基于證據(jù)理論優(yōu)化的態(tài)勢(shì)預(yù)測(cè)模型
2015-04-17 02:45:10汪永偉劉育楠趙榮彩常德顯
計(jì)算機(jī)工程與應(yīng)用 2015年16期
汪永偉,劉育楠,趙榮彩,常德顯,邱 衛(wèi)
WANG Yongwei1,2,LIU Yunan1,2,ZHAO Rongcai1,CHANG Dexian1,2,QIU Wei1,2
1.信息工程大學(xué),鄭州450004
2.河南省信息安全重點(diǎn)實(shí)驗(yàn)室,鄭州450004
1.Information Engineering University,Zhengzhou 450004,China
2.Henan Key Laboratory of Information Security,Zhengzhou 450004,China
1 引言
態(tài)勢(shì)預(yù)測(cè)是網(wǎng)絡(luò)安全態(tài)勢(shì)感知的必要環(huán)節(jié),能夠檢驗(yàn)安全措施的有效性,并對(duì)網(wǎng)絡(luò)安全狀態(tài)的發(fā)展趨勢(shì)進(jìn)行事前預(yù)判、“防患于未然”。因此,態(tài)勢(shì)預(yù)測(cè)已經(jīng)成為態(tài)勢(shì)感知領(lǐng)域的研究熱點(diǎn)之一。
當(dāng)前,態(tài)勢(shì)預(yù)測(cè)研究已取得了一定的研究成果。王慧強(qiáng)等人提出了基于遺傳算法優(yōu)化神經(jīng)網(wǎng)絡(luò)模型的態(tài)勢(shì)預(yù)測(cè)方法[1]。李松等人提出了采用粒子群算法對(duì)BP神經(jīng)網(wǎng)絡(luò)的權(quán)值和閾值進(jìn)行優(yōu)化,獲得最優(yōu)BP 神經(jīng)網(wǎng)絡(luò)模型進(jìn)行預(yù)測(cè)的方法[2]。程緒超等人提出了采用多目標(biāo)優(yōu)化算法改進(jìn)Elman 網(wǎng)絡(luò)的預(yù)測(cè)方法[3]。李彩虹等人提出了使用神經(jīng)網(wǎng)絡(luò)對(duì)誤差進(jìn)行校正的組合預(yù)測(cè)方法[4]。Yan 等人提出了基于相對(duì)誤差求最優(yōu)權(quán)重組合的預(yù)測(cè)方法[5]。Xu 等人提出了通過(guò)構(gòu)建相對(duì)誤差矩陣和線性方程求解最優(yōu)組合模型的預(yù)測(cè)方法[6]。Zheng 等人提出了利用信息熵權(quán)法構(gòu)建組合模型權(quán)重的方法[7]。
分析現(xiàn)有的研究工作可以看出,現(xiàn)有預(yù)測(cè)模型研究主要包括兩大類(lèi):?jiǎn)我活A(yù)測(cè)模型和組合預(yù)測(cè)模型。由于單一預(yù)測(cè)模型都是針對(duì)曲線的某種特征而設(shè)計(jì)的,因此,前一種態(tài)勢(shì)預(yù)測(cè)方法僅能做到對(duì)某種特質(zhì)的態(tài)勢(shì)曲線的高精度預(yù)測(cè),在應(yīng)用上具有一定的局限性;第二種預(yù)測(cè)模型的思路清晰,預(yù)測(cè)模型的適應(yīng)性也更強(qiáng)。現(xiàn)有的組合模型中,組合權(quán)重都是依據(jù)誤差精度進(jìn)行調(diào)整,即依據(jù)單指標(biāo)建立組合模型。然而,在一些情況下,誤差精度指標(biāo)不能全面反映預(yù)測(cè)子模型的性能優(yōu)劣程度。如,在平均誤差相同的情況下,預(yù)測(cè)子模型的誤差分布可能會(huì)有較大差異,依據(jù)不均勻誤差分布而建立的組合模型在預(yù)測(cè)性能上會(huì)表現(xiàn)出極大的不確定性;此外,態(tài)勢(shì)曲線的變化趨勢(shì)也是影響預(yù)測(cè)精度的重要因素。現(xiàn)有組合模型對(duì)上述因素尚未給予充分考慮。
針對(duì)上述問(wèn)題,本文提出一種基于證據(jù)理論優(yōu)化的態(tài)勢(shì)組合預(yù)測(cè)模型(Situation Forecast Model based on Evidence Theory Optimization,SFM_ETO)。SFM_ETO模型首先對(duì)參與組合預(yù)測(cè)的各子模型進(jìn)行訓(xùn)練,獲得各子模型的多指標(biāo)性能評(píng)價(jià);然后利用證據(jù)理論對(duì)多指標(biāo)權(quán)重進(jìn)行融合,獲得最優(yōu)的初始權(quán)重組合;在組合預(yù)測(cè)完成后,再次利用證據(jù)理論對(duì)指標(biāo)權(quán)重進(jìn)行折扣,強(qiáng)化高可信指標(biāo)對(duì)權(quán)重分配的作用,弱化低可信指標(biāo)對(duì)權(quán)重分配的影響,從而優(yōu)化組合模型。
2 基于證據(jù)理論優(yōu)化的態(tài)勢(shì)組合預(yù)測(cè)算法
2.1 基本思路
網(wǎng)絡(luò)安全態(tài)勢(shì)隨時(shí)間并未表現(xiàn)出顯著的規(guī)律性特征,在某些情況下表現(xiàn)平穩(wěn),在另外一些情況下則表現(xiàn)出周期變化或隨機(jī)變化,因此,只用一種模型很難精確地刻畫(huà)預(yù)測(cè)過(guò)程[8-9]。本文將能夠精確刻畫(huà)不同特征曲線的典型態(tài)勢(shì)預(yù)測(cè)模型進(jìn)行綜合,試圖利用不同模型各自在態(tài)勢(shì)預(yù)測(cè)上的優(yōu)勢(shì),取長(zhǎng)補(bǔ)短,從而獲得更為精確的預(yù)測(cè)結(jié)果。證據(jù)理論具有較強(qiáng)的多目標(biāo)融合決策能力,能夠?qū)崿F(xiàn)綜合多源信息,獲得更為精確的決策。因此,本文提出一種基于證據(jù)理論優(yōu)化的態(tài)勢(shì)預(yù)測(cè)模型SFM_ETO。該模型分為四個(gè)階段:訓(xùn)練準(zhǔn)備、權(quán)重融合、組合預(yù)測(cè)和優(yōu)化演進(jìn)。SFM_ETO 模型的工作過(guò)程如圖1 所示。
