基于全局變量CRFs模型的微博情感對象識別方法
2015-04-21 08:17:31郝志峰杜慎芝蔡瑞初
中文信息學報 2015年4期
郝志峰,杜慎芝, 蔡瑞初,溫 雯
(廣東工業大學 計算機學院,廣東 廣州 510006)
?
基于全局變量CRFs模型的微博情感對象識別方法
郝志峰,杜慎芝, 蔡瑞初,溫 雯
(廣東工業大學 計算機學院,廣東 廣州 510006)
微博行文具有較大的自由性,其中情感對象識別是一個困難的問題,尤其是情感對象未顯性出現情況下的情感對象識別,暫未發現有效解決方法。該文針對這一難題,結合中文微博的特點,提出了一種改進的條件隨機場的模型。該模型把情感對象識別看作一個序列標記問題,通過在傳統的CRF序列標記模型上增加情感對象的全局節點,有效地結合上下文信息、句法依賴以及情感詞典,從而可以識別出微博中的情感對象。該方法的優勢在于能夠應用于情感對象未顯性出現的情況。實驗結果表明該方法比現有方法能更有效地識別出微博中的情感對象。
條件隨機場;微博;情感對象識別;信息抽取;情感分析
1 引言
近年來,隨著社交網絡的高速發展,微博作為一種新的媒介承載了海量的互聯網信息,如何有效地對微博信息進行觀點挖掘與情感分析具有重要意義。 近年來國內外已有許多情感表達和情感對象方面的研究,但是他們大多是針對產品評論信息或者新聞信息進行分析。與傳統的文本信息不同,微博字數限制和網絡行文的自由性,使得其含有大量縮略的表達,以及中英混用、錯別字、特殊符號(如表情符號等)等各類非規范中文表達,這些因素增加了情感分析的難度。目前國外已經有一些學者針對Twitter等[1-2]信息進行情感分析方面的研究,如Twitter Sentiment*http://twittersentiment.appspot.com/,也取得了不錯的效果。然而,由于國內的情感分析和觀點挖掘起步較晚以及中英文的差異性,準確識別出情感對象是困難的。
本文針對中文微博文本內容提出了一種情感對象的識別方法,把情感對象抽取看成一個詞級別的序列標記問題,即微博文本內容為需要進行標記的序列,通過對序列中不同位置的詞標記不同的標簽,達到識別情感對象的目的。為了更好地理解微博情感對象的抽取過程,通過一個例子來說明其工作過程。例如,現有一條微博“太開心了!今天買了個新手機,它的屏幕非常清晰,但是電池不太耐用!”,對之進行分析可以看出:
(1) “太開心了!”句中有一個明顯帶有情感傾向的詞“開心”和修飾的程度副詞“太”,該句是帶有正向的情感傾向的,但是情感作用的對象卻不在微博文本內容中,而是作用于發表該微博的作者“我”。 微博中存在大量這種博客主在網上進行個人情感表達的信息。
(2) “今天買了個新手機”是陳述一個事實,因此不帶有情感傾向。
(3) “它的屏幕非常清晰”是帶有正向情感傾向的表達,對象在文本中為“屏幕”,更粗粒度也可以是“它的屏幕”。
(4) “但是電池不太耐用!”中有一負向情感對象“電池”。
在上例中,情感對象識別的目標是將上述的如“它的屏幕”、“電池”以及隱藏的“我”這類情感對象標記出來,并為情感對象標記情感傾向。從例子中還可以看出,情感對象可能在標記文本內容中,也可能不在文本中。由于隱性情感對象未直接顯性地出現在文本內容中,因此要從文本內容中正確提取出這種情感對象是困難的,現有的研究和方法都不能解決這個問題。 在實際問題中除了上例中的這種情感對象是作者這個人的此類情況以外,微博中還包括一種常見的對象非顯性情況就是話題評論。