城鄉個人收入差距的分位數因果效應估計
2015-05-30 21:44:57韓開山黃群周曉華
現代管理科學 2015年2期
韓開山 黃群 周曉華


摘要:文章深入研究了中國健康和營養調查數據庫(CHNS)中的成人調查數據,發現影響城鄉收入的協變量存在不平衡。文章提出利用傾向值方法對數據加權,使得數據平衡,利用加權分位數因果效應方法和改進的加權分位數因果效應方法估計城鄉收入差距。研究表明,城鄉個人收入存在較大差距,同時隨著收入水平的提升,這種差距有增大的趨勢,但城鄉個人收入的相對差距隨著收入水平的提升變化并不顯著。特困人群中,城鄉個人收入的相對差距為33.3%,中等收入以下群體,相對差距小于20%,中等收入以上群體,相對差距介于25%~36%之間。
關鍵詞:傾向值;分位數回歸;分位數因果效應
一、 引言
我國是典型的城鄉二元經濟結構,從1993年~2012年,農村居民家庭人均總收入由1 333.82提高到10 990.67元,增長了近8.24倍,城鎮居民家庭人均總收入由2 583.16提高到26 958.99元,增長了近10.44倍[中經網統計數據庫]。城鄉居民家庭人均收入比從1.94∶1擴大到2.45∶1,城鄉居民人均收入的差距沒有遞減的趨勢。城鄉二元經濟結構對家庭人均收入的影響,國內外學者已經進行了大量的研究。郭劍熊認為低人力資本積累率和高生育率是造成城鄉收入不平等的主要原因。姚先國等分析了城鄉居民收入不平等主要是由人力資本水平差異和就業差異造成的。段景輝等利用分位數回歸分別對影響城鄉家庭人均收入的因素進行了分析,并利用Rubin的反事實理論和Machado和Mata的分位數分解方法對城鄉收入差距進行了分解,說明勞動力教育水平、工作年限等是造成差距的主要原因。陳建寶等利用分位數回歸分析的方法對中國性別工資差距進行了分析,找出影響性別工資的因素。但這些文獻數據都是一個非隨機化試驗,兩類人員的協變量分布是很不平衡的,按照隨機試驗的方法做分位數回歸處理具有一定的偏差,即容易產生內生性問題。
強可忽略假設是研究處理效果時廣泛使用的基本假設。Hahn基于這個假設和非參數估計兩條件回歸函數提出了一種估計量,并給出了其有效界。由于Rosenbaum和Rubin所作的工作,越來越多的人避免直接調節協變量,而改用估計傾向值來調節估計方法,其中一個主要的方法就是利用傾向度對觀測數據進行加權,以使得處理組和對照組達到平衡。
Firpo提出先利用半參的方法估計出傾向值,再利用加權傾向值估計分位數處理效應,并證明了這種方法為是一致收斂、近似正態,能取到半參有效界,Fr?觟lich和Melly證明了利用Logistic回歸計算傾向值,并能取到利用半參的估計方法相同的性質,即該方法是一致收斂、近似正態,能取到半參有效界,本文在計算傾向值時采用了Logistic回歸方法。
本文在前人的研究成果的基礎上,利用中國健康和營養調查數據庫(CHNS)中的2006年成人調查數據表的微觀數據,利用加權分位數因果效應方法和改進的加權分位數因果效應方法對城鄉個人收入差距進行深入分析,找到影響城鄉個人收入差距的因素、城鄉個人收入差距和城鄉個人收入相對差距在不同收入階層的分布特征。
二、 數據分析
本文數據取自中國健康和營養調查數據庫(CHNS)2006年成人調查數據,該數據采用多層次隨機抽樣方法得到,選取東部(遼寧、江蘇、山東、廣西)、中部(河南、湖南、湖北)、西部(貴州)八個省份進行抽查。農村樣本6 428個,城市樣本3 360個,但由于收入數據的很大缺失,本文所采用的數據時剔除掉缺失數據后的農村樣本915個,城市樣本798個。本文研究的目的是了解不同收入層次上城鄉個人收入的差距,以及差距的分布特征。
1. 數據描述。依據抽樣調查數據,分別計算以農村、城市為調查對象的年齡、受教育年限、工作年限、收入的均值、中值、標準差、并做正態性檢驗,結果發現,農村和城市人口在年齡、工作年限上沒有顯著差異,農村的教育年限平均要比城市的受教育年限低1.5年,農村人口的年平均收入比城市人口的年平均收入低4 803.54元。從正態性檢驗看,這幾個變量都不服從正態分布。下表計算不同收入水平下城鄉收入的差異。
