基于邊權(quán)重的主題核心術(shù)語(yǔ)抽取
2015-05-30 22:06:44薛涵秦兵劉挺
智能計(jì)算機(jī)與應(yīng)用 2015年4期
薛涵 秦兵 劉挺
摘 要:術(shù)語(yǔ)抽取是層次體系構(gòu)建的首要子任務(wù)。目前的術(shù)語(yǔ)抽取研究主要集中在文本語(yǔ)料并且混合多個(gè)主題,存在知識(shí)獲取的瓶頸和術(shù)語(yǔ)表述的模糊與歧義的問(wèn)題。為了解決這些問(wèn)題,本文提出一種基于邊權(quán)重的主題核心術(shù)語(yǔ)抽取方法,從社會(huì)化標(biāo)簽中抽取主題核心術(shù)語(yǔ)。考慮到社會(huì)化標(biāo)簽豐富的語(yǔ)義關(guān)聯(lián)特征,本文提出結(jié)合具體主題的局部共現(xiàn)和資源集合中所有主題的全局語(yǔ)義相似度的邊權(quán)重。新穎的邊權(quán)重將傳統(tǒng)的隨機(jī)游走方法分解成多個(gè)主題相關(guān)的隨機(jī)游走,并針對(duì)每個(gè)具體主題排序相關(guān)的候選術(shù)語(yǔ)。排序靠前的術(shù)語(yǔ)被抽取作為主題核心術(shù)語(yǔ)。實(shí)驗(yàn)結(jié)果表明本文提出的方法顯著優(yōu)于前人的相關(guān)工作。
關(guān)鍵詞:術(shù)語(yǔ)抽取;社會(huì)化標(biāo)簽;主題核心術(shù)語(yǔ)抽取;主題相關(guān)的隨機(jī)游走
中圖分類(lèi)號(hào):TP391 文獻(xiàn)標(biāo)識(shí)號(hào):A
Topic Key Term Extraction based on Edge Weight
XUE Han1,2, QIN Bing1, LIU Ting1
(1 School of Computer Science and Technology, Harbin Institute of Technology, Harbin 150001, China;2 Library, Harbin Engineering University, Harbin 150001, China)
Abstract: Term extraction is a primary subtask of hierarchy construction. Existing studies for term extraction mainly focus on text corpora and indiscriminately mix numerous topics, which may lead to a knowledge acquisition bottleneck and misconception. To deal with these problems, this paper proposes a method of topic key term extraction based on edge weight to extract topic key term from folksonomy. In view of semantic association characteristics of folksonomy, the edge weight which combines the local co-occurrence in a specific topic with the global semantic similarity over all the topic dimensions in the whole collection considered is proposed. The new edge weight can decompose a traditional random walk into multiple random walks specific to various topics, and each of these walks outputs a list of terms ordered on the basis of importance score. Then, the top-ranking terms are extracted as the topic key terms for each topic. Experiments show that the proposed method outperforms other state-of-the-art methods.
