一種基于郵件用戶行為分析的發件人信譽值生成方法
2015-04-13 04:14:18魏麗麗何慶戚國飛許敬偉
移動通信 2015年24期
魏麗麗,何慶,戚國飛,許敬偉
(1.中國移動通信集團廣東有限公司,廣東 廣州 510640;2.深圳市彩訊科技有限公司,廣東 深圳 518000)
1 引言
隨著互聯網技術的迅猛發展,電子郵件以其低成本、便捷、可查閱等特點有效解決了遠距離溝通的難題,是人與人之間日常溝通必不可少的重要工具。但是日益泛濫的垃圾郵件嚴重影響了人們的日常生活,如何高效地過濾垃圾郵件成為熱點議題。
調查顯示:2015年第一季度中國電子郵箱用戶平均每周收到14.6封垃圾郵件,占所有郵件的37.37%。其中,93%的被調查者都對他們接收到的大量垃圾郵件表示非常不滿。一方面,垃圾郵件消耗網絡資源、占用網絡帶寬、浪費用戶的寶貴時間、增加用戶的上網成本,影響企事業單位的日常辦公和溝通效率;另一方面,垃圾郵件成了計算機病毒傳播的途徑,垃圾郵件的傳播將嚴重威脅網絡安全,已成為網絡公害。
針對反垃圾郵件的方法,有研究者提出基于用戶反饋的個性化垃圾郵件過濾方法[1]:首先,根據用戶反饋提煉郵件分類特征,由此制定個性化郵件分類標準;其次,綜合全局郵件分類標準和個性化分類標準,利用樸素貝葉斯分類過程,完成用戶郵件的個性化分類。但是篩選參數會影響選取的郵件特征詞,當篩選參數取值較小或較大時,此方法在精確度方面的表現并不理想。還有學者提出了基于行為特征加權的決策樹過濾算法[2],這種方法將垃圾郵件的判斷轉化為郵件的路徑權值與垃圾郵件閾值的大小關系的判定。這種優化的算法在一定程度上可以提高篩選的精準性,但篩選結果的準確性受行為特征庫影響較大。
現有的這些技術都或多或少的存在缺點,無法進行百分之百的準確判斷。其中,也有學者提出一種基于用戶群組將信譽值高的用戶反饋的規則同步到信譽值低的用戶的方法,但是這種做法會使用戶的規則受到影響,無法反映用戶真實的情況,也無法對用戶的信譽值做實時的調整。垃圾郵件攔截準確率的提高迫切需要一種新的攔截技術。
基于此,本文提出基于郵件用戶行為分析的發件人信譽值生成方法,通過機器學習的方法,對線上產生的海量日志進行分析,選取多個特征維度,通過海量日志對特征模型進行訓練,對這些特征值生成了一個總體的信譽分值庫,實時的郵件匹配這個特征信譽庫,對滿足條件的發件人生成發件人特定的信譽值,提高信譽值的準確度。
2 反垃圾郵件過濾技術
對于垃圾郵件,主流的過濾技術有黑白名單、關鍵詞過濾、基于規則的過濾技術、Hash技術、貝葉斯過濾技術等。
黑名單(Black List)和白名單(White List)技術首先檢查郵件頭,如果白名單有發件人就接收該郵件[3],否則拒絕接收該郵件。這種方法可以百分之百屏蔽已確認的垃圾郵件制造者所生產的垃圾郵件,但是由于有些用戶是首次聯系收件人,尚未收錄在收件人的白名單內,所以黑名單與白名單技術會過濾掉此類正常通信郵件。此外,因為發送垃圾郵件時可以采用自動郵件偽造郵件發送者或域名,所以這種技術在垃圾郵件防范領域尚有改進空間。
由于某些垃圾郵件會以較高的頻率使用“贈送”、“禮包”等關鍵詞,如果標識一些垃圾郵件常用的單詞,并以此識別和處理垃圾郵件,那么就能有效攔截垃圾郵件,這就是關鍵詞過濾技術。基于這種識別原理,關鍵詞過濾技術極有可能導致誤判,比如設置單詞“test”為過濾關鍵字,那么所有含有“test”的郵件都將難逃濾網。
Hash技術是一種近似文本檢測技術,可以描述郵件的內容[4],計算Hash時通常以郵件的題目、發件人等元素作為參數。Hash技術正是利用了垃圾郵件網絡傳播的高密度性和內容高度相似性等特點,通過檢測所收郵件與已知類別郵件的相似性來區分郵件類別,是檢測垃圾郵件的有效技術手段。
除此之外,郵件系統還可以根據單詞、大小、位置、附件等特征元素制定規則[5],并以此描述和判別垃圾郵件。但該技術的缺點是如果要使過濾器有效,管理人員需要維護一個龐大的規則庫。
相比上述幾種過濾技術來說,貝葉斯算法更加智能化[6],是最為精確的攔截垃圾郵件的技術之一。它通過持續地學習跟進垃圾郵件的新規則,可使過濾準確率達到99%[7]。但美中不足的是,過濾的準確性依賴大量的歷史數據。
貝葉斯過濾器很難被繞過[8]。為了繞過郵件內容檢查,通常垃圾郵件發送者會減少信中的垃圾詞匯(如免費、禮包)或者在信中摻雜少許正式的詞匯(如會議、文件)。但由于貝葉斯具有強烈的個性化色彩,只有研究單個收件人的偏好才有機會繞過貝葉斯檢查,而這幾乎是不可能完成的任務。
3 基于用戶行為分析生成發件人信譽值 解決方案
3.1 方案說明
本文提出一種基于用戶行為分析生成發件人信譽值的方法,用來更好地過濾垃圾郵件。這種方法優化實現了對垃圾郵件的過濾,技術方案描述如下:
(1)初始階段:主要包括運行前準備和特征值錄入數據庫兩部分。
(2)發件人信譽值生成階段:主要根據用戶的歷史行為生成相應的信譽值。
(3)發件人信譽值入庫階段:根據發件人特征值的匹配結果進行后續操作。
3.2 方案具體實施方式
基于用戶行為分析生成發件人信譽值的流程圖如圖1所示:
