認知無線電網絡遺傳-蟻群聯合優化路由算法
2015-05-04 08:06:34陳善學張佳佳鄭文靜
計算機工程與設計 2015年4期
陳善學,張佳佳,朱 江,鄭文靜
(重慶郵電大學 移動通信技術重慶市重點實驗室,重慶400065)
0 引 言
人們對認知無線電的研究主要集中在物理層、媒體訪問控制層[1-3]。其中,作為認知無線電技術的重要組成部分,至今認知無線電路仍未有一個具有代表性的路由協議。在認知無線電中,頻譜可能隨著空間、時間的變化而變化,所以只考慮物理層、MAC層往往是不夠的,只有在優化物理層、MAC層的基礎上,同時優化網絡層才能取得更好的性能指標。因此路由算法將會成為認知無線電的一個重要研究方向。
為了提高網絡的性能指標,很多學者利用NP完全(NP complete,NPC)問題來解決。其中,在解決NP完全問題方面啟發式算法具有很明顯的優勢。為了解決NP完全問題,模擬退火算法[4]、神經網絡[5]、遺傳算法[6]、蟻群算法[7]等啟發式算法被學者們采納。但在求最小時延最優解過程中遺傳算法計算量比較大,得到的結果可靠性差,不能穩定得到解且容易產生局部收斂不能得到最優解。然而,蟻群算法在求解復雜問題時具有很好的優越性,但容易過早收斂陷入局部最優化。為了找出最小時延最優解,本文通過結合遺傳算法和蟻群算法的優點提出了遺傳-蟻群聯合優化路由算法。在遺傳算法求最優解的基礎上,利用蟻群算法使螞蟻有一個很高的起點,然后采用自適應搜索方式求解最優路徑。在自適應搜索過程中,當信息素積累很多時,收斂性會變慢但搜索范圍擴大。因此,遺傳-蟻群聯合算法在求最優解問題上穩定性、全局性比較好。
1 系統模型
認知無線電網絡是由一系列的次用戶組成,當主用戶未占用授權頻段時次用戶可以機會接入該頻段。本文采用的是分布式網絡結構,每個次用戶自身可進行頻譜感知。這里用G=(N,L)來表示一個認知無線電網絡,其中N為網絡中的次用戶集合,L為網絡中通信鏈路集合。這里每個次用戶在獲得自身可用頻譜后都可以進行信道轉換和接入空閑信道。在通信范圍之內,當兩個次用戶之間存在空閑信道時,兩次用戶可以進行通信。在干擾范圍內的兩條鏈路如果使用同一條信道彼此之間會產生一定的干擾。
