明。在大數據平臺中主要是對異構數據源和同構數據源進行連接管理,例如對 Oracle、Hive、MySQL、HDFS、Impala進行連接管理以供元數據管理系統調用。這是大數據平臺ETL處理的第一步情況,也是貫穿整個大數據任務調度的一個關鍵點。
1.3大數據平臺中各種數據庫的元數據獲取
傳統關系型數據庫的元數據主要有:分區設置、索引、數據庫管理系統層次的安全性特權與授權;視圖定義;存儲過程與 SQL管理腳本;數據庫管理系統備份狀態、備份程序及備份安全性。而大數據不僅僅是關系型數據庫,還有基于列族的HBase,基于文件的MongDB,HDFS,數據倉庫Hive,Impala等NoSQL,獲取這些元數據才能夠使得大數據平臺滿足各大數據庫之間數據相互遷移,數據清洗,數據裝載。
2 基于Neo4j來設計元數據溯源方案
2.1Neo4j原理
Neo4j是一個基于圖論算法、完全兼容ACID的圖形數據庫。低層數據以一種針對圖形網絡進行過優化的文件格式保存在磁盤上。由于Neo4j的圖形結構導致其數據結構不是必須的,而且可以完全沒有,它在數據建模方面針對常見的復雜領域數據集,如CMS里的訪問控制可被建模成細粒度的訪問控制表,類對象數據庫的用例等進行圖形數據建模。常常被用于基因分析、社交網絡數據建模、深度推薦算法等領域。由于Neo4j是自適應規模的,而且它的圖遍歷執行速度是常數,與圖大小無關,所以其讀性能可以達到每毫秒遍歷2000多節點關系,在處理圖關系時候完全是事務性的,這就保證了圖數據庫操作的完整性和準確性。相比關系型數據庫其性能更突出,而最為主要的一點是Neo4j面向分析的圖形數據庫。
2.2數據建模存儲
在大數據平臺的元數據池中,建模之后的數據模型都以JSON格式展現出來,基于Neo4j進行模型存儲,就要對其調用方式最小顆粒度進行分析、對其使用范圍進行規范、對其調用方式進行分析然后確定存儲方式。Neo4j存儲時候主要進行節點Label標簽定義、節點屬性定義、節點與節點之間關系定義。定義Label,主要是為了標示一個節點集合,為所屬節點的屬性定義某些限制,增加索引。Label機制提供的是一種對節點進行分組的方法,建立在分組上的管理需要采用TraversalDescription遍歷API機制來實現,進而在該集合上執行建立索引、定義約束和查詢等操作。定義節點屬性,按照首先創建空節點方法,添加屬性。而在創建的節點之間按照自己定義的關系語義來兩兩節點之間創建有向圖關系。
如圖1所示:這是基于Neo4j實現Storm兩張表進行Join操作最后導入HDFS中的數據模型存儲。
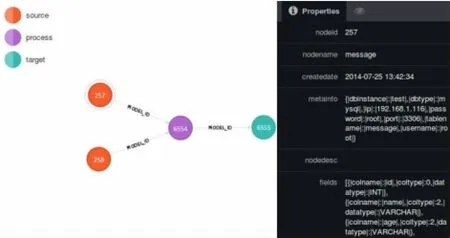
圖1 Neo4j存儲的Storm的Topology模型
2.3元數據版本維護
針對元數據的不斷更新、補缺、變換,傳統元數據管理系統沒有版本維護功能,很難完整地記錄所有的更改歷史記錄,也很難在某個時間戳的時間節點上進行統計和查詢。在大數據平臺中,如果對元數據的追加和元數據的更新做一個版本維護的話,數據量太大很少有人去愿意這樣做,而我們基于Neo4j做元數據版本管理,針對圖關聯,以及最短路徑算法對其進行高效存儲和快速查詢。與數據模型不同的是大量元數據我們存儲進入Neo4j圖形數據庫,采取嵌入式離線存儲方式,其內部采取MapReduce,可以快速存儲上億節點,把每條元數據設計為最小顆粒度進行節點存儲,一旦某條記錄被改變,不用去刪除節點,只需要在節點之后擴展一個加入時間戳的新節點,并建立有向圖關系,在查詢時候可以根據需求,對每一個修改時間段進行版本維護,可以快速實現不同版本之間全表對比,而且可以對修改的元數據很快速地遍歷修改過程和修改詳情。
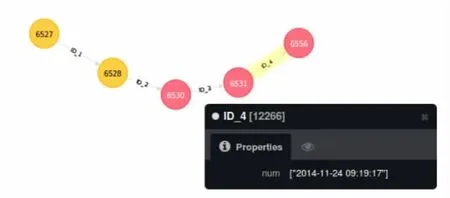
圖2 元數據版本管理
如圖2所示:按照我們的設計方案,某元數據經歷5次改變,甚至元數據都改變了Label,實現了跨集合之間版本管理和全表對比。
2.4元數據溯源
基于異構數據源的連接管理和數據源版本管理的基礎之上,我們需要對元數據的每一條信息,例如數據庫的表字段,進行數據溯源,在整個大數據平臺數據處理中,一旦某元數據做了更新和變換,我們都能通過最終形式的表現追溯到這個字段的整個遍歷歷史詳情,我們采用Neo4j進行有向圖擴展,每次元數據更改我們會基于這個節點對其進行節點擴展,其中兩個節點之間關系類型設計為修改標示符,在新增節點加入修改時間戳,以利于遍歷節點時候,能夠記錄修改時間,以及做時間段修改數量統計和遍歷詳情管理,數據源的每一個表一個Label,每一個字段一個節點,節點中屬性就是Value,外加連接節點信息。這種設計模式,可以最小粒度來溯源以及管理整個元數據,在大數據平臺整個元數據這種粒度調用管理,可以任意調取,以及實現不同的推送功能和將來擴展的應用。元數據溯源節點遍歷主要是對最短路徑算法和Dijkstra算法的實現。
最短路徑算法如下所示:

這種最短路徑算法,針對數據模型的深入和節點關系的出入度,而Dijkstra解決有向圖中任意兩個頂點之間的最短路徑問題,這種算法在元數據溯源和版本維護中可以快速查找作業流程和全表對比。

3 結語
