科技計劃與戰略性新興產業相關性研究與實現
2015-06-27 05:08:45李光文
天津科技 2015年12期
李光文
(天津市科技統計與發展研究中心 天津300051)
科技計劃與戰略性新興產業相關性研究與實現
李光文
(天津市科技統計與發展研究中心 天津300051)
科技計劃以支撐引領經濟社會發展為目標,戰略性新興產業是未來經濟持續增長的先導產業。為研究科技計劃項目與戰略性新興產業之間的相關性,將戰略性新興產業行業分類進行關鍵詞拆分,使用關鍵詞在科技計劃項目研究內容中進行搜索,對搜索結果利用空間向量模型建立一套分析模型,計算出科技計劃與戰略性新興產業相關性系數,并對相關性系數進行分析。此外,利用天津市科技支撐計劃項目數據對分析模型、分析方法進行了試算,試算結果顯示兩者相關性程度較高。
空間向量模型 科技計劃 相關性
0 引 言
戰略性新興產業是一個國家或地區實現未來經濟持續增長的先導產業,對國民經濟發展和產業結構轉換具有決定性的促進、導向作用,具有廣闊的市場前景和引導科技進步的能力,關系到國家的經濟命脈和產業安全。[1]戰略性新興產業具有技術新、市場前景好、資源消耗低、綜合效益強等特點。我國的戰略性新興產業是在2009年召開的新興戰略性產業發展座談會上提出來的,包括新能源、節能環保、電動汽車、新材料、新醫藥、生物育種和信息產業。
天津市以科學發展觀為指導,不斷提升自主創新能力,為更好地發揮科學技術對經濟社會的支撐和引領作用,制定了天津市科技發展“十二五”規劃,其主要目標是“加快提高優勢產業和戰略性新興產業的技術自給能力和核心競爭力,提升科技對發展方式轉變的支撐能力,率先建成水平更高、帶動作用更強的創新型城市,成為我國自主創新高地、高水平研發轉化基地、北方產業創新中心”。從規劃可以看出,天津市把戰略性新興產業作為科技發展的重要任務。科技規劃的落實主要體現在科技計劃項目的實施上,“十二五”期間天津市科技計劃項目與戰略性新興產業發展的相關性如何,是本文的研究重點。本文通過數據挖掘技術和搜索引擎技術,將戰略性新興產業包括的行業分類進行關鍵詞拆分,利用關鍵詞在科技計劃項目主要研究內容中進行搜索,進行相關性分析,嘗試建立兩者的相關性。
1 分析技術與工具
1.1 向量空間模型(見圖1)
向量空間模型(Vector Space Model)是由Salton等人在20 世紀70年代提出,用向量空間模型進行特征表達,用TFIDF (Term-Frequency Inverse-Document-Frequency)進行特征項賦權,TF-IDF認為如果某個詞或短語在一篇文章中出現的頻率TF高,并且在其他文章中很少出現,就認為該詞或短語具有很好的區分能力,適合用來分類。向量空間模型用倒排文檔進行索引,用余弦夾角進行距離度量,用查全率和查準率評價檢索系統性能。向量空間模型已成為信息檢索領域的研究基礎。向量空間模型是在文本中提取其特征項構成特征向量,并以某種方式為特征項賦權,可以理解為在忽略特征項之間的相關信息后,一個文本用一個特征向量來表示,一個文本集表示成一個矩陣,也就是特征項空間中的一些點的集合。
1.2 向量空間模型使用關鍵
向量空間模型在使用過程中,需要重點解決特征項的選擇和特征項賦權。中文文檔是由漢字和標點符號等基本的語言符號組成的字符串,由字構成詞,由詞構成短語,進而形成句、段、節、章、篇等語言結構。中文文檔的特征項可以是字、詞、短語,甚至是句子或句群等。特征項的選擇需要考慮處理速度、精度、存儲空間等,遵循包含語義信息較多、文檔在特征項上的分布具有統計規律性、容易實現等要求。特征項賦權一般由頻率因子、文檔集因子和規格化因子3部分組成。頻率因子指特征項在文檔中出現的頻率,頻繁出現的特征項具有較高權重。文檔集因子是與文檔集合有關的因子,加大文檔之間的區分度。規格化因子是為了解決文檔長度對匹配結果的影響。
