基于CUDA的直方圖問題并行優化
2015-09-26 05:18:24吳志輝徐小紅朱同林
現代計算機 2015年19期
吳志輝,徐小紅,朱同林
(1.華南農業大學信息與數學學院,廣州 510642;2.華南農業大學圖像圖形研究中心,廣州 510642)
基于CUDA的直方圖問題并行優化
吳志輝1,2,徐小紅2,朱同林1,2
(1.華南農業大學信息與數學學院,廣州510642;2.華南農業大學圖像圖形研究中心,廣州510642)
1 研究內容
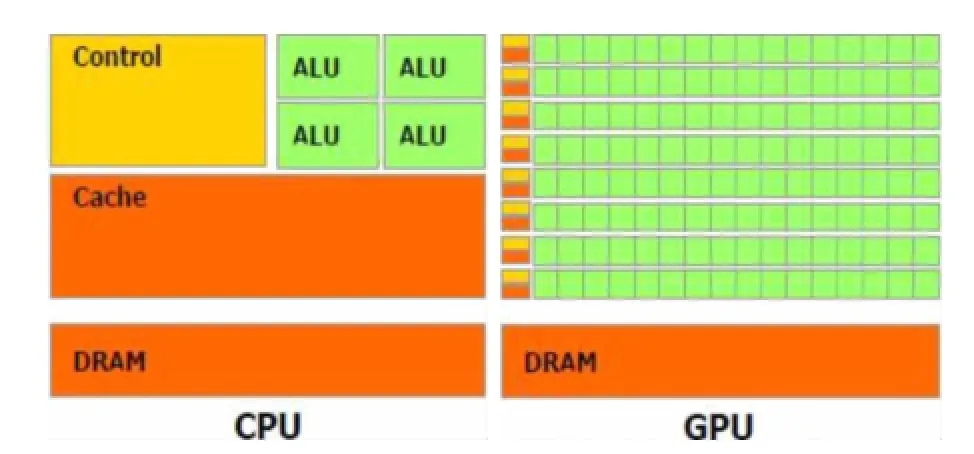
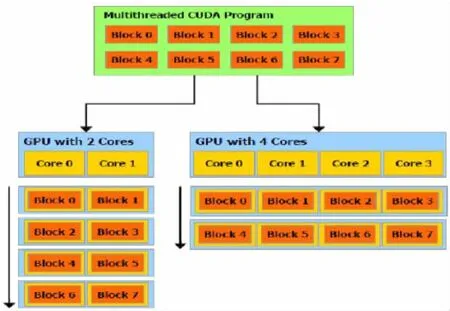
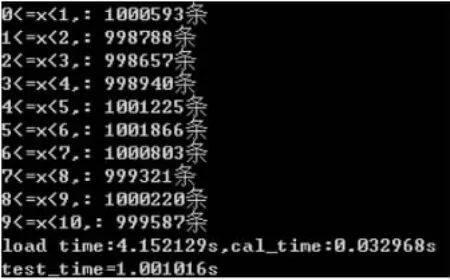
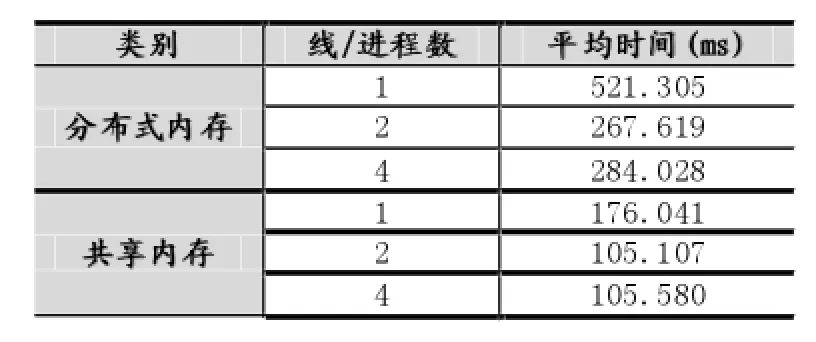
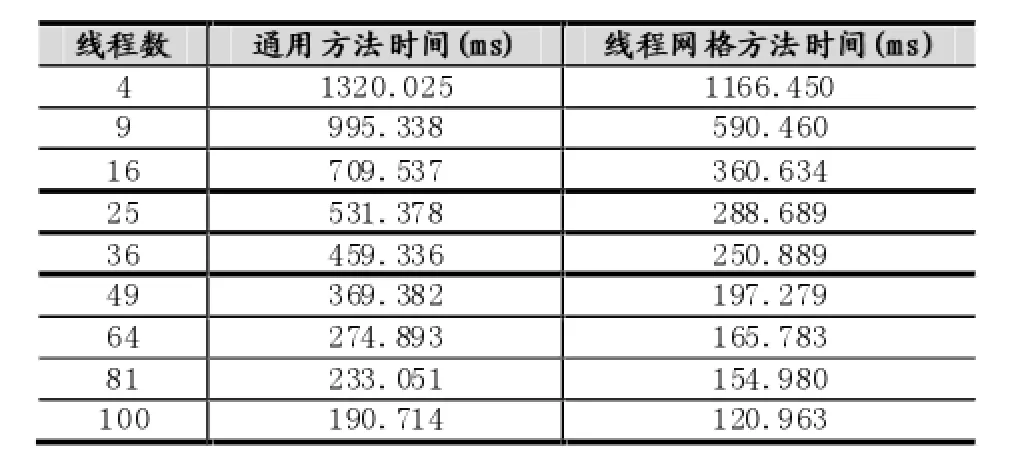
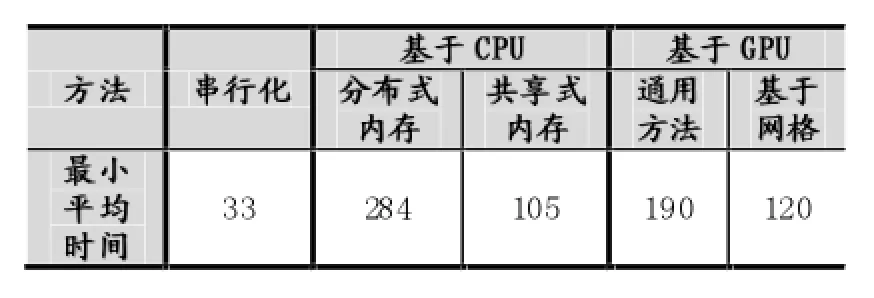
現有使用文件保存的輸入數據集N條,其中數據為浮點數,取值范圍為a≤x 直方圖問題是一個經典的問題,要解決這個問題需要遍歷所有的數據集中的數據,判斷所在的區間分布。隨著數據規模的增加,問題的規模也隨著增大。而數據間并沒有關聯性,適合使用并行計算的方法來實現。因此本文以該問題為切入點,來研究基于CUDA (Compute Unified Device Architecture)即英偉達公司推出的通用并行計算架構的并行計算的特點和優劣。 串行化方法即使用單線程的方法,數據集采用文件的形式,保存一個擁有n行的浮點數,然后統計完結果直接輸出到命令行中。串行化方法步驟如下: ①通過讀取文件的形式讀取出浮點數,由于后續的操作主要是查詢操作,所以使用數組形式保存即可。建立一個大小為N的實數類型的數組Inp,并全部初始化為0。然后依次i=0,1,…,N-2,N-1讀取數據到Inp[i]。 ②保存結果的投票箱同樣使用數組,建立一個大小M的整數數組,其中M=b-a,并全部初始化為0。 ③使用基于正序的順序遍歷,下標從小到大取出數字對應的浮點數。判斷浮點數屬于哪個投票箱。使用以下的方法來簡化,直接將浮點數轉化為對應的整數,此時的整數剛好是投票箱的下標,這樣就避免了重復比較,提高了效率。 ④直接將投票箱的內容輸出到命令行,串行程序結束。 根據串行化的方法步驟,利用分布式內存并行系統的特點,不同的進程擁有相互不共享的內存,因此所有的數據的交換都要通過通信來實現,而通信的時間消耗非常大,所以要減少數據的交換。具體優化如下: 首先要確定串行程序那些步驟可以進行并行化。串行化程序中,其中時間消耗最大的就是遍歷數組所有的浮點數,統計范圍的分布。因此并行化該步驟,將數組根據進程數N平均分為n份,每個進程即處理N/n個。 其次確定不同進程哪些數據需要進行數據交換。串行程序中主要涉及到的數據包括:①輸入浮點數數組,大小為N;②投票箱數組,大小為M。由于數據通信是非常大的時間消耗,為了縮短時間,浮點數數組的數據來自數據集文件,而一個進程讀取文件與多個進程讀取文件的時間相當,因此采用每個進程均讀取文件的方法來減少數據通信。而對于投票箱數組,則每個進程建立一個投票箱副本,然后再利用數據通信匯總。 根據串行化的方法步驟,利用共享式內存并行系統的特點,不同的線程共享同一個內存系統,所以數據交換方便,但容易出現數據出錯以及死鎖等問題,所以并行化時盡量多地防止數據出現的錯誤。 