一種改進的商品評價情感極性分析算法
2015-06-23 13:52:01邵其武繆裕青謝益均蔡國永
桂林電子科技大學學報 2015年2期
邵其武,繆裕青,2,謝益均,高 韓,蔡國永,2
(1.桂林電子科技大學計算機科學與工程學院,廣西桂林 541004; 2.桂林電子科技大學廣西可信軟件重點實驗室,廣西桂林 541004)
一種改進的商品評價情感極性分析算法
邵其武1,繆裕青1,2,謝益均1,高 韓1,蔡國永1,2
(1.桂林電子科技大學計算機科學與工程學院,廣西桂林 541004; 2.桂林電子科技大學廣西可信軟件重點實驗室,廣西桂林 541004)
針對商品評價信息的褒貶分析問題,提出PMI_HRV算法。算法在基于語料庫的PMI算法基礎上,采用最新的基于知網詞典算法,解決基于語料庫算法中低頻詞準確率差的問題;建立評價領域詞語相關的基準詞表,并增加否定屬性表和網絡用語表以擴充知網詞典,使結果更為準確。實驗結果表明,PMI_HRV算法具有較高的準確率和召回率。
情感分析;商品評價;點互信息;知網詞典;基準詞表
情感分析(sentiment analysis)又稱評論挖掘或意見挖掘,是數據挖掘和計算機語言學相結合的一種對網上各種內容進行分析(包括提取、分析、處理、推理等)的技術[1]。情感分析的一個重要應用是對網絡上大量的產品評論進行挖掘和分析,計算情感褒貶傾向性,進而發現產品優缺點,為用戶決策提供支持[2]。
目前,計算情感褒貶傾向性主要有2類方法:1)基于大規模語料庫,通過統計詞的概率分布來計算[3];2)基于某種世界知識,一般是語義詞典,通過詞典層次結構關系來計算[4]。前一類方法結果比較準確,人為影響小,但計算復雜、計算量大,而且與語料庫的規模和領域關系比較大;后一類方法簡單有效,計算量小,但結果依賴人工建立的詞典,受人主觀因素的影響比較大,并不一定能客觀地反映事實。
鑒于此,提出一種改進的評價詞情感極性計算方法PMI_HRV(point mutual information and hownet and reference vocabulary)算法。該方法在點互信息方法基礎上,采用最新的基于知網詞典算法,解決基于語料庫算法中低頻詞準確率低的問題。在計算2個詞的相似度時,不僅考慮2個詞的距離,還考慮2個詞的位置信息,從而使相似度計算的結果更為準確;建立結合評價領域詞語的基準詞表,分別從待評價語料和人民日報語料中選擇基準詞,組成基準詞表,并增加否定屬性表和網絡用語表來擴充知網詞典。
1 相關研究
1.1 基于語料庫的詞語情感極性計算方法
語料庫是一種電子文本庫,通常已經過科學取樣和加工,借助一些分析工具(如計算機),可開展相關的語言理論以及應用研究。
《人民日報》標注語料庫是北京大學計算語言學研究所和富士通研究開發中心共同制作的標注語料庫,是我國第一個大型現代漢語標注語料庫[5]。語料庫中每個詞語的詞性均有明確的標記,目前共有40多個標記。語料庫涵蓋范圍廣,涉及領域多,是當前最常用語料庫之一,也是本研究所采用的語料庫。
基于語料庫的方法主要是點互信息(point mutual information,簡稱PMI)方法[3],通過大規模語料庫中詞語的統計信息進行情感傾向計算。首先,選取一些基準詞,其中有褒義詞也有貶義詞,計算待求詞與所有基準詞基于語料庫的點互信息值,然后計算待求詞褒貶傾向。PMI計算公式為:
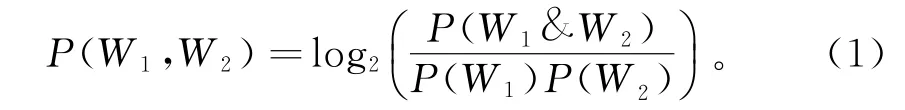
其中:P(W1)為詞W1在語料庫中獨立出現的概率; P(W2)為詞W2在語料庫中獨立出現的概率; P(W1&W2)為詞W1和W2在語料庫中同時出現的概率,一般指θPMI個詞距內W1和W2共同出現的概率。例如,W1在語料庫中出現了n次,則P(W1)=n,同理,W2在語料庫中出現了m次,則P(W2)=m,θPMI=p,則P(W1&W2)指在距離為p的范圍內,W1和W2同時出現的次數,由此可得PMI值。由式(1)可知,PMI值與語料庫和基準詞有關。
假定褒義基準詞集Swordset1={C1,C2,…,Cn},貶義基準詞集Swordset2={D1,D2,…,Dn},則對于待求詞W,基于PMI的情感極性SSO_PMI(W)計算公式為:

即所有褒義詞與待求詞的PMI值之和減去所有貶義詞與待求詞的PMI值之和,歸一化后使結果為[-1, 1]。若結果大于0,則待求詞為褒義詞,情感極性強弱由結果大小表示,結果越大,則褒義越強;若結果小于0,則待求詞為貶義詞,情感極性強弱由結果大小表示,結果越小,則貶義越強。
通過分析可知,基于語料庫的PMI方法人工干預較少,當待求詞在語料庫中出現概率較大時,能夠比較真實地反映詞語褒貶傾向。然而,該法的計算過程復雜,計算結果嚴重依賴語料庫,若某個詞情感極性強,但在語料庫中出現次數很少甚至為0,則計算結果值很小,不能完全體現真實情況。另外,基準詞的選取對最終結果影響很大。
1.2 基于詞典的詞語情感極性計算方法
《知網》是由著名機器翻譯家董振東先生發起和創建的一個常識知識庫,用來描述漢語和英語詞語所代表的概念[6]。“概念”與“義原”是知網中最重要的2個概念。每個詞語可表示為一個或多個“概念”,每個“概念”可表示為一個或多個“義原”。“義原”是知網中最小的有意義的單位,共有約1500個義原。義原之間存在復雜的關系,《知網》描述了義原之間的8種關系,其中最重要的是上下位關系。根據上下位關系,所有義原組成一個義原層次結構,它是一個樹狀結構,是語義相似度計算的基礎。詞語、概念、義原關系如圖1所示,義原層次結構如圖2所示。

圖1 知網詞典中詞語、概念、義原間的關系Fig.1 The relationship of words,concepts and sememes in Hownet

圖2 樹狀的義原層次結構Fig.2 Sememes hierarchy tree
基于詞典的方法是基于知網詞典進行相似度計算[4-8]。首先,選取一些基準詞,其中有褒義也有貶義,計算待求詞與所有基準詞基于知網的相似度,然后計算待求詞褒貶傾向。
假如一個詞語有m個概念,另一個詞語有n個概念,那么就有m×n種組合,計算每對概念的相似度,取最大者作為詞語間相似度。這樣,2個詞語的相似度就歸結為2個概念的相似度。實詞概念和虛詞概念之間相似度為0。實詞概念的語義表達式分為4部分:1)第一獨立義原描述式,其相似度記為s1; 2)其他獨立義原描述式,其相似度記為s2;3)關系義原描述式,其相似度記為s3;4)符號義原描述式,其相似度記為s4。總的相似度為4部分加權和,

其中βi為參數,指si在最終s中所占比例,β1+β2+β3 +β4=1。
第一獨立義原更能反映詞語的主要特征,對次要部分相似度值起制約作用,即若SSIM1比較小,SSIM2比較大,則最終結果不能真實反映2個詞語相似度情況[4]。因此,對式(3)進行修改,得到新的相似度計算公式:

義原相似度計算公式[7]:

其中:S1、S2為2個義原;α為可調節參數;d為2個義原在義原樹上的距離。
2個義原的相似度不能僅考慮2個義原的距離,還應考慮其他因素,因此,2個義原的相似度還應考慮義原在義原樹上的位置因素[9]:

其中:dS1、dS2分別為2個義原在知網層次樹中的深度;D(S1,S2)為2個義原在層次樹中的距離。
通過式(6)得到2個詞語的相似度,然后通過基準詞計算某個詞的情感極值。假定褒義基準詞集SWordset1={C1,C2,…,Cn},貶義基準詞集SWordset2= {D1,D2,…,Dn},則對于待求詞W,基于知網的情感極性SSo_Hownet(W)計算公式為:

通過分析可發現,基于知網詞典的情感極性計算方法,計算過程簡單,能很快得到結果。然而,該法的計算基礎為知網詞典,而知網詞典是手工建立,不能完全真實反映所有領域的所有情況,尤其是當一個詞在不同語境下有不同意義時,知網計算取所有情況下相似度最大值,顯然不能真實反映詞語的相似度。因此,通過知網難以獲得完全真實的結果。
2 PMI_HRV算法
基于語料庫的方法與基于知網詞典的方法均有一定的局限性,在基于語料庫方法的基礎上,結合最新的基于知網的相似度計算方法,建立結合評價領域詞語的基準詞表,并增加否定屬性表和網絡用語表來擴充詞典,提出PMI_HRV算法。
首先,對需要處理的商品評價語句進行預處理。從網上獲取的評價語句長短不一,格式各不相同,需要進行預處理才能進行分析。預處理首先是斷句,然后通過分詞和依存句法分析以及否定標記等,得到三元對(屬性名、情感詞、否定屬性標記)。
觀察發現,商品評論句子有很多相似性,比如一般評論偏向口語化,用語比較簡單,一般都是常用詞,情感表達比較明確,且容易判斷。另外,人民日報語料庫涵蓋范圍廣,大多都是通俗易懂的報道,比較符合商品評論特點,因此,大部分三元對中的情感詞都可通過式(2)計算得到明確的褒貶極性。對于一些特殊評價詞,比如出現概率不大或者不常用的詞,雖然比例很小,但對最終的結果仍有影響,這部分用式(7)計算。
2.1 基準詞表、否定屬性表、網絡用語表的建立
基準詞表是情感極性計算的重要影響因素,通常選擇詞典中出現頻率較高的詞作為基準詞[10],但這種選擇基準詞的方法不能反映不同領域的情況。PMI_HRV算法動態生成基準詞表。首先,統計語料中詞語詞頻,選擇詞頻最高的30個褒義詞和30個貶義詞作為基準詞表一部分,然后統計待計算詞語詞頻,將最多的10個褒義詞和10個貶義詞作為基準詞表一部分。不同測試集將得到不同的基準詞表。
本算法將原始數據處理成三元對(屬性名、情感詞、否定屬性標記)。一般對商品評價數據的處理得到二元對(屬性名、情感詞)[11],然而,商品某些屬性本身含有否定意義,比如費用、塑料感、溫度等,對應的情感詞如高、強、高等,它們是褒義詞,但實際上屬于否定意義,因此,有必要對這部分屬性進行單獨標記。本算法通過人工篩選建立了一個否定屬性表。
商品評價的特點是口語化、通俗易懂、網絡用語多,其中網絡用語是影響結果的一個重要因素。本算法從大量網絡用語中篩選出與商品評價相關的網絡用語,建立網絡用語表。
2.2 算法描述
圖3為算法流程圖。PMI_HRV算法描述如下:

圖3 算法流程圖Fig.3 The flow chart of algorithm
Input:數據集dataset、語料庫文件corpus、知網詞典hownet、網絡用語詞典集net_dic、否定屬性集neg_att、一般基準詞集base_list1。
Output:褒義詞識別數qua1、褒義詞正確數qua2、貶義詞識別數qua3、貶義詞正確數qua4。
for(eachSentence(i)∈Dataset)//預處理
{(attribute(i),word(i))←sentence(i);}
for(i=0;i≤dataset.size;i++)
{if(attribute(i)∈neg_att)
(attribute(i),word(i))→(attribute(i),word (i),1);
else
(attribute(i),word(i))→(attribute(i),word (i),0);}
for(i=0;i≤dataset.size;i++)
{if(word(i)∈褒義詞)褒義詞集←word(i);
else if(word(i)∈貶義詞)貶義詞集←word(i);}
base_list←top10(褒義詞集)//取頻次最高的10個加入基準詞集
base_list←top10(貶義詞集)
base_list←top30(base_list1中褒義詞)∪top30 (base_list1中貶義詞)
for(i=0;i<=dataset.size;i++)
{if(word(i)對應三元對為(attribute(i),word (i),1))
{通過式(2)計算word(i)的PMI值a
if(a>θ)result←(attribute(i),-a);
else通過式(7)計算word(i)的hownet值b
result←(attribute(i),-b);}
else if(word(i)對應三元對為(attribute(i), word(i),0))
{通過式(2)計算word(i)的PMI值a
if(a>θ)result←(attribute(i),a);
else通過式(7)計算word(i)的hownet值b
result←(attribute(i),b);}}
if((attribute(i),i).get(i)>0)
{qua1++;
if(attribute(i)是褒義詞)qua2++;}
else if((attribute(i),i).get(i)<0)
{qua3++;
if(attribute(i)是貶義詞)qua4++;}
return qua1,qua2,qua3,qua4;
3 實驗與分析
3.1 實驗環境與實驗數據
測試環境是PC機,配置Intel Core i3 3.4 GHz, 4 GB內存,Windows 7系統,算法實現語言為Java,運行環境為Eclipse 3.6。
測試數據是網上某電商關于某款筆記本電腦的評價數據,實驗語料庫是人民日報標注語料庫,知網詞典從知網官網下載,網絡用語詞典是收集整理網絡用語后手工建立。
首先建立基準詞表,通過知網和測試數據,得到基準詞表,如表1所示。通過測試數據分析得到否定屬性表,如表2所示。建立的網絡用語詞典如表3所示。

表1 基準詞表Tab.1 Reference words list

表2 否定屬性表Tab.2 Negative attribute words list

表3 網絡用語詞典Tab.3 Network words list
3.2 實驗過程
為了對比實驗效果,共進行5次實驗。實驗1單獨采用文獻[3]的PMI方法,統計褒義詞和貶義詞數;實驗2單獨采用文獻[9]的知網詞典方法,統計褒義詞和貶義詞數;實驗3采用PMI_HRV算法,統計褒義詞和貶義詞數;實驗4通過不同的設定,找到合適的θPMI值和θ值;實驗5通過不同的基準詞表在PMI_HRV算法下的效果對比說明本算法采用的基準詞表的作用。
5次實驗所用的預處理后的數據、否定屬性表和網絡用語詞典完全一致,前4個實驗所用的基準詞表為本算法所用基準詞表,實驗5對比的基準詞表是一般用的基準詞表和本算法基準詞表。
3.3 實驗結果與分析
實驗結果采用P、R、F值作為評價指標,P為準確率,R為召回率,F為綜合評價指標。P和R是廣泛用于信息檢索和統計學分類領域的2個度量值,用來評價結果的好壞,其中P衡量檢索系統的查準率, R衡量檢索系統的查全率。通過計算各個算法的P、R以及F值來衡量算法的優劣,F=P×R×2/(P+ R)。表4~7為實驗結果。
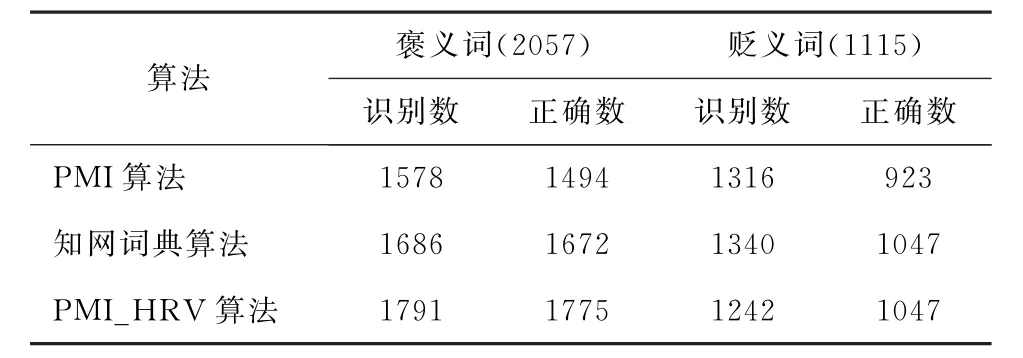
表4 不同算法識別數與正確數對比Tab.4 The comparison of different algorithms in identification and correct number
從表4可看出,對于褒義詞,3種算法識別數都小于總數,其中PMI_HRV算法識別數1791比PMI算法識別數1578和知網詞典算法識別數1686更接近總數2057;在3種算法的正確數上,PMI_HRV算法的1775最高。對于貶義詞,3種算法的識別數大于總數1115,說明有部分褒義詞被判斷成了貶義詞,這是評論語料的詞語分布不平衡所導致的。PMI_ HRV算法的識別數更接近褒義詞總數1115,說明效果最好;在貶義詞的正確數上,PMI_HRV算法為1047,和知網詞典算法相同,高于PMI算法的923。綜合來看,PMI_HRV算法的性能要好于基于PMI和基于知網詞典的算法。