階段1訓(xùn)練準(zhǔn)備
對(duì)組合模型的子模型進(jìn)行訓(xùn)練,獲得態(tài)勢(shì)預(yù)測(cè)子模型的參數(shù)、評(píng)價(jià)指標(biāo)和權(quán)重分配。
階段2權(quán)重融合
基于證據(jù)理論對(duì)獲得的多重評(píng)價(jià)指標(biāo)進(jìn)行權(quán)重融合,獲得初始的最優(yōu)組合權(quán)重。
階段3組合預(yù)測(cè)
利用組合預(yù)測(cè)算法對(duì)態(tài)勢(shì)進(jìn)行預(yù)測(cè)。
階段4優(yōu)化演進(jìn)
基于證據(jù)理論對(duì)組合權(quán)重和評(píng)價(jià)指標(biāo)進(jìn)行優(yōu)化,強(qiáng)化高可信度指標(biāo)在預(yù)測(cè)模型評(píng)價(jià)和權(quán)重分配過(guò)程中的作用,降低可信度較低的指標(biāo)對(duì)權(quán)重決策的不利影響。
2.2 SFM_ETO 模型的子模型
基于2.1 的分析,SFM_ETO 模型將態(tài)勢(shì)分為平穩(wěn)變化量、周期變化量和隨機(jī)變化量。本文選擇二次指數(shù)平滑法、BP 神經(jīng)網(wǎng)絡(luò)模型和ARIMA 三種模型用于分別刻畫(huà)這三種分量。
2.2.1 二次指數(shù)平滑法
二次指數(shù)平滑法由布朗(Robert G.Brown)提出,是時(shí)間序列平滑法的一種[10]。其基本思想是:時(shí)間序列的變化態(tài)勢(shì)具有穩(wěn)定性或規(guī)則性,所以時(shí)間序列可被合理地順勢(shì)推延,可以將其作為下一期預(yù)測(cè)的基礎(chǔ)。二次指數(shù)平滑法強(qiáng)調(diào)近期數(shù)據(jù)對(duì)預(yù)測(cè)值的作用,適用于預(yù)測(cè)變化不大、變動(dòng)較為平滑的數(shù)據(jù)。
2.2.2 BP 神經(jīng)網(wǎng)絡(luò)預(yù)測(cè)模型
BP(Back Propagation)網(wǎng)絡(luò)是神經(jīng)網(wǎng)絡(luò)中采用誤差反傳算法作為其學(xué)習(xí)算法的前饋網(wǎng)絡(luò)[11]。其基本思想是:BP 神經(jīng)網(wǎng)絡(luò)通常由輸入層、輸出層和隱含層構(gòu)成,層與層之間的神經(jīng)采用全互連的連接方式,通過(guò)相應(yīng)的網(wǎng)絡(luò)權(quán)系數(shù)相互聯(lián)系,每層內(nèi)的神經(jīng)元之間沒(méi)有連接。BP 神經(jīng)網(wǎng)絡(luò)模型的自適應(yīng)性、自學(xué)習(xí)能力和抗干擾能力強(qiáng),適用于預(yù)測(cè)有周期性特征的數(shù)據(jù)。
2.2.3 ARIMA 預(yù)測(cè)模型
ARIMA 模型全稱(chēng)為自回歸移動(dòng)平均模型(Autoregressive Integrated Moving Average Model,ARIMA)[12]。其基本思想是:首先對(duì)時(shí)間序列做平穩(wěn)性檢驗(yàn);對(duì)非平穩(wěn)時(shí)間序列進(jìn)行差分使其轉(zhuǎn)化為平穩(wěn)序列,需要的差分次數(shù)就是參數(shù)d;然后,對(duì)ARIMA 的自回歸項(xiàng)p和移動(dòng)平均項(xiàng)q進(jìn)行識(shí)別;最后,建立ARIMA 模型對(duì)時(shí)間序列進(jìn)行預(yù)測(cè)[9]。ARIMA 模型對(duì)噪音數(shù)據(jù)有很強(qiáng)的預(yù)測(cè)能力,適用于具有非周期性、突變特征的數(shù)據(jù)預(yù)測(cè)。
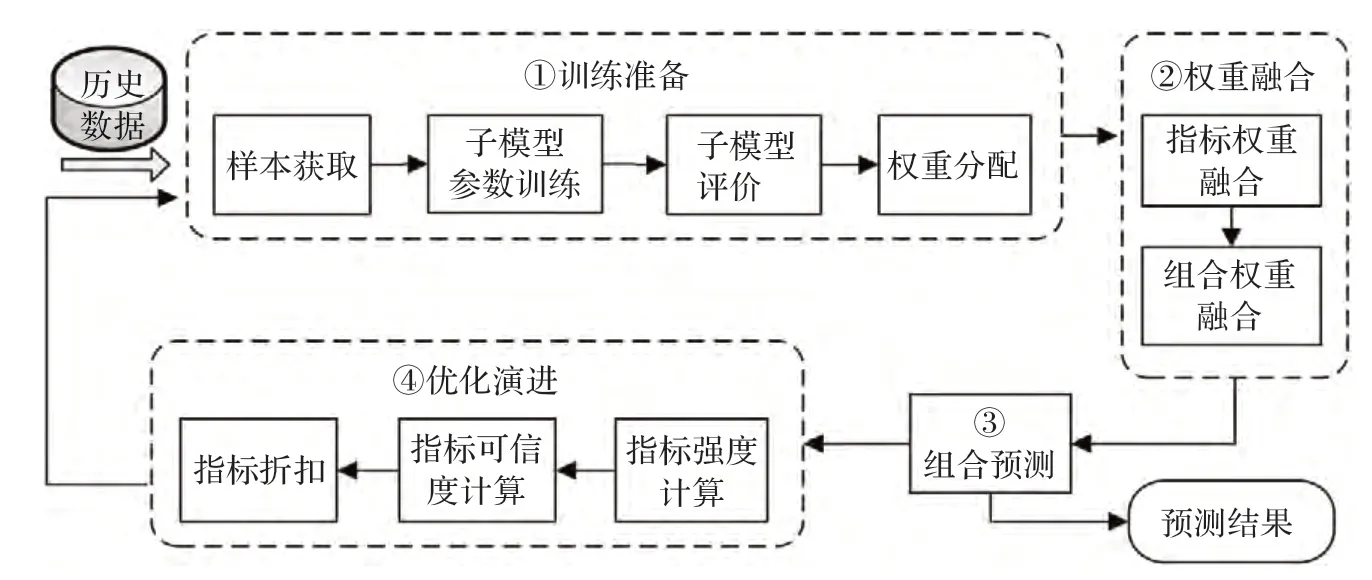
圖1 基于證據(jù)理論優(yōu)化的態(tài)勢(shì)預(yù)測(cè)模型
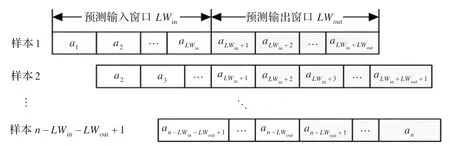
圖2 態(tài)勢(shì)預(yù)測(cè)訓(xùn)練樣本集
2.3 訓(xùn)練準(zhǔn)備
2.3.1 樣本集獲取
SFM_ETO 模型采用滑動(dòng)窗口動(dòng)態(tài)生成樣本集。假設(shè)已采集的態(tài)勢(shì)樣本序列為a1,a2,…,an,預(yù)測(cè)輸入滑動(dòng)窗口大小為L(zhǎng)Win,預(yù)測(cè)輸出滑動(dòng)窗口為L(zhǎng)Wout,則第1條訓(xùn)練樣本為。預(yù)測(cè)輸入滑動(dòng)窗口和預(yù)測(cè)輸出滑動(dòng)窗口依次向右滑動(dòng),完成樣本集構(gòu)建。樣本集的構(gòu)建過(guò)程如圖2 所示。
2.3.2 評(píng)價(jià)指標(biāo)與權(quán)重分配
2.3.2.1 基于相對(duì)誤差的權(quán)重分配
態(tài)勢(shì)預(yù)測(cè)一般使用誤差來(lái)描述預(yù)測(cè)模型的精度[4],下面給出相關(guān)定義。
定義1絕對(duì)誤差(Absolute Error,AE)