本文基于Neo4j對大數據平臺的元數據進行溯源設計。通過Neo4j構建數據模型池,生成數據模型圖以供平臺調用,而對元數據的連接管理和任務調度過程以圖形進行關聯,進而對元數據進行版本管理和溯源,對整個大數據平臺的ETL模塊進行流程監控,流程回溯和全局掌控,并且對平臺內部擴展功能模型進行流程關聯和任務調度流程記錄。大數據的元數據溯源實現并且大大地提高了大數據平臺的推送能力和擴展N個大數據應用的能力,在未來大數據發展中,進一步提高平臺擴展性和推送能力將是大數據平臺自適應發展的一個核心發展方向。
[1]宋杰,郝文寧,陳剛等.基于MapReduce的分布式ETL體系結構研究[J].計算機科學,2013,40(6):152~154
[2]Ian Robinson,Jim Webber,and Emil Eifrem.Graph Databases[M].US:O'Reilly Media,2013
[3]宋青,汪小帆.最短路徑算法加速技術研究綜述[J].電子科技大學學報,2012,2(41):177~178
[4]戴磊,馬小平,姜代紅.基于優化Dijkstra算法的物流配送系統設計[J].微電子學與計算機,2011,10(28):34~35
[5]方圓,杜祝平,周功業.基于對象存儲的新型元數據管理策略[J].計算機工程,2012(3):25~27
[6]White T.Hadoop:The Definitive Guide[M].US:O'Reilly Media,2012
[7]Jin X J.Trident Storm and Flow Calculation Experience[J].Journal of Programmers,2012(10):99~103
[8]陸嘉桓.大數據挑戰與NoSQL數據庫技術[M].北京:電子工業出版社,2013
Big Data;Metadata;Provenance;Neo4j
Research on the Process of Metadata Provenance in the Big Data Based on Neo4j
JIN Yong-chao1,2,WU Huai-gu2
(1.College of Mathmatic and Computer,Xihua University,Chengdu 610039;2.College of Information Science Technology,Chengdu University,Chengdu 610106)
1007-1423(2015)08-0061-04
10.3969/j.issn.1007-1423.2015.08.014
靳永超(1987-),男,陜西寶雞人,碩士,研究方向為云計算、大數據處理
2015-02-12
2015-03-12
在大數據處理中,針對大量的結構化數據、半結構化數據,數據以不同形式被遷移、轉換、裝載,整個流程的數據和元數據都得不到很好掌控和集中管理,沒有辦法追根溯源,這對整個大數據平臺自適應的推送能力和擴展能力產生極大影響。提出一種基于Neo4j圖形數據庫來對大數據的元數據進行溯源的方法,以使得整個大數據處理過程中對元數據進行全局掌控,流程監控和流程回溯。
大數據;元數據;溯源;Neo4j
吳懷谷(1975-),男,四川成都人,博士,教授,研究方向為云計算體系結構、移動應用體系結構和分布式信息系統
In the process of big data,as for the large number of structured data,semi-structured data,the data is migrated,transformed,and loaded in different forms.The whole process of the data and metadata are hard to control and centralize management.And there is also no way to track back these data,so it affects this push capability and scalability of the whole large data platform.Proposes a method which is based on Neo4j graphics databases to provenance to the metadata,in order to global control,flow monitoring and flow provenance the processing of the data.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
今日農業(2022年15期)2022-09-20 06:56:20
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
財經(2017年2期)2017-03-10 14:35:35
光學精密工程(2016年6期)2016-11-07 09:07:19
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
雜文月刊(2016年1期)2016-02-11 10:35:51
