基于層疊CRF模型的詞結構分析
2015-04-21 08:17:22周國棟
中文信息學報 2015年4期
方 艷,周國棟
(蘇州大學 自然語言處理實驗室,江蘇 蘇州 215006;蘇州大學 計算機科學與技術學院,江蘇 蘇州 215006)
?
基于層疊CRF模型的詞結構分析
方 艷,周國棟
(蘇州大學 自然語言處理實驗室,江蘇 蘇州 215006;蘇州大學 計算機科學與技術學院,江蘇 蘇州 215006)
傳統的中文分詞就是識別出每個詞的邊界,它忽略了漢語中詞與短語分界不清這一特點。在理論上,語言學家對詞邊界的確定往往各持己見,各語料庫的分詞標準不能統一,在實踐中也不能完全滿足具體應用的需求。該文給出了基于層疊CRF模型的詞結構自動分析方法,能夠以較高的精確度獲得詞的邊界信息和內部結構信息。相比于傳統的分詞,詞的結構分析更加符合漢語詞法與句法邊界模糊的事實,解決了語料庫標準的不一致性以及應用的不同需求。
中文分詞;內部結構;分詞標準;層疊CRF
1 引言
中文分詞是中文自然語言處理中最基本的一個步驟,其出發點是希望漢語的后續處理過程(如句法和語義分析)跟英語等西方語言基本一致,但漢語中詞與短語間的界限往往難以劃清,這就導致實踐中人工標注的分詞語料存在嚴重的不一致性,這種不一致性無疑會制約漢語的后續處理工作。
分詞語料的不一致性不僅體現在不同語料庫間分詞標準不同,而且同一語料庫中的分詞標準也不一致。其主要原因是從認知角度來看“詞”的概念本身就是模糊的,因而不同的人對“詞”的概念有著不同的理解。例如,在PKU語料庫中,“總教練”被切分為“總”和“教練”兩個詞,而“總書記”卻是一個詞。但是,“總教練”和“總書記”都有相同的結構,即前綴“總”加名詞構成,它們可以表示成具有內部結構的標注形式: “[總 書記]”和“[總 教練]”。這種結構上的標注比起線性分割的詞串,不僅容易取得一致性,而且能夠更加適應漢語詞法及句法之間界限模糊的特點。
另一方面,不同的自然語言處理應用對詞的粒度大小也有不同的需求,單一的分詞標準難以滿足各種要求。例如,機器翻譯通常偏好細粒度的詞語,而信息抽取等應用則需要粗粒度的詞語切分。以人名“江澤民”為例,在機器翻譯中,需要將人名切分為姓和名以便分別翻譯;而在信息抽取中則關注整個人名。如果我們能給出人名的內部結構標注“[江 澤民]”,那么不同的自然語言處理應用系統都可以從中提取所需粒度的語言單位。
由此可見,要解決分詞標準的不一致性以及應用的不同需求,一個有效的方法就是分析詞的內部結構。對詞進行結構分析是一種與傳統分詞(加空格)不同的詞法分析選擇,它更加符合漢語詞法及句法邊界模糊的事實,有利于發揮詞法分析在實際應用中的作用。因此,本文提出了詞內部結構的自動分析方法。該方法對于無結構的詞,如“華盛頓”、“葡萄”等,其輸出等同于傳統的分詞輸出,而對于有結構的詞,輸出的結果中不僅有詞的邊界信息,還包含詞的內部結構信息。
本文第二部分簡要介紹詞內部結構研究的相關工作;第三部分是任務定義;第四部分介紹語料的標注工作;第五部分詳細描述基于層疊條件隨機場(CRF)模型的詞結構分析方法;第六部分對實驗結果進行分析與比較;最后是本文的總結與展望。
2 相關研究
目前,自動分析詞結構的相關研究較為匱乏,人們對分詞的概念還只是停留在識別出詞的邊界,不過,也有許多研究者已經意識到當前分詞研究中存在的不足之處。Zhao[1]指出直到bakeoff-4為止,共有七種中文分詞標準。分詞作為中文語言處理最基礎和關鍵的步驟,如果沒有統一的標準,那必將影響其后續處理。Dong等[2]指出目前中文分詞的結果雖然已經很好,但其在實際應用中的作用卻沒有大的突破,一個原因是不同的自然語言處理應用對分詞的要求各不相同,因此需要改變傳統的分詞策略。