例如,微博中包含有“#”符號的Hashtag等主題(話題)信息或者承接上一句話題等,在這些情況下對帶有主題背景的句子進行帶有情感傾向的評價時,對象本身就可能不在文本中,而默認的情感對象就是該話題本身。本文針對該問題提出了一種有效的解決辦法,對隱藏情感對象進行歸納和抽象化,使得抽取這類情感對象變得可行。同時提出了一種基于條件隨機場模型進行微博情感對象識別的方法,該方法綜合考慮了微博文本內容的上下文信息,以及其各個詞之間的句法依賴關系進行統計建模,通過向常見的條件隨機場模型中添加全局變量節點的方法來解決情感對象不在文本內容中的這種情況。
本文主要貢獻如下:
(1) 提出了一種基于條件隨機場模型的方法來進行微博情感對象識別,該方法對文本進行句法解析處理,充分利用了詞、詞性標注、情感詞、句法依賴和表情符等多種有效特征,有效地提高了模型標注的性能。
(2) 提出了一種向傳統的條件隨機場模型中添加全局變量節點的方法,用于識別情感對象不在微博文本內容中的情況,這使得方法具有更好的適用性,能夠有效地識別出微博中一些非顯性蘊含的情感對象。
(3) 針對微博內容的特殊性,對之進行特殊處理,有效地提高數據集的質量。構建特殊的網絡用語情感詞典和用戶分詞詞庫,能夠有效地提高特征的情感詞判定和分詞的準確度。
本文第2部分介紹相關工作,第3部分重點詳細介紹情感對象抽取模型,第4節進行對比實驗驗證模型,并對實驗結果進行分析,第5部分進行相關總結。
2 相關工作
早期的情感對象抽取的方法主要是針對產品評論信息而提出的,在此過程中,通常將情感對象看成是產品的特征信息,這些特征信息包括產品的組成部件和產品的屬性等信息。Hu和Liu等人[3-4]最早提出的方法是:產品評論信息評論的是與產品相關的產品特征信息,而產品的特征信息是有限的,通常為名詞(或名詞性短語)并且頻繁的在評論中出現,對于非頻繁的特征信息則通過離情感詞(通常為形容詞)最近的名詞(或名詞性短語)來進行補充。在此基礎之上,Popescu和Etzioni等人[5]提出了需要在預先已知給定一些產品屬性信息情況下,通過網絡搜索和計算名詞(或名詞性短語)與指定屬性的PMI值來確定是否為一個產品的特征。但該工作需要依賴Web或其他類似語料庫搜索來保證其足夠的覆蓋范圍。Scaffidi等[6]則認為在產品特征抽取過程中,產品評論信息中產品特征比在一般語料中更加頻繁出現,該方法在較小的語料集下則不一定可靠。
Kobayashi等人[7]則針對博客中寫的產品評論提出了不同的方法,通過利用模式挖掘抽取的句法模式,對之抽取情感對象和極性對。與該方法不同的是本文利用的是句法依賴樹而不是句法模式,因此不僅要考慮情感詞和情感對象之間的關系,還要考慮其他多種類型的依賴關系。
Stoyanov和Cardie等人[8]則把情感對象抽取看成一個主題指代確定問題,核心思想是把針對同一個對象的觀點進行聚類,用來判斷是否是針對相同的對象。而在本文中則是把情感對象識別看成一個序列標記問題。另外,Qiu和Liu等人[9]提出利用情感詞和情感對象之間的句法依賴關系不斷迭代來進行對象識別。這種方法則不能識別上文提到的情感對象不在文本中的情況。
以上幾種方法針對的是產品評論的情感對象抽取,由于評論中有指定的產品信息和限定的領域,使得問題更加具體、清晰,因此抽取工作往往都能達到比較好的效果。但是在其他文本中,情感對象抽取效果并不佳。例如,在新聞中抽取情感對象,主要通過主觀動詞(認為、相信)來找。這主要在于這些文本中評論對象很雜,另外情感詞也多樣化。Ma和Wan[10]提出在中文新聞評論中抽取中心詞作為情感對象。該方法對一句話只能抽取一個對象,因為沒有考慮其情感,所以抽取的對象未必是情感對象。
