大量網絡游記文本中熱度地名提取方法與實證研究
2015-06-07 11:31:42李照航,郭風華,李仁杰,3*,傅學慶,3,嚴正峰,3
地理與地理信息科學 2015年1期
李 照 航,郭 風 華,李 仁 杰,3*,傅 學 慶,3,嚴 正 峰,3
(1.河北師范大學資源與環境科學學院,河北 石家莊 050024;2.河北省科學院地理科學研究所,河北 石家莊 050021;3.河北省環境演變與生態建設實驗室,河北 石家莊 050024)
?
大量網絡游記文本中熱度地名提取方法與實證研究
李 照 航1,郭 風 華2,李 仁 杰1,3*,傅 學 慶1,3,嚴 正 峰1,3
(1.河北師范大學資源與環境科學學院,河北 石家莊 050024;2.河北省科學院地理科學研究所,河北 石家莊 050021;3.河北省環境演變與生態建設實驗室,河北 石家莊 050024)
探討網絡游記文本中的地名使用特征及其研究意義,地名使用狀態的定量特征能夠反映游客對旅游地景觀的認知結構與旅游行為的一般過程。在現有中文分詞技術基礎上,結合游記文本中的地名使用特點,選用ATF*PDF方法計算特征詞匯在整個旅游文本集中使用狀態的綜合權重,設計了一種基于大量網絡游記文本的熱度地名自動提取方法,為不使用自定義地名庫的旅游地理研究奠定了基礎。以游客點評網游記為樣本的實驗證明,該方法能夠實現旅游相關地名的快速提取,地名使用熱度越高,提取準確率越高;對地名提取結果的類型結構分析發現了自然和人文旅游地游記在詞匯使用方面的共性和差異,指示了旅游文本地名的分布意義及其對旅行過程其他信息解讀的潛在價值,預示了網絡游記文本在進一步解析旅游者的旅游地認知特征和旅游行為過程方面的科學意義。
網絡游記文本;熱度地名;ATF*PDF模型;多樣本集合共現
0 引言
網絡游記是旅游者基于自身旅游體驗主動發表在互聯網中主要描述旅行過程和感受的文本,其相比問卷調查和訪談更能夠代表游客的真實態度[1],可以作為旅游地研究的重要數據來源[2]。目前,國內外以互聯網游記文本為數據源的旅游地研究越來越多,主要關注旅游者行為及其對旅游地整體的認知和情感特征[3]。例如,選擇互聯網內容分析方法,通過旅游文本中的高頻特征詞研究旅游者行為特征[4]和旅游地整體形象認知[5-7];深入分析旅游文本在游客地方感構建中的作用[8]及其對旅游目的地形象形成過程的影響[9,10]。總體看,現有研究主要關注大中尺度的區域旅游,或從整體、全局視角對特定旅游地開展研究,缺少對旅游地內部景觀尺度及其與外部旅游空間關系的關注。
地名(本文中既包括旅游地及相關地名,還包括旅游地內部景觀名稱)在游記文本描述中起主線作用,游記中的地名可用于區分旅游者對旅游地不同區域和景觀的認知評價單元,對旅游地內部小尺度景觀認知與旅游行為的空間分異研究具有重要意義。不同作者撰寫的同一旅游地游記文本的集合具有相同的描述對象,可以作為地名使用特征挖掘的重要數據來源。近年來,從自然語言中解析地名及相關空間信息成為地理信息科學的重要研究內容[11],但從大量旅游者自由撰寫的文本中快速提取使用熱度較高的特定旅游地相關地名,目前還缺少有效的方法。