針對分詞研究中存在的問題,許多研究者提出了一些后處理方法來解決分詞標準的不一致性以及各種應用的不同需求。Wu[3]認為中文分詞不存在統一的標準來滿足所有的語言學家和各種應用的需求,因此,他通過輸出粒度可調的結果來滿足不同的應用需要。Gao等[4]認為中文分詞的有用性關鍵在于它能適應不同領域的文本以及不同分詞標準的能力,并給出了基于轉換的方法使特定領域的分詞系統能夠適應其它不同的領域。Jiang等[5]針對不同語料庫間分詞標準的不同,提出了基于錯誤驅動的方法來自動轉換不同標準間的語料庫。孟凡東等[6]在Jiang的基礎上進行異種語料的融合研究。他們都試圖把各個不同標準的語料庫轉換成同一標準,從而減少人工標注的工作量,但是這些工作都屬于識別詞邊界框架內的純工程性質的研究,并且通過后處理來自動轉換分詞標準,不僅轉換難度比較大,還不能保證足夠精度。
針對目前的分詞規范在理論上和實際運用中的不足,Li[7]提出了漢語詞法與句法統一分析的方法,把詞結構的分析融入到普通的成分句法分析中,即在進行句法分析的同時也分析出詞的內部結構。在賓州樹庫上的實驗表明,該方法能有效進行詞內部結構的分析,標準分詞的性能達到了97.3%,且句法分析的總體性能也相當好。不過,過高的時間復雜度和空間復雜度使句法分析并不適合于處理大規模的文本,且在某些情況下不需要用到頂層的句法結構。為此,本文將分詞和詞結構分析作為一個單獨的任務,提出了基于層疊CRF模型的分詞與詞結構的一體化識別方法,克服了句法分析的復雜性,有效提高了分析效率。
3 任務定義
本文分析的含結構的詞并非所有的復合詞,因為從自然語言處理角度來看,有些復合詞的結構并不需要分析,例如,“研究”雖為復合詞,但自然語言處理應用系統一般不需要對其內部結構進行分析。本文所指的有結構的詞界定如下。
1. 詞中包含中心成分,并且該結構具有能產性*能產性指由某種規則能產生大量新詞,也可指某語言單位能產生大量更大的單位,但本文中的能產性更偏向于后者。。例如,“工程師”,其中的“師”為中心成分,并且“師”字是能產的。
2. 具有中心成分但不滿足能產性的情形,如果該中心成分對應的所有詞構成平行的語義類別,則也作為有結構的詞。例如,“洋”字嚴格意義上不算能產,但由它派生的詞(如: 太平洋、北冰洋、大西洋、印度洋)在本文也分析了它們的結構,因為分析其結構可以緩解句法分析時中心詞面臨的稀疏問題。
3. 不具有中心成分的“離心結構”,如果具有能產性并且產生的詞句法功能一致,也是本文所指的有結構的詞。例如,“反革命”中的兩個成分“反”和“革命”都不是整個詞的中心成分,但由于“反+名詞”這種結構具有能產性(反貪,反帝,反華,反浪費,反盜版等),本文仍將其作為有結構的詞。
4. 漢語的人名是一類特殊的含結構的詞,每個人名都包含姓與名,故本文對漢語人名的結構也作了分析。
本文將詞結構(除人名外)中能產的部分(以及第二種情況下的中心成分)稱為前綴或后綴(不同于語言學上的前后綴)。本文的前后綴不僅限于單個漢字,也可能是多個漢字,例如,主義,階級。詞的結構可能是一層,也有可能是多層的,如 “總工程師”具有兩層結構(圖1),本文用方括號表明了詞的內部結構,一層括號表示一層詞的結構,即圖1的結構表示為“[總 [工程 師]]”。表1列出了具有不同形式的詞結構,從中可以看出,漢語中詞的內部結構紛繁復雜。
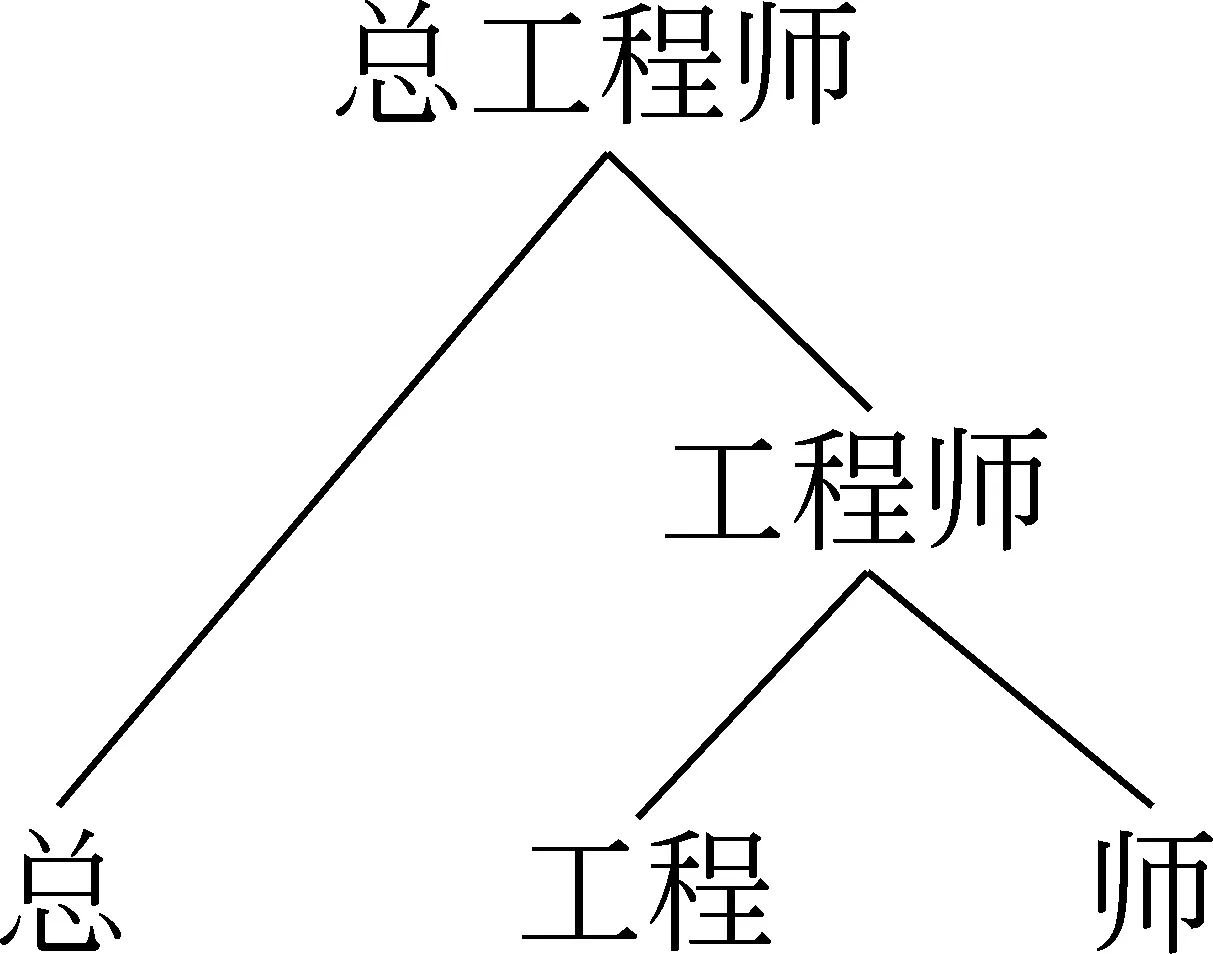
圖1 “總工程師”的結構
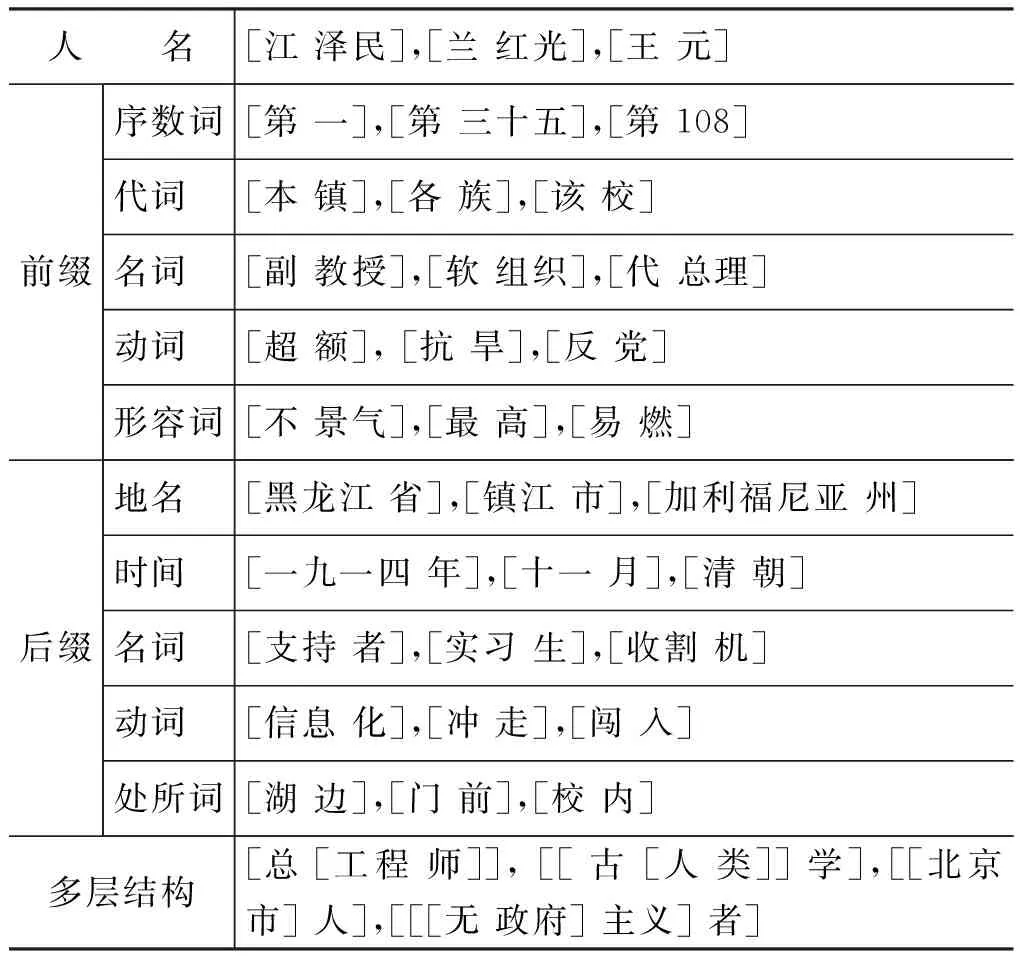
人 名[江澤民],[蘭紅光],[王元]前綴序數詞[第一],[第三十五],[第108]代詞[本鎮],[各族],[該校]名詞[副教授],[軟組織],[代總理]動詞[超額],[抗旱],[反黨]形容詞[不景氣],[最高],[易燃]后綴地名[黑龍江省],[鎮江市],[加利福尼亞州]時間[一九一四年],[十一月],[清朝]名詞[支持者],[實習生],[收割機]動詞[信息化],[沖走],[闖入]處所詞[湖邊],[門前],[校內]多層結構[總[工程師]],[[古[人類]]學],[[北京市]人],[[[無政府]主義]者]