首先要確定串行化哪些步驟可以并行化,而其他的步驟直接使用串行即可。串行化時間銷售最大的就是遍歷數組所有浮點數,統計范圍分布了。因此,采用與分布式內存并行系統類似的方法。將數組根據線程數n,平均分為n份,每個線程處理個N/n。 其次,要確定是否出現死鎖、數據錯誤等問題。程序涉及到的數據包括:①輸入浮點數數組,大小為N;②投票箱數組,大小為M。其中對于浮點數數組,所有的線程均只進行讀操作,所以不存在問題。而對于投票箱數組,則會出現多線程同時寫入的問題,因此解決方案為,首先各線程先建立投票箱副本,然后針對匯總投票箱時增加鎖,使得匯總時只能有一個線程操作投票箱。這樣就實現了防止數據錯誤的問題。 市場對實時、高清晰度的三維圖形具有無法滿足的需求,由于這種需求的推動,可編程圖形處理器(GPU)已經演化成高并行度、多線程、擁有強大計算能力和極高存儲器帶寬的多核處理器[1]。 GPU和CPU的浮點計算能力差異的原因是:GPU是特別為計算密集、高并行度計算(如同圖像渲染)設計的,因此將更多的晶體管用于數據處理而不是數據緩存和流控,如圖1所示。 基于這樣的原因,2006年11月,英偉達推出了CUDA,一種基于新的并行編程模型和指令集架構的通用計算架構,CUDA能夠利用英偉達GPU的并行計算引擎比CPU更高效地解決許多復雜計算任務。 圖1 CPU與GPU CUDA核心包含三個重點抽象:線程組層次、共享存儲器和柵欄同步,這些被作為一個最小的語言擴展集簡單呈現(expose)給程序員。這些抽象提供了細粒度數據并行度和線程并行度,嵌套在粗粒度數據并行和任務并行中。它們引導程序員將問題劃分為可以被多個塊內線程獨立并行處理的粗粒度子問題,而每個子問題又被分為可以被一個塊內線程并行協作處理的更小的片段。這種分解通過在處理子問題的時候允許線程協作保持了語言的表達性,同時保證了自動可擴展性。事實上,每個塊可被調度到可用處理器核心的任意一個上,以任何順序,并行或者串行執行,這使得已編譯好的CUDA程序能夠在任意核心的GPU上執行。 圖2 系統可擴展性 基于CUDA的GPU程序同樣支持類似于在CPU下的并行優化方法,完全可以簡單地將原來針對多核CPU下的共享式內存并行系統程序移植到基于CUDA 的GPU程序下。而所不同的就在于GPU下有自己的存儲系統,所以要利用CUDA使用GPU進行計算,要將數據傳輸到GPU上。 首先要確定基于共享內存式并行系統有沒有存在基于CUDA的GPU程序下無法實現的情況。基于共享式內存并行系統的程序主要的并行步驟為遍歷數組的所有數據,統計分布。此步驟只涉及到讀操作,同樣適用于基于CUDA的GPU程序,因此直接移植即可。 其次要確定主機(即CPU)與GPU之間的數據傳輸。主要數據包括:①輸入浮點數數組,大小為N;②投票箱數組。其中,浮點數數組是并行計算的主要數據來源,因此此數據需要從主機傳輸到GPU。而投票箱數組是保存結果的主要來源,針對各線程,同樣需要將數據從GPU傳輸到主機中。 最后要根據GPU的不同,確定可使用GPU線程數。與CPU針對超過核心的線程數并行串行化不同,基于CUDA的GPU程序對超過核心數的線程很敏感,申請超過核心的線程非常容易導致程序出錯,因此無法超出核心數的使用線程。而相比CPU的核心,GPU擁有非常多的核心,例如本文實驗所用的GPU英偉達GT 540m就有多達96個核。 基于CUDA的GPU程序不僅提供了基于多線程的方法,還提供了線程網格的方法。