基于大數據的安全事件挖掘框架*
2015-06-23 13:55:21李明桂陳劍鋒
通信技術 2015年3期
關鍵詞:分析
李明桂,肖 毅,陳劍鋒,許 杰
(中國電子科技集團公司第三十研究所,四川 成都 610041)
基于大數據的安全事件挖掘框架*
李明桂,肖 毅,陳劍鋒,許 杰
(中國電子科技集團公司第三十研究所,四川 成都 610041)
安全態勢感知是掌控網絡空間的聽覺和視覺,安全事件的獲取是安全態勢感知的基礎。在大數據時代,安全事件的挖掘是一個典型的大數據問題。運用大數據技術進行網絡安全研究,構建了一種安全事件挖掘框架,結合在線反饋和離線分析兩種方式,從海量、多源、異構的原始數據中,提取有效的安全事件,發現安全風險、潛在威脅和未知攻擊。挖掘結果可用于安全態勢感知、攻擊追蹤溯源、攻擊知識學習等進一步研究。
大數據 安全事件 數據挖掘 機器學習
0 引 言
自棱鏡計劃曝光以后,國家層面在網絡空間安全領域相繼展開大動作,網絡安全領導小組成立、世界互聯網安全大會在烏鎮召開、國家網絡安全宣傳周設定,網絡空間的安全越來越受到全社會的關注。
關注網絡空間安全,需要能夠全面感知網絡安全態勢,而安全事件是網絡安全態勢感知的基礎,這就要求能夠快速、高效、準確地發現網絡安全事件。安全事件的提取依賴于以主動方式獲取的探針數據和以被動方式接收的上報數據。探針數據是指操作系統、防火墻、入侵檢測等產生的日志信息或告警信息。上報數據則是指網絡用戶、運營商等主動上報的威脅信息。在大規模網絡環境中,數量龐大、類型不一的安全防護設備將產生大數據級、格式多樣的日志、告警和威脅信息。在此背景下,傳統的數據挖掘或安全分析方法就不再適用了。
在大規模網絡環境中,安全事件的挖掘已經成為一個大數據問題,需要借助大數據分析技術予以解決。
1 研究進展
