龔小龍,王明文,萬劍怡,王曉慶
(江西師范大學(xué) 計(jì)算機(jī)信息工程學(xué)院,江西 南昌 330022)
?
結(jié)合鄰近度的語義位置語言檢索模型
龔小龍,王明文,萬劍怡,王曉慶
(江西師范大學(xué) 計(jì)算機(jī)信息工程學(xué)院,江西 南昌 330022)
在傳統(tǒng)的檢索模型中,文檔與查詢的匹配計(jì)算主要考慮詞項(xiàng)的統(tǒng)計(jì)特征,如詞頻、逆文檔頻率和文檔長(zhǎng)度,近年來的研究表明應(yīng)用查詢?cè)~項(xiàng)匹配在文檔中的位置信息可以提高查詢結(jié)果的準(zhǔn)確性。如何更好地刻畫查詢?cè)~在文檔中的位置信息并建模,是研究提高檢索效果的問題之一。該文在結(jié)合語義的位置語言模型(SPLM)的基礎(chǔ)上進(jìn)一步考慮了詞的鄰近信息,并給出了用狄利克雷先驗(yàn)分布來計(jì)算鄰近度的平滑策略,提出了結(jié)合鄰近度的位置語言檢索模型。在標(biāo)準(zhǔn)數(shù)據(jù)上的實(shí)驗(yàn)結(jié)果表明,提出的檢索模型在性能上要優(yōu)于結(jié)合語義的位置語言模型。
語義位置語言模型;Dirichlet平滑;鄰近度信息;檢索模型
1 引言
在過去的幾十年間,信息檢索領(lǐng)域出現(xiàn)了很多經(jīng)典的模型,諸如布爾模型、向量空間模型以及概率模型等。1998年,Ponte和Croft[1]首次將統(tǒng)計(jì)語言模型應(yīng)用于信息檢索,提出了查詢似然語言模型,之后研究者又陸續(xù)提出了隱馬爾科夫模型、統(tǒng)計(jì)翻譯模型和風(fēng)險(xiǎn)最小化模型等,但是大多數(shù)檢索模型都是僅使用了詞在文檔中的頻率這一特征,而未考慮詞在文檔中的位置關(guān)系,對(duì)那些相同詞在不同文章中的位置和順序的不同,大多數(shù)檢索模型對(duì)這樣的文檔的檢索得分是一樣的,而考慮了位置關(guān)系的檢索模型的檢索效果就會(huì)有所區(qū)分。基于此,Lv和Zhai[2]提出了一種位置語言模型(PLM),該模型細(xì)微到每個(gè)位置建立一個(gè)語言模型,并成功應(yīng)用于信息檢索,而且考慮了文檔中詞與詞的位置關(guān)系。但該模型還具有可完善的地方,在上述模型基礎(chǔ)上,余偉和王明文[3]對(duì)其做出了改進(jìn),提出了一種結(jié)合語義的位置語言模型(SPLM),并在文中提出了一種新的技術(shù)——“平滑互信息”來度量?jī)蓚€(gè)詞之間的轉(zhuǎn)移概率。通過使用Jelinek-Mercer平滑和相對(duì)熵(KL)來衡量查詢?cè)~的分布和查詢?cè)~在文檔中的位置i的檢索得分。
信息檢索中的關(guān)鍵任務(wù)是對(duì)用戶的查詢所匹配的相關(guān)性文檔集進(jìn)行排序。在這一領(lǐng)域里,概率模型已經(jīng)很成功地被應(yīng)用于文檔的排序中。但是傳統(tǒng)的檢索模型并沒有考慮一篇文檔中查詢?cè)~的鄰近度信息,而最近幾年提出的PLM模型和SPLM模型在其檢索模型中也沒有明確詳細(xì)地指出查詢?cè)~在文檔中的鄰近度關(guān)系。鄰近度代表的是一篇文章中查詢?cè)~和查詢?cè)~之間的靠近程度和緊密程度,潛在的意思是,詞與詞之間如果越緊密,就越能說明它們的主題相關(guān),也因此說明該文檔和用戶查詢的意圖是相關(guān)的。Beeferman,Berger和Lafferty[4]在其文中也表達(dá)出了詞項(xiàng)鄰近度對(duì)于詞與詞之間的依賴性有較強(qiáng)的影響。
先前也有一些研究將鄰近度因素整合到已有的檢索模型當(dāng)中去[5-7],這些工作都說明了一個(gè)恰當(dāng)?shù)泥徑炔呗缘脑O(shè)計(jì)可以提高概率檢索模型的性能。本文提出了在SPLM的檢索模型的基礎(chǔ)上,加入了查詢?cè)~在文檔中的內(nèi)部結(jié)構(gòu)信息,即鄰近度信息,來提升文檔檢索的準(zhǔn)確率,并且我們使用了Dirichlet先驗(yàn)平滑方法來對(duì)比SPLM中的JM平滑的方法。實(shí)驗(yàn)結(jié)果表明本文提出的加入鄰近度信息的檢索模型使得文檔檢索的準(zhǔn)確率相比于原檢索模型有一定的提高。
本文組織如下:第2節(jié)對(duì)傳統(tǒng)的模型與鄰近度信息的結(jié)合進(jìn)行了介紹與分析;第3節(jié)介紹結(jié)合鄰近度的語義位置語言檢索模型的構(gòu)建;第4節(jié)描述了多種不同的詞項(xiàng)鄰近度策略的計(jì)算方法;第5節(jié)介紹了實(shí)驗(yàn)環(huán)境并對(duì)實(shí)驗(yàn)結(jié)果進(jìn)行了分析;第6節(jié)是工作總結(jié)。
2 相關(guān)研究
詞項(xiàng)鄰近度所表達(dá)的是在一個(gè)指定的距離范圍中詞項(xiàng)同現(xiàn)的情況。國(guó)外有相當(dāng)一部分工作是將詞項(xiàng)鄰近度的信息整合到傳統(tǒng)的布爾模型和概率模型當(dāng)中,如Keen[8-9]首先嘗試將詞項(xiàng)鄰近度加入到布爾檢索模型中,而后Buttcher[10]等人提出將詞項(xiàng)鄰近度得分加入到BM25中以此得到對(duì)多個(gè)不同數(shù)據(jù)集合上效率的提升。Tao[6]等在文章中系統(tǒng)地闡述了五個(gè)鄰近度策略,并分別對(duì)KL距離的檢索模型中和BM25檢索模型中所達(dá)到的效率做了相應(yīng)的比較。國(guó)內(nèi)相關(guān)的工作中韓中元、李生[11]等提出的利用近鄰信息取代聚類語言模型中的聚類信息,通過計(jì)算文檔之間的KL距離來選擇近鄰文檔,有助于消除聚類邊界文檔使用聚類語言模型時(shí)所帶來的不確定性影響。對(duì)鄰近度的建模可以看作是間接捕捉詞項(xiàng)獨(dú)立性的一種方法,在一些早期的工作當(dāng)中,是通過計(jì)算查詢?cè)~項(xiàng)在文檔中的跨度和密度來度量文檔間相似度得分的。文獻(xiàn)[6]嘗試將鄰近度因子分別和BM25概率模型與KL距離模型相結(jié)合,最終的得分函數(shù)表示為式(1)和式(2)。
Rank(Q,D)=BM25(q,d)+
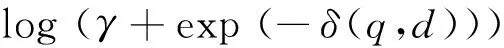
(1)
Rank(Q,D)=KL(q,d)+
(2)
其中,KL(q,d),BM(q,d)是分別通過KL距離和BM25模型計(jì)算的排序得分,δ(q,d)是和查詢q有關(guān)的文檔d中的鄰近度距離的度量。
以上所有的工作主要集中在將詞項(xiàng)鄰近度信息整合到布爾模型和概率模型中,國(guó)內(nèi)外也有部分研究者嘗試將鄰近度信息加入到語言模型中。但也包含兩個(gè)主要的問題:1) 國(guó)內(nèi)多數(shù)研究如文獻(xiàn)[11]旨在處理文檔之間的鄰近關(guān)系,丁凡、王斌[12]在文中提出的融入詞項(xiàng)依存關(guān)系的檢索模型, 金凌、吳文虎[13]提出考慮一個(gè)句子中非相鄰詞之間的關(guān)系,通過距離加權(quán)函數(shù)來引入距離信息以及文獻(xiàn)[14]中提出的查詢?cè)~項(xiàng)之間的平行概念效應(yīng),大部分對(duì)文檔中查詢?cè)~項(xiàng)間的鄰近度沒有給出詳細(xì)的形式化定義。2) 國(guó)外研究者如文獻(xiàn)[15]中提出的整合鄰近度信息的語言模型較復(fù)雜(如式(3)),從而導(dǎo)致算法復(fù)雜度過高,效果雖有,但致使計(jì)算效率降低,

(3)
其中dl,i為詞i在文檔dl中的頻率,nl是文檔總長(zhǎng)度,C為文檔集合,V為文檔集合中所有詞匯表的集合。Prox(wi)為詞項(xiàng)鄰近度得分,μ,λ為平滑參數(shù)。實(shí)驗(yàn)部分將文獻(xiàn)[15]中提出的上述模型與本文提出的模型進(jìn)行了復(fù)雜度的對(duì)比。
在語言模型方面,Lv和Zhai[2]提出的位置語言模型(PLM),余偉和王明文[3]提出的結(jié)合語義的位置語言模型(SPLM)在檢索效率方面都有不錯(cuò)的效果。但以上語言模型中的平滑方法都忽略了文檔中詞項(xiàng)結(jié)構(gòu)的信息,本文結(jié)合SPLM模型,并利用Dirichlet平滑的方法,僅考慮查詢?cè)~在文檔中的鄰近度信息,為確保降低計(jì)算復(fù)雜度,本文采用平滑方法與鄰近度線性結(jié)合的方式,以期能夠更好地利用詞在文檔中的分布,獲得檢索性能上的提升。
3 結(jié)合鄰近度的語義位置語言檢索模型
為了形成一個(gè)有效的查詢語句,用戶會(huì)盡可能用多的查詢?cè)~來共同的表達(dá)其查詢的意圖。在文檔中查詢?cè)~越是相近,此文檔就與查詢?cè)~越相關(guān),文檔就更能滿足用戶查詢的意圖。如給定兩篇文檔Da和Db,假設(shè)其他因素都是相同的,當(dāng)查詢q中的查詢?cè)~在Da中比在Db中出現(xiàn)的要更加鄰近,那我們可認(rèn)為文檔Da相比于文檔Db和查詢q更相關(guān)。由此,在SPLM上的檢索模型中,增加查詢?cè)~Wi為中心的鄰近度得分這個(gè)因素。
3.1 語義位置語言檢索模型的建立
在文獻(xiàn)[3]中首先引入一個(gè)隨機(jī)變量d,d表示文檔D中其他位置與目標(biāo)位置i的距離,這個(gè)距離含有正負(fù)關(guān)系(d>0,表示在目標(biāo)位置i的后面,d<0表示在目標(biāo)位置i的前面)。由此,d=1-i,d=2-i, ...,d=|D|-i就是樣本空間一個(gè)劃分,根據(jù)全概率公式有式(4)。
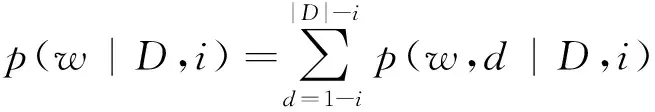

(4)
p(j|D,i)和p(w|D,j)的估計(jì)以及模型中其他概率估計(jì)均可參看文獻(xiàn)[3]。并最終提出SPLM模型為式(5)。
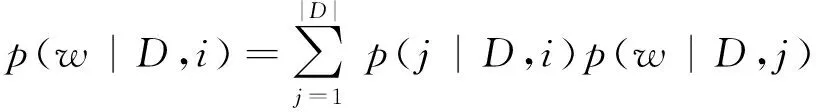
(5)
其中k(i,j)是權(quán)重函數(shù)(式(6)),文獻(xiàn)[3]中選取高斯核函數(shù)來度量:
(6)
由上式可知: 當(dāng)位置j離位置i越遠(yuǎn)時(shí),位置j對(duì)位置i的權(quán)重就越小。還可以對(duì)式(5)的分母進(jìn)行如下近似計(jì)算:
(7)
由于文檔集中詞的稀疏性,需對(duì)SPLM進(jìn)行Jelinek-Mercer平滑,即文獻(xiàn)[3] 最后提出的檢索模型為式(8)。
(8)
其中ε是平滑參數(shù),范圍[0,1];p(w|D,i)可采用式(5)計(jì)算。
3.2 結(jié)合鄰近度的語義位置語言檢索模型的建立
假設(shè)有一查詢“搜索引擎”和兩篇不同的文檔,文檔1中為“…搜索引擎…”,而文檔2中為“…搜索…引擎…” 直觀上看,文檔1中查詢?cè)~是毗鄰的,文檔1理應(yīng)比文檔2的排序得分高。相比之下,文檔2中兩個(gè)查詢?cè)~不相鄰,并不能直接表達(dá)出作為名詞的“搜索引擎”的概念,而更可能是一篇同時(shí)闡述有關(guān)“搜索”和“引擎”兩個(gè)不同概念的文檔。這就說明文檔1查詢的相關(guān)性要強(qiáng)于文檔2,而事實(shí)上,在傳統(tǒng)平滑算法的語言模型中,這兩篇文檔對(duì)于該查詢的計(jì)算得分是相同的,這也暴露出語言模型中平滑方法的不足。
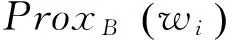
(9)
其中μ是平滑參數(shù),wi表示查詢語句中第i個(gè)位置的單詞,|q|是查詢語句的長(zhǎng)度。
其次,使用w在查詢?cè)~Q的分布和在文檔D中位置i的分布的差異性(負(fù)KL散度)來衡量文檔D中位置i的檢索得分,并取文檔中得分最高的前k個(gè)位置的平均得分作為文檔D的檢索得分:
(10)