本文在現有中文分詞方法基礎上,結合游記文本中的地名使用特點,嘗試設計一種基于大量網絡游記文本集合的熱度地名提取方法:在有效分詞基礎上,設計游記文本中地名使用情況的綜合權重值計算模型,并構建一種非地名詞匯的排除詞集合,進而通過熱度排序提取出旅游者對某一旅游地關注度較高的景觀或旅游地相關地名,即本文中的“熱度地名”。通過此方法提取出的旅游景觀與相關旅游地名可用于旅游地名數據庫的自動構建[12]。大量網絡游記文本中共同表征的定量化地名使用狀態也是旅游者對旅游地認知狀態的重要表征,可以為旅游地形象認知度及其內部分異等研究提供方法與數據來源。
1 游記文本中的地名
地名是為了達到表達與溝通目的,對旅游地附近和旅游地內部重要、典型的地形地物或景觀等進行的命名[13]。景觀與旅游地名是具有不固定、形式多樣等特點的臨時耦合廣義地名[14],一般由旅游規劃設計者在規劃思想指導下命名,在旅游地發展的過程中逐漸被旅游者所熟悉,如黃山的光明頂、九寨溝的五花海等。互聯網游記一般記錄了出行的時間和目的地,并比較完整地記錄旅行過程中的認知與感受,對旅行過程的描述往往通過地名串聯起來。對互聯網游記初步分析后發現其中的地名使用存在以下特點:1)相關地名數量大,由于旅游地周邊及其內部的地物、景觀數量眾多,游記文本中也大量出現旅游地相關的地名;2)地名的使用既有共性也有差異,核心、標志性景觀與旅游地名稱在多數游記中被描述,同時由于旅游者審美視角差異,對旅游地景觀的描述有明顯個性化特征;3)同一旅游地相關的地名處于動態變化中,隨著旅游地不斷發展演化,新的旅游景觀不斷被規劃設計者和旅游者發現、命名,并出現在后續旅游者的游記文本中,而缺乏活力的旅游地景觀會逐漸被淘汰,失去旅游者的關注;4)地名的使用比較自由,簡稱、昵稱較多,如“布宮”、“九寨”等。網絡游記文本中使用地名的上述特點,使得許多旅游地名(尤其是景觀名稱)在常規的文本分詞過程中往往被識別為地名之外的其他詞匯。但由于旅游地名在旅游文本中出現的頻率非常高,常規分詞系統雖然未能將其識別為地名,卻能夠將其識別為新詞,這就為基于大量游記文本的詞匯統計特征提取旅游地名提供了可行性。
2 地名提取方法
2.1 方法設計
國內外對于地名提取方法的研究主要集中在規范化地名的自動識別,已達到較高的識別準確率。主要有基于統計模型的地名識別方法,如隱馬爾可夫模型[15]、條件隨機場等[16],以及在這些模型基礎上加以的改進的最大間隔隱馬爾可夫模型[17]、篇章關系引入條件隨機場的地名識別方法等[18];此外還有結合地名特征詞統計特征[19]進行地名識別等方法。上述方法主要針對規范化地名的識別,對于旅游地名和景觀名稱關注較少,地名時效性較低,簡稱、別名等非標準地名信息缺失[20]。上述分詞方法的分詞結果中,人名、地名、機構名等命名實體占文本中未登錄詞(沒有收錄在分詞詞表中但必須切分出來的詞)的很大比重[21]。
采用上述分詞方法對網絡游記文本分詞后,大量旅游地名也會歸入未登錄詞。雖然從未登錄詞匯中難以直接判斷哪些屬于旅游地名,但從游記文本中的地名使用特點看,如果將同一旅游地的大量游記文本作為一個文本集合,文本分詞后未登錄詞匯中的高頻詞匯屬于該旅游地相關地名的概率較高。綜合上述分析和假設,本文提出了基于大量互聯網游記文本統計特征的旅游地名提取方法,具體流程如圖1所示。首先采集同一旅游地的網絡游記形成游記文本集合,并利用現有分詞方法對每一篇游記進行分詞,對分詞結果按照詞性進行初步篩選;第二,統計每篇文本中各詞匯的頻次及總詞匯數,選擇合適的權重分配模型計算各詞匯在整個文本集合中的綜合權重值;第三,按照同樣方法選擇3個以上的旅游地樣本進行前兩步處理,建立基于多個旅游地文本集合共現的排除詞集合;最后,利用排除詞集合分別將各樣本游記文本詞匯集的高頻詞中包含的少量非地名詞匯剔除,就得到了使用熱度較高的詞匯,后續實驗證明該部分詞匯以旅游地相關的地名為主。
