基于自然語言理解的在線答疑系統(tǒng)設計與實現(xiàn)
2015-05-30 10:48:04趙靜黨麗瓊
計算機時代 2015年5期
趙靜 黨麗瓊
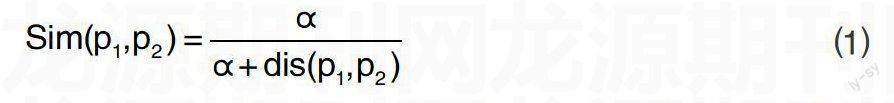
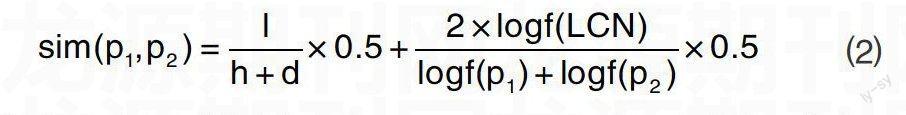
摘 要: 基于自然語言理解的相似度計算仍是計算機語言處理技術尚需深入研究的內(nèi)容。通過在“知網(wǎng)”知識表示的基礎上,綜合考慮深度和密度兩方面的影響因素,利用一種較為成熟的改進的多因素語義相似度處理算法,基于全文檢索匹配技術,設計并實現(xiàn)了一個限定領域內(nèi)的在線答疑系統(tǒng)。實例運行結果表明,系統(tǒng)可靠性較高,且答疑效果較為明顯,達到了預期目標。
關鍵詞: 自然語言理解; 語義相似度; 全文檢索; 在線答疑系統(tǒng)
中圖分類號:TP399 文獻標志碼:A 文章編號:1006-8228(2015)05-10-03
Abstract: The similarity calculation based on natural language understanding is still a research content of the computer language processing technology. Based on the knowledge representation of "HowNet", considering the both factors of depth and density, by using a more sophisticated multivariate semantic similarity algorithm, and with a full-text search matching technology, an online answer system in the limited field is designed and implemented. The experimental results show that, the system is reliable, the answer effect is more obvious, and the desired goal is achieved.
Key words: natural language understanding; semantic similarity; full text retrival; on-line answer system
0 引言
隨著計算機網(wǎng)絡技術的飛速發(fā)展,傳統(tǒng)的教學手段已不能滿足當前大信息量的教學內(nèi)容需求,因此,創(chuàng)造一個在教師指導和引導下學生自主式學習的智能系統(tǒng)平臺很有必要。智能的網(wǎng)絡答疑系統(tǒng)可以利用自然語言處理技術對學生的疑問進行自動匹配處理,它的出現(xiàn)為網(wǎng)絡教學提供了交互的情境,成為支持網(wǎng)絡教學順利進行的重要條件。智能網(wǎng)絡答疑系統(tǒng)是傳統(tǒng)課堂教學的重要補充,并逐漸在學生學習、認知、再學習這樣一個閉環(huán)的學習過程中發(fā)揮著舉足輕重的作用[1]。
1 設計思想及算法原理
基于計算機自然語言處理技術,充分利用校園網(wǎng)絡資源,通過人機互動等豐富信息表現(xiàn)形式,實現(xiàn)一個智能的、高效的基于自然語言理解的專業(yè)課程自動答疑系統(tǒng)。系統(tǒng)設計的關鍵是如何實現(xiàn)快速、高效的智能搜索答案。該過程實際上類似于一個搜索引擎,其核心就是構建一個結構合理、具有完整豐富內(nèi)容的知識庫,并能夠在自然語言理解的基礎上,快速、準確的完成自動答疑工作。基于自然語言理解的在線答疑系統(tǒng)中兩個關鍵技術分別是:中文分詞技術和相似度計算。
