基于文本紋理特征的中文情感傾向性分類
2015-04-21 08:33:32許歆藝劉功申
中文信息學報 2015年3期
許歆藝,劉功申
(上海交通大學 信息安全工程學院, 上海 200240)
?
基于文本紋理特征的中文情感傾向性分類
許歆藝,劉功申
(上海交通大學 信息安全工程學院, 上海 200240)
隨著互聯網的發展,社交網絡、電子商務等已經成為人們關注的焦點,對社交網絡的文本進行情感傾向性分析和挖掘變得越來越重要。該文針對網絡上的中文文本,提出一種基于文本紋理特征的情感傾向性分類方法。通過測試多種文本紋理特征對文本情感傾向性的影響,成功將文本紋理特征融入情感分類中。通過計算各類特征與文本的情感傾向性的相關度,對特征進行降維。相對于基于詞頻的情感傾向性分類方法,查準率平均提高了10%左右。
中文文本分類;情感傾向性;文本紋理;SVM
1 引言
近年來,飛速發展的互聯網已經逐步成為了人們生活的一部分,網絡上的信息隨之急劇增長,互聯網已經成為人們發表觀點和評論的重要載體之一。網絡上的文章、評論直接地反映了網民的態度和見解,對大量文本的分析可以相當真實地反映民眾對于某一事物的態度,因此對網絡上的文本進行情感傾向性分析和挖掘正變得越來越重要。
在同一主題下,對這些網絡評論、文學作品進行挖掘和分析,識別出其中的情感傾向,對于電子商務、輿情監管等領域有著重要的意義和實用價值。文本傾向性分類正逐步成為自然語言研究領域的一個熱點方向。
上世紀90年代起,國外就開始了對詞匯傾向性的分析研究,Turney提出了一種通過一組基準詞計算詞語的情感傾向性的方法,達到了95%的準確率[1];Kim等人同樣將工作重點放在情感詞匯的傾向性分析上,在一對基準詞集的基礎上使用WordNet計算未知詞匯的情感傾向性[2]。隨著研究工作和實際應用領域的發展,對整篇文檔的觀點抽取和傾向性判斷成為研究工作的熱點,情感詞的上下文信息和語義搭配關系也逐漸被應用到語義傾向性計算當中。Wiebe等利用詞語的搭配關系進行文檔級別的觀點挖掘,將具有搭配關系的詞對作為特征,判斷整篇文檔的情感傾向性[3]。而在實際工作中,單詞的傾向性與短語的傾向性往往相反,Wilson和Wiebe等人在后期研究中著力研究了短語級情感傾向性,并對中立情感這一實際大量存在的文本進行研究[4]。在有領域針對性的文本傾向性分類方面,Melville給出一個統一的框架,可以使用不同背景知識生成模型結合傳統的分類工作,達到更精準的分類效果[5]。