大數據分析是指用以解決大數據問題的,包括集成、存儲、處理、分析、評估、預測等在內的方法[1]。它具有兩層涵義:其一是處理的數據量非常龐大,這是一個存儲問題;其二是如何對海量的數據進行分析,這是一個計算問題。因而,現有的大數據技術都可以被劃分為存儲和計算兩個層面。
國外針對大數據的研究開展較早,已經取得了頗為豐碩的成果,形成了以Hadoop為基礎的大數據生態系統[2],包括HDFS、GFS、MapReduce、YARN、Spark、Storm、HBase、BigTable、Hive、Mahout、Pig、Impala、Dremel、Kafka、Flume、Lucene、Zookeeper等。
在大數據發展的短短幾年間,Hadoop從一種邊緣技術已然成為大數據分析事實上的標準。
Hadoop是一個能夠對大量數據進行分布式存儲和計算的軟件框架。Hadoop框架最核心的設計就是HDFS和MapReduce,HDFS為海量數據提供存儲,則MapReduce為海量數據提供計算。Hadoop平臺廣泛應用于大數據處理,得益于其自身在數據提取、轉換和加載(ETL)方面上的天然優勢。Hadoop的分布式架構,將大數據處理引擎盡可能的靠近存儲,對例如像ETL這樣的批處理操作相對合適,因為類似操作的批處理結果直接走向存儲。Hadoop的MapReduce功能實現了將單個任務打碎,并將碎片任務發送(Map)到多個節點上,之后再以單個數據集的形式加載(Reduce)到數據倉庫里。
雖然我國在大數據領域的研究起步較晚,但我國是一個天然的數據大國,擁有著絕對量數據資源。目前,國內針對大數據的研究正如火如荼。比如,中國計算機協會(CCF)專門成立了大數據專家委員會,可以看出大數據在國內已經受到了足夠的重視。國內廠商的研究成果主要以百度、阿里巴巴、騰訊等互聯網巨頭和中國移動、中國電信、中國聯通等電信運營商為代表,尤以“BAT”三巨頭為最。其中,百度成立了深度學習研究院開展大數據和深度神經網絡的研究,已經面向市場推出了“百度預測”、“百度大數據引擎”產品。阿里巴巴繼推出阿里云之后,又高調打造大數據平臺服務。騰訊也開放了大數據基礎平臺,提供大數據技術框架。然而,眼下國內的大數據產品大都基于國外開源軟件修改而來,且研究進度明顯滯后于美國等發達國家,天然的海量數據資源還沒有能力充分加以利用。