其中,pi表示預(yù)測(cè)輸出值,ai表示實(shí)際輸出值。
定義2平均絕對(duì)誤差(Mean Absolute Error,MAE)
絕對(duì)誤差的平均值稱(chēng)為平均絕對(duì)誤差,表示為:

定義3相對(duì)誤差(Absolute Percent Error,APE)
相對(duì)誤差可用預(yù)測(cè)輸出值與實(shí)際輸出值之間的相對(duì)差值表示。
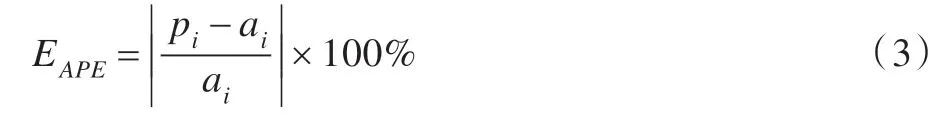
定義4平均相對(duì)誤差(Mean Absolute Percent Error,MAPE)
相對(duì)誤差的平均值稱(chēng)為平均相對(duì)誤差,表示為:
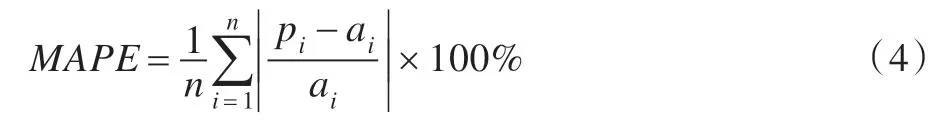
EAPE值越大,表明預(yù)測(cè)算法的預(yù)測(cè)精度越低,在組合預(yù)測(cè)算法中應(yīng)為其分配越低的權(quán)重;反之,應(yīng)為其分配越高的權(quán)重。
通過(guò)式(4)計(jì)算每個(gè)預(yù)測(cè)算法的相對(duì)誤差后,對(duì)相對(duì)誤差進(jìn)行歸一化處理,可得每種算法的權(quán)重Ew(Error Weight)。

2.3.2.2 基于趨勢(shì)擬合的權(quán)重分配
從數(shù)學(xué)形式上看,可用連續(xù)型時(shí)變曲線z=f(t)描述態(tài)勢(shì)的演化過(guò)程。對(duì)態(tài)勢(shì)數(shù)據(jù)按照時(shí)間間隔τ進(jìn)行離散采樣,得到由采樣點(diǎn)(tk,zk)所形成的離散型時(shí)間序列。如圖3 所示。
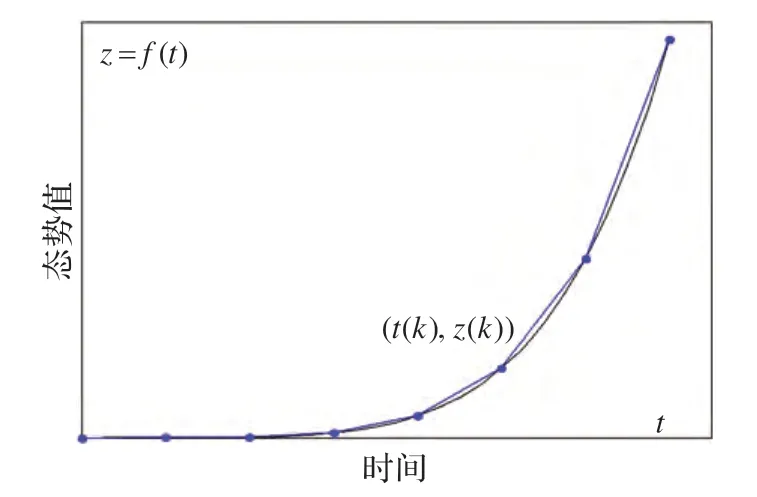
圖3 曲線分段擬合
假設(shè),F(xiàn)(i,n)表示從ti時(shí)刻開(kāi)始的由采樣點(diǎn)構(gòu)成的折線子圖。每條線段的斜率gk可表示為:

其中,zk表示tk時(shí)刻的態(tài)勢(shì)值。依據(jù)式(6)可得預(yù)測(cè)曲線的斜率序列(Prediction Serial,PS)和實(shí)際曲線的斜率序列(Actual Serial,AS)。
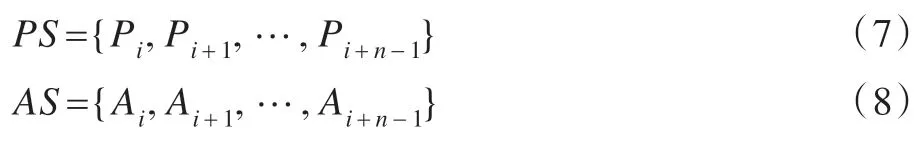
計(jì)算PS 與AS 轉(zhuǎn)置的乘積,可得乘積向量MS={Mi,Mi+1,…,Mi+n-1}。即:

向量MS中的元素為正值表示預(yù)測(cè)曲線與實(shí)際曲線變化趨勢(shì)相同,MS中的元素為負(fù)值表示預(yù)測(cè)曲線與實(shí)際曲線變化趨勢(shì)相反。MS中的元素為正值的個(gè)數(shù),m越大,表明預(yù)測(cè)曲線在大多數(shù)時(shí)間的變化趨勢(shì)與實(shí)際曲線相似;反之,m越小,表明預(yù)測(cè)曲線在大多數(shù)時(shí)間的變化趨勢(shì)與實(shí)際曲線相反。MS中正值的個(gè)數(shù)從某種意義上反映了預(yù)測(cè)算法對(duì)真實(shí)值的預(yù)測(cè)能力。
定義5趨勢(shì)一致量TCA(Trend Consistent Amount)
預(yù)測(cè)序列的趨勢(shì)一致量用向量MS中正值個(gè)數(shù)來(lái)表示。即:

其中,{?Mi|Mi>0}表示乘積向量MS中正值元素所構(gòu)成的集合,|{ ?Mi|Mi>0} |為該正值集合的勢(shì),表示其中元素的個(gè)數(shù)。
定義6趨勢(shì)擬合度TF(Trend Fitness)
預(yù)測(cè)曲線的趨勢(shì)擬合度用預(yù)測(cè)序列與實(shí)際序列中趨勢(shì)相同序列個(gè)數(shù)與序列的勢(shì)之間的比率來(lái)表示。

其中,TCA表示乘積向量MS中正值個(gè)數(shù),|PS|稱(chēng)為序列PS 的勢(shì),表示序列PS 中元素的個(gè)數(shù)。預(yù)測(cè)序列與實(shí)際曲線的趨勢(shì)擬合度越高,說(shuō)明預(yù)測(cè)算法的預(yù)測(cè)精確性高的可能性越大,因此在組合預(yù)測(cè)時(shí)應(yīng)賦予其較高的組合權(quán)重;反之,在組合預(yù)測(cè)時(shí)為其分配較低的組合權(quán)重。在獲得每個(gè)算法的趨勢(shì)擬合度之后,對(duì)趨勢(shì)擬合度進(jìn)行歸一化處理,可將其歸一化結(jié)果作為其趨勢(shì)擬合權(quán)重Tw(Trend Fitness Weight)。

2.3.2.3 基于信息熵的權(quán)重分配
信息熵標(biāo)志著所含信息量的多少,是對(duì)系統(tǒng)不確定性程度的描述,可以用來(lái)衡量信息的不確定性程度[13]。對(duì)于一組在[0,1]內(nèi)的且滿(mǎn)足歸一化的數(shù)據(jù),信息熵可以衡量數(shù)據(jù)的集中程度。如果一個(gè)信息系統(tǒng)中n個(gè)不確定事件,記為x1,x2,…,xn,每個(gè)事件的發(fā)生概率記為p1,p2,…,pn,則信息熵的計(jì)算公式為:

預(yù)測(cè)序列中每個(gè)分段的相對(duì)誤差構(gòu)成相對(duì)誤差序列(Absolute Percent Error Serial,EAPES):
EAPES={EAPES1,EAPES2,…,EAPESn}
根據(jù)信息熵的含義,EAPES序列的信息熵越大,預(yù)測(cè)算法對(duì)態(tài)勢(shì)真實(shí)值的擬合越趨于穩(wěn)定,其對(duì)態(tài)勢(shì)真實(shí)曲線的擬合能力越強(qiáng)。因此,能較好地反映預(yù)測(cè)算法對(duì)目標(biāo)態(tài)勢(shì)曲線的穩(wěn)定、持續(xù)擬合能力。
定義7擬合穩(wěn)定度FS(Fitness Stability)
擬合穩(wěn)定度用MAPES 序列的信息熵來(lái)表示。定義如下:
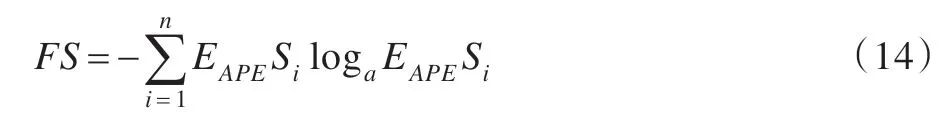
預(yù)測(cè)序列與實(shí)際曲線的擬合穩(wěn)定度越高,說(shuō)明預(yù)測(cè)算法的持續(xù)精確預(yù)測(cè)能力越高,因此,在組合預(yù)測(cè)時(shí)應(yīng)賦予其較高的組合權(quán)重;反之,應(yīng)為其分配較低的組合權(quán)重。
在獲得每個(gè)算法的擬合穩(wěn)定度之后,對(duì)擬合穩(wěn)定度進(jìn)行歸一化處理,可將其歸一化結(jié)果作為其擬合穩(wěn)定性權(quán)重Sw(Fitness Stability Weight)。

2.4 基于證據(jù)理論的權(quán)重融合
證據(jù)理論通過(guò)對(duì)多源證據(jù)的融合,獲得對(duì)命題的一致性描述,降低信息的不確定性[14-15]。在證據(jù)理論中,所有研究對(duì)象的全體稱(chēng)為一個(gè)識(shí)別框架Θ,證據(jù)理論的核心是Dempster合成規(guī)則[16]。
定義8Dempster合成規(guī)則
設(shè)識(shí)別框架Θ 的n個(gè)證據(jù)為(E1,E2,…,En),其對(duì)應(yīng)的基本信任分配函數(shù)為mi(i=1,2,…,n),則n個(gè)證據(jù)組合后的信度分配函數(shù)為:
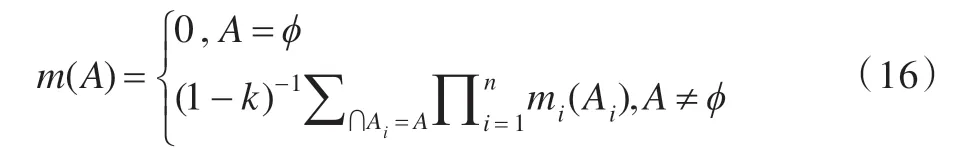
2.4.1Ew權(quán)重融合
Ewi是采樣序列中第i個(gè)采樣點(diǎn)計(jì)算的權(quán)重分配,n個(gè)采樣點(diǎn)可獲得n組權(quán)重分配。n個(gè)采樣的權(quán)重分配可看作是n個(gè)專(zhuān)家為不同算法的信任賦值。因此,可以利用證據(jù)理論在不確定性問(wèn)題處理上的優(yōu)勢(shì),對(duì)n個(gè)權(quán)重序列進(jìn)行合成,從而獲得更為精確的Ew權(quán)重分配。
假設(shè),二次指數(shù)平滑、BP 神經(jīng)網(wǎng)絡(luò)模型和ARIMA模型的預(yù)測(cè)值為P1,P2,P3,三種模型的權(quán)重分別為w1,w2,w3,識(shí)別框架Θ={P1,P2,P3},采樣序列的長(zhǎng)度為n,則通過(guò)式(17)可將權(quán)值分配轉(zhuǎn)化為信任分配:

將三種權(quán)值分配的結(jié)果轉(zhuǎn)化為信任分配,可獲得相對(duì)誤差證據(jù)矩陣Ee:
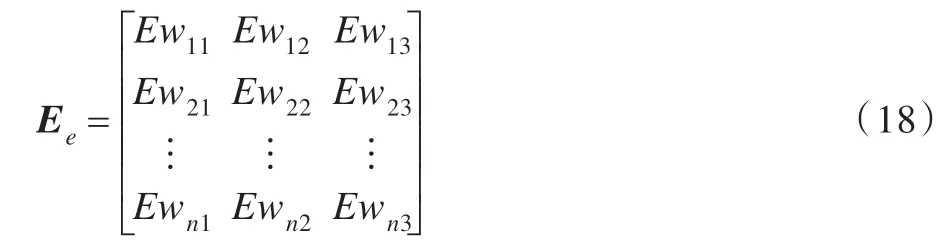
通過(guò)證據(jù)理論的組合公式(16)對(duì)矩陣Ee進(jìn)行融合,可以獲得更為精確的相對(duì)誤差權(quán)值Ewc1、Ewc2、Ewc3。
2.4.2 三種權(quán)值分配方案的證據(jù)融合
依據(jù)相對(duì)誤差、趨勢(shì)擬合度和擬合穩(wěn)定度可以為組合算法模型中的算法賦予不同的權(quán)值序列Ewc1,Ewc2,Ewc3、Tw1,Tw2,Tw3、Sw1,Sw2,Sw3。三種權(quán)值分配方案從不同的角度評(píng)價(jià)了子模型的預(yù)測(cè)精度。類(lèi)似于Ew的處理,通過(guò)式(17)將三種權(quán)值分配結(jié)果轉(zhuǎn)化為信任分配,可得組合權(quán)重證據(jù)矩陣Ec:
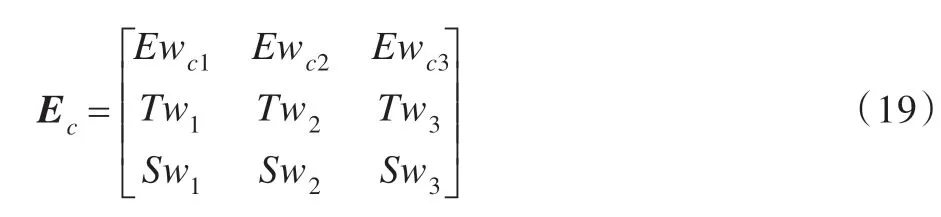
通過(guò)證據(jù)理論對(duì)證據(jù)矩陣Ec進(jìn)行融合,可以獲得更為精確的權(quán)重分配Fw=(mc1,mc2,mc3)。此時(shí),組合預(yù)測(cè)結(jié)果可表示為:
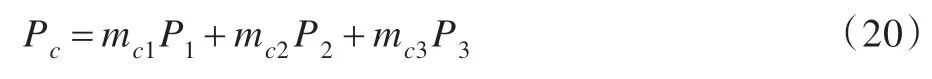
為了后續(xù)描述的方便,后文中將由各指標(biāo)直接獲取的權(quán)重稱(chēng)之為指標(biāo)權(quán)重,將指標(biāo)權(quán)重證據(jù)理論融合的結(jié)果稱(chēng)之為組合權(quán)重。
2.5 組合預(yù)測(cè)算法
圖4 給出了基于SFM_ETO 的預(yù)測(cè)算法(SFM_ETO Algorithm,SFM_ETO_A)的偽碼描述。

圖4 基于SFM_ETO 的態(tài)勢(shì)預(yù)測(cè)算法
2.6 優(yōu)化演進(jìn)算法
本文采用的相對(duì)誤差、擬合一致度和擬合穩(wěn)定度指標(biāo)對(duì)刻畫(huà)預(yù)測(cè)模型的性能具有一定的普遍性。但是,由于態(tài)勢(shì)曲線的變化是不確定的,因此,在一些情況下,某些指標(biāo)對(duì)態(tài)勢(shì)曲線的表達(dá)會(huì)出現(xiàn)較大偏差,從而導(dǎo)致較差的預(yù)測(cè)精度。證據(jù)理論一般通過(guò)最大信任的方法做出決策,其信任值代表了對(duì)決策結(jié)果的支持程度。如果指標(biāo)權(quán)重的決策結(jié)果與組合權(quán)重的決策結(jié)果一致,且預(yù)測(cè)結(jié)果達(dá)到精度閾值要求,則說(shuō)明指標(biāo)權(quán)重與精確預(yù)測(cè)之間具有強(qiáng)相關(guān)性。因此,可以利用這種相關(guān)性的強(qiáng)弱來(lái)表達(dá)指標(biāo)的強(qiáng)弱程度。
定義9指標(biāo)強(qiáng)度(Index Strength,IS)
假設(shè)進(jìn)行了n次精確組合預(yù)測(cè)(達(dá)到設(shè)定的精度閾值),若依據(jù)某指標(biāo)獲得的權(quán)重分配與組合權(quán)重分配有m次保持一致,則該指標(biāo)的指標(biāo)強(qiáng)度可表示為:

指標(biāo)的強(qiáng)度表示了對(duì)精確預(yù)測(cè)的支持程度。指標(biāo)強(qiáng)度越高,該指標(biāo)在組合模型中的地位越重要,可信程度越高;反之,該指標(biāo)在組合模型中的地位越重要,可信程度越低。
定義10指標(biāo)可信度(Index Confidence,IC)
指標(biāo)強(qiáng)度的歸一化結(jié)果稱(chēng)之為指標(biāo)可信度。

指標(biāo)可信度較好地刻畫(huà)了預(yù)測(cè)指標(biāo)對(duì)預(yù)測(cè)子模型的評(píng)價(jià)能力。態(tài)勢(shì)預(yù)測(cè)模型的優(yōu)化演進(jìn)過(guò)程應(yīng)弱化低可信指標(biāo)的權(quán)重分配結(jié)果,盡可能地降低低可信指標(biāo)的負(fù)面影響。在組合模型中,指標(biāo)權(quán)重是以證據(jù)的形式進(jìn)行組合的,Shafer 提出的證據(jù)折扣法可有效降低低可信證據(jù)在融合結(jié)論中的影響。因此,每次組合預(yù)測(cè)完成后,計(jì)算證據(jù)可信度,在新的預(yù)測(cè)周期中采用Shafer 的證據(jù)折扣法對(duì)指標(biāo)權(quán)重進(jìn)行優(yōu)化調(diào)整。證據(jù)折扣法的表達(dá)式如式(23)所示。
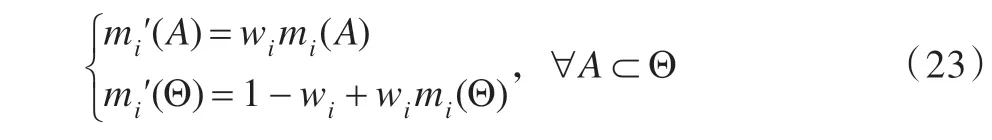
其中,w1,…,wi,…,wn表示證據(jù)i的權(quán)重,可用指標(biāo)可信度來(lái)代替;mi(A)表示證據(jù)中焦元的信任度,可用指標(biāo)權(quán)重代替。
圖5 給出了優(yōu)化演進(jìn)算法(Optimization Evolution Algorithm,OEA)的偽代碼描述。

