航天三維可視化系統中語音控制技術的研究與應用
2015-07-09 21:40:50朱俊等
現代電子技術 2015年8期
朱俊等
摘 要: 語音控制技術作為一種有效的自動化控制方法在航天領域有著廣闊的應用前景。基于Kinect設備,將語音控制技術運用于航天三維可視化系統的智能控制,通過語音指令采集、預處理、語音識別和三維可視化界面控制,實現了一套完整的航天三維可視化系統的語音控制方案。測試結果表明,該語音控制方案能有效識別用戶的語音命令,并完成對三維可視化界面的控制。
關鍵詞: 語音控制; 語音識別; 航天三維可視化; Kinect
中圖分類號: TN912?34 文獻標識碼: A 文章編號: 1004?373X(2015)08?0151?03
三維可視化展示在航天領域有著極其重要的地位,指揮顯示系統需要通過三維可視化展示向各級指揮員直觀地顯示航天器發射的過程。在實際應用中,傳統的可視化控制方式是指揮員向可視化操作人員下達指令,然后由操作人員完成三維可視化系統的操作,包括視角的切換、推遠、拉近以及關鍵動作的控制等。這種控制模式在很大程度上限制了指揮員對于三維可視化系統的自由控制,并且加重了三維可視化操作人員的工作負擔。同時,傳統控制模式不能實現遠距離控制,指揮員的位置與三維可視化操控臺要控制在一定的距離內。而語音識別技術能夠很好地解決這些問題,通過語音識別技術,指揮員可直接向三維可視化服務器下達口令,無需通過操作人員進行控制,并能解除指揮員與操控臺距離的限制。
語音識別技術是通過識別說話者聲音標識而正確判斷出聲音所傳遞的信息,以方便實現相關處理和控制[1]。近年來該技術在軍事、工業、家電、通信、醫療[2]等諸多領域得到廣泛應用,如電燈等家用電器的控制,通過語音識別可以實現設備的控制自動化等[3]。張建等人將語音識別技術應用到雷達模擬系統中,通過設置語音服務器將內話通信系統與語音識別相結合,運用語音命令輸入進行模擬控制,降低了模擬機長的工作負擔,提高了工作效率[4]。孫愛中等人對基于DSP的語音識別系統進行了研究,實現了在移動電子設備上的漢字語音輸入[5]。另外,語音識別技術在機器人控制[6]、機器狗控制系統模型[7] 方面也有應用。隨著航空航天領域的發展,語音識別在機載語音控制方面也有相關研究[8]。
本文基于語音識別技術設計了一套航天可視化界面控制系統,通過識別三維可視化常用控制命令,實現指揮員對顯示頁面的直接語音控制,突破傳統指揮控制模式的局限性。
1 系統結構
為實現通過語音技術對三維可視化頁面完成視角切換、場景放縮等語音控制功能,設計了如下步驟:第一步通過語音采集設備獲取指令;第二步運用語音識別系統對獲取的指令進行識別;第三步將識別出的指令傳遞給三維可視化服務器并觸發相應控制動作。
1.1 硬件結構
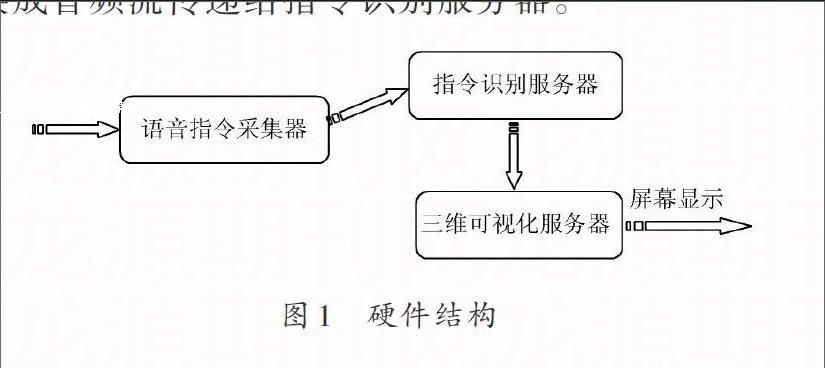
硬件設備主要包括三個部分(如圖1所示):語音指令采集器、指令識別服務器和三維可視化系統服務器。語音指令采集器主要用于捕獲語音指令,并將語音指令轉換成音頻流傳遞給指令識別服務器。
由于Kinect[9]在語音采集和識別方面有很多優良的特性和廣泛的應用,這里選擇了Kinect作為語音指令采集器。指令識別服務器的主要功能是對Kinect傳入的音頻進行預處理和語音指令的識別,并將識別出的控制指令發送給三維可視化系統服務器。預處理包括背景噪音去除、回音去除、自動增益控制等內容。由于語音控制指令相對簡單,并且指令識別服務器只需要對幾條固定的指令進行正確識別,所以對于計算機硬件要求不高。因此,采用一臺普通的聯想辦公電腦作為指令識別服務器。三維可視化系統服務器要完成航天發射過程中各器件的三維模型和狀態的展示,并響應從指令識別服務器獲取的指令,完成三維可視化頁面的操作和控制。由于三維可視化系統服務器在顯示各航天器件的三維可視化模型和圖像時計算資源開銷比較大,所以采用了配置較高的聯想工作站(ThinkStation D30)作為三維可視化系統服務器。
1.2 軟件模塊
系統軟件模塊主要包括語音預處理、語音指令識別、三維可視化界面控制三個模塊。
(1) 語音預處理。從語音指令采集器獲取的原始音頻數據質量較低,需要通過一系列算法處理來提高音頻數據質量,主要處理包括回聲消除(Acoustic Echo Cancellation,AEC)、自動增益控制(Acoustic Gain Control,AGS)和噪聲抑制(Noise Suppression,NS)。回聲消除(AEC)通過提取發聲者的聲音模式,然后根據這一模式從麥克風接收到的音頻中挑選出特定的音頻來消除回聲。自動增益控制(AGS)用于調整發生者聲音振幅與時間保持一致。例如當發聲者靠近或者遠離麥克風時,聲音會出現變得響亮或更柔和,自動增益控制就是將這種變化效果進一步增強。噪聲抑制(NS)用于從麥克風接收到的音頻信號中剔除非語言聲音。通過刪除背景噪音,使講話者的聲音能夠被麥克風更清楚更明確地捕獲到。
(2) 語音指令識別。語音識別可分為兩類:對自由形式的語音識別(Recognition of Free?form Dictation)和對特定命令的識別(Recognition of Command)。自由形式的語音識別需要訓練軟件來識別特定的聲音以提高識別精度,通常讓講話人朗讀一段文字使得軟件能夠識別講話人聲音的特征模式,然后根據這一特征模式來進行識別。而特定命令的識別限制了說話人所講詞匯的范圍,基于這一詞匯范圍,識別軟件不需要熟悉講話人語音模式就可以識別出講話人所說的內容。針對本文的應用,語音識別引擎只需要識別幾種特定的語音指令,因此屬于對特定命令的識別。在實際應用中,向語音識別引擎中添加了6種三維可視化界面控制常用的語音命令,包括“打開”、“點火”、“重置”、“推遠”、“拉近”、“切換”。語音識別引擎對上述6種指令進行識別,并向三維可視化界面控制模塊發送控制信號。
(3) 三維可視化界面控制。三維可視化界面控制模塊能夠接受語音指令識別模塊發送的6種語音指令,并觸發每個指令所對應的事件,調用一些控制三維可視化界面的函數,實現對三維可視化界面的控制。例如,當接受到“打開”命令信號時,三維可視化界面控制模塊觸發“打開”所對應的事件,可視化界面會開始展示發射塔架抱臂打開的三維動畫。
2 基于Kinect的語音控制系統