在中文領域的研究中,文本情感傾向性主要的研究方法主要分為兩種,如朱嫣嵐等人利用HowNet提供的語義相似度和語義相關場計算功能對詞語的褒貶傾向度按一定計算法則進行賦值,并根據該值判別該詞語義傾向,并在后續工作中利用詞語傾向性進行計算文本傾向性[6];另一種方法把機器學習的文本分類方法應用于中文文本傾向性分類領域。通過采用不同的停用詞表、特征選取方法、特征加權方法進行比較實驗,并應用不同的分類算法進行分類尋取較好的分類效果。例如,代六玲[7]等人針對不同的特征選取方法的有效性,特別是組合的特征抽取方法進行了研究,縮短了分類精度和訓練時間。基于機器學習方法的情感自動分類方面,徐軍[8]等人還提出了詞語成對共現對表現不同情感的影響。目前已有多種標準算法可用于文本的學習與分類,例如,K最近鄰算法、樸素貝葉斯算法、支持向量機算法[9]。徐琳宏等人進一步考慮到語義理解,在處理詞語傾向性的基礎上添加了否定規則和程度副詞的識別,對褒貶的識別力度得到了進一步加強[10]。
本文的研究工作采用機器學習的方法,識別包括句式、修辭、詞語間依賴關系等在內的文本紋理,以情感詞匯、評價詞匯、語氣詞以及部分文本紋理為基礎特征,并根據所識別的文本紋理調整基礎特征的權重,并且通過對所有特征與褒貶文本的相關性檢測對特征進行降維, 達到了更高的準確度以及更快的分類速度。
2 文本傾向性分類
現存的傳統的文本情感傾向性分類大多是基于情感詞匯的傾向性來進行綜合判斷[11],而情感分類是要對文本的整體進行情感傾向的判斷,當受到分詞的影響時,原本的句子紋理都被丟失了。
例如,“雖然總體算不錯,但是我并不喜歡。”經過分詞后變成“雖然”、“總體”“算”“不錯”“,”“但是”“我”“并”“不”“喜歡”“。”如果直接將詞語作為特征項,“不錯”“喜歡”這樣的特征詞會將本句判定為一句正面感情的句子,然而當考慮到否定詞的修飾、轉折句型,本句完全是一句負面感情的句子。
本文中提到的句子紋理主要包括詞語間依賴關系、句型、句子修辭手法等,本節將詳細介紹將句子紋理提取為文本特征的原理和步驟。而經過實驗,單純將句子紋理本身作為特征效果并不很好。于是本文提出了一種基于句子紋理的文本特征的權重計算方法: 對于出現了句子紋理信息的句子,將其中的出現的特征的特征權重在原始權重的基礎上做相應的浮動,同時對不同的特征權重計算方法進行了對比分析。本文在實驗中還考慮到特征維度較高,進行降維工作[12],實際使用維度從1 206維降至260,同時能保持分類正確率不變。
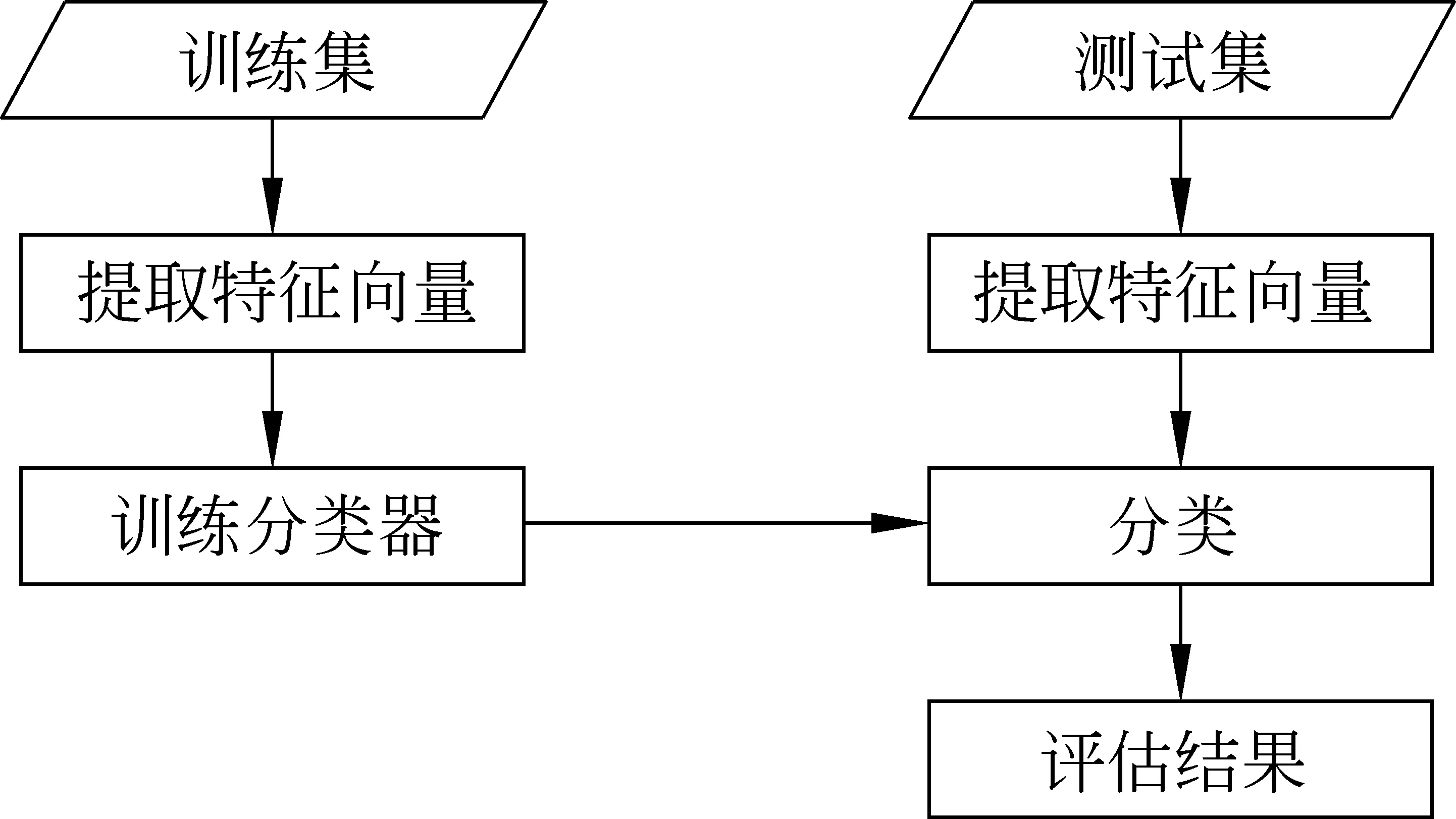
圖1 基于句子紋理的文本情感傾向性分析總體流程圖
2.1 支持向量機算法
本文實驗中使用的分類算法為支持向量機算法,又稱為SVM算法[13]和最大邊緣算法(Maximum Margin)。SVM可以用于監督式或者半監督式學習[14],依靠對有限的樣本的學習實現對非線性和高維度模式的識別。