2 設計思想
在大規模網絡環境中,安全事件的挖掘是一個大數據問題。大數據問題需要具體問題具體分析。落實到安全事件的挖掘這個問題上,大數據的分析技術使我們看到了從海量的原始數據中發現安全威脅的可能。
挖掘網絡安全事件,需要結合離線和在線兩種方式,離線方式以深層分析為主,在線方式以快速反饋為先,兩者互為補充。在線方式用于實時或準實時地捕捉短時間高并發的攻擊行為,例如,端口掃描、嗅探、DDoS等。而離線的方式能夠發現更深層次的威脅,例如周期或潛伏期較長的APT類攻擊。
基于上述思想,提出一種安全事件挖掘系統框架,如圖1所示。
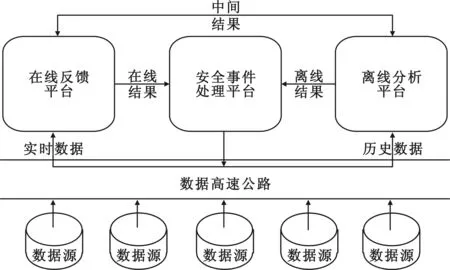
圖1 安全事件挖掘系統框架
在線反饋平臺接入網絡中,在線收集和處理原始數據,實時或準實時地給出安全事件的挖掘結果。離線分析平臺在線下收集和分析全網的歷史數據,利用聚類、關聯和深度學習等方法,深層次地挖掘安全事件。離線平臺注重挖掘結果,適當弱化時延的要求,在線平臺則強調分析的實時性,容忍一定的遺漏,兩者為補充。
安全事件處理平臺維護全局的安全事件庫,用于進一步的處理,如安全態勢感知、攻擊追蹤溯源、攻擊知識學習等。
3 框架設計
3.1 在線反饋平臺
在線反饋平臺收集原始數據,并對其進行并行化ETL處理。這是因為,原始數據具有多源異構性,需要對其進行清洗,去除冗余、統一格式,以便后續分析。數據清洗時,只保留事件挖掘所關心的字段信息,并按照預先定義的數據格式存于數據庫中。挖掘引擎利用并行化聚類算法從數據庫中挖掘有效的安全事件,并轉交給安全事件處理平臺進一步分析。挖掘引擎中的深度學習訓練模塊以規則庫為依據在線地進行訓練,訓練完畢的深度學習算法可用于離線分析,同時,離線平臺會將新的事件挖掘結果抽象成規則用于更新在線平臺的規則庫。在線反饋平臺基本架構如圖2所示。