從表1看,在不同收入水平下,城市人口的收入都大于農村人口的收入,并且從收入的差可以看出,隨收入水平的增高,城市和農村收入的差也相應的提高,從低收入人群(5%)的收入差1 200元,到高收入人群(95%)的收入差8 730元。這種純收入的差別沒有考慮到個體的差異,比如,城市人口的受教育年限比農村人口高1.5年,而這種個體之間的差異的影響,勢必反應到個體收入的差異上。因此,城鄉二元結構所造成的收入差距,不能簡單的取城鄉人口收入的差,而應該是所有影響個人收入的影響因素都相同的條件下,城鄉人口收入的差。因此本文研究的第一步要求數據的協變量達到分布相同。
2. 數據的平衡性檢驗。本文中以個人收入作為因變量Y,個人所處的狀態(城市或農村)為處理指標T,T=1表示個人來自城市,T=0表示個人來自農村,X為影響Y,T的協變量,包括受教育年限(Edulong),工作年限(Occuplong),工作經驗的邊際效率(Occupymargin),職業(Occupation),工作屬性(Character),地區(Area)其中職業分為管理人員、專門技術人才、辦事人員、服務人員、農林牧漁人員、制造業和運輸人員、軍人,工作屬性分為政府機關、國有企事業單位、集體企事業單位、私有制企業,地區分為東部地區、中部地區、西部地區。
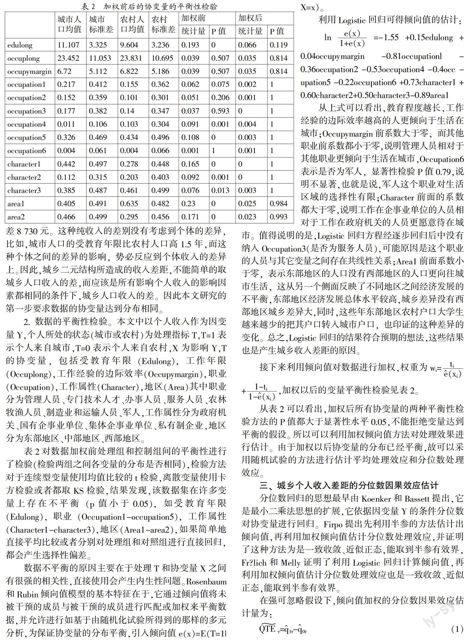
表2對數據加權前處理組和控制組間的平衡性進行了檢驗(檢驗兩組之間各變量的分布是否相同),檢驗方法對于連續型變量使用均值比較的t檢驗,離散變量使用卡方檢驗或者都取KS檢驗,結果發現,該數據集在許多變量上存在不平衡(p值小于0.05),如受教育年限(Edulong),職業(Occupation1-occupation5),工作屬性(Character1-character3),地區(Area1-area2),如果簡單地直接平均比較或者分別對處理組和對照組進行直接回歸,都會產生選擇性偏差。
數據不平衡的原因主要在于處理T和協變量X之間有很強的相關性,直接使用會產生內生性問題。Rosenbaum和Rubin傾向值模型的基本特征在于,它通過傾向值將未被干預的成員與被干預的成員進行匹配或加權來平衡數據,并允許進行如基于由隨機化試驗所得到的那樣的多元分析,為保證協變量的分布平衡,引入傾向值e(x)=E(T=1|X=x)。
利用Logistic回歸可得傾向值的估計:
ln■=-1.55+0.15edulong+0.04occupymargin-0.81occupationl-0.36occupation2-0.53occupation4-0.4occ-upation5-0.22occupation6+0.73character1+0.60character2+0.50character3-0.89area1
從上式可以看出,教育程度越長,工作經驗的邊際效率越高的人更傾向于生活在城市;Occupymargin前系數大于零,而其他職業前系數都小于零,說明管理人員相對于其他職業更傾向于生活在城市,Occupation6表示是否為軍人,顯著性檢驗P值0.79,說明不顯著,也就是說,軍人這個職業對生活區域的選擇性有限;Character前面的系數都大于零,說明工作在企事業單位的人員相對于工作在政府機關的人員更愿意待在城市。值得說明的是,Logistic回歸方程經逐步回歸后中沒有納入Occupation3(是否為服務人員),可能原因是這個職業的人員與其它變量之間存在共線性關系;Area1前面系數小于零,表示東部地區的人口沒有西部地區的人口更向往城市生活,這從另一個側面反映了不同地區之間經濟發展的不平衡,東部地區經濟發展總體水平較高,城鄉差異沒有西部地區城鄉差異大,同時,這些年東部地區農村戶口大學生越來越少的把其戶口轉入城市戶口,也印證的這種差異的變化。總之,Logistic回歸的結果符合預期的想法,這些結果也是產生城鄉收入差距的原因。