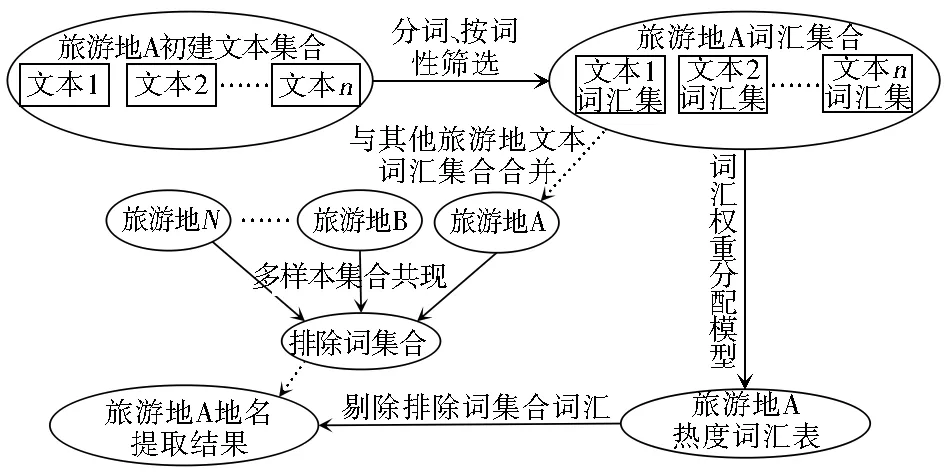
圖1 地名提取方法流程
Fig.1 Toponym extraction flow
2.2 基于隱馬爾可夫模型的分詞方法
分詞工具選用NLPIR漢語分詞系統(ICTCLAS2013),該系統具有中文分詞、詞性標注和新詞發現功能,并能夠將未登錄詞識別為新詞。NLPIR分詞工具采用層疊隱馬爾可夫模型對未登錄詞匯進行識別[22]。首先將要進行分詞的原始字符串切分為分詞原子序列;將一個給定的分詞原子序列S的某個分詞結果記為W=(w1,w2,…,wn),W對應的類別序列記為C=(c1,c2,…,cn),同時取概率最大的分詞結果W#作為最終的分詞結果,則:
(1)
如果wi未在核心詞典收錄,即為未登錄詞。其詳細識別與標注過程本文不再闡述。本文利用JNI(JavaNativeInterface,Java本地接口)實現對NLPIR系統的Java調用。對初始文本進行分詞,并對分詞結果根據詞性標注進行篩選,只保留詞性標注為地名和新詞的詞匯,將每篇文本處理后的詞匯集作為下一步處理的數據源。
2.3 基于ATF*PDF模型的詞匯權重分配方法
描述同一旅游地的游記文本集合中,每篇游記可以看做一名游客在該旅游地旅行的認知與感受表述。因此,某個景觀或旅游地名在越多的游記中出現,說明游客對其認知度越高。文本集中每個文本的大小不同,文本越大詞表越大,詞語在文本中出現的次數可能就越多。為了降低文本大小對詞頻的影響,應該對詞語在每個文本中的詞頻進行歸一化,然后取詞語在文本集中詞頻的平均值作為詞語在文本集中的詞頻。同時詞語存在的文本數不同,詞語的文本頻率越大,其重要性就越大,相應的景觀名稱關注度也就越高。因此,權重模型需要賦予在文本集眾多文本中均高頻出現的詞匯更高的權重。
針對以上需求,本文選用ATF*PDF(AverageTermFrequency*ProportionalDocumentFrequency)方法[23]計算詞匯在整個文本集中的綜合權重,以綜合權重的大小反映詞語的熱度。ATF*PDF是在TF*PDF(TermFrequency*ProportionalDocumentFrequency)方法[24]基礎上的改進,目前主要用于對多文檔關鍵詞的提取[25]。ATF*PDF方法在體現詞語頻率和文本頻率對權重值的共同作用的同時弱化了單篇文本長度對詞匯權重的影響。該方法應用于游記文本中的地名權重計算,既能反映地名在單篇游記中的認知深度,又能體現在游記集合中的認知廣度,權重值大小更符合游記文本中地名熱度特點。根據綜合權重的大小,將詞語i的權重wi定義為:
(2)
其中:N為整個文本集包含的文本數量;ni為文本集中包含詞語i的文本數;|tfji|為詞語i在文本j中的標準化詞頻,它的計算方法為:
(3)
其中:mj為第j個文本的詞表大小,tfji為詞語i在文本j中的詞頻。

2.4 基于多樣本集合共現的排除詞集構建方法