本文目的是為了找出最小時延路徑及其所使用的信道,因此我們這里的優化目標為其中
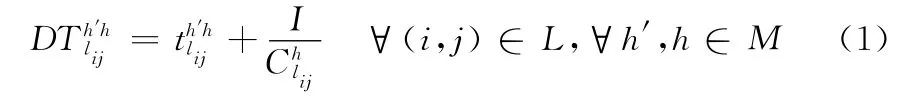
式中:h′——上一跳節點到節點i所使用的信道,h——節點i到節點j所使用的信道,I——數據包長度,信道切換、退避時延以及排隊時延之和為
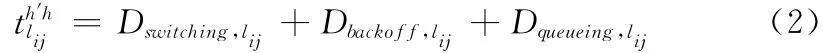
節點i經過H+1個次用戶后到達目的節點,由于信道切換引起的時延為
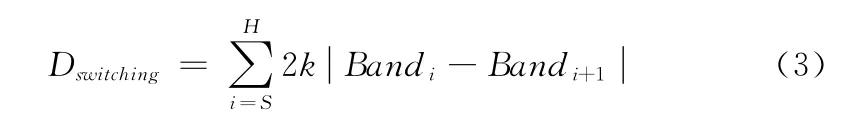
不同節點競爭同一條信道引起的退避時延為

式中:pc——節點沖突概率,Numi——頻段Bandi的沖突節點個數,W0——退避窗口最小值。
排隊等候時延為

式中:Bh——頻段Bandi的帶寬。
信道容量為
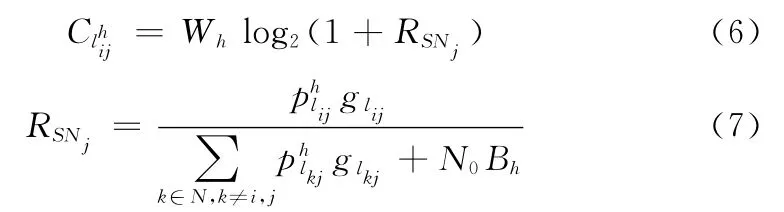
式中:RSNj——從節點i到節點j使用h信道通信的信噪比,其中噪聲主要包括高斯白噪聲和使用相同信道引起的鏈路間的干擾,為傳輸損 耗為節點i到節點j的距離,λ為路徑損耗指數 (這里設置為4),N0為高斯白噪聲密度為鏈路上的傳輸時延。
約束條件為

其中,M為網絡中空閑信道的集合,lij為從節點i到節點j的鏈路,式 (8)是對源節點、中間節點、目的節點的定義;式 (9)是為了保證從源節點到目的節點路徑的連通性;式 (10)是指h信道的授權用戶使用該信道時次用戶不能使用該信道;式 (11)是指在通信范圍內,若鏈路lij檢測到可用信道集中含有h信道為1,否則為0,且只能取二進制數;式 (12)是指在通信范圍內,鏈路lij若使用h信道進行通信為1,否則為0,且只能取二進制數;式 (13)是指鏈路lij只有檢測到h信道可用時才能使用h信道進行通信,即式 (14)是指節點i不能同時使用同一個信道進行發送和接收信息,否則節點i不能進行正常通信,主要是為了避免通信過程中的耳聾現象。
