基于云填充和蟻群聚類的協同過濾圖書推薦算法
2015-08-17 05:30:15毛志勇趙盼盼
現代情報 2015年5期
毛志勇 趙盼盼
(遼寧工程技術大學工商管理學院 ,遼寧 葫蘆島125105)
基于云填充和蟻群聚類的協同過濾圖書推薦算法
毛志勇趙盼盼
(遼寧工程技術大學工商管理學院 ,遼寧 葫蘆島125105)
針對傳統協同過濾技術在圖書推薦中效率不高、數據極端稀疏性及主觀性強等問題,提出一種基于云填充和蟻群聚類的協同過濾圖書推薦方法,首先根據蟻群聚類算法得到用戶群分類,然后在進行協同過濾前預先通過云模型填充用戶——項目矩陣 ,以降低數據的稀疏性。實驗結果表明 ,該算法在推薦精度上有明顯的提高。
協同過濾 ;蟻群聚類 ;云填充;圖書推薦
隨著網絡技術的不斷發展,圖書館服務向個性化、智能化方向發展成為必然趨勢。雖然現在各級圖書館都建立了信息服務平臺 ,但大部分信息服務平臺只是提供簡單的查詢功能,需要用戶主動提交查詢的內容,然而隨著圖書流通數據的不斷積累,讀者在這種平臺中很難快速的獲得所需要的信息,智能圖書推薦系統則是通過分析不同用戶的興趣所在,主動幫助用戶從海量的信息中找出感興趣的信息,為用戶提供個性化的信息服務。因此構建有效的智能圖書推薦系統是提高圖書館信息服務水平的重要途徑 ,為此研究者提出了很多推薦方法:基于內容的推薦,混合推薦和協同過濾等 ,同時結合先進的技術,如聚類,關聯規則,貝葉斯網,神經網絡和圖論模型等來實現這些方法[1]。
目前協同過濾是應用最成功的推薦技術,在許多領域也得到了廣泛的應用。但是它也仍然存在很多的問題。由于用戶和資源種類的爆發式增長,用戶——項目矩陣成了高維矩陣 ,與此同時,用戶評分的資源卻很少,一般情況下在1%以下[2]。而圖書館中也會遇到同樣的問題 ,圖書數目會不斷增加,并且隨著時間的推移,借閱記錄也會成階梯式增長,數據的極端稀疏性大大降低了傳統的協同過濾的推薦效率。目前文獻[3-5]提出了用k-means對用戶進行聚類 ,以實現對用戶——項目矩陣的降維,但由于kmeans算法需要事先指定初始聚類中心 ,而初始聚類中心對聚類結果有較大的影響,所以具有一定的主觀性,導致協同過濾圖書推薦質量的降低。
針對上述問題,本文提出了一種基于云填充和蟻群聚類的協同過濾圖書推薦方法 ,嘗試利用改進的蟻群聚類算法對用戶進行聚類,然后在得到的小的聚類中,利用云模型對用戶——項目矩陣進行填充,最后采用基于用戶的協同過濾算法來計算用戶間的相似性并找到最近鄰居集,得到目標用戶對未評分項目的預測評分,形成Top-N推薦。目的在于縮小目標用戶最近鄰的搜索范圍,有效減少搜索開銷,從而達到推薦效率的提高,同時,通過云模型填充用戶——項目矩陣,有效地緩解數據極端稀疏性和主觀性強的問題。