圖5 優(yōu)化演進(jìn)算法
3 實(shí)驗(yàn)仿真
本文在Matlab2013 下進(jìn)行了仿真實(shí)驗(yàn),對(duì)比本文模型與單預(yù)測(cè)模型和單指標(biāo)組合預(yù)測(cè)模型在性能上的差異。單預(yù)測(cè)模型選取本文中的子模型:二次指數(shù)平滑、BP 神經(jīng)網(wǎng)絡(luò)和ARIMA。單指標(biāo)組合預(yù)測(cè)模型選取文獻(xiàn)[5]中Yan 提出的組合預(yù)測(cè)模型。實(shí)驗(yàn)數(shù)據(jù)為態(tài)勢(shì)預(yù)測(cè)領(lǐng)域所使用的經(jīng)典數(shù)據(jù)集HoneyNet[4],選取2000 年12 月1 日到2001 年1 月31 日的數(shù)據(jù)作為預(yù)測(cè)樣本。由于網(wǎng)絡(luò)安全態(tài)勢(shì)和網(wǎng)絡(luò)告警具有正相關(guān)性,故本文直接以數(shù)據(jù)集中網(wǎng)絡(luò)告警的統(tǒng)計(jì)值作為態(tài)勢(shì)。由于在態(tài)勢(shì)評(píng)估中,一般取[0,1]為態(tài)勢(shì)的取值區(qū)間,因此,本文對(duì)所得態(tài)勢(shì)值均作極值標(biāo)準(zhǔn)化處理[4],處理結(jié)果如圖6 所示。
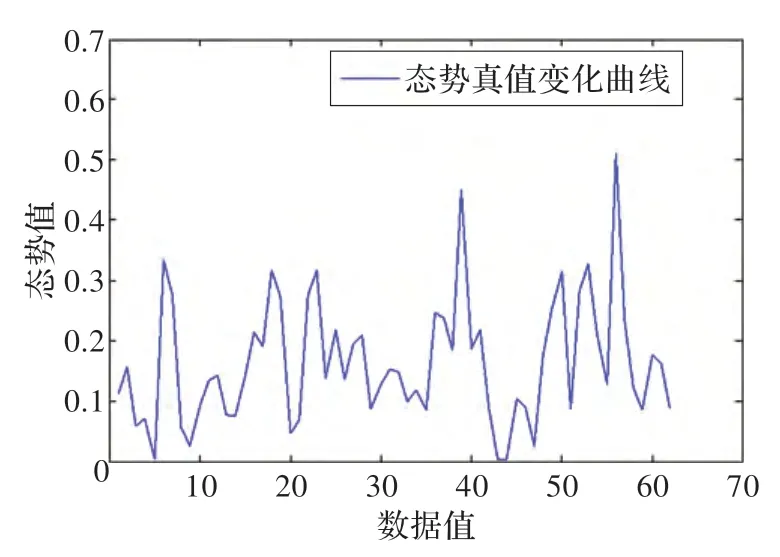
圖6 態(tài)勢(shì)真值
3.1 實(shí)驗(yàn)設(shè)置
設(shè)置預(yù)測(cè)輸入窗口LWin=25;為了檢測(cè)輸出窗口對(duì)預(yù)測(cè)精度的影響,預(yù)測(cè)輸出窗口取較大值LWout=5。即,首先,取前25 個(gè)數(shù)據(jù)作為樣本進(jìn)行訓(xùn)練,獲得各子模型的合理參數(shù)配置;然后,子模型對(duì)26~30 個(gè)數(shù)據(jù)進(jìn)行態(tài)勢(shì)預(yù)測(cè),獲得子模型的評(píng)價(jià),并利用證據(jù)理論進(jìn)行權(quán)重分配;最后,利用組合模型對(duì)31~35 個(gè)數(shù)據(jù)進(jìn)行態(tài)勢(shì)預(yù)測(cè),并將其結(jié)果與典型預(yù)測(cè)模型的結(jié)果進(jìn)行比較。
實(shí)驗(yàn)中的參數(shù)設(shè)置如表1 所示。
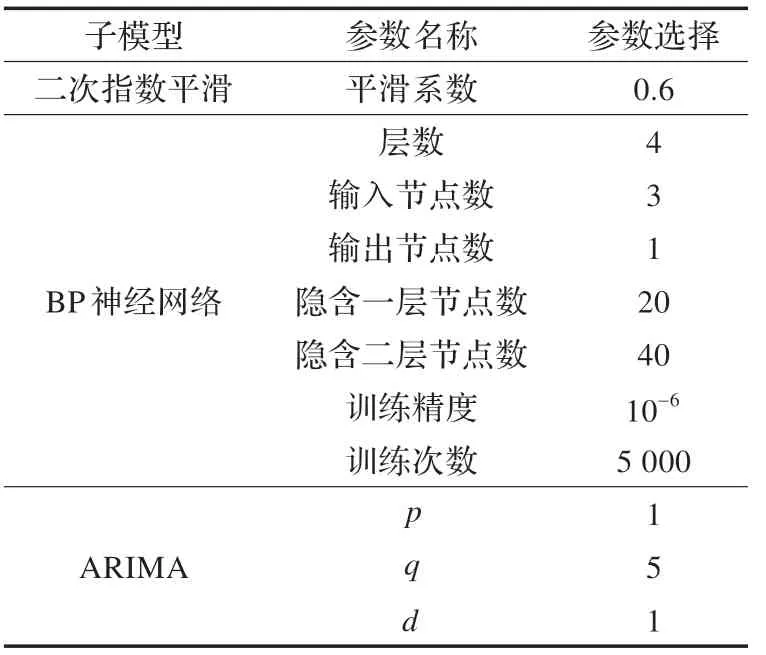
表1 實(shí)驗(yàn)參數(shù)設(shè)置
3.2 實(shí)驗(yàn)結(jié)果
前25 組態(tài)勢(shì)數(shù)據(jù)的訓(xùn)練結(jié)果如表2 所示。
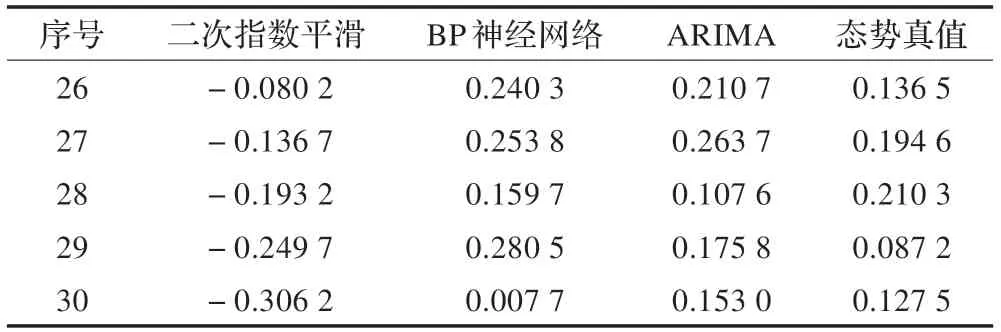
表2 訓(xùn)練獲取的單模型預(yù)測(cè)結(jié)果
依據(jù)式(5)、(12)、(15)和(19)可得組合權(quán)重矩陣為:

利用證據(jù)理論對(duì)Ec進(jìn)行證據(jù)融合,可得最終的組合預(yù)測(cè)模型為:
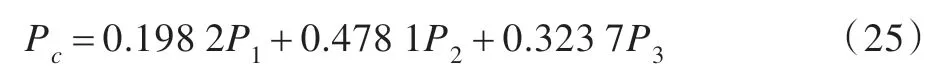
利用該組合模型對(duì)第31~35 組數(shù)據(jù)分別進(jìn)行組合預(yù)測(cè)和單模型預(yù)測(cè)。不同預(yù)測(cè)模型的實(shí)驗(yàn)對(duì)比如圖7~圖9 和表3 所示。
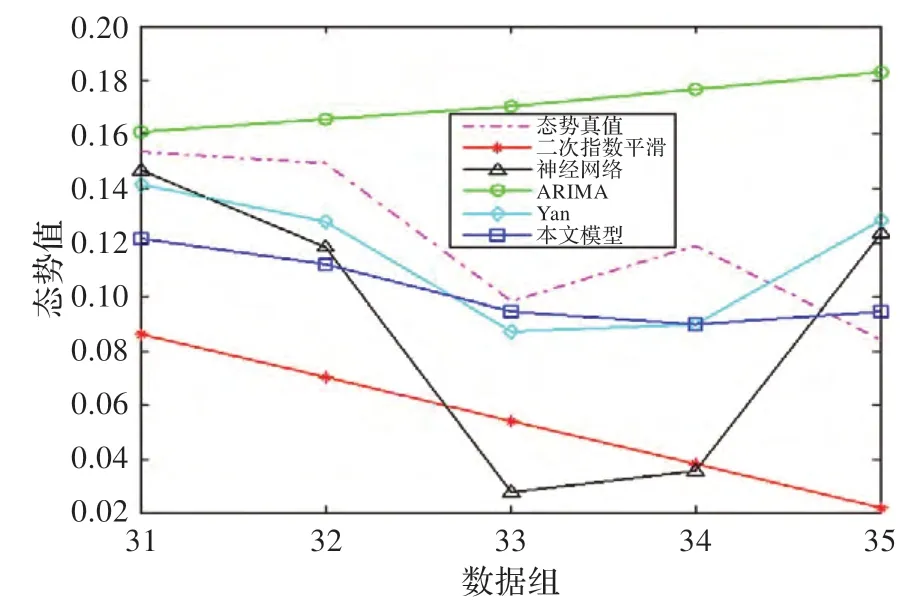
圖7 不同預(yù)測(cè)模型的預(yù)測(cè)結(jié)果對(duì)比
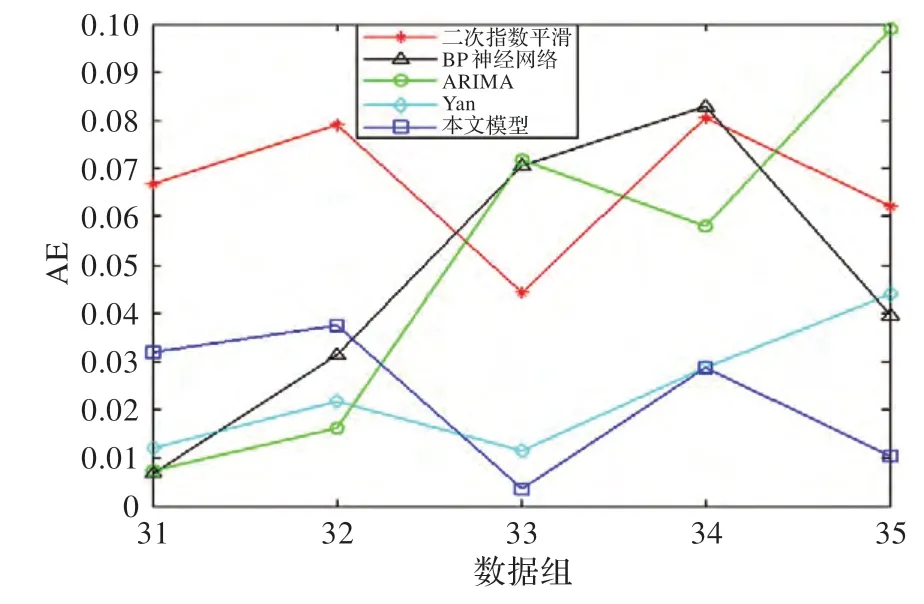
圖8 不同預(yù)測(cè)模型的AE 對(duì)比
3.3 實(shí)驗(yàn)分析
從圖7 中可以看出,本文預(yù)測(cè)模型與Yan 預(yù)測(cè)模型的擬合曲線在變化上更趨近于實(shí)際的態(tài)勢(shì)曲線。圖8和圖9 中的絕對(duì)誤差A(yù)E 和絕對(duì)相對(duì)誤差A(yù)PE 對(duì)比表明,在預(yù)測(cè)窗口較大時(shí),單預(yù)測(cè)模型的誤差變化起伏較大,隨著預(yù)測(cè)步長(zhǎng)的增加,預(yù)測(cè)誤差上升較快,而本文模型和Yan 模型在誤差穩(wěn)定性上的表現(xiàn)要優(yōu)于單預(yù)測(cè)模型,本文預(yù)測(cè)模型的誤差變化曲線相對(duì)更為穩(wěn)定,主要原因是本文模型在組合權(quán)重確定時(shí)考慮了曲線趨勢(shì)變化特征和穩(wěn)定性特征。表3 中的平均絕對(duì)誤差MAE 和平均相對(duì)誤差MAPE 的對(duì)比結(jié)果表明,本文模型的誤差最小,分別為MAE=0.022 4,MAPE=17.26%,其預(yù)測(cè)精度比Yan 模型高4.91%。
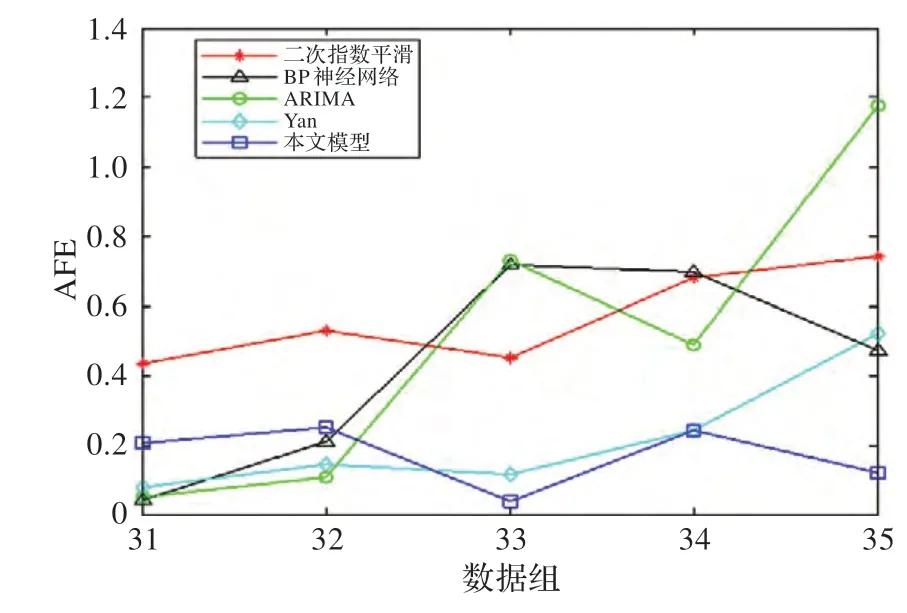
圖9 不同預(yù)測(cè)模型的APE 對(duì)比

