基于音素混淆網絡的蒙古語語音關鍵詞檢測方法的研究
2015-04-25 09:57:38高光來鮑玉來
中文信息學報 2015年1期
飛 龍,高光來,鮑玉來
(1. 內蒙古大學 計算機學院,內蒙古 呼和浩特 010021;2. 內蒙古大學圖書館,內蒙古 呼和浩特,010021)
?
基于音素混淆網絡的蒙古語語音關鍵詞檢測方法的研究
飛 龍1,高光來1,鮑玉來2
(1. 內蒙古大學 計算機學院,內蒙古 呼和浩特 010021;2. 內蒙古大學圖書館,內蒙古 呼和浩特,010021)
蒙古語語音識別系統的詞表很難覆蓋所有的蒙古文單詞,并且隨著社會的發展,蒙古文的新詞和外來詞也越來越多。為了解決蒙古語語音關鍵詞檢測系統中的集外詞檢測問題,該文提出了基于音素混淆網絡的蒙古語語音關鍵詞檢測方法,并采用音素混淆矩陣改進了關鍵詞的置信度計算方法。實驗結果表明,基于音素混淆網絡的蒙古語語音關鍵詞檢測方法可以較好地解決集外詞的檢測問題。蒙古語語音關鍵詞檢測系統采用改進的置信度計算方法后精確率提高了6%,召回率提高了2.69%,性能得到明顯的提升。
蒙古語;關鍵詞檢測;集外詞;混淆網絡;音素混淆矩陣
1 引言
近年來,隨著計算機技術和多媒體技術的飛速發展,蒙古語語音資料在教育、影視、文化等諸多方面的應用越來越廣泛,數量急劇增加,已形成了豐富的民族文化資源。如何對這些語音文檔進行有效地檢索和分類成為了蒙古文信息處理領域中的一個熱點問題。語音關鍵詞檢測技術是根據用戶給定的查詢,從指定的語音數據集中返回與其對應的語音片段。