Keywords: Term Extraction; Folksonomy; Topic Key Term Extraction; Topic-Sensitive Random Walk
0 引言
作為層次體系構(gòu)建的第一步,術(shù)語(yǔ)抽取是一項(xiàng)重要的子任務(wù)[1]。核心術(shù)語(yǔ)通常定義為可以概括語(yǔ)料所蘊(yùn)含語(yǔ)義主題內(nèi)容的一系列術(shù)語(yǔ)。語(yǔ)料往往包含多個(gè)主題,其中每個(gè)術(shù)語(yǔ)對(duì)于不同的主題會(huì)表達(dá)不同的含義。多個(gè)主題的共有術(shù)語(yǔ)在不同主題的重要性往往不同。混合主題衡量術(shù)語(yǔ)的重要性可能會(huì)導(dǎo)致某些不太常見(jiàn)或者新涌現(xiàn)出的主題核心術(shù)語(yǔ)無(wú)法被識(shí)別出來(lái)。例如,“牛仔”在“西部”主題中是核心術(shù)語(yǔ),而在其他主題中則是非核心術(shù)語(yǔ)。混合多個(gè)主題構(gòu)建的單一層次體系容易導(dǎo)致不同主題共有術(shù)語(yǔ)的模糊和歧義問(wèn)題,在同一個(gè)層次體系中用完全不同的含義定義同一個(gè)術(shù)語(yǔ)是不準(zhǔn)確的,然而忽略其中任何一個(gè)含義會(huì)導(dǎo)致無(wú)法完整詮釋術(shù)語(yǔ)的含義。為此,本研究提出抽取主題核心術(shù)語(yǔ),即根據(jù)從語(yǔ)料中學(xué)習(xí)得到的具體主題,抽取能夠較好地概括和描述該主題的內(nèi)容并與此主題下其他非核心術(shù)語(yǔ)密切相關(guān)的術(shù)語(yǔ)。例如,電影領(lǐng)域的主題核心術(shù)語(yǔ)通常有“喜劇”、“科幻”、“傳記”等。主題核心術(shù)語(yǔ)抽取是許多自然語(yǔ)言處理任務(wù)的基礎(chǔ),例如,信息檢索和導(dǎo)航、問(wèn)答、推薦系統(tǒng)等。
目前核心術(shù)語(yǔ)抽取研究主要基于領(lǐng)域文本語(yǔ)料,但是發(fā)現(xiàn)能夠準(zhǔn)確描述專(zhuān)業(yè)性較強(qiáng)或者主題變化較快的文本語(yǔ)料并非易事[2]。即便可以,人工遍歷所有的文本語(yǔ)料并且隨時(shí)跟蹤所有新出現(xiàn)的主題也幾乎是不可能完成的任務(wù)。例如,對(duì)于常見(jiàn)的電影主題“喜劇”來(lái)說(shuō),找到形式化定義和描述“喜劇”主題的文本語(yǔ)料相對(duì)容易,但是對(duì)于不太常見(jiàn)的主題“Cult”,發(fā)現(xiàn)類(lèi)似的文本語(yǔ)料則相對(duì)困難。但是,標(biāo)簽卻可以用“Cult”、“非主流”、“小成本”等自然語(yǔ)言詞匯更加輕松、自由地定義這樣的主題。正因?yàn)槿绱耍恍┭芯空唛_(kāi)始探索和嘗試使用社會(huì)化標(biāo)簽這種新興的語(yǔ)料。社會(huì)化標(biāo)簽[3]允許擁有不同專(zhuān)業(yè)知識(shí)的大量互聯(lián)網(wǎng)“草根”用戶(hù)使用任意詞匯(標(biāo)簽)自由標(biāo)注感興趣的資源并與他人分享,由于技術(shù)門(mén)檻低、用戶(hù)易于使用,因此蘊(yùn)含著豐富并且及時(shí)的互聯(lián)網(wǎng)大眾語(yǔ)義知識(shí)。互聯(lián)網(wǎng)用戶(hù)通過(guò)標(biāo)注、分享標(biāo)簽,瀏覽他人標(biāo)簽的過(guò)程,形成異步反饋并逐漸達(dá)成共識(shí)。在這個(gè)過(guò)程中產(chǎn)生了豐富的顯式和隱式關(guān)聯(lián)。顯式關(guān)聯(lián)存在于通過(guò)標(biāo)簽關(guān)聯(lián)的資源和用戶(hù)之間,隱式關(guān)聯(lián)存在于擁有相同興趣或社區(qū)的用戶(hù)之間,以及共享相同標(biāo)簽或者用戶(hù)的資源之間。