1 基于云模型的數據填充算法
1.1云模型簡介
云模型是李德毅院士提出的一種定量定性轉換模型[6],能夠實現定性概念與其數值表示之間的不確定性轉換。正態云模型是最重要的一種云模型,它利用云模型的3個數字特征期望,熵和超熵形成特定的發生器,生成與定性概念相對應的定量轉換值。
云發生器分為正向云發生器和逆向云發生器。正向云算法是由云的3個數字特征C(Ex,En,He)通過正向云發生器生成相應的云滴(x,y),而大量云滴聚集在一起形成云,實現定性概念向定量的轉換。逆向云計算是由 N個云滴(x,y)通過逆向云發生器生成云的3個數字特征C(Ex,En,He),實現定量值到定性概念的轉換。
兩朵云之間的相似度可以用兩朵云的數字特征向量的夾角余弦來表示,計算如下:

1.2基于云模型的云填充算法
對于任何一個圖書館,讀者對圖書的評分記錄是很少的,從而評估矩陣相當稀疏,導致推薦效果大大降低。為解決該問題,本文采用云填充的方法解決稀疏問題。其基本思想是:首先根據云相似性定義來計算項目之間的相似性,利用用戶對相似項目的評分來預測未評分項目的評分[7],填充用戶項目矩陣。具體的過程是 ,先找出未評分的項目,采用云模型計算項目之間的相似性,找出該項目的最近鄰,最后得出未評分項目的評分。
算法1:基于云模型的云填充算法
輸入:用戶——項目矩陣Rm×n
輸出:填充較完整的用戶——項目矩陣
Step1:根據用戶——項目矩陣 Rm×n,統計出項目的評分頻度向量 Ii,然后通過逆向云計算,得出每一個項目的評分特征向量Vi(Exi,Eni,Hei)(1≤i≤n);
Step2:根據云的相似性度量公式 (1)來計算未評分項目 j和其他項目間的相似性,得到項目相似度矩陣;
Step3:找出未評分項目 j的最近鄰居集Mj,鄰居集 Mj中的項目與項目i的相似性依次降低;
Step4:利用文獻[8]的方法來預測用戶對項目 j的評分
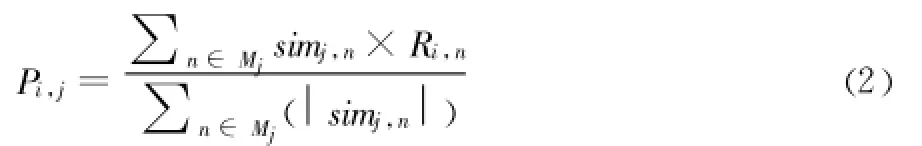
其中 simj,n是項目j和項目n的相似度;Ri,n是用戶i對項目n的評分,n是任意的項目p的相似項目。
例如,系統中有4名讀者Anne、Tim、John、Joe,5本圖書A、B、C、D。假設評分標準為5個級別 ,對應的分值分別為{1,2,3,4,5}。表1中Tim對圖書A的評分就是要預測的評分。

表1 R讀者評分矩陣