表3 不同預(yù)測(cè)模型的MAE 和MAPE 對(duì)比
4 結(jié)束語(yǔ)
本文研究了多模型態(tài)勢(shì)組合預(yù)測(cè)問(wèn)題。通過(guò)對(duì)現(xiàn)有典型預(yù)測(cè)方法的分析,提出了一種基于證據(jù)理論優(yōu)化的態(tài)勢(shì)組合預(yù)測(cè)方法。Matlab 實(shí)驗(yàn)仿真結(jié)果表明,本文的組合預(yù)測(cè)模型能夠依據(jù)態(tài)勢(shì)曲線的變化特征對(duì)組合權(quán)重進(jìn)行動(dòng)態(tài)調(diào)整,模型的適應(yīng)性和穩(wěn)定性較好,且預(yù)測(cè)精度明顯高于典型預(yù)測(cè)模型。
本文提出的預(yù)測(cè)模型組合方法和優(yōu)化演進(jìn)方法提供了對(duì)多個(gè)單預(yù)測(cè)模型進(jìn)行組合、優(yōu)化以實(shí)現(xiàn)更精確預(yù)測(cè)的框架,在預(yù)測(cè)子模型選擇上并未刻意尋求性能最優(yōu)的子模型。因此,SFM_ETO 模型的預(yù)測(cè)子模型可進(jìn)一步擴(kuò)展,或采用性能更優(yōu)的預(yù)測(cè)子模型替代本文的子模型,以獲得更好的預(yù)測(cè)效果。如何針對(duì)具體的態(tài)勢(shì)類(lèi)型,如性能態(tài)勢(shì)、傳輸態(tài)勢(shì)、安全態(tài)勢(shì)等,改進(jìn)上述模型的子模型構(gòu)成是下一步工作的重點(diǎn)。
[1] 王慧強(qiáng),賴(lài)積保,胡明明,等.網(wǎng)絡(luò)安全態(tài)勢(shì)感知關(guān)鍵實(shí)現(xiàn)技術(shù)研究[J].武漢大學(xué)學(xué)報(bào),2008,33(10):995-998.
[2] 李松,劉力軍,劉穎鵬.改進(jìn)PSO 優(yōu)化BP神經(jīng)網(wǎng)絡(luò)的混沌時(shí)間序列預(yù)測(cè)[J].計(jì)算機(jī)工程與應(yīng)用,2013,49(6):245-248.
[3] 程緒超,陳新宇,郭平.基于改進(jìn)Elman 網(wǎng)絡(luò)模型的軟件可靠性預(yù)測(cè)[J].通信學(xué)報(bào),2011,32(4):86-93.
[4] 李彩虹.兩類(lèi)組合預(yù)測(cè)方法的研究與應(yīng)用[D].蘭州:蘭州大學(xué),2012.
[5] Yan Bin,Yu Haibo,Gao Zhenwei.A combination forecasting model based on IOWA operator for dam safety monitoring[C]//2013 Fifth International Conference on Measuring Technology and Mechatronics Automation(ICMTMA),2013:5-8.
[6] Xu Yabo,Wang Tong,Song Bingxue,et al.Forecasting of production safety situation by combination model[J].Procedia Engineering,2012,43(2012):132-136.
[7] Zheng Jianhong,Qiao Jinyou.Application and evaluation on combination forecasting model based on information entropy and Shapley value[C]//2011 International Conference on Consumer Electronics,Communications and Networks(CECNet).IEEE,2011:1990-1993.
[8] Martins V L M,Werner L.Forecast combination in industrial series:A comparison between individual forecasts and its combinations with and without correlated errors[J].Expert Systems with Applications,2012,39(13):11479-11486.
[9] 于靜,王輝.基于組合模型的網(wǎng)絡(luò)流量預(yù)測(cè)[J].計(jì)算機(jī)工程與應(yīng)用,2013,49(8):92-95.
[10] Rodrigues L R L,Doblas-Reyes F J,dos Santos Coelho C A.Multi-model calibration and combination of tropical seasonal sea surface temperature forecasts[J].Climate Dynamics,2013,4(1):1-20.
[11] Huwiler M,Kaufmann D.Combining disaggregate forecasts for inflation:The SNB's ARIMA model[R].[S.l.]:Swiss National Bank,2013.
[12] Li G,Shi J,Zhou J.Bayesian adaptive combination of shortterm wind speed forecasts from neural network models[J].Renewable Energy,2011,36(1):352-359.
[13] 尋二輝,任趁妮.一種改進(jìn)的沖突證據(jù)融合方法[J].計(jì)算機(jī)科學(xué),2012,39(11):31-38.
[14] Yee Leung,Ji Nannan,Ma Jianghong.An integrated information fusion approach based on the theory of evidence and group decision-making[J].Information Fusion,2012,23(2):1-13.
[15] 陳金廣,張芬.多證據(jù)源沖突的組合度量方法[J].計(jì)算機(jī)工程與應(yīng)用,2013,49(9):222-227.
[16] Xu Xiaobin,F(xiàn)eng Haishan.An information fusion method of fault diagnosis based on interval basic probability assignment[J].Chinese Journal of Electronics,2011,20(2):255-260.
猜你喜歡
童話(huà)王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
艦船科學(xué)技術(shù)(2022年13期)2022-08-11 09:30:02
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
鐵道通信信號(hào)(2020年9期)2020-02-06 09:15:22
數(shù)學(xué)大王·趣味邏輯(2019年5期)2019-06-13 20:27:43
小學(xué)科學(xué)(學(xué)生版)(2019年5期)2019-05-21 01:00:18
經(jīng)濟(jì)技術(shù)協(xié)作信息(2018年30期)2018-11-22 06:20:24
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