通過上述方法開展分詞和計算權重之后,得到的僅是某旅游地系列游記文本中整體權重值較高的已識別地名及熱度新詞的集合,其中除地名外還可能包括一些用于描述旅行過程的常用詞匯,如“退房”、 “訂票”、“指示牌”等。當僅關注旅游地名研究時,如何快速有效地剔除其他詞匯,就成為地名提取效率與精度的一個重要環節。
根據游記文本描述方式的共性和現代旅游者行為特征分析,本文提出了基于多樣本集合共現的排除詞集合構建方法。描述不同旅游地的系列游記文本集合間共同出現的詞匯一般有兩類:客源地名稱和分詞結果中未登錄詞匯構成的新詞。客源地名稱本質是地名(且一般都是標準化地名),在分詞過程中能被直接識別并標注為地名;共同出現的未登錄詞匯主要是描述“吃、住、行、游、購、娛”等旅游過程的常用詞匯,這些詞匯不屬于任意一個旅游地相關地名,應該在各個旅游地保留的高頻詞匯集合中剔除。基于多樣本集合共現的排除詞集合構建過程:首先,對分詞和加權統計提取的不同旅游地的地名詞匯集合進行篩選,僅保留未登錄新詞集合,并將不同旅游地的提取結果詞匯合并;第二,統計各詞匯在合并后的詞匯集合中的出現頻次(即樣本旅游地文本中的出現頻次);第三,選取出現頻次大于等于樣本旅游地總數量一半的詞匯作為排除詞集。
排除詞集合構建時需要具備兩個基本條件:首先,樣本旅游地數量應該大于等于4個,以保證能夠識別在不同旅游地游記中共同出現的非地名等旅行描述詞匯;其次,樣本旅游地相互獨立,一般旅游者不會安排在同一次旅行過程中,以保證文本中的旅游地名使用具有相對獨立性。排除詞集合對于提高旅游地名自動提取的精度和效率具有重要意義,但并非說明這些詞匯在開展旅游學其他相關研究時都需要被剔除。例如,基于多樣本共現的排除詞集合在用于研究旅游者行為或旅游地之間的對比分析時,有可能成為重要的核心指示詞匯,具有很好的應用價值,本文不再深入探討。
3 實驗與分析
3.1 關鍵技術
3.1.1 數據源選取與處理 本研究以專業游客點評網站攜程網(www.ctrip.com)上旅游者自由發布的網絡游記文本為數據源。為了充分證明提取方法的可行性、科學性和潛在應用價值,研究挑選了在國內具有較高影響力、游記文本數量較充足的黃山、九寨溝、故宮、布達拉宮4個旅游地作為研究樣本。其中黃山是世界文化與自然雙遺產旅游地,自然與文化景觀內涵都比較豐富,九寨溝則是以自然景觀為主的世界遺產地,兼有特色的藏文化景觀,故宮和布達拉宮則為世界著名的人文景觀旅游地。利用火車采集器(LocoySpider)并編寫采集規則,采集了攜程網上4個樣本旅游地的所有游記文本共13 410篇。為保證樣本游記質量,提高研究效率和準確性,對所采集的游記樣本進行了預處理:1)對于旅游者把同一次旅游經歷分成若干游記發表的系列游記進行合并處理;2)刪除字數較少缺少實質性旅游過程描述的游記,確保樣本游記信息量的規模。每個旅游地分別保留2 000篇旅游游記作為實驗文本。
3.1.2 地名提取 實驗文本處理完畢后,使用NLPIR開源分詞工具的JNI接口,編寫Java程序實現4個旅游地樣本共計8 000篇游記文本批量分詞;根據分詞結果的詞性標注,只保留詞性為地名和新詞的分詞結果,將其余詞性的詞匯、標點符號等全部刪除。統計每篇文本中各詞匯的頻次與總詞匯數,并統計每個詞匯出現的文本頻次。各旅游地樣本選取預處理與相關頻次統計完成后,基于ATF*PDF模型進行詞匯的綜合權重計算,并利用多樣本集合共現方法構建排除詞集合,對提取結果詞匯集合進行非旅游地名詞匯排除,最終得到各旅游地相關地名提取結果。選取權重排序前50位的詞匯(表略)初步觀察發現,本方法的提取結果以旅游地相關地名為主,既包括旅游地景觀與旅游地名稱,也包括重要的客源地名稱,還包括少量未被過濾的非地名詞匯。