所以如果位置i上w的分布與查詢?cè)~中w的分布越一致,則檢索得分S(Q,D)就越高。其中topK表示文檔D中檢索得分最高的k個(gè)的位置。
4 詞項(xiàng)鄰近度策略
第一, 如何定義一篇文檔中兩個(gè)不同的查詢?cè)~之間的距離?
第二, 如何設(shè)計(jì)一個(gè)恰當(dāng)?shù)姆蔷€性函數(shù)來將距離轉(zhuǎn)化為鄰近度得分?
4.1 詞項(xiàng)距離和鄰近度得分定義方法
首先來解決第一個(gè)問題。要想知道不同查詢?cè)~之間的距離,先要知道每個(gè)查詢?cè)~在文檔中的位置信息,但主要的困難在于一個(gè)查詢?cè)~可能在一篇文檔中出現(xiàn)了多次。本文按如下方式來解決,設(shè)Q={Q1,Q2……Qn}代表一條查詢語句中不同的查詢?cè)~,用另外一個(gè)集合PQi={Pi1,Pi2……Pim}來表示查詢?cè)~Qi在文檔D中出現(xiàn)的所有位置。用Dis(x,y;D)(式(11)和式(12))來表示不同詞項(xiàng)間的距離。跟隨文獻(xiàn)[6]的工作,本文用詞項(xiàng)在文檔中的位置靠得最近的那段長(zhǎng)度來作為這對(duì)詞項(xiàng)之間的距離。
Dis(Qi,Qj;D)=
(11)
(12)
|D|代表的是文檔D的長(zhǎng)度,|PQi|代表的是查詢?cè)~
Qi在文檔D中出現(xiàn)的次數(shù)。這里要注意到詞項(xiàng)對(duì)的距離是有對(duì)稱性的即Dis(Qi,Qj;D)=Dis(Qj,Qi;D)。
解決了查詢?cè)~之間距離的問題之后,接下來定義一個(gè)函數(shù)來將距離轉(zhuǎn)化成詞項(xiàng)對(duì)的鄰近度得分。根據(jù)前面所得的分析可知,查詢?cè)~距離越遠(yuǎn)說明表達(dá)的意圖和文檔主題越不相關(guān),那它們的得分也要相應(yīng)的低些。下面的指數(shù)形式的公式(13)用來給鄰近度打分,其中arg是控制得分函數(shù)的參數(shù),distance代表的是距離:
(13)
所以最終的詞項(xiàng)鄰近度得分本文定義為式(14)。
(14)
4.2 以詞項(xiàng)為中心的鄰近度計(jì)算方法
基于以上的策略,考慮三種不同的詞項(xiàng)中心化鄰近度計(jì)算方法(Minimum,Average和Summation)。
定義1(基于最小距離的詞項(xiàng)鄰近度(MinDist)): 在這個(gè)策略中,查詢?cè)~項(xiàng)的鄰近度得分是依靠查詢?cè)~之間的最短距離來計(jì)算的,本文表示成式(15)。
(15)
定義2(基于平均距離的詞項(xiàng)鄰近度(Average)): 用所有查詢?cè)~之間的平均距離來計(jì)算查詢?cè)~項(xiàng)的鄰近度分?jǐn)?shù),本文表示成式(16)。
(16)
定義3(基于所有詞項(xiàng)對(duì)鄰近度求和的詞項(xiàng)鄰近度(Summation)): 這個(gè)方法首先對(duì)任何一個(gè)查詢?cè)~不同的配對(duì)進(jìn)行鄰近度得分計(jì)算,然后再將其相加作為本查詢?cè)~的鄰近度得分:
(17)
注意,以上提出的方法都要首先通過計(jì)算匹配查詢?cè)~項(xiàng)之間的距離而后才能進(jìn)行定義。
5 實(shí)驗(yàn)
5.1 數(shù)據(jù)集與評(píng)價(jià)指標(biāo)
5.1.1 數(shù)據(jù)集介紹與預(yù)處理
本文選取了三個(gè)常用的標(biāo)準(zhǔn)測(cè)試文檔集adi,
med, cran*ftp://ftp.cs.cornell.edu/pub/smart/,數(shù)據(jù)集的具體情況如表1所示。
預(yù)處理階段主要進(jìn)行了以下步驟:
Step1 提取了每篇文檔中的
和<BODY>部分的內(nèi)容;</p><p>Step2 對(duì)< TITLE >和<BODY>中的內(nèi)容過濾非法字符(包括標(biāo)點(diǎn)符號(hào)和阿拉伯?dāng)?shù)字等),只保留我們需要的英文單詞,然后將英文字母全部轉(zhuǎn)換成小寫形式;</p><p>Step3 根據(jù)標(biāo)準(zhǔn)的英文停用詞表,對(duì)Step 2所得的文本去停用詞;</p><p>Step4 采用Porter Stemmer算法,對(duì)Step 3所得的文本進(jìn)行詞干化處理。</p><p><img src="https://cimg.fx361.com/images/2023/0130/3fefd0ea1a0eac2044704770ea615e21575a3bdd.webp"/></p><p>表1 實(shí)驗(yàn)中的數(shù)據(jù)集</p><p>值得注意的是,Zhai在文獻(xiàn)[17]的實(shí)驗(yàn)采取了保留停用詞,文獻(xiàn)[18]中采取了去除停用詞。本文選擇的是后一種情況,理由是停用詞的加入會(huì)疏遠(yuǎn)詞與詞的位置關(guān)系。當(dāng)然停用詞不能去除得太多,因?yàn)檫@些詞畢竟含有語義。在計(jì)算鄰近度方面,我們只考慮了查詢語句中在總詞匯表中存在的查詢</p><p>詞,舍棄不在總詞匯表中的查詢?cè)~,然后計(jì)算其相應(yīng)的鄰近度。</p><p>5.1.2 參數(shù)設(shè)置與評(píng)價(jià)指標(biāo)</p><p>本文對(duì)三種檢索算法進(jìn)行了實(shí)驗(yàn): BM25和采用JM平滑的SPLM的檢索模型,兩者作為基準(zhǔn)線;使用Dirichlet平滑改進(jìn)的SPLM檢索模型,為了方便,實(shí)驗(yàn)結(jié)果中簡(jiǎn)記為“SPLM_1”;結(jié)合鄰近度的Dirichlet平滑的SPLM的檢索模型,實(shí)驗(yàn)結(jié)果中簡(jiǎn)記為“Pro_SPLM”。</p><p>本文的檢索模型和SPLM的檢索模型含有1個(gè)共同的參數(shù): topk,而Pro_SPLM,即公式(9),還另外含有2個(gè)參數(shù): arg,μ。通過對(duì)數(shù)據(jù)集上的訓(xùn)練,按如下方法設(shè)置參數(shù): (1)對(duì)于topk,三個(gè)數(shù)據(jù)集都取2;(2)對(duì)于核函數(shù)中的σ和公式(9)中μ這兩個(gè)參數(shù),將在表2的結(jié)果中具體給出;(3)本文在三個(gè)數(shù)據(jù)集中統(tǒng)一對(duì)Dirichlet參數(shù)μ取: 100,150,200,……,1 000做了實(shí)驗(yàn)。圖1為Adi數(shù)據(jù)集上的數(shù)據(jù)結(jié)果,給出選取不同μ,σ對(duì)檢索結(jié)果的影響,縱坐標(biāo)為3-AVG的值;(4)在Pro_SPLM中一個(gè)重要的參數(shù)是arg,在第四部分中公式(13)提到,這個(gè)參數(shù)是用來控制不同查詢?cè)~項(xiàng)鄰近度得分規(guī)模大小的。當(dāng)前,本文按如下的范圍對(duì)arg進(jìn)行設(shè)置: arg:1.1,1.2,……,2.0。本文選取最終的arg為1.7,在三個(gè)數(shù)據(jù)集上的效果都較好。SPLM中其他參數(shù)參照文獻(xiàn)[3]中的設(shè)置。</p><p><img src="https://cimg.fx361.com/images/2023/0130/5f76d20bdd8e46aba805b5436a5a008935c86662.webp"/></p><p>表2 三個(gè)檢索模型在三個(gè)數(shù)據(jù)集上的檢索性能</p><p>由于三個(gè)數(shù)據(jù)集上的相關(guān)文檔是無序的,因此采用了下面三個(gè)檢索度量指標(biāo):</p><p>(1) 3-AVG: 當(dāng)召回率R分別達(dá)到三個(gè)等級(jí)(R=0.2,0.5,0.8)時(shí),各自對(duì)應(yīng)的準(zhǔn)確率求均值作為3-AVG。</p><p>(2) 11-AVG: 當(dāng)召回率R分別達(dá)到11個(gè)等級(jí)(R>0,R=0.1,0.2,...,0.9,1)時(shí),所對(duì)應(yīng)的準(zhǔn)確率,再對(duì)這11個(gè)準(zhǔn)確率取平均值作為11-AVG。</p><p>(3) MAP: 平均準(zhǔn)確率是每篇相關(guān)文檔檢索出后的準(zhǔn)確率的平均值。</p><p>5.2 檢索性能對(duì)比</p><p>表2給出了四個(gè)檢索模型在三個(gè)數(shù)據(jù)集上的檢索得分,需要說明的是:①粗體: 在每個(gè)數(shù)據(jù)集上,四個(gè)檢索模型中獲得最高檢索得分的數(shù)值使用粗體標(biāo)出;②百分比: 分別表示SPLM_1在SPLM基礎(chǔ)上增加的百分比和Pro_SPLM在SPLM_1基礎(chǔ)上增加的百分比;③SPLM_1和Pro_SPLM下面的參數(shù): 表示兩個(gè)模型獲得最優(yōu)性能時(shí)所取的參數(shù)值。</p><p>這里要重點(diǎn)說明一下表2中Pro_SPLM用的鄰近度策略是PSumProx,本文在表4中進(jìn)行了三種不同策略的比較。同樣我們?cè)诒?中給出了四種檢索模型在MAP評(píng)價(jià)標(biāo)準(zhǔn)下的對(duì)比,對(duì)比結(jié)果和在插值平均(3-AVG/11-AVG)的評(píng)價(jià)標(biāo)準(zhǔn)下的對(duì)比效果一致。</p><p>表4中展現(xiàn)的就是不同鄰近度得分計(jì)算策略分別在三個(gè)不同的數(shù)據(jù)集上的檢索性能的比較,可以看到PSumProx和PMinDist都要比PAveDist的性能好。同樣的還可以看到PSumProx比PMinDist性能上要優(yōu)越一點(diǎn)。</p><p><img src="https://cimg.fx361.com/images/2023/0130/bc2f6c29b9bc49907094f0068b856e592714adf8.webp"/></p><p>表3 MAP評(píng)價(jià)標(biāo)準(zhǔn)下的檢索性能對(duì)比</p><p>通過三個(gè)檢索模型的得分比較可發(fā)現(xiàn): SPLM_1在三個(gè)數(shù)據(jù)集上都要優(yōu)于SPLM;而Pro_SPLM在三個(gè)數(shù)據(jù)集上的檢索得分都要明顯好于SPLM和SPLM_1,特別是在adi上提升較大。直觀上來說,檢索效果對(duì)于那些更能從鄰近度信息中獲益的長(zhǎng)查詢語句來說應(yīng)該更好,但是先前有工作表明當(dāng)使用了鄰近度的信息特征時(shí),查詢語句的長(zhǎng)度和檢索性能是成反比的[19]。而在本文工作當(dāng)中正好說明了這點(diǎn),經(jīng)過統(tǒng)計(jì),adi和med數(shù)據(jù)集中的查詢語句的平均長(zhǎng)度是三個(gè)數(shù)據(jù)集中比較短的,所以兩者檢索性能也是提高較多的。</p><p><img src="https://cimg.fx361.com/images/2023/0130/2d2e6d7c58441df84bce4f5d8709d9140a6cd1d9.webp"/></p><p>表4 使用不同鄰近度策略的Pro_SPLM在三個(gè)數(shù)據(jù)集上的檢索性能</p><p>5.3 σ和μ對(duì)模型檢索性能的影響</p><p>在文獻(xiàn)[3]中,同樣做出了σ對(duì)模型的解釋,但它們是在PLM中和SPLM中做出的比較,本文主要是在SPLM_1和Pro_SPLM中說明。表2中,為了獲得最優(yōu)的性能,數(shù)據(jù)集最小的adi上σ在本文提出的模型中取40,稍大的med和cran都取了100。這說明,σ的取值變化是和數(shù)據(jù)集的大小成正比的,因本文考慮鄰近度時(shí)只考慮了查詢?cè)~在文檔中的距離,實(shí)驗(yàn)的過程中發(fā)現(xiàn),在adi數(shù)據(jù)集中,由于其數(shù)據(jù)量較小,文章的數(shù)量、長(zhǎng)度和總詞匯量也相應(yīng)的少,一條查詢語句中的查詢?cè)~在文檔中出現(xiàn)的次數(shù)會(huì)比較少,并且本文丟棄了查詢語句中沒有在總詞匯表中出現(xiàn)的詞,這樣做的目的,一是為了提高查詢的準(zhǔn)確率,二是為了簡(jiǎn)化計(jì)算查詢?cè)~之間的鄰近度得分。同理在med和cran中,由于這兩個(gè)數(shù)據(jù)集比較大,查詢?cè)~分別在其文檔中出現(xiàn)的次數(shù)也會(huì)變多,相應(yīng)查詢?cè)~的檢索貢獻(xiàn)就會(huì)越大。在圖2中給出了adi數(shù)據(jù)集上的σ的敏感度分析,其他兩個(gè)數(shù)據(jù)集上的曲線規(guī)律是類似的。</p><p>圖2中曲線“SPLM_1_3-AVG”表示該數(shù)據(jù)集上基于SPLM_1的檢索模型對(duì)3-AVG評(píng)價(jià)指標(biāo)的檢索得分,其他曲線代表含義可類推。由圖可知: SPLM_1和Pro_SPLM在σ=40時(shí)獲得最好性能;當(dāng)σ小于35或大于45時(shí),兩個(gè)模型的性能整體上都呈現(xiàn)遞減趨勢(shì);因?yàn)镻ro_SPLM和SPLM_1只是鄰近度上的區(qū)別,前者只是一個(gè)線性的結(jié)合,它們?cè)谧兓厔?shì)基本上是持平的。</p><p>在圖3中表示出了在med數(shù)據(jù)集上不同的μ對(duì)檢索模型的性能影響。med數(shù)據(jù)集上當(dāng)σ=100性能達(dá)到最好,圖3中的μ的范圍都是在σ=100時(shí)計(jì)算的,以此來獲得最優(yōu)的參數(shù)μ。圖3表明當(dāng)μ=550,med數(shù)據(jù)集上的檢索性能達(dá)到最好,再當(dāng)μ增大時(shí),兩個(gè)模型的性能整體上保持平穩(wěn),趨于緩慢的下滑趨勢(shì),斜率變化非常小,說明σ相對(duì)與μ來講,對(duì)模型的檢索性能影響更大一些。經(jīng)實(shí)驗(yàn)表明,改進(jìn)后的檢索模型對(duì)于不同的數(shù)據(jù)集,達(dá)到最優(yōu)性能的μ一般不同,但基本處于[500,600]上,μ對(duì)檢索模型性能的影響的效果和文獻(xiàn)[16]中分析的Dirichlet平滑的效果基本一致。</p><p><img src="https://cimg.fx361.com/images/2023/0130/5340ce37cc901a9886982c4612074dd8d189a16f.webp"/></p><p>圖1 不同μ下,σ對(duì)評(píng)價(jià)標(biāo)準(zhǔn)的影響</p><p><img src="https://cimg.fx361.com/images/2023/0130/73919b94bab52a9e1ad01ebab8c971e66849dfd2.webp"/></p><p>圖2 σ對(duì)檢索性能的影響</p><p><img src="https://cimg.fx361.com/images/2023/0130/bad2d61871558193222898ab9325cb1a4e4f9950.webp"/></p><p>圖 3 μ對(duì)檢索性能的影響</p><p>5.4 模型復(fù)雜度分析</p><p>算法1給出了本文提出的檢索模型的實(shí)現(xiàn)過程,算法2給出了式(3)的實(shí)現(xiàn)過程。給定數(shù)據(jù)集,本文提出的檢索模型在訓(xùn)練過程中的時(shí)間復(fù)雜度分為:</p><p>1. O(Nd): 語義位置語言模型部分的復(fù)雜度主要來自文檔的長(zhǎng)度N和文檔集的大小d。</p><p>2. O(NQ*Dis): 鄰近度模型中復(fù)雜度主要考慮查詢語句中所有查詢?cè)~在文檔中的位置關(guān)系,即算法1中步驟2和步驟3。Q為查詢語句的長(zhǎng)度,Dis為詞項(xiàng)之間最小距離。</p><p>3. O(Nd)+O(NQ*Dis): 與鄰近度模型線性結(jié)合,故本文提出的模型的總復(fù)雜度為上述兩部分之和。</p><p>給定相同的數(shù)據(jù)集,算法2在訓(xùn)練過程中的復(fù)雜度分為:</p><p>1. O(Nd): 語言模型部分的復(fù)雜度主要來自文檔的長(zhǎng)度N和文檔集的大小d。</p><p>2. O(NV*Dis): 公式(3)中給出的鄰近度模型主要考慮查詢?cè)~和文檔集中所有詞項(xiàng)的位置關(guān)系,即算法2中步驟2其中V為詞匯表的長(zhǎng)度。</p><p>3. O(Nd)*O(NV*Dis): 與鄰近度模型是整體結(jié)合,在實(shí)現(xiàn)過程中在要考慮語言模型的結(jié)構(gòu)。</p><p>則通過對(duì)比發(fā)現(xiàn),由于V>>Q,且多項(xiàng)式復(fù)雜度遠(yuǎn)小于算法2的復(fù)雜度。則本文提出的模型在時(shí)間復(fù)雜度上具有一定優(yōu)勢(shì)。</p><p>算法1 結(jié)合鄰近度的語義位置語言檢索模型</p><p>輸入:</p><p>D=(x1,...,xN): 文檔向量</p><p>Q=(q1,...,qN): 查詢?cè)~項(xiàng)向量</p><p>Dis (qi,qj;D): 查詢?cè)~項(xiàng)在文檔中的距離</p><p>f>0: 查詢?cè)~項(xiàng)距離轉(zhuǎn)換成鄰近度得分</p><p>1. 首先對(duì)數(shù)據(jù)集中文檔進(jìn)行文檔向量化,并記錄每個(gè)單詞的位置信息。</p><p>2. 其次對(duì)數(shù)據(jù)集中對(duì)應(yīng)的查詢語句向量化,并記錄每一個(gè)查詢?cè)~在文檔中的位置。</p><p>3. 按照鄰近度策略計(jì)算每個(gè)查詢?cè)~的鄰近度得分,只考慮文檔中查詢?cè)~之間的位置關(guān)系。</p><p>輸出:</p><p>模型中利用Dirichlet平滑的語義位置語言檢索模型與鄰近度模型線性相加來計(jì)算Pμ(w|D,i),進(jìn)而計(jì)算文檔檢索得分。</p><p>算法2 整合鄰近度的語言模型</p><p>輸入:</p><p>D=(x1,...,xN): 文檔向量</p><p>Q=(q1,...,qN): 查詢?cè)~項(xiàng)向量</p><p>Dis (qi,qj;D): 查詢?cè)~項(xiàng)在文檔中的距離</p><p>f>0: 查詢?cè)~項(xiàng)距離轉(zhuǎn)換成鄰近度得分</p><p>1: 對(duì)文檔進(jìn)行文檔向量化,記錄每個(gè)單詞的位置信息,以及整個(gè)數(shù)據(jù)集中詞匯表信息。</p><p>2: 計(jì)算查詢?cè)~與詞匯表中所有單詞的鄰近度得分。見公式(3)。</p><p>輸出:</p><p>模型中利用Dirichlet平滑的語言模型與鄰近度模型整合為一體來計(jì)算 P(w|D,i),進(jìn)而計(jì)算文檔檢索得分。</p><h2>6 結(jié)論及未來工作</h2><p>本文認(rèn)為考慮查詢?cè)~項(xiàng)鄰近度的信息能夠更合理地反映詞項(xiàng)在文檔中的分布,有助于提升檢索模型的效果,因此將查詢?cè)~在文檔中的鄰近度信息整合到結(jié)合語義的位置語言模型當(dāng)中去,提出結(jié)合鄰近度的語義位置語言檢索模型。進(jìn)一步地,對(duì)于查詢?cè)~在文檔中的位置關(guān)系給出詳細(xì)的解釋和關(guān)注。最后,在標(biāo)準(zhǔn)數(shù)據(jù)集上的測(cè)試了結(jié)合鄰近度的語義位置語言檢索模型的性能。總體上有如下幾點(diǎn)工作: (1)采用Dirichlet先驗(yàn)平滑方法對(duì)檢索模型提出改進(jìn),并結(jié)合鄰近度的信息;(2)對(duì)詞項(xiàng)之間的距離做了具體的定義,并引入非線性的函數(shù),將距離轉(zhuǎn)化成鄰近度得分;(3)引入三種不同的計(jì)算鄰近度得分策略,并在實(shí)驗(yàn)中帶入不同檢索模型進(jìn)行性能比較;(4)實(shí)驗(yàn)表明基于Dirichlet平滑的SPLM檢索模型在性能上要優(yōu)于基于Jelinek-Mercer平滑的SPLM模型,而結(jié)合鄰近度的Pro_SPLM檢索也要明顯好于上述所有檢索模型;本文還分析了兩個(gè)模型對(duì)受參數(shù)μ和σ的影響程度,得出了最優(yōu)的μ取值范圍。未來將在以下方面進(jìn)一步研究: (1)本文提出的模型只是在小數(shù)據(jù)集上進(jìn)行實(shí)驗(yàn),在下一步的工作中將會(huì)在大數(shù)據(jù)集上進(jìn)行檢測(cè)。(2)本文中提出的結(jié)合鄰近度的信息是線性的結(jié)合方式,即多項(xiàng)式模型,結(jié)合方式在不提高計(jì)算復(fù)雜度的前提下還有待進(jìn)一步改善。</p><p>[1] Ponte J M, Croft W B. A language modeling approach to information retrieval [C]//Proceedings of the 21st annual international ACM SIGIR conference on research and development in information retrieval,Melbourne,Austrailia: ACM,1998: 275-281.</p><p>[2] Yuanhua Lv,Chengxiang Zhai. Positional language models for information retrieval [C]//Proceedings of the 32nd international ACM SIGIR conference on research and development in information retrieval,Boston: ACM, 2009: 299-306.</p><p>[3] 余偉,王明文,萬劍怡,等. 結(jié)合語義的位置語言模型[J].北京大學(xué)學(xué)報(bào)(自然科學(xué)版),2013,49(2): 203-212.</p><p>[4] Beeferman D,Berger A, Lafferty J. A model of lexical attraction and repulsion [C]//Proceedings of the 8th Conference on European Chapter of the Association for Computational Linguistics,1997: 373-380.</p><p>[5] Bai J,Chang Y,Cui H,et al. Investigation of partial query proximity in web search [C]//Proceedings of the 21st Annual Conference on World Wide Web,Beijing,China: 2008: 1183-1184.</p><p>[6] Tao T, Zhai C. An exploration of proximity measures in information retrieval [C]//Proceedings of the 30th annual international ACM SIGIR conference on research and development in information retrieval,Amsterdam,Netherlands: ACM,2007: 295-302.