本文中詞結構自動分析的任務不僅(以空格)分隔出一個句子中的詞,而且給出詞的內部結構,并且這種結構可能是嵌套的。如在下列句子中:
1. 林志浩是總工程師
2. 林志浩 是 總工程師
3. 林 志浩 是 總 工程師
4. [林 志浩] 是 [總 [工程 師]]
其中句1是未經分詞的原始句子,句2和句3是兩種不同的分詞結果。顯然,就分詞的顆粒度而言,句2和句3是不同的。句4是本文的詞結構分析所要輸出的結果,它不僅包含了各種可能的分詞情況,而且用方括號表明了詞的內部結構,由此可見,詞結構分析符合了漢語中詞與短語界限不清的特點,并且該種詞法分析可以很好地兼容不同的分詞標準,不同的應用可以根據需要提取不同粒度的詞,克服了目前分詞中所存在的問題。
4 語料標注
為了便于語料的共享及降低標注成本,本文采用PKU1998年1月《人民日報》作為語料的來源。PKU只考慮了詞的邊界信息,因此需要對其再進行人工處理。其基本思路是對所有含前綴或后綴的復合詞重新進行人工標注。
雖然漢語中詞的內部結構紛繁復雜,幸運的是,一個詞是否具有內部結構一般不依賴于上下文,因此在標注的時候每個詞只需要標注一次,而不需要在不同的上下文中單獨標注,這大大減輕了標注的工作量。標注的過程分為四步。
1. 提取漢語人名: 漢語的人名作為一類特殊的含結構的詞需另外處理。從帶有詞性標記的語料中提取所有漢語人名,標注它們的結構信息。
2. 提取前后綴: 首先提取語料中所有出現過的詞,然后將長度大于或等于兩個漢字的詞分別按照每個詞中的第一個漢字和最后一個漢字進行歸類,根據有結構詞的定界從每一類中提取前綴或后綴。
3. 提取未被切分的結構: 在確定了前后綴集合之后,逐一檢查語料中所有由前綴和后綴派生出來的復合詞,標注它們的結構信息。
4. 提取被切分的結構: 把語料中所有獨立成詞的前后綴連同其上下文(前后各三個詞)一起提取出來,逐一人工檢查,重新標注所需的結構信息。這樣做的目的是語料庫中存在著前綴或后綴獨立成詞的情況,例如,在PKU語料中“總教練”已經被分成兩個詞“總”和“教練”, 但是“總書記”卻是一個詞。
經過上述標注之后,統計表明語料中所有出現過的詞共有55 303個,提取的前綴有114個,后綴503個,含有結構的詞占總詞數的56.8%。表2列出了語料庫中按結構層次劃分的詞結構的統計情況,由表2可知,含有結構的詞中約88%只有一層結構,三層及以上結構的詞非常少。另外,人名中的兩層結構指漢語中妻子姓名前加丈夫姓的情況,如“陳方安生”的結構“[[陳 [方 安生]]”。
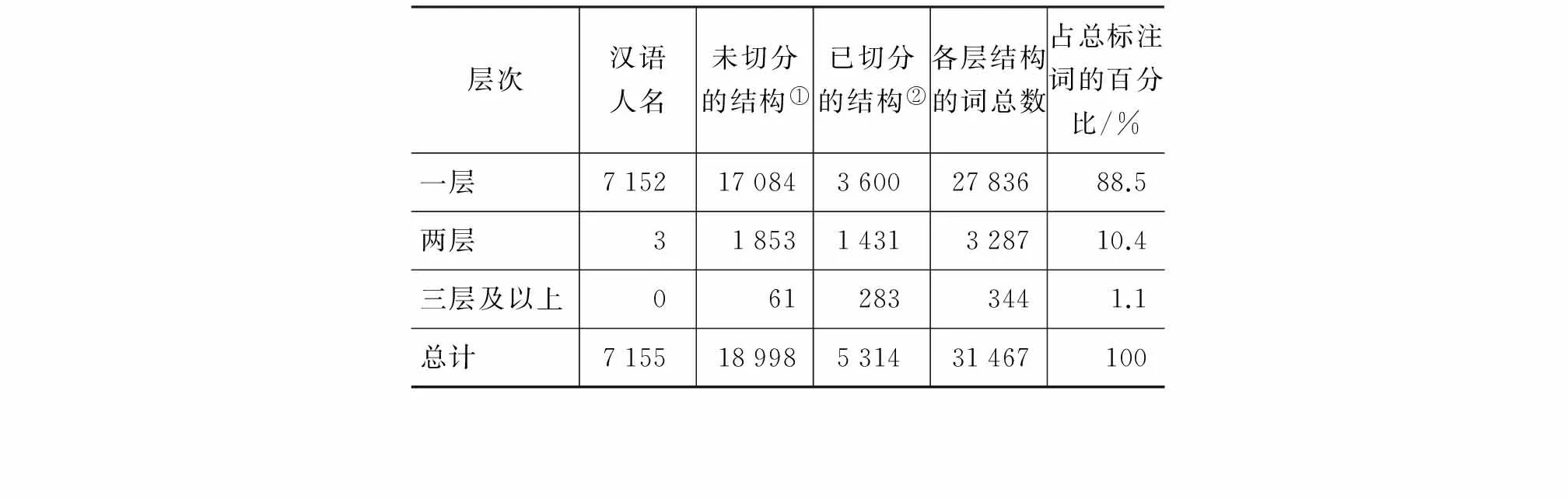
表2 各層次結構詞的個數
①未切分的結構指原PKU語料中作為一個詞單獨出現,但在本文中需分析其結構的詞,即標注過程中第三步提取的詞。
②已切分的結構指原PKU語料中作為多個詞出現,但在本文中需將其作為一個整體,并給出結構。這類詞即標注過程中第四步提取的詞。
5 基于層疊CRF模型的詞結構分析
作為解決序列標注問題的有效方法,CRF模型在自然語言處理的各個領域都得到了廣泛的應用,在分詞方面也取得了較好的性能[8]。由于詞結構的嵌套性,單一的CRF模型顯然無法滿足詞結構分析的需求,因此本文提出了基于層疊CRF模型的詞結構分析方法,其整體框架如圖2所示。整個系統包含訓練和測試兩個部分,采用兩個子模型,即底層模型和高層模型分別實現細粒度分詞和詞結構分析。訓練時,通過提取不同的特征產生兩個不同的CRF模型;而測試時,底層模型首先對未切分的漢字序列進行細粒度分詞,然后,高層模型將細粒度分詞后的序列進行逐層次的結構分析,一次結構分析得出一層詞的結構,直到所有的結構都被識別出來為止。