在之前的研究中,我們提出了基于詞混淆網絡(Confusion Network, CN)的蒙古文語音關鍵詞檢測方法[1],該方法分為兩個階段進行處理。第一階段為識別階段,通過蒙古語大詞匯量連續語音識別(Large Vocabulary Continuous Speech Recognition, LVCSR)系統[2-3]把語音識別成文本;第二階段為檢測階段,從識別的文本中查詢對應關鍵詞,并返回結果。蒙古語是有粘著性特點的語言,蒙古文單詞是由詞根綴加多個后綴組成,而所有的詞根和后綴可以組合成大規模的蒙古文單詞。現有的蒙古語LVCSR系統的發音詞典無法包含所有的蒙古文單詞。并且,隨著社會的發展,蒙古文的新詞和外來詞也越來越多。因此,蒙古文集外詞(Out of Vocabulary,OOV)的檢測問題成為了蒙古語語音關鍵詞檢測系統亟待解決的關鍵問題。
漢語LVCSR中的集外詞可以以詞(或單字)的合成詞形式被識別出來,因此在漢語語音識別任務和語音檢索任務中,集外詞問題往往被忽略而很少提及。英語語音檢索任務中集外詞問題一直是研究熱點之一,他們主要采用了子詞或音素的識別形式解決集外詞的檢測問題[4-7]。
為了解決蒙古文集外詞的檢測問題,本文提出了基于音素混淆網絡的蒙古語語音關鍵詞檢測方法。蒙古語語音文件被解碼成音素形式時正確識別率會變得很低,并會出現很多不符合韻律學的發音序列。為了提高系統的精準率和召回率,本文采用了音素混淆矩陣(Phoneme Confusion Matrix, PCM)來計算關鍵詞的置信度得分,并得到了較好的實驗結果。
本文其余部分組織如下: 第2節介紹了蒙古語發音特點;第3節詳細描述了基于音素混淆網絡的蒙古語語音關鍵詞檢測方法;第4節為實驗部分;最后為結論部分。
