基于微博的情感傾向性分析方法研究
2015-04-21 08:17:30李思雨阮冬茹劉邵博周二亮喬世權
中文信息學報 2015年4期
高 凱,李思雨,阮冬茹,劉邵博,周二亮,喬世權
(河北科技大學 信息科學與工程學院,河北 石家莊 050018)
?
基于微博的情感傾向性分析方法研究
高 凱,李思雨,阮冬茹,劉邵博,周二亮,喬世權
(河北科技大學 信息科學與工程學院,河北 石家莊 050018)
隨著微博等新型社會網絡媒體的發展,人們在網絡上傳播著對各類話題的情感,社會網絡也因此成為了挖掘社情民意的有效平臺。傳統文本分析算法難以適應篇幅短小、內容瑣碎且富含情感特征的微博等短文本挖掘的需要。該文提出基于情感單元和評價對象分析的微博情感傾向性分析方法,通過基于詞性共現概率計算的情感單元和情感評價對象抽取,計算情感單元的情感度,建立博主個性化及情感傾向性分析模型,完成情感傾向性分析。實驗結果及分析驗證了上述算法的有效性。
社會網絡;短文本挖掘;情感單元;評價對象
1 引言
近年來,微博等社會網絡新媒體發展迅速。由于在博文中蘊含著潛在的輿情價值,因此需要有效的處理機制來獲取用戶觀點并分析其情感傾向性,對基于微博的文本情感傾向性方法進行研究,是必要的。選擇微博作為研究數據集是出于如下考慮: 首先,博文內容短小,口語化、內容碎片化等特點明顯,常規的文本挖掘算法常難以發揮有效作用;其次,微博用戶傾向于發布自己當前感受等主觀性信息,博文可能富含情感因素;最后,微博傳達著社會輿情,通過對博文的深度分析,可對相關部門了解社情民意提供幫助。
目前,人工智能領域中的心理狀態與認知分析主流方法多是采用有監督學習方法分析情感并借助語言和心理學所發現出的規則完成相應處理,所處理的文本多是電子郵件、新聞或文學作品等較規范的文本。將微博文本中蘊含的情感與自然語言處理、文本挖掘中所涉及到的方法結合起來進行的研究較少,且相關工作中存在的主要問題有: 單純基于規則的方法需要領域專家定義大量的規則,代價較高,在對情感傾向性分析過程中有局限性;已有的情感分析多是將對評價詞語的識別作為分析基礎,并基于評價詞語完成相關分析(如采用基于情感句打分的方法和基于有指導的分類方法等),但只考慮評價詞語的作用常常是不夠的,因為出現在句中的評價詞語并不一定總能表現出一定的情感傾向性。
本文提出一種針對評價類博文中情感單元的抽取方法,通過基于詞性共現概率的情感單元和情感評價對象抽取,利用正態分布規律對情感詞權重進行計算,分析情感單元的情感度;通過博主個性化分析,完成針對博主的情感傾向性分析。研究成果對呈短小、碎片、不規范、富含情感特征的社會網絡文本挖掘有重要意義。
2 相關工作
由于立場、觀點等的不同,人們對生活中各種事件所持態度和情感傾向性存在差異,這種差異尤其體現在社會網絡等反映草根觀點的社會網絡媒體上。情感傾向性分析對說話人態度進行分析,并識別出其情感傾向。利用它,便于分析熱點事件背后的輿情,可為企業、政府等機構提供重要的決策參考依據。相關工作中,文獻[1]在針對Twitter的文本進行情感分析后,提出它可作為社會投票調查的一種替代方法。而對微博語言分析主要指面向事實的博文挖掘,包括主題抽取與情感評價、熱點話題探測、共同興趣挖掘等。在主題抽取與情感評價方面,文獻[2]提出一種基于句法路徑的情感單元自動識別方法;在熱點話題探測方面,文獻[3]給出在社區網絡中基于用戶討論話題內容和鏈接分析的統計模型。按照技術遞進關系,文獻[4]將文本情感分析歸納為三項遞進的研究任務: 情感信息抽取、情感信息分類、情感信息檢索與歸納。在情感信息抽取方面,構建情感詞典是一項基礎性工作。相關工作中,文獻[5]用兩種資源對情感詞典進行擴展,建立了具有傾向程度的情感詞典;基于統計和上下文信息來發掘評價詞和評價對象的方法也在一些文獻中提到[6-7],其中,文獻[6]提出語義詞典構建及擴展方法,通過對情感詞匯與所對應的評價主題關系的分析,給出一種基于Propagation思想的情感詞擴展方法,文獻[7]討論了針對不同應用域的基于條件隨機場CRF的評價對象抽取方法;文獻[8]給出基于雙語信息和標簽傳播算法的中文情感詞典構建方法,并借助機器翻譯,結合雙語言資源的約束信息,利用標簽傳播算法計算詞語的情感信息,但它缺乏對語料中存在的情感極性反轉情況(如否定、轉折等)的分析;文獻[9]給出評價對象及其傾向性的抽取和判別方法,在LTP平臺對語料處理結果的基礎上,利用SBV極性傳遞法,引入指代消解、ATT鏈算法和互信息法,對語料中的評價對象進行抽取,并在對極性詞進行傾向性判別時考慮不同類型的句子以及副詞、連詞對極性的影響,但基于淺層句法分析的方法對句法分析結果的依賴度較大。在情感信息分類方面,文獻[10]提出SentiRank方法;文獻[11]認為在判斷文檔的情感極性時,不同句子具有不同的情感貢獻度。限于篇幅,本文不對情感信息檢索與歸納的相關工作進行介紹。