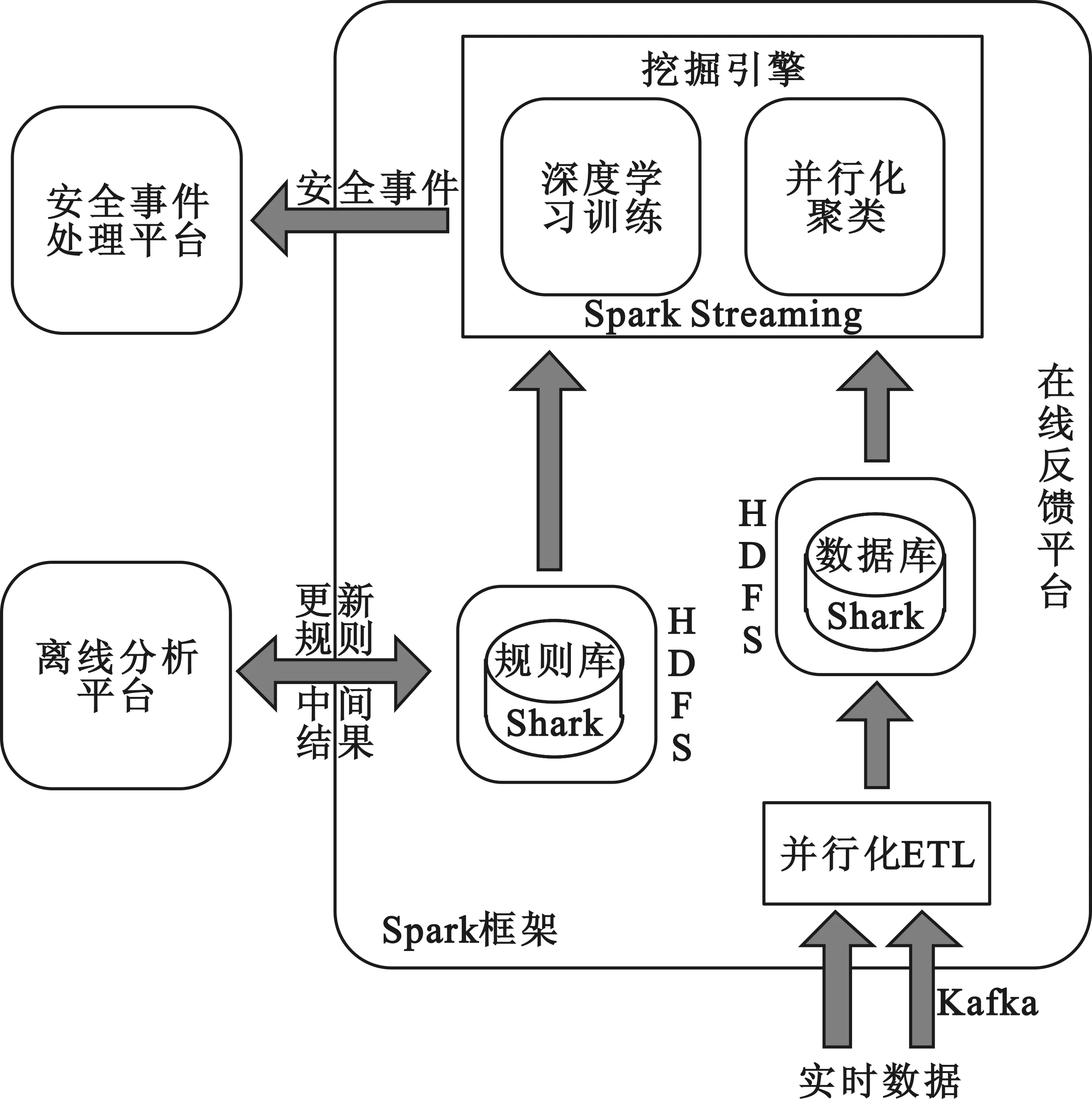
圖2 在線反饋平臺基本架構
在線反饋平臺基于Spark框架,Spark采用內存計算方式對批量數據進行流處理,具有高效的計算能力和并發處理能力[3],特別適用于在線分析的情形。此外,Spark的流計算與深度學習數據交互簡單,學習成本較低,資源可統一規劃,并且能夠充分利用足夠量的在線數據作為訓練樣本。此外,由于Hadoop不支持迭代[4],因而不能用于深度學習的訓練過程,即便通過復雜的設計使深度學習訓練能夠在Hadoop上實現,其效率也將是非常不理想的。這也是在線反饋平臺基于Spark框架的另一個原因。
各數據源通過數據高速公路進入在線反饋平臺。數據高速公路選用Kafka,由Linked in提供,是一種分布式消息系統,其數據消費方式支持pull模式,具有O(1)復雜度的持久化和很高的吞吐率。憑借這些特性,Kafka非常適用于在線反饋平臺對高并發數據的在線計算。
通過并行化的ETL過程對多源異構的原始數據進行預處理。ETL的并行化是因為:一方面,數據吞吐量大,并行化能夠大大提高處理效率;另一方面,Spark是基于MapReduce原理構建的,并行化能夠較為容易的實現。
經過ETL的數據存放于數據庫中,數據庫選用Shark。Shark類似于Hadoop上的Hive[5],本質上是通過Hive的HQL解析,把HQL翻譯成Spark上的RDD操作,然后通過Hive的metadata獲取數據庫里的表信息,實際存放于HDFS的數據和文件會由Shark獲取并放到Spark上計算。