在資源、標(biāo)簽、用戶(hù)三者之間的顯式和隱式關(guān)聯(lián)提供了潛在有價(jià)值的語(yǔ)義信息。標(biāo)簽作為候選術(shù)語(yǔ),已經(jīng)被廣大用戶(hù)人工抽取出來(lái),從而避免了一系列自然語(yǔ)言處理任務(wù)如分詞、詞性標(biāo)注、句法分析等。可見(jiàn),社會(huì)化標(biāo)簽相對(duì)于由少量領(lǐng)域?qū)<揖幾透碌奈谋菊Z(yǔ)料來(lái)說(shuō)能夠克服知識(shí)獲取的瓶頸。但是,從社會(huì)化標(biāo)簽中抽取主題核心術(shù)語(yǔ)至少面臨兩方面的挑戰(zhàn)。第一,社會(huì)化標(biāo)簽僅僅按照出現(xiàn)頻率簡(jiǎn)單排序并未區(qū)分主題。第二,標(biāo)簽由于大眾標(biāo)注的隨意性和模糊性,質(zhì)量差異很大。為了克服這些挑戰(zhàn),研究需要識(shí)別出主題,并按照主題排序和抽取出主題核心術(shù)語(yǔ)。
鑒于此,本文提出基于邊權(quán)重的主題核心術(shù)語(yǔ)抽取方法。考慮到中文語(yǔ)法的復(fù)雜性和可用研究資源不足的問(wèn)題,嘗試從中文社會(huì)化標(biāo)簽數(shù)據(jù)出發(fā)開(kāi)展研究,一來(lái)可以豐富中文研究資源和成果,二來(lái)可以體現(xiàn)社會(huì)化標(biāo)簽緩解知識(shí)獲取瓶頸的優(yōu)勢(shì)。需要說(shuō)明的是,提出的研究方法雖然基于中文數(shù)據(jù)源,但是無(wú)監(jiān)督而且語(yǔ)言無(wú)關(guān)的,可以應(yīng)用于更廣泛的語(yǔ)料和其他任何語(yǔ)言。具體地,研究首先通過(guò)LDA模型,從社會(huì)化標(biāo)簽數(shù)據(jù)中發(fā)現(xiàn)隱含的主題,并學(xué)習(xí)得到候選術(shù)語(yǔ)的主題分布。然后,分析社會(huì)化標(biāo)簽的語(yǔ)義關(guān)聯(lián)特征,提出由具體主題的局部共現(xiàn)信息和所有主題的全局語(yǔ)義相似度共同構(gòu)成的邊權(quán)重。進(jìn)而,通過(guò)邊權(quán)重改進(jìn)PageRank[4]方法,將傳統(tǒng)的隨機(jī)游走方法分解成多個(gè)主題相關(guān)的隨機(jī)游走,并針對(duì)每個(gè)具體主題排序相關(guān)的候選術(shù)語(yǔ)。最后,抽取排在最前面的候選術(shù)語(yǔ)作為主題核心術(shù)語(yǔ)。據(jù)現(xiàn)有成果所知,本研究工作在中文層次體系構(gòu)建領(lǐng)域尚屬首例。本文研究對(duì)方法進(jìn)行較詳細(xì)的分析,希望對(duì)此方向的未來(lái)研究有所助益。
1 基于邊權(quán)重的主題核心術(shù)語(yǔ)抽取
基于邊權(quán)重的主題核心術(shù)語(yǔ)抽取方法的核心思想是通過(guò)邊權(quán)重的設(shè)計(jì),將主題信息融入候選術(shù)語(yǔ)的重要性值傳播。首先,可從社會(huì)化標(biāo)簽抽取資源集合S和標(biāo)簽集合(候選術(shù)語(yǔ))V。由于標(biāo)簽反映了大眾對(duì)資源的認(rèn)識(shí),在此僅僅將用戶(hù)集合U的標(biāo)簽按照資源 組織成文檔。然后,給出假設(shè)資源集合S存在主題集合Z,每個(gè)候選術(shù)語(yǔ) 屬于多個(gè)語(yǔ)義主題,并且在不同主題下重要性不同。進(jìn)而,研究從資源集合中識(shí)別出主題。對(duì)于每個(gè)主題,根據(jù)候選術(shù)語(yǔ)的主題分布,計(jì)算結(jié)合局部和全局語(yǔ)義相似度的邊權(quán)重,并建立主題相關(guān)的候選術(shù)語(yǔ)組成的圖(見(jiàn)第1.1節(jié))。隨后,再將一個(gè)傳統(tǒng)的隨機(jī)游走方法分解成多個(gè)主題相關(guān)的隨機(jī)游走,并針對(duì)每個(gè)主題根據(jù)重要性值對(duì)候選術(shù)語(yǔ)排序(見(jiàn)第1.2節(jié))。最后,排序靠前的術(shù)語(yǔ)被抽取出來(lái)作為每個(gè)主題的核心術(shù)語(yǔ)。