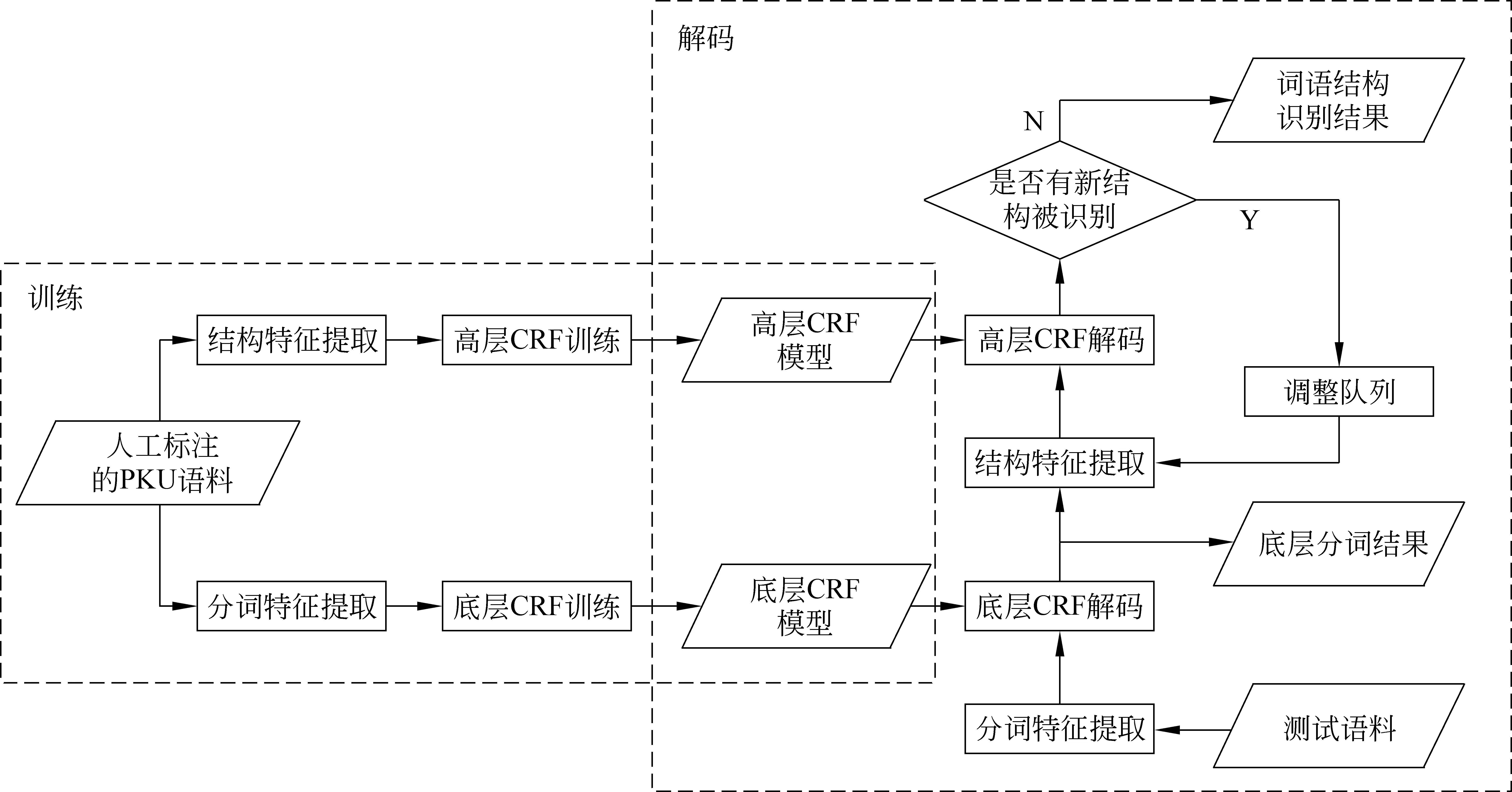
圖2 基于層疊CRF模型的詞結構分析流程圖
5.1 底層模型: 細粒度分詞
在識別詞的內部結構之前,首先需要對語料進行細粒度分詞。細粒度分詞是一個標準的分詞過程,只不過其中所有詞的前后綴都作為一個單獨的詞。CRF模型能夠很好地解決分詞的序列化標注問題,本文采用的標記集為{B、M、E、S},分別表示詞首、詞中、詞尾和單獨成詞。由于人工標注的語料存在詞的結構信息,它們對細粒度分詞是沒有意義的,因此在提取分詞特征時,首先要去除這些結構信息,也就是將所有的前后綴都獨立成詞。
表3是底層CRF模型所用的分詞特征模板,其中Unigram是一元字符特征;Bigram(即二元特征)是相鄰兩個字符相結合產生的特征;Trigram(即三元特征)是當前字符與前后相鄰的兩個字符結合所
產生的特征。在該模板中,C0指當前字符,C-1指當前字符的前一個字符,C1指當前字符的下一個字符,以此類推。

表3 底層模型的分詞特征模板
在訓練之前,需對語料作預處理。具體方法是: 將訓練語料和測試語料中的四類不同字符分別替換成四個特殊字符,如將語料中所有的英文字母替換成‘A’,將阿拉伯數字替換成‘B’,將中文數字替換成‘C’,將標點符號替換成‘D’。然后用替換后的語料訓練CRF模型,當測試結束后,再把測試語料中被替換掉的字符還原成原來的字符。
5.2 高層模型: 結構分析
經細粒度分詞后的詞序列,繼續使用高層CRF模型來識別詞的結構。本文采用單一的高層模型,在結構識別時分層次調用該模型,一次分析識別一層詞的結構。結構的識別問題仍然作為一個序列化標注問題。此時,高層模型所使用的標記集合為{B,I,O},其中B表示一個結構的開始,I表示一個結構的中間,O表示結構之外(Tsuruoka等[9])。
高層模型的訓練需要提取原人工標注語料中的結構信息作為特征。對于一個人工標注語料中的句子,需分層次提取語料中的結構。如果句中詞結構的最高層次為N,那么該句需提取N次的結構特征,每次提取一層結構,最后將所有層次的特征加入到CRF訓練器中產生高層模型。以“[林 志浩] 是 [總 [工程 師]]”為例,由于“[總 [工程 師]]”的結構為兩層,且是該句中層次數最高的詞,因此需要提取訓練特征兩次。第一次提取特征的樣本為“[林 志浩] 是 總 [工程 師]”,第二次提取特征的樣本為“林志浩 是 [總 工程師]”。
與高層模型的訓練有所不同,應用高層CRF模型進行詞結構分析時,無法一次識別出所有層次的結構,而是一次分析過程只在當前層次的結構序列基礎上識別出上一層詞的結構。因此,每一次分析結束后,都將從當前的結構序列中重新提取新的結構特征進入下一次分析,如此反復,直到無法識別出新的結構為止,把最終識別出的結構作為詞結構分析的輸出。仍以漢字序列“林志浩是總工程師”為例,圖3給出了整個分析過程。圖3(a)所示的初始狀態是原語料進行細粒度分詞的結果,該狀態是結構分析的最底層。調用高層模型進行第一次結構分析后,識別出了兩個包含結構的詞,即“[林 志浩]”和“[工程 師]”,如圖3(b)所示。接下來再將這兩個包含結構的詞作為一個整體重新加入到序列中繼續進行結構分析。第二次結構分析后,模型分析器又識別出新的結構“[總 [工 程師]]”,如圖3(c)所示,再把這個結構作為一個整體加入到序列中進行分析。當輸出序列中已不存在新的結構時,分析結束。
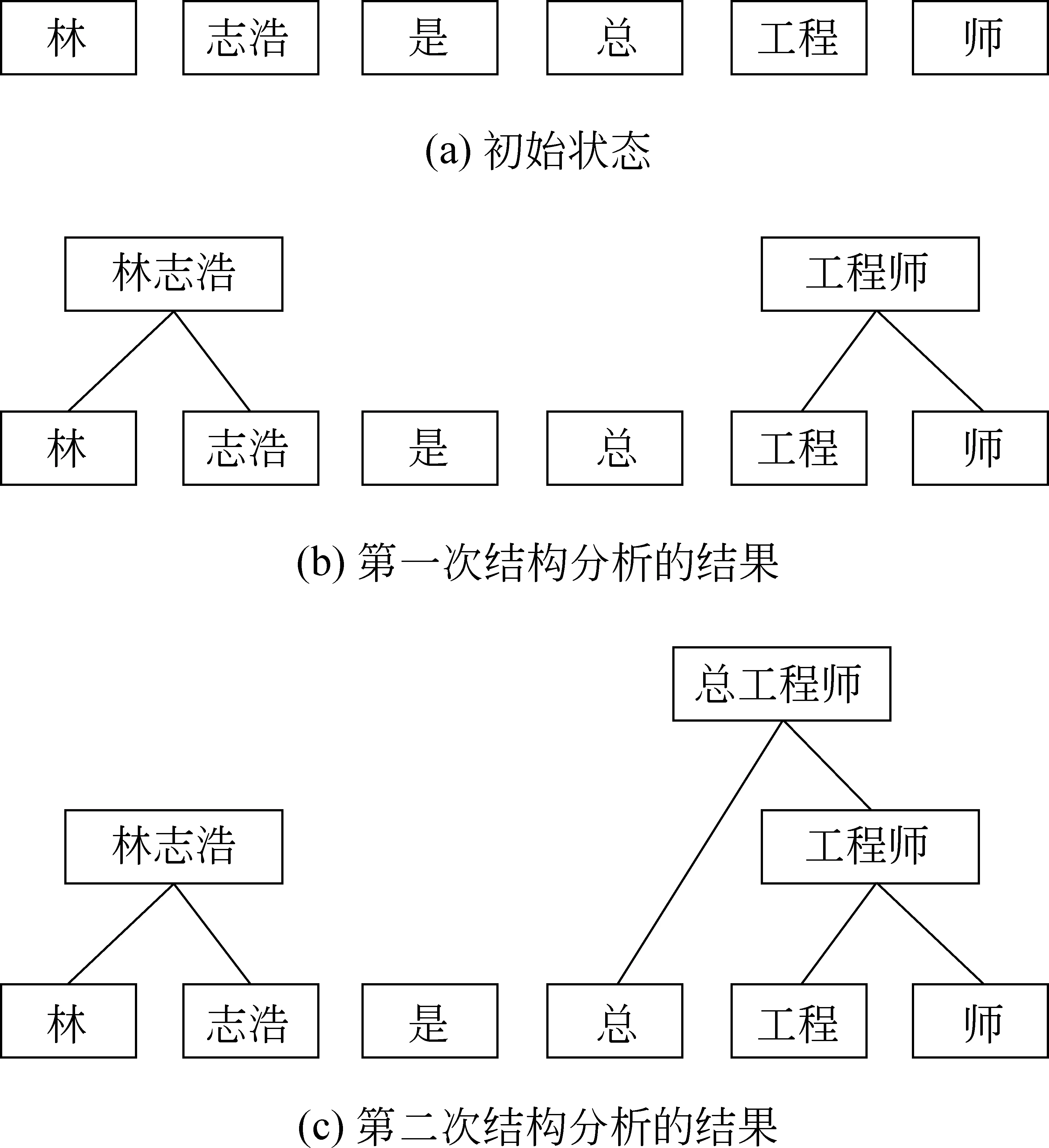
圖3 分析過程
表4是高層CRF模型在進行詞結構分析時所用的特征模板,它與底層模型的特征模板不同之處在于此時的特征單元是詞,而非字。具體而言Unigram是單個詞作為特征,Bigram是相鄰兩個詞結合產生的特征,Trigram是當前詞與前后相鄰的兩個詞結合產生的特征,W0指當前詞,W-1指當前詞的前一個詞,W1指當前詞的下一個詞,以此類推。