2 蒙古語發音特點
蒙古文是拼音文字,它的字母表由8個元音字母和27個輔音字母組成[8]。在蒙古語中,語音最小單位為音素,常用的口語發音音素共64個,其中元音音素37個,輔音音素27個,如表1所示。在蒙古語口語中,元音音素可分為兩類: 一類是獨立元音,這類元音音素發音比較清晰,比較完整,而且往往也是一個詞的重音所在,獨立元音包括處于單詞第一音節的短元音以及處于單詞任意位置的長元音和復合元音。另一類是依附元音,這類元音音素通常發音不夠清晰,不夠完整,它包括處于非第一音節的所有短元音。

表1 蒙古文音素表
3 基于音素混淆網絡的蒙古語語音關鍵詞檢測
基于音素混淆網絡的蒙古語語音關鍵詞檢測系統的框架如圖1所示。首先,利用蒙古語自動語音識別(Automatic Speech Recognition, ASR)系統將蒙古語語音文件進行解碼,并生成音素網格文件;其次,將音素網格文件轉化成混淆網絡結構的文件,并建立索引;最后,采用蒙古文字母到音素轉換系統[8]將關鍵詞轉換成對應的音素串,并利用音素串從索引庫中進行檢測。
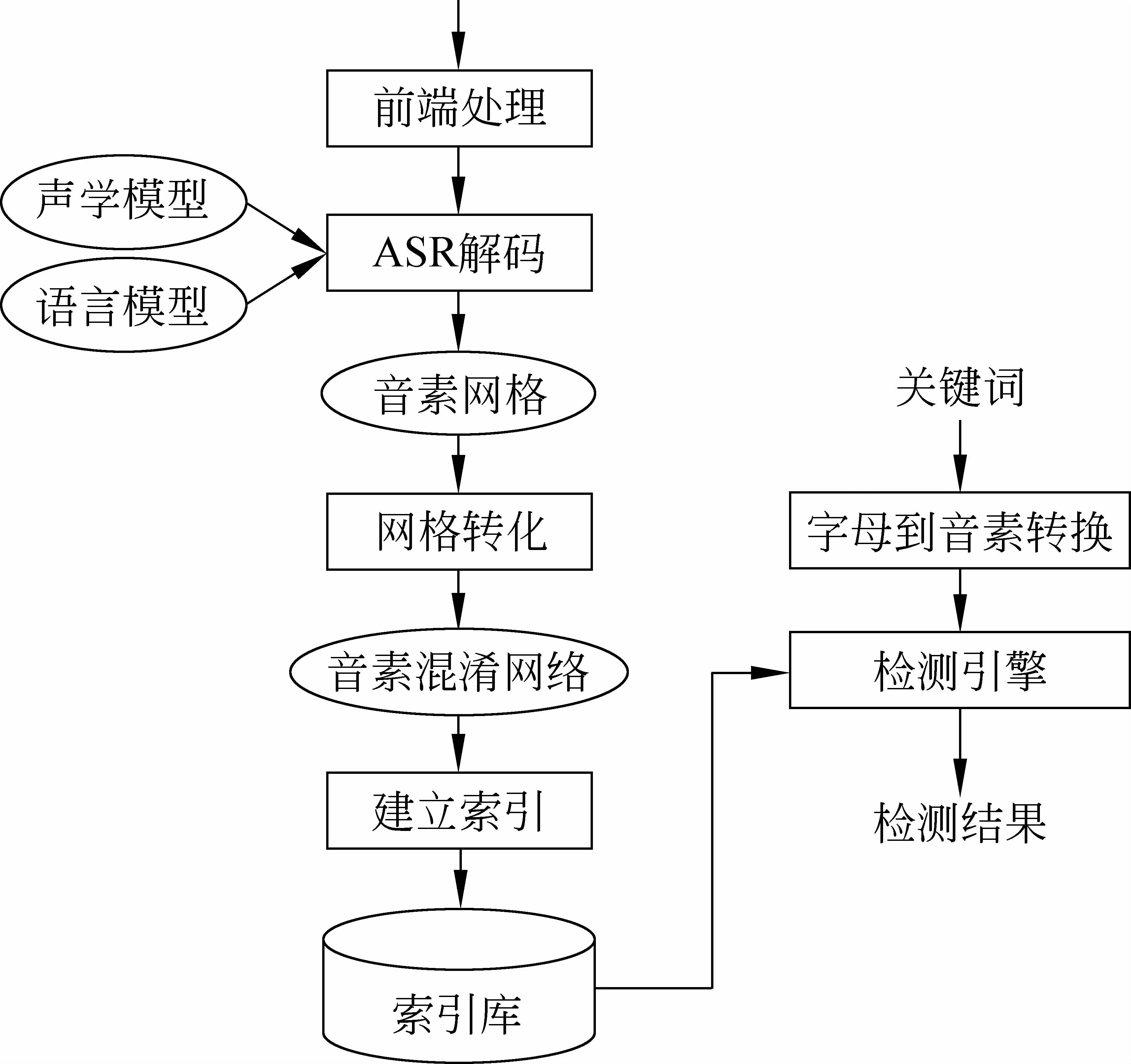
圖1 基于音素混淆網絡的蒙古文關鍵詞檢測系統框架
3.1 ASR解碼
本文采用蒙古語ASR系統對蒙古語語音文件進行了解碼。蒙古語ASR系統的聲學模型采用了詞內上下文相關的三音素模型,并利用決策樹進行了捆綁,最后采用CHMM混合高斯模型進行了訓練。訓練語言模型時,首先將訓練文本中的全部蒙古文單詞轉換成了音素串形式,并用n-gram語言模型進行了訓練。語言模型的平滑算法采用了Kneser-Ney平滑算法。最后,利用聲學模型和語言模型將蒙古語語音文件解碼成n-best音素網格文件。