2 遺傳-蟻群聯合優化路由算法
遺傳-蟻群聯合優化路由算法主要由兩部分組成:初始信息素求解算法、最優路徑求解算法。首先通過遺傳算求解初始信息素,然后利用遺傳算法求出的初始信息素進行蟻群算法求最優路徑。
2.1 初始信息素求解算法設計
這里利用遺傳算法求解初始信息素,遺傳算法是用來解決整數規劃問題的方法之一,它主要由5個部分組成:染色體、適應函數、交叉、變異、生存選擇。
(1)染色體:這里的染色體代表在認知無線電網絡中所有通信鏈路上空閑信道的使用情況,基因代表一條鏈路上的一個信道的使用情況,它的值是二進制數如下所示
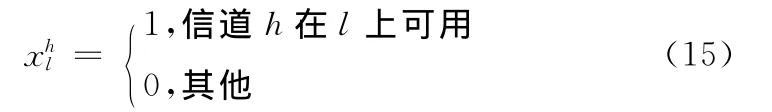

圖1 染色體
(2)適應度函數:適應度函數是一個衡量時延大小的參數,目的是為了最小化從源節點到目的節點的路徑總時延。其中,在滿足式 (8)~式 (14)約束條件的基礎上,若一條染色體中存在多條不同的從源節點到目的節點的路徑,則從中隨機選擇一條路徑及其相關信道計算其適應度函數。這里將適應度函數定義為

(3)染色體交叉:隨機地從父代染色體中選取兩條染色體,首先對兩個染色體進行異或運算。然后,判斷兩者相同的基因是否超過60%,若超過60%繼續隨機選取兩個染色體操作直到相同基因個數小于60%。通過此次判斷可以提高染色體交叉變換后的多樣性。最后,隨機分配給其中一個染色體的每個基因一個 (0,1)的概率值,判斷相對應基因位置的概率值是否小于給定的門限概率pe(這里設置為0.7),若兩基因的概率值都小于pe則進行交叉互換。
染色體交叉如圖2所示。

圖2 染色體交叉
(4)染色體變異:隨機分配給每個子染色體的每個基因一個 (0,1)的概率值,給定一個突變概率門限pm(這里pm=0.9),當基因的概率值大于pm時對該基因值取非。
染色體變異如圖3所示。
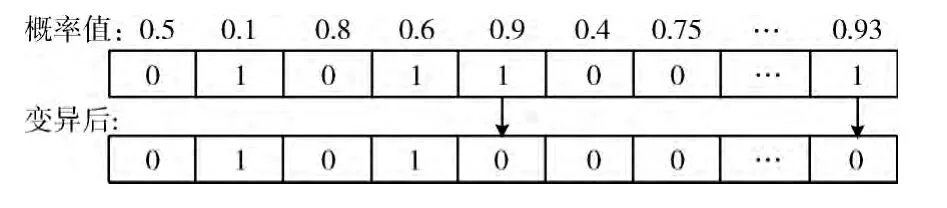
圖3 染色體變異