接下來利用傾向值對數據進行加權,權重為wi=■+■,加權以后的變量平衡性檢驗見表2。
從表2可以看出,加權后所有協變量的兩種平衡性檢驗方法的P值都大于顯著性水平0.05,不能拒絕變量達到平衡的假設。所以可以利用加權傾向值方法對處理效果進行估計。由于加權以后協變量的分布已經平衡,故可以采用隨機試驗的方法進行估計平均處理效應和分位數處理效應。
三、 城鄉個人收入差距的分位數因果效應估計
分位數回歸的思想最早由Koenker和Bassett提出,它是最小二乘法思想的擴展,它依據因變量Y的條件分位數對協變量進行回歸。Firpo提出先利用半參的方法估計出傾向值,再利用加權傾向值估計分位數處理效應,并證明了這種方法為是一致收斂、近似正態,能取到半參有效界,Fr?lich和Melly證明了利用Logistic回歸計算傾向值,再利用加權傾向值估計分位數處理效應也是一致收斂、近似正態,能取到半參有效界。
在強可忽略假設下,傾向值加權的分位數因果效應估計量為:
■?子=q1?子-q0?子(1)
q1?子=infq■■■?叟?子,
q0?子=infq■■■?叟?子
從(1)式和(2)式可以看出,當樣本容量有限,傾向值接近0或1時,該估計量不一定有效,也就是,當個體i接收處理組治療的概率很小時,個體i在估計因果效果時提供了一個很大的權重。簡單地一個改進方法是改進其權重,使得權重之和為1。
改進的權重為wwi=■■-1■+■■-1■(3)
改進的加權傾向值估計量:
■?子=q1?子-q0?子(4)
qw1?子=infq■■-1■■?叟?子,
qw0?子=infq■■-1■■?叟?子(5)
可以證明,在一些正則條件下,改進的加權傾向值估計方法是一致無偏的。同時,改進的加權傾向值的優點的是利用了傾向值,可以平衡數據,降低混雜變量的維數。
因果效應的算法如下:
步驟1 應用Logistic回歸估計傾向值e(xi)。
步驟2利用傾向值e(xi)計算的權重wi=■+■對數據進行加權,此時,如果數據已經是平衡數據,故可以采用隨機試驗的方法進行估計平均處理效應和分位數處理效應,如果數據還不平衡,可以按照不平衡的變量對數據進行分層,在每一層內保證數據是平衡的,在每一層中采用隨機試驗的方法進行估計平均處理效應和分位數處理效應。本文加權以后數據已經平衡,所以沒有采用分層的技術。
步驟3 利用ATE=■■-1■■-■■-1■■求得城鄉收入差距的平均處理效應ATE。
利用公式(4)(5)計算■?子,即求得了在?子分位數下的分位數因果效應,即在?子分位數下的收入的差距,記為WQTE。
計算結果見表3。
由表3可以看出,三種方法下,低收入水平下(分位數較小時),城鄉收入差距較小,隨著收入水平的提高(分位數不斷增大),城鄉收入差距不斷增大。平均處理效應為4 027,說明城鄉收入差距的平均值為4 027,該值遠大于用城鄉收入的中位數差距(三種分位數方法的中位數差距分別為2 200,1 417,1 200),其中的原因歸結為該數據集中城鄉收入的異常點較多,并且異常點都為高收入人。
對于ydiff方法,由于沒有考慮協變量X的影響,僅僅是兩組收入在不同分位數的比較,得到的收入差距最大,從最小的1 200到最大8 748.6。對于reg.QTE方法,增加了協變量X的調節,但是,協變量在兩組之間分布存在差異,直接的增加協變量調節容易產生選擇性偏差,其估計的城鄉收入差距在分位數在10%時收入差距為580,在95%分位數時收入差距為5 386,達到最大。這種方法得到的城鄉收入差距在各收入水平上都低估了城鄉差距。對于WQTE方法,有效的利用傾向值進行加權,估計的城鄉差距介于ydiff和reg.QTE之間,最小差距在15%分位數時,城鄉收入差距為480元,從檢驗看,該分位點城鄉收入沒有顯著差異。最大差距為95%分位數時的7 000元。
結合傾向值的估計方程可以得到,教育程度越長,工作經驗的邊際效率越高的人更傾向于生活在城市,會加劇城鄉的收入差距。同理,職業前的系數都為負值,工作屬性前的系數都為正值,地區前的系數為負值,說明職業、工作屬性、地區這些變量都通過影響傾向值,從而影響城鄉收入差距。