1.1 主題識(shí)別
本文選擇使用無(wú)監(jiān)督的機(jī)器學(xué)習(xí)技術(shù)從資源集合中識(shí)別出主題并獲得每個(gè)候選術(shù)語(yǔ)的主題分布,而不是已標(biāo)注的語(yǔ)義知識(shí)庫(kù)(如,WordNet),因?yàn)槠渲械脑~匯并不能很好地覆蓋社會(huì)化標(biāo)簽。機(jī)器學(xué)習(xí)中的隱含主題模型能夠根據(jù)語(yǔ)料中詞的共現(xiàn)信息推斷隱含的主題。LDA[5]是隱含主題模型的代表,其中文檔d中的每個(gè)詞w的產(chǎn)生,是通過(guò)首先從d的主題分布θ中取出主題z,然后,從詞的分布Ф中取出能代表主題z的詞。θ和Ф分別來(lái)自共軛狄利克雷先驗(yàn)α和β。在此使用資源集合S作為L(zhǎng)DA模型的輸入,其中每個(gè)資源是由用戶(hù)集合U對(duì)其打出的標(biāo)簽組成的文檔。通過(guò)LDA,對(duì)于給定主題 ,則通過(guò)公式(1)獲得每個(gè)候選術(shù)語(yǔ) 的主題分布 。
(1)
進(jìn)而,又通過(guò)公式(2)和(3)分別計(jì)算出候選術(shù)語(yǔ)之間的局部和全局語(yǔ)義相似度。
(2)
(3)
代表候選術(shù)語(yǔ)wi和wj之間的局部語(yǔ)義相似度(見(jiàn)公式(2)),反映了候選術(shù)語(yǔ)對(duì)于具體主題的局部共現(xiàn)信息。其中, 計(jì)算為候選術(shù)語(yǔ)wi和wj在同一個(gè)資源 中共現(xiàn)并且屬于同一個(gè)主題z的次數(shù)。 計(jì)算為候選術(shù)語(yǔ)wi和wj在同一個(gè)資源 中共現(xiàn)的次數(shù)。 代表候選術(shù)語(yǔ)wi和wj之間的全局語(yǔ)義相似度,通過(guò)將公式(1)代入公式(3)計(jì)算得到,定義為兩個(gè)候選術(shù)語(yǔ)wi和wj在整個(gè)資源集合S中所有主題維度上的余弦相似度,反映了候選術(shù)語(yǔ)對(duì)于整個(gè)主題集合的全局語(yǔ)義相似度。
1.2 術(shù)語(yǔ)排序
PageRank[4]是計(jì)算網(wǎng)頁(yè)重要性的著名圖排序算法,也可以用于計(jì)算術(shù)語(yǔ)的重要性。如果有邊存在于節(jié)點(diǎn)wi和wj之間,研究就用節(jié)點(diǎn)集合 和邊集合 組成圖 。其中,每個(gè)節(jié)點(diǎn)代表一個(gè)術(shù)語(yǔ),每條邊說(shuō)明連接的兩個(gè)術(shù)語(yǔ)的相關(guān)關(guān)系,wi和wj之間邊的權(quán)重定義為 ,節(jié)點(diǎn)wi的出度定義為 。在PageRank中,詞wi的重要性值通過(guò)迭代地運(yùn)行公式(4)直到收斂獲得。其中,衰減因子λ的取值范圍為0到1,|V|是節(jié)點(diǎn)數(shù)。衰減因子說(shuō)明每個(gè)節(jié)點(diǎn)有(1-λ)的概率隨機(jī)跳轉(zhuǎn)到圖中的其他節(jié)點(diǎn),同時(shí)有λ的概率隨出度邊跳轉(zhuǎn)到相鄰節(jié)點(diǎn)。
(4)
然而,傳統(tǒng)的PageRank算法僅為每個(gè)術(shù)語(yǔ)保留唯一的重要性值。為了能夠按照主題排序,傳統(tǒng)PageRank的隨機(jī)游走被分解成多個(gè)主題相關(guān)的隨機(jī)游走,目的就是將術(shù)語(yǔ)的重要性值分解成與主題相關(guān)的重要性向量,準(zhǔn)確記錄術(shù)語(yǔ)對(duì)于不同主題的重要性。相關(guān)工作主要有Liu等人提出的方法[6]MTPR,主要思想是對(duì)于每個(gè)主題分別運(yùn)行有偏好的PageRank算法,將公式(4)中第二項(xiàng)統(tǒng)一的隨機(jī)跳轉(zhuǎn)改為主題相關(guān)的隨機(jī)跳轉(zhuǎn)概率即偏好值 ,且 ,從三種備選中最終確定為 。對(duì)于主題z,MTPR計(jì)算候選術(shù)語(yǔ)的主題重要性值如公式(5)所示。其中,邊權(quán)重 定義為兩個(gè)候選術(shù)語(yǔ)在固定窗口大小中的共現(xiàn)次數(shù)。