挖掘引擎對高并發數據進行實時或準實時處理,采用批量流計算模型。與MapReduce調度計算不同,流計算是對數據的調度。流計算能夠對流式數據進行實時或準實時處理,能夠根據計算的規模進行彈性資源擴展,能夠靈活數據處理任務之間的依賴關系,較為適合對數據的在線分析與處理,但是流計算不適合海量數據處理的情形。選用Spark Streaming能夠很好的解決這個問題。Spark Strea-ming是一種小規模批處理系統,它將數據分成很小的batch在Spark上處理,其數據吞吐率很高,并且可以與YARN[6]和Hadoop共享計算資源。
在線反饋平臺對在線數據流進行實時或準實時的分析,強調快速高效的處理能力,適當弱化對安全事件的挖掘結果的準確度要求。挖掘引擎的主要功能是挖掘安全事件和判決威脅類型,對于不確定的疑難事件,交由離線分析平臺進一步處理。
3.2 離線分析平臺
離線分析平臺收集全部歷史數據,經ETL后,存放于數據倉庫之中。另外,數據倉庫還存儲在線反饋平臺轉交的疑難事件數據。離線分析平臺維護著一個已知的安全事件倉庫,事件倉庫中的安全事件來自離線平臺分析的結果和在線平臺反饋的結果。挖掘引擎結合該事件倉庫對數據倉庫中數據進行深層分析,將最新的事件挖掘結果交由安全事件處理平臺進一步處理,并把最新的事件保存于事件倉庫中。同時,離線平臺將新型安全事件抽象形成規則,用于在線平臺的規則庫更新。離線分析平臺基本架構如圖3所示。
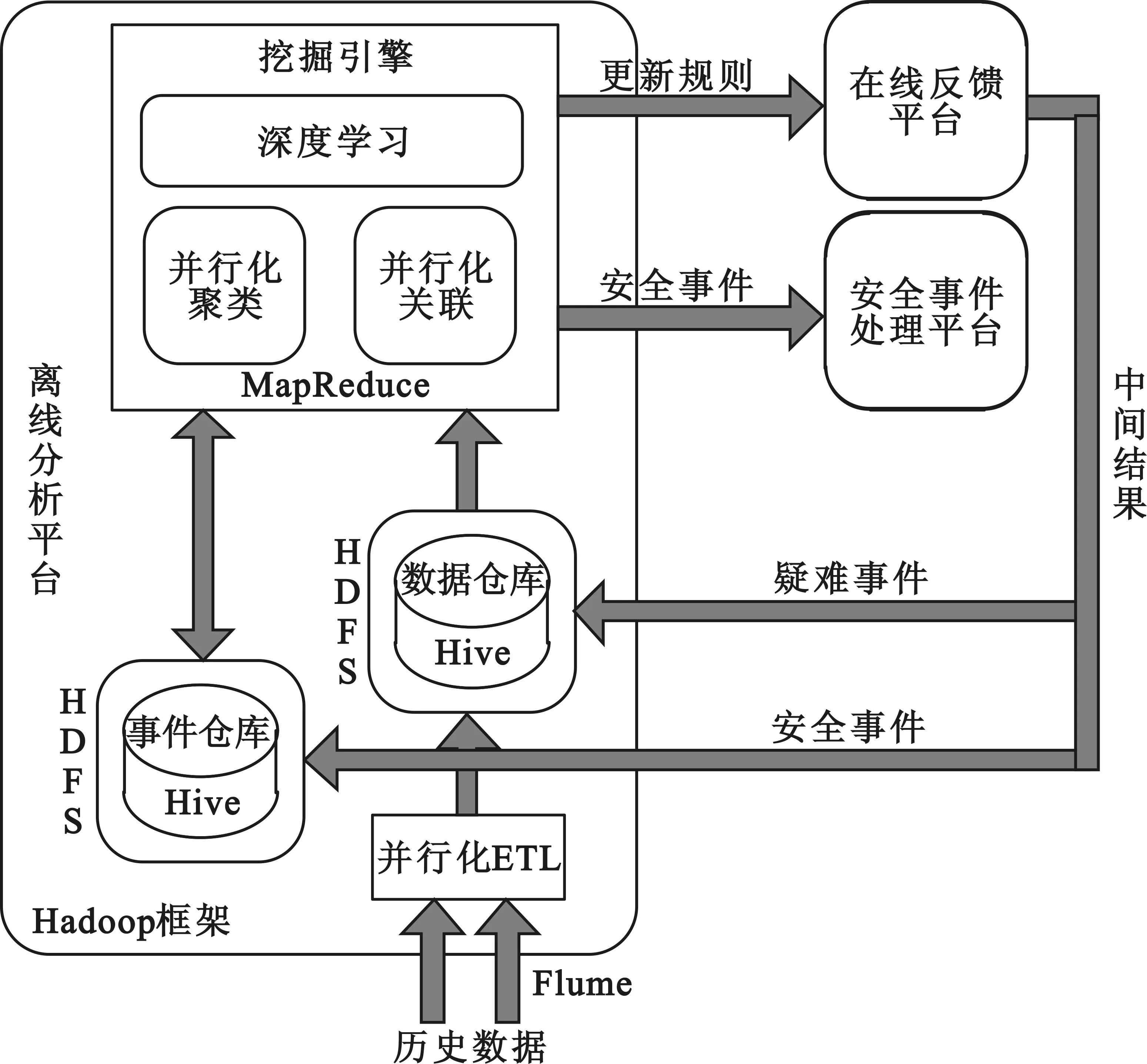
圖3 離線分析平臺基本架構
離線分析平臺承載PB級的數據量,規模可達到數千服務器節點,需要進行海量數據的持久化和非實時批處理計算,采用分布式存儲和計算的Hadoop框架。分布式存儲要求使大量服務器的物理存儲聚合,統一訪問,采用HDFS的分布式文件系統[7]。分布式計算要求將分布式存儲上的海量數據做分布式處理,盡可能調度計算而不是調度數據,即各節點獨立計算,并將計算結果匯總得出最終結果,采用MapReduce的計算模型[8]。在Hadoop框架上,基于MapReduce模型實現ETL并行化、關聯分析并行化、聚類分析并行化以及高并發海量數據的深度學習,基于HDFS分布式文件系統、HBase數據庫和Hive數據倉庫,提供海量數據的存儲能力。