3.2 提取結果分析
3.2.1 地名提取準確率 為了清晰表述和分析地名提取結果,本文提出了“地名提取準確率”的概念,指通過文本分詞、詞匯權重和排除詞集合篩選后的提取結果對旅游地相關地名的識別率,以結果中屬于本文界定的地名詞匯的數量占提取結果總數量的比例表示。研究者對4個樣本旅游地游記文本的地名提取準確率進行了逐一人工判別,以25個結果詞匯為累計統計單元,按照詞匯權重排序后的前200個結果詞匯的提取準確率分布情況如表1所示。總體看,4個樣本旅游地文本的前200個結果詞匯中地名提取準確率都較高,但準確率的分布整體隨詞匯權重值下降而降低,其中,綜合權重值前50的詞匯中,地名提取準確率均達到了90%以上,前100的地名提取準確率也達到了80%以上。準確率分析初步表明,基于大量網絡游記文本的地名提取方法適用于提取旅游者使用熱度較高的地名,該方法對自然和人文景觀旅游地的游記文本地名提取均具有較高準確率。隨著旅游文本中使用的詞匯熱度降低,提取結果詞匯中包含的地名逐漸減少,地名提取準確率降低。
表1 樣本旅游地游記文本中的地名提取準確率
Table 1 The accuracy of toponyms extracted from sample travel blog texts

權重排序黃山九寨溝故宮布達拉宮地名數準確率(%)地名數準確率(%)地名數準確率(%)地名數準確率(%)前252496.0025100.002392.002392.00前504590.004794.004590.004590.00前756586.676688.006586.676688.00前1008484.008484.008888.008787.00前20014673.0015276.0015979.5016582.50
3.2.2 提取結果的類型結構 提取準確率評價為后續基于游記文本等旅游者自由發布信息的旅游學應用奠定了基礎。由于提取結果中不同類型的地名分布特征和結構對于解析旅游者對旅游目的地的認知特征和旅游行為過程具有重要意義,研究中將旅游目的地自身名稱以外的結果詞匯進一步劃分為5種類型:目的地內部景觀名稱、周邊旅游地名稱、政區與城市名稱、重要地理要素名稱、其他詞匯。其中,前4種類型都屬于廣義的地名范疇,最后一種類型“其他詞匯”是提取結果中不屬于地名的詞匯,這些詞匯的熱度較高,對于解釋旅游文本中的地名分布意義或解讀旅游過程的其他信息具有潛在價值。在類型結構描述中采用3種數量分布指標:不同類型詞匯的數量、最大權重值和累積權重值。4個樣本旅游地提取結果中綜合權重值排序前100的詞匯類型分布結構如圖2所示。
從詞匯數量(圖2a)和累積權重值分布(圖2b)可以看出,兩種指標可以較好地反映不同旅游地游記文本在詞匯使用類型方面的共性和差異。以自然景觀為主導的黃山、九寨溝旅游地和以人文景觀為主導的故宮、布達拉宮旅游地表現出了明顯的自然和人文類型差異。自然景觀主導的游記中表現出“旅游目的地景觀名稱主導型”地名使用特征,游記作者使用了豐富的景觀名稱描述旅行過程;人文景觀主導的游記中則表現出“政區與城市名稱主導型”地名使用特征,結果詞匯中的旅游地內部景觀名稱較少,但包含大量周邊其他旅游地名稱。最大權重值分布(圖2c)可以反映不同類型單個詞匯在游記文本中的主導性狀態,4個旅游地的總體結構具有一定的相似度,政區與城市名稱整體上主導性明顯,周邊旅游地名稱的主導性位于其次,重要地理要素名稱的主導性在不同旅游地之間差異較大,而旅游地內部景觀名稱的主導性整體較弱。