表5 不同算法P、R、F對比Tab.5 The comparison of different algorithms in P,R and F
表5由表4的實驗數據計算得到。PMI_HRV算法在褒義詞上的P值比基于PMI和基于知網詞典的算法稍差,但R值要高很多,F值比基于知網的算法高3個百分點,比基于PMI的算法高10個百分點。PMI_HRV算法在貶義詞上的P值比基于PMI和基于知網詞典的算法分別高6個和14個百分點, R值比基于知網的算法稍高,比基于PMI的算法高11個百分點,F值比基于知網的算法高3個百分點,比基于PMI的算法高13個百分點。
從表6可看出,不同閾值下P、R、F有不同結果,從實驗數據看,θPMI=5,θ=0.2時,褒義詞上的P、R、F值分別為0.991、0.863、0.923,貶義詞上的P、R、F值分別為0.843、0.939、0.888,都比其他情況下的值更高,因此,選取5、0.2作為最終閾值。
從表7可看出,采用本算法基準詞表在褒義詞P值上比一般基準詞表高22個百分點,R值低5個百分點,F值高9個百分點;在貶義詞上P值與一般基準詞表基本相等,R值比一般基準詞表高39個百分點,F值比一般基準詞表高30個百分點。采用本算法的基準詞表,算法效果明顯。
單獨用基于語料庫的算法和單獨用基于知網詞典的算法,結果F值均低于PMI_HRV算法。主要原因是單獨用基于語料庫的算法,部分低頻詞和中性詞無法區分;單獨用基于知網詞典的算法,依賴手工建立的知網詞典。PMI_HRV算法是2種算法的融合,可以很好地解決這些問題。基準詞表是算法計算的基礎,實驗結果表明,本算法基準詞表因為兼顧語料庫中詞語和待評價領域中詞語,F值高于一般的基準詞表,說明不同領域之間沒有通用的基準詞表,需要建立結合評價領域的基準詞表。