(5)
Zhao等人的方法[7]McTPR認(rèn)為與主題背景知識(shí)無(wú)關(guān)的傳播會(huì)導(dǎo)致重要性值偏離主題,因而,基于MTPR的工作,進(jìn)一步在邊權(quán)重的設(shè)置上用與主題相關(guān)的背景知識(shí)建模重要性值傳播,如公式(6)所示。其中,邊權(quán)重 定義為兩個(gè)候選術(shù)語(yǔ)在同屬于主題z的微博中共現(xiàn)的次數(shù)。
(6)
受到前人相關(guān)工作的啟發(fā),研究認(rèn)為在PageRank算法的邊權(quán)重中融入主題信息能夠?qū)鹘y(tǒng)的隨機(jī)游走分解成多個(gè)主題相關(guān)的隨機(jī)游走,考慮到社會(huì)化標(biāo)簽豐富的顯式和隱式關(guān)聯(lián)特性,文中提出MeTPR方法,通過(guò)新穎的邊權(quán)重如公式(7)所示,進(jìn)一步改進(jìn)主題相關(guān)的隨機(jī)游走方法。
(7)
其中,權(quán)重因子ρ控制公式(2)表示的局部語(yǔ)義相似度和公式(3)表示的全局語(yǔ)義相似度兩者的比重。通過(guò)新的邊權(quán)重,主題術(shù)語(yǔ)的重要性傳播不僅反映出兩個(gè)術(shù)語(yǔ)在具體主題下資源組織結(jié)構(gòu)上的局部共現(xiàn)信息,還反映出兩個(gè)術(shù)語(yǔ)在所有主題下整個(gè)資源集合上的全局語(yǔ)義相似度。相應(yīng)地,將公式(7)代入公式(6),迭代運(yùn)行MeTPR直到收斂,得到為每個(gè)術(shù)語(yǔ)計(jì)算的主題相關(guān)的重要性值。最終,排序靠前的術(shù)語(yǔ)被抽取出來(lái)作為主題核心術(shù)語(yǔ)。
2 實(shí)驗(yàn)及分析
2.1 實(shí)驗(yàn)設(shè)置
研究從豆瓣電影網(wǎng)站收集實(shí)驗(yàn)所需的數(shù)據(jù),豆瓣電影是一個(gè)流行的中文社交網(wǎng)站,允許注冊(cè)用戶(hù)提交與電影相關(guān)的信息,并與他人分享。實(shí)驗(yàn)獲取截止到2012年6月,豆瓣電影網(wǎng)站用戶(hù)對(duì)豆瓣Top250的電影打出的標(biāo)簽信息,共計(jì)1760個(gè)標(biāo)簽。經(jīng)過(guò)去除停用詞和噪聲等預(yù)處理,最終獲得1 737個(gè)標(biāo)簽作為候選術(shù)語(yǔ)。根據(jù)數(shù)據(jù)集的規(guī)模和人工經(jīng)驗(yàn)的判斷,實(shí)驗(yàn)中嘗試10到100之間不同主題數(shù)目的設(shè)置學(xué)習(xí)LDA模型,并最終選擇將初始主題數(shù)目設(shè)定為40。然后,隨即運(yùn)行LDA算法,并每隔1 000次迭代進(jìn)行Gibbs取樣一次。接著,在同樣的數(shù)據(jù)集上將我們的方法與前人相關(guān)工作做比較。
(1)MTPR 代表Liu等人的方法[6],邊權(quán)重計(jì)算為兩個(gè)候選術(shù)語(yǔ)在同一個(gè)資源中共現(xiàn)的數(shù)目 ,偏好值通過(guò)公式(1)得到,候選術(shù)語(yǔ)對(duì)于不同主題的重要性通過(guò)迭代地運(yùn)行公式(5)直到收斂后得到。
(2)McTPR 代表Zhao等人的方法[7],邊權(quán)重計(jì)算為兩個(gè)候選術(shù)語(yǔ)在同一個(gè)資源中共現(xiàn)并且屬于同一個(gè)主題的數(shù)目 ,偏好值通過(guò)公式(1)計(jì)算得到,候選術(shù)語(yǔ)對(duì)于不同主題的重要性通過(guò)迭代地運(yùn)行公式(6)直到收斂后得到。
(3)MeTPR 代表本文提出的方法,邊權(quán)重和偏好值分別通過(guò)公式(7)和(1)計(jì)算得到,候選術(shù)語(yǔ)對(duì)于不同主題的重要性通過(guò)迭代地運(yùn)行公式(6)直到收斂后得到。