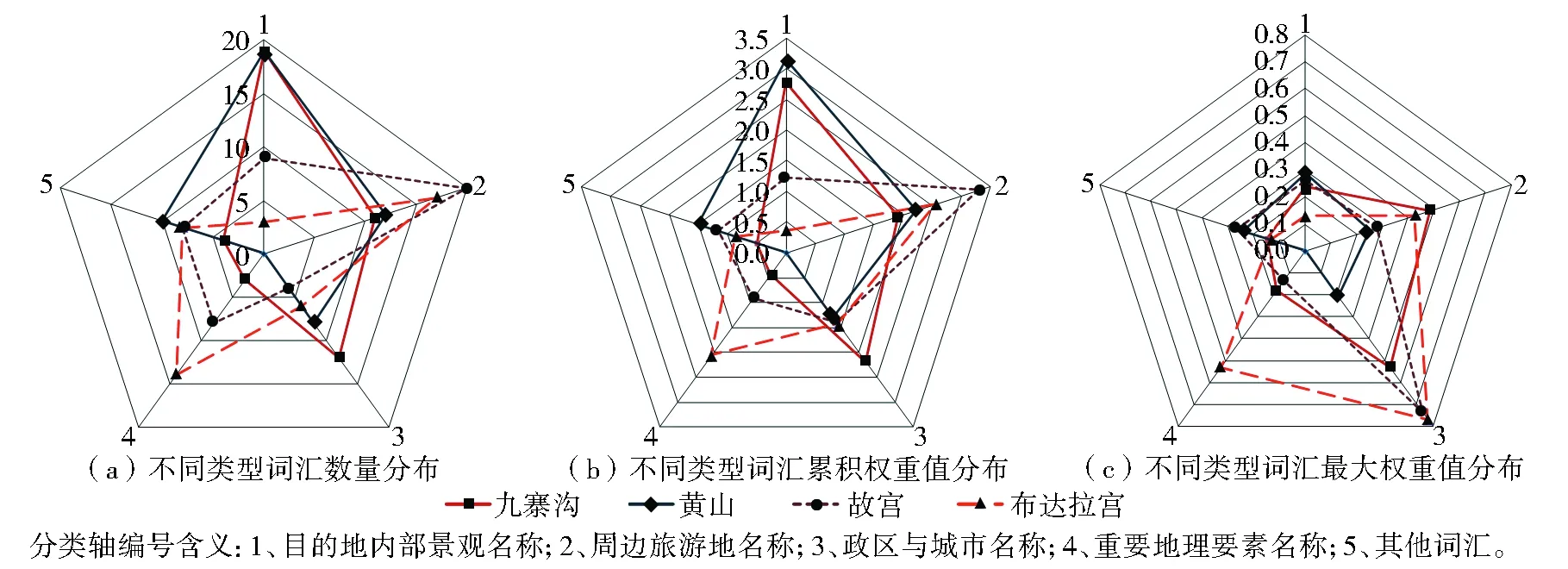
圖2 不同樣本旅游地游記文本中權重值前100位的詞匯類型結構對比
Fig.2 Comparison of top 100 words of different sample travel blog texts
分析結果直接體現了游客在描述不同類型旅游地時記述方式的差異。由于自由撰寫的旅行游記是旅游者記錄旅行過程中的所見、所聞、所感的真實體現,因此,游記熱度詞匯的應用模式和類型結構也能間接反映旅游者對不同旅游目的地的認知差異。
4 結論與討論
不同于已有基于文本的地名提取方法,本文基于大量網絡游記文本提取熱度旅游地名的思路充分利用了地名在旅游者自由撰寫的游記文本中的重要地位,同時利用同一旅游地和不同旅游地游記文本集合在地名與其他詞匯使用上的共性和差異特征進行提取方法設計。以黃山、九寨溝、故宮和布達拉宮4個旅游地為樣本的實驗結果顯示,每個旅游地統計結果加權排序前200位的熱度詞匯均以該旅游地相關的地名為主,充分證明該方法能夠較好地實現熱度較高的旅游地和景觀名稱提取。
本文提取方法能夠一定程度上解決基于大量自由描述文本開展旅游地理學研究的難點,使研究視角進入旅游地內部的較小空間尺度,并能夠有效與更大空間尺度整合研究,也可以作為旅游地非標準化地名庫建設的技術支撐。結果分析初步證明了地名與景觀名稱在旅游者自由撰寫的旅游文本中的核心地位和研究價值,同時也為基于其他熱度詞匯的旅游學提供了空間研究視角和思路。ATF*PDF方法獲得的綜合權重值反映了地名及其相關詞匯在游記文本集合中的整體重要程度,能夠指示旅游者對旅游景觀關注程度的高低,可以為后續旅游地景觀關注度、景觀認知與評價和旅游者行為的時空特征等研究提供參考,也能夠通過旅游地相關地名的熱度演變及時追蹤旅游者的景觀認知演化過程,對于準確把握和解釋旅游目的地形象演化過程和機理,適時調整不同類型旅游目的地管理制度和政策也具有參考意義。本文提取方法還為不使用自定義地名庫的旅游地理研究提供了可能,在一定程度上避免了自定義詞庫方式帶來的主觀性影響。但本文方法對文本規模具有一定要求,適合提取關注度較高的熱度地名,對旅游者使用熱度較低的詞匯則不適用。
[1] 王佳果,王堯.基于NVivo軟件的互聯網旅游文本的質性研究——以貴州黔東南肇興的旅游者文本為例[J].旅游論壇,2009,2(1):30-34.
[2] 苗學玲,保繼剛.“眾樂樂”:旅游虛擬社區“結伴旅行”之質性研究[J].旅游學刊,2007,22(8):48-54.
[3] BANYAI M,GLOVER T D.Evaluating research methods on travel blogs[J].Journal of Travel Research,2012,51(3):267-277.
[4] 趙振斌,黨嬌.基于網絡文本內容分析的太白山背包旅游行為研究[J].人文地理,2011,26(1):134-139.