(5)生存選擇:重復 (1)~ (4)步驟直到染色體個數達到要求值,利用式 (16)求出各個染色體的適應度函數值,從適應度函數值不等于∞且路徑信息不相同的染色體中,提取前30%最小適度函數值的染色體作為生存選擇后的染色體,將該染色體集合記為F。將F中適應度函數計算時被選中的從源節點到目的節點的路徑相關的鏈路、信道及其對應的時延等信息進行存儲,其它鏈路及其相關信道對應的時延設置為∞。并將各鏈路時延轉換為蟻群算法的初始信息素。這樣可以避免蟻群算法由于缺乏初始信息素造成的收斂速度過慢的現象。
遺傳算法中生存選擇得到的30%較優解,其實是從源節點到目的節點尋找的路徑信息以及路徑時延,不同染色體中可能存在相同且被選擇作為路由的基因,若該基因位于f染色體中將其時延記為。這里可將這些路徑時延通過轉換作為初始信息素,轉換后的初始信息素定義為
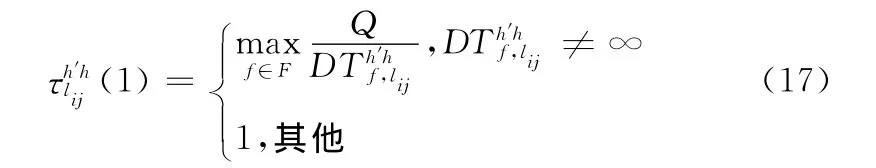
2.2 最優路徑求解算法設計
在使用蟻群算法尋找最優路由過程中,首先利用遺傳算法得到解,然后經轉換后作為蟻群算法的初始信息素,最后運用尋路規則以及信息素的更新規則找出本次迭代的最優解。
2.2.1 尋路規則
在第NC次迭代時,由節點i到節點j傳輸信息使用h信道且上游鏈路使用h′信道時路徑選擇概率為
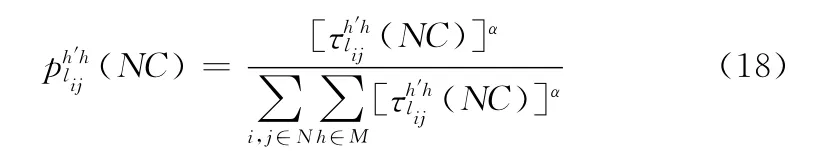
這里在滿足式 (8)~式 (14)約束條件的基礎上通過輪盤賭的方式利用選擇下一跳節點及其所使用的信道。由式 (18)可知,信息素越大,就越大,該路徑及信道就越容易被選中。當j為目的節點時停止尋路,否則按照尋路規則繼續尋路。
2.2.2 信息素更新規則
當螞蟻k找到目的節點時停止尋路,利用式 (16)計算螞蟻k的路徑總時延Lk(NC),當所有螞蟻到達目的節點時計算本次迭代螞蟻的平均時延即ML(NC),其中m為螞蟻的總數。更新后的信息素為
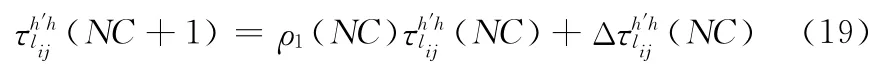
其中
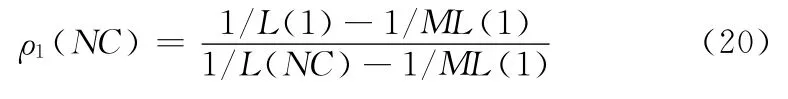