表4 高層模型的特征模板
另外,為了體現序列的結構性,高層模型加入了Daughter特征,表示一個包含結構的詞所擁有的子結點信息,其中D0、D1和D2分別表示它的子結點序列。例如“[總 [工程 師]]”這個結構的Daughter特征就是D0=總、D1=工程、D2=師。
6 實驗
本文實驗中將已標注的PKU語料分成兩部分,分別作為訓練語料和測試語料,其規模如表5所示。
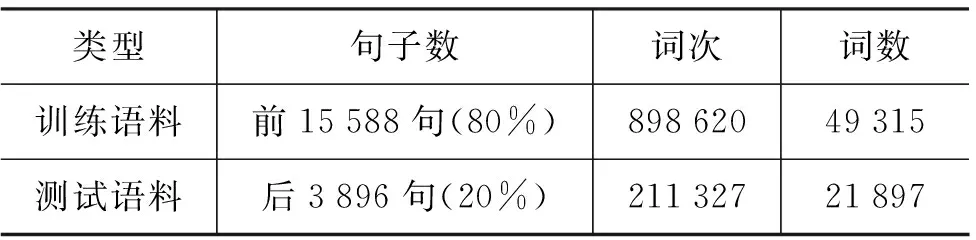
表5 訓練語料及測試語料的規模
6.1 評測標準
目前,還沒有在PKU語料上進行詞內部結構分析的相關研究,因此沒有一個基準系統可以參考。本文采用的評測方法借鑒了句法分析的評測方法PARSEEVAL[10],采用正確率,召回率和F-值作為評測的三個指標,計算公式分別如式(1)~(3)所示。
正確率(Precision)=
(1)
召回率(Recall)=
(2)
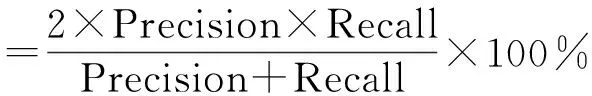
(3)
評測時,將分析結果中的所有節點表示成如下標記格式: X-(起始位置: 終止位置)。其中X可以是無結構的終節點,也可以有結構的非終節點;(起始位置: 終止位置)為該節點的跨越范圍。與句法分析評測不同的是,詞結構評測的對象不是一棵完整的樹,而是包含內部結構的分詞結果,并且沒有各種句法標記,其終節點與非終節點都是詞。
6.2 實驗結果及分析
本文首先進行細粒度分詞,再將分詞后的序列進行結構分析,因此分詞結果的好壞直接影響結構分析的最終結果。為了考察分詞對結構分析的影響,分別進行了自動分詞下和標準分詞下的詞結構分析實驗。
6.2.1 自動分詞下的性能
表6是進行自動分詞后再進行結構分析的實驗結果。其中,零層結構考察無結構的詞以及詞結構中的最底層的詞,即細粒度分詞的性能;一層結構考察含有一層結構的詞,由表2可知,大部分含結構的詞都屬于此類(約占88%),而兩層及以上層次結構較少(約占12%)。
從表6中可以看出,采用層疊CRF模型的詞結構分析方法取得了較好的總體性能,達到了實用水平,其中細粒度分詞的性能為94.7%。當然,隨著結構層數的增加,性能有所下降,特別是對于兩層及以上結構,性能F值大幅度下降。其主要原因有兩個方面: 一是高層結構的訓練數據較少,導致稀疏性問題;二是錯誤的傳遞性,底層結構的錯誤識別直接導致高層結構的錯誤識別。
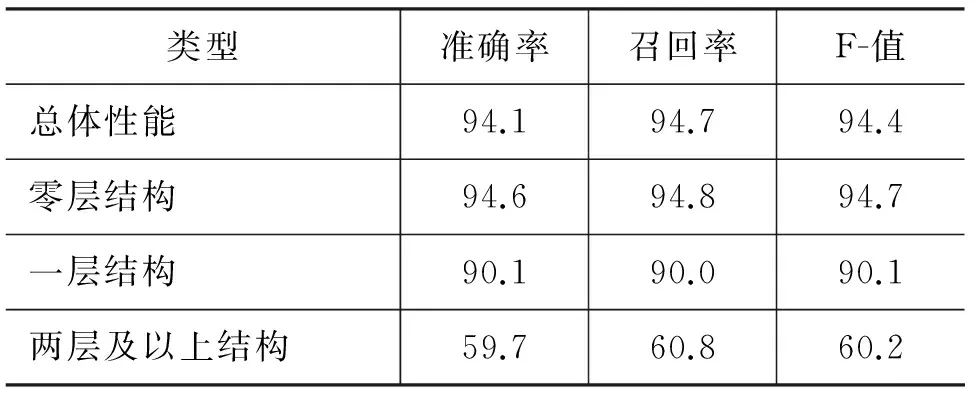
表6 自動分詞下的詞結構分析性能
通過對測試結果的分析,詞結構分析的錯誤除了詞邊界的錯誤識別外,還有許多結構的錯誤識別也是由于詞邊界的錯誤切分而產生的。例如,“新華文摘”錯誤切分為“新華 文 摘”,導致結構分析時識別為“[新華 文] 摘”;地名“石河子”錯誤切分為“石 河 子”,導致錯誤的分析結構“[[石 河] 子]”。
6.2.2 標準分詞下的性能
表7是在標準分詞的情況下進行結構分析的實驗結果。和表6中的數據相比,一層結構的F值提高了5.6,兩層及以上結構的F值也提高了6.4,這說明分詞的性能對詞結構的分析相當重要。另外,從表中可以看出,盡管兩層及以上層次結構詞的識別準確率還不到70%, 但由于在測試集中這類詞的出現次數較少,因此詞結構分析的總體性能相當高。
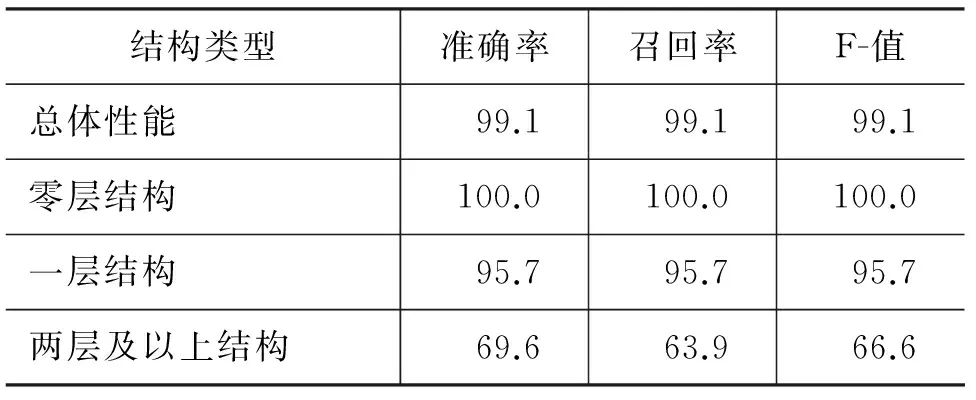
表7 標準分詞下的詞結構分析性能
通過對測試結果的錯誤分析發現,一些能產的前后綴容易生成錯誤的結構。例如,“志愿 者 進 社區”經結構分析后的結果為“[[志愿 者] 進] 社區”,“一 名 熱愛 海 的 看海 者”經結構分詞的結果為“一 名 [熱愛 海] 的 [看海 者]”。
6.2.3 與其他系統的比較