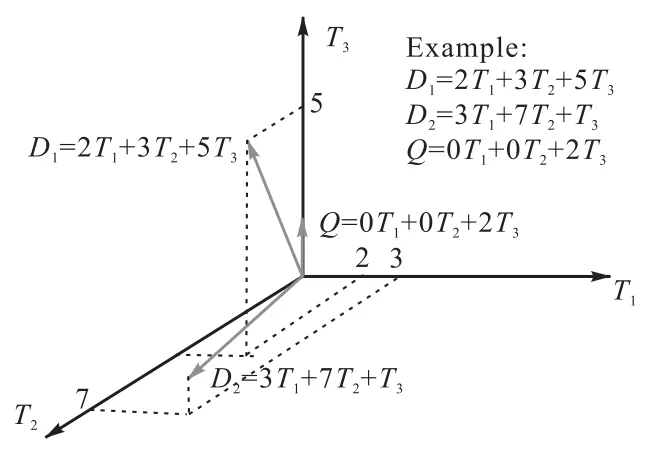
圖1 向量空間模型Fig.1 The vector space model
1.3 向量空間模型應用
向量空間模型的重要應用是兩個文檔D1和D2之間相似度Sim(D1,D2)研究,當文檔D1、D2被表示為空間向量時,就可以計算向量之間的距離來表示文檔間的相似度,常用的距離計算有余弦距離公式:
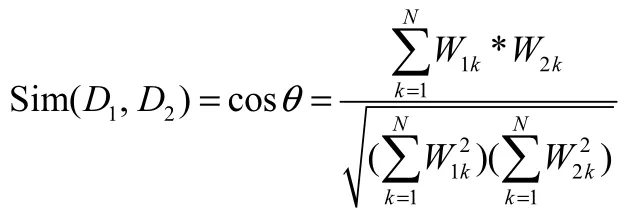
1.4 中文分詞技術
英文以詞為單位,詞和詞之間使用空格隔開,而中文是以字為單位,句子中所有的字連起來才能描述一個意思。例如,英文句子“I am a student”,用中文表達為“我是一個學生”。計算機程序可以很容易通過空格知道student是一個單詞,但是不能很容易明白兩個字合起來才表示一個詞。把中文的漢字序列切分成有意義的詞,就是中文分詞。中文分詞技術主要用于搜索引擎,用于對用戶提交的查詢關鍵詞進行處理再搜索。中文分詞技術主要有字符串匹配分詞法、詞義分詞法、統計分詞法。
1.5 Lucene搜索引擎
Lucene是Apache軟件基金會的一個子項目,它不是一個完整的全文檢索引擎,而是一個全文檢索引擎的架構,提供了完整的查詢引擎和索引引擎以及部分文本分析引擎。Lucene為軟件開發人員提供了一個簡單易用的工具包,以便于在目標系統中實現全文檢索的功能,或者是以此為基礎建立起完整的全文檢索引擎。
2 分析方法
本文對空間向量模型進行了微調,引入分詞技術、搜索引擎技術定義了分析模型(見圖2),實現科技計劃與戰略性新興產業相關性研究。
①按照國家統計局制定的《戰略性新興產業分類》(試行),將《國務院關于加快培育和發展戰略性新興產業的決定》中包括的節能環保產業、新一代信息技術產業、生物產業、高端裝備制造產業、新能源產業、新材料產業、新能源汽車產業等7個戰略性新興產業,與《國民經濟行業分類》中的行業類別建立對應關系,實現了戰略性新興產業與行業分類相結合。共包括《國民經濟行業分類》中的行業類別359個,戰略性新興產業產品及服務2410項,作為戰略性新興產業的特征項。
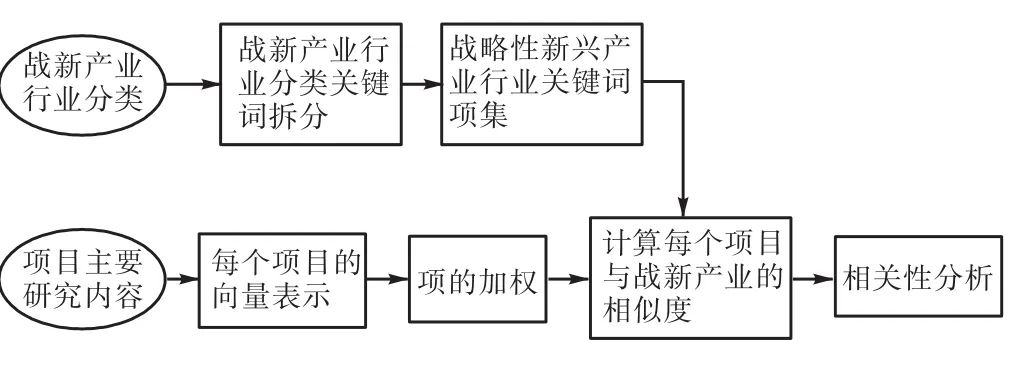
圖2 分析模型Fig.2 Analysis model
②使用庖丁解牛分詞技術編寫程序,分別對七大戰略性新興產業對應的國民經濟行業分類進行關鍵詞拆分。再對關鍵詞進行整理,包括:去掉每個產業中重復關鍵詞;去掉一個字的關鍵詞,如“大”、“新”等;通過主觀判斷去掉異常關鍵詞,如“和氣”、“水的”、“其他”等;去掉部分常用動詞,如“發展”、“設計”、“利用”等。形成7個戰略性新興產業關鍵詞項集Zn,n=7。7大戰略性新興產業規格化因子如表1所示。

表1 七大戰略性新興產業規格化因子Tab.1 Normalizing factor of seven strategic industries
③將科技計劃項目主要研究內容作為科技計劃特征項。使用Java語言,引入Lucene架構編寫搜索引擎程序,利用每個戰略性新興產業的關鍵詞項集,到每個科技計劃項目中進行搜索,搜索出每個科技計劃項目中出現的關鍵詞,以及每個的關鍵詞出現的次數,表示成X(t1,t2,…,tN)。計算出戰略性新興產業關鍵詞項集與科技計劃特征項之間向量余弦距離,作為其相關性系數。本文主要是研究向量相關性的相對大小,為了簡化計算難度,忽略未在某個科技計劃特征項中出現的戰略性新興產業關鍵詞。將余弦距離計算公式變換為:
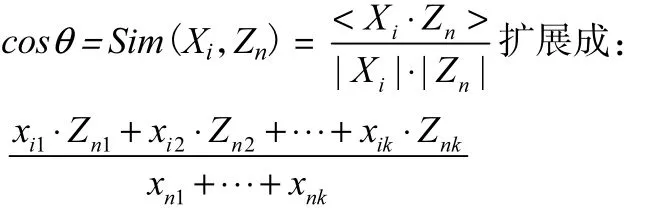
為消除每個產業關鍵詞數量的差異導致的比較誤差,設立規格化因子,w表示某個產業關鍵詞項集的數量。每個項目內容與每個產業的相關性系數結果除以規格化因子作為最后相關性結果,對相關性系統進行分析。
3 研究結果
3.1 試算數據
天津市科技計劃根據所支持項目研發處階段設立了不同的科技計劃類別,在天津市科技計劃體系中,科技支撐計劃定義為“為天津市產業升級和結構調整、社會可持續發展和提高人民生活質量提供技術支撐”,與產業發展最為緊密。本文選用“十二五”期間天津市科委支持的科技支撐計劃項目作為試算數據。
3.2 試算結果
利用分析模型進行試算,試算結果顯示,天津市科技支撐計劃項目與戰略性新興產業相關性程度較高,不包含戰略性信息產業關鍵詞的項目僅占2.5%,含1個關鍵詞的項目占9.8%,含2個關鍵詞的項目占13.9%,含3個及以上關鍵詞的項目占73.8%(見圖3)。
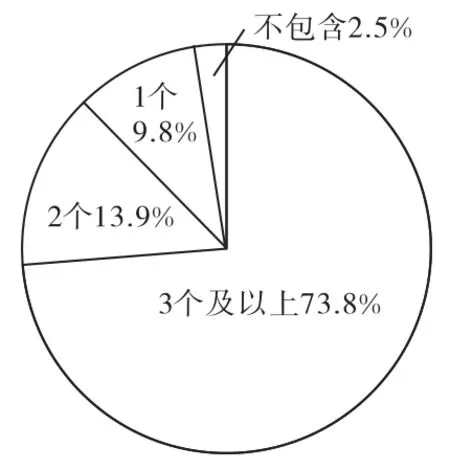
圖3 項目含關鍵詞數量比例Fig.3 Project keyword ratios
如果設定含有3個及以上關鍵詞的項目與戰略性新興產業相關,說明天津市科技支撐計劃項目與戰略性新興產業的相關性程度高。

圖4 項目含關鍵詞數量統計(單位:項)Fig.4 Statistics of project keyword numbers(Unit:per unit)
取含有3個及以上關鍵詞的項目相關性系數作為有效觀測數,共9544項(見圖4),對有效觀測數進行描述性匯總統計,相關性系數的最大值為4.111,最小值為1.007,中位數為1.671,眾數為1.633。
根據項目立項年度對相關性結果進行分析,分析結果顯示,天津市科技支撐計劃項目與戰略性新興產業相關性逐年增大,呈上升趨勢,如圖5。
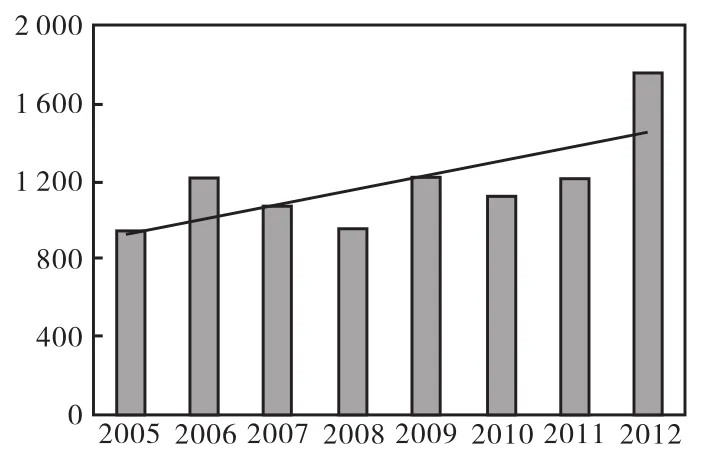
圖5 相關性按年度統計Fig.5 Correlation between annual statistics
根據對七大戰略性新興產業分類,對相關性結果進行分析,結果顯示天津市科技支撐計劃項目與新一代信息技術相關性最高,與新能源汽車相關性最低,相關性程度依次為:新一代信息技術、高端裝備制造、生物產業、節能環保、新能源、新材料、新能源汽車。說明天津市科技支撐計劃對信息技術、裝備制造、生物產業項目支持相對較多,而對新能源汽車項目支持相對較少。
4 存在不足
分析模型中為消除由于關鍵詞數量不同導致的搜索結果偏差,設定了規格化因子,規格化因子的計算方式引自論文,其合理性需要進一步研究。本文在研究過程中,為了簡化搜索過程,使用了約2000字的科技計劃項目簡要說明作為搜索內容,搜索內容偏少,下一步將研究實現對科技計劃項目申請書進行全文搜索,增強相關性結果的科學性。分析模型完善后,可以應用到科技計劃項目研究內容查重,項目評審回避專家等工作中,提高科技計劃項目管理的科學性與公正性。
[1] 朱瑞博. 中國戰略性新興產業培育及其政策取向[J].改革,2010(3):19-28.
[2] 陳治綱,何丕廉,孫越恒,等. 基于向量空間模型的文本分類方法的研究與實現[J]. 計算機應用,2004(6):277-279.
[3] 楊小平,丁浩,黃都培. 基于向量空間模型的中文信息檢索技術研究[J]. 計算機工程與應用,2003(15):109-111.
[4] Lucene 4. 0原理與代碼分析–相似度評分算法之向量空間模型(VSM)[OB/EL]. http://so.searchtech. pro/articles/2013/05/22/1369204044879. html.
