汽車車內噪聲與振動等級評估*
2015-09-04 06:25:48劉興恕張伯俊張鵬飛
汽車工程師 2015年8期
劉興恕張伯俊張鵬飛
(1.天津職業技術師范大學汽車與交通學院;2.邢臺職業技術學院)
噪聲與振動是汽車界最活躍的研發領域之一,在汽車研究與產品開發過程中的作用越來越突出。汽車制造公司為了提高汽車車內舒適度,積極開展研究。研究人員認為在汽車車內,暴露的噪聲與振動直接與發動機轉速的增加或者減少一致,一般來說,與發動機轉速的傳播成正比。在前人研究的基礎上,本研究基于試驗考慮了聲品質指標和振動,通過聚類和分類算法建立評估模型,使用“遺傳算法-神經網絡”(GANN)分類聚類的數據,應用線性判別分析(LDA)驗證分類結果[1]。研究表明:采用聚類和分類算法評估汽車車內噪聲與振動等級是可行的,并為今后車內噪聲與振動分析和控制提供借鑒。
1 研究方法
1.1 振動評估
測量振動等級最理想的方法是參考振動劑量值,故在本研究中,依據文獻[2]并參考加權加速度評估振動等級。振動劑量值的計算公式為:
式中:μVDV——振動劑量值,ms-1.75;
a(t)——加權加速度,m/s2;
t——時間,s;
T——發生振動的總時間,s。
1.2 聲學等級評估
文章使用聲品質軟件,選擇響度、尖銳度、粗糙度和抖動度4個聲品質指標[3],來定量并且定性地評估聲學等級。
1.3 蒙特·卡羅模擬
蒙特·卡羅模擬是一種概率性技術,通常是基于目前數據中存在的趨勢用來產生大量的隨機樣本[4]。由于多元正態分布(MVN)是蒙特·卡羅模擬的一種應用,且文中數據涉及多個變量,因此,使用MVN法是最合適的方法[5]。
1.4 聚類和分類
1.4.1 聚類
本方法對聚類所應用的工具是層次聚類。聚類過程的初始步驟在于將數據集中的每個項目分配到其本身的群中。在這種情況下,如果項目數為n,即意味著現在具有的群數為n。這是因為每個群僅包含一個項目。在這里,就項目之間的距離而言令相似性等于群之間的距離;然后,通過觀察最相似的一對,或者可以組合為單個群的最接近的群,繼續該過程,如圖1所示。
1.4.2 分類
分類包括“遺傳算法-神經網絡”(GANN)和線性判別分析(LDA)。在本研究中,出于分類的目的而采用GANN模型。該模型包括遺傳算法和人工神經網絡2個要素。LDA作為另一種選擇,通過“類別和其他范圍內的分散矩陣”及“類別之間的分散矩陣”2種分類方法,旨在最大化類別之間的可分性。
2 試驗
根據聲音頻率和振幅測量噪聲,使用B&K頭&軀干(HAT)2100型傳感器獲得特定的聲品質指標。評估振動等級的測量位置包括前車門(副駕駛員側)、變速箱、轉向裝置、前車門(駕駛員側)、儀表盒和后側車門(駕駛員側)[6]。需要在3種狀態下進行數據測量:
1)靜止:無任何路面激勵的影響;
2)高速路上的運動:路面粗糙度的影響適中;
3)人行道上的運動:路面粗糙度的影響強烈[7]。
測試車采用自動質子位V6發動機。測量車內聲品質所使用的設備為布魯爾&卡亞爾便攜式及多通道脈沖3560D型儀器。為了記錄噪聲,B&K頭&軀干(HAT)2100型傳感器位于前排副駕駛右側車門,在儀表板前底部安裝了振動探測器B&K同位素分離器751-100模型,如圖2所示。
首先使用B&K脈沖Lapshop軟件測量噪聲;然后使用布魯爾&卡亞爾聲品質7698型軟件分析噪聲,獲得聲品質指標值。在本例中,所有測點處讀取的數據必須記錄汽車底部、儀表盒、轉向、車門和變速箱的振動測量值。
測量中每個試驗的記錄時間為10 s,由駕駛員和筆記本電腦處理器進行測試。駕駛員的任務是驅動汽車,專注于汽車行駛方向并維持特定的轉速。與此同時,筆記本電腦處理器的任務是操作B&K脈沖Lapshop軟件,記錄測試過程中在每個試驗中發生的噪聲和振動。發動機在特定轉速下,每個測量必須重復3次[8]。
3 結果