2.3 遺傳-蟻群聯合優化路由算法流程
GACA算法融合了遺傳算法和蟻群算法兩種算法的優點,使得該算法具有全局性并且穩定性較好。該算法首先求出遺傳算法求得的前30%的最優解,然后把它作為蟻群算法的初始信息素,這樣在求最優解時會比蟻群算法有一個更好的起點,并且初始的收斂速度也會比蟻群算法更快。最后利用蟻群算法求最優解。在求最優路徑過程中,隨著信息素的積累,揮發度增大即ρ1(NC)減小,收斂速度減慢,搜索范圍得到增大,這樣可以找出比蟻群算法更優的解。在遺傳-蟻群聯合優化路由算法流程圖中,條件1:遺傳算法中染色體總數達到一個定值時結束循環。條件2:蟻群算法中經過一定次數的迭代后求出的最優解一直保持不變時結束循環。其流程如圖4所示。
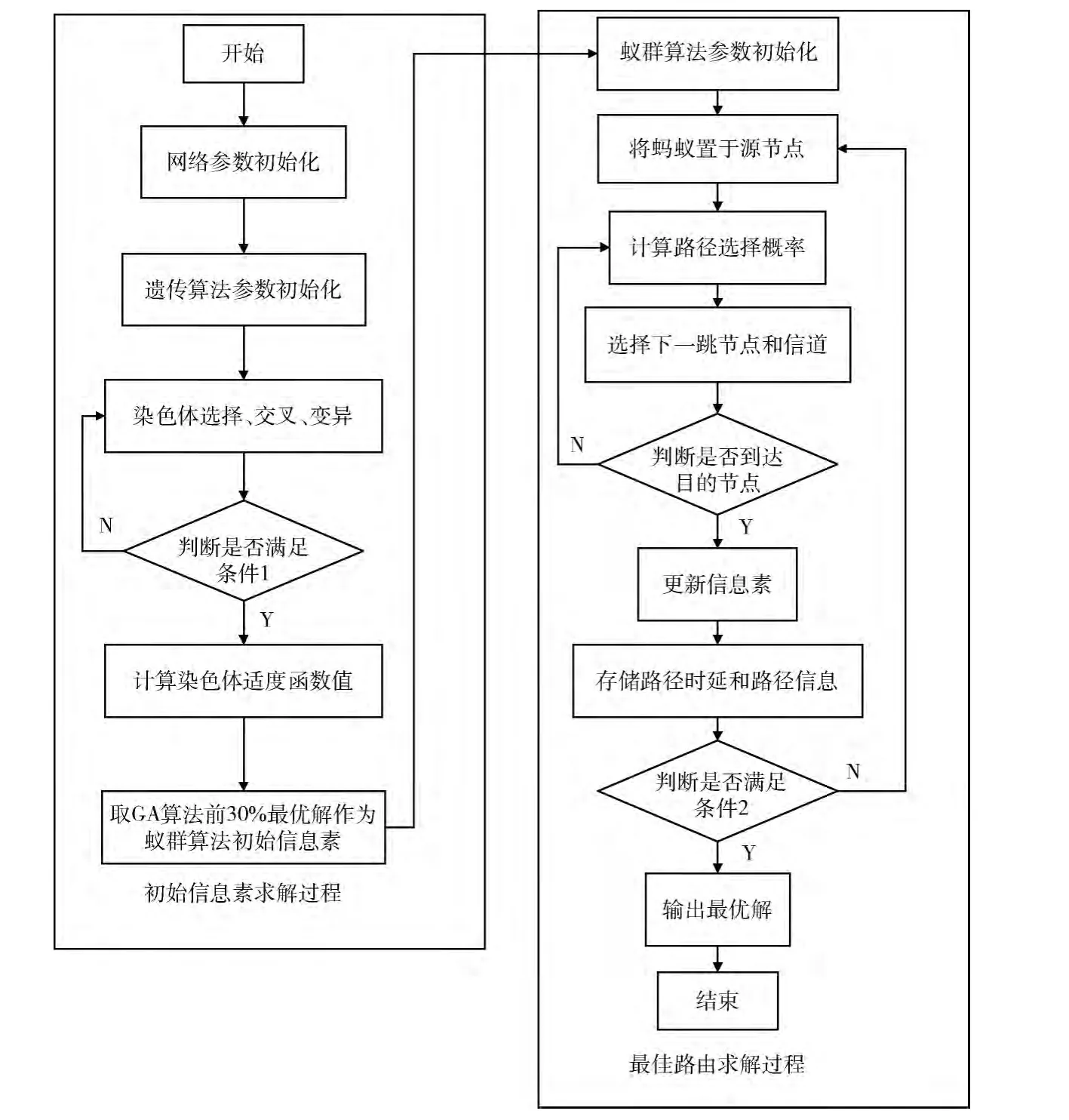
圖4 遺傳-蟻群聯合優化路由算法流程
3 實驗仿真
3.1 仿真環境
仿真中,在一個1500m×1500m網絡中,最大通信距離和干擾范圍分別為300m和600m,由n個節點組成,節點位置隨機分布在該網絡中。在20MHz~2.4GHz的頻譜范圍內隨機選取5個頻段作為仿真場景中的SOP集合,每個節點隨機選取2~5個頻段作為可用信道,發射功率為1000 W。在n個節點中隨機取10組節點,每組節點由2個節點組成,分別作為路由的源節點和目的節點。傳輸的數據包長度I=100kbit。GACA算法中遺傳算法的第一代染色體個數都為30,種群的總個數為6000。GACA算法和AC算法中的蟻群算法Q設置為0.5,控制參數α為2,螞蟻的個數都設置為30。AC算法中的初始信息素全部為1,揮發因子ρ為常數1。此外,迭代次數對時延與吞吐量影響的仿真是在由9個節點組成的網絡中進行的。在最優路由求解過程中,GACA算法和AC算法循環結束條件為連續40次迭代求出的最優解不變。然后,分別計算上述10組數據的總時延和端到端吞吐量,最后對10數據值求平均。本文評估的性能主要分為3個方面:端到端時延、端到端吞吐量以及算法時間復雜度。端到端時延是指從源節點發送長度為I的數據包到目的節點所需要的時間。端到端吞吐量是指大小為I的數據包,除以其從源節點到目的節點的各段鏈路中所用的時間,得到的最大數據傳輸速率[8]。時間復雜度是指執行算法所需要的計算工作量。
