基于散列值的文件碎片與原始文件一致性檢驗方法研究
2015-05-30 07:55:58趙廣曄
科技創新與應用 2015年16期
趙廣曄
摘 要:在侵犯知識產權、網絡入侵等案件的計算機司法檢驗過程中,經常需要檢驗存儲介質中是否存在被泄露文檔、植入的木馬等。而在實際鑒定過程中,往往只能找到一些文件碎片,那么如何檢驗原始文件與文件碎片之間的一致性關系就成了一個值得深入探討的問題。文章提出了一種基于散列值的文件碎片與原始文件一致性檢驗的方法。
關鍵詞:電子文件;文件碎片;同一性檢驗;散列值
引言
在進行計算機司法鑒定的過程中,經常需要進行文件的一致性檢驗。根據GA/T 827-2009《電子物證文件一致性檢驗技術規范》,比較兩個文件的散列值,若兩個散列值相同,則可以判斷兩個文件的數據相同;若兩個散列值不同,則可以判斷兩個文件的數據不同[1]。但在實際檢驗的過程中,嫌疑人往往會對證據文件及其存儲介質進行刪除或格式化等操作,通常只能夠找到一些文件碎片。因此,如何對文件碎片與原始文件的一致性關系進行鑒定就成為了相關案件鑒定過程中的一個難點。
1 文件碎片的產生原因及其與原始文件的關系
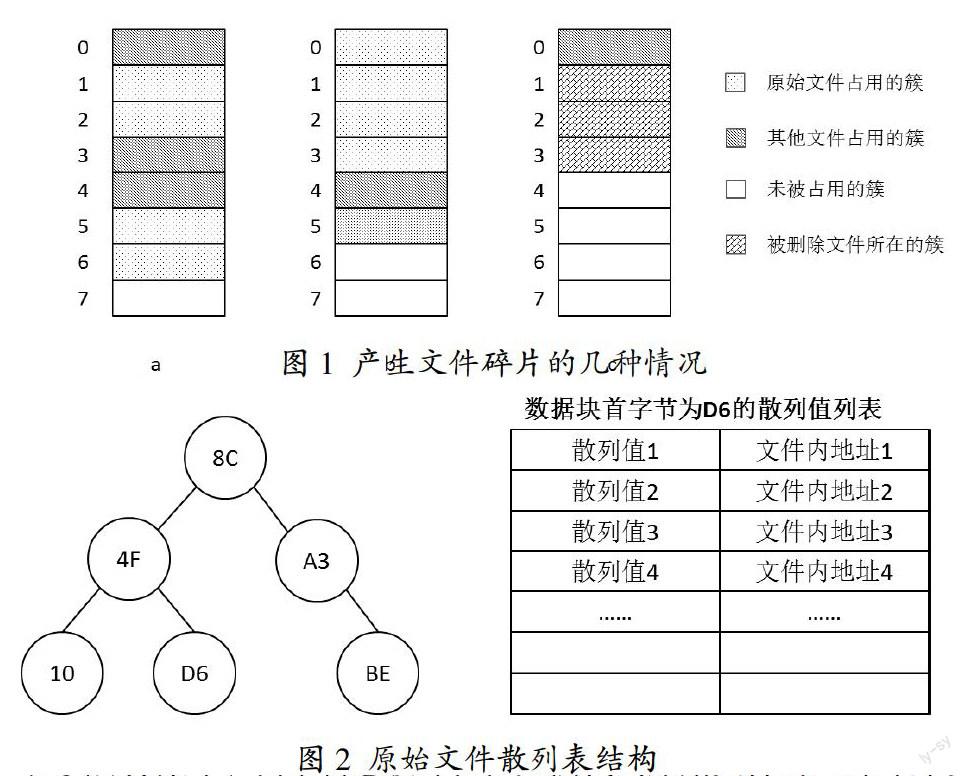
圖1 產生文件碎片的幾種情況
文件碎片是指由于文件在磁盤中不連續存儲而產生的文件分塊。圖1為產生文件碎片的幾種情況:(1)原始文件大小為4個簇,磁盤中的0、3、4三個簇已經被其他文件占用,因此文件被分別存儲在1-2和3-4兩部分簇中,形成了兩塊文件碎片;(2)文件的原始原本存放在磁盤的0-3簇,另一個文件存儲在簇4中,現在對文件進行編輯使其長度增加到5個簇,在保存時新增加的內容將保存在簇5中,產生了新的文件碎片;(3)文件原來存放在磁盤的0-3簇,被刪除后,簇0位置又存儲了另一個文件,這樣1-3三個簇就形成了文件碎片。由此可見,文件碎片實際上就是原始文件中的一部分。但是實際辦案中,由于蓄意破壞往往無法找到原始文件的全部碎片。鑒定檢材中是否曾經存在原始文件就成了一個難題。
2 檢驗方法設計
由上述內容可知,只需要驗證檢材中的文件碎片與原始文件中的部分內容完全一致,即可認定該碎片屬于原始文件。為此,文章提出了一種基于散列值的文件碎片與原始文件一致性檢驗的方法。該方法的具體操作步驟如下:(1)將原始文件等分為大小為N字節的塊,分別計算散列值并生成散列表。該散列表結構包含兩部分:塊索引樹,以分塊起始字節為結點關鍵字的二叉樹,見圖2左側部分;散列值索引表,記錄原始文件中以指定字節為起始的塊的散列值及其在原始文件內的偏移地址,見圖2右側部分,該列表存放在對應的結點中。(2)對目標文件碎片進行遍歷,如果字節值與塊搜索樹節點匹配,則計算N個字節的散列值,并在散列索引表中搜索,記錄匹配項。(3)按原始文件內偏移地址整理遍歷結果,生成一致性檢驗報告。
3 檢驗方法的實現及驗證