</p><p>[7] Y Rasolofo, J Savoy. Term Proximity Scoring for Keyword-Based Retrieval Systems [C]//Lecture Notes in Computer Science,2003: 207-218.</p><p>[8] E Michael Keen. The use of term position devices in ranked output experiments [J]. The Journal of Documentation,1991,(47): 1-22.</p><p>[9] E Michael Keen. Some aspects of proximity searching in text retrieval systems [J]. Journal of Information Science,1992,(18): 89-98.</p><p>[10] Stefan Buttcher, Charles L A Clarke, Brad Lushman. Term proximity scoring for ad-hoc retrieval on very large text collections [C]//Proceedings of the 29th annual international ACM SIGIR conference,New York,USA: ACM,2006: 621-622.</p><p>[11] 韓中元,李生,齊浩亮,等. 面向信息檢索的近鄰語言模型[J]. 中文信息學(xué)報(bào),2011,25(1): 67-70.</p><p>[12] 丁凡,王斌,白碩,等. 文檔檢索中句法信息的有效利用研究[J]. 中文信息學(xué)報(bào),2008,22(4): 66-74.</p><p>[13] 金凌,吳文虎,鄭方,等. 距離加權(quán)統(tǒng)計(jì)語言模型及其應(yīng)用[J]. 中文信息學(xué)報(bào),2001,15(6): 47-52.</p><p>[14] 喬亞男,劉躍虎,齊勇. 查詢?cè)~相似度加權(quán)的鄰近性檢索方法[J].模式識(shí)別與人工智能,2013,26(2): 191-194.</p><p>[15] Jinlei Zhao, Yeogirl Yun. A Proximity Language Model for information Retrieval[C]//Proceedings of the 32nd international ACM SIGIR conference, Boston, USA: ACM,2009: 291-298.</p><p>[16] Zhai C, Lafferty J. A study of smoothing methods for language models applied to ad hoc information retrieval [C]//Proceedings of the 24th annual international ACM SIGIR conference,New Orleans,Louisiana,USA: ACM,2001: 334-342.</p><p>[17] Zhai C, Lafferty J. Two-stage language models for information retrieval [C]//Proceedings of the 25th annual international ACM SIGIR conference on research and development in information retrieval,Tampere,F(xiàn)inland: ACM,2002: 49-56.</p><p>[18] Yuanhua Lv,Chengxiang Zhai. Positional Relevance Model for Pseudo-Relevance Feedback [C]//Proceedings of the 33rd international ACM SIGIR conference on research and development in information retrieval,Geneva,Switzerland: ACM,2010: 579-586.</p><p>[19] Krysta M Svore,Pallika H Kanani,Nazan Khan. How Good is a Span of Terms Exploiting Proximity to Improve Web Retrieval [C]//Proceedings of the 33rd international ACM SIGIR conference on research and development in information retrieval,Geneva,Switzerland: ACM,2010: 154-161.</p><p>Semantic Positional Language Retrieval Models with A Proximity Information</p><p>GONG Xiaolong, WANG Mingwen, WAN Jianyi, WANG Xiaoqing</p><p>(School of Computer Information Engineering, Jiangxi Normal University, Nanchang, Jiangxi 330022, China)</p><p>In most existing retrieval models, the calculations on the relevance between the document and the query are based on the statistical features, such as within-document frequencies, inverse document frequencies, document lengths and so on. Recent studies show that the term position information can promote the precision of the query results, but how to best employ this information remains an open issue. This paper proposes to integrate the terms proximity information into the semantic positional language model(SPLM), with a Dirichlet prior distribution as smoothing measure to compute proximity. The proposed semantic positional language retrieval models with a proximity information performs better than classical semantic positional language model in the experiments.</p><p>semantic positional language models; Dirichlet smooth; proximity information; retrieval model</p><p><img src="https://cimg.fx361.com/images/2023/0130/2c2ebd4c5ee4fd6ebd2e7c20c72ba95c3cf422db.webp"/></p><p>龔小龍(1991-),碩士,主要研究領(lǐng)域?yàn)樾畔z索與機(jī)器學(xué)習(xí),數(shù)據(jù)挖掘。E-mail:gxl121438@sjtu.edu.cn王明文(1964-),博士,教授,主要研究領(lǐng)域?yàn)樾畔z索,數(shù)據(jù)挖掘,自然語言處理。E-mail:mwwang@jxnu.edu.cn萬劍怡(1974-),博士,教授,主要研究領(lǐng)域?yàn)橹悄苄畔⑻幚怼-mail:wanjianyi@aliyun.com</p><p>1003-0077(2015)04-0183-09</p><p>2013-07-23 定稿日期: 2013-11-25</p><p>國(guó)家自然科學(xué)基金(60963014,61163006,61203313);江西省科技廳自然科學(xué)基金(20132BAB201038)</p><p>TP391</p><p>A</p></p>
<!-- <div id="g0gggggg" class="article_pdf"><a >查看pdf文檔請(qǐng)下載app</a></div>--><div id="g0gggggg" class="article_love">
<div id="g0gggggg" class="title">猜你喜歡</div>
<div id="g0gggggg" class="article_love_keyword"><span><a href="/tags/5/a/3ec7629d528fb6a2/1.html" target="_blank">語義</a></span><span><a href="/tags/2/5/f5205801d57d6727/1.html" target="_blank">語言</a></span><span><a href="/tags/8/0/a5d4f41f098c85c8/1.html" target="_blank">模型</a></span></div>
<div id="g0gggggg" class="article_love_news"><dd><a class="txt_title" href="/page/2024/0619/24295180.shtml" target="_blank" title="一半模型">一半模型</a><div id="g0gggggg" class="rsorc"><a href="/bk/thwgqmljtl/20245.html" class="ly" title="童話王國(guó)·奇妙邏輯推理(2024年5期)">童話王國(guó)·奇妙邏輯推理(2024年5期)</a><span id="g0gggggg" class="txt">2024-06-19 16:03:38</span></div></dd><dd><a class="txt_title" href="/page/2020/1126/13925649.shtml" target="_blank" title="重要模型『一線三等角』">重要模型『一線三等角』</a><div id="g0gggggg" class="rsorc"><a href="/bk/zxsslhqnjsxrjb/202010.html" class="ly" title="中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)">中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)</a><span id="g0gggggg" class="txt">2020-11-26 08:24:50</span></div></dd><dd><a class="txt_title" href="/page/2020/0602/17732655.shtml" target="_blank" title="重尾非線性自回歸模型自加權(quán)M-估計(jì)的漸近分布">重尾非線性自回歸模型自加權(quán)M-估計(jì)的漸近分布</a><div id="g0gggggg" class="rsorc"><a