Kinect被譽為和鼠標一樣偉大的人機交互方式,其提供的動作識別、手勢識別和語音識別功能在醫療、教育、科研以及娛樂等多個領域都有令人驚嘆的應用。針對航天三維可視化系統的語音控制這一實際需求,采用Kinect提供的強大語音識別功能來實現對航天三維可視化界面的智能控制。
Kinect配備有麥克風陣列用于采集用戶的語音音頻數據,其麥克風陣列包含4個相互獨立的朝向下方的小型麥克風,能夠捕捉多聲道立體聲音。值得一提的是,微軟認為最佳的聲音收集方向應該是朝下的。因此,Kinect設計了朝下的麥克風陣列用于盡可能地獲取優質聲音信號以及判斷不同方向的聲源。與普通單麥克風采集的數據相比,Kinect陣列技術包含了噪聲抑制(NS)、回聲消除(AEC)以及自動增益控制(AGS)等多種預處理,盡可能避免了環境噪聲的影響,大大提高了采集的語音數據質量。正是因為Kinect在高質量地采集用戶語音數據方面展現出來的優良性能,才促使在實際采集用戶語音命令時選擇Kinect作為語音采集設備。
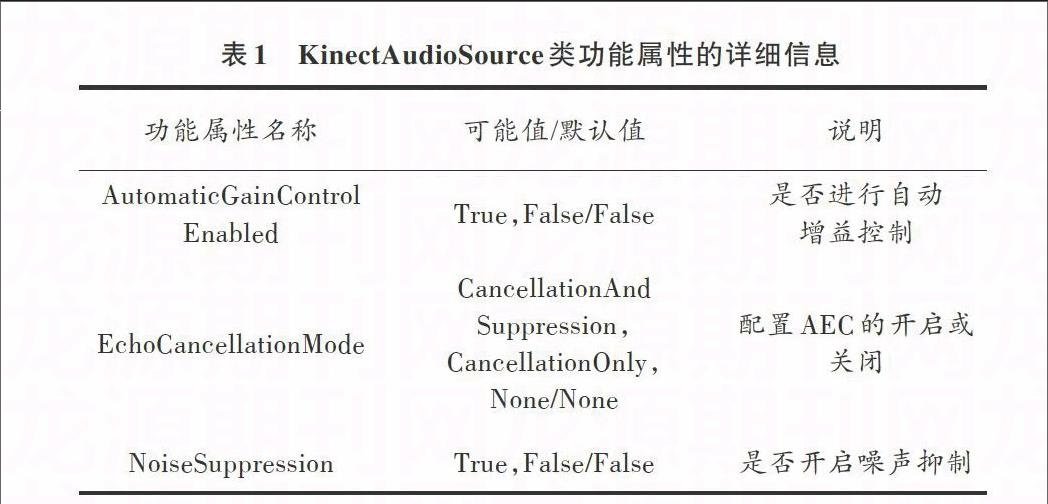
為了方便開發人員基于Kinect進行開發,微軟提供的Kinect SDK允許開發者借助Visual Studio,利用C++或C#等語言進行相關應用的開發[10]。針對本文涉及的語音指令識別應用,主要用到Kinect SDK中封裝的KinectAudioSource和SpeechRecognitionEngine兩個類。通過設置KinectAudioSource對象提供的功能屬性NoiseSuppression、EchoCancellationMode和AutomaticGainControlEnabled的屬性值,就可以很方便地
實現語音原始數據的預處理,具體屬性值如表1所示。SpeechRecognitionEngine是基于Microsoft.Speech類庫實現的語音命令識別,它可以分析和解譯預處理后的音頻數據流,然后匹配出最合適的語音命令。語音識別引擎會對音頻數據流中的特定單元設定一定的可信度權重,并有選擇地過濾不包含特定待識別命令的音頻數據流。待識別命令集可以通過GrammarBuilder類進行建立和添加。在本文中,通過GrammarBuilder類添加了包含“打開”、“點火”、“重置”、“推遠”、“拉近”、“切換”6種語音命令的待識別命令集,SpeechRecognitionEngine會查找和識別這6種語音指令,并向三維可視化界面控制模塊發送相應控制信號。另外,Kinect SDK不支持中文語音識別,添加了微軟中文語音識別功能,實現了基于Kinect中文語音指令識別。
3 實驗結果與分析
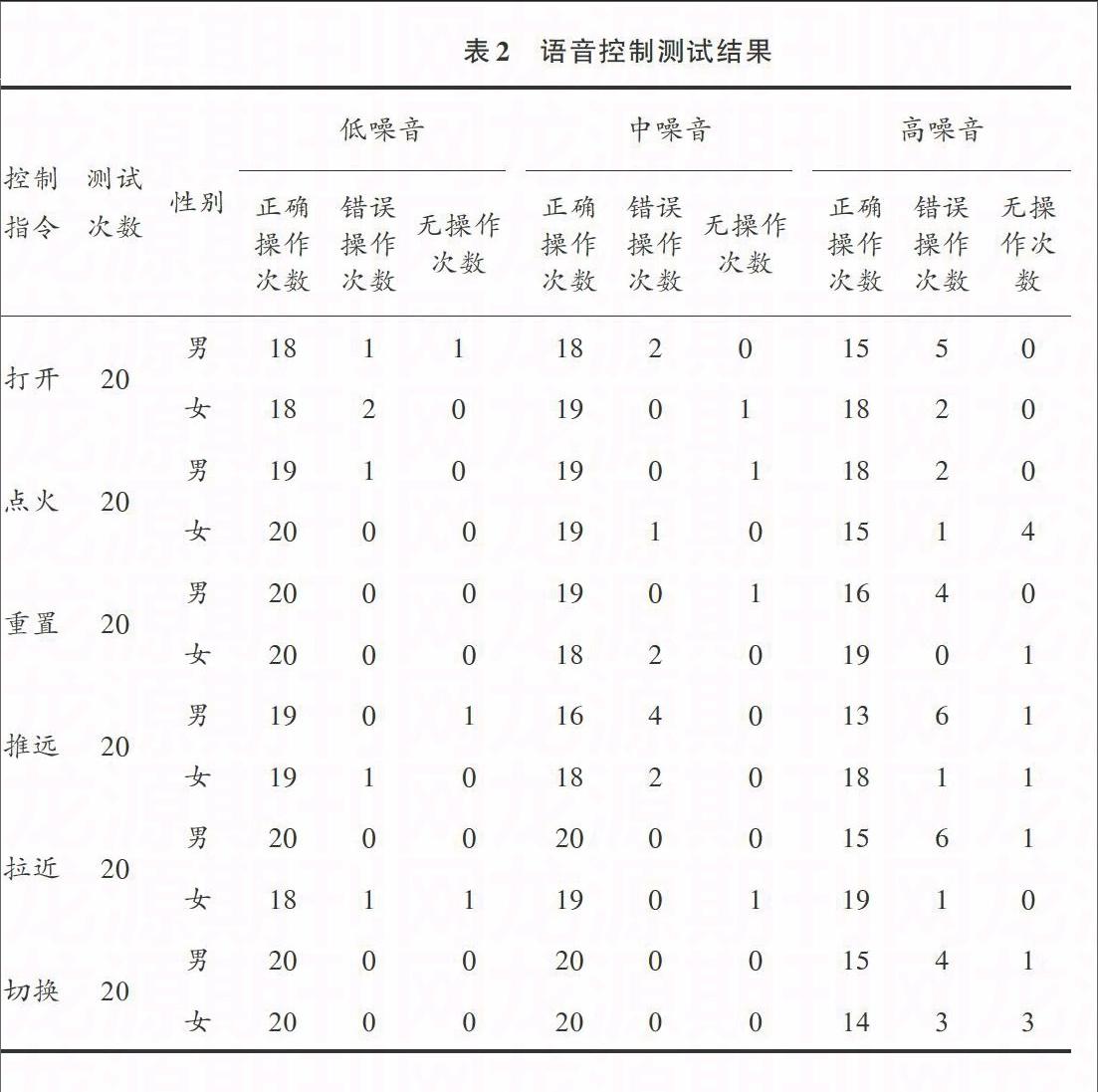
為了檢驗本文設計的語音控制系統在航天三維可視化界面控制中的效果,選取了男女各一名,在不同噪聲背景下,向語音指令采集設備發出6種語音命令20次,以測試是否正確控制界面。考慮到實際應用中,指揮員在下達控制口令時環境中可能存在不同程度的背景噪聲,因此,在測試時設置三種不同強度的背景噪音,以檢測本語音控制系統的抗噪能力。三種背景噪聲非別設定為低噪音(20~40 dB)、中噪音(40~60 dB)、高噪音(60~80 dB)。詳細測試結果見表2。
