基于信令數據的交通出行分布異常檢測
2015-04-13 04:14:26李紀華劉建玲肖瑞
移動通信 2015年21期
李紀華,劉建玲,肖瑞
(中國聯合網絡通信有限公司北京市分公司,北京 100038)
1 引言
基于信令數據在交通領域的挖掘應用具有很大價值,由于目前智能移動終端的滲透率越來越高,因此移動信令的數據包含了用戶的出行行為特征、出行時間及出行地點等信息。這些信息不僅能夠用來分析用戶的出行偏好和出行方式,還可以預測用戶的出行時間分布,為交通部門、城市規劃部門提供巨大的參考意義。基于信令數據的交通出行分布異常檢測的方法不僅能夠輕量級反映用戶的出行分布規律以及出行異常情況,大大提高城市交通部門的信息化水平,而且能夠節省城市交通部門昂貴的硬件支出與維護,因此受到了越來越多研究者的關注。
2 異常檢測的方法
異常檢測又叫偏差檢測,其目的是把不滿足一定分布或者反常的對象找出來,以達到管理異常對象的目的。異常檢測的方法有以下5種:
(1)基于分布的方法
基于異常分布的方法的原理是通過分析整個數據集的分布規律,例如二項分布、泊松分布或正態分布等,利用概率等原理發現一些分布不一致的數據。該方法的優點是具有較高的異常檢測效率,但缺點就是使用者很難確定數據集的分布。
(2)基于深度的方法
基于深度的方法的原理是通過把數據映射到數據集的K維向量中,然后賦給數據一個深度值,最后利用異常檢測的方法把深度較小的值找出來。該方法的優點是可以計算高維數據的異常性,缺點是該算法隨著數據維度的增大計算復雜度迅速增加,導致檢測效率大大降低。
(3)基于距離的方法
基于距離的方法的原理是通過計算1個點O在一定距離D內的數量,如果數量小于某一個閾值,則判定O點為異常點。該算法的優點是容易使用,在實際場景使用較多,但缺點也很明顯:對線性分布的數據異常檢測的準確性很低。
(4)基于聚類的方法
基于聚類的方法的原理是通過對相似性的計算,找出數據集中不同的類簇,對小類簇進行判別從而得出異常對象。該算法的優點是不需要考慮數據的分布以及聚類的種類,適用于海量數據的檢測,缺點是由于利用相似性進行數據的度量,因此處理高維數據時效率相對較低。
(5)基于密度的方法
基于密度的方法的原理是通過測量給定范圍的密度,如果該密度超出一定閾值,那么可以認定該范圍是異常區域。該算法的優點是計算簡單,能夠很好處理不同密度的區域,缺點是計算復雜度很高,對于高維數據的計算效率相對較低。
3 基于空間密度聚類方法進行交通出行 分布異常檢測
基于空間密度聚類方法進行交通出行分布異常檢測主要解決的技術問題是如何利用移動運營商一系列的信令數據進行分析挖掘,從而識別交通出行分布的異常,通過結合移動通信技術和大數據挖掘技術,使得交通部門及城市建設規劃部門能夠降低分析用戶出行狀態的成本,通過用戶出行的規律間接反映城市道路交通結構的合理性,為智慧交通的建設提供很好的支撐作用。
3.1 DBSCAN算法的介紹
DBSCAN(Density-Based Spatial Clustering of Applications with Noise,具有噪聲的基于密度的聚類方法)的基本原理是:對于簇中的每一個點,在設定的半徑范圍內至少包括設定數據的點。該算法把具有足夠密度的區域劃分成一類,優點是對于帶“噪音”的空間數據可以發現任何形狀的聚類,聚類速度很快。
3.2 基于DBSCAN算法的交通出行分布異常檢測 過程
(1)通過小區切換法識別道路上的用戶
擁有智能手機的用戶在道路上發生語音或者數據業務的時候,信令會記錄用戶在連續多個小區發生的小區切換,如果一個用戶在一段時間內連續發生多個小區切換的現象,則認為該用戶的地理位置在道路上。表1是通過對信令數據提取的字段表:
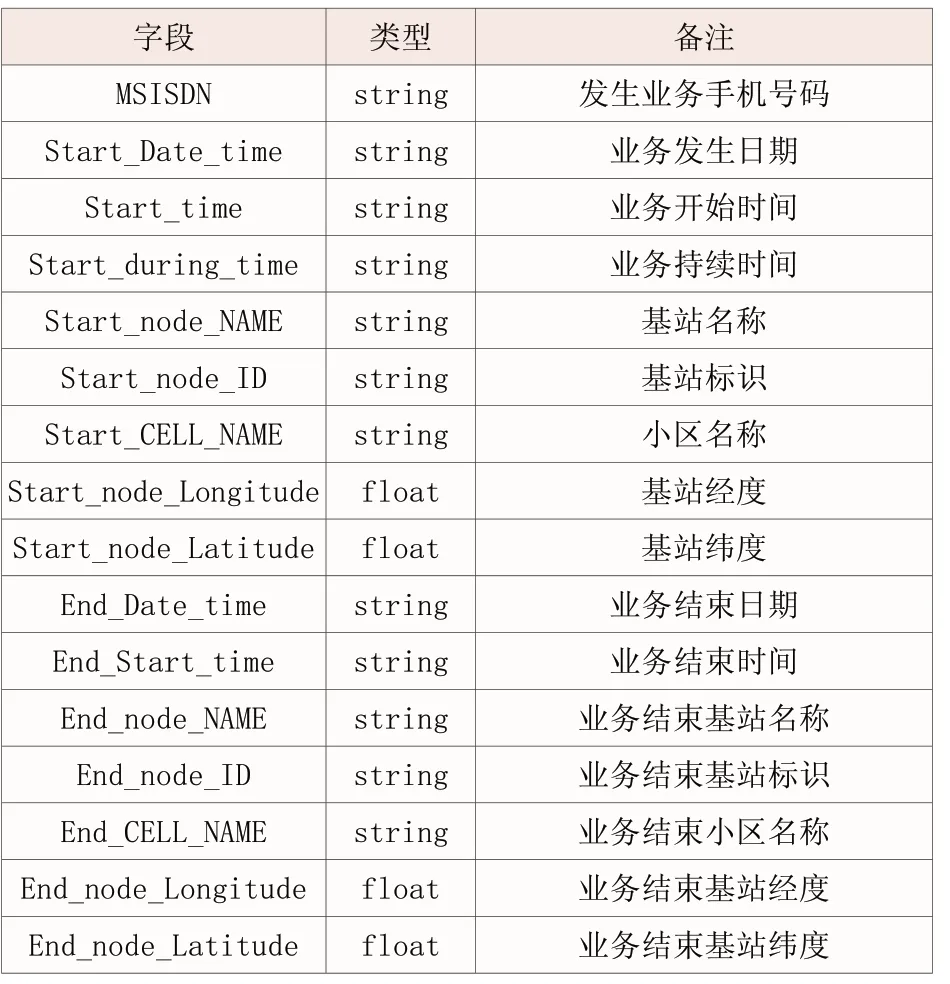
表1 基于小區切換法識別道路上用戶
(2)基于手機信令的用戶定位
1)路測方式獲得用戶定位的信息庫
本文首先把道路劃分成一個30m×30m的網格,然后利用路測方式確定每一個網格可能接收到的小區數量以及相應的場強,建立小區-網格定位的位置信息庫。
2)位置信息庫匹配定位的過程
信息庫定位算法最大特點就是僅僅通過小區就能實現用戶的定位,無需增加額外的設備。位置識別依靠表征目標特征的數據庫進行,其定位過程主要包括訓練階段和定位階段,具體如下:
◆訓練階段的目標在于建立一個位置信息識別數據庫。首先選擇參考點分布,確保能為定位階段的準確位置估計提供足夠的信息。接著依次在各個參考點上測量來自不同接收小區的電平,將相應的小區號碼與參考點的位置信息記錄在數據庫中,直至遍歷關注區域內所有的參考點。
◆在定位置信息識別數據庫后,依據一定的匹配算法將待測點上接收的小區號碼、電平值與數據庫中的已有數據進行比較,計算位置估計值。
3)基于KNN算法的位置識別
KNN(K-Nearest Neighbor,最鄰近規則)算法的基本原理是:首先計算測試點與識別庫中參考點之間的相似度距離,按照距離的降序選出前k個近鄰值,有以下公式:
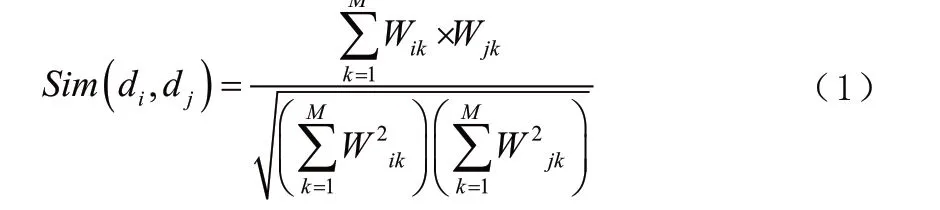
其次計算測試點的k個近鄰值每類的權重,計算公式如下:

(3)基于DBSCAN的交通出行分布異常檢測
1)交通出行分布異常點的確定
通過計算道路上出行用戶的局部密度,當局部密度大于設定的值時,則認為該點是交通出行分布異常點(異常點也就是異常網格),有如下公式:

其中,γi表示道路網格數據集與網格xi之間的距離小于設定距離的網格個數;δi表示設定的局部距離,一般該道路的總網格長度的1%~2%為最佳距離。
2)交通出行分布邊界的確定
一旦確定出行異常點,下一步就是對非異常網格進行歸類,具體步驟是:按照網格的密度從大到小進行遍歷;通過密度獲得每一個異常點的網格編號;按照密度大小的方法對異常點進行降序,按照每一個異常點所包含的網格密度的順序確定異常點的邊界。按照降序方法的好處在于異常點之間的交叉區域由于先進行了降序的處理而能夠快速確定邊界。
4 實驗結果
本文采用某地市某運營商提供的2015年8月1號到8月28號的IUCS接口數據和IUPS接口數據,IUCS數據約為3TGB,IUPS數據約為15TGB,包含400多萬用戶的數據,其中IUCS數據約150億條,IUPS數據約200億條,實驗結果如圖1所示:
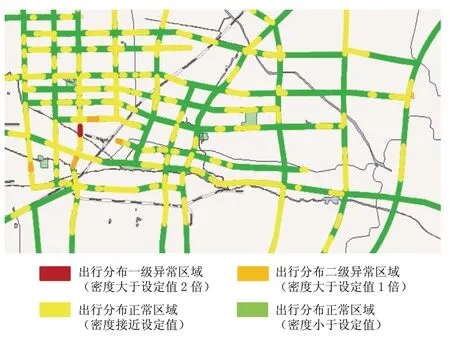
圖1 交通出行分布異常檢測圖
該系統是基于20個集群搭建的Hadoop平臺進行數據處理和分析,采用SSH框架實現Web的加載與渲染,以每0.5h為顆粒度來展現某地市道路出行分布異常檢測情況。本文把基于DBSCAN算法找出的交通異常點發生的區域與實際的交通路況進行驗證,情況基本比較吻合。
5 結束語
基于信令數據的交通出行分布異常檢測的方法不僅能夠快速發現交通出行分布的異常檢測,而且具有投資小、數據采集簡便、實用性強及計算復雜度小的優點,因此應強化其在智慧交通領域的應用。
[1] ESTER M, KRIEGEL H, SANDER J, et al. A densitybased algorithm for discovering clusters in large spatial databases with noise[C]. Portland: AAAI Press, 1996: 226-231.