href="/bk/sxwlxb/20202.html" class="ly" title="數(shù)學(xué)物理學(xué)報(bào)(2020年2期)">數(shù)學(xué)物理學(xué)報(bào)(2020年2期)</a><span id="g0gggggg" class="txt">2020-06-02 11:29:24</span></div></dd><dd><a class="txt_title" href="/page/2020/0530/11380942.shtml" target="_blank" title="語言是刀">語言是刀</a><div id="g0gggggg" class="rsorc"><a href="/bk/wenyuan/20204.html" class="ly" title="文苑(2020年4期)">文苑(2020年4期)</a><span id="g0gggggg" class="txt">2020-05-30 12:35:30</span></div></dd><dd><a class="txt_title" href="/page/2020/0331/14523854.shtml" target="_blank" title="語言與語義">語言與語義</a><div id="g0gggggg" class="rsorc"><a href="/bk/kfjyyj/20202.html" class="ly" title="開放教育研究(2020年2期)">開放教育研究(2020年2期)</a><span id="g0gggggg" class="txt">2020-03-31 01:54:14</span></div></dd><dd><a class="txt_title" href="/page/2018/0418/11986870.shtml" target="_blank" title="讓語言描寫搖曳多姿">讓語言描寫搖曳多姿</a><div id="g0gggggg" class="rsorc"><a href="/bk/xxszwzgnjsy/20183.html" class="ly" title="小學(xué)生作文(中高年級(jí)適用)(2018年3期)">小學(xué)生作文(中高年級(jí)適用)(2018年3期)</a><span id="g0gggggg" class="txt">2018-04-18 01:24:47</span></div></dd><dd><a class="txt_title" href="/page/2016/1201/18470107.shtml" target="_blank" title="累積動(dòng)態(tài)分析下的同聲傳譯語言壓縮">累積動(dòng)態(tài)分析下的同聲傳譯語言壓縮</a><div id="g0gggggg" class="rsorc"><a href="/bk/hbdldxxbshkxb/20164.html" class="ly" title="華北電力大學(xué)學(xué)報(bào)(社會(huì)科學(xué)版)(2016年4期)">華北電力大學(xué)學(xué)報(bào)(社會(huì)科學(xué)版)(2016年4期)</a><span id="g0gggggg" class="txt">2016-12-01 03:59:30</span></div></dd><dd><a class="txt_title" href="/page/2016/1107/18790514.shtml" target="_blank" title="3D打印中的模型分割與打包">3D打印中的模型分割與打包</a><div id="g0gggggg" class="rsorc"><a href="/bk/gxjmgc/20166.html" class="ly" title="光學(xué)精密工程(2016年6期)">光學(xué)精密工程(2016年6期)</a><span id="g0gggggg" class="txt">2016-11-07 09:07:19</span></div></dd><dd><a class="txt_title" href="/page/2016/0525/18224768.shtml" target="_blank" title="“上”與“下”語義的不對(duì)稱性及其認(rèn)知闡釋">“上”與“下”語義的不對(duì)稱性及其認(rèn)知闡釋</a><div id="g0gggggg" class="rsorc"><a href="/bk/xdywyyyj/201621.html" class="ly" title="現(xiàn)代語文(2016年21期)">現(xiàn)代語文(2016年21期)</a><span id="g0gggggg" class="txt">2016-05-25 13:13:44</span></div></dd><dd><a class="txt_title" href="/page/2015/0707/957910.shtml" target="_blank" title="我有我語言">我有我語言</a><div id="g0gggggg" class="rsorc"><a href="/bk/sekxzksnb/20154.html" class="ly" title="少兒科學(xué)周刊·少年版(2015年4期)">少兒科學(xué)周刊·少年版(2015年4期)</a><span id="g0gggggg" class="txt">2015-07-07 21:11:17</span></div></dd></div>
</div><div id="g0gggggg" class="other_pel mt80">
<p class="fl"><a href="/bk/zwxxxb/20154.html" target="_blank"><img src="https://cimg.fx361.com/images/2023/0130/13e3e3d796680a5ba73e6ef1a3cb5708a2e3fe2d.webp" alt=""></a><span id="g0gggggg" class="p1"><a href="/bk/zwxxxb/" target="_blank">中文信息學(xué)報(bào)</a></span><span id="g0gggggg" class="p2"><a href="/bk/zwxxxb/20154.html" target="_blank">2015年4期</a></span></p>
<dl class="fl"><dt>中文信息學(xué)報(bào)的其它文章</dt><dd><a href="/page/2015/0421/16159454.shtml" title="基于多樣化特征的中文微博情感分類方法研究">基于多樣化特征的中文微博情感分類方法研究</a></dd><dd><a href="/page/2015/0421/16160913.shtml" title="基于復(fù)述技術(shù)的漢語成語翻譯方法研究">基于復(fù)述技術(shù)的漢語成語翻譯方法研究</a></dd><dd><a href="/page/2015/0421/16160385.shtml" title="編碼與同義詞替換結(jié)合的可逆文本水印算法">編碼與同義詞替換結(jié)合的可逆文本水印算法</a></dd><dd><a href="/page/2015/0421/16157050.shtml" title="特征和實(shí)例遷移相融合的跨領(lǐng)域傾向性分析">特征和實(shí)例遷移相融合的跨領(lǐng)域傾向性分析</a></dd><dd><a href="/page/2015/0421/16156967.shtml" title="面向中文文本的情感信息抽取語料庫(kù)構(gòu)建">面向中文文本的情感信息抽取語料庫(kù)構(gòu)建</a></dd><dd><a href="/page/2015/0421/16156261.shtml" title="事件關(guān)系檢測(cè)的任務(wù)體系概述">事件關(guān)系檢測(cè)的任務(wù)體系概述</a></dd></dl>
</div></div>
</div>
</div>
<div id="g0gggggg" class="sidebarR">
<!-- tab選項(xiàng)卡 -->
<div id="g0gggggg" class="tab01 mb20"><div id="g0gggggg" class="tabArrow"></div><div id="g0gggggg" class="tabItem"><div id="g0gggggg" class="tabTit"><a href="#">雜志排行</a></div>
<div id="g0gggggg" class="tabCont"><ol><li><p class="row01"><span id="g0gggggg" class="topNum">1</span><a href="/bk/sdjy/202410.html" class="row01a">《師道·教研》</a><span id="g0gggggg" class="row01_fr"><a href="/bk/sdjy/202410.html">2024年10期</a></span></p></li><li><p class="row01"><span id="g0gggggg" class="topNum">2</span><a href="/bk/swyzhsby/202411.html" class="row01a">《思維與智慧·上半月》</a><span id="g0gggggg" class="row01_fr"><a href="/bk/swyzhsby/202411.html">2024年11期</a></span></p></li><li><p class="row01"><span id="g0gggggg" class="topNum">3</span><a href="/bk/xdgyjjhxxh/20242.html" class="row01a">《現(xiàn)代工業(yè)經(jīng)濟(jì)和信息化》</a><span id="g0gggggg" class="row01_fr"><a href="/bk/xdgyjjhxxh/20242.html">2024年2期</a></span></p></li><li><p class="row01"><span id="g0gggggg" class="topNum">4</span><a href="/bk/wxxsyb/202410.html" class="row01a">《微型小說月報(bào)》</a><span id="g0gggggg" class="row01_fr"><a href="/bk/wxxsyb/202410.html">2024年10期</a></span></p></li><li><p class="row01"><span id="g0gggggg" class="topNum">5</span><a href="/bk/gywsw/20241.html" class="row01a">《工業(yè)微生物》</a><span id="g0gggggg" class="row01_fr"><a href="/bk/gywsw/20241.html">2024年1期</a></span></p></li><li><p class="row01"><span id="g0gggggg" class="topNum">6</span><a href="/bk/xl/20249.html" class="row01a">《雪蓮》</a><span id="g0gggggg" class="row01_fr"><a href="/bk/xl/20249.html">2024年9期</a></span></p></li><li><p class="row01"><span id="g0gggggg" class="topNum">7</span><a