研究中,終止運(yùn)行上述方法的條件是僅當(dāng)?shù)螖?shù)達(dá)到100或者候選術(shù)語(yǔ)在相鄰兩次迭代中的重要性值差異小于0.000 001。有三個(gè)參數(shù)影響主題核心術(shù)語(yǔ)抽取方法,包括(1)衰減因子λ,用于對(duì)比方法中調(diào)節(jié)重要性傳播通過(guò)出度邊跳轉(zhuǎn)到相鄰候選術(shù)語(yǔ)(公式(5),(6)中的第一項(xiàng))和隨機(jī)跳轉(zhuǎn)到任意候選術(shù)語(yǔ)(公式(5),(6)中的第二項(xiàng))之間的比重。(2)權(quán)重因子ρ,在MeTPR中應(yīng)用于邊權(quán)重(公式(7)),用于控制兩個(gè)候選術(shù)語(yǔ)之間的關(guān)于具體主題的局部共現(xiàn)和所有主題的全局語(yǔ)義相似度之間的比重。(3)閾值Q。當(dāng)把Q應(yīng)用于MTPR,McTPR,MeTPR三種方法時(shí),如果兩個(gè)候選術(shù)語(yǔ)之間的全局語(yǔ)義相似度小于Q,有針對(duì)地將移除這對(duì)術(shù)語(yǔ)之間的邊。并且分別設(shè)定參數(shù)λ,ρ,Q的取值范圍為從0.1到0.9,步長(zhǎng)為0.1,這樣每個(gè)參數(shù)就有9種候選取值。經(jīng)過(guò)三個(gè)參數(shù)的排列組合,相應(yīng)地就分別得到以上對(duì)比方法的729組實(shí)驗(yàn)結(jié)果。
2.2 評(píng)價(jià)標(biāo)準(zhǔn)
評(píng)價(jià)標(biāo)準(zhǔn)通過(guò)Pooling方法[8]構(gòu)建完成。首先,社會(huì)化標(biāo)簽中不存在主題核心術(shù)語(yǔ)抽取的黃金標(biāo)準(zhǔn);第二,人工識(shí)別出所有主題,并判斷主題核心術(shù)語(yǔ)是不可能完成的任務(wù)。為此隨機(jī)混合對(duì)比方法MTPR,McTPR,MeTPR的所有實(shí)驗(yàn)結(jié)果,并要求兩個(gè)標(biāo)注者獨(dú)立標(biāo)注。如果抽取結(jié)果中給出的是與具體主題相關(guān)的、較為抽象的、具有代表性的候選術(shù)語(yǔ),就標(biāo)注為1;否則,如果抽取結(jié)果中給出的是與具體主題不相關(guān)的,或者缺乏代表性、太過(guò)于具體的候選術(shù)語(yǔ),就標(biāo)注為0。僅當(dāng)兩個(gè)標(biāo)注者都標(biāo)注為1的候選術(shù)語(yǔ)才被認(rèn)為是正確的主題核心術(shù)語(yǔ),其他情況的候選術(shù)語(yǔ)均被認(rèn)為是錯(cuò)誤的結(jié)果。以“致我們終將逝去的青春”為例,對(duì)于這部電影和同類(lèi)型的其他相關(guān)電影所屬的主題來(lái)說(shuō),正確的主題核心術(shù)語(yǔ)可能是“青春”、“校園”、“愛(ài)情”等,而“2013”(上映時(shí)間)和有關(guān)電影具體屬性的其他候選術(shù)語(yǔ),如導(dǎo)演、演員等,在本文任務(wù)的評(píng)價(jià)中均應(yīng)被標(biāo)注為0。最終,將兩個(gè)標(biāo)注者共同認(rèn)可的主題核心術(shù)語(yǔ)集合作為基于邊權(quán)重的主題核心術(shù)語(yǔ)抽取任務(wù)評(píng)價(jià)的黃金標(biāo)準(zhǔn)(Kappa值為0.95)。
研究對(duì)主題核心術(shù)語(yǔ)抽取任務(wù)的評(píng)價(jià)策略包括經(jīng)典的精確率(Precision)、召回率(Recall)、F1值(F1)(見(jiàn)公式(8)),以及兩個(gè)考慮順序的評(píng)價(jià)策略包括平均準(zhǔn)確率(MAP:Mean Average Precision)(見(jiàn)公式(9))和平均排序倒數(shù)(MRR:Mean Reciprocal Rank)(見(jiàn)公式(10))。