SVM本質上是一個二分類的分類器,目的是為了在一個支持平面上尋找一個將兩類類別區分開的超平面,因此經典的SVM分類器非常適合用于本文實驗中區分正反兩面情感的分類工作。在多分類,比如更細膩的情感傾向性劃分中,可以通過多個二類支持向量機的組合來解決。主要有一對多組合模式、一對一組合模式和SVM決策樹;再就是通過構造多個分類器的組合來解決。
2.2 基于文章紋理的特征構造方法
為了消除分詞給文本情感傾向性判斷帶來的不良效果,本文在實驗中嘗試了各種幫助表現文意的元素,除了詞語本身之外還有詞語間的依賴關系、詞語順序、句型、文章修辭手法等等。本節將闡述的實驗中用到的文本特征中包括了情感詞匯、評價詞匯、語氣詞、句型以及文本紋理,文本紋理中包括詞語間依賴關系和文本修辭手法。本節將首先給出實驗中
采用的特征項,隨后說明特征權重的兩種計算方法,然后給出將用以調整特征項權重的句子紋理,最后給出調整特征項權重的方案。
2.2.1 基礎特征項
在本文實驗中,以情感詞匯、評價詞匯、語氣詞這三類詞匯作為特征向量的基礎組成部分。
? 情感詞匯
這里指表現對象正面或者負面的情緒的詞語,如: 暢快、大喜過望、感興趣、悲哀、委屈、哀怨等。
? 評價詞匯
這里指描述對象正面或者負面特征的詞語,例如,標致、別具一格、雋永、礙眼、鄙俗、表里不一等。
? 語氣詞
語氣詞是表示語氣的虛詞,常用在句尾或句中停頓處表示種種語氣。常見的語氣詞有: 哈,嗎,啦,唉。
這三類詞匯都能表達文本中人物的情感、人和物的特征,進而表現了文本的作者的情感傾向性。其中,情感詞匯也是傳統的文本傾向性分析的研究中最常用也是最重要的特征項。因此本文在構造文章紋理特征時,也采用了這三種詞匯作為待分析情感傾向性的文章的特征項。但是從實驗數據中可以明顯看到,僅僅簡單采用這三種詞匯作為特征所得到的分析結果并不十分理想。
2.2.2 文本紋理特征項
在本文實驗中,除基礎特征項之外,嘗試了以下幾種文本紋理作為特征的組成部分。
? 詞語間的依賴關系
詞語間存在著復雜的依賴關系,如果單純地以詞語作為特征項會丟失很大一部分文意。比如“總的來說,我并不贊同這一提議。”本身這個句子表達了作者對這件事的一種否定,但是經過單純以詞語作為特征項的特征化處理后,這些詞匯綜合的情感傾向性為褒義。顯然,單純以詞語來判別句子中表達的作者態度是有欠缺的。
本文在實驗中先通過Stanford Parser獲取詞語依賴關系組,如: dvpmod(防止, 有效),并提取依賴關系,如: dvpmod,并將詞語依賴關系作為文本特征的一部分。
? 句型