[5] 殷偉. 財務文檔分詞及文檔相關性分析[J]. 電腦知識與技術,2013,9(7):1718-1719,1722.
[6] 龐劍鋒,卜東波,白碩. 基于向量空間模型的文本自動分類系統的研究與實現[J]. 計算機應用研究,2001(9):23-26.
A Correlation Study of Science and Technology Plans and New Strategic Industries
LI Guangwen
(Tianjin Science and Technology Statistic Center,Tianjin 300051,China)
As science and technology plans take the goal of supporting and leading economic and social development and new strategic industries will become the leading industry in the future economic growth this paper studies the relationship between the S&T plan projects and new strategic industries. By dividing categories of new strategic industries into key words it carries out key words searching in the study content of the S&T Plan projects. The search results were modeled with the help of space vector model to calculate the correlation coefficients of the projects and the industries and then analyze them. In addition the data of Tianjin Science and Technology Support Program were used to analyze the model and the method. Test results show that the two have strong relevance.
vector space model;science and technology plan;implementation
G312
:A
:1006-8945(2015)12-0052-03
2015-11-08
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
學苑創造·B版(2021年2期)2021-03-15 05:50:49
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
少兒科學周刊·兒童版(2017年9期)2018-03-15 15:00:11
兒童故事畫報·發現號趣味百科(2017年4期)2017-06-30 12:41:53
光學精密工程(2016年6期)2016-11-07 09:07:19
兒童故事畫報·發現號趣味百科(2016年6期)2016-08-19 06:35:19
兒童故事畫報·發現號趣味百科(2015年10期)2016-01-20 00:47:36
核科學與工程(2015年4期)2015-09-26 11:59:03