3.2 節點個數對時延的影響
隨著網絡中節點數目的增多,頻譜切換次數增加從而導致信道切換時延的增加,此時競爭同一條信道的節點增多使得退避時延也會增加,另外由于路由跳數的增多使得排隊時延也會增加,因此隨著網絡中節點數的增多路徑總時延會逐漸增加。比較GACA算法和AC算法,如圖5所示,隨著節點個數的增多GACA算法時延增加的速度比AC算法的慢,并且時延比AC算法求出的要小,主要由于隨著節點個數的增加,AC算法的局部收斂現象越來越嚴重。
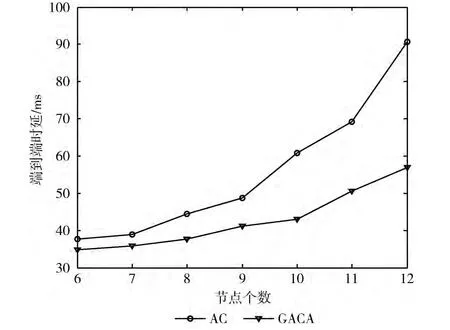
圖5 不同節點個數下平均時延的比較
3.3 節點個數對吞吐量的影響
由于數據包傳輸時間和吞吐量是成反比的,隨著節點數目的增加,端到端的吞吐量逐漸減小。如圖6所示,隨著節點個數的增多GACA算法吞吐量減小的速度比AC算法的慢,并且吞吐量比AC算法求出的要大。
3.4 迭代次數對時延的影響
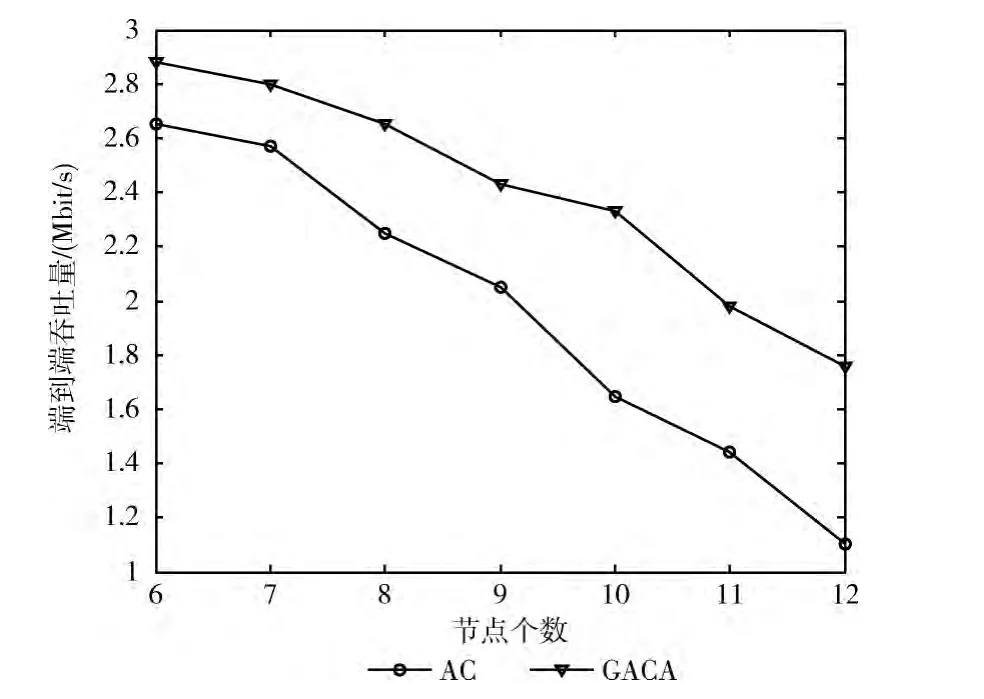
圖6 不同節點個數下端到端吞吐量的比較
隨著迭代次數的增加時延越來越小,最終會收斂到一點。如圖7所示,在迭代次數20時,GACA算法得出的時延值比AC算法得出的值要小很多,主要由于AC算法中的初始信息素是相同的,而GACA算法利用遺傳算法求出30%最優解作為蟻群算法的初始信息素,使其在尋優過程中比AC蟻群算法有一個更好的起點。此外,AC算法迭代次數靠近100時已經收斂,而GACA算法迭代次數靠近160時收斂,可見GACA算法由于引入了參數ρ1(NC)與路徑時延有關,使得當路徑總時延很小時收斂速度變慢,這樣可以擴大螞蟻的搜索范圍找出更優的解,從GACA算法的最終收斂時延值比AC算法小可驗證。
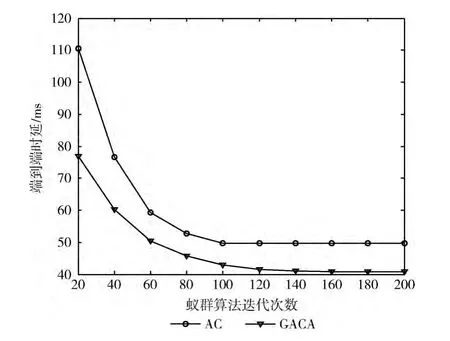