本文將Zhang等[11]基于字符的句法分析模型中的詞結構分析的結果與本文模型的結果做了比較,如表8所示。從表中可看出,我們的模型與Zhang的模型在詞結構分析的性能上基本相同。但Zhang采用的是字符級的詞結構,且所使用的語料庫領域及規模都與本文不同,故對結果的可比性有較大的制約。
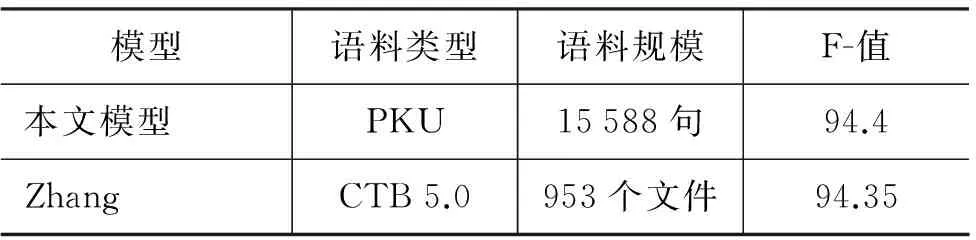
表8 本文模型與Zhang的對比
盡管沒有相同的研究可以直接比較,我們仍將細粒度分詞的性能同目前最好的系統進行了比較。表9列出這些系統所使用的語料類型,語料規模和性能等。當然,由于語料庫領域和規模不同,訓練集和測試集不同,這些比較僅供參考。
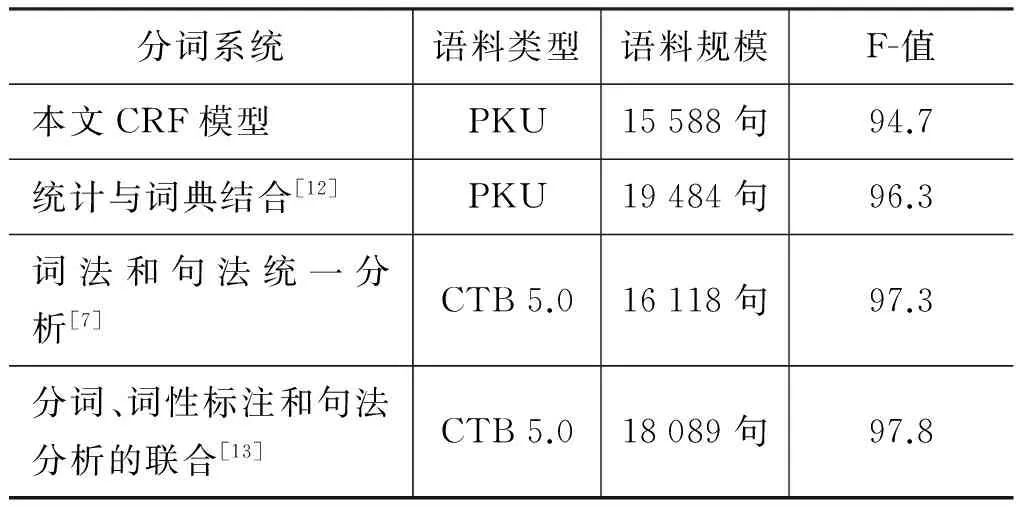
表9 不同分詞系統的性能比較
從表9中可以看出,本文的分詞性能雖然低于目前的最好成績(97%左右),但基本上是在同一水平上,且本文的重點在于探索有效的詞結構分析方法,如層疊CRF模型在PKU語料上的訓練時間約為40分鐘(處理器: Intel Pentium CPU;主頻: 2.20GHz;內存: 8G)。下一步要做的工作是如何進一步提高分詞性能從而提高詞結構分析的總體性能。
7 結語
詞與短語的界限往往難以分清,但這并不妨礙人們對語言的理解,同樣計算機也不必給詞與短語設定一個界限,只要能夠正確給出所有語言單位的結構,有利于后續應用系統的處理和使用即可。本文從漢語所固有的特點出發,對詞的內部結構進行了分析,給出了一種與傳統分詞不同的詞法分析選擇,它更加適應漢語詞法及句法分析階段的特點,同時解決了語料庫分詞標準的不一致性以及不同的應用需求。本文提出了基于層疊CRF模型的詞結構識別方法,該方法首先進行細粒度分詞,再將分詞后的序列進行分層結構分析。實驗結果表明,該方法取得了令人滿意的效果。接下來,我們將進一步探究高層模型和底層模型的特征設計,以及挖掘更多的語料知識來提高詞結構分析的總體性能。
[1] Hai Zhao. Character-level dependencies in Chinese: Usefulness and learning[C]//Proceedings of the 12th Conference of the European Chapter of the ACL(EACL 2009). 2009:879-887.
[2] Zhengdong Dong, Qiang Dong, Changling Hao. Word segmentation needs change-from a linguist’s view[C]//Proceedings of CIPS-SIGHAN Joint Conference on Chinese Language Processing. 2010:1-7.
[3] Andi Wu. Customizable segmentation of morphologically derived words in Chinese[C]//Computational Linguistics and Chinese language processing. 2003,8(1):1-27.
[4] Jianfeng Gao, Andi Wu, Mu Li Chang-Ning Huang, et al. Adaptive Chinese word segmentation[C]//Processings of the 42nd Annual Meeting on Association for Computational Linguistics. 2004:62-469.