在對社會網絡情感傾向性分析的主要方法中,一類是基于情感知識的方法,另一類是基于機器學習的方法。基于情感知識的方法將表示情感的詞語分為正、負情感詞,再與規則相結合,以便決定句子情感傾向,文獻[12]將抽取的每個句子的情感詞表及依存關系進行情感傾向計算,評價情感句子和整個博文的情感傾向。基于機器學習的方法是選擇文本中的一些特征標注訓練集和測試集,通過機器學習算法訓練得到分析結果,相關工作中,文獻[13]將訓練集中的文本分別標記情感傾向和主題類別,根據不同情感和主題的語言表達方式分別估計情感和主題語言模型,評估測試文本與模型之間的相似性并確定文本主題和情感傾向;文獻[14]提出一種基于淺層篇章結構的評論文傾向性分析方法,采用基于n元詞語匹配的方法識別主題,通過對比與主題的語義相似度大小和進行主客觀分類抽取出候選主題情感句,計算其中相似度最高的若干個句子的傾向性,將其平均值作為評論文的整體傾向性,但沒有針對非評論文文體的處理效果分析;文獻[15]提出一種基于動態隨機特征子空間的半監督學習方法,通過動態生成多個隨機特征子空間,基于協同訓練方法,在每個特征子空間中挑選置信度高的未標注樣本,并使用這些挑選出的樣本更新訓練模型;文獻[16-17]提出依據粉絲或@、Follow等標記,基于SVM完成微博信息分類研究,并基于正文和評論之間的關系等進行微博情感分析。
3 算法設計與系統實現
3.1 概述
算法流程如圖1所示。在進行情感分析與處理前,需要對微博文本進行預處理,包括基于Double-Trie Tree的詞法分析、詞義消歧、未登錄詞處理等。由于中文自然語言的極端復雜性以及博文中網友自造詞的普遍使用,詞義消歧處理是必要的,通過基于Bi-Gram模型,通過計算最短路徑的Viterbi算法,得到切詞產生的前后兩個詞條間的前后依賴得分,其絕對值越大,說明兩個詞條的前后關系越密切,即這兩個詞條應切分出來。對未登錄詞的處理是采用基于統計和基于規則并用的方法,對博文中切分出來的詞條集合進行基于距離的詞條間共現概率統計,當兩個或多個詞條相鄰共現概率相同或達到指定閾值時,認為它們可合并為一個新詞,例如:“我是歌手節目不錯。”正常可分為“我/是/歌手/節目/不錯”,但當“我是歌手”共現頻率相同或達到指定閾值時,則將其視為一個新詞被識別出來,即切分成“我是歌手/節目/不錯”;同時,采用基于規則方法(如詞性關聯關系規則、連續數值串規則、連續字母串規則、數值字母符號混合規則等),可將諸如“50”、“3.5%”、“百分之八十”、“x5”、“2014年3月8日”、“4月9日”等詞條正確切分出來,從而對達到未登錄詞識別的目的。采用基于距離的詞條間共現概率統計方法發現未登錄詞,即迭代統計各詞條間的共現概率及其距離值,當兩者滿足指定的閾值條件時,則合并詞條。
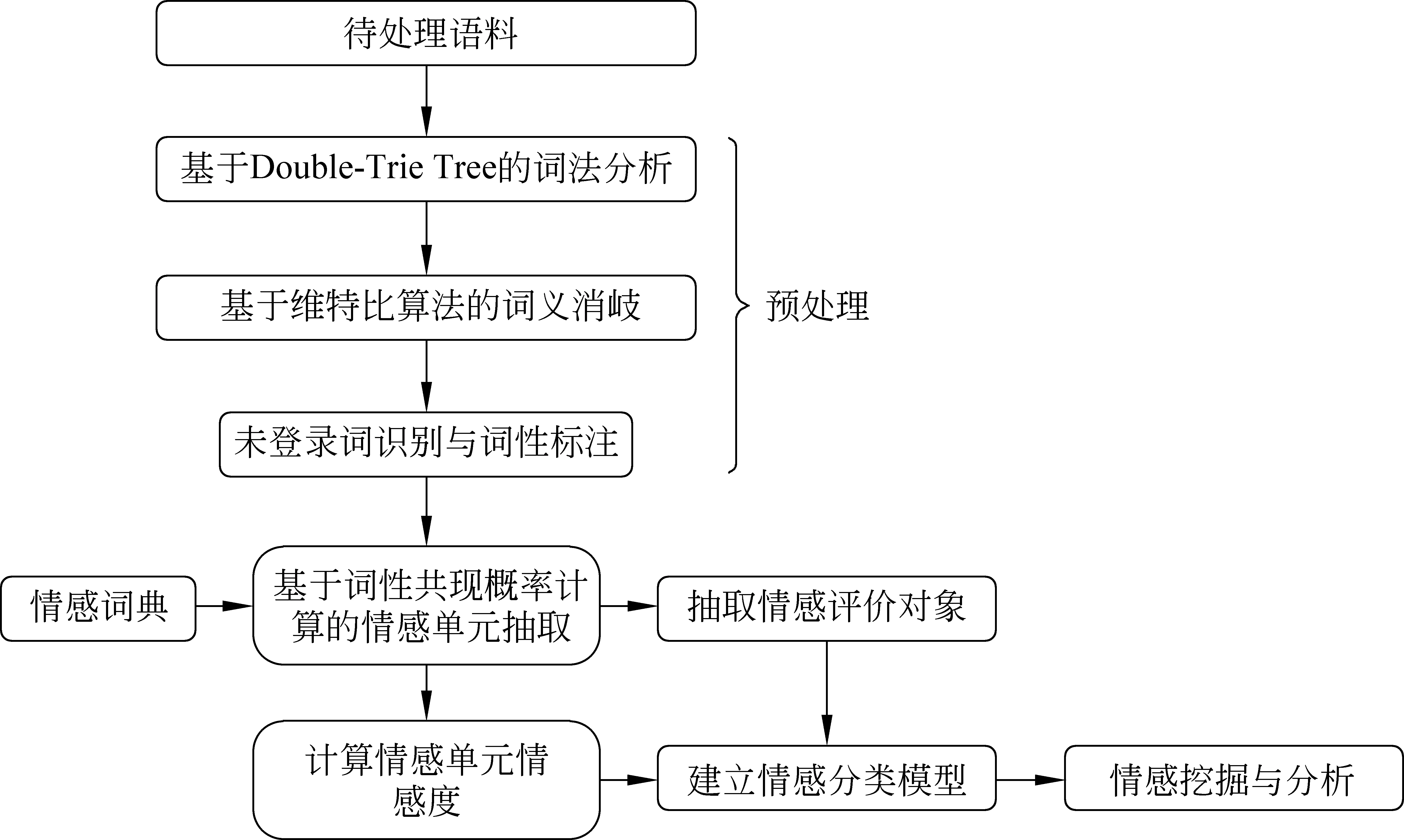
圖1 算法主要流程
3.2 基于詞性共現概率的情感單元抽取方法
基于詞性共現概率的情感單元抽取,是在情感詞典的幫助下,找出博文中出現的情感詞并確定情感單元在句中位置,計算詞性共現概率,判斷其左右詞匯是否易于與情感詞結合構成情感單元。通過對情感句進行分詞和詞性標注,統計待處理語料中詞匯的詞性共現頻數,具體步驟如算法1所示。

Algorithm1:基于詞性共現概率的情感單元抽取BeginStep1 訓練語料獲得詞性共現頻率input:訓練語料庫;1)輸入博文;2)分詞,詞性標注;3)根據情感詞典進行情感詞正負性標記;4)統計詞性共現頻率;Step2 根據詞性共現頻率抽取情感單元;input:情感句;1)分詞,詞性標注;2)情感詞正負性標記;3)計算詞匯在當前詞性下為情感詞的概率;分析詞性共現概率;End