根據算法1,首先統計出每本圖書分值出現的頻度,記作圖書的評分頻度向量I=(IA,IB,IC,ID,IE),IA~IE分別表示每本圖書相對于5個等級的評價次數,表中給出的5本圖書的評分頻度向量分別為IA=(1,2,0,0,0),IB=(0,0,0,2,2),IC=(0,0,1,2,1),ID=(2,2,0,0,0),IE=(0,1,1,1,1),利用逆向云計算,分別算出5本圖書的評分特征向量VA=(1.25,0.54819,0.37163),VB=(4.5,0.62650,0.45000),VC=(4.0,0.62650,0.73201),VD=(1.5,0.626450,0.45002),VE=(3.5,1.25300,1.06925),很顯然,圖書A和圖書D的評分偏低 ,圖書B,C,E的評分偏高。
利用云相似性公式 (1),計算出兩兩之間的相似度,結果如表2所示:
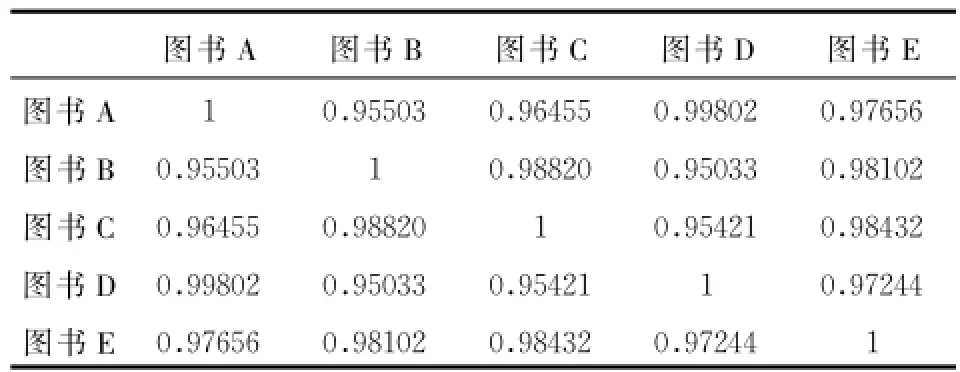
表2 R項目相似度矩陣
由表2可知,圖書A和圖書D的相似性最高 ,與我們的直觀判斷一致。利用預測評分公式 (2)計算Tim對圖書A的評分為3。以此來填充讀者評分矩陣。
2 改進的蟻群聚類算法
2.1蟻群聚類基本原理
基于蟻堆聚類的基本原理是:在工蟻堆積螞蟻尸體的過程中,小蟻堆通過不斷吸引工蟻來堆積更多的螞蟻尸體,從而形成一個正反饋機制。根據螞蟻搬運尸體的行為,Deneubourg等[8]提出了BM模型,Lumer等[9]進而提出了LF算法,從而將BM模型運用于數據的聚類分析。但LF算法中的參數的設置沒有理論基礎,大都是靠經驗來主觀設定,所以也存在很大的缺陷。徐曉華[10]等給出了一種新型的螞蟻運動模型,成為AM模型。該模型將每一個聚類的數據看作是一只螞蟻 ,同樣采取了相似度和概率轉換來實現聚類,在一定程度上解決了BM模型中的時間成本高的問題。
2.2改進的蟻群聚類算法
本文對基本蟻群聚類的改進主要有以下幾個方面:
2.2.1投點問題
在BM和AM模型中,數據采取的是隨機投點大方式投射到二維表格中 ,這會導致在聚類初期螞蟻很容易被撿起或放下,螞蟻與局部環境中的其他螞蟻的相似度比較低,從而形成初期分類的時間比較長。本文先對數據進行主成分分析 (PCA),將PCA處理過的前兩個主成分投影坐標,由于前兩個主成分已經保留了數據的大部分信息,所以相似性比較大的數據在投影之后就會挨得比較近,這樣在聚類初期,數據和局部環境中的其他數據的相似性比較高,從而提高算法的運行效率[11]。
2.2.2群體相似度的計算
群體相似度是螞蟻與其所在局部環境中其他螞蟻的綜合相似度。LF(Lumer Faieta[9])算法中給出了基本的群體相似性度量公式:
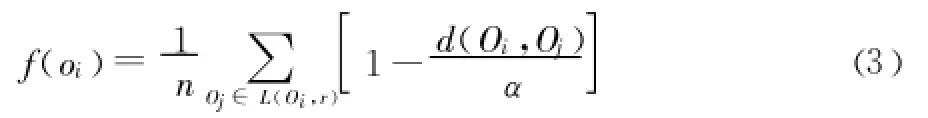