情感對象抽取過程通常可以當成序列標記問題,條件隨機場(CRF)由于有較好的序列標注效果使得其在情感對象抽取方面具有得天獨厚的優勢,目前國內的鄭敏潔[11]和王榮洋[12]等人有對基于CRF的情感對象識別進行了研究。而在微博情感對象識別方面,文坤梅[13]和高磊[14]等人通過對微博文本內容進行句法依賴關系分析結合情感詞典得到成對的<情感詞,情感對象>關系,進行抽取情感對象。現有中文情感對象抽取的研究和方法,要么不能較好應用于微博這種特殊的文本,要么存在較大性能瓶頸,而面對對象不在文本中的情況尚未提出適用的解決辦法。為了解決這些問題,本文提出了一種方法進行情感對象抽取,在第3節將對該方法進行詳細介紹。
3 基于改進CRF模型的情感對象抽取方法
在本節中將詳細介紹情感對象抽取方法的過程及其原理。該方法是基于條件隨機場模型提出的,下面3.1節首先介紹一下條件隨機場模型,3.2節介紹情感對象抽取模型及其推理和參數估計,在本節的最后介紹情感對象抽取模型用到的特征。
3.1 條件隨機場模型
條件隨機場(Conditional Random Fields,CRFs)是由Lafferty等人[15]于2001年提出來的概率無向圖模型,主要用來進行序列標記和切分。CRFs被廣泛的應用于文本處理,計算機視覺系統和生物信息學等領域[16],特別是在中文分詞、詞性標注、命名實體識別和信息抽取等自然語言處理領域都取得了不錯的效果,目前已有一些利用條件隨機場模型進行情感分析和情感對象識別方面的研究[11-12,16]。
傳統的線性鏈條件隨機場如圖1所示,已知其觀測值X={x1,x2,…,xn}為一個輸入序列,序列第i個位置的元素為xi,總共包含n個元素,輸出標記序列為Y={y1,y2,…,yn}同樣包含n個元素且第i個位置的元素為yi表示對應位置的輸入元素xi的輸出標記標簽。由上述可知,在通常的條件隨機場模型中,輸入元素的個數和輸出元素的個數是相等的。
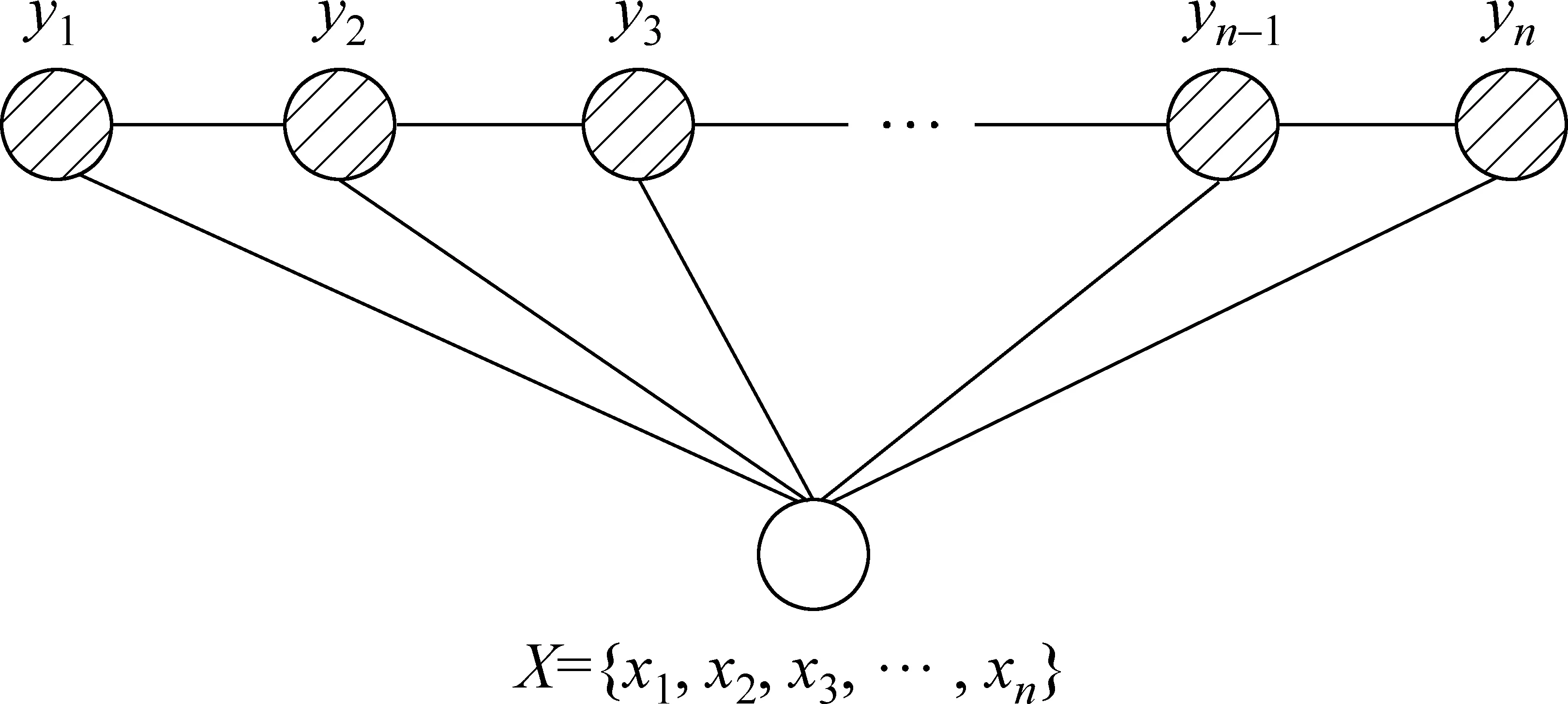
圖1 線性鏈條件隨機場
在概率模型進行情感對象抽取過程中,給定目標序列X取值為x的情況下,隨機變量Y取值為y的條件概率式(1)所示。
(1)
(2)
(3)
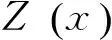
(4)
式(4)中Kn和Ke分別表示點特征集合和邊特征集合。
3.2 針對情感對象抽取的改進CRF模型
如果情感對象全部都在輸入的觀測序列X中,那么就可以用條件隨機場模型進行序列標記,從而抽取出情感對象。然而在進行情感對象抽取的過程中,發現情感對象不一定都在文本序列本身之中,上文中的微博例子中的“太開心了!”就屬于這種情況。為了解決這個問題,通過觀察微博發現其包含有這種隱藏的情感對象通常是有限的幾種可能,本文認為通常兩種就能概括:要么是微博主本人情感表達,這種情況可以認為對象為“我”;要么就是句子或者微博有個主題(話題)作為背景,類似于產品評論有一個確定的評價產品,這種情況對象即為“主題”。因此考慮到LDCRF(Latent-DynamicConditionalRandomField)模型[17-18],可以通過在線性鏈條件隨機場的基礎上添加兩個全局節點g1和g2,用于標記情感對象為“主題”和“我”,該模型如圖2所示,稱之為LLCRF(Linear-chainLatent-DynamicConditionalRandomField)模型。