如在博文“這個賓館的房間沒有做出改進”中,“改進”是情感詞,“沒有做出改進”是情感單元,“房間”是情感評價對象。先對該句進行分詞以便獲得詞匯列表,處理結果是:“這個/r 賓館/n 的/uj房間/n 沒有/v 做出/v 改進/v”。對該詞匯列表進行情感詞標記,處理結果是:“這個/r,賓館/n,的/uj,房間/n,沒有/v,做出/v,改進/v@”,其中@表示正向情感詞。使用本文采用的情感語料庫(詳見后續試驗數據說明),按算法1得詞性共現概率結果是:“v=159278v@=8560 vv@=1324 vvv@=162 dvv@=391”。分別計算v@情感詞在情感詞為動詞v出現下的概率(即a: = v@/v),計算vv@情感單元在情感詞v@中出現下的概率(即b: = v v@/v@)。由于vv@向后結合沒有詞匯,故其概率c=0。比較a、b、c大小,以vv@作為情感單元并重新計算情感單元的b、c值,一直循環直到b、c值全部小于a值時停止,可得到情感單元“做出改進”。顯見,此例中的實際情感單元應是“沒有做出改進”。導致上述錯誤的原因是詞匯“沒有”在句子中既可作動詞v又可作副詞d來使用,如能將其標記為副詞d,根據dvv@在已知條件下的概率,就能正確抽取情感單元,可見這種在句中具有改變情感正負性的詞匯對于句子情感度的影響較大,不恰當的分詞和詞性標注(這幾乎是不可避免的)可能會將其誤標記為其他詞性。本文針對這種情況的處理策略是在抽取情感單元結束后,如發現情感單元前的詞匯是這種可改變情感正負性的詞匯,就將其加入情感單元中,見公式2中影響因子β的使用。
3.3 基于詞性共現概率的情感評價對象抽取方法
情感評價對象多是一些名詞性短語,它們往往位于情感單元附近。通過情感單元位置向前或向后搜索名詞,可初步確定情感評價對象位置。如果單純以名詞來斷定哪個詞匯是情感評價對象,情感評價對象的位置就可能是在情感單元的前或后,而對于在句子中存在多個名詞及情感評價對象等不確定位置的情況,可通過詞性共現概率來抽取情感評價對象,具體方法如算法2所示。

Algorithm2:基于詞性共現概率的情感評價對象抽取BeginInput:情感句;1)執行Algorithm1算法,獲得情感單元在句中位置信息及詞性共現頻數;2)抽取情感單元前最近名詞與情感單元間詞匯詞性串(含名詞和情感單元);3)抽取情感單元后最近名詞與情感單元間詞匯詞性串(含名詞和情感單元);4)分析上述結果,確定情感評價對象;End
下面給出基于上述算法抽取情感評價對象的過程。如針對博文“公司在美麗的鄭州”的分詞結果為:“公司/n 在/p 美麗/a 的/uj鄭州/ns”。句中存在兩個名詞“公司”和“鄭州”。究竟“公司”是“美麗”的?還是“鄭州”是“美麗”的?通過對語料的詞性共現概率分析可知,“美麗/a,的/uj,鄭州/ns”的詞性共現概率比“公司/n,在/p,美麗/a”的詞性共現概率大。因此可獲得正確的情感評價對象,并確定情感評價對象是“鄭州”,而非“公司”。
由于中文自然語言的極端復雜性,應區分不同情感評價對象。如對博文“酒店房間有點小”以及“酒店房間的衣柜有點小”,這兩句所表達的情感對象不一樣——前句對“房間”表達了不滿,而后句對房間的“衣柜”表達了不滿。經統計發現,詞匯“房間”的使用頻數遠高于“衣柜”的頻數。對情感評價對象對情感傾向的影響度進行分析,統計語料中的名詞頻率,利用指數函數Y=ax, x∈(0,1)計算名詞權重,再進行歸一化處理。實驗結果表明,隨著a值變化,情感句的判別準確率發生相應改變,且正負情感句判定變化一致,可見情感評價對象對情感單元情感度確實存在影響(詳見后文的實驗結果與分析)。
3.4 情感單元的情感度及其計算
對于抽取出來的情感單元,要計算其情感詞權重(即情感度)。對于不同的情感詞,其權重是不一樣的。統計發現,測試語料中具有極端正、負傾向的情感詞的使用是較少的,而具有中庸傾向的情感詞匯是出現頻率較高的,可見情感度的分布基本滿足正態分布規律。公式(1)中,x表示詞匯的情感度,F(x)表示詞匯出現的頻率。對實驗語料庫中的情感詞詞頻進行統計,計算情感詞出現的頻度并作為此情感詞的y值,通過正態分布函數的逆函數計算出該情感詞的x值(即該詞情感度)。由于情感詞分布不一定是標準正態分布,在建立計算模型時,分布的期望μ值一般為0,直接影響情感詞分布稀疏與稠密程度的正態分布標準差σ值可通過實驗來確定。
(1)
實際中,情感單元不僅存在正、負向情感詞,也可能存在一些修飾詞匯,這些詞匯可能會加強、削弱甚至扭轉情感的極性。對于這些本身不存在情感但卻對情感表達有增強、削弱或扭轉作用的詞,可單獨設置詞表。當計算情感單元的情感度時,可對其進行一定的加權計算——即對情感有增強效果的詞匯,定義其影響因子β>1;對情感有削弱作用的詞匯,其影響因子0<β<1;對情感取扭轉效果的詞匯,其影響因子-1<β<0。當這樣的副詞有多個時,其總體影響因子為多個影響因子的加權代數式。情感度的形式化計算如式(2)所示,式中n為修飾詞匯個數,x為情感詞情感度,degree為情感單元情感度,f()為情感度函數。
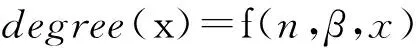