[5] 肖亮,趙黎明.互聯網傳播的臺灣旅游目的地形象——基于兩岸相關網站的內容分析[J].旅游學刊,2009,24(3):75-81.
[6] CHOI S,LEHTO X Y,MORRISON A M.Destination image representation on the web:Content analysis of Macau travel related Websites[J].Tourism Management,2007,28(1):118-129.
[7] LI X,WANG Y C.China in the eyes of western travelers as represented in travel blogs[J].Journal of Travel and Tourism Marketing,2011,28(7):689-719.
[8] 唐順英,周尚意.文本在游客地方感建構中的作用研究——基于曲阜游記的分析[J].地理與地理信息科學,2013,29(2):100-104.
[9] GOVERS R,GO F M.Projected destination image online:Website content analysis of pictures and text[J].Information Technology &Tourism,2004,7(2):73-89.
[10] WANG H Y.Investigating the determinants of travel blogs influencing readers′ intention to travel[J].The Service Industries Journal,2012,32(2):231-255.
[11] GOODCHILD M F.Citizens as voluntary sensors:Spatial data infrastructure in the world of Web 2.0[J].International Journal of Spatial Data Infrastructures Research,2007(2):24-32.
[12] GOLDBERG D W,WILSON J P,KNOBLOCK C A.Extracting geographic features from the Internet to automatically build detailed regional gazetteers[J].International Journal of Geographical Information Science,2009(1):93-128.
[13] 張雪英,張春菊,閭國年.地理命名實體分類體系的設計與應用分析[J].地球信息科學學報,2010,12(2):220-227.
[14] 劉瑜,張毅,田原,等.廣義地名及其本體研究[J].地理與地理信息科學,2007,23(6):1-7.
[15] 俞鴻魁,張華平,劉群,等.基于層疊隱馬爾可夫模型的中文命名實體識別[J].通信學報,2006,27(2):87-94.
[16] 唐旭日,陳小荷,張雪英.中文文本的地名解析方法研究[J].武漢大學學報(信息科學版),2010,35(8):930-935.