href="/bk/sjbl/202421.html" class="row01a">《世界博覽》</a><span id="g0gggggg" class="row01_fr"><a href="/bk/sjbl/202421.html">2024年21期</a></span></p></li><li><p class="row01"><span id="g0gggggg" class="topNum">8</span><a href="/bk/zxqyglykj/20246.html" class="row01a">《中小企業(yè)管理與科技》</a><span id="g0gggggg" class="row01_fr"><a href="/bk/zxqyglykj/20246.html">2024年6期</a></span></p></li><li><p class="row01"><span id="g0gggggg" class="topNum">9</span><a href="/bk/xdsp/20244.html" class="row01a">《現(xiàn)代食品》</a><span id="g0gggggg" class="row01_fr"><a href="/bk/xdsp/20244.html">2024年4期</a></span></p></li><li><p class="row01"><span id="g0gggggg" class="topNum">10</span><a href="/bk/wszyjy/202410.html" class="row01a">《衛(wèi)生職業(yè)教育》</a><span id="g0gggggg" class="row01_fr"><a href="/bk/wszyjy/202410.html">2024年10期</a></span></p></li></ol> </div></div>
</div>
</div>
<div id="g0gggggg" class="clr"></div>
</div>
</div>
<!--div class="advertisement">
</div-->
<div id="g0gggggg" class="footer">
<p><a href="/aboutus/index.html">關(guān)于參考網(wǎng)</a></p>
</div>
<!--
<script>
if ('serviceWorker' in navigator) {
window.onload = function () {
navigator.serviceWorker.register('/sw.js');
};
}
</script>
-->
<script type="text/javascript" src="https://s1.pstatp.com/cdn/expire-1-M/jquery/3.4.0/jquery.min.js"></script>
<script type="text/javascript" src="https://s1.pstatp.com/cdn/expire-1-M/sticky-kit/1.1.3/sticky-kit.min.js"></script>
<script type="text/javascript">
document.write('<script src="https://cimg.fx361.com/cdn/w/index.js"><\/script>');
</script>
<footer>
<div class="friendship-link">
<p>感谢您访问我们的网站,您可能还对以下资源感兴趣:自贡牌麓投资有限公司</p>
<a href="http://m.handmsg.com"title=999精品在线视频,手机成人午夜在线视频,久久不卡国产精品无码,中日无码在线观看,成人av手机在线观看,日韩精品亚洲一区中文字幕,亚洲av无码人妻,四虎国产在线观看">999精品在线视频,手机成人午夜在线视频,久久不卡国产精品无码,中日无码在线观看,成人av手机在线观看,日韩精品亚洲一区中文字幕,亚洲av无码人妻,四虎国产在线观看</a>
<a href="/sitemap.xml">网站地图</a>
<div style="position:fixed;left:-9000px;top:-9000px;"></div>
<div class="friend-links">
</div>
</div>
</footer>
主站蜘蛛池模板:
<a href="http://www.canafactoring.com" target="_blank">亚洲另类国产欧美一区二区</a>|
<a href="http://www.eticaretdanismanligi.net" target="_blank">中文字幕av一区二区三区欲色</a>|
<a href="http://www.xmfangfumu.com" target="_blank">综合天天色</a>|
<a href="http://www.vzxihzo.cn" target="_blank">久久性妇女精品免费</a>|
<a href="http://www.17kuaibao.com" target="_blank">精品少妇人妻无码久久</a>|
<a href="http://www.renrennuan.com" target="_blank">AV天堂资源福利在线观看</a>|
<a href="http://www.apyice.com" target="_blank">欧美国产菊爆免费观看</a>|
<a href="http://www.feichangbao.com" target="_blank">国产91高清视频</a>|
<a href="http://www.wanjuche.net" target="_blank">久久人妻xunleige无码</a>|
<a href="http://www.cctviptv.com" target="_blank">72种姿势欧美久久久大黄蕉</a>|
<a href="http://www.0626077.com" target="_blank">亚洲最大看欧美片网站地址</a>|
<a href="http://www.sihushansj.com" target="_blank">波多野结衣无码AV在线</a>|
<a href="http://www.hgxcw.cn" target="_blank">孕妇高潮太爽了在线观看免费</a>|
<a href="http://www.qbuv.cn" target="_blank">99久久精品免费视频</a>|
<a href="http://www.zzwaa.com" target="_blank">国产精品乱偷免费视频</a>|
<a href="http://www.colorbeam.net" target="_blank">无码精油按摩潮喷在线播放</a>|
<a href="http://www.80ixp.cn" target="_blank">99人妻碰碰碰久久久久禁片</a>|
<a href="http://www.jasfril.cn" target="_blank">亚洲欧美日韩视频一区</a>|
<a href="http://www.gauiufg.cn" target="_blank">精品视频第一页</a>|
<a href="http://www.yuyingfang.net" target="_blank">日本亚洲成高清一区二区三区</a>|
<a href="http://www.bikerscap.net" target="_blank">成人在线亚洲</a>|
<a href="http://www.lingtouhui.com" target="_blank">国产一区二区免费播放</a>|
<a href="http://www.xzjkdq.com" target="_blank">狠狠五月天中文字幕</a>|
<a href="http://www.m-mei.com" target="_blank">综合色在线</a>|
<a href="http://www.daxiangsteel.cn" target="_blank">成人精品区</a>|
<a href="http://www.xtr8.com" target="_blank">欧美日韩一区二区三区在线视频</a>|
<a href="http://www.hsdonghong.com" target="_blank">国产va免费精品</a>|
<a href="http://www.lnganshu.com" target="_blank">国产老女人精品免费视频</a>|
<a href="http://www.tsjhtz.com" target="_blank">国产精品久久久久婷婷五月</a>|
<a href="http://www.51cqh.com" target="_blank">一级毛片在线免费看</a>|
<a href="http://www.popo2048.net" target="_blank">久久精品这里只有精99品</a>|
<a href="http://www.yueyuexiao.cn" target="_blank">国产在线观看成人91</a>|
<a href="http://www.200050.com" target="_blank">亚洲精品人成网线在线</a>|
<a href="http://www.eticaretdanismanligi.net" target="_blank">亚洲A∨无码精品午夜在线观看</a>|
<a href="http://www.tjzzsd.com" target="_blank">国产网友愉拍精品</a>|
<a href="http://www.mrjl.net" target="_blank">伊人欧美在线</a>|
<a href="http://www.4x4world.net" target="_blank">丁香婷婷久久</a>|
<a href="http://www.30gl.com" target="_blank">日韩人妻无码制服丝袜视频</a>|
<a href="http://www.maftkay.cn" target="_blank">国产福利大秀91</a>|
<a href="http://www.cnmjyx.com" target="_blank">少妇被粗大的猛烈进出免费视频</a>|
<a href="http://www.xg-aohua.com" target="_blank">无码丝袜人妻</a>|
<a href="http://www.southphillydiecast.com" target="_blank">亚洲国产成人麻豆精品</a>|
<a href="http://www.jkmyu.com" target="_blank">亚洲香蕉在线</a>|
<a href="http://www.qutuike.com" target="_blank">中国毛片网</a>|
<a href="http://www.rocafs.com" target="_blank">国产欧美高清</a>|
<a href="http://www.xwssm7.com" target="_blank">免费人成在线观看成人片</a>|
<a href="http://www.djzc365.com" target="_blank">成人国产小视频</a>|
<a href="http://www.lyyngdst.com" target="_blank">久久96热在精品国产高清</a>|
<a href="http://www.xueshuj.com" target="_blank">欧美成人一级</a>|
<a href="http://www.kjxkm.com" target="_blank">亚洲中文字幕在线一区播放</a>|
<a href="http://www.3g5188.com" target="_blank">夜夜爽免费视频</a>|