3.2 音素混淆網絡的生成和索引的建立
最大似然識別結果(最優路徑)有比較高的錯誤率,但網格中往往包含了大量正確的補充信息。網格的結構圖如圖2所示。網格主要由節點和邊組成,每一個節點(Node)表示一個時間點,每一條邊(Arc)表示一個識別單元假設(Hypothesis: 音素),邊將不同時刻的節點連接起來,形成一個有向非循環圖。
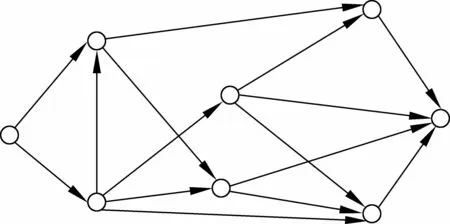
圖2 網格結構圖
音素網格可以用來進行語音關鍵詞檢測,然而,網格具有結構復雜,占用存儲空間大的缺點。Mangu等人[9]提出的混淆網絡(Confusion Network)是一種新穎的語音識別多候選存儲結構,是對網格進一步處理的結果,可以看作是一種簡化的線性網格結構,比網格占用存儲空間更小,研究表明混淆網絡能獲得比網格更小的詞錯誤率。混淆網絡的結構圖如圖3所示。
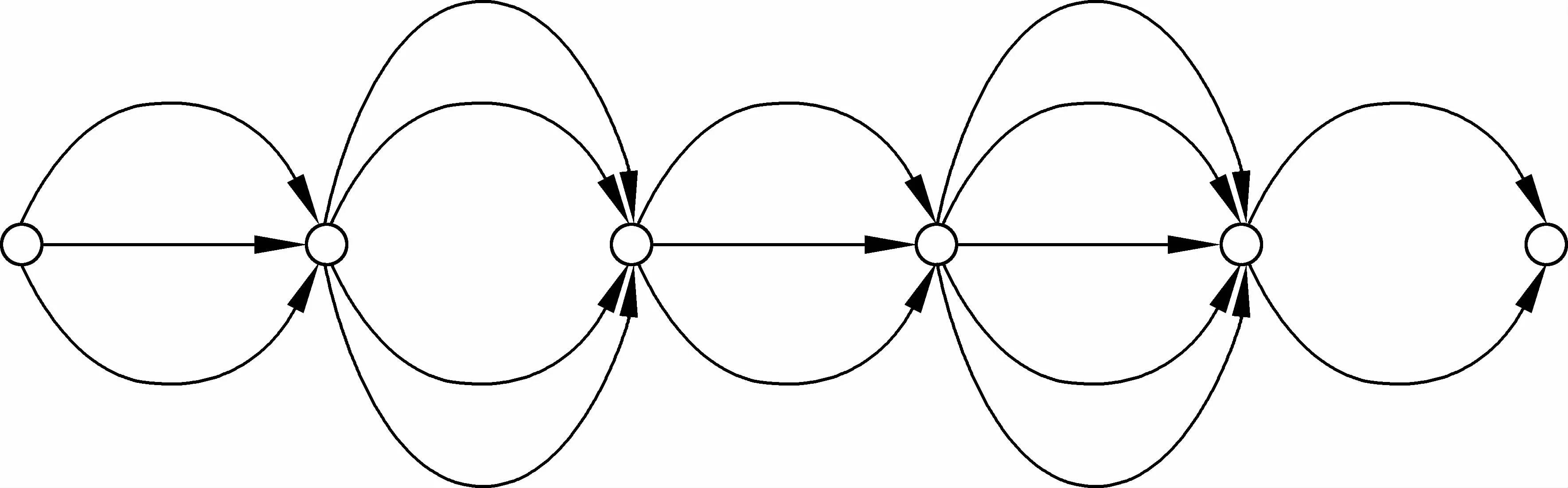
圖3 混淆網絡結構圖
為了提高檢測速度,本文對生成的音素混淆網絡文件建立了索引。音素混淆網絡中存在著大量的空弧,所以對索引庫進行搜索時必須對空弧也要進行處理。本文建立索引時為了保證混淆網絡的完整性,將空弧當成獨立的一個音素進行了處理,所以對空弧也建立了對應的索引。對空弧建立索引時,因為空弧只有后驗概率得分,沒有其他附加信息(如開始時間、持續時間、聲學得分和語言模型得分等),所以將其他信息都置為了空。