文本中句子的句型是句子紋理的一個重要部分,本文選擇了轉折句作為研究的切入點。轉折句表示出作者表達的意向的著重點主要在句子的后半句,因此識別轉折句能夠體現出作者的表達意圖和表達重點。
漢語中,轉折句型主要有以下結構:
可是、但是、盡管……還、雖然(雖是、說、盡管、固然)……但是(但、可是、然而、卻) 、卻、不過、然而、只是 、盡管……可是……、雖然……但是……、……卻……
轉折句的識別方法為:
1) 對句子進行分詞;
2) 在句子中查找是否出現上面提到的結構,如出現則判定為轉折句。
? 文章修辭手法
在中文中有一種特殊的句子紋理——修辭手法,是一種通過修飾、調整語句,運用特定的表達形式以提高語言表達作用的方法。由于修辭手法能表現作者相對一般句子更為強烈的情感,尤其是排比句。排比句利用三個或三個以上意義相關或相近,結構相同或相似和語氣相同的詞組或句子并排,達到了一種加強語勢的效果。所以本文擬從文中提取排比的修辭手法,并將其作為特征項的一部分。
修辭手法的識別方法為:
1) 先通過Stanford Parser獲取一個整句的句法結構;
2) 排比句中分句的句式結構往往相近甚至相同,因此通過句子結構提取和識別,把結構相似度高的分句判定為排比句。
2.2.3 特征的權重
特征的權重[15]基本可以分為兩大類: 特征出現頻率、特征出現與否。本文分別試驗了這兩種權重,并對以特征出現頻率作為權重的方法進行了改進。下面主要介紹以特征出現頻率為基礎的權重設定方法。
由于經過實驗,數據顯示單純添加詞語的依賴關系、句式本身作為特征并且計算其頻率作為特征權重的效果并不好,這是因為紋理特征本身與文章情感傾向性之間并無直接的聯系,紋理特征的直接引入反而給文章情感傾向性帶來了一定噪聲。因此文本在實驗中根據詞語依賴關系、句式、修辭來改變核心詞的特征權重,表2給出的修改值為經過實驗(對比數據列于表4)所得到的最優值。
1. 基于詞語依賴關系的特征權重
從Stanford Parser解析得到的詞語依賴關系中選擇了兩種依賴關系作為文章紋理特征研究的切入點: 否定修飾(negative modifier)和副詞修飾(adverbial modifier)。
否定修飾如: neg(愉快, 不),“愉快”一詞出現一次,其特征權重原本應當采取“+1”操作,由于否定修飾的影響,取消該“+1”操作。
程度副詞修飾的作用是改變情感詞和評價詞匯原本的表現強烈程度,知網情感分析用詞語集中總結了219個程度副詞,并劃分為六個程度。
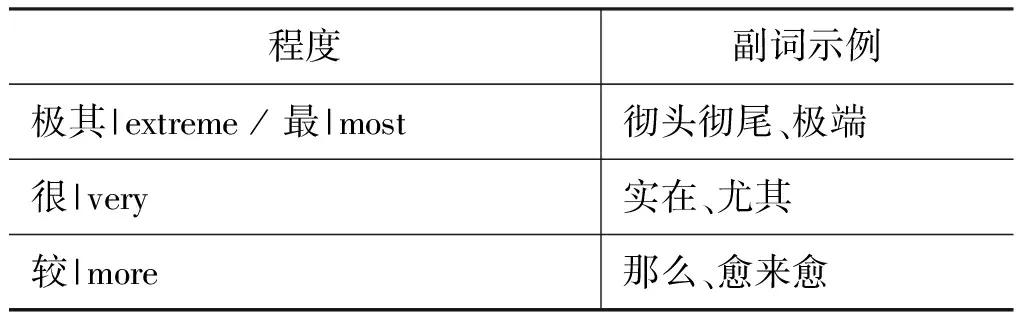
表1 知網程度副詞表
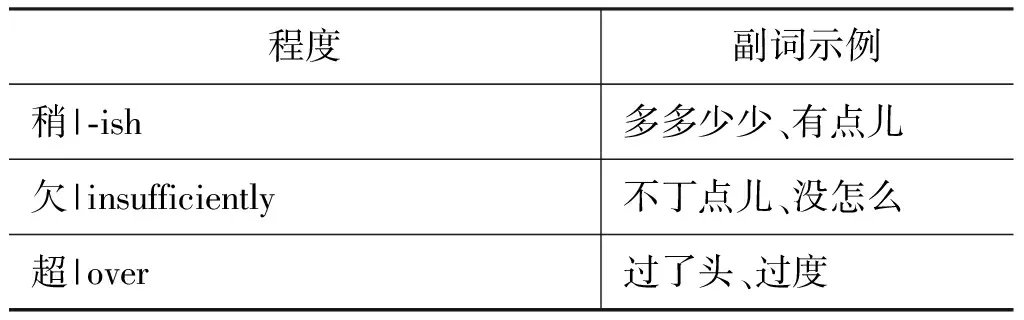
續表
特征權重修改幅度的參考值為:
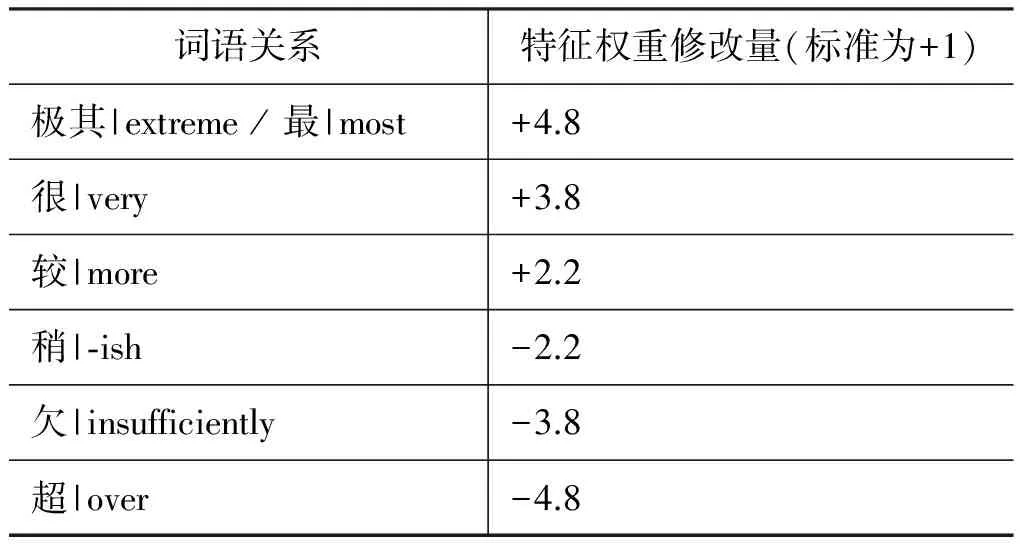
表2 程度副詞對特征值修改幅度表
2. 基于轉折句句型的特征權重
轉折句中,作者通過轉折來強調突出轉折后的半句的句意,比一般的陳述句感情更為強烈。因此本文通過識別句子是否為轉折句,來調整句子情感傾向性: 減少前半句中出現的情感詞匯、評價詞匯的特征權重,修改后每個詞出現一次對特征值的增加幅度為+0.5(標準為+1);增加后半句中出現的情感詞匯、評價詞匯的特征權重,修改后每個詞出現一次對特征值的增加幅度為+1.8(標準為+1)。
3. 基于排比修辭手法的特征權重
排比句是把三個或以上意義相關或相近、結構相同或相似、語氣相同的詞組或句子并排在一起組成的句子。排比比一般句子更能突出作者的感情思想,起到強調句意的作用。因此本文通過識別句子是否為排比句,來調整句子的情感傾向性: 增加該句中出現的情感詞匯和評價詞匯的特征權重,修改后每個詞出現一次對特征值的增加幅度為+1.3(標準為+1)。
2.3 基于互信息量MI的特征降維
互信息(Mutual Information)是一種有用的信息度量,它是指兩個事件集合之間的相關性。兩個事件X和Y的互信息定義為:
I(X;Y) =H(X)-H(X|Y)=H(Y)-H(Y|X)
=H(X)+H(Y)-H(X,Y)
=H(X,Y)-H(X|Y)-H(Y|X)
通過計算特征的出現以及正面(負面)文本的出現這兩個事件發生的相關性,可以得知每一個特征與文本傾向性的相關度。
在本文實驗中預先定義的特征集合的維度為6 919維,其中包含了3 730個正面情感詞匯和評價詞匯,3 116個負面情感詞匯和評價詞匯,20個語氣詞,53個詞語間的依賴關系,而在實驗中實際出現的特征共為1 206維,經計算互信息量并對其進行排序可以篩選出與正面(負面)文本相關度最高的那一部分特征,隨后為了消減噪聲的影響,剔除了出現在該類別文本中出現次數極少的部分特征,共得到260個分別與正面文本負面文本相關度最高的特征。通過實驗發現降維之后分類的正確率能夠保持不變。
表3為實驗所得部分相關度最高的情感詞匯、評價詞匯、語氣詞以及依賴關系
表3 部分MI值最高的情感詞匯、評價詞匯、語氣詞、依賴關系
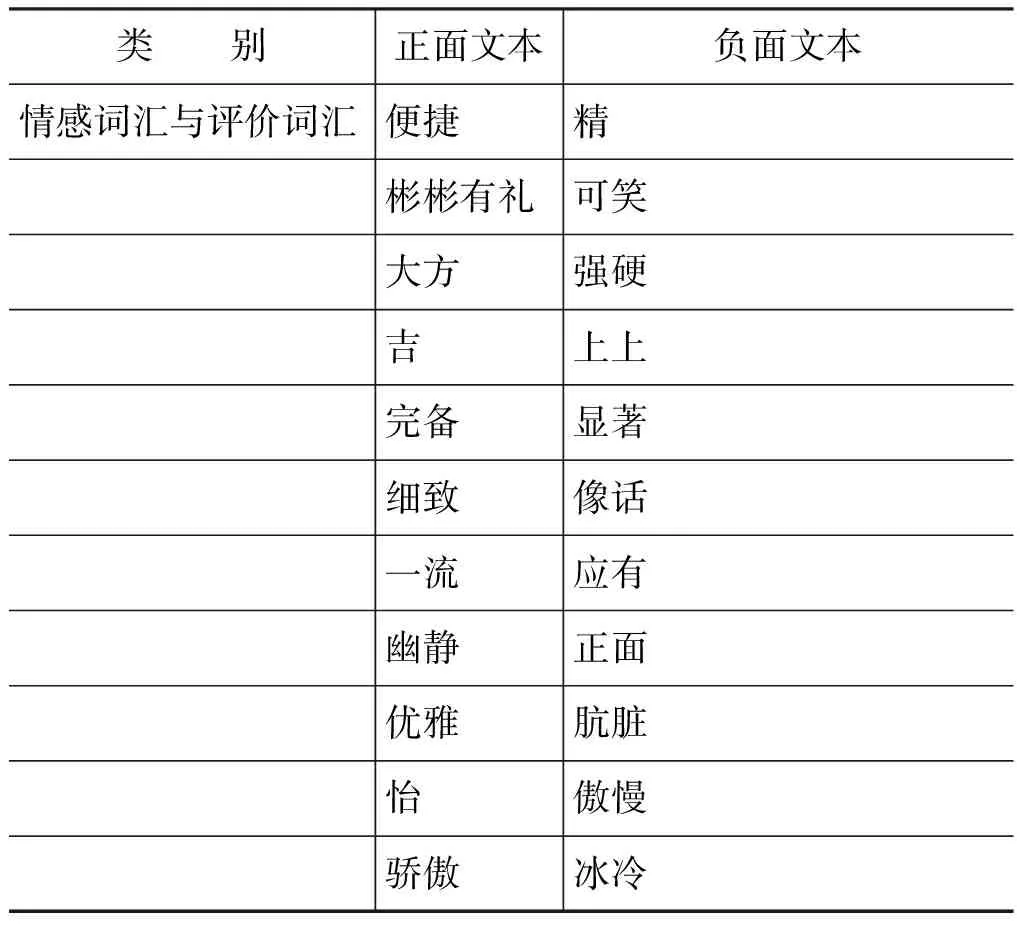
類 別正面文本負面文本情感詞匯與評價詞匯便捷精彬彬有禮可笑大方強硬吉上上完備顯著細致像話一流應有幽靜正面優雅骯臟怡傲慢驕傲冰冷
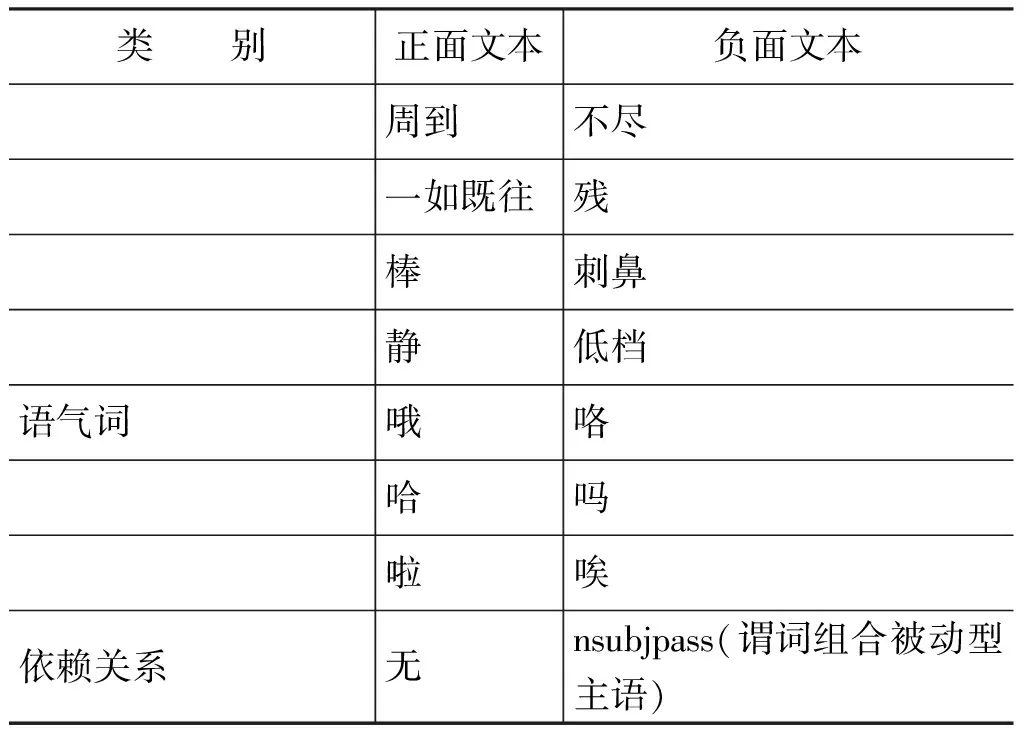
續表
3 實驗流程及結果