其中:L(Oi,r)為螞蟻 Oi的局部環境,即以 r為半徑的圓形區域;d(Oi,Oj)為模式 Oi,Oj之間的距離,通常為歐式距離;n為模式Oi的局部環境內其他模式的個數;α為群體相似系數,它對聚類中心的個數以及算法的收斂速度有重要影響,但是它的調整主要依靠個人經驗,缺乏理論指導而難以掌握。所以考慮到 α的影響 ,本文在相似性公式中去掉α,因為相似度本質上是由螞蟻間的距離所決定的。因此直接用 d來定義相似度,同時由于每一個屬性在聚類中的作用是不一樣的,所以考慮特征對分類的貢獻率[12],利用主成分分析得到屬性的貢獻率作為屬性的權重,使屬性在聚類過程中發揮更大的作用,從而有效的改善聚類的質量。其公式如下:
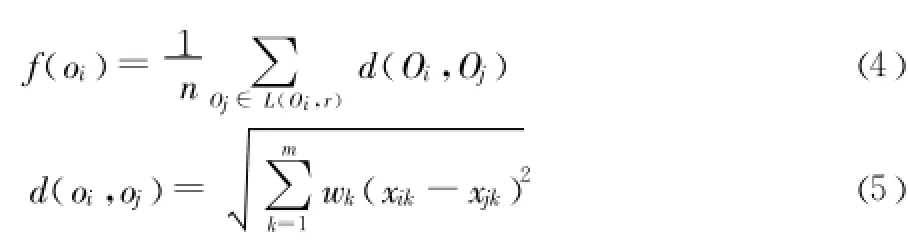
其中w=(w1,w2,…,wm)是與屬性相對應的一個權重矢量。wi為該分量的貢獻率,刻畫了第 i維屬性在聚類過程中的重要程度。
2.2.3局部最近鄰移動原則
本文中螞蟻的移動原則是遵循局部最近原則[13],其直接含義是螞蟻向距離最近的伙伴移動,先在局部找到自己的最近鄰,進而找到全局的最近鄰伙伴,這符合物以類聚的原理。在這種思想的指導下,給出了螞蟻移動的下一個坐標的定義:
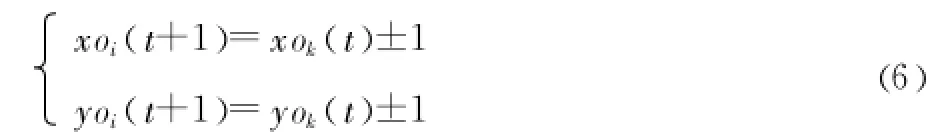
其中 t為循環次數,每次螞蟻的坐標都不完全重合,相比傳統的隨機移動方式 ,這種方法能尋找局部最優,尤其在聚類一段時間之后 ,螞蟻與局部環境中的其他螞蟻已經有一定的相似性時,這種移動方式更加合理。
與此對應,該算法中不再采用概率轉換函數,而是直接設定相似性閾值 F,通過 F與f(Oi)的比較可以看出螞蟻的狀態。這種方法簡單易行,并且避免了概率轉換函數中參數對算法的影響。
閾值 F必須隨算法的進行適當調整,如果 F過大,會導致螞蟻老是靜止不動;過小,會導致螞蟻一直在動,找不到合適的地方停下來休息。一般移動螞蟻的數量占總螞蟻數量的比例為20%時 ,相似性閾值 F比較合理。因此本文提出一種自適應調整閾值的方法 ,具體策略如下:
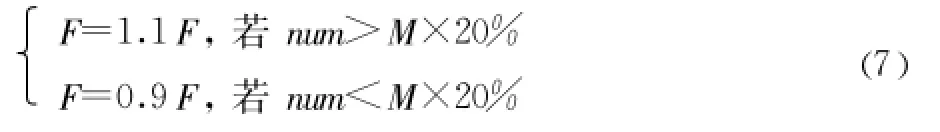
其中:num為此次迭代中處于移動狀態螞蟻的數量,M為總螞蟻數。
算法2:改進的蟻群聚類算法
Step1:初始化參數,鄰域半徑 r,相似性閾值 F等,并將所有螞蟻的狀態設置為睡眠狀態。
Step2:對待聚類的螞蟻進行主成分分析,并將處理過的前兩維數據投射在二維坐標平面上,并給螞蟻賦予初始坐標。
Step3:for t=1∶N
for i=1∶M
以螞蟻 Oi的當前坐標為中心,r為半徑,利用式 (4)計算螞蟻在局部環境中的相似度 f,比較 f與F的大小,若 f<F,則螞蟻靜止不動,否則按照最近鄰移動原則 (式(6))更新螞蟻的坐標值
End(螞蟻個數循環完畢)
自適應調整閾值F
End(總迭代完成)
Step4:根據聚類結果計算各聚類中心,并輸出個聚類的螞蟻。
3 基于云模型和蟻群聚類的協同過濾