定義第?子分位數下城鄉收入差距的相對值為:reletive.diff?子=QTE?子/q0?子,其中q0?子表示農村收入的第?子分位數。從表3可以看出,在5%分位點處,WQTE得到的城鄉收入差距的相對值為33.3%,在最低收入人群中,城市人口的收入是農村人口收入的1.333倍,這部分收入差距的原因是城市低保水平要比農村的低保水平高,維持人民生活的最低生活水平農村要比城市人口低很多。從10%到55%分位點之間,WQTE得到的城鄉收入差距的相對值都小于等于20%。從60%到95%分位點之間,WQTE得到的城鄉收入差距的相對值介于0.25%到36%之間,這一部分人群中,城鄉收入差距的相對值稍有增大。整體來說,城鄉收入差距的相對值沒有隨收入水平的增大產生顯著的增大,只是有小幅的改變。
四、 結論
本文首先對中國健康和營養調查數據庫(CHNS)2006年成人調查數據進行統計描述,發現影響收入結果的因素在城鄉兩組之間存在較大的分布不一致性,直接使用分位數回歸方法會產生選擇性偏差,故提出使用加權的分位數回歸方法,并在假設1的條件下證明這種加權的分位數回歸方法是無偏的。
通過傾向值對數據進行加權,再利用分位數回歸的方法估計出了在不同分位點下城鄉收入的差距。同時比較說明了y.diff方法、reg.QTE方法、WQTE方法的估計結果的區別。從調查數據中可以得到在在低收入階層中,城鄉收入差距較小,在高收入階層中,城鄉收入差距較大,并且隨著收入水平的提高(分位數不斷增大),城鄉收入差距不斷增大。通過城鄉收入差距的相對值,知最低收入人群中,由于最低生活保障體制的不同,引起收入差距的相對值較大,其它收入階層中,城鄉收入差距的相對值變化只是有小幅改變。
現階段,城鄉收入達到絕對的公平是不太可能的,那么如何縮小城鄉收入差距,我們應該按照影響城鄉收入差距的原因及差距的具體特點入手:(1)教育機會不均等是導致城鄉收入差距的一個關鍵因素,為縮小這種不平等,國家必須對農村地區增加教育投入,增加農村低收入人群接受教育的機會。同時實施農民工技能培訓工程,逐步培養使用于現代科技進步的技工人才。(2)地區經濟發展不平衡也是導致城鄉收入差距的一個重要原因。針對中、西部地區經濟發展水平和收入水平落后于東部地區的現狀,各地政府應因地制宜發展具有地區特色的產業經濟、農村經濟。(3)提高農村最低生活保障水平,縮小城鄉城鄉保障制度的差別。
參考文獻:
1. 郭劍熊.人力資本、生育率與城鄉收入差距的收斂.中國社會科學,2005,(2):27-37.
2. 姚先國.中國勞資關系的城鄉戶籍差異.經濟研究,2004,(7):82-90.
3. 段景輝,陳建寶.我國城鄉家庭收入差異影響因素的分位數回歸解析.經濟學家,2009,(9):46-53.
4. Machado J, Mata J. Counterfactual Decomposition of Changes in Wage Distributions Using Quantile Regression.Journal of Applied Econometrics,2005,(20):445-465.
5. 陳建寶,段景輝.中國性別工資差異的分位數回歸分析.數量經濟技術經濟研究,2009,(10):87-97.
6. Rubin D.Estimating Causal Effects of Tr- eatment in Randomized and Nonrandomized Studies. Journal of Educational Psychology,1974,(66):688- 701.
基金項目:國家自然科學基金資助項目(項目號:11226165)。
作者簡介:周曉華(1963-),男,漢族,重慶市人,中國人民大學統計學院教授、博士生導師,研究方向為生物統計;韓開山(1978-),男,漢族,山西省夏縣人,中北大學理學院講師,中國人民大學統計學院博士生;黃群(1972-),女,漢族,四川省眉山市人,北京城市學院副教授,研究方向為經濟統計。
收稿日期:2014-12-21。