首先,我們對音素混淆網絡建立了前向索引,并根據前向索引建立了逆向索引。逆向索引的結構圖如圖4所示。
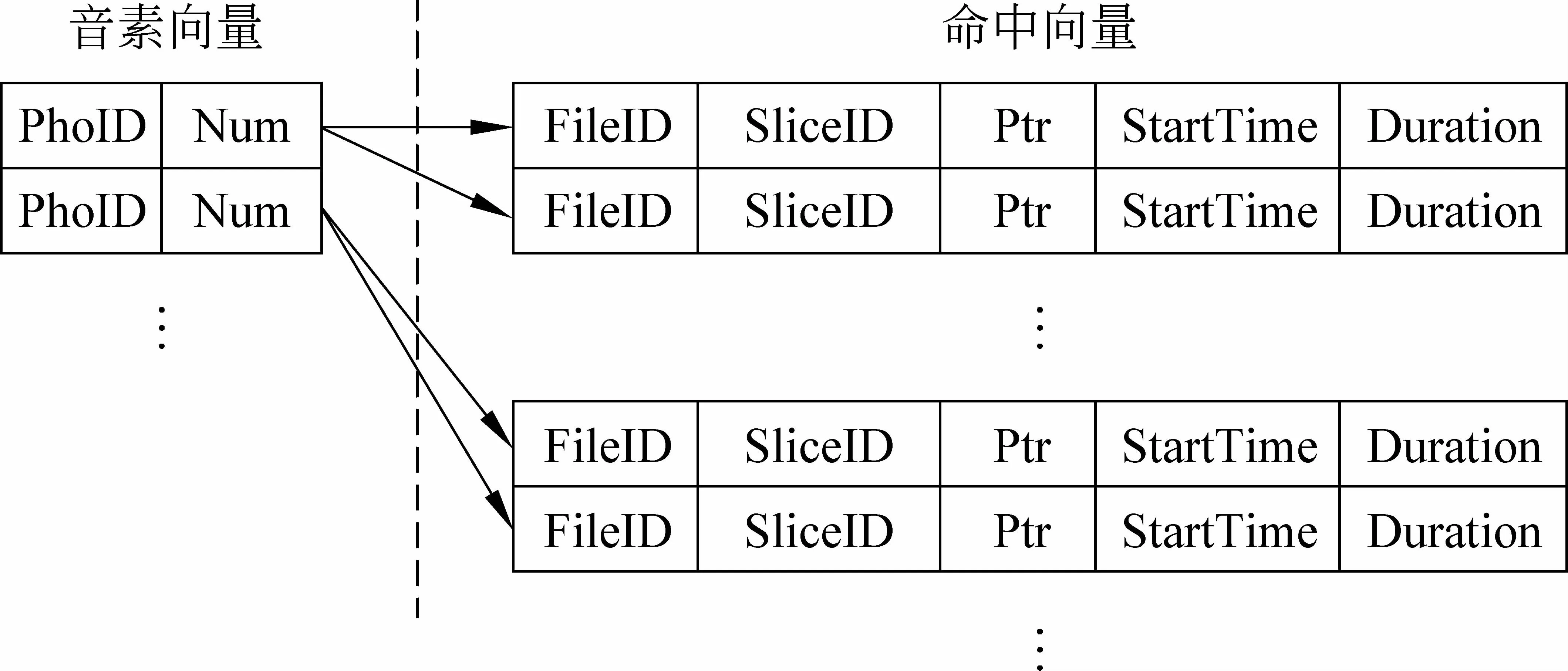
圖4 音素逆向索引結構
其中,PhoID為音素的編號,Num表示該音素對應的命中向量個數,FileID為語音文件編號,SliceID為混淆集編號,Ptr為音素的后驗概率,StartTime為音素的開始時間,Duration為音素的持續時間。
3.3 關鍵詞的搜索與確認
3.3.1 音素混淆矩陣
PCM的每個元素p(wi|wj)代表音素wj被替換成音素wi的概率。我們通過音素混淆網絡生成混淆矩陣。假設語音片段中都包含音素wj,則分類函數α(n)定義為式(1)。
那么音素混淆概率p(wi|wj)可以被表示成式(2)。
其中,N表示訓練數據中的語音片段的總數,K表示所有音素的數目,count(wk|wj)表示在同一個語音片段中跟wj對齊的wk的數目。
3.3.2 搜索與確認
對于輸入關鍵詞,經過字母到音素轉換得到相應音素串,對每個音素,按照混淆概率由高到低排列,找出前n個競爭音素,生成該音素的競爭集VieSet。假設關鍵詞為Q,轉換成音素串形式為Q={q1,q2,...,qm},m為音素數目。對于混淆網絡D,關鍵詞Q的置信度得分為score(m,D),可以表示成式(3)和式(4)。
其中,λ為權重系數,p(qi|D)為qi的后驗概率,Prela(i,D)為音素qi的競爭集VieSet(qi)的后驗概率總和,p(qi|φj)為混淆矩陣的概率值。