(2)
3.5 情感傾向性分析
3.5.1 基于博文的情感傾向性分析
將博文表示為情感向量A(用抽取的情感評價對象數目作為A的維度,用其情感度作為A中相應維的值);計算情感向量A在設定向量B上的映射向量C,用C的正負情感傾向作為博文的情感傾向。該模型與傳統文本分類算法中向量空間模型VSM的區別在于,傳統VSM算法選擇在文本中對文本內容具有代表性的詞匯作為文本特征詞,通過特定的特征權重計算方法計算出特征權重并將其作為維度權值,由此建立分析模型。具體地,抽取情感句中的情感評價對象的數目作為向量維度,利用情感詞典抽取句中具有情感傾向的詞匯為特征詞,用基于詞性共現概率計算的情感單元抽取算法抽取情感單元,計算情感單元的情感度,并將其作為模型中相應維度的權重。如對于博文“這個賓館的環境不錯,交通很便利,家具都很新,大床,大電視,就是衛生間有點小”,情感評價對象存在包含關系(即上層對象“賓館”包含下層對象“家具”、“衛生間”等)。為此,建立情感向量,針對本例為A(a1,a2,a3,a4,a5,a6) (注:A(a1,a2,a3,a4,a5,a6)數值分別為此例中的情感單元“不錯”、“便利”、“很新”、“大”、“大”、“有點小”的情感度權值),計算A在設定向量B上的映射向量C(C的方向為情感句的情感傾向)。本例情感向量是正值,其情感度越高,則所獲得的對評價客體的評價就越高。當對客體“賓館”的子客體的評價存在不同的評價態度時,可計算出該句對評價客體“賓館”的總體情感態度。
首先需要對語料庫進行分詞與標注,以便將句子切分成帶有詞性標注的詞匯,得到相應的統計信息(含詞性共現、情感詞詞頻、名詞詞頻等);之后,通過分析完成情感單元抽取、情感評價對象抽取、計算情感單元的情感度等,系統處理流程如圖2所示,主要包括情感詞情感度計算、情感評價對象影響因子計算、情感單元抽取、情感單元情感度計算、情感評價對象抽取、情感句向量構建等六個部分(見圖2中的模塊)。其中,情感詞情感度計算模塊通過統計情感詞詞頻,利用正態分布逆函數計算獲得情感詞匯的情感度;情感評價對象影響因子計算模塊計算情感評價對象對情感的影響因子;情感單元抽取模塊利用情感詞詞典統計詞性共現頻率,抽取情感句中的情感單元;情感單元情感度計算模塊利用情感詞情感度、情感評價對象影響因子和副詞詞典計算抽取到的情感單元的情感度;情感評價對象抽取模塊利用詞性共現和抽取到情感單元的位置抽取情感句中的情感評價對象;情感句向量構建模塊利用抽取的情感評價對象和計算的情感單元情感度構建情感句向量。
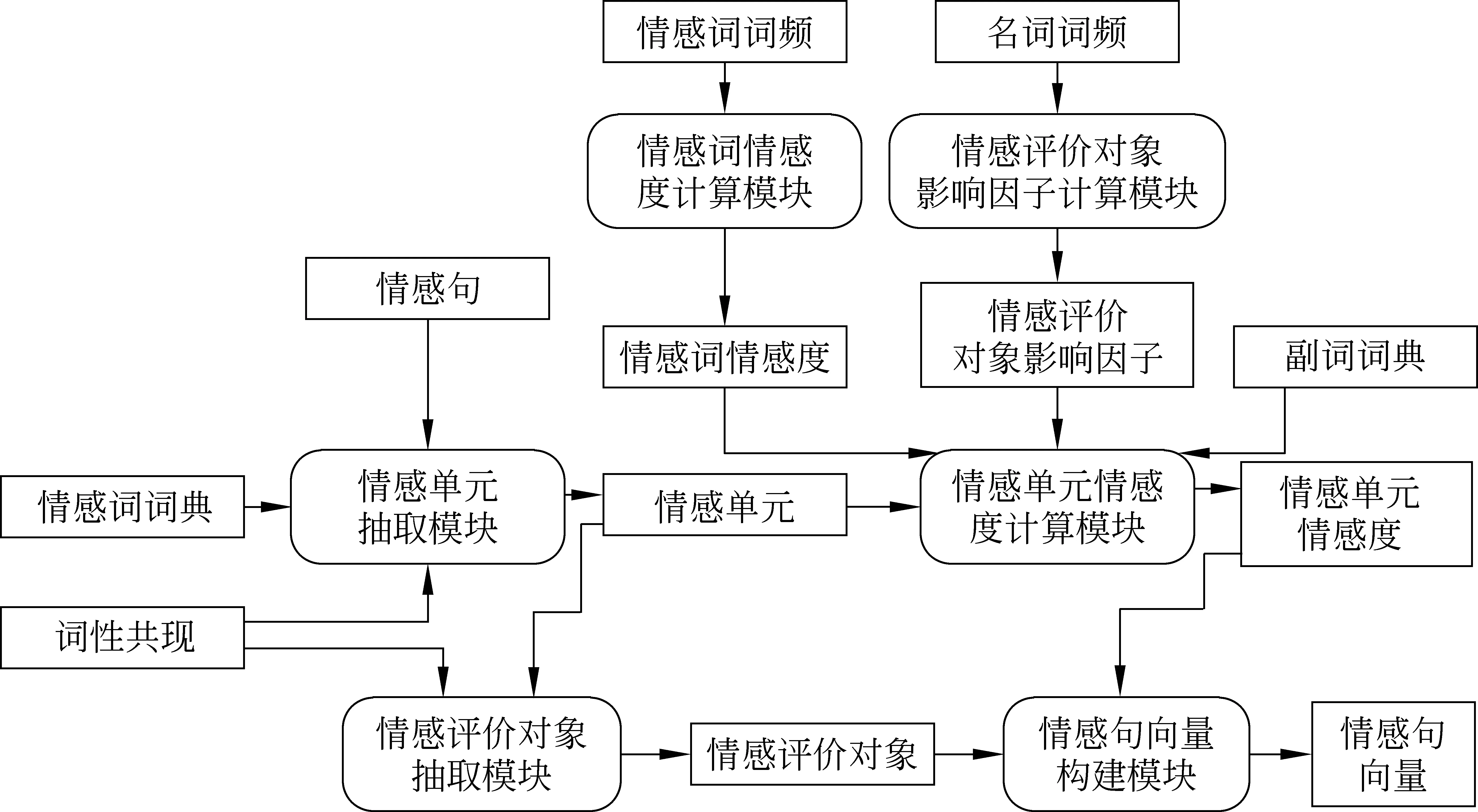
圖2 系統處理流程
3.5.2 基于博主的情感傾向性分析
認知科學研究表明,人的相對穩定的情感特征不僅和外部事件的刺激有關,也和人的個性和歷史情感態度相關。雖然可通過基于詞性共現概率實現情感單元和情感評價對象抽取,計算情感單元的情感度,但中文較為復雜,單純基于博文進行分析常常是不夠的,因為同樣的話出自不同人之口,其權威性也有很大差異。如果缺少對博主歷史情感態度和個性化屬性的分析,可能會對情感分析帶來不利影響,而依據博主的個性與歷史言論,可得出較合理的情感分析結論。從前期工作中統計的數字來看,一部分博主已完成了實名認證(且這個數字目前還在繼續增長)。因此,對擁有背景和個體信息的博主進行個性化建模,從結合了博主個性化因素的多個維度去分析,是必要的。提出基于博主個性化建模分析的方法,刻畫博主的個性化信息的主要維度是博主個性化特征向量V、博主權威度W、博主影響度F。
? 博主個性化特征向量V: 分析博主的微博標簽和博主的歷史博文。通過對其內容的主題詞提取,形成個性化特征向量集合。
? 博主權威度W: 分析博主是否完成了實名認證、所在領域domain、學歷情況等。其中,認證代表其身份的可信性;學歷代表自身知識的廣度和深度層次;所在領域代表自身所善長的方向,如存在行業領域domain,則將其作為衡量權威度的一個因子,即當博主個性化特征向量涉及其行業領域時,要進行相應的加權操作,以強化博主在該特征向量上的權威度,如不存在行業領域值,則將特征向量設定為經驗閾值。設實名認證權重為經驗參數wr,學歷權重為經驗參數we(其基值base=1),權威度計算方法如公式3所示。
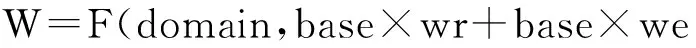
(3)