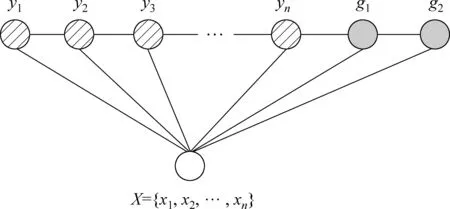
圖2 添加兩個全局節點后的線性鏈條件隨機場(LLCRF)模型
LLCRF模型每個狀態節點僅與它鄰接的狀態節點相連,yn和g2都與g1相連 ,則其求條件概率時有:
(5)
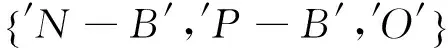
考慮到“我”和“主題”為整個句子的全局情感對象,因此鏈式連接的方式與句子末尾的詞進行聯系起來顯然不是最好的選擇。為了提高全局情感對象識別效果,提出另外一種改進模型(圖3),把兩個全局節點與句子中每個位置的詞進行全連接,提升兩個全局節點g1和g2跟整個句子之間的聯系,從而達到提高模型隱藏情感對象的識別效果。為了方便,把該模型稱之為GLCRF(GlobalLatent-DynamicConditionalRandomField)。
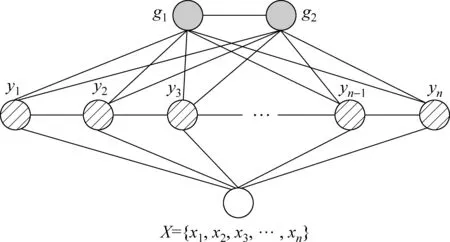
圖3 改進的GLCRF模型

(6)
3.3 模型推理和參數估計
下面討論在給定一個句子x情況下,如何得到該句子輸出對應的情感對象標記標簽s。在對句子進行分詞之后,輸出s序列由句子中每個詞對應的情感對象標記標簽yi以及g1和g2組成,即有s={y1,y2,…,yn,g1,g2},因此s可以進行如式(7)計算得到:
(7)
在計算各個節點的情感對象標記si的邊際概率過程中,直接用枚舉法進行計算將是困難的,因此采用了LoopyBP(LoopyBeliefPropagation)算法來進行計算。LoopyBP算法能夠非常有效地對概率圖模型中的邊際概率進行計算,它主要是通過各個隨機變量以及用因子(factors)連接變量的邊之間的消息(beliefs)傳遞來求出邊際概率(關于置信傳播算法的詳細描述請見文獻[19])。
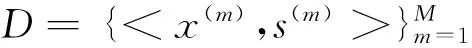
(8)
(9)
其中σ是一個給定的高斯先驗值,Lλ的偏導形式如式(10)所示。
(10)
在已知目標函數和它的偏導,模型的參數λ可以通過L-BFGS擬牛頓法來進行計算。
3.4 特征選擇
模型用到的主要有五類特征,包括基本詞特征、詞性標注特征、情感詞特征、句法依賴特征和表情特征。
基本詞特征:基本詞特征采用了一個固定長度的滑動窗口作為特征。例如,有一個句子分詞后序列為{“最近”,“天氣”,“一直”,“很”,“陰沉”},當前位置為第二個位置,即基本詞為“天氣”,假如窗口size為3,則基本詞特征為:{“最近”,“天氣”,“一直”}。為了防止特征過多造成維度災難,在此過程中需要過濾掉一些詞。
詞性標注特征:該特征與基本詞特征類似,把詞換成了詞的詞性標注,但是它的窗口被固定為3,即當前詞的詞性標注以及前后兩個詞的詞性標注。
情感詞特征:構建一個情感詞典,對每個詞的情感傾向進行標注,在情感詞典中就對之標注為對應的情感傾向,不在情感詞典中的詞則默認不帶有情感。pi表示序列第i個位置的詞wi的情感傾向。由于網絡微博用語的特殊性,在實驗中沒有直接采用常用的公開情感詞典(HowNet中文情感詞典*http://www.keenage.com/html/c_index.html和NTU情感詞集*http://nlg18.csie.ntu.edu.tw:8080/opinion),而是手工建立了包含微博常用網絡用語情感詞的一個情感詞典(如“給力”,“腦殘”等)與公開情感詞典相結合的情感詞典。