(8)
其中, 代表通過(guò)某種方法抽取的正確主題核心術(shù)語(yǔ)的數(shù)目, 代表通過(guò)某種方法自動(dòng)抽取的主題核心術(shù)語(yǔ)的總數(shù), 代表根據(jù)黃金標(biāo)準(zhǔn)得到的主題核心術(shù)語(yǔ)的總數(shù)。這些評(píng)價(jià)策略均對(duì)所有主題求平均值。
進(jìn)一步地,研究使用平均準(zhǔn)確率(MAP)[7]來(lái)評(píng)價(jià)主題核心術(shù)語(yǔ)抽取的整體性能,如公式(9)所示。
(9)
其中,Z是主題集合。I(S)是一個(gè)示函數(shù),當(dāng)S為真時(shí)返回1,否則返回0。Mz,j代表對(duì)于主題z,通過(guò)方法M產(chǎn)生的第j個(gè)候選術(shù)語(yǔ),score(.)是兩個(gè)人工標(biāo)注結(jié)果的平均值。Mz代表對(duì)于主題z,通過(guò)方法M產(chǎn)生的所有候選術(shù)語(yǔ)。NM,z,j代表對(duì)于主題z,通過(guò)方法M返回前j個(gè)候選術(shù)語(yǔ)中正確的主題核心術(shù)語(yǔ)的數(shù)目,Nz代表對(duì)于主題z,根據(jù)黃金標(biāo)準(zhǔn)得到正確的主題核心術(shù)語(yǔ)的總數(shù)。
平均排序倒數(shù)(MRR)[9],如公式(10)所示,用于評(píng)價(jià)對(duì)于每個(gè)主題來(lái)說(shuō)第一個(gè)正確的主題核心術(shù)語(yǔ)所在的排序。對(duì)于主題z,rankz代表第一個(gè)正確的主題核心術(shù)語(yǔ)返回的位置。
(10)
2.3 與前人工作的對(duì)比
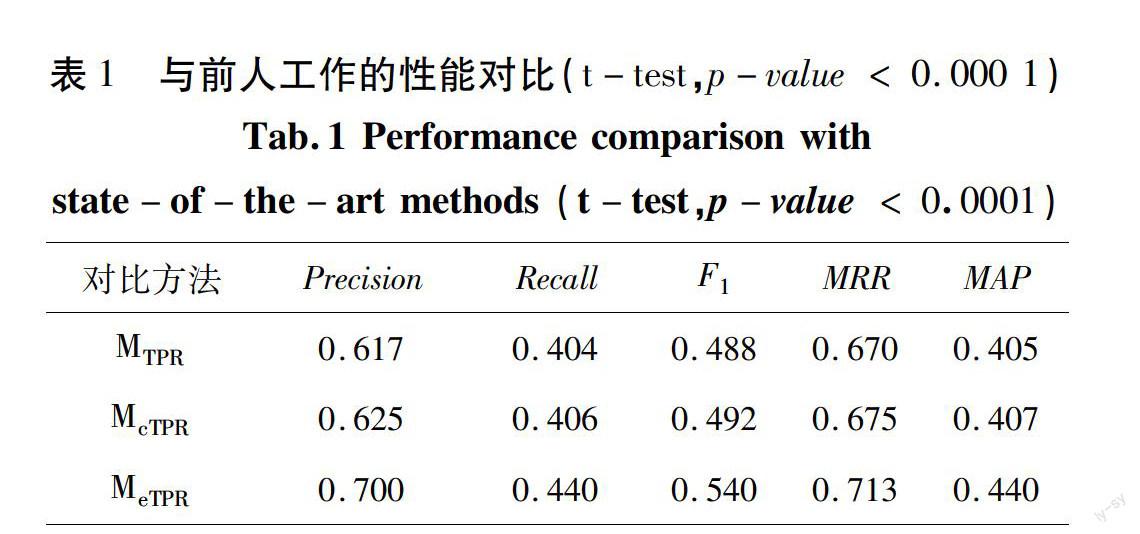
研究通過(guò)對(duì)影響方法性能的三個(gè)參數(shù)的窮舉獲取最優(yōu)參數(shù)組合,得出提出的方法MeTPR與對(duì)比方法MTPR,McTPR在五項(xiàng)評(píng)價(jià)指標(biāo)上的最優(yōu)性能對(duì)比。如表1所示,本文提出的方法MeTPR在準(zhǔn)確率上獲得較大提升,比MTPR、McTPR兩種對(duì)比方法分別提升8.3%、7.5%。在召回率、F1值、MRR、MAP四項(xiàng)評(píng)價(jià)指標(biāo)上,MeTPR相對(duì)于其他兩種對(duì)比方法的提升均超過(guò)3.3%。由于邊權(quán)重的設(shè)置結(jié)合具體主題的局部共現(xiàn)信息和所有主題的全局語(yǔ)義相似度,MeTPR整體性能最好。McTPR由于在邊權(quán)重的傳播中考慮主題背景知識(shí),性能好于在邊權(quán)重中僅考慮候選術(shù)語(yǔ)共現(xiàn)次數(shù)的MTPR。但是,LDA算法對(duì)于初始主題數(shù)的設(shè)置,可能會(huì)給后續(xù)多個(gè)彼此獨(dú)立的主題相關(guān)的隨機(jī)游走帶來(lái)不可避免的錯(cuò)誤,因此未來(lái)需要考慮新的途徑來(lái)改善這類(lèi)核心術(shù)語(yǔ)抽取方法。
表1 與前人工作的性能對(duì)比(t-test,p-value < 0.0001)
Tab.1 Performance comparison with state-of-the-art methods (t-test,p-value < 0.0001)
對(duì)比方法 Precision Recall F1 MRR MAP
MTPR 0.617 0.404 0.488 0.670 0.405
McTPR 0.625 0.406 0.492 0.675 0.407
MeTPR 0.700 0.440 0.540 0.713 0.440
3 結(jié)束語(yǔ)