? 博主影響度F: 計算博主影響度時,需要參考博主發布的博文、轉發、評論等對其他網絡用戶的傳播影響力。由于存在僵尸粉、水軍等,故只從粉絲、關注等的某一方面去度量顯然是不合理的。考慮從兩個方面來綜合度量: 一方面是粉絲數與關注數之比值,說明該博主的正反關系倍數R1;一方面為被轉發數、點贊、收藏數、評論數的和與發博數之比值,說明該博主所發博文的真實受眾的倍數R2。博主影響度F的測度公式見公式4。
(4)
4 實驗結果與分析
4.1 基于博文的情感傾向性實驗結果與分析
為驗證相關算法性能,進行了相關實驗,實驗硬件環境為: CPU雙核主頻1.60GHz+2G內存+Window系統,訓練語料庫使用的是公開的10 000篇中文情感挖掘語料[18](其中7 000篇為正向語料,3 000篇為負向語料),測試語料有上述中文情感挖掘語料的6 000篇語料子集[18](其中3 000為正向語料,3 000為負向語料)。
4.1.1 參數確定
實驗采用的詞典中的詞本身是無權重的。通過計算,在建立模型時為其賦予合理權重,之后再進行情感分析。使用的情感詞的情感權重是通過正態分布逆函數計算出來的,其中正態分布期望μ=0,正態分布標準差σ通過實驗確定;情感評價對象對情感度的影響因子是通過指數函數Y=ax計算獲得的(a為情感評價對象屬性權重影響因子,其值通過實驗確定)。通過訓練和測試,從結果中選擇最優的情感權重,來確定最優的參數σ以及影響因子a。訓練語料采用前述的10 000篇公開語料,測試語料采用前述的6 000篇語料子集,情感詞典采用知網詞典(含4 370個負向詞以及4 566個正向詞),實驗結果如表1所示,其行表頭表示在計算情感詞情感度中不同標準差的正態分布,列表頭為計算對象影響因子所采用的指數函數,表中數據為正向情感判定正確率和負向情感判定正確率(表中“|”前為正向情感判定正確率,“|”后為負向情感判定正確率)。隨著對象影響因子指數函數Y=ax中的a取值從1升到3,正向情感判定和負向情感判定正確率都先增加后減少,在a=2的時候正確率最高,這表明情感評價對象確實對情感單元情感度有一定的影響;對情感詞情感度的計算中,隨著標準差的增加,負向情感判定正確率增大,正向情感判定正確率減小,二者表現不一致,這說明標準差越大,詞匯情感度值分布越分散,對負向情感的判定越有利,反之詞匯情感度分布越稠密,對正向情感的判定越有利。實驗表明情感詞權重計算標準差σ最優為1.2,情感評價對象影響因子計算中指數函數最優為Y=2x。
4.1.2 情感元素抽取
通過召回率和準確率對情感元素抽取結果進行評估。實驗中采用的訓練語料為上述中文情感挖掘10 000篇公開語料(正向7 000篇,負向3 000篇),測試語料為上述中文情感挖掘6 000篇語料子集(正向3 000篇,負向3 000篇)。情感詞匯情感度計算時正態分布標準差σ=1.2,情感評價對象影響因子采用Y=2x,采用由對相關領域語料人工統計情感詞獲得的情感詞典,對情感單元及情感對象屬性進行抽取,專家對實驗結果評測,結果如表2所示,可見提出的通過判斷情感詞前后詞性共現概率的情感元素抽取算法具有一定可行性。

表1 情感詞及權重對情感分類的影響

表2 抽取結果性能分析
表2中的情感單元的召回率和準確率比情感評價對象的相應指標高,是因為通過情感單元的位置來尋找情感對象并進行抽取,這樣在尋找情感對象的過程中就會存在一定誤差;情感單元和情感評價對象的召回率都大于準確率,說明在抽取過程中存在誤將非情感對象或非情感單元當作情感對象或情感單元抽取的情況。為驗證這個結論,對抽取結果進行分析,如存在博文:“酒店的軟硬件設施不夠完善”,其評價單元為“不夠完善”,其中“不夠”只是情感詞“完善”的一個修飾詞,但由于“不夠”和“完善”這兩個詞都存在于情感詞典中,系統錯誤地將其拆分為多個情感單元,導致情感單元的準確率下降。如何解決該問題,是我們下一步的研究內容。
4.1.3 情感判定性能指標分析
為了評價和分析情感判定情況,采用前述的由對相關領域6 000篇語料人工統計情感詞獲得的情感詞典,訓練語料為前述的10 000篇中文情感挖掘語料,測試語料為從訓練語料中隨機抽取200個評論語料(其中100句正向評價,100句負向評價),情感詞權重計算標準差σ=1.2,情感對象影響因子計算函數為Y=2x,統計經情感分析后的召回率和準確率情況如表3所示。

表3 情感判定性能指標
4.1.4 情感分析結果評價
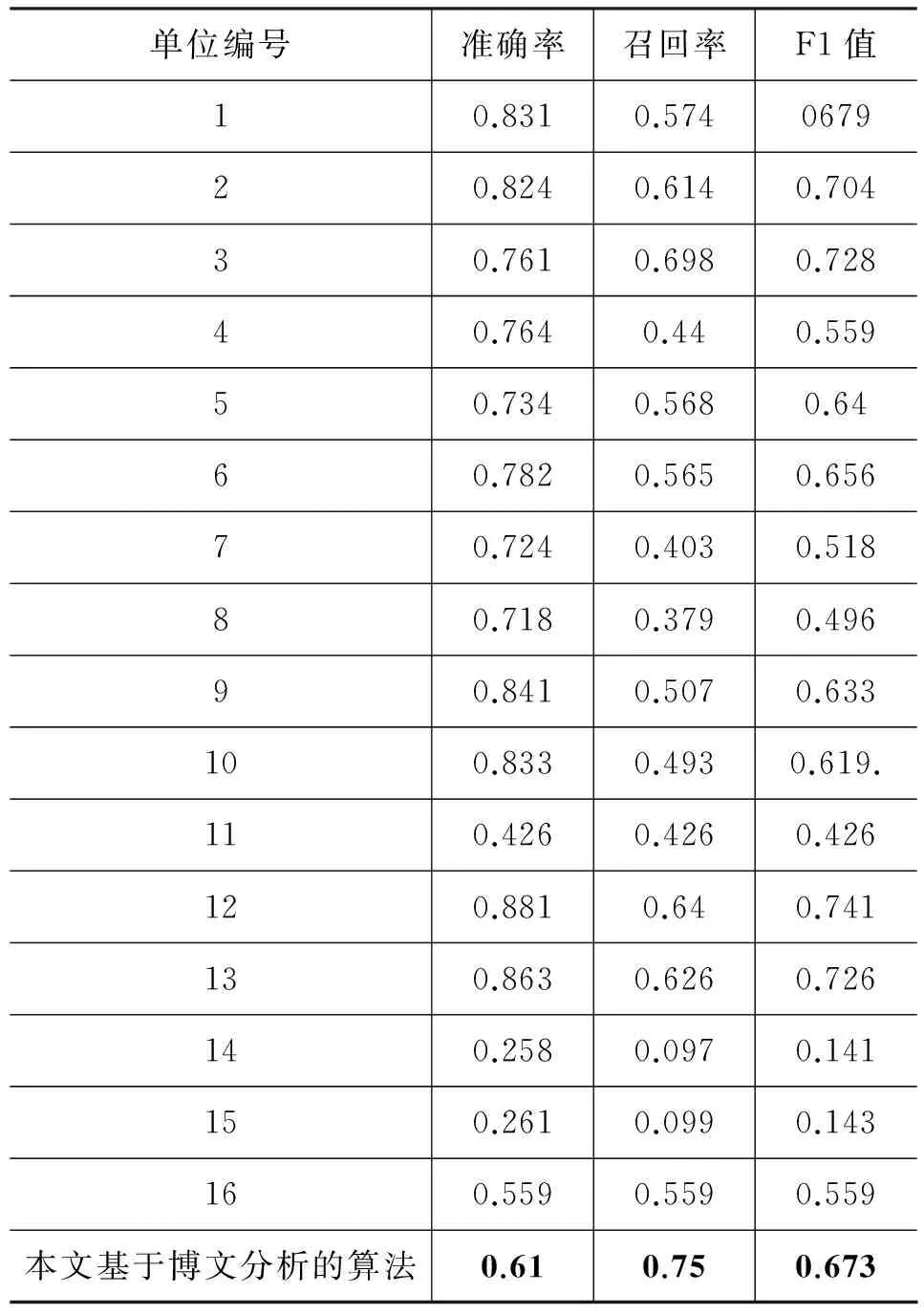