表6 不同閾值下結果對比Tab.6 The comparison of different thresholds
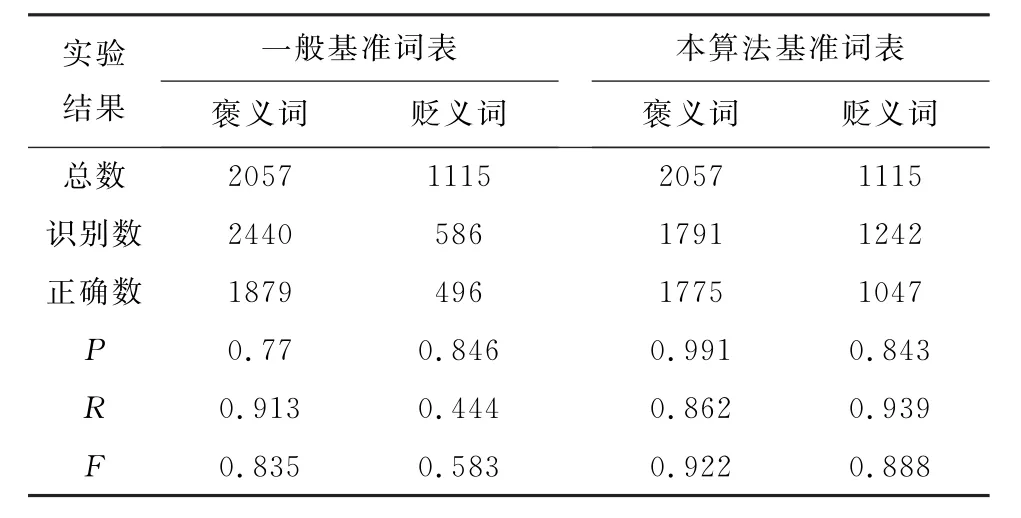
表7 不同基準詞表結果對比Tab.7 The comparison of different reference words list
4 結束語
對商品評價信息進行褒貶分析可為商家和消費者提供決策支持。傳統基于語料庫的方法,結果比較準確,人為影響小,但計算復雜、計算量大,對于出現頻率很低的詞,準確率低;基于知網詞典的方法簡單有效,計算過程簡單,但其結果依賴人工建立的詞典,受人主觀意識影響較大。在基于語料庫的PMI方法基礎上,通過建立結合評價領域詞語的基準詞表,增加否定屬性表和網絡用語表,結合基于知網詞典方法,提出PMI_HRV算法,解決了使用PMI算法計算時低頻詞無法計算的問題,擴展了知網詞典,使基于知網詞典的計算結果更為準確。實驗結果和分析表明,算法的準確率、召回率和F值相比已有算法有明顯提高,有一定的實際應用價值。
本研究提出算法在某些方面仍然有待改進。例如,采用的語料庫是人民日報語料庫,對特定領域適應性不高,下一步工作將考慮研究建立一個較通用的跨領域語料庫。
[1] 蘇杰,繆裕青,劉少兵,等.基于語義傾向計算器的情感分析方法[J].桂林電子科技大學學報,2012,32(4):302-306.
[2] 魏慧玲.文本情感分析在產品評論中的應用研究[D].北京:北京交通大學,2014:1-2.
[3] Turney P D.Thumbs up or thumbs down?semantic orientation applied to unsupervised classification of reviews [C]//Proceedings of the 40th Annual Meeting on Association for Computational Linguistics.Stroudsburg:Association for Computational Linguistics,2002:417-424.
[4] 劉群,李素建.基于《知網》的詞匯語義相似度計算[C]//第三屆漢語詞匯語義學研討會論文集.臺北:臺北市中研院語言學研究所,2002:59-76.
[5] 北京大學計算語言學研究所.人民日報語料庫簡介[EB/OL].[2001-05-10].http://www.icl.pku.edu. cn/icl_res/.
[6] 董振東,董強.知網簡介[EB/OL].[2013-01-29].http://www.keenage.com.
[7] 李峰,李芳.中文詞語語義相似度計算:基于《知網》2000 [J].中文信息學報,2007,21(3):99-105.
[8] 朱嫣嵐,閔錦,周雅倩,等.基于Hownet的詞語語義傾向計算[J].中文信息學報,2005,20(1):14-20.
[9] 江敏,肖詩斌,王宏蔚,等.一種改進的基于知網的詞語語義相似度計算[J].中文信息學報,2008,22(5):84-89.
[10] 祖李軍,王衛平.中文網絡評論中提取產品特性的研究[J].計算系統應用,2014,23(5):196-201.
[11] 周劍鋒,陽愛民,周詠梅,等.基于二元搭配詞的微博情感特征選擇[J].計算機工程,2014,40(6):162-165.
編輯:梁王歡
An improved algorithm for sentiment polarity analysis of product reviews
Shao Qiwu1,Miao Yuqing1,2,Xie Yijun1,Gao Han1,Cai Guoyong1,2
(1.School of Computer Science and Engineering,Guilin University of Electronic Technology,Guilin 541004,China; 2.Guangxi Key Laboratory of Trusted Software,Guilin University of Electronic Technology,Guilin 541004,China)
In order to solve the problem that low-frequency words have poor accuracy,PMI_HRV algorithm is proposed for judgment analysis on product evaluation information.PMI_HRV uses the latest method of Hownet based on the PMI.Moreover,the reference vocabulary in the method is related to the evaluation.In addition,the negative attribute table and the network glossary is appended to the Hownet to improve the accuracy.Experimental results show that PMI_HRV algorithm has better precision and recall rates.
sentiment analysis;product review;point mutual information;Hownet;reference vocabulary
TP301.6
A
1673-808X(2015)02-0156-06
2015-01-26
廣西自然科學基金(2014GXNSFAA118395);廣西教育廳科研項目(2013YB094);廣西可信軟件重點實驗室基金(kx201116);桂林電子科技大學研究生教育創新計劃(GDYCSZ201466)
繆裕青(1966-),女,浙江臺州人,副教授,博士,研究方向為數據挖掘、分布式計算、云計算。E-mail:miaoyuqing@guet.edu.cn
邵其武,繆裕青,謝益均,等.一種改進的商品評價情感極性分析算法[J].桂林電子科技大學學報,2015,35(2):156-161.
猜你喜歡
石油瀝青(2021年4期)2021-10-14 08:50:44
世界科學技術-中醫藥現代化(2021年10期)2021-03-02 05:52:06
中國生殖健康(2020年5期)2021-01-18 02:59:48
家庭醫學(下半月)(2020年4期)2020-05-30 12:42:50
北極光(2019年12期)2020-01-18 06:22:10
小太陽畫報(2019年10期)2019-11-04 02:57:59
中國生殖健康(2018年5期)2018-11-06 07:15:40
發明與創新(2016年6期)2016-08-21 13:49:38
中國教育技術裝備(2015年19期)2015-03-01 02:43:07
中國工程咨詢(2015年2期)2015-02-14 02:59:26