音素混淆網絡中存在著大量的空弧,所以索引搜索時必須對空弧也要進行處理。在音素逆向索引中搜索關鍵詞的過程如圖5所示。Heps表示刪除命中向量(對應混淆網絡中的空弧),Hi表示音素qi和相同位置的所有競爭集VieSet(qi)的命中向量的合并。Hi的置信度可以通過式(3)得到。搜索方法的主要思想是: 首先,從H1中搜索q1,如果命中則生成候選集X1,然后從H2,Heps和X1中搜索q1q2,如果命中則生成候選集X2,通過這種方式我們可以檢測到音素串對應的候選集Xm;最后,通過候選集Xm的置信度排序得到關鍵詞的檢測結果。
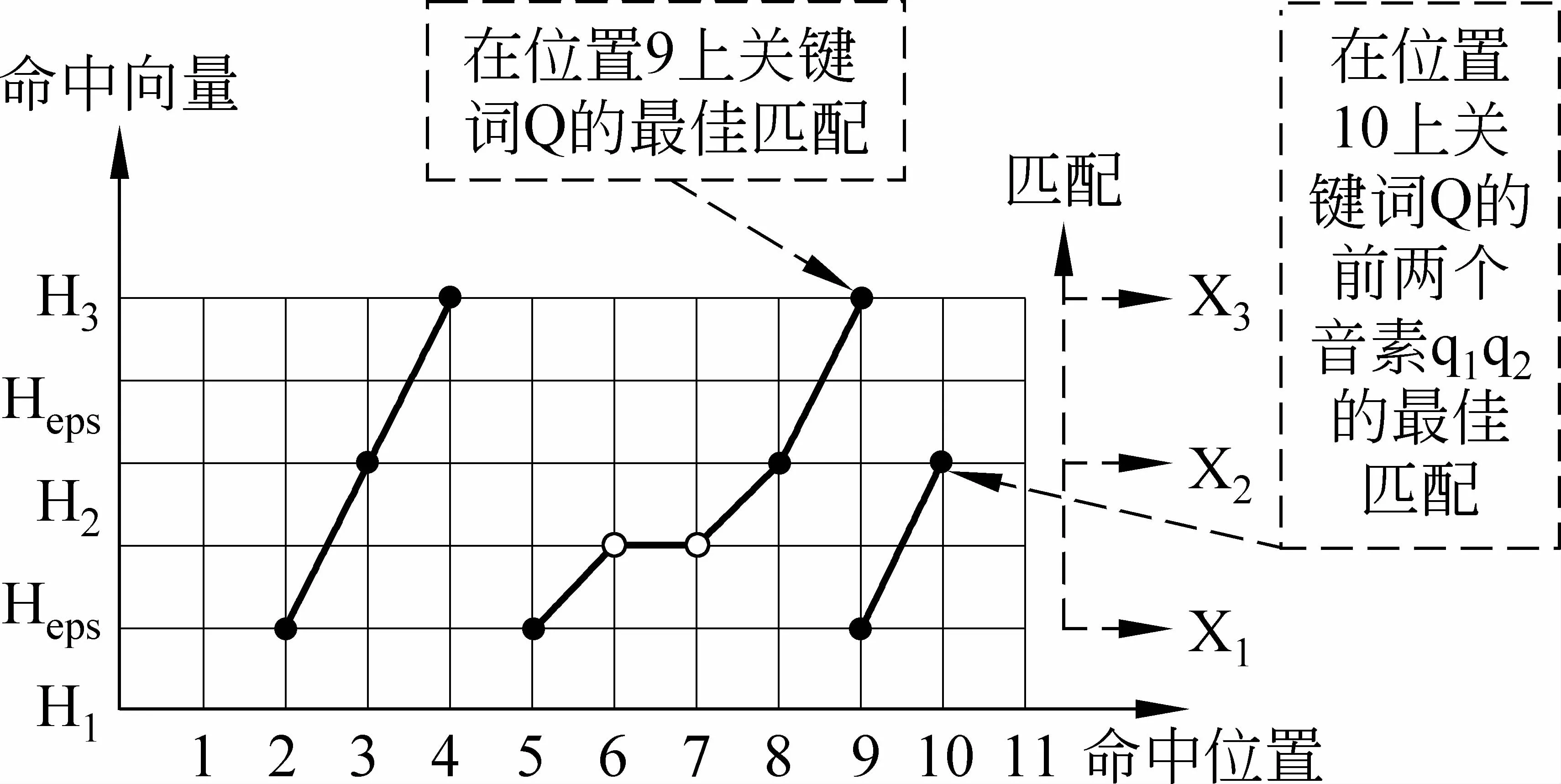
圖5 從音素逆向索引中搜索關鍵詞的過程
4 實驗
實驗使用的工具有HTK3.4[10]和SRILM[11]。實驗用來檢測關鍵詞的蒙古語語音語料為15 000句,約21小時。本文選擇了10個關鍵詞(query)對測試語音進行了檢測,每個關鍵詞包含2個到5個蒙古文單詞。
召回率(Recall rate)和精確率(Precision Rate)是信息檢索的重要評估方法,也可以用來評估關鍵詞檢測系統的檢出性能,對整個關鍵詞檢出結果集的質量進行量化評價。召回率是指關鍵詞被正確找到的比例,精確率是指所有找到關鍵詞中正確的比例。
實驗利用基于聯合序列模型的蒙古文字母到音素的轉換系統[8]將10個關鍵詞轉換成了音素串形式。我們對沒有采用PCM的基于音素混淆網絡的關鍵詞檢測方法和采用了PCM的基于音素混淆網絡的關鍵詞檢測方法進行了實驗比較。在采用PCM的方法中,每個音素采用了混淆矩陣概率排名為前5的競爭音素作為了競爭集。