為了測試算法在其他公開微博評測語料上的準確性,驗證其擴展性,采用中國計算機學會中文信息技術專業委員會發布的2012年CCF自然語言處理與中文計算會議上(NLP&CC 2012)的微博博主對自己所使用的ipad的評價測試語料[19]。表4是上述會議中編號1-16單位情感判定的評測結果,最后一行是本文提出方法對微博語料的測試結果,情感詞權重計算標準差σ=1.2,情感對象計算影響因子函數Y=2x。采用的情感詞典是從中國計算機學會自然語言處理與中文計算會議上相關微博語料中統計情感詞獲得的情感詞典(含負向詞匯57個,正向詞匯85個)。
表4 NLP&CC2012中部分單位及本文基于博文的情感判定評測結果比較
單位編號準確率召回率F1值10.8310.574067920.8240.6140.70430.7610.6980.72840.7640.440.55950.7340.5680.6460.7820.5650.65670.7240.4030.51880.7180.3790.49690.8410.5070.633100.8330.4930.619.110.4260.4260.426120.8810.640.741130.8630.6260.726140.2580.0970.141150.2610.0990.143160.5590.5590.559本文基于博文分析的算法0.610.750.673
由于NLP&CC2012評測數據是未加任何修飾的真實微博語料,句式更加復雜,博文中的口語化內容較多,博文經常省略前文提到的內容或采用指代方式,且博文中也存在一些網絡新詞匯,所以使得分詞及詞性標注效果相應有所下降,從而對最終的情感判定效果產生一定程度的影響;另外,由于使用的詞典詞匯量小,而本算法受詞典影響較大,詞典中詞匯越準確,最終的分析效果也會越好,說明本文算法有一定的可行性和實用價值。
4.1.5 存在的不足和下一步的研究計劃
隨著情感詞典的不斷完善,情感詞的情感度越來越準,說明利用情感句中各屬性及其情感權重建立模型的方法是可行的,但情感判定結果還有待進一步提高,原因有:1)某些情感詞對不同的情感評價對象所表達的情感傾向有可能是相反的,如博文“酒店的性價比高,硬件設施比過去更加改善。滿意”,以及博文“房間小,價格還高,以后再也不住這家酒店了”,兩句中同時出現了情感詞“高”,但表達的意思卻截然相反;2)某些詞本身不具有情感傾向,但當用來修飾特定對象時,可能會賦予一定的情感,反之亦然,如博文“房間叫餐好,方便,味道足,量足,價格平民”,這里“平民”本身不具情感傾向,但它卻表達了一種肯定的正向傾向;又如“蘋果的價太高了”句中用“高”來表達負向語氣,但詞典中“高”往往表示正向語氣,由此可能產生語義偏差;而與此相反,某些詞本身具有情感傾向,但當和其他詞結合后卻不再擁有情感傾向性,如博文“我在2月23日定了鄭州大酒店的豪華單人間”,這里的“豪華”已沒有了情感傾向;3)有些本身并不具有情感傾向的詞在句中也可表達情感傾向,如博文“酒店在CBD中心,周圍沒什么店鋪,不知道為什么衛生間沒有電吹風”中并沒有出現情感詞,但博文卻表達了對酒店的不滿。如何處理上述問題,是下一步的研究內容。
4.2 基于博主個性化建模的情感傾向性實驗結果與性能評價
4.2.1 測試數據集及實驗結果
為驗證基于博主個性化建模分析算法的效果,以采集的微博語料庫為實驗數據集。由于該語料中不同博文數據中有可能是同一博主發布的情況,故去掉重復博主,實際得到博主數量為6 545,其中有正向情感的博主3 135個,有負向情感的博主3 410個。抓取去重后博主的個人信息及其所發表的所有博文信息,共得到全部博主的個人信息6 545條,博文數據1 538 073條。提取博主數據的主題詞的top-20作為該博主的特征詞表示(即主題詞抽取過程中,打分從高到低排序,取其排名前20的主題詞)。抽取的數據源分為兩部分,第一部分是用戶的基本信息抽取,因其相對較簡短且較有代表性,預設取其主題詞的top-5;第二部分是用戶的博文數據,其數據相對較多,取其主題詞的top-15。示例結果如表5所示。從表中可得,其主題詞提取結果基本符合人們對他們的定位。
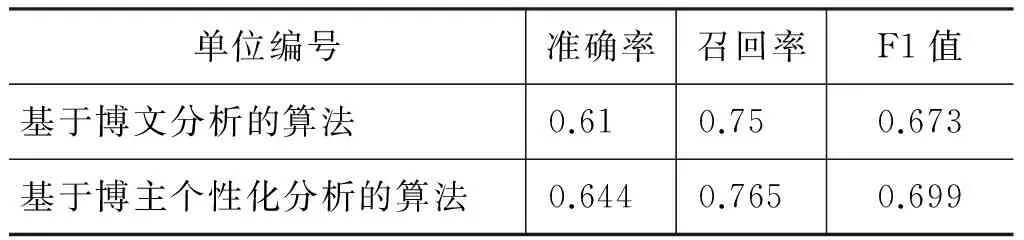
針對該方法在不含博主個性化信息的測試集上的性能見表5。為公平起見,同樣也采用中國計算機學會中文信息技術專業委員 會發 布的2012年CCF自然語言處理與中文計算會議上(NLP&CC 2012)的微博博主對自己所使用的ipad的評價測試語料[19]。由于評測語料沒有提供博主個性化等背景信息,因此本文提出的基于博主個性化建模方法和上文基于博文分析方法的性能差異不大。也就是說,在沒有博主個性化信息的情況下,該方法不能有效地發揮其作用。表6中評測數據出現差異的原因可能是由于在基于博主個性化分析的算法中,采用的博文預處理方法包括基于Double-Trie Tree的分詞、詞性標注、未登錄詞處理、數據清洗等;而在基于博文分析的算法中,預處理僅僅是完成了基本的數據清洗、正則匹配等。

