Hadoop在數(shù)據(jù)挖掘中的應(yīng)用研究*
2015-07-12 17:17:50李校紅張秀芳
新技術(shù)新工藝 2015年4期
關(guān)鍵詞:數(shù)據(jù)挖掘
李校紅,張秀芳
(西安歐亞學(xué)院,陜西 西安710065)
Hadoop在數(shù)據(jù)挖掘中的應(yīng)用研究*
李校紅,張秀芳
(西安歐亞學(xué)院,陜西 西安710065)
隨著互聯(lián)網(wǎng)和計(jì)算機(jī)技術(shù)越來越廣泛的應(yīng)用,數(shù)據(jù)量也在迅速增長,如何在海量數(shù)據(jù)中快速挖掘到有價(jià)值的信息成為數(shù)據(jù)挖掘研究的重點(diǎn)。本文分析了Hadoop云計(jì)算平臺,設(shè)計(jì)了基于Hadoop的數(shù)據(jù)分析系統(tǒng),提出了基于MapReduce的K-均值空間聚類算法。
Hadoop;數(shù)據(jù)分析系統(tǒng);K-均值空間聚類算法
隨著科學(xué)技術(shù)和Hadoop技術(shù)的不斷發(fā)展,數(shù)據(jù)挖掘在大數(shù)據(jù)處理中的作用越來越重要,在企業(yè)數(shù)據(jù)領(lǐng)域起著十分重要的作用[1]。在Hadoop平臺上,通過分布式文件系統(tǒng)(HDFS)實(shí)現(xiàn)超大文件的容錯和存儲,應(yīng)用MapReduce編程模式實(shí)現(xiàn)數(shù)據(jù)的計(jì)算。數(shù)據(jù)挖掘中應(yīng)用Hadoop的關(guān)鍵問題是怎樣實(shí)現(xiàn)傳統(tǒng)數(shù)據(jù)挖掘算法的并行化,通過研究傳統(tǒng)的數(shù)據(jù)挖掘算法并根據(jù)算法的自身特點(diǎn),研究其是否能夠?qū)崿F(xiàn)并行化。如果算法能夠?qū)崿F(xiàn)并行化,根據(jù)MapReduce編程模式,可將這種算法移植到Hadoop平臺上,并行、高效地完成數(shù)據(jù)挖掘任務(wù)[2-3],實(shí)現(xiàn)大量信息的高效處理。
1 Hadoop云計(jì)算平臺
Hadoop是一個應(yīng)用軟件平臺,用來編寫和運(yùn)行處理大規(guī)模數(shù)據(jù)。Hadoop 集群搭建好之后,先通過HDFS將大數(shù)據(jù)安全、穩(wěn)定地存儲分布到集群中的多臺機(jī)器內(nèi),再利用MapReduce模型對數(shù)據(jù)集進(jìn)行處理。和高端服務(wù)器相比,在處理大數(shù)據(jù)時(shí)應(yīng)用集群處理可以降低成本,所以,在數(shù)據(jù)挖掘中應(yīng)用Hadoop將有更加寬廣的發(fā)展前景。
Hadoop的核心設(shè)計(jì)思想是HDFS和MapReduee。存儲式分布式計(jì)算的基礎(chǔ)是存儲,HDFS為分布式計(jì)算存儲提供底層支持,其具有下述基本特點(diǎn):1)集群的命名空間是單一的;2)數(shù)據(jù)具有一致性;3)數(shù)據(jù)具有冗余性。
MapReduce是一個軟件架構(gòu),其主要作用是對大規(guī)模數(shù)據(jù)進(jìn)行并行運(yùn)算。在進(jìn)行數(shù)據(jù)處理時(shí),MapReduce作業(yè)會先把輸入的數(shù)據(jù)分割成數(shù)據(jù)塊,這些數(shù)據(jù)庫相互獨(dú)立,然后以鍵值對形式將這些數(shù)據(jù)塊輸給Map函數(shù)進(jìn)行并行處理,生成中間鍵值對集合,由MapReduce列表庫保存這些集合,并將集合中所有具有相同中間key值的中間value值傳遞給Reduce函數(shù),Reduce函數(shù)接收這些集合,合并value值,產(chǎn)生一個value值集合,最后生成輸出數(shù)據(jù)。
2 基于Hadoop的數(shù)據(jù)分析系統(tǒng)設(shè)計(jì)
具有代表性的數(shù)據(jù)挖掘系統(tǒng)部分模塊需要很大的計(jì)算量,部分模塊不需要較大的計(jì)算量,而基于Hadoop的數(shù)據(jù)分析系統(tǒng),要充分應(yīng)用Hadoop的集群特征,對需要巨大計(jì)算能力的模塊的存儲要求和計(jì)算進(jìn)行擴(kuò)展,擴(kuò)展到Hadoop集群的各個節(jié)點(diǎn)上,然后應(yīng)用集群的存儲和并行計(jì)算能力進(jìn)行相關(guān)數(shù)據(jù)的挖掘。在對系統(tǒng)進(jìn)行設(shè)計(jì)時(shí),采用分層設(shè)計(jì)思想,底層應(yīng)用Hadoop對大數(shù)據(jù)量進(jìn)行存儲、處理和分析,在高層可以通過接口實(shí)現(xiàn)底層存儲和計(jì)算能力的調(diào)用。