本文通過11點的召回率-精確率曲線分析了兩種關鍵詞檢測方法的性能,并對所有關鍵詞的檢測結果進行了平均計算,結果如圖6所示。表1給出了兩種關鍵詞檢測方法的相應的11點平均精確率、對應的召回率。從圖6和表2中可以看出采用PCM方法的精確度和召回率都明顯優于沒有采用PCM的方法,并且平均精確度提高了6%,召回率提高了2.69%。
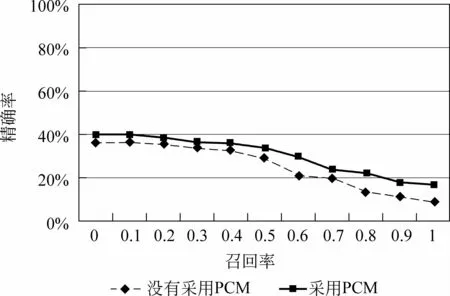
圖6 召回率-精確率曲線
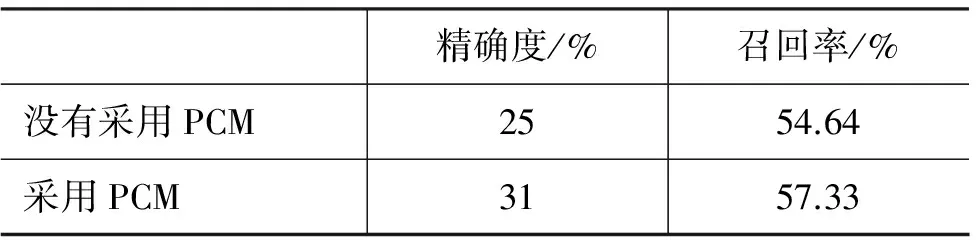
表2 對傳統蒙古文集外詞檢測的結果比較
5 結論
為了解決蒙古文集外詞的檢測問題,本文提出了基于音素混淆網絡的蒙古語語音關鍵詞檢測方法。首先,本文介紹了蒙古語發音特點;其次,介紹了基于音素混淆網絡的蒙古文關鍵詞檢測系統的框架;第三,概述了蒙古語ASR解碼和建立音素索引的方法;最后,詳細描述了采用PCM的關鍵詞搜索和確認方法。實驗結果表明,基于音素混淆網絡的蒙古語語音關鍵詞檢測方法可以較好的解決集外詞的檢測問題,并且采用PCM的置信度計算方法提高了系統的整體性能。
[1] Feilong Bao, Guanglai Gao. The Research on Mongolian Spoken Term Detection Based on Confusion Network[C]//Proceedings of the Chinese Conference on Pattern Recognition (CCPR2012).Beijing, 2012:606-612.