[5] Wenbin Jiang, Liang Huang, Qun Liu. Automatic adaptation of annotation standards: Chinese word segmentation and POS tagging-a case study[C]//Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP. 2009: 522-530.
[6] 孟凡東, 徐金安, 姜文斌, 等. 異種語料融合方法: 基于統計的中文詞法分析應用[J]. 中文信息學報,2012, 26(2): 3-7.
[7] Zhongguo Li. Parsing the Internal Structure of Words: A new paradigm for Chinese word segmentation[C]//Proceedings of the 49th Annual Meeting of the Association of Computational Linguistics. 2011:1405-1414.
[8] Hai Zhao, Changning Huang, Mu Li. An improved Chinese word segmentation system with conditional random field[C]//Proceedings of the Fifth SIGHAN Workshop on Chinese Language Processing. 2006: 162-165.
[9] Yoshimasa Tsuruoka, Jun’ichi Tsujii, Sophia Ananiadou. Fast full parsing by linear_chain conditional random fields[C]//Proceedings of the 12th Conference of the European Chapter of the ACL. 2009:790-798.
[10] S Abney, S Flicknger, C Gdaniec, et al. Procedure for quantitatively comparing the syntactic coverage of English grammars [C]//Proceedings of the workshop on Speech and Natural Language, Association for Computational Linguistics. 1991: 306-311.
[11] Meishan Zhang, Yue Zhang, Wanxiang Che, et al. Chinese Parsing Exploiting Characters [C]//Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics. 2013:125-134.
[12] 張梅山,鄧知龍,車萬翔,等. 統計與字典相結合的領域自適應中文分詞[J]. 中文信息學報. 2012, 26(2): 8-12.
[13] Qian Xian, Yang Liu. Joint Chinese word segmentation, POS tagging and parsing[C]//Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning. Association for Computational Linguistics. 2012:501-511.
Word Structure Analysis Based on Cascaded CRFs
FANG Yan,ZHOU Guodong