句法詞依賴特征:依賴特征包含三種情況,第一種,當前第i個位置的詞依賴的詞和被依賴的詞及其詞性;另一種為當前第i個位置的詞與其依賴的詞和被依賴的詞之間的依賴關系;最后一種是當前第i個位置的詞是否依賴情感詞或被情感詞依賴。

4 實驗和結果分析
4.1 數據預處理
在數據預處理階段,主要是對收集的微博進行處理,主要有以下幾個步驟。
第一步,微博處理和分句。由于微博數據的隨意性,為了方便后期斷句和分詞等處理需要進行一些必要的處理,微博中存在大量網絡用語和縮寫,因此需要對之進行轉換;有些人習慣用空格或其他符號(如“~”)代替標點符號進行斷句,因此也需要對之進行轉換;還有一些對實驗評估無用的鏈接(如圖片鏈接等)和特殊字符串需要剔除掉。在微博中常常包含有帶“#”符號的話題和帶“@”符號的聯系人也進行了處理,把微博頭和尾出現的話題和聯系人直接刪除,在微博句子中的則只刪除“#”和“@”符號。每條微博為一條文本數據,它通常包含一個或幾個句子以及一些表情符號,而模型情感對象抽取是在句子級別上進行序列標記的,因此需要對之進行分句處理,這樣做有助于提高分詞和語法解析的效率。表情為一種帶有強烈情感表達的方式,因此也需要把它提取出來,便于后期的特征提取過程。
第二步,分詞。在進行情感對象抽取的過程中,標記序列是一個由若干個詞和標點符號組成的序列。因此需要預先對句子進行分詞處理。在實驗中用到了斯坦福大學發布的自然語言處理工具*http://nlp.stanford.edu/index.shtml,其中用StanfordWordSegmenter*http://nlp.stanford.edu/software/segmenter.shtml分析工具來進行句子分詞處理。
第三步,詞性標注和句法解析。在情感對象抽取模型中用到了多種特征,其中包括有詞性標注特征和詞依賴特征,因此需要對句子中各個詞語進行詞性標注和句法解析才能得到。在此過程中用到了StanfordParser*http://nlp.stanford.edu/software/lex-parser.shtml句法解析工具來進行處理。該工具能夠對分詞后的句子進行詞性標注,并進行句法解析得到詞之間的依賴關系。針對微博的特殊性,分詞過程中有添加一個用戶詞典來提升分詞的效果,該詞典收集了一些常用網絡用語(如“抓狂”、“圍觀”等)。
第四步,標注。手工對每個詞進行標注,實驗用到的都是有監督學習,因此需要對實驗數據進行標注才能進行實驗。
第五步,數據規范化。將第四步處理得到的數據轉化為各個模型軟件工具包或程序需要的規范化數據,以便進行實驗。
4.2 不同模型對比實驗及結果分析
為了避免過擬合現象發生,實驗結果均采用五折交叉驗證進行實驗驗證。實驗數據包括兩部分: 手工收集數據集和NLP&CC2012評測數據集,數據詳情如表1所示。手工收集數據全部來自新浪微博,通過新浪開放API隨機爬取的真實微博數據,然后手工篩選和標注的。手工收集數據集中標注有情感對象1 264個,其中隱性情感對象約395個,全局隱形情感對象中“我”為193個,“主題”為147個。在NLP&CC2012評測數據集中,454個隱性情感對象包含對象“我”37個以及對象“主題”417個。
為了驗證模型的有效性,實驗過程中采用了樸素貝葉斯(Na?veBayes,NB)、支持向量機(SVM)和鏈式條件隨機場(LLCRF)以及其改進的全局變量條件隨機場(GLCRF)模型進行對比,四種模型均采用前文所述全部特征,并對表1中的實驗數據集進行五折交叉驗證實驗。實驗采用的GRMM*http://mallet.cs.umass.edu/grmm/是一個實現了CRF等概率圖模型的軟件工具包,被大量地用于科研領域。支持向量機(SVM)模型部分的實驗是利用libsvm*http://www.csie.ntu.edu.tw/~cjlin/libsvm/軟件工具包來進行的。實驗環境為: 2.0G雙核CPU,8G內存,64位Linux操作系統。
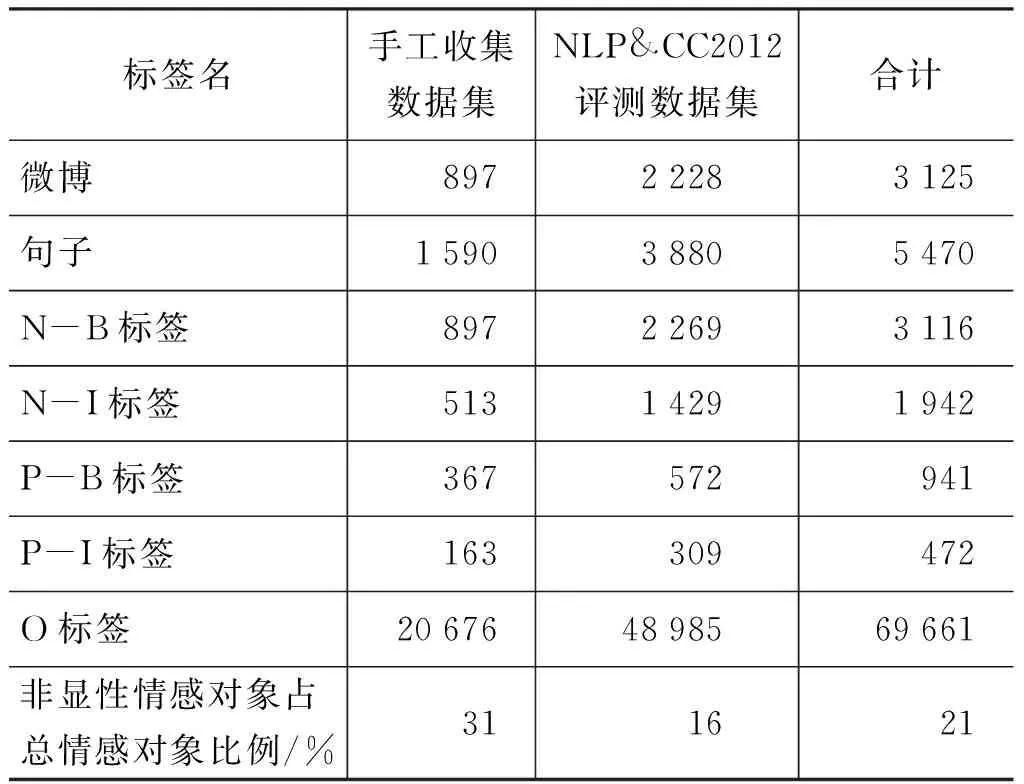
表1 實驗數據集的詳細情況
由于模型本身的復雜性以及引入了較多的特征,LLCRF和GLCRF模型的訓練過程比較費時,具體消耗時間根據訓練數據集的大小不同有所變化(本文實驗環境進行一次五折交叉驗證一般需花費數十分鐘),但是模型的標注過程比較迅速。同時實驗過程還發現,引入的各種特征、各種詞典以及分詞和句法解析過程均需消耗較多的內存(本文實驗過程中峰值期需要消耗6G以上的內存空間)。
實驗采用Precision值和Recall值的綜合評價指標F1值對實驗結果進行評價。實驗結果如圖4所示,其中圖4(a)表示手工收集數據集實驗結果,圖4(b)表示NLP&CC2012評測數據集實驗結果,圖4(c)表示手工收集數據集加NLP&CC2012評測數據集實驗結果。從曲線圖4(a)可以看出, LLCRF和GLCRF模型評測結果在N-B和P-B這兩個標簽已經體現出了優勢,但是其他標簽相對于SVM模型沒有表現出明顯優勢,這可能是由于手工收集數據集規模不夠造成,隨著數據集的增大,LLCRF和GLCRF的優勢會越來越明顯。O標簽在幾個模型中的F1值表現都比較好,評價結果都在0.9以上,而主要目標是提取出其他四種情感對象標簽,因此非情感對象標簽O的參考意義不大。在圖4(b)和圖4(c)中均可以看出LLCRF和GLCRF在N-B、N-I、P-B和P-I這四種情感對象標記標簽上F1值明顯優于SVM和NB。綜合三個實驗結果NB表現最差,SVM模型次之,LLCRF和GLCRF模型表現較好,能夠比較有效地標記出微博中的情感對象。

圖4 不同數據集的F1值結果曲線圖
另外注意到圖4的三個圖中, GLCRF模型在N-B和P-B標簽這兩個標簽上的表現均不同程度優于LLCRF模型,這是由于“我”和“主題”在表現為隱性全局情感對象時標記為N-B(負情感對象)或者P-B(正情感對象)這兩種標簽,GLCRF模型改進的實際效果就是體現在N-B和P-B標簽上。為了進一步驗證GLCRF模型對非顯性情感對象識別提升效果,我們進行了另一組實驗,統計了非顯性情感對象識別結果(表2)。從實驗結果數據可以看出,僅在NLP&CC2012評測數據集中“我”表現為情感對象時識別率有所降低,主要原因可能是由于評測數據集均為帶有hashtag的主題微博,而這種“我”情感對象所占比例太少(僅有37個)造成。而在其他情況下,非顯性情感對象識別率都有不同程度地提升,這說明了從LLCRF模型到GLCRF模型的改進,對隱性情感對象“我”和“主題”的識別具有一定提升效果,模型改進設計恰好是出于這一點考慮。因此,只要數據中包含有一定比例的非顯性情感對象,通過該方式提升識別率具有實際意義。
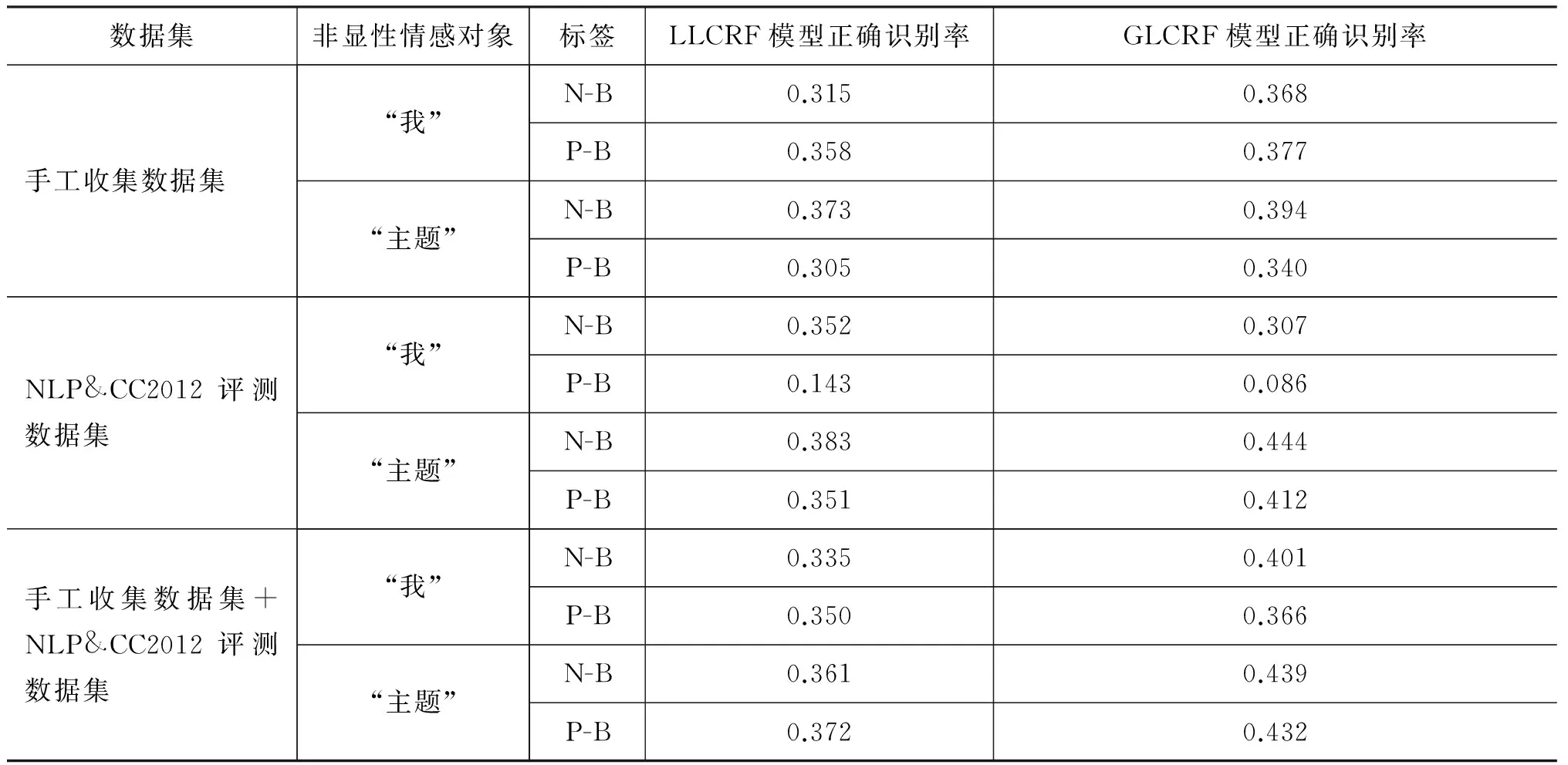
表2 非顯性情感對象識別結果
4.3 同現有同類研究實驗結果對比