[2] QIAN Wei-ning, GONG Xue-qing, AO Ying-zhou. Clustering in very large databases based on distance and density[J]. Journal of Computer Science and Technology, 2003,18(1): 67-76.
[3] ZHOU Shui-geng, ZHOU Ao-ying, CAO Jing, et al. A fast density-based clustering algorithm[J]. Journal of Computer Research and Development, 2000,37(11): 1287-1292.
[4] ESTER M, KRIEGEL H P, SANDER J, et al. Incremental clustering for mining in a data warehousing environment[C]. New York: Morgan Kaufmann, 1998: 323-333.
[5] Alex Rodriguez, Alessandro Laio. Clustering by fast search and find of density peaks[J]. Science, 2014,344(6191): 1492-1498.
[6] Rakesh A, Johanners G, Dimitrios G, et al. Automatic subspace clustering of high dimensional data for data mining applications[J]. Data Mining & Knowledge Discovery, 1994,27(2): 94-105.
[7] Hans-Peter Kriegel, Peer Kroger, Alexey Pryakhin, et al. Effective and efficient distributed model-based clustering[C]. Houston: Data Mining, 2005(11): 8-19.
[8] Maria Halkidi, Michalis Vazirgiannis. Clustering validity assessment: Finding the optimal partitioning of a data set[C]. California: Data Mining, 2001: 187-194.
[9] 熊忠陽,孫思,張玉芳,等. 一種基于劃分的不同參數值得DBSCAN算法[J]. 計算機工程與設計, 2005,26(9): 2319-2321.
[10] 楊靜. 分層模糊最小——最大聚類算法及其在圖像聚類中的應用研究[D]. 合肥: 合肥工業大學, 2007.
[11] 許慧. 基于數據分區和QR*樹的并行DBSCAN算法研究[D]. 哈爾濱: 哈爾濱工程大學, 2007. ★
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
海峽科技與產業(2016年3期)2016-05-17 04:32:12
商用汽車(2016年4期)2016-05-09 01:23:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