本文針對(duì)從社會(huì)化標(biāo)簽中抽取主題核心術(shù)語(yǔ)的任務(wù),提出基于邊權(quán)重的主題核心術(shù)語(yǔ)抽取方法。從社會(huì)化標(biāo)簽豐富的關(guān)聯(lián)特性出發(fā),提出結(jié)合具體主題的局部共現(xiàn)信息和所有主題的全局語(yǔ)義相似度共同構(gòu)成的邊權(quán)重。進(jìn)而,通過(guò)新穎的邊權(quán)重將傳統(tǒng)PageRank的隨機(jī)游走分解成多個(gè)主題相關(guān)的隨機(jī)游走,經(jīng)過(guò)候選術(shù)語(yǔ)的重要性傳播,排序抽取出主題核心術(shù)語(yǔ)。在豆瓣電影數(shù)據(jù)集上的實(shí)驗(yàn)結(jié)果驗(yàn)證了所提出方法的有效性和健壯性。未來(lái)工作,將會(huì)通過(guò)探索更多社會(huì)化標(biāo)簽的數(shù)據(jù)源,同時(shí)結(jié)合對(duì)基于邊權(quán)重的主題核心術(shù)語(yǔ)抽取方法的改進(jìn),進(jìn)一步提高主題核心術(shù)語(yǔ)抽取的性能。
參考文獻(xiàn):
[1] CUI G, LU Q, LI W, et al. Automatic acquisition of attributes for ontology construction[C]//the 22nd International Conference,Hong Kong:ICCPOL,2009:248-259.
[2] LIU X, SONG Y, LIUiu S, et al. Automatic taxonomy construction from keywords[C]//Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,New York,NY,USA:ACM,2012:1433-1441.
[3] TRANT J. Studying social tagging and folksonomy: A review and framework [J]. Journal of Digital Information,2009,10(1):1-42.
[4] Page L, Brin S, Motwani R, et al. The Pagerank Citation Ranking: Bringing Order to the Web[R]. Stanford:Stanford Digital Library Technologies Project,1999:1-17.
[5] BLEI D M, NG A Y, JORDAN M I. Latent Dirichlet allocation[J]. Journal of Machine Learning Research,2003(3):993-1022.
[6] LIU Z Y, HUANG W Y, ZHENG Y B, et al. Automatic keyphrase extraction via topic decomposition[C]// Proceedings of the 2010 Conference on Empirical Methods in Natural Language Processing,Association for Computational Linguistics,Stroudsburg,PA,USA:ACL,2010:366-376.
[7] ZHAO X, JIANG J, HE J, et al. Topical keyphrase extraction from twitter[C]. Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies,Portland,OR,United states:ACL,2011:379-388.
[8] Voorhees E, Harman D, Standards N I, et al. TREC: Experiment and Evaluation in Information Retrieval[M]. Cambridge: MIT press,Boston,2005:1-567.
[9] VOORHEES E M. The TREC-8 question answering track report[C]//Proceedings of TREC, Gaithersburg,Maryland:NIST,1999:77-82.