圖7 迭代次數對端到端時延的影響
3.5 迭代次數對吞吐量的影響
分別通過GACA算法和AC算法求吞吐量,隨著迭代次數的增大端到端的吞吐量越來越大,如圖8所示在起始點由于遺傳算法的引入GACA算法求出的吞吐量明顯比AC算法大,隨著迭代次數的增大GACA算法的收斂速度比AC算法的慢,這樣使得GACA算法避免算法過早陷入局部收斂的狀態同時擴大搜索范圍。由圖8可知GACA算法的最終收斂值是比AC算法更好。
3.6 復雜度分析
由于GACA算法在AC算法基礎上引入了GA算法,所以它的復雜度比AC算法要高。表1中,M是指網絡中的空閑信道個數,N是指網絡中的節點個數。由表1可知,GACA算法的加減、乘除、取對數運算復雜度明顯比AC算法要高。
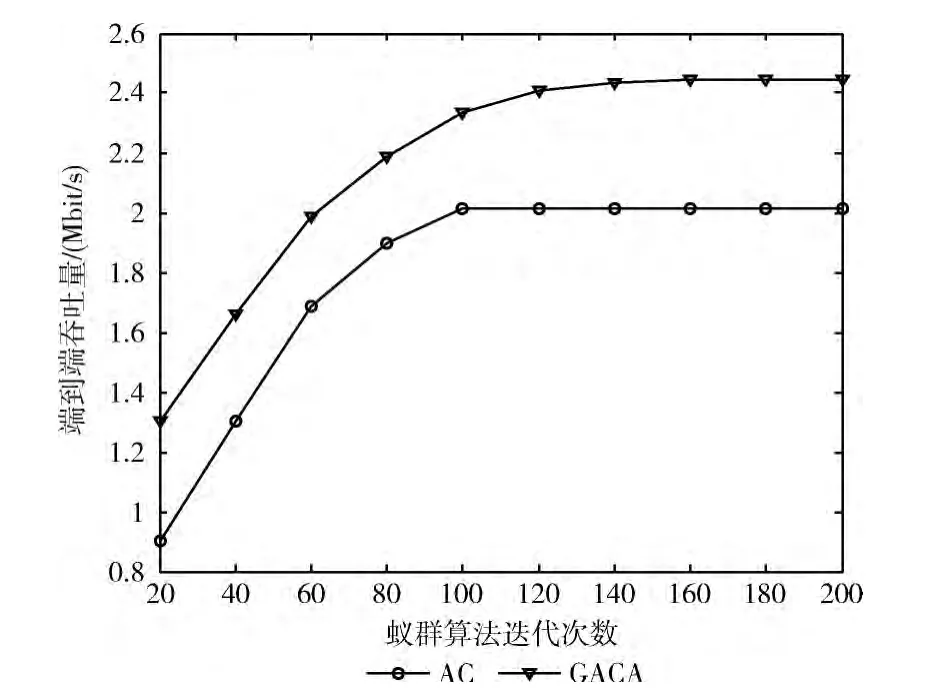
圖8 迭代次數對端到端吞吐量的影響
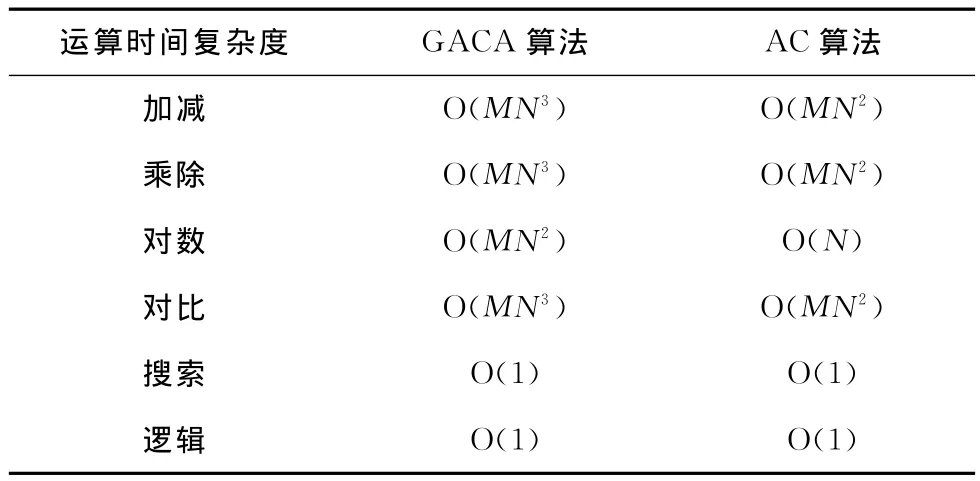
表1 算法復雜度分析
4 結束語
本文提出的GACA算法主要適用于認知無線電路由的研究,該算法綜合了遺傳算法和AC算法各自的優點,使得該算法在初始時收斂速度快,但它的算法復雜度要比AC算法高出很多。然而,隨著計算機處理技術的發展,這種代價是完全可以接受的。另外,自適應搜索方式的引入使得算法的收斂速度變慢但擴大了搜索范圍,這樣可以有效地避免了GACA算法過早陷入局部收斂狀態。經仿真結果比較,GACA算法不受種群數目的限制求出的結果比較穩定。雖然在迭代的后期算法收斂速度較慢,但與AC算法相比,GACA算法的實時性提高了18%,網絡吞吐量提高了23%。
[1]Akyildiz I,Lee W Y,Vuran M C,et al.Next generation dynamic spectrum access cognitive radio wireless networks:A survey [J].Computer Networks,2006,50 (13):2127-2159.