1.1 中文分詞技術
自然語言理解(Natural Language Understanding,簡稱NLU)研究如何讓計算機理解和運用人類的自然語言,使得計算機懂得自然語言的含義,并對人給計算機提出的問題,通過人機對話(man-machine dialogue)的方式,用自然語言進行回答。為了使計算機系統(tǒng)能夠較好地理解用戶提出的問題,首先需要對問題進行處理,這一過程最先用到的最為關鍵的技術就是分詞技術【2,3】。由于中英文之間的語言組織、詞法結構不同,使得中文分詞一直以來成為制約中文自然語言處理的主要因素。而中文文本中,只是字、句和段之間可以通過明顯的分界符來簡單劃界,詞與詞之間沒有天然的分隔符,中文詞匯大多是由兩個或兩個以上的漢字組成,并且語句是連續(xù)書寫的。這就要求在對中文文本進行自動分析之前,先將整句切割成小的詞匯單元,即中文分詞(或中文切詞),相比英文語句處理,中文分詞難度更大。
從算法處理上看,目前主要有三種【4-6】:一是基于詞典的分詞方法,它使用機器詞典作為分詞依據(jù),分詞效率高,目前應用范圍較廣;二是基于統(tǒng)計的分詞方法,它是利用統(tǒng)計方法,通過對大規(guī)模文本的統(tǒng)計,讓計算機自動判斷的方法,該方法使系統(tǒng)資源開銷較大;三是基于人工智能的分詞方法,如專家系統(tǒng)和神經(jīng)網(wǎng)絡分詞方法等,這類方法目前尚處于實驗室階段,尚未投入實際應用。
1.2 相似度處理技術
相似度計算在自然語言處理、智能檢索、文本聚類、文本分類、自動應答、詞義排歧和機器翻譯等領域都有廣泛的應用[7]。其計算方法按照基于規(guī)則和統(tǒng)計分為兩種情況:一是根據(jù)某種世界知識(如Ontology)來計算,主要是基于按照概念間結構層次關系組織的語義詞典的方法,根據(jù)在這類語言學資源中概念之間的上下位關系和同位關系來計算詞語的相似度[8];二是利用大規(guī)模的語料庫進行統(tǒng)計,這種基于統(tǒng)計的方法主要將上下文信息的概率分布作為詞匯語義相似度的參照依據(jù)[9]。
⑴ 常用語義詞典
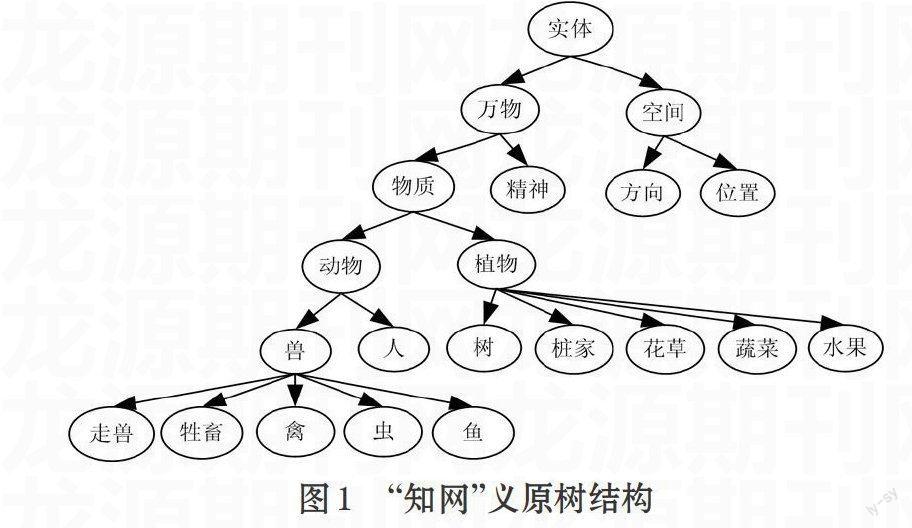
對于基于語義詞典的相似度計算方法,由于存在計算簡單、基礎條件低、假設條件易于滿足等優(yōu)點,受到越來越多研究者的歡迎。常用語義詞典主要有[10-12]:WordNet、FrameNet、MindNet、知網(wǎng)(HowNet)、同義詞詞林、中文概念詞典(CCD),以及敘詞表、領域概念網(wǎng)、概念圖等概念網(wǎng)絡結構。本文對于相似度的計算主要是基于知網(wǎng)(HowNet)結構。其概念結構如圖1所示。
⑵ 相似度計算
與概念相似度密切相關的一個概念是語義距離(semantic distance)。在一棵樹形圖中,任何兩個節(jié)點之間有且只有一條路徑,在計算語義相似度的時候,這條路徑的長度就可以作為這兩個概念的語義距離的一種度量,通常認為它們是概念關系特征的不同表現(xiàn)形式,兩者之間可以建立一種簡單概念詞相似度用來描述概念樹中兩個節(jié)點之間的語義接近程度,一般最常用的是劉群提出的以《知網(wǎng)》為基礎的相似度計算方法[13]:
式⑴中,p1和p2表示兩個概念節(jié)點,dis(p1,p2)是樹狀結構中兩節(jié)點間的最短距離,α是一個調(diào)節(jié)參數(shù),表示相似度為0.5時的路徑長度。
文獻[14,15]綜合考慮深度與密度因素,提出了多因素義原相似度計算方法:
式⑵中,h為義原樹深度,l為LCN層次,LCN為最小公共父節(jié)點。
文獻[16]認為該方法存在兩點不足:一是該式僅把相似度取為密度、深度因素的算術平均值,顯然對于概念節(jié)點分布不均的情況不夠合理;二是該式?jīng)]有對密度、深度兩者的影響程度進行分析,這樣對他的使用范圍受到了限制。基于此考慮,提出了改進的語義相似度計算方法:
式⑶中,l(p1,p2)為分別遍歷概念網(wǎng)中節(jié)點p1,p2到達其最小公共父結點所歷經(jīng)的父結點(包括最小公共父結點)數(shù)的最大值。w(p1,p2)為p1,p2所在層概念數(shù)的最大值。算法關鍵部分引進了一個調(diào)節(jié)參數(shù)λ(p1,p2),并保證在該參數(shù)的作用下,當節(jié)點p1,p2所在層概念數(shù)較多,即w(p1,p2)增大時,密度因素對相似度的貢獻值大;而當p1,p2離最小公共父結點較遠,即l(p1,p2)增大時,深度因素對相似度的貢獻值較大。同時算法約定,當p1,p2的父結點和最小公共父結點相同,且同層只有p1,p2兩個節(jié)點時,調(diào)節(jié)參數(shù)為0.5。該方法即為本文在相似度計算方面采用的算法模型。
2 模型設計
下面我們參考文獻[17],按照一般教師對于問題的處理方式,在上述概念語義相似度計算的基礎上,從計算機建模層面上給出計算機自動答疑模型的建模過程。
Step1:計算條件
已知標準問題庫A可以表示為關鍵詞序列:A=(a1,a2,…,an);學生提問B可以表示為關鍵詞序列:B=(b1,b2,…,bn)。
Step2:相似度計算
⑴ 知識點關鍵詞信息提取
該問題的處理主要通過提取學生問題中每一個關鍵詞,對照系統(tǒng)知識庫,從底層開始遍歷搜索,當找到對應的概念節(jié)點時,提取該節(jié)點的高度、密度等屬性信息,并保存起來,搜索完成后即可參加相似度的計算。
⑵ 概念相似度求解
概念相似度的計算采用語義相似度技術,設標準問題庫A可以表示為知識點的一個向量組A=(a1,a2,…,an),循環(huán)遍歷每一個學生輸入的問題關鍵詞序列,通過概念語義相似度算法可得到任意兩概念之間的相似度Sim(ai,bj),其中i=1,2,…,m,j=1,2,…,n。
Step3:匹配結果輸出
前面已經(jīng)完成了輸入問題和標準問題庫之間的循環(huán)相似度匹配計算,為了將需要的信息提取出來,模型還需要設置一個閥值δ。通過閥值δ這個關卡,將相似度結果大于δ的問題提取出來,并按照降序排列輸出即可。論文答疑系統(tǒng)模型建模流程如圖2所示。
3 系統(tǒng)實現(xiàn)與驗證
系統(tǒng)設計環(huán)境為Visual Studio 2005,數(shù)據(jù)庫服務器為SQL Server 2000。采用B/S網(wǎng)絡模型進行構架設計,按照系統(tǒng)功能需求劃分為用戶表示層、應用邏輯層和數(shù)據(jù)訪問層三個層面。系統(tǒng)測試界面如圖3所示。
如圖3所示,在答疑系統(tǒng)界面中輸入問句:“計算機包含哪些硬件?”,系統(tǒng)自動分詞后生成的關鍵詞語匯單元為:“計算機;硬件”(其中“包含;哪些”等作為停用詞已經(jīng)被過濾掉了),然后系統(tǒng)自動在數(shù)據(jù)庫中檢索匹配,最終反饋了12條相關結果,圖3為部分結果截圖。這里說明一點,反饋結果的多少取決于閥值δ,測試中我們選取的閥值δ為0.8,一般我們?nèi)¢y值δ在0.8左右即可。
為了進一步驗證系統(tǒng)的查詢能力,我們將剛才的問句調(diào)整為:“計算機包含?”,這時系統(tǒng)自動分詞后生成的匯單元只有一個關鍵詞“計算機”,最終匹配結果如圖4所示。
這里讀者或許會發(fā)現(xiàn),系統(tǒng)反饋回來的結果與問題毫不相關。其實,這并不是系統(tǒng)出錯,而是“知網(wǎng)”概念網(wǎng)絡中“計算機”與“硬件、軟件”兩個概念關系比較密切,表現(xiàn)為在概念網(wǎng)絡中的節(jié)點位置較為接近,匹配結果相似度值較高,因此才有了上述的結果。也就是說,也許在某些時候當查詢某個概念時,相近的結果就會被檢索出來(或者當不確定查找的問題時,只需輸入相近的問題,也會查詢到想要的答案),這就是基于自然語言理解的語義相似度計算模型優(yōu)勢所在。