針對非顯性地全局情感對象尚未發現類似的研究和評測,為了更好地評測模型性能,將模型與NLP&CC2012*http://tcci.ccf.org.cn/conference/2012/index.html評測結果進行對比。第一屆自然語言處理與中文計算會議(NLP&CC2012)是由中國計算機學會(CCF)主辦,其評測任務中包含有一個情感對象抽取的任務,并提供了公開評測數據集。在實驗過程中由于本文中創新性地引入了全局情感對象,而評測中并不包含這類情感對象,因此需要在原公開數據集上額外標記了全局情感對象。為了使本文中的模型同NLP&CC2012評測結果具有可比性,在此實驗過程中采用與評測任務參賽隊伍一樣的訓練集和測試集進行實驗。對比實驗取寬松評價指標宏平均值進行比較,在寬松評價中,評價指標通過提交的結果與標準標注結果之間的覆蓋率計算(詳情參見NLP&CC2012),值越高效果越好。
將本文中用到的四種有效的情感對象標簽匯總計算與標準標注結果之間的覆蓋率同NLP&CC2012評測結果中的寬松評價指標宏平均值提交結果進行對比,結果如圖5所示,從圖中可以明顯看出本文提出的LLCRF和GLCRF模型各項評測均大幅度優于NLP&CC2012評測的平均結果,在精確度(precision)上也明顯優于NLP&CC2012的最好結果,最后的F1綜合評測也達到了與NLP&CC2012的兩個最好結果Best1和Best2相當的性能。實驗結果表明模型具有較好的性能,由于本文中的模型用于解決更復雜的問題,更多情感對象引入導致了recall值有所下降。
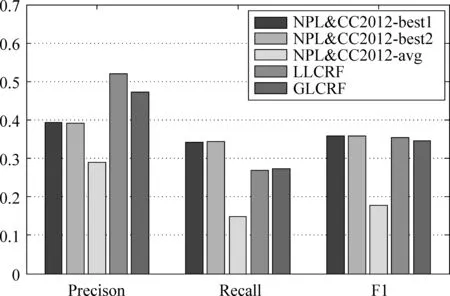
圖5 同NPL&CC2012評測結果對比
綜上所述,本文提出的基于CRF的模型相比于其他兩種模型具有一定的優勢,能夠較好地對情感對象進行提取。當存在大量的情感對象不在文本內容本身中這種情況時,LLCRF到GLCRF模型的改進是有意義的,反之則是有限的。盡管從實驗結果數值上看,微博情感對象的抽取性能離實用還有一定的距離,但是相比于同類方法具有一定的優勢,能夠解決更復雜的問題。
5 總結
本文提出了一種基于條件隨機場的情感對象識別模型,能夠在給定微博這種表達非常自由的文本信息下,不進行主題背景設定,從微博等文本信息中抽取出情感對象以及作用在該情感對象上的情感傾向,特別是該模型能夠有效識別出情感對象沒有顯性出現在文本信息中的情況。實驗對比證明該方法在實際表現中具有較好的效果,相比其他模型具有一定的優勢。
[1] Jiang L, Yu M, Zhou M, et al. Target-dependent Twitter Sentiment Classification[C]//Proceedings of ACL. 2011: 151-160.
[2] Barbosa L, Feng J. Robust sentiment detection on twitter from biased and noisy data[C]//Proceedings of the 23rd International Conference on Computational Linguistics: Posters. Association for Computational Linguistics, 2010: 36-44.
[3] Hu M, Liu B. Mining and summarizing customer reviews[C]//Proceedings of the 10th ACM SIGKDD International Conference on Knowledge Discovery and Data mining. ACM, 2004: 168-177.