本文采用機器學習的方法對文本進行傾向性研究,實驗中的訓練數據和測試數據都采用譚松波收集整理的攜程網酒店評論平衡語料庫,正面文本和負面文本各2 000條,分別分為10份數據,輪流將其中九份即3 600條作為訓練數據,另外一份數據即400條作為測試數據,根據10折交叉驗證的平均值驗證實驗結果。分類算法采用的是SVM支持向量機算法。特征向量的構造方法采用的是以情感詞匯、評價詞匯、語氣詞、詞語間依賴關系的作為特征項。特征權重的計算使用了兩種方法,一是采用特征出現頻率為基礎、依靠詞語間依賴關系和句式對特征出現頻率做修正的方法,二是采用特征出現與否記錄為0和1作為權重。實驗還嘗試對特征維度進行降維,使得實際使用的特征維度降到了原本的21.6%。
下面首先給出對同一批特征選取方案中的特征權重修正的實驗結果,參見表4。
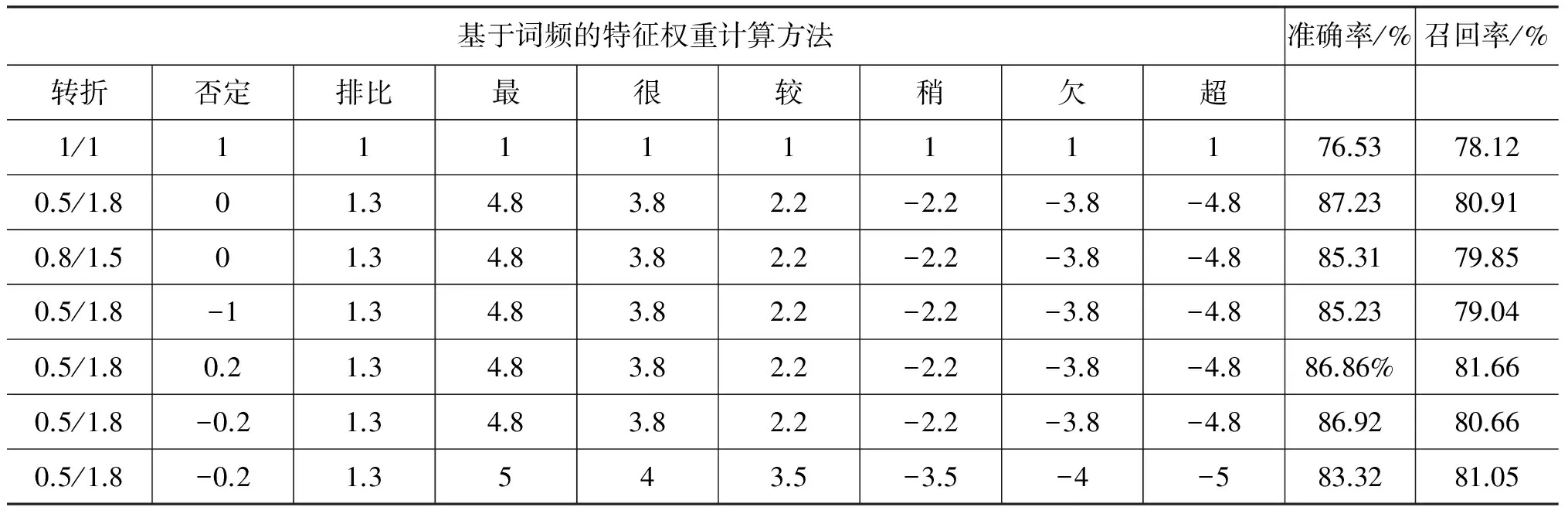
表4 根據文本紋理特征對特征權重修改方案實驗結果

續表
從表4可以看出,在基礎特征相同情況下,紋理特征特別是詞語間依賴關系對于文意的表現存在很大的影響。通過實驗,不斷修改不同的修改參數更好地模擬文本紋理結構對文意的影響程度。
本文在接下來的實驗中都將采用修改組合四,即本文2.2.3“特征的權重”一節中提到的修改方案。在包括決定特征權重修改參數、壓縮維度的預備工作完成后,實驗步驟如下:
1) 使用中科院漢語分詞系統ICTCLAS對文本進行分詞
2) 使用Stanford自然語言處理工具Stanford Parser獲取詞語間依賴關系
3) 提取文本中的情感詞匯、評價詞匯、語氣詞、詞語間依賴關系作為特征項
4) 計算特征項出現頻率作為特征權重
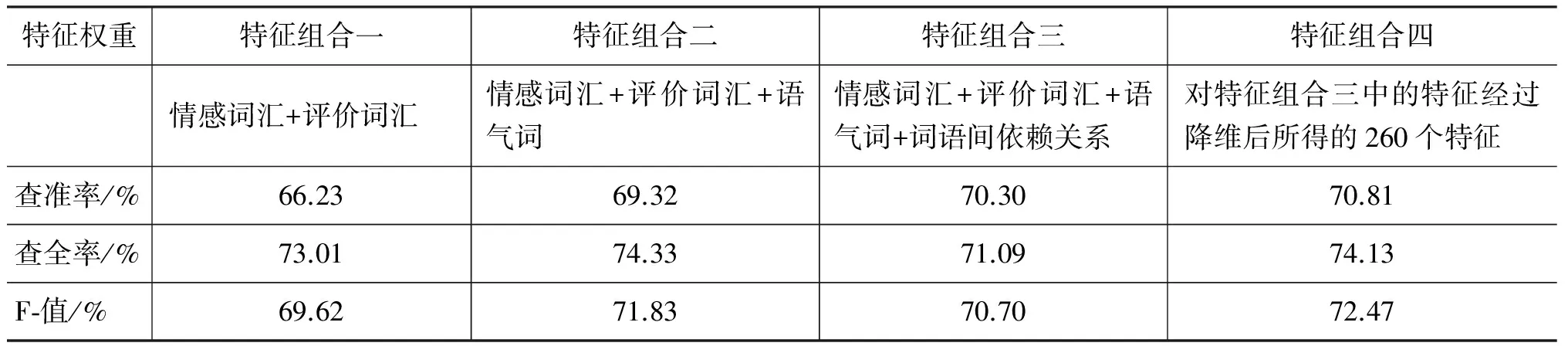
表5 以特征出現與否(0/1)作為特征權重進行分類
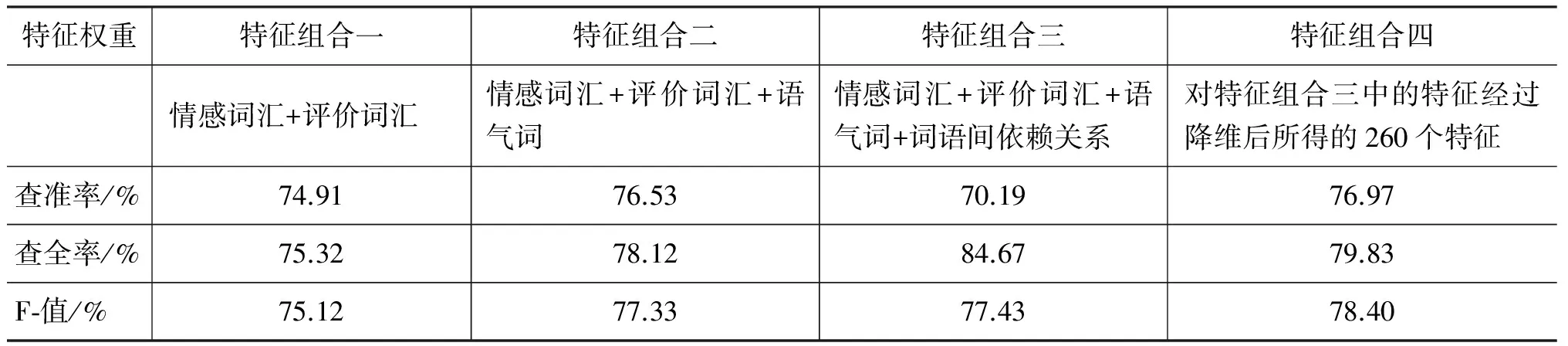
表6 以原始詞頻計算權重進行分類
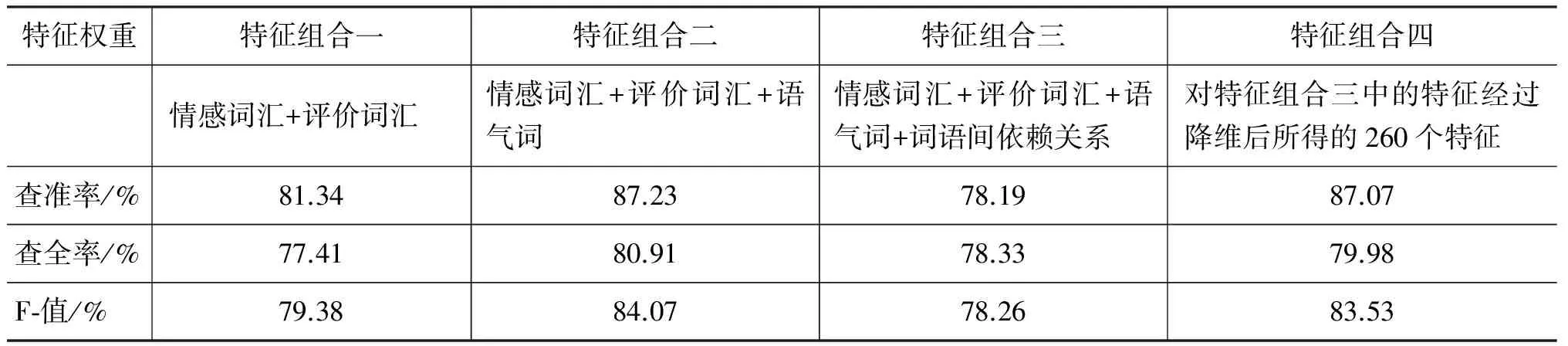
表7 以原始詞頻計算權重,以詞語間依賴關系、句式修正詞頻進行分類
5) 識別文本中轉折句、排比句,對出現在該句中的特征頻率進行修正
6) 對存在于副詞修飾、否定修飾的詞語間依賴關系中的詞語的特征頻率進行修正
7) 使用SVM分類器對訓練集進行學習
8) 使用SVM分類器對測試集進行分類,并評估結果的正確率和召回率
由實驗結果表5~7可見,在相同特征組合情況下,權重的計算方法的選擇很大影響到結果的準確率。傳統計算方法中以詞頻作為基礎計算權重的方法可以得到比較不錯的計算結果(表6),但是本文提出的由詞語依賴關系與句式修正詞頻的計算方法明顯提升了計算的結果(表7)。可見對于文本中詞語間相互關系以及整體句子結構的挖掘進一步提升了文本傾向性判斷的準確率。