基于聲品質指標的測量結果,發現在駐車或者驅動狀態下,響度指標值隨著發動機轉速的增加而增加。與響度指標相反的是尖銳度指標值隨著發動機轉速的增加而減少。然而,關于粗糙度指標和抖動度指標對發動機轉速的變化并沒有觀察到特別的趨勢。應用方差分析(ANOVA)來研究存在于不同位置之間結果中的變化,如圖3所示。
從圖3可以看出,產生振動等級較高的主要位置是汽車儀表盒、轉向、車門和變速箱。比起其他零部件,汽車底部是具有較低振動暴露的唯一位置。
通過調查聲品質參數與振動劑量值之間存在的相關性,可以建立線性回歸模型確定這2個因素之間存在相關性的明顯程度。根據線性回歸分析的結果,發現在特定零部件上聲品質指標的某些參數與暴露的振動的某些等級是一致的,如圖4所示。選擇的因素是響度指標和在汽車底部、轉向和變速箱處的暴露振動。為了評估駕駛室內經歷的聲品質等級,將這4個因素作為聚類模型中的輸入,以便能夠將其分成5種舒適度,如表1所示。
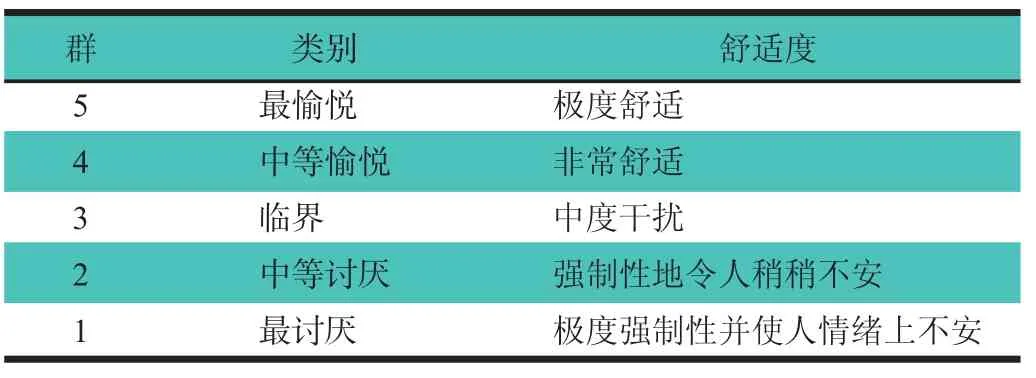
表1 汽車車內舒適度特性
盡管在駕駛室內測量了不同零部件處的振動等級,但是注意到只有一些區域是明顯的振動暴露點,其中僅選擇與參數響度、底部、轉向及變速箱因素相關聯的數據應用在聚類和分類過程中。明顯的暴露振動點可以通過線性回歸分析結果觀察到。聚類結果根據發動機轉速在1 200~3 500 r/min范圍內,分別在靜止、高速路及人行道狀態下,獲得的響度及振動劑量值(底部、轉向和變速箱)的數值不同,對應的群類也不同。基于所觀察到的結果,發現通過考慮輸入的噪聲與振動,使用基于舒適度的層次聚類,可以對噪聲與振動的暴露成功進行聚類。這是一個新穎的方法,而不是暫時的評估,因為這些暴露的噪聲與振動通常是主觀的,并且很難評估。
根據評估結果,還知道層次聚類能夠找到在調查的特定零部件上響度參數與暴露的振動之間存在的相關性。為生成更多的數據,模擬了層次聚類,在這之后,執行的分類過程產生的結果準確性更高。在分類過程中使用了GANN和LDA 2類分類,對每個GANN模型,分類算法都進行了20個試驗。在相應的模型中通過衍生的5 000個數據庫和測試的2 500個數據庫,來評估提出的GANN。同時對于每個LDA模型,衍生的數據庫為5 000個。根據聚類所得到的結果,通過隨機模擬可以獲得分類所需的數據庫。基于這些結果,發現2種模型對于數據的分類是足夠有效的,因為獲得每個試驗的精度都超過70%。但是,對比這2種模型,LDA的性能要比GANN的性能更好,如圖5所示。
4 結論
基于提供的數據,提出的層次聚類的算法和混合GANN與LDA 2種算法能夠有效地聚類和分類噪聲振動的等級。通過參考經歷噪聲與振動的趨勢,提出的模型就噪聲振動而言能夠將這些組之間的舒適度區分為最愉悅、中等愉悅、臨界、中等討厭和最討厭5個群。除此之外,LDA算法通過使用噪聲振動的輸入數據庫,成功簡化了經歷的噪聲振動產生的舒適度。通過觀察圖5中的結果,得出相比于GANN,LDA算法更有效,因為后者表現的準確率更高。
猜你喜歡
科學大眾(2023年17期)2023-10-26 07:39:14
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
天天愛科學(2020年6期)2020-09-10 07:22:44
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
兒童時代·快樂苗苗(2017年7期)2018-01-24 18:28:45
數學物理學報(2017年6期)2018-01-22 02:26:40
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
作文大王·低年級(2016年4期)2016-04-18 00:24:37
決策探索(2014年21期)2014-11-25 12:29:50