(1)原始文件散列表的數據結構。設原始文件的大小為T字節,拆分塊大小為N字節,拆分塊的總數量為S。若文件分塊的起始字節共有X種值,也就是在構建塊索引樹時需要進行X次結點的插入操作,那么需要進行查找操作的次數Y=S-X。塊索引樹的結構定義如下:
typedef struct BlockIndexTreeNode
{
byte startByte;
HashTable hashTable;
struct BlockIndexTreeNode *leftChild, *rightChild;
}BlockIndexTreeNode, *BlockIndexTree;
在構建各個結點的散列值索引表時共需要進行S次插入操作,而且為了便于比對需要將索引表項按照散列值進行排序。散列值索引表結構定義如下:
typedef struct HashListNode
{
byte[] hashValue;
long inFileOffset;
struct HashListNode *next;
}HashListNode;
(2)構建散列表的文件分塊大小的界定。通過前面的分析可知,拆分塊總數量S=T/N或[T/N]+1,構建塊索引樹時需要進行Y=S-X次查詢。即Y=T/N-X或T/N-X+1。由于X值很小。T為固定值,因此由N決定索引表構建速度,N值越大,散列表的構建和搜索比對速度就越快。但是,如果N值過大,就會導致比對結果不準確。文件系統對磁盤的管理單位為簇,因此N的值不應該大于簇的大小。同時,為更精確的檢驗碎片文件與原始文件一致性,碎片文件應該可以劃分成多個大小為N字節的塊。另外,因為常用的散列值大于等于16字節,若N值小于16字節則會降低檢驗效率。綜上所述,文件分塊大小N的計算方法如下:
N=MIN(簇大小,T/原始文件拆分度,MAX(16,碎片大小/碎片分析粒度))。
其中原始文件拆分度可以調節檢驗結果中的量化值精度,值越大精度越高;碎片分析粒度可以調節文件碎片被損壞對檢驗的影響,值越大影響越小。
(3)文件碎片的搜索比對方法。在比對的過程中對要檢驗的文件碎片進行按字節遍歷,如果當前字節存在于塊索引樹中,則從計算N個連續字節的散列值,并在散列值索引表中查找,并記錄匹配項。最后用匯總記錄的結果生成一致性檢驗報告。
(4)檢驗方法的驗證。首先,準備一些原始文件并制作文件碎片存放在測試檢材中。其次,模擬文件碎片被破壞的情況。之后,從檢材中提取可能的文件碎片。最后,使用文章提出的檢驗方法來檢驗提取出的文件碎片與原始文件的一致性。通過測試發現:以扇區為單位的方式進行遍歷可以大幅提高效率,但是部分情況無法匹配命中;逐字節進行遍歷執行速度很慢,但是得到的檢驗結果精度很高。因此,提取出的文件碎片比較大的情況下,應當優先考慮以扇區為單位構建散列表和遍歷文件碎片,否則應當考慮縮小N值并進行逐字節進行遍歷。
4 結束語
文章基于散列值的文件碎片與原始文件一致性檢驗方法可以檢驗出文件碎片是否與原始文件部分匹配,并可以量化的給出一致性檢驗結果。由此可見,該方法解決了在檢驗過程中遇到檢材被破壞的情況下檢驗檢材中的文件碎片與原始文件一致性的問題。