離線平臺分析的數據吞吐量很大,為TB以上量級。數據源來自大量的、不同類型的設備節點,需要被送到多個目的地。轉運的數據可以容許很少量的丟失,也可以容許一定的亂序。基于上述原因,采用Flume收集歷史數據。Flume是一個高可用、高可靠、分布式的海量日志采集、聚合和傳輸系統,能夠滿足吞吐量大、數據源結構復雜、數據一致性要求稍低等的環境要求[9]。
挖掘引擎包含三部分,并行化聚類、并行化關聯、深度學習。并行化聚類與在線反饋平臺相似,用于從數據倉庫中提取有效安全事件,并判別威脅類型。并行化關聯挖掘用于深層次地威脅發現,基于數據倉庫中的原始數據集和平臺的事件倉庫中的已知安全事件,進行深入的關聯規則分析,找出多個安全事件背后隱藏的聯系,并將一次成體系的系列攻擊動作產生的系列安全事件歸并為一個新的安全事件,另外,通過將確定的安全事件與關聯關系結合,還能發現還未啟動的、潛在的威脅。采用在線反饋系統中訓練完成的深度學習算法,結合事件倉庫的已知安全事件集,從數據倉庫的原始數據集合中挖掘全部已知威脅和部分未知攻擊。
離線分析平臺對歷史數據進行并行化的關聯分析和深層挖掘,強調安全事件挖掘結果的嚴謹性,適當弱化對處理延時的要求,但關注并行化處理效率,即不要求實時或準實時的給出分析結論,卻需要在可接受的時間內給出準確的挖掘結果。
3.3 事件處理平臺
安全事件處理平臺基于已獲取的安全事件進一步分析,包括但不局限于安全態勢感知、攻擊追蹤溯源、攻擊知識學習,其基本架構如圖4所示。
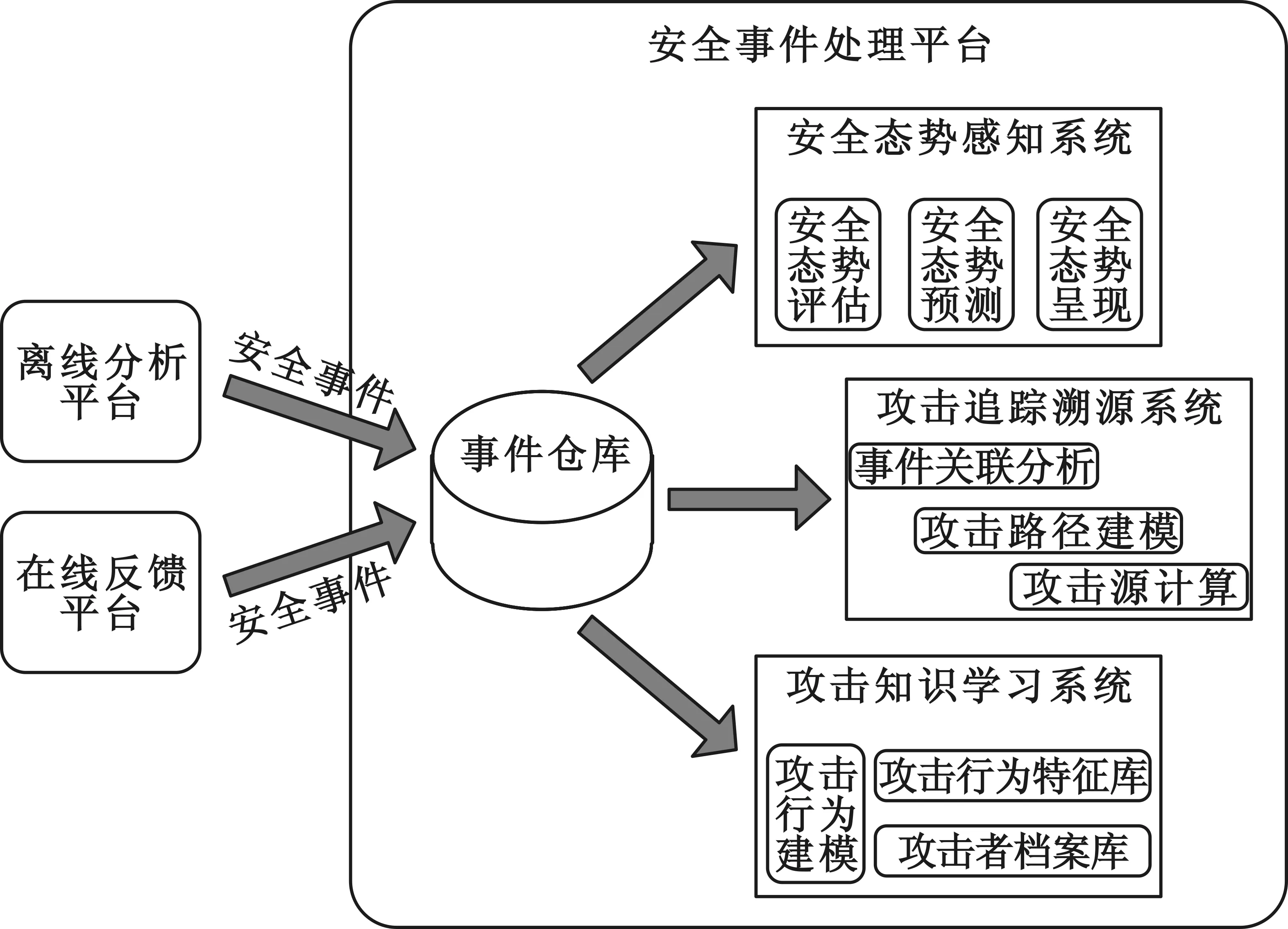
圖4 安全事件處理平臺基本架構