基于云模型和蟻群聚類的協同過濾算法的基本思想是:根據改進的蟻群聚類得到用戶的分類,在每一小類中利用逆向云計算的云填充方法來填充用戶項目矩陣,尋找用戶的最近鄰,最終產生推薦集。
具體步驟如下:
Step1:利用算法2對用戶進行聚類
Step2:在小類中利用算法1對未評分的項目進行填充
Step3:得到填充較完整的用戶——項目矩陣,根據Pearson相關性度量方法計算用戶之間的相似性,計算方法如下:
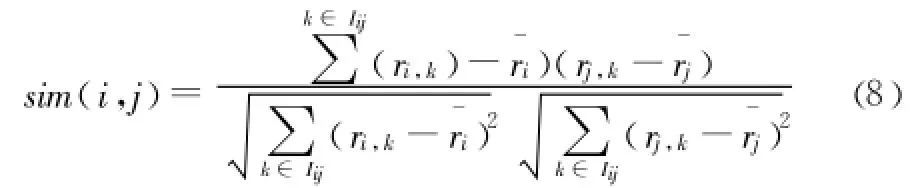
其中,Iij表示經用戶i和j共同評分的項目集,ri,k表示用戶i對項目k的評分,表示用戶i對所有項目興趣度的平均值。
Step4:將sim(i,j)的值從大到小進行排序,取前 N個鄰居組成目標用戶的最近鄰集合Nu。
Step5:根據最近鄰居對項目的評分來計算目標用戶對待推薦項目的評分,選擇評分比較高的前 N個項目推薦給目標用戶,方法如下:
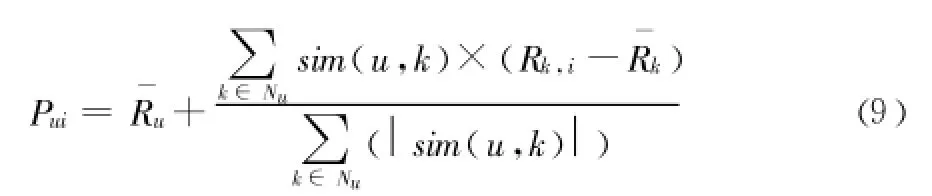
ˉRu和ˉRk表示目標用戶u和鄰居用戶k對項目的平均評分,sim(u,k)表示目標用戶 u與鄰居用戶k對項目評分的相似度,Rk,i表示鄰居用戶k對項目i的評分。
4 實驗結果及其分析
4.1實驗數據集
本文從某高校圖書館提取了2012年1月到2013年12月部分用戶的圖書借閱記錄 ,共24 907條借閱數據 ,讀者為兩個專業共423人,圖書選取6個學科2 500冊教材和讀物。該數據庫包括借閱信息表,讀者信息表和圖書信息表。借閱信息表提供了借閱證號、索書號、評分等屬性;讀者信息表提供了讀者姓名、專業、性別、年級、借閱證號等屬性;圖書信息表提供了學科、書名、作者、出版社等屬性。將實驗數據集分為訓練集和測試集兩部分,其中訓練集占整個數據集的80%,測試集占整個數據集的20%。在其基礎上做如下處理:
(1)數據清理:對原表中的無效的,冗余的數據進行刪除操作,同時由于讀者興趣的變化,刪除時間過早的讀者借閱記錄。
(2)讀者借閱號作為讀者身份的標示,一般采用字符類型,不便于計算,應該將其轉換為數據型。
(3)對數據進行標準化處理,以方便算法的應用。
4.2度量標準
本實驗中采取的是評價絕對偏差 (MAE)作為推薦系統質量的度量標準。該方法是通過計算用戶實際的評分與通過算法得到的預測的用戶評分之間的偏差來衡量衡量的準側性。MAE越小,預測的就越準確,推薦的質量就越高。
假設預測的用戶的評分集合為{p1,p2,…,pN},而對應的用戶的真實評分集合為{h1,h2,…,hN},則平均絕對偏差可描述為:

4.3實驗結果
實驗中利用改進的蟻群聚類方法對用戶進行聚類,蟻群算法中采用更簡單的相似度度量方法和自適應的閾值調整方法 ,簡化了參數的選取,減少了實驗的不確定性,提高了算法的實用性。閾值的自適應調整曲線如圖1所示。