<a href="http://www.guoqibaike.com" target="_blank">麻豆AV网站免费进入</a>|
<a href="http://www.yfcapacitor.com" target="_blank">a级毛片免费看</a>|
<a href="http://www.sxhaiyuyuan.com" target="_blank">亚洲黄网在线</a>|
<a href="http://www.989753.com" target="_blank">亚洲va欧美va国产综合下载</a>|
<a href="http://www.hl-thread.com" target="_blank">青青青国产视频手机</a>|
<a href="http://www.whszxx.com" target="_blank">亚洲AV无码乱码在线观看裸奔</a>|
<a href="http://www.hzpipe.com" target="_blank">国产超薄肉色丝袜网站</a>|
<a href="http://www.whejz.com" target="_blank">日韩在线播放中文字幕</a>|
<a href="http://www.1xin11.com" target="_blank">国产精品三级av及在线观看</a>|
<a href="http://www.nongaicheng.com" target="_blank">99视频在线观看免费</a>|
<a href="http://www.lezaojiao.com" target="_blank">97在线免费</a>|
<a href="http://www.xhual.com" target="_blank">a毛片在线播放</a>|
<a href="http://www.haotou168.com" target="_blank">日韩高清中文字幕</a>|
<a href="http://www.eztron.net" target="_blank">亚洲国产精品不卡在线</a>|
<a href="http://www.fjyiyi.com" target="_blank">色成人亚洲</a>|
<a href="http://www.skstar.cn" target="_blank">婷婷综合色</a>|
<a href="http://www.safecronite-china.com" target="_blank">青草91视频免费观看</a>|
<a href="http://www.dffetvn.cn" target="_blank">国产青榴视频</a>|
<a href="http://www.saccidanandayoga.com" target="_blank">亚洲一区二区日韩欧美gif</a>|
<a href="http://www.szmylike.net" target="_blank">国产人在线成免费视频</a>|
<a href="http://www.dianjincanyin.com" target="_blank">亚洲综合经典在线一区二区</a>|
<a href="http://www.shygbaidu.com" target="_blank">亚洲精品欧美日本中文字幕</a>|
<a href="http://www.24kyx.com" target="_blank">国产精品极品美女自在线看免费一区二区</a>|
<a href="http://www.longrunguoji.com" target="_blank">在线日韩一区二区</a>|
<a href="http://www.tootui.com" target="_blank">国产玖玖视频</a>|
<a href="http://www.hgxcw.cn" target="_blank">国产一区二区精品福利</a>|
<a href="http://www.cclib.net" target="_blank">99伊人精品</a>|
<a href="http://www.bdccz.com" target="_blank">亚洲日本在线免费观看</a>|
<a href="http://www.cqhxzl.com" target="_blank">亚洲精品国产成人7777</a>|
<a href="http://www.niaogege.com" target="_blank">日韩精品无码免费一区二区三区
</a>|
<a href="http://www.tc2086.com" target="_blank">精品黑人一区二区三区</a>|
<script>
(function(){
var bp = document.createElement('script');
var curProtocol = window.location.protocol.split(':')[0];
if (curProtocol === 'https') {
bp.src = 'https://zz.bdstatic.com/linksubmit/push.js';
}
else {
bp.src = 'http://push.zhanzhang.baidu.com/push.js';
}
var s = document.getElementsByTagName("script")[0];
s.parentNode.insertBefore(bp, s);
})();
</script>
</body><div id="p97p7" class="pl_css_ganrao" style="display: none;"><thead id="p97p7"><strong id="p97p7"></strong></thead><pre id="p97p7"><th id="p97p7"></th></pre><strong id="p97p7"></strong><big id="p97p7"><label id="p97p7"><thead id="p97p7"><ins id="p97p7"></ins></thead></label></big><label id="p97p7"></label><meter id="p97p7"></meter><optgroup id="p97p7"><address id="p97p7"><menuitem id="p97p7"><style id="p97p7"></style></menuitem></address></optgroup><label id="p97p7"></label><th id="p97p7"></th><p id="p97p7"></p><strike id="p97p7"></strike><ins id="p97p7"><small id="p97p7"><acronym id="p97p7"><track id="p97p7"></track></acronym></small></ins><small id="p97p7"></small><p id="p97p7"><dfn id="p97p7"></dfn></p><sup id="p97p7"><ruby id="p97p7"><small id="p97p7"><acronym id="p97p7"></acronym></small></ruby></sup><b id="p97p7"><dl id="p97p7"><legend id="p97p7"><u id="p97p7"></u></legend></dl></b><form id="p97p7"><form id="p97p7"><meter id="p97p7"><pre id="p97p7"></pre></meter></form></form><acronym id="p97p7"></acronym><tt id="p97p7"><rp id="p97p7"></rp></tt><menuitem id="p97p7"><tt id="p97p7"><ol id="p97p7"><rp id="p97p7"></rp></ol></tt></menuitem><legend id="p97p7"><track id="p97p7"><div id="p97p7"><form id="p97p7"></form></div></track></legend><dfn id="p97p7"></dfn><b id="p97p7"></b><mark id="p97p7"><em id="p97p7"><sup id="p97p7"><ruby id="p97p7"></ruby></sup></em></mark><b id="p97p7"><dl id="p97p7"></dl></b><legend id="p97p7"><u id="p97p7"><nobr id="p97p7"><progress id="p97p7"></progress></nobr></u></legend><dfn id="p97p7"><menuitem id="p97p7"></menuitem></dfn><menuitem id="p97p7"><tt id="p97p7"><ol id="p97p7"><thead id="p97p7"></thead></ol></tt></menuitem><small id="p97p7"><acronym id="p97p7"><track id="p97p7"><form id="p97p7"></form></track></acronym></small><strong id="p97p7"><sub id="p97p7"></sub></strong><ruby id="p97p7"><strike id="p97p7"><span id="p97p7"><nobr id="p97p7"></nobr></span></strike></ruby><optgroup id="p97p7"></optgroup><b id="p97p7"><dl id="p97p7"></dl></b><dfn id="p97p7"></dfn><th id="p97p7"><optgroup id="p97p7"></optgroup></th><pre id="p97p7"><th id="p97p7"></th></pre><label id="p97p7"></label><form id="p97p7"><form id="p97p7"></form></form><strike id="p97p7"><small id="p97p7"></small></strike><var id="p97p7"></var><i id="p97p7"></i><mark id="p97p7"></mark><address id="p97p7"><dfn id="p97p7"></dfn></address><legend id="p97p7"></legend><tt id="p97p7"></tt><tt id="p97p7"></tt><listing id="p97p7"><label id="p97p7"></label></listing><nobr id="p97p7"><strong id="p97p7"><sub id="p97p7"><mark id="p97p7"></mark></sub></strong></nobr><rp id="p97p7"><form id="p97p7"><form id="p97p7"><listing id="p97p7"></listing></form></form></rp><video id="p97p7"><legend id="p97p7"><optgroup id="p97p7"><dfn id="p97p7"></dfn></optgroup></legend></video><output id="p97p7"></output><thead id="p97p7"></thead><strong id="p97p7"></strong><rp id="p97p7"></rp><mark id="p97p7"><i id="p97p7"></i></mark><dfn id="p97p7"></dfn><video