安全事件處理平臺接收來自離線分析平臺和在線反饋平臺的安全事件挖掘結果,存儲于數據倉庫中,形成全局事件倉庫。安全態勢感知系統、攻擊追蹤溯源系統、攻擊知識學習系統提取事件倉庫的數據進行業務分析。
安全態勢感知系統,從事件倉庫中提取安全事件,通過SQL查詢獲取安全事件統計結果,利用特定的態勢評估模型進行安全態勢評估,利用特定的態勢預測算法進行安全態勢預測,進而通過可視化方法將態勢現狀和預測結果呈現出來。
攻擊追蹤溯源系統,對事件倉庫中的全部安全事件做關聯規則分析,依據事件關聯結果,構建攻擊路徑模型,利用圖論經典算法進行分析,找出攻擊源頭,進而獲取攻擊者IP地址、地理位置和真實身份信息。
攻擊知識學習系統,基于對全局安全事件的特定分析,標記出可疑節點,提取可疑節點的真實IP等關鍵信息,建立攻擊者檔案庫,再對可疑節點的行為建模分析,將攻擊者的行為抽象成某種特征,形成攻擊行為特征庫。攻擊知識學習系統的重要輸出就是攻擊者檔案庫、攻擊行為特征庫,它們可以作為知識庫幫助挖掘引擎從海量數據中發現安全事件或安全事件集。
4 結 語
安全態勢感知是網絡空間對抗的耳與目,而安全事件的提取是安全態勢感知的基礎。本文利用大數據分析技術,構建了一種安全事件挖掘系統框架。主要包含三個部分,以在線反饋平臺和離線分析平臺相互配合,有效地監測各類安全事件,其結果交由安全事件處理平臺作進一步分析處理。本文提出的方法為部署大規模網絡環境下的安全態勢感知、攻擊追蹤溯源等業務系統提供了一種技術思路。
[1] 劉師語,周淵平,杜江.基于HADOOP分布式系統的數據處理分析[J].通信技術, 2013,46(09): 99-102. LIU Shi-yu, ZHOU Juan-ping, DU Jiang. Analysis of Massive Data Processing based on Hadoop Cluster[J]. Communications Technology, 2013, 46(09): 99-102.