表5 博主信息主題詞提取示例
表6 基于博文的情感判定評測結果與基于博主個性化的分析結果比較
單位編號準確率召回率F1值基于博文分析的算法 0.610.750.673基于博主個性化分析的算法0.6440.7650.699
為此,在前述的包含博主個人信息(6 545條)和博文數據(1 538 073條)的測試集上,我們針對擁有個性化背景信息的微博大V的情感傾向性進行了分析。首先,請不同專家對待測試的博文的情感傾向性進行了人工標注;之后,采用基于博主個性化建模的情感傾向性分析方法,得出實驗結果如表7所示(其中,人工標注統計結果是選擇了不同專家人工標注的結果)。
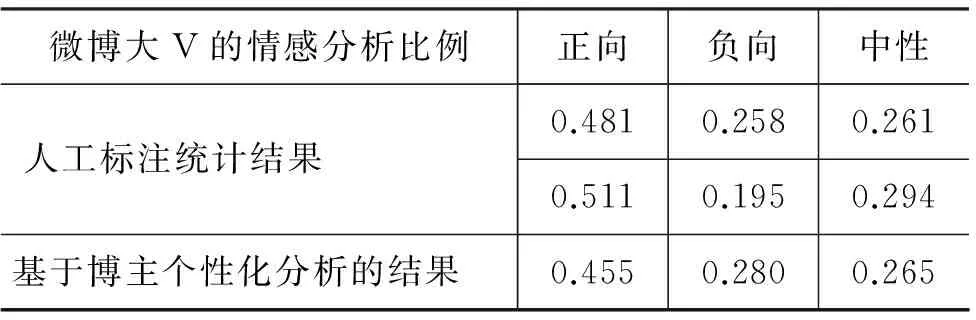
表7 基于博主個性化的情感傾向性分析結果比較
4.2.2 存在的不足和下一步的研究計劃
首先,本文提出的基于博主個性化建模的情感分析方法與某些人工標注結果是基本吻合的,這也說明應對結果進行置信度評估,通過設置正負傾向性的置信度閾值,對獨立計算的情感傾向性進行極性糾正。如何確定博主總體情感傾向性概率分布、博文對應的上下文之間的情感傾向性概率分布、動態調整權重方法等,是下一步的研究計劃。
其次,在不同的語境下,同樣的詞可能有不同的含義或情感色彩。而真實語境中少部分詞匯的情感傾向會受到其修飾的情感對象的影響——有些詞本身帶有情感傾向,但與情感對象結合后,并沒有表現出情感傾向;而有些詞本身沒有情感傾向,但與情感對象結合后卻表現出了情感傾向;甚至還有的情感傾向不確定,與不同的情感對象結合會有不同的情感傾向。如何解決上述問題以及反諷、褒義貶用、貶義褒用等也是下一步的研究內容。對于反諷的識別,擬根據評論內容,計算該用戶是否為廣告用戶、槍手等異常用戶,計算包括該用戶的相似用戶群體對該評論對象的總體評價、該評論對象的總體評價等,以便做進一步的判斷。
5 結論
本文給出基于情感單元和評價對象分析的短文本情感挖掘與分類算法,通過計算情感句對情感評價對象的情感傾向和情感權重,完成情感計算。通過情感單元抽取、情感評價對象抽取、情感詞情感權重、博主個性化建模分析,給出了情感分析算法,實現了微博情感分類及檢索系統。結果表明算法具有一定可行性和實用價值。同時,也對可能存在的問題及下一步的研究計劃進行了說明。
[1] Brendan O C, Ramnath B, Bryan R R, et al. From Tweets to Polls: Linking Text Sentiment to Public Opinion Time Series[C]//Proceedings of the 4th International AAAI Conference on Weblogs and Social Media, USA, 2010:122-129.
[2] 趙妍妍, 秦兵, 車萬翔, 等. 基于句法路徑的情感評價單元識別[J].軟件學報, 2011, 22(5): 887-898.
[3] Sachan M, Contractor D, Faruquie T A, et al. Using Content and Interactions for Discovering Communities in Social Networks[C]//Proceedings of the International Conference on World Wide Web, France, 2012: 331-340.
[4] 趙妍妍, 秦兵, 劉挺. 文本情感分析[J], 軟件學報.2010, 21(8):1834-1848.
[5] 楊超, 馮時, 王大玲, 等. 基于情感詞典擴展技術的網絡輿情傾向性分析[J]. 小型微型計算機系統, 2010, 31(4):691-695.
[6] Qiu G, Liu B, Bu J, et al. Expanding Domain Sentiment Lexicon through Double Propagation[C]//Proceedings of the 21st International Joint Conference on Artificial Intelligence(IJCAI2009), USA, 2009:1199-1204.