結(jié)合具有代表性的數(shù)據(jù)模型和上述基本設(shè)計(jì)思想,應(yīng)用分層思想,從上向下,最上層為交互層,每層透明調(diào)用下層接口,交互層實(shí)現(xiàn)系統(tǒng)和用戶之間的交互。從上到下分別為:交互層、業(yè)務(wù)應(yīng)用層、數(shù)據(jù)挖掘平臺層、分布式計(jì)算層,最底層應(yīng)用Hadoop實(shí)現(xiàn)文件的并行計(jì)算和分布式存儲功能。各層之間相互獨(dú)立,互不干擾,可以提高系統(tǒng)的擴(kuò)展性。系統(tǒng)模型如圖1所示。

圖1 基于Hadoop數(shù)據(jù)挖掘系統(tǒng)模型
基于Hadoop的數(shù)據(jù)挖掘系統(tǒng)的流程如下。
1)存儲。在基于Hadoop的數(shù)據(jù)挖掘系統(tǒng)中,文件和數(shù)據(jù)的存儲使用HDFS實(shí)現(xiàn)。HDFS的數(shù)據(jù)吞吐量很高并且容錯機(jī)制能夠很好地實(shí)現(xiàn),能夠提供各種操作命令接口和API接口,應(yīng)用HDFS原始大數(shù)據(jù)的存儲空間更加充足,可存儲臨時(shí)文件,為數(shù)據(jù)預(yù)處理和挖掘過程提供輸入數(shù)據(jù),同時(shí)HDFS中也保存輸出數(shù)據(jù)。
2)計(jì)算。該系統(tǒng)中對數(shù)據(jù)進(jìn)行計(jì)算時(shí)應(yīng)用MapReduce,將數(shù)據(jù)挖掘系統(tǒng)中的計(jì)算任務(wù)發(fā)布到集群中的各個節(jié)點(diǎn)進(jìn)行并行計(jì)算,在計(jì)算時(shí)應(yīng)用函數(shù)。MapReduce的伸縮性和擴(kuò)展性良好,可屏蔽分布式計(jì)算層,通過提供編程接口快速實(shí)現(xiàn)各種算法的并行方式。
3 基于MapReduce的K-均值空間聚類算法
空間聚類分析是聚類分析研究的重要組成部分,其在數(shù)據(jù)處理中的應(yīng)用越來越廣泛。目前,基于MapReduce的K-Means并行化算法及優(yōu)化算法已經(jīng)較為成熟。
由K-Means空間聚類算法的描述可知,其主要計(jì)算新的聚類中心和聚類中心與每個樣本的空間距離。對于樣本和聚類中心空間距離的計(jì)算,可以完全獨(dú)立進(jìn)行操作,實(shí)現(xiàn)并行計(jì)算,但計(jì)算新的聚類中心是部分獨(dú)立操作;因此,可以先對部分聚類信息進(jìn)行計(jì)算后再匯總,這樣前半部分可以應(yīng)用MapReduce框架實(shí)現(xiàn)并行計(jì)算。每次迭代中算法執(zhí)行的操作相同,因此基于MapReduce的K-均值空間聚類算法的實(shí)現(xiàn)只需要在每次迭代中執(zhí)行相同的Map和Reduce操作即可,其中,為了提高M(jìn)apReduce并行計(jì)算模型的數(shù)據(jù)處理效率,需先將數(shù)據(jù)進(jìn)行預(yù)處理,實(shí)現(xiàn)數(shù)據(jù)的按行讀取,快速提取有用信息,這些有用數(shù)據(jù)即為Map函數(shù)的輸入數(shù)據(jù)。
基于 MapReduce的 K-均值空間聚類并行算法主要包括2個處理部分:1)將簇類中心點(diǎn)信息文件初始化,并對數(shù)據(jù)集進(jìn)行分割,使其成為M塊,且大小規(guī)格相同,供并行處理;2)產(chǎn)生聚類結(jié)果,其實(shí)現(xiàn)過程是啟動Map和Reduce任務(wù)對算法進(jìn)行并行化計(jì)算,算法流程圖如圖2所示[4-5]。
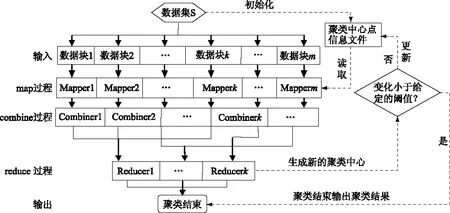
圖2 基于MapReduce的K-均值空間聚類算法并行流程
MapReduce計(jì)算過程每次迭代都要重新啟動,每次計(jì)算過程不止包含1個Map和Reduce任務(wù),每個Map任務(wù)都要對數(shù)據(jù)塊信息和當(dāng)前的聚類中心點(diǎn)信息文件進(jìn)行讀取。Map任務(wù)主要是計(jì)算各數(shù)據(jù)對象到簇類中心點(diǎn)之間的距離,然后根據(jù)距離最近原則將數(shù)據(jù)對象分配到距離最近的簇類中;Reduce任務(wù)是將各個簇類中的對象進(jìn)行匯集,并計(jì)算尋找新的簇類中心點(diǎn),對聚類過程進(jìn)行判斷,決定是否應(yīng)該結(jié)束。這里增加了 Comebine任務(wù),其作用是對各簇類的平均值進(jìn)行分塊計(jì)算,獲得局部結(jié)果,再將其傳輸至Reduce任務(wù),降低節(jié)點(diǎn)間的通信負(fù)荷。