[17] LI L,DING Z,HUANG D.Recognizing location names from Chinese texts based on max-margin network[A].International Conference on Natural Language Processing and Knowledge Engineering[C].2008.19-22.
[18] 唐旭日,陳小荷,許超,等.基于篇章的中文地名識別研究[J].中文信息學報,2010,24(2):24-32.
[19] 黃德根,岳廣玲,楊元生.基于統計的中文地名識別[J].中文信息學報,2003,17(2):36-41.
[20] 張春菊,張雪英,朱少楠,等.基于網絡爬蟲的地名數據庫維護方法[J].地球信息科學學報,2011,13(4):492-499.
[21] 黃昌寧,趙海.中文分詞十年回顧[J].中文信息學報,2007,21(3):8-19.
[22] 劉群,張華平,俞鴻魁,等.基于層疊隱馬模型的漢語詞法分析[J].計算機研究與發展,2004,41(8):1421-1429.
[23] 楊潔,季鐸,蔡東風,等.基于聯合權重的多文檔關鍵詞抽取技術[J].中文信息學報,2008,22(6):75-79.
[24] BUN K K,ISHIZUKA M.Topic extraction from news archive using TF*PDF algorithm[A].Proceedings of the 3rd International Conference on Web Information Systems Engineering[C].Singapore:IEEE CS Press,2002.73-82.
[25] 胡志敏.基于綜合權重的多文檔關鍵詞抽取算法[J].計算機與數字工程,2010,38(6):45-48.
Method and Case Study of Hot-Toponym Extraction from Mass Amount of Internet Travel Blog Text
LI Zhao-hang1,GUO Feng-hua2,LI Ren-jie1,3,FU Xue-qing1,3,YAN Zheng-feng1,3
(1.CollegeofResourceandEnvironmentScience,HebeiNormalUniversity,Shijiazhuang050024; 2.InstituteofGeographicalSciences,HebeiAcademyofSciences,Shijiazhuang050021; 3.HebeiKeyLaboratoryofEnvironmentalChangeandEcologicalConstruction,Shijiazhuang050024,China)
This paper discusses the characteristics of toponyms being used in text of Internet travel blog and the significance of this research.The toponyms in Internet travel blog refer to place names or landscape names in tourism.The quantitatively characteristics of toponyms used in travel blog can reflect the cognition structure and the common process of tourists.Depending on the existing Chinese Word Segmentation foundation and the characteristics of toponym in travel blog,this paper selects and uses the ATF*PDF method to calculate the joint weight of characteristic words in the whole travel blog collection.Design an automatic method of hot-toponym extraction from mass amount of text of Internet travel blog,laid the foundation of tourism geography research without manually defined gazetteer.The result of case study indicates that the method can extract tourism related toponym from text quickly.The hotter toponym has higher accuracy.The paper finds out the commonalities and differences in toponyms when being used in natural and cultural travel blog.This could help us find the meaning and potential value of toponyms in travel process by data interpretation.
text of Internet travel blog;hot-toponym;ATF*PDF model;multiple sample collection co-occurrence
2014-07-01
國家自然科學基金項目(41101105、41171105);河北省軟科學研究計劃項目(13406002D);河北省高校重點學科建設項目
李照航(1989-),男,碩士研究生,研究方向為地理信息可視化。*通訊作者E-mail:lrjgis@163.com
10.3969/j.issn.1672-0504.2015.01.015
F590
A
1672-0504(2015)01-0068-06
猜你喜歡
現代裝飾(2021年6期)2021-12-31 05:27:54
中華胰腺病雜志(2021年1期)2021-02-26 11:28:36
小學科學(學生版)(2020年12期)2021-01-08 09:28:10
山東醫藥(2020年34期)2020-12-09 01:22:24
少年漫畫(藝術創想)(2020年12期)2020-06-09 05:50:08
制造技術與機床(2019年10期)2019-10-26 02:48:08
中華胰腺病雜志(2019年4期)2019-08-29 08:52:20
電子制作(2018年18期)2018-11-14 01:48:06
小學教學參考(2015年20期)2016-01-15 08:44:38
中國攝影家(2014年6期)2014-04-29 14:54:47