[2] 張鋒軍.大數據技術研究綜述[J].通信技術,2014,47(11):1240-1248. ZHANG Feng-jun. Overview on Big Data Technology[J]. Communications Technology,2014,47(11):1240-1248.
[3] ZAHARIA M, CHOWDHURY M, DAS T, et al. Fast and interactive analytics over Hadoop data with Spark [J]. USENIX, 2012, 37(04): 45-51.
[4] BIFET A. Mining Big Data in Real Time [J]. Informatica (Slovenia), 2013, 37(01): 15-20.
[5] THUSOO A, SARMA J S, JAIN N, et al. Hive: a warehousing solution over a map-reduce framework [J]. Proceedings of the VLDB Endowment, 2009,2(02):1626-1629.
[6] KULKARNI A P, KHANDEWAL M. Survey on Hadoop and Introduction to YARN [J]. International Journal of Emerging Technology and Advanced Engineering, 2014, 4(05): 82-87.
[7] BORTHAKUR D. The hadoop distributed file system: Architecture and design [J]. Hadoop Project Website, 2007, 11(2007): 21.
[8] DEAN J, GHEMAWAT S. MapReduce: simplified data processing on large clusters [J]. Communications of the ACM, 2008, 51(01): 107-113.
[9] LOGANATHAN A, SINHA A, MUTHURAMAKRISHNAN V, et al. A Systematic Approach to Big Data [J]. International Journal of Information & Computation Technology, 2014, 4(09): 869-878.
LI Ming-gui (1989- ),male,graduate student,majoring in information security and big data;
肖 毅(1970—),男,碩士,研究員,主要研究方向為通信與信息安全;
XIAO Yi (1970- ),male,M. Sci.,research fellow,mainly engaged in telecommunication and information security;
陳劍鋒(1983—),男,博士,高級工程師,主要研究方向為信息安全與云計算;
CHEN Jian-feng(1983- ),male,Ph. D.,senior engineer,specialized in information security and cloud computing;
許 杰(1978—),男,博士,工程師,主要研究方向為信息安全與大數據。
XU Jie(1978- ),male,Ph. D.,engineer,majoring in information security and big data.
National Natural Science Foundation Project (No.61202043)
Big Data-based Framework for Security Event Mining
LI Ming-gui, XIAO Yi, CHEN Jian-feng, XU Jie
(No.30 Institute of CETC, Chengdu Sichuan 610041, China)
Security situation awareness is,just like the eyes and ears,to grasp and control the cyber space. Further,the acquisition of security event is the basis for security situation awareness. In the era of big data, security event mining is also a typical big data problem. This paper proposes a framework for mining security event by on-line and off-line mode. It provides a solution to detect security risks, potential threats and unknown attacks from the massive, multi-source, heterogeneous raw data. Moreover, the mined results can be used for implementing further processing,including security situation awareness,attack-source tracking attack-knowledge learning.
big data; security event; data mining; machine learning
date:2014-10-07;Revised date:2015-02-04
國家自然科學基金項目(No.61202043)
TP309
A
1002-0802(2015)03-0346-05

李明桂(1989—),男,碩士研究生,主要研究方向為信息安全與大數據;
10.3969/j.issn.1002-0802.2015.03.019
2014-10-07;
2015-02-04
猜你喜歡
現代畜牧科技(2021年9期)2021-10-13 06:39:14
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
電子制作(2018年18期)2018-11-14 01:48:24
山東工業技術(2016年15期)2016-12-01 05:31:22
當代經濟研究(2016年5期)2016-12-01 03:12:05
現代農業(2016年5期)2016-02-28 18:42:46
出版與印刷(2016年3期)2016-02-02 01:20:11
中國中醫藥現代遠程教育(2014年11期)2014-08-08 13:23:44
華北水利水電大學學報(社會科學版)(2014年3期)2014-04-16 04:38:31
終身教育研究(2014年5期)2014-02-28 01:23:06