有3個組件的向量,所以線程可以使用一維、二維、三維索引標識,形成相對應的線程塊。這提供了一種自然的方式來調用作用在域內元素上的計算,如向量、矩陣、體元(volume)。線程塊被組織成一維、二維或三維的線程網格。所以使用線程網格。通過構建線程網格,可以專門針對CUDA 做GPU的程序并行優化,這個是GPU相比CPU獨有的。 因此,在申請GPU的線程時,可以構建從一維到二維,乃至最高維的線程網格。對提供線程的效率也有幫助。由于數組為二維矩陣,因此采用二維網格優化。建立一個n×n的二維網格線程,將數組根據線程數k= n×n,平均分為k份,每個線程處理N/k。 實驗的平臺如下: 硬件方面:使用華碩A43SV系列筆記本作為測試平臺.其配置為:Intel Core i5-2410M CPU@2.30 GHz(即雙核四線程,主頻2.3GHz),NVIDIA GeForce GT540M CUDA.1GB(即顯存1G,支持CUDA的顯卡),4.00G內存。搭載64bits Windows 7操作系統。 軟件方面:使用VS 2008為基本平臺,基于分布式內存使用MPICH軟件;基于共享式內存系統使用OpenMP庫作為基礎;基于CUDA的GPU使用CUDA 4.0作為基礎。 實驗的數據: 數據集的大小取10,000,000,其中數據為浮點數,取值范圍為0≤x<10。 串行程序使用C++語言進行編寫,分別使用Query PerformanceFrequency和 QueryPerformanceCoun-ter這兩個函數統計時間消耗,單獨計算統計的耗時,時間穩定在33毫秒左右。 圖3 串行化方法實驗結果 針對通用方法的并行化程序,利用VMWare虛擬機軟件模擬了一個雙核的平臺。時間與前面串行的程序沒有對比性,因此單獨在此平臺下利用串行程序測試了一遍,時間穩定在0.17秒左右。 針對分布式內存并行系統,本文采用了單機MPICH2軟件來實現,測試了進程數為1,2,4的時間消耗。 針對共享式內存并行系統,本文利用OpenMP庫作為現實的載體,測試了線程數為1,2,4的時間消耗。 表1 基于CPU并行化程序實驗結果 針對基于CUDA的GPU程序實驗結果,包括兩個內容:①基于CUDA的通用方法的并行優化的結果;②基于CUDA的線程網格的并行優化的結果。 表2 基于CUDA的并行優化實驗結果 實驗的最終每種方法的最小平均時間結果如表3所示: 表3 實驗結果比較 本文使用將基于CUDA的GPU程序與普通的串行以及傳統的CPU的相關并行方法做了比較。從實驗的結果可以看出,在本文舉例的直方圖中,采用GPU來進行并行計算更具有優勢。表現在以下: (1)GPU的基于計算密集,高并行度計算設計的。采用多核心的流式結構,本身就更適合用于做并行計算。本文所采用的CPU和GPU,論主頻來說CPU是擁有更快的速度,但是在具體實驗中,GPU利用多核的優勢達到了和CPU差不多的效率。 (2)基于CUDA的GPU程序開發提供相比針對CPU的并行更多的功能。例如:本文使用的基于線程網格的優化,比使用傳統CPU并行計算方法提升了效率,減少了時間的消耗。 因此,在可以預見的未來,基于GPU的并行計算會發揮重要的作用。而針對GPU的CUDA架構也將大有用處。 [1]盧風順,宋君強,銀福康,張理論.CPU/GPU協同并行計算研究綜述[J].