[2]Khalife H,Ahuja S,Malouch N,et al.Probabilistic path selection in opportunistic cognitive radio networks [C]//IEEE Global Telecommunications Conference,2008:4861-4865.
[3]YANG Chungang,LI Jiandong,LI Weiying,et al.Cognitive radio power allocation method based on non-cooperative game theory [J].Xi’an University of Electronic Science and Technology,2009,36 (1):1-4 (in Chinese).[楊春剛,李建東,李維英,等.認知無線電中基于非合作博弈的功率分配方法[J].西安電子科技大學學報,2009,36 (1):1-4.]
[4]Ahmed Tariq Sadiq,Amaal Ghazi Hamad.A hybrid bees simulated annealing algorithm to solve optimization & NP-complete problems[J].Eng &Tech Journal,2010,28 (2):271-281.
[5]FAN Yuanyuan,SANG Yingjun.The research of nonlinear control based on fuzzy neural network [C]//Proceedings of International Conference on Electrical and Control Engineering.Wuhan:IEEE,2010:2417-2420.
[6]WANG Zhenchao,WANG Jing,JING Xin.Multipath routing based on genetic algorithms [J].Computer Engineering,2011,37 (20):197-199 (in Chinese). [王振朝,王靜,荊鑫.基于遺傳算法的多路徑路由研究 [J].計算機工程,2011,37 (20):197-199.]
[7]QI Jin,ZHANG Shunyi,SUN Yanfei,et al.Multi-constrained QoS routing algorithm based on ant colony algorithm independent cognitive networks [J].Nanjing University of Posts and Telecommunications,2012,32 (6):86-90 (in Chinese).[亓晉,張順頤,孫雁飛,等.基于自主蟻群算法的認知網絡多約束QoS路由算法 [J].南京郵電大學學報,2012,32(6):86-90.]
[8]LI Yun,ZHANG Zhihui,HUANG Wei,et al.Cognitive radio networks based on multi-hop routing algorithms channel allocation [J].Systems Engineering and Electronics,2013,35(4):852-858 (in Chinese). [李云,張智慧,黃巍,等.基于信道分配的多跳認知無線電網絡路由算法 [J].系統工程與電子技術,2013,35 (4):852-858.]
[9]XIANG Biqun,ZHANG Zhenghua,QIN Fengxie,et al.A routing algorithm based on cognitive radio channel capacity estimation[J].Journal of Chongqing University of Posts and Telecommunications,2011,23 (4):406-410 (in Chinese).[向碧群,張正華,覃鳳謝,等.基于信道容量估計的一種認知無線電路由算法[J].重慶郵電大學學報,2011,23 (4):406-410.]
[10]Re E,Gorni G,Ronga L S,et al.Flexible and dynamic use of spectrum:The cognitive radio approach [J].Globalization of Mobile and Wireless Communications,2011,5 (1):159-183.
[11]Beltagy I,Youssef M,Mohamed E D.A new routing metric and protocol for multipath routing in cognitive networks[C]//Proc of the IEEE Wireless Communications and Networking Conference,2011:974-979.
[12]GAO Cunhao,YI Shi,THOMAS Y.Multicast communications in multi-hop cognitive radio networks [J].IEEE Journal on Selected Areas in Communications,2011,29 (4):784-793.