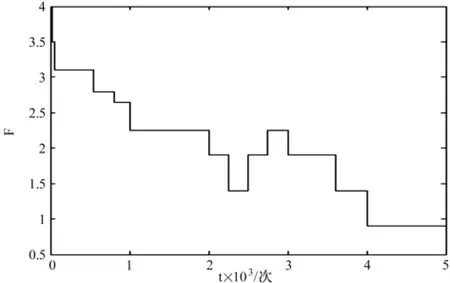
圖1 RR閾值的自適應調整
將本文算法與傳統的協同過濾推薦算法以及文獻 [1]提出的基于用戶模糊聚類的協同過濾推薦研究進行比較,在計算MAE值時,鄰居數目從10增至55,間隔為5,實驗結果如圖2所示。
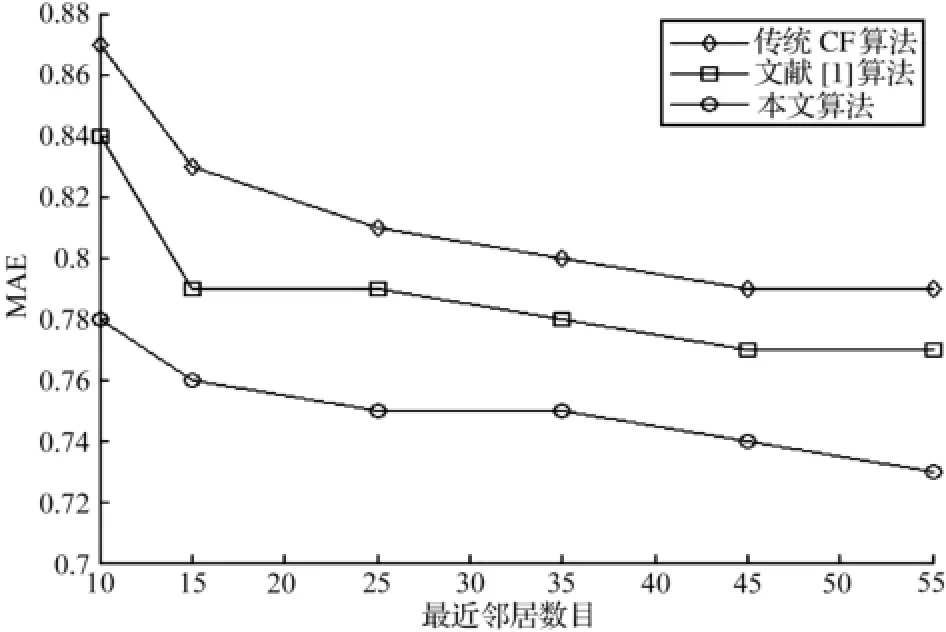
圖2 RR各算法MAE值比較
從圖2可以看出 ,隨著鄰居數目的增加,3種算法的MAE值都呈下降趨勢,但本文的算法在整體上都具有最小的MAE值,說明本文的算法不僅有效地緩解數據稀疏性的問題,還提高了推薦的效率和質量。
為驗證本文提出算法的有效性,使用查準率和誤判率[14]來檢查實驗結果 ,從兩個專業中抽取200人,為每位讀者推薦20本圖書,實驗結果如表3所示:
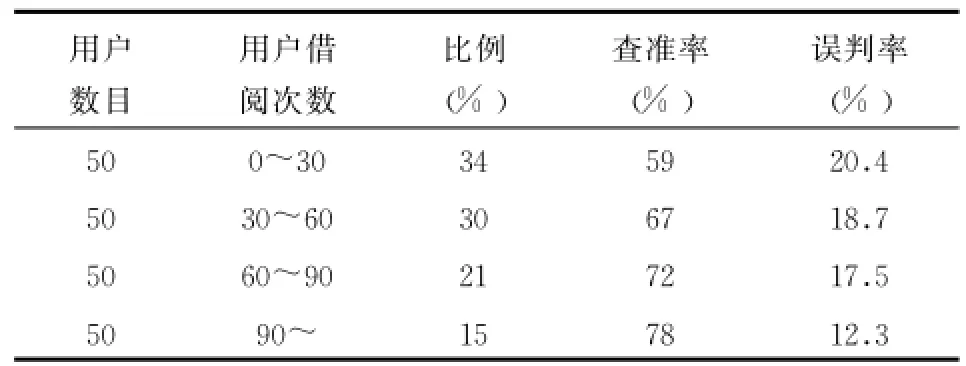
表3 R準率和誤判率統計表
從表3可以看出 ,借閱次數為0~30的讀者群的推薦效果與借閱次數為90以上的讀者群的推薦效果相差較大,并且隨著用戶借閱次數的增加,推薦效果也越來越準確。
4.4實驗結果分析
傳統的基于用戶的協同過濾算法利用所有用戶對項目的評分來計算用戶間的相似性,不僅計算量大,并且由于數據的極端稀疏性,同時在推薦過程中將所有用戶對項目的評分同等對待,忽略了用戶之間的差異性,導致推薦質量的降低。基于用戶模糊聚類的協同過濾運用模糊聚類和slope-one對用戶項目矩陣進行填充,最終產生推薦,但模糊聚類在數據結果簇是密集的,且簇與簇之間區分明顯時效果才比較好,基于用戶模糊聚類的協同過濾忽略了孤立點對模糊聚類的影響,同時該算法需要事先指定聚類數目和模糊加權指數,具有一定的主觀性。在大數據時代,slope-one在運算過程中會產生巨大的中間數據,對單機來說很難處理,一定程度上降低了運行的效率。而本文擯棄了不必要參數的影響 ,盡量減少主觀性,并且利用改進的蟻群聚類實現全局搜索和并行運算,避免聚類陷入局部最優解,同時利用云模型對用戶項目矩陣進行填充,綜合考慮用戶的統計特征,大大提高了近鄰用戶選取的準確性。實驗結果表明,本文提出的算法有效地提高了推薦系統的質量。
5 結束語
本文提出的基于云填充和蟻群聚類的協同過濾圖書推薦算法,有效地緩解了數據的稀疏性,避免了主觀臆斷,提高了推薦的效率。實驗結果表明,該算法明顯提高了推薦質量和精度。為進一步提高該算法的推薦質量,下一步研究中考慮如何改進蟻群聚類算法中閾值F的自適應調整,提高聚類質量。
[1]李華 ,張宇 ,孫俊華 .基于用戶模糊聚類的協同過濾推薦研究[J].計算機科學,2012,39(12):83-86.