重慶:計算機科學,2011,03:5-9. Histogram;Serialization;Distributed Memory;Shared Memory;CUDA Parallel Optimization of Histogram Problem Based on CUDA WU Zhi-hui1,2,XU Xiao-hong2,ZHU Tong-lin1,2 1007-1423(2015)19-0058-05 10.3969/j.issn.1007-1423.2015.19.015 吳志輝(1989-),男,廣東揭陽人,在讀碩士研究生,研究方向為數字圖像處理 朱同林(1963-),男,江西南康人,博士,教授,博士生導師,研究方向為計算機圖形學及數字圖像處理 2015-05-12 2015-06-25 直方圖問題是一個經典的問題,以該問題為切入點,比較基于CUDA的GPU(圖形處理器)程序,與串行和傳統的基于CPU(中央處理器)的并行程序的比較,從而找出基于CUDA的GPU程序的特點與優勢。 直方圖;串行化;分布式內存;共享內存;CUDA 高等學校博士學科點專項科研基金聯合資助課題(No.20124404110018:2013.1-2015.12) 徐小紅(1975-),女,湖南寧鄉人,博士,講師,研究方向為生物統計、計算機視覺和圖像處理 Histogram program is a classic problem,takes the the problem as starting point,compares the GPU program based on comparison CUDA with the serial and traditions based on the CPU comparison of parallel programs,in order to identify the features and advantages of GPU program based on CUDA.2 直方圖問題的串行化方法
3 基于CPU的并行化方法

4 基于CUDA的并行優化算法

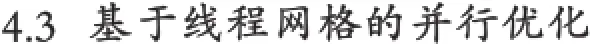
5 實驗結果
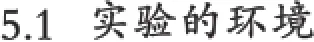
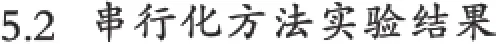
6 結語
(1.College of Mathematics and Information,South China Agricultural University,Guangzhou 510642;2.Research Center of Image&Graphics,South China Agricultural University,Guangzhou 510642)
猜你喜歡
兒童故事畫報(2019年5期)2019-05-26 14:26:14
人大建設(2019年12期)2019-05-21 02:55:44
中山大學法律評論(2018年1期)2018-03-30 01:21:00
瞭望東方周刊(2017年42期)2017-12-05 18:49:38
環球時報(2017-03-30)2017-03-30 06:44:45
Coco薇(2016年2期)2016-03-22 02:42:52
中國衛生(2015年3期)2015-11-19 02:53:32
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