通過比較表5~7的橫向數據,可以看到語氣詞的引入提高了判斷的準確性,就是說雖然語氣詞本身一般不含有任何正負面情感,但是我們在表達正面與負面情感時確實使用了不同的語氣詞。詞語間依賴關系本身作為特征是一種冗余,因為幾乎所有依賴關系本身不能夠表達任何正負面情感,必須與具體的詞語相結合才能表達出信息。
通過比較表5~7的最后兩列數據,可以發現降維后,大大加快了特征抽取與計算過程的時間,在大規模的文本分類(比如數十萬條的微博情感分類)中節省了大量時間。另外在計算特征與文本相關度的結果中,發現不同的語料庫所對應的高相關度特征中情感詞匯不盡相同,而語氣詞非常相似,因此后續工作中可以針對不同類別語料庫中相同部分進行研究,找出更多共通的特征。而且由于排除了很多冗余的特征,所以在準確率的評判中與前三種組合中結果最好的第二組相比,降維后的結果有的略低一些,有的不變,有的略高一些,綜合看來降維對準確率沒有特別大的影響,但是能極大提高工作效率。
4 總結與展望
本文主要做了兩部分工作,其一是從文本中詞與詞之間的結構、句子結構中進行挖掘文本紋理,修正了以詞頻為基礎的特征權重計算方法,有效提高了分類的準確性。
因為這些文本紋理是一種用以幫助表達作者情感起伏強弱變化的結構,采取以情感詞語和評價詞語為基礎,通過識別文本紋理修正特征權重可以更好擬合作者情感起伏。在將來的研究中,結合更多的詞語間依賴關系以及句式的研究,可以通過進一步的尋找依賴關系、句式與情感傾向之間的關系來達到更高的準確率。
其二是對繁多的特征進行分析降維, 刪減了與不同情感傾向性相關度較低的特征,保留了有明顯相關度的特征。實驗證明,降維的過程既能保證分類的準確性,也大大提高了分類速度。
因為考慮到網絡文本的不標準、描述對象的不統一,在文本中有些詞匯的出現有很大的隨機性,而根據相關度降維這一工作恰恰刪除了這些隨機性和冗余度,但是在刪除過程中雖然刪除了一些不恰當的特征,但是也排除了一部分出現次數過少或者被錯誤信息干擾了的有用特征,所以查準率并沒有能得到提升,但能與降維前保持一致。在將來工作中可以用更多算法來計算特征與不同文本間的相關度,更多更好保留有用特征。
[1] Peter D Turney, Michael L Littman. Measuring praise and criticism: Inference of semantic orientation from association[J].ACM Transactions on Information Systems (TOIS).2003, 21(4):315-346.