id="p97p7"><legend id="p97p7"><optgroup id="p97p7"><dfn id="p97p7"></dfn></optgroup></legend></video><tt id="p97p7"></tt><strong id="p97p7"></strong><ol id="p97p7"></ol><font id="p97p7"><label id="p97p7"><output id="p97p7"><p id="p97p7"></p></output></label></font><strong id="p97p7"><sub id="p97p7"></sub></strong><ol id="p97p7"></ol><em id="p97p7"></em><rp id="p97p7"><thead id="p97p7"></thead></rp><nobr id="p97p7"><progress id="p97p7"><pre id="p97p7"><label id="p97p7"></label></pre></progress></nobr><span id="p97p7"><nobr id="p97p7"><pre id="p97p7"><font id="p97p7"></font></pre></nobr></span><nobr id="p97p7"><progress id="p97p7"><strong id="p97p7"><var id="p97p7"></var></strong></progress></nobr><sup id="p97p7"><ruby id="p97p7"></ruby></sup><tt id="p97p7"></tt><label id="p97p7"><output id="p97p7"></output></label><track id="p97p7"><div id="p97p7"></div></track><ins id="p97p7"></ins><optgroup id="p97p7"><address id="p97p7"></address></optgroup><legend id="p97p7"></legend><output id="p97p7"><p id="p97p7"><dfn id="p97p7"><pre id="p97p7"></pre></dfn></p></output><label id="p97p7"><output id="p97p7"><p id="p97p7"><pre id="p97p7"></pre></p></output></label><p id="p97p7"><dfn id="p97p7"><pre id="p97p7"><th id="p97p7"></th></pre></dfn></p><form id="p97p7"><form id="p97p7"></form></form><big id="p97p7"><label id="p97p7"></label></big><style id="p97p7"><font id="p97p7"><label id="p97p7"><p id="p97p7"></p></label></font></style><pre id="p97p7"><em id="p97p7"><ruby id="p97p7"><strike id="p97p7"></strike></ruby></em></pre><progress id="p97p7"><strong id="p97p7"></strong></progress><var id="p97p7"></var><small id="p97p7"></small><thead id="p97p7"></thead><label id="p97p7"></label><var id="p97p7"><mark id="p97p7"></mark></var><strong id="p97p7"></strong><form id="p97p7"><form id="p97p7"><listing id="p97p7"><meter id="p97p7"></meter></listing></form></form><nobr id="p97p7"><progress id="p97p7"><strong id="p97p7"><var id="p97p7"></var></strong></progress></nobr><legend id="p97p7"><u id="p97p7"></u></legend><progress id="p97p7"><strong id="p97p7"></strong></progress><strong id="p97p7"><sub id="p97p7"><var id="p97p7"><i id="p97p7"></i></var></sub></strong><var id="p97p7"><mark id="p97p7"><i id="p97p7"><b id="p97p7"></b></i></mark></var><p id="p97p7"><b id="p97p7"><dl id="p97p7"><video id="p97p7"></video></dl></b></p><optgroup id="p97p7"><address id="p97p7"><dfn id="p97p7"><style id="p97p7"></style></dfn></address></optgroup><thead id="p97p7"><form id="p97p7"><form id="p97p7"><listing id="p97p7"></listing></form></form></thead><em id="p97p7"><sup id="p97p7"></sup></em><var id="p97p7"><mark id="p97p7"><i id="p97p7"><b id="p97p7"></b></i></mark></var><listing id="p97p7"><meter id="p97p7"></meter></listing><font id="p97p7"><label id="p97p7"><p id="p97p7"><b id="p97p7"></b></p></label></font><style id="p97p7"><font id="p97p7"></font></style><strong id="p97p7"><sub id="p97p7"></sub></strong><em id="p97p7"></em><optgroup id="p97p7"><dfn id="p97p7"></dfn></optgroup><ruby id="p97p7"><strike id="p97p7"></strike></ruby><thead id="p97p7"><form id="p97p7"></form></thead><track id="p97p7"><strong id="p97p7"></strong></track><strong id="p97p7"></strong><optgroup id="p97p7"><address id="p97p7"></address></optgroup><var id="p97p7"><i id="p97p7"><em id="p97p7"><sup id="p97p7"></sup></em></i></var><big id="p97p7"><label id="p97p7"><thead id="p97p7"><strong id="p97p7"></strong></thead></label></big><font id="p97p7"><label id="p97p7"></label></font><u id="p97p7"><span id="p97p7"><nobr id="p97p7"><progress id="p97p7"></progress></nobr></span></u><u id="p97p7"><span id="p97p7"></span></u><em id="p97p7"><sup id="p97p7"><ruby id="p97p7"><strike id="p97p7"></strike></ruby></sup></em><form id="p97p7"><listing id="p97p7"></listing></form><th id="p97p7"></th><b id="p97p7"></b><track id="p97p7"></track><tt id="p97p7"></tt><progress id="p97p7"><pre id="p97p7"></pre></progress><track id="p97p7"></track><rp id="p97p7"><thead id="p97p7"><form id="p97p7"><form id="p97p7"></form></form></thead></rp><meter id="p97p7"></meter><ol id="p97p7"><rp id="p97p7"><thead id="p97p7"><dfn id="p97p7"></dfn></thead></rp></ol><pre id="p97p7"><th id="p97p7"></th></pre><legend id="p97p7"><optgroup id="p97p7"><address id="p97p7"><dfn id="p97p7"></dfn></address></optgroup></legend><p id="p97p7"><b id="p97p7"><dl id="p97p7"><video id="p97p7"></video></dl></b></p><output id="p97p7"><dfn id="p97p7"></dfn></output><listing id="p97p7"></listing><ol id="p97p7"><rp id="p97p7"><thead id="p97p7"><dfn id="p97p7"></dfn></thead></rp></ol><thead id="p97p7"></thead><font id="p97p7"></font><strong id="p97p7"><sub id="p97p7"></sub></strong><pre id="p97p7"><em id="p97p7"></em></pre><listing id="p97p7"><meter id="p97p7"></meter></listing><ins id="p97p7"></ins><p id="p97p7"><dfn id="p97p7"></dfn></p><b id="p97p7"></b><i id="p97p7"><em id="p97p7"></em></i><ruby id="p97p7"><strike id="p97p7"><small id="p97p7"><acronym id="p97p7"></acronym></small></strike></ruby><span id="p97p7"><nobr id="p97p7"></nobr></span><var id="p97p7"></var><strong id="p97p7"></strong><thead id="p97p7"><dfn id="p97p7"><pre id="p97p7"><big id="p97p7"></big></pre></dfn></thead><thead id="p97p7"><strong id="p97p7"></strong></thead><tt id="p97p7"><ol id="p97p7"><thead id="p97p7"><form id="p97p7"></form></thead></ol></tt><listing id="p97p7"><meter id="p97p7"></meter></listing></div>
</html>