表1 KinectAudioSource類功能屬性的詳細信息
通過表2的測試統計數據可以看出,在各種不同條件下,運用語音識別技術對航天三維可視化系統進行控制均能夠達到較高的正確率,能夠滿足航天領域的實際需求。其中,在低噪音下的控制正確率能達到90%以上,隨著環境噪音增強,界面控制的正確率有所下降,這和最初的估計一致。考慮到實際發射時,現場環境的噪聲不會太高,因此本語音控制系統的抗噪能力可以達到實際應用的要求。
4 結 語
本文研究了語音控制技術在航天三維可視化系統中的應用,并基于Kinect的語音處理和識別系統具體實現了對航天三維可視化界面的語音控制,取得了初步研究成果。目前,只實現了6種最常用的三維可視化界面語音控制,但隨著航天三維可視化技術的發展,必然對三維可視化界面控制提出更高的要求,屆時將進一步豐富和完善本文實現的語音控制系統。另外,隨著語音控制技術進一步發展,將深入發掘該技術在航天領域的其他應用潛力。
參考文獻
[1] SHANNON R V, ZENG F G, KAMATH V, et al. Speech recognition with primarily temporal cues [J]. Science, 1995, 270(5234): 303?304.
[2] HAWLEY M S, ENDERBY P, GREEN P, et al. A speech?controlled environmental control system for people with severe dysarthria [J]. Medical Engineering & Physics, 2007, 29(5): 586?593.
[3] 徐子豪,張騰飛.基于語音識別和無線傳感網絡的智能家居系統設計[J].計算機測量與控制,2012,20(1):180?183.
[4] 張健,譚景信.語音命令識別技術及其在雷達模擬機中的應用技術及其在雷達模擬[J].計算機工程與設計,2010,31(3): 655?659.
[5] 孫愛中,劉冰,張琬珍,等.基于DSP的語音識別系統研究與實現[J].現代電子技術,2013,36(9):76?78.
[6] ROGALLA O, EHRENMANN M, ZOLLNER R, et al. Using gesture and speech control for commanding a robot assistant [C]// Proceedings of 2002 11th IEEE International Workshop on Robot and Human Interactive Communication. [S.l.]: IEEE, 2002: 454?459.
[7] 閔華松,劉冬.王田苗智能機器狗的語音控制模型研究[J].計算機工程,2012,38(1):188?191.
[8] 須明,王博,王凱.駕駛艙語音控制指令的設計問題討論[J].航空電子技術,2012,43(3):39?43.
[9] 余濤.Kinect應用開發實戰:用最自然的方式與機器對話[M].北京:機械工業出版社,2012.