[2] Kim, S M, E Hovy. Automatic Detection of Opinion Bearing words and Sentences[A]. Companion Volume to the Proceedings of IJCNLP-05[C].Jeju Island, KR,2005: 61-66.
[3] Janyce wiebe, Theresa wilson, Matthew Bell. Identifying Collocations for Recognizing Opinions[A]. ACL-01 Workshop on Collocation: Computational Extraction, Analysis, and Exploitation[C]. Toulouse, France, 2001: 24-31.
[4] Theresa Wilson, Janyce Wiebe, Paul Hoffmann.Recognizing Contextual Polarity:An Exploration of Features for Phrase-Level Sentiment Analysis[J].Computational Linguistics,2009,35(3):399-433.
[5] Prem Melville, Wojciech Gryc, and Richard D. Lawrence.Sentiment analysis of blogs by combining lexical knowledge with text classification[A]. KDD ′09: Proceedings of the 15th ACM SIGKDD international conference on Knowledge discovery and data mining[C].New York, USA:ACM, 2009,1275-1284.
[6] 朱嫣嵐,閔錦,周雅倩等.基于HowNet的詞匯語義傾向計算[J].中文信息學報,2006,20(1): 14-20.
[7] 代六玲,黃河燕,陳肇雄.中文文本分類中特征抽取方法的比較研究[J].中文信息學報,2004,18(1): 26-32.
[8] 徐軍,丁宇新,王曉龍,使用機器學習方法進行新聞的情感自動分類[J].中文信息學報,2004,18(1): 95-100.
[9] 劉依璐. 基于機器學習的中文文本分類方法研究 [D]. 西安:西安電子科技大學,2009.
[10] 徐琳宏, 林鴻飛, 楊志豪.基于語義理解的文本傾向性識別機制[J].中文信息學報,2007,21(6): 96-100.
[11] Bo Pang,Lillian Lee,Shivakumar Vaithyanathan.Thumbs up? Sentiment Classification using Machine Learning Techniques[A].EMNLP ′02 Proceedings of the ACL-02 conference on Empirical methods in natural language processing[C]Stroudsburg, PA, USA:Association for Computational Linguistics,2002: 79-86.
[12] 胡潔.高維數據特征降維研究綜述[J].計算機應用研究.2008,25(9): 2601-2606.
[13] N. Cristianini, J. Shawe-Taylor.An introduction to support vector machines and other kernel-based learning methods[M].Cambridge:Cambridge University Press,2000.
[14] Nitin Namdeo Pise, Parag Kulkarn.Semi-Supervised Learning with SVM and K-Means Clustering Algorithm[A].Prasad, Bhanu.IICAI[C].IICAI,2010: 463-482.
[15] 張愛華,靖紅芳,王斌等.文本分類中特征權重因子的作用研究[J].中文信息學報,2010,24(3): 97-104.
Texture Based Sentiment Orientation Identification for Chinese Texts
XU Xinyi, LIU Gongshen
(Shanghai Jiao Tong University, School of Information Security Engineering, Shanghai 200240, China)
With the development of Internet, the text orientation identification and text mining in social network is becoming a hot research issue. In this paper, a text sentiment orientation identification method using textures is proposed. The feature reduction is conducted by mutual information between the texture features and the text orientations. Compared to sentiment orientation classification method based on word frequency, the proposed method is proved about 10% increase for precision on average.
Chinese text categorization; sentiment orientation; textures of text; SVM

許歆藝(1989—),碩士,主要研究領域為自然語言處理,文本情感傾向性分析等。E?mail:katrinaxxy@gmail.com劉功申(1974—),博士,副教授,主要研究領域為信息內容安全,自然語言處理等。E?mail:lgshen@sjtu.edu.cn
1003-0077(2015)03-0106-07
2013-04-08 定稿日期: 2013-10-30
國家自然科學基金(61272441, 61171173)
TP391
A
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中華胰腺病雜志(2021年1期)2021-02-26 11:28:36
山東醫藥(2020年34期)2020-12-09 01:22:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中華胰腺病雜志(2019年4期)2019-08-29 08:52:20
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