[4] Hu M, Liu B. Mining opinion features in customer reviews[C]//Proceedings of AAAI. 2004, 4: 755-760.
[5] Popescu A M, Etzioni O. Extracting product features and opinions from reviews[M]//Natural language processing and text mining. Springer London, 2007: 9-28.
[6] Scaffidi C, Bierhoff K, Chang E, et al. Red Opal: product-feature scoring from reviews[C]//Proceedings of the 8th ACM Conference on Electronic Commerce. ACM, 2007: 182-191.
[7] Kobayashi N, Inui K, Matsumoto Y. Extracting Aspect-Evaluation and Aspect-Of Relations in Opinion Mining[C]//Proceedings of EMNLP-CoNLL. 2007: 1065-1074.
[8] Stoyanov V, Cardie C. Topic identification for fine-grained opinion analysis[C]//Proceedings of the 22nd International Conference on Computational Linguistics-Volume 1. Association for Computational Linguistics, 2008: 817-824.
[9] Qiu G, Liu B, Bu J, et al. Opinion word expansion and target extraction through double propagation[J]. Computational linguistics, 2011, 37(1): 9-27.
[10] Ma T, Wan X. Opinion target extraction in Chinese news comments[C]//Proceedings of the 23rd International Conference on Computational Linguistics: Posters. Association for Computational Linguistics, 2010: 782-790.
[11] 王榮洋, 鞠久朋, 李壽山, 等. 基于 CRFs 的評價對象抽取特征研究[J]. 中文信息學報, 2012, 26(2): 56-61.
[12] 鄭敏潔, 雷志城, 廖祥文, 等. 基于層疊 CRFs 的中文句子評價對象抽取[J]. 中文信息學報, 2013, 27(3): 69-76.
[13] 高磊,李斌,戴新宇等.基于依存分析和褒義指向的微博情感隊形抽取方法[C]//自然語言處理與中文計算會議(NLP&CC).北京:2012.
[14] 文坤梅,徐帥.基于句法依存關系的微博情感分析方法[C]//自然語言處理與中文計算會議(NLP&CC).北京:2012.
[15] Lafferty J, McCallum A, Pereira F C N. Conditional random fields: probabilistic models for segmenting and labeling sequence data[C]//Proceedings of the 18th International Conference on Machine Learning(ICML-2001). Morgan Kaufman. 2001.
[16] Sutton C, McCallum A. An introduction to conditional random fields[J]. Machine Learning, 2011, 4(4): 267-373.
[17] Nakagawa T, Inui K, Kurohashi S. Dependency tree-based sentiment classification using CRFs with hidden variables[C]//Proceedings of the 2010 Annual Conference of the North American Chapter of the Association for Computational Linguistics. Association for Computational Linguistics, 2010: 786-794.
[18] Morency L P, Quattoni A, Darrell T. Latent-dynamic discriminative models for continuous gesture recognition[C]//Proceedings of the Computer Vision and Pattern Recognition, IEEE Conference on. IEEE, 2007: 1-8.
[19] Murphy K P, Weiss Y, Jordan M I. Loopy belief propagation for approximate inference: An empirical study[C]//Proceedings of the Fifteenth Conference on Uncertainty in Artificial Intelligence. Morgan Kaufmann Publishers Inc., 1999: 467-475.
Sentiment Target Extraction Based on CRFs Global Variables for Chinese Micro-blog
HAO Zhifeng, DU Shenzhi, CAI Ruichu, WEN Wen
(Department of Computers, Guangdong University of Technology, Guangzhou, Guangdong 510006, China)
Owing to informal words and expressions widely used in micro-blogs, target recognition for the sentiment analysis of microblogs is difficult, especially when the targets are not clearly mentioned. An improved conditional random fields model is proposed to deal with this issue, treating sentiment target extraction as a sequence-labeling problem. Through adding global nodes, the contextual information, syntactic rules and opinion lexicon are considered in the targets extraction. The major contribution of this method is that it can be applied to the texts in which the targets are mentioned in the sequence. Experimental results on the Sina microblog data demonstrate that this method outperforms the state-of-art methods.
CRFs; microblog; sentiment target; information extraction; sentiment analysis

郝志峰(1968—),博士,教授,博士生導師,主要研究領域為機器學習,仿生算法,生物信息學。E-mail:zfhao@gdut.edu.cn杜慎芝(1988—),碩士,主要研究領域為機器學習,自然語言處理。E-mail:dushenzhi@qq.com蔡瑞初(1983—),博士,副教授,主要研究領域為機器學習,數據挖掘。E-mail:cairuichu@gmail.com
1003-0077(2015)04-0050-09
2013-08-22 定稿日期: 2013-12-02
國家自然科學基金(61100148,61202269);廣東省自然科學基金(S2011040004804);廣東省科技計劃項目(2010B050400011)
TP391
A
猜你喜歡
中華詩詞(2021年3期)2021-12-31 08:07:22
大連民族大學學報(2021年2期)2021-07-16 05:41:42
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年18期)2018-11-14 01:48:06
中華詩詞(2018年3期)2018-08-01 06:40:40
中華詩詞(2018年11期)2018-03-26 06:41:32
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
小學教學參考(2015年20期)2016-01-15 08:44:38