l)Map函數(shù)設(shè)計(jì)。Map函數(shù)的任務(wù)是先從需要處理的文件中提取得到數(shù)據(jù)對象集,文件中每個對象占據(jù)1行,以W

3)根據(jù)Reduce函數(shù)的輸出結(jié)果得到新的聚類中心集合,并在HDFS文件系統(tǒng)中進(jìn)行更新,然后比較本次的聚類中心和上一次執(zhí)行任務(wù)所得聚類中心,如果前后2次聚類中心的變化在預(yù)先設(shè)定的閾值范圍之內(nèi),則結(jié)束算法,停止迭代,輸出最后的聚類結(jié)果;相反,以本次的聚類中心覆蓋原有的聚類中心文件,參與下一次迭代。啟動新一輪的MapReduce Job任務(wù),直到算法滿足收斂條件。
4 結(jié)語
本文對Hadoop平臺的數(shù)據(jù)挖掘進(jìn)行了分析,分析了基于Hadoop的數(shù)據(jù)分析系統(tǒng),基于MapReduce的K-均值空間聚類算法進(jìn)行了并行研究,改進(jìn)該算法后,提高了數(shù)據(jù)挖掘的效率,尤其在當(dāng)今數(shù)據(jù)規(guī)模不斷增大的情況下,將會取得良好的效果,未來要加強(qiáng)空間聚類分析算法的研究,并拓展其實(shí)際應(yīng)用范圍。
[1] 韓隸煒,坎伯.數(shù)據(jù)挖掘概念與技術(shù)[M].北京:機(jī)械工業(yè)出版社,2008.
[2] 朱珠.基于Hadoop的海量數(shù)據(jù)處理模型研究和應(yīng)用[D].北京:北京郵電大學(xué),2008.
[3] 程瑩,張?jiān)朴?徐雷,等.基于Hadoop及關(guān)系型數(shù)據(jù)庫的海量數(shù)據(jù)分析研究[J].電信科學(xué),2010(11):47-50..
[4] 李應(yīng)安. 基于 MapReduce 聚類算法的并行化研究[D].廣州:中山大學(xué),2010.
[5] 郭鵬勃. 參數(shù)設(shè)計(jì)及CAD相似技術(shù)的整合研究[J].新技術(shù)新工藝,2014(9):94-96.
*陜西省科技廳資助項(xiàng)目(2013JM8023)
責(zé)任編輯李思文
AppliedResearchonDataMiningbasedonHadoop
LI Xiaohong, ZHANG Xiufang
(Xi′an Eurasia University,Xi′an 710065, China)
With the usage of Internet and computer technology more widely, the amount of data is growing rapidly, therefore, how to quickly tap into the vast amounts of data in data mining valuable information becomes focus of the researching fields. The paper analyzed the Hadoop cloud computing platform and designed Hadoop-based data analysis system, finally concluded K-means clustering algorithm space based on MapReduce.
Hadoop, data analysis system , K-means clustering algorithm space
TP 311
:A
李校紅(1976-),女,講師,主要從事網(wǎng)絡(luò)通信、嵌入式、大數(shù)據(jù)等方面的研究。
2015-01-12
猜你喜歡
艦船科學(xué)技術(shù)(2022年14期)2022-09-22 03:10:36
大眾投資指南(2021年35期)2021-02-16 01:06:26
中國交通信息化(2020年1期)2020-07-27 02:50:04
電力與能源(2017年6期)2017-05-14 06:19:37
中國中醫(yī)藥信息雜志(2016年7期)2016-12-01 06:07:55
信息通信技術(shù)(2015年6期)2015-12-26 01:16:46
西安工程大學(xué)學(xué)報(bào)(2014年2期)2014-02-28 18:03:05
河南科技(2014年23期)2014-02-27 14:18:43
電子設(shè)計(jì)工程(2014年18期)2014-02-27 12:00:13
電子設(shè)計(jì)工程(2014年18期)2014-02-27 12:00:12
