k均值聚類中的EM思想
2015-04-14 09:47:14馬麗娜
科技視界 2015年17期
馬麗娜
(西安財經學院行知學院信息系,陜西 西安 710038)
0 引言
在數據分析中,根據數據集中有無某些已知類別的樣本,可以分為監(jiān)督學習和無監(jiān)督學習兩種。無監(jiān)督學習是最常見的一種統(tǒng)計學習模式,又稱為聚類分析,已經在文本挖掘[1]、遙感圖像[2]、生物醫(yī)學[3]、社交網絡[4]、安全檢測[5]等領域得到了廣泛的應用。目前已經有許多成熟的聚類方法,像k均值聚類,支持向量機,層次聚類,基于密度的聚類等[6]。k均值算法以其簡潔高效的特性,是最受關注的聚類方法之一。最大期望值算法(EM算法),是針對缺失數據的一種統(tǒng)計學習理論,常常被用來求在含有不完整觀測的數據集下的極大似然估計[7]。本文分析了k均值聚類和EM算法思想上的相通之處,指出了兩種方法迭代過程的等價性。
1 相關理論知識
1.1 k均值聚類
k均值算法中的輸入變量為類個數k和樣本矩陣X。其中X中存有參與聚類的n個樣本。算法的目標是將n個數據對象劃分為k個類,以便使得所獲得的k個子類滿足:同一子類中的對象相似度較高;而不同子類中的對象相似度較小。k均值算法基本步驟如下:
a)從n個樣本中任意選擇 k個對象作為初始類中心;
b)根據每個子類中樣本的均值,計算每個對象與這些中心樣本點的距離;并將每個樣本分到這樣一個子類,這個子類的中心是所有k個中心點離該樣本最近的;
c)重新計算每個子類的均值;
d)當滿足一定收斂條件(如類中心不再變化)時,則算法終止;如果條件不滿足則回到步驟b)。
1.2 模糊k均值聚類
模糊k均值聚類(FCM)是對傳統(tǒng)k均值聚類的拓展。在FCM中,樣本不再明確地屬于或者不屬于某一類,而是對各個子類有個0和1之間的隸屬度。詳細算法如下:
a)從n個樣本中任意選擇k個對象作為初始類中心;
b)計算每個對象與這些中心點的距離;并根據這些距離值計算樣本對各單類的隸屬度;
c)根據樣本的隸屬度重新計算每個子類的均值(找出中心樣本);
d)當滿足一定收斂條件時,則算法終止;如果條件不滿足則回到步驟 b)。
可以看出傳統(tǒng)k均值其實是一種特殊的FCM,即限制了隸屬度為 0或 1。
1.3 改進模糊k均值聚類
傳統(tǒng)的模糊k均值聚類對噪聲點敏感。這是由于其對隸屬度進行了概率歸一化的限制,使得隸屬度是相對的,而不是絕對的。比如,如果有兩個點A和B,A和B均和兩個類的距離相等。不同的是,A到兩個類中心的距離較小,而B到兩個類中心的距離很大。傳統(tǒng)的模糊k均值不能區(qū)分這兩種情況的不同,都會給A和B賦予0.5的各類隸屬度。為此,目前有許多針對傳統(tǒng)模糊k均值聚類的改進算法([8,9]),如噪聲模糊k均值算法([10])。這種算法在原來的各個類的基礎上,增加了噪聲類。設定了一個距離閾值t,當樣本到各個類中心的距離都大于t時,則將該樣本歸為噪聲類,算法如下。
a)初始化k個類中心,設定噪聲類閾值t;
b)計算每個對象與這些類中心點的距離;并根據這些距離值和閾值t計算樣本對各單類和噪聲類的隸屬度;
c)根據樣本的隸屬度重新計算每個子類的均值(找出中心樣本);
d)當滿足一定收斂條件時,則算法終止;如果條件不滿足則回到步驟 b)。
1.4 EM算法
在統(tǒng)計計算中,EM模型中常用來計算在帶有不完全觀測的數據集下參數的最大似然估計。為了方便起見,我們將數據集W分為兩部分,可直接觀測部分Y和不可觀測(隱藏)部分Z。EM算法同樣經過兩個步驟交替進行計算:
a)E步:利用對隱藏變量Z的當前估計值(在觀測Y下的條件期望),計算完全(對數)似然函數 Q;
b)M步:最大化在E步上求得的似然函數Q來計算參數的值。
在M步上找到的參數估計值將被用于下一個E步計算中,這個過程不斷交替進行,直到算法收斂。
2 k均值和EM迭代過程的等價性
EM算法的迭代過程類似于爬山的過程。在E步,為基于完全數據的對數觀測似然函數確定一個下界函數。然后在M步,極大化這個下界函數。接下來就是一個循環(huán)往復的過程。在EM算法剛開始的時候,給定初始點,進行E步,觀測似然函數值并沒有提升,它只是找到了一個下界函數Q,并且這個函數和對數觀測似然函數在初始點的值相等。在極大化之后,我們再計算期望,這時的E步才會提升觀測似然函數值。
E步是對不可觀測的隱藏變量進行猜測。這種猜測是在觀測樣本的基礎上進行的,即在觀測樣本和現有參數下求條件期望。如果以觀測樣本和現有的參數為猜測依據,那么期望就是最靠譜的猜測。所謂的靠譜,就是說在現行的參數下,目標函數和猜測函數Q的值相等,而且猜測函數在參數為其他值時也不會超過對應的目標函數。E步保證了這種猜測是目標函數的下界,所以M步求得的極大值依然沒有超過目標函數的最大值。在M步求得極大值后,參數進行了更新,所以也要將猜測根據新的參數進行更新。可以說,下一次迭代的E步提升了上一次迭代M步的值。而這種提升的原因,有兩點:(1)基于上一次E步,猜測函數的值小于目標函數。(2)在進行新的E步之后,目標函數和新的猜測函數值相同,而新的猜測函數同樣是目標函數的下界。
再來看一下k均值的更新過程。k均值通過更新兩種變量來極小化目標函數,類中心和隸屬度。隸屬度,即類別標簽,相當于不可觀測的隱藏變量。而類中心是可觀測的。在已知觀測變量的條件下,首先猜樣本屬于哪一類。易知通過將樣本分到最近的中心所在的類,就可以實現目標函數在現有觀測條件下的極小化。所謂的條件期望,在這里其實就是根據各類幾何中心確定類標簽或隸屬度。接下來就要通過極小化的方法來確定類中心。因此,類中心的更新過程相當于EM中的M步,而隸屬度更新的過程相當于EM中的E步。
對于均值聚類來講,剛開始并不知道每個樣本對應的隱藏變量,即其類別標簽。剛開始的時候可以對類標簽進行一個隨機初始化,然后在類別已知的情況下,極大化目標函數。接下來發(fā)現會有更好的類標簽的指定辦法。如此往復,直到目標函數收斂。所以,聚類的目標函數相當于EM中觀測對數似然函數的角色。對于傳統(tǒng)k均值聚類來講,隱藏類別的指定方法比較特殊,屬于非此及彼的硬指派。而對于模糊均值聚類,類別的指派辦法是依賴隸屬度的。
以上的討論不限于傳統(tǒng)k均值聚類,對其各種改進算法,如噪聲k均值聚類同樣適用。
3 k均值聚類的實現
R語言是當前最為流利的一種統(tǒng)計分析語言,它包含一套完整的數據處理、計算和制圖軟件系統(tǒng)。現在已經有成熟的R包集成了聚類算法,包含k均值聚類,比如vegclust包。其中,vegclust函數提供了k均值和模糊k均值聚類的功能。但是,這個函數并沒有利用R矩陣化運算的特點,這就降低了程序的執(zhí)行效率。R語言作為一種解釋型編譯語言,顯式循環(huán)比較慢是其一個很大的缺點。雖然已經有apply系列的函數來避免顯式循環(huán),但是在很多情況下還是不能滿足需求。其實,R語言的一個顯著的、優(yōu)點是支持矩陣化運算。如果能用矩陣運算來代替顯式循環(huán),將會大大提高程序的效率。比如,在隸屬度確定時,利用矩陣化運算的思想,可以通過矩陣乘積來實現。假設樣本距離矩陣為D,則隸屬度的計算過程為:
a)計算D的倒數的1/(m-1)次方,其中m為模糊化因子,計算結果記為S。
b)用S除以S和k維全1矩陣的矩陣乘積。
經過上述兩個步驟,就得到了各個樣本的隸屬度。同樣的,可以設計更新樣本中心時的矩陣化方法。記隸屬度矩陣為U,中心更新算法如下。
a)計算U的m次方和樣本矩陣的矩陣乘積。
b)計算U的m次方和n*d維全1矩陣的矩陣乘積。其中n為樣本的個數,d為樣本的維數。
c)將上面兩個步驟得到的矩陣向量相除得到中心矩陣V。
噪聲k均值聚類算法的隸屬度更新可類似進行:
a)計算D的倒數的1/(m-1)次方,同樣將計算結果記為S。
b)用S除以S與k維全1矩陣的矩陣乘積和t的倒數的1/(m-1)次方的和。
增加的噪聲類對各個類中心的計算無影響,所以中心的更新過程和上面模糊k均值聚類是完全一樣的。有了隸屬度和中心更新的主程序,不同k均值聚類均可依下流程進行。
a)初始化k個類中心,指定需要的附加參數。
b)依如上介紹的隸屬度更新算法計算矩陣U。
c)依如上介紹的中心確定算法計算矩陣V。
d)判斷算法收斂條件,如不滿足收斂條件,返回b)。如滿足,則算法結束。
算法的收斂條件可以根據需要設計,可以為相鄰兩次迭代目標函數的值變化不大,或相鄰兩次迭代確定的類中心完全相同。
為了顯示矩陣化后的程序的優(yōu)勢,我們以Iris數據集為例,用vegclust和本文設計的算法FCM分別執(zhí)行模糊k均值聚類,將實驗以不同的隨機初始點重復進行1000次,比較系統(tǒng)運行的時間,結果如表1所示。
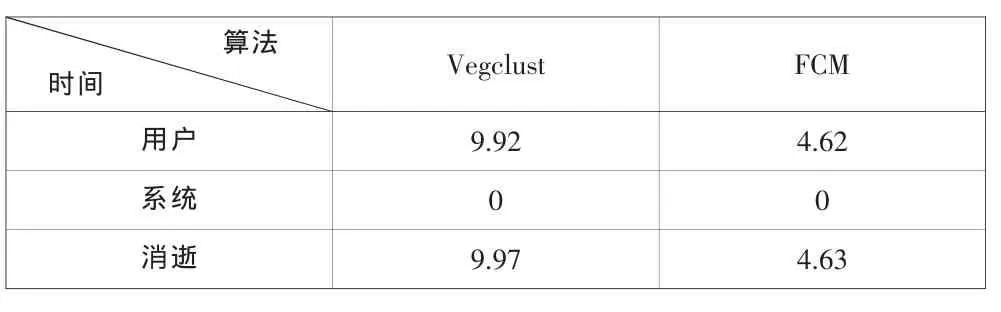
表1 運行時間對比
從上表可以看出,矩陣化運算可以使程序的運行時間大大縮短,這就極大地提高了算法的效率。尤其在海量數據的時代,更具有實際應用價值。
4 結論
本文討論了k均值聚類中包含的EM思想,并指出了兩個算法在迭代過程中的等價性。k均值中樣本隸屬度更新和類中心更新分別與EM算法中的E步和M步的等價,兩個不同領域的方法在思想上是相通的。同時,介紹了如何基于矩陣化運算進行k均值聚類的程序設計。并用數值實例證明了矩陣化算法可以使R程序的執(zhí)行效率大大提高。
[1]任江濤,孫婧昊,施瀟瀟,等.一種用于文本聚類的改進的k均值算法[J].計算機應用,2006,26(B06):73-75.
[2]王易循,趙勛杰.基于k均值聚類分割彩色圖像算法的改進[J].計算機應用與軟件,2010,27(8):127-130.
[3]王興偉,沈蘭蓀.基于改進的k均值聚類和數學形態(tài)學的彩色眼科圖像病灶分割[J].中國生物醫(yī)學工程學報,2002,21(5):443-448.
[4]楊建新,周獻中,葛銀茂.基于拉普拉斯圖譜和k均值的多社團發(fā)現方法[J].計算機工程,2008,34(12):178-180.
[5]胡艷維,秦拯,張忠志.基于模擬退火與k均值聚類的入侵檢測算法[J].計算機科學,2010,37(6):122-124.
[6]湯效琴,戴汝源.數據挖掘中聚類分析的技術方法[J].微計算機信息,2003,19(1):3-4.
[7]王愛平,張功營,劉方.EM算法研究與應用[J].計算機技術與發(fā)展,2009,19(9):108-110.
[8]傅德勝,周辰.基于密度的改進k均值算法及實現[J].計算機應用,2011,31(2):432-434.
[9]孔銳,張國宣,施澤生,等.基于核的 k-均值聚類[J].計算機工程,2004,30(11):12-13.
[10]謝志偉,王志明.基于上下文約束的噪聲模糊聚類算法[J].計算機工程與應用,2012,48(5):143-145.