4 結束語
由于漢語詞匯表達的復雜性和詞匯語義概念較強的主觀性,以及具體應用領域的專業(yè)性等因素影響,目前基于自然語言理解的相似度計算仍是計算機語言處理技術需深入研究的內(nèi)容。本文在“知網(wǎng)”知識表示的基礎上,充分考慮“知網(wǎng)”深度和密度因素影響,基于全文檢索匹配技術,設計并實現(xiàn)了一個限定領域內(nèi)的在線答疑系統(tǒng),大量的運行結果證明了該系統(tǒng)是可靠的,達到了系統(tǒng)設計的目的。但在準確性方面還存在不足,從第一個測試中可以看出,提問人員真正需要的是:“計算機的硬件組成”。其重點關注的是計算機、硬件,而答案給出了太多的“計算機特點,計算機發(fā)展”等其他一些與“計算機”有關的匹配答案,其原因是關鍵詞權重的影響因素沒有體現(xiàn)出來,離真正的自然語言理解還存在一定的距離,這是系統(tǒng)下一步有待改進的地方。
參考文獻:
[1] 馮志偉.自然語言問答系統(tǒng)的發(fā)展與現(xiàn)狀[J].外國語,2012.35(6):28-30
[2] 黃崑,符紹宏.自動分詞技術及其在信息檢索中的應用研究[J].現(xiàn)代圖書情報技術,2001.3:26-29
[3] 沈斌.基于分詞的中文文本相似度計算研究[D].天津財經(jīng)大學,2006:12-17
[4] 張波.網(wǎng)絡答疑系統(tǒng)的設計與實現(xiàn)[D].吉林大學,2006:30-31
[5] 張麗輝.計算機領域中文自動問答系統(tǒng)的研究[D].天津大學,2006:14-18
[6] 朱珣.中文自動分詞系統(tǒng)的研究[D].華中師范大學,2004:12-13
[7] 周舫.漢語句子相似度計算方法及其應用的研究[D].河南大學,2005:24-25
[8] 于江生,俞士汶.中文概念詞典的結構[J].中文信息學報,2002.16(4):13-21
[9] 胡俊峰,俞士汶.唐宋詩中詞匯語義相似度的統(tǒng)計分析及應用[J].中文信息學報,2002.4:40-45
[10] Miller G A, Fellbaum C. Semantic network of English [M]//Levin B, pinker S. lexical & conceptual semantics. Amsterdam, Netherlands: E lsevier Science Publishers,1991.
[11] Baker C F. The Berkeley frameNet project [C]//Proceeding ofthe COLING -ACL.98.Montreal, Canada,1998:86-90
[12] 黃康,袁春風.基于領域概念網(wǎng)絡的自動批改技術[J].計算機應用研究,2004.11:260-262
[13] 劉群,李素建.基于“知網(wǎng)”的詞匯語義相似度計算[C].第三屆漢語詞匯語義學研討會論文集,2002:59-76
[14] AGIRREE, RIGAU G. A Proposal for Word Sense Disambigua-tion Using Conceptual Distance[EB/OL],1995:112-118
[15] 蔣溢,丁優(yōu),熊安萍等.一種基于知網(wǎng)的詞匯語義相似度改進計算方法[J].重慶郵電大學(自然科學版),2009.21(4):533-537
[16] 黨麗瓊,劉文輝.一種改進的多因素語義相似度計算方法[J].計算機與現(xiàn)代化,2011.10:24-26
[17] 穗志方.語句相似度研究中的骨架依存分析法及應用[D].北京大學,1998:18-19