[7] Jakob N, Gurevych I. Extracting Opinion Targets in a Single- and Cross-Domain Setting with Conditional Random Fields[C]//Proceedings of the 2010 Conference on Empirical Methods in Natural Language Processing(EMNLP2010), 2010: 1035-1045.
[8] 李壽山, 李逸薇, 黃居仁, 等. 基于雙語信息和標簽傳播算法的中文情感詞典構建方法[J]. 中文信息學報, 2013, 27(6):75-81.
[9] 顧正甲, 姚天昉. 評價對象及其傾向性的抽取和判別[J]. 中文信息學報, 2012, 26(4): 91-97.
[10] Tan S B, Cheng X Q, Wang Y F, et al. Adapting Naive Bayes to Domain Adaptation for Sentiment Analysis[C]//Proceedings of the European Conference on Information Retrieval, France, 2009: 337-349.
[11] 林政, 譚松波, 程學旗. 基于情感關鍵句抽取的情感分類研究[J]. 計算機研究與發展, 2012, 49(11): 2376-2382.
[12] 馮時, 付永陳, 陽峰, 等. 基于依存句法的博文情感傾向分析研究[J]. 計算機研究與發展, 2012, 49(11): 2395-2406.
[13] 樊娜, 蔡皖東, 趙煜. 基于混合模型的文本主題情感分析方法[J].華中科技大學學報(自然科學版), 2010, 38(1): 31-34.
[14] 楊江, 侯敏, 王寧. 基于淺層篇章結構的評論文傾向性分析[J]. 中文信息學報, 2011, 25(2):83-87.
[15] 蘇艷, 居勝峰, 王中卿, 等. 基于隨機特征子空間的半監督情感分類方法研究[J]. 中文信息學報, 2012, 26(4):85-90.
[16] Tan C, Lee L, Tang J. User-Level Sentiment Analysis Incorporating Social Networks[C]//Proceedings of the 17th ACM SIGKDD international conference on Knowledge discovery and data mining, USA, 2011:1397-1405.
[17] Jiang L, Yu M, Zhou M, et al. Target-dependent Twitter Sentiment Classification[C]//Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics, USA, 2011: 151-160.
[18] 中文情感挖掘語料[OL], http://www.datatang.com/data/14617, 2013.
[19] 中國計算機學會自然語言處理與中文計算會議. 中文情感分析及詞匯語義關系抽取評測數據[OL],http://tcci.ccf.org.cn/conference/2012/pages/page04_evares.html, 2012.

高凱(1968—),博士,副教授,主要研究領域為大數據搜索與挖掘、自然語言處理、網絡信息檢索、社會計算等。E-mail:gaokai@hebust.edu.cn李思雨(1990—),碩士研究生,主要研究領域為自然語言處理、情感計算。E-mail:l_sy1111@126.com阮冬茹(1967—),碩士,副教授,主要研究領域為自然語言處理、大數據挖掘及信息安全。E-mail:ruandr@hebust.edu.cn
第十屆中國中文信息學會暑期學校在北京大學成功舉辦
2015年7月24日至25日,第十屆中國中文信息學會暑期學校在北京大學成功舉辦。自2005年以來,語言技術暑期學校已成功舉辦九屆,是國內語言信息處理領域最為重要的學術活動之一。歷屆暑期學校獲得了廣大師生的普遍好評,為自然語言技術的人才培養和技術推廣做出了卓越貢獻,數以千計的學子在暑期學校中獲得了來自國內外著名高校和科研機構的知名學者的當面指導,受益匪淺。
本屆2015年度暑期學校由北京大學計算語言學研究所承辦。此次暑期學校的特邀講師均是在機器學習、自然語言處理領域有著較高知名度的華裔學者。其中,24日上午,來自美國布蘭迪斯大學的薛念文教授講解了語言學研究中語義分析方面的基本方法和算法;24日下午,來自德克薩斯大學達拉斯分校的Vincent Ng教授介紹了指代消解的相關技術成果;25日上午,中國科學院信息工程研究所王斌研究員針對信息檢索相關技術做了詳細講解并介紹了其團隊針對傳統方法的一些改進;25日下午,在微博圈中享有很高人氣的來自卡內基梅隆大學的王威廉博士梳理了信息抽取領域基礎算法,并分享了自己團隊的最新技術和成果。25日晚上,由來自諾特丹大學的蔣偉教授,介紹了機器翻譯的相關技術和成果,并針對具體問題進行了現場答疑。最后北京大學計算語言學研究所所長王厚峰教授做了簡單總結和回顧。
中國中文信息學會秘書長,中國科學院軟件研究所孫樂研究員,中國科學院自動化研究所宗成慶研究員,計算語言學教育部重點實驗室主任穗志芳教授等國內知名專家出席了暑期學校并致辭。來自全國各地高校,研究所和企業的300多名研究生、教師和研究人員參加了此次為期兩天的暑期學校,學員規模為歷屆之最。
本屆暑期學校的成功舉辦,不僅讓大家對自然語言處理及相關技術有了更深入的認識,而且通過交流讓大家對自然語言處理技術的發展前景更加充滿信心,大家都非常珍惜這次難得的學習機會,紛紛表示希望以后還有更多的學習交流機會。
A Micro-blog Sentiment Analysis Approach
GAO Kai, LI Siyu, RUAN Dongru, LIU Shaobo, ZHOU Erliang, QIAO Shiquan
(School of Information Science & Engineering, Hebei University of Science and Technology, Shijiazhuang, Hebei 050018, China)
The social network has become an effective platform to mine the society and public opinions. This paper proposes a sentiment analysis approach based on sentiment unit and opinion target. The extraction of sentiment unit and sentiment evaluation object is based on the co-occurrence probability. This paper also calculates sentiment degree of the sentiment unit. Experimental results validate the feasibility of the approach.
social network; short-text mining; sentiment unit; opinion target
1003-0077(2015)04-0040-10
2013-09-12 定稿日期: 2014-05-19
河北省社會科學發展研究課題(2015030344)
TP391
A
猜你喜歡
石油瀝青(2021年4期)2021-10-14 08:50:44
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
中國生殖健康(2020年5期)2021-01-18 02:59:48
北極光(2019年12期)2020-01-18 06:22:10
小太陽畫報(2019年10期)2019-11-04 02:57:59
電子制作(2018年18期)2018-11-14 01:48:24
中國生殖健康(2018年5期)2018-11-06 07:15:40
山東工業技術(2016年15期)2016-12-01 05:31:22
中國教育技術裝備(2015年19期)2015-03-01 02:43:07
俄羅斯問題研究(2012年1期)2012-03-25 09:54:51