[2]Sarwar BM.Sparsity,scalability,and distribution in recommender system [D].Minneapolis,USA:University of M innesota,2001.
[3]Adomavicius G,Tuzhilin A.Toward the next generation of recommender systems:a survey of the state-of-the-art and possible extensions[J].IEEETranson Knowledgeand Data Engineering,2005,17(6):734-749.
[4]李濤 ,王建東.一種基于用戶聚類的協同過濾推薦算法 [J].系統工程與電子技術,2007,29(7):1178-1182.
[5]黃國言,李有超.基于項目屬性的用戶聚類協同過濾推薦算法[J].計算機工程與設計,2010,31(5):1038-1041.
[6]李德毅 ,劉常昱 .論正態云模型的普適性[J].中國工程科學 ,2004,6(8):28-34.
[7]徐德智,李小慧 .基于云模型的項目評分預測推薦算法[J].計算機工程,2010,36(17):48-50.
[8]Deneubourg J L,Goss S,Frank Net al.The dynamics of collective sorting:robot-like ants and ant-like robots[C]∥Proceedings of the 1st International Conference on Simulation of Adaptive Behavior:From Animals to Animats.Cambridge,MA:MIT Press/Bradford Books,1991:356-363.
[9]Lumer E,Faieta B.Diversity and adaptation in populations of clustering ants[C]∥Proceedings of the 3 rd International Conference on Simulation of Adaptive Behavior:From Animals to Animats.Cambridge,MA:MIT Press/Bradford Books,1994:501-508.
[10]徐曉華,陳崚 .一種自適應的螞蟻聚類算法 [J].軟件學報,2006,17(9):1884-1889.
[11]張蕾 ,曹其新 ,李杰 .一種基于群體智能聚類的設備性能橫向比較算法[J].上海交通大學學報 ,2006,40(3):439-443.
[12]林金爍,葉東毅.基于蟻群聚類算法的優化與改進 [J].計算機系統應用 ,2013,22(12):93-99.
[13]張蕾 ,曹其新,李杰 .一種新型的自適應蟻群聚類算法 [J].上海交通大學學報,2009,43(6):1006-2467.
[14]李克潮 ,藍冬梅 ,凌霄娥 .一種高校讀者借閱偏好的個性化圖書推薦 [J].現代情報,2013,33(8):1008-0821.
(本文責任編輯:孫國雷)
A Collaborative Filtering Recommendation Algorithm Based on Cloud Model and Ants Clustering
Mao Zhiyong Zhao Panpan
(College of Business Administration,Liaoning Project Technology University,Huludao 125105,China)
A new recommendation algorithm based on cloudmodeland antcolonywasdesigned to reduce the sparsity of user rating data,the efficiency and subjectivity of conventional collaborative filtering recommendation.First,usersare clustered by ants clustering,then the user-item ratingmatrix should be filled through cloud model in advance before collaborative filtering,improving the sparsity of user rating data.The experimental results indicate that the recommendation accuracy of this algorithm is largely improved.
collaborative filtering;ants clustering;cloudmodel;book recommendation
毛志勇 (1976-),男,副教授,研究方向:數據挖掘。
10.3969/j.issn.1008-0821.2015.05.015
TP18;TP301.6
A
1008-0821(2015)05-0078-05
2014-12-20
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
商用汽車(2016年11期)2016-12-19 01:20:16
光學精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
核科學與工程(2015年4期)2015-09-26 11:59:03
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