[2] Feilong Bao, Guanglai Gao. Improving of Acoustic Model for the Mongolian Speech Recognition System[C]//Proceedings of the Chinese Conference on Pattern Recognition (CCPR2009). Nanjing, 2009:616-620.
[3] Feilong Bao, Guanglai Gao, Xueliang Yan. Segmentation-based Mongolian LVCSR Approach[C]//Proceedings of the 38th International Conference on Acoustics, Speech, and Signal Processing (ICASSP2013), Vancouver, 2013: 8136-8139.
[4] J Mamou, B Ramabhadran and O Siohan. Vocabulary independent spoken term detection[C]//Proceedings of the ACM-SIGIR’07. Amsterdam, 2007:615-622.
[5] Ville T. Turunen and Mikko Kurimo, Indexing Confusion Networks for MorPh-based Spoken Document Retrieval [C]//Proceedings of the ACM-SIGIR’07. Amsterdam, 2007:631-638.
[6] D Wang. Out-of-vocabulary spoken term detection [D]. Ph.D. dissertation University of Edinburgh. 2010.
[7] G Gosztolya and L Toth. Spoken term detection based on the most probable phoneme sequence[C]//Proceedings of the 2011 International Symposium on Applied Machine Intelligence and Informatics (SAMI) (IEEE), Slovakia, 2011:101-106.
[8] 飛龍,高光來,閆學亮. 蒙古文字母到音素的轉換方法的研究[J]. 計算機應用研究, 2013,30(6): 1696-1700.
[9] L Mangu, E Brill, and A Stolcke: Finding consensus in speech recognition: word error minimization and other applications of confusion networks [J]. Computer Speech and Language, 2000, 14(4): 373-400.
[10] Young S, et al. The HTK book (Revised for HTK version 3.4.1)[M]. Cambridge University.2009.
[11] A Stolcke. SRILM—An Extensible Language Modeling Toolkit[C]//Proceedings of Intl. Conf. Spoken Language Processing. Denver, Colorado,2002.
Research on Mongolian Spoken Term Detection Based on Phoneme Confusion Network
BAO Feilong1, GAO Guanglai1, BAO Yulai2
(1. College of Computer Science, Inner Mongolia University, Hohhot, Inner Mongolia 010021, China; 2. Library of Inner Mongolia University, Hohhot, Inner Mongolia 010021, China)
To deal with Out-of-Vocabulary detection on Mongolian spoken term detection system, this paper proposes a Mongolian spoken term detection method based on phoneme confusion network.The Confidence Measure is improved by incorporating phoneme confusion matrix. Experimental results show that our method obtains a satisfying performance in the task of Mongolian Out-of-Vocabulary detection, with 6% improvement in precision rate and 2.69% in recall rate.
Mongolian; spoken term detection; Out-of-Vocabulary word; confusion network; phoneme confusion matrix

飛龍(1985—),博士,講師,主要研究領域為蒙古文信息處理,語音識別,語音合成。E?mail:csfeilong@imu.edu.cn高光來(1964—),碩士,教授,博士生導師,主要研究領域為模式識別,自然語言處理。E?mail:csggl@imu.edu.cn鮑玉來(1975—),碩士,副研究館員,碩士生導師,主要研究領域為數字圖書館,信息資源管理。E?mail:65003846@qq.com
1003-0077(2015)01-0178-05
2013-04-08 定稿日期: 2013-07-11
國家自然科學基金(61263037, 71163029);內蒙古自然科學基金(2014BS0604);內蒙古大學高層次人才引進科研項目
TP391
A
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
兒童故事畫報(2019年5期)2019-05-26 14:26:14
海峽科技與產業(2016年3期)2016-05-17 04:32:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