(Natural Language Processing Lab, Soochow University, Suzhou, Jiangsu 215006, China;School of Computer Science & Technology, Soochow University, Suzhou, Jiangsu 215006, China)
Traditional research in Chinese word segmentation focuses on identifying word boundaries, without considering the ambiguity of boundaries between Chinese words and phrases. In theory, linguists stick to their own view of word boundaries such that no uniform standard exists in Chinese word segmentation, and in practice, the corpus of various guidelines cannot bring satisfactory reusltsto wide applications. In this paper, we present a model based on cascaded CRF models to automatically parse internal structures of words, deciding both word boundaries and internal structures simultaneously with high precision. Compared with the traditional word segmentation methods, analyzing the structure of words is more consistent with the fact of fuzzy boundaries between Chinese lexical and syntactic units, solving the problem of inconsistent corpus standards and meeting different application requirements.
Chinese word segmentation;internal structure;annotation standard;cascaded CRFs

方艷(1989—),碩士,主要研究領域為自然語言處理。E-mail:yfangyan@yeah.net周國棟(1967—),博士,教授,主要研究領域為自然語言處理、信息抽取。E-mail:gdzhou@suda.edu.cn
1003-0077(2015)04-0001-07
2013-08-20 定稿日期: 2013-10-30
自然科學基金青年項目(61202162),教育部博士點基金新教師類課題(20123201120011)
TP391
A
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
哲學評論(2021年2期)2021-08-22 01:53:34
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中華詩詞(2019年7期)2019-11-25 01:43:04
電子制作(2018年18期)2018-11-14 01:48:24
山東工業技術(2016年15期)2016-12-01 05:31:22
影視與戲劇評論(2016年0期)2016-11-23 05:26:01
光學精密工程(2016年6期)2016-11-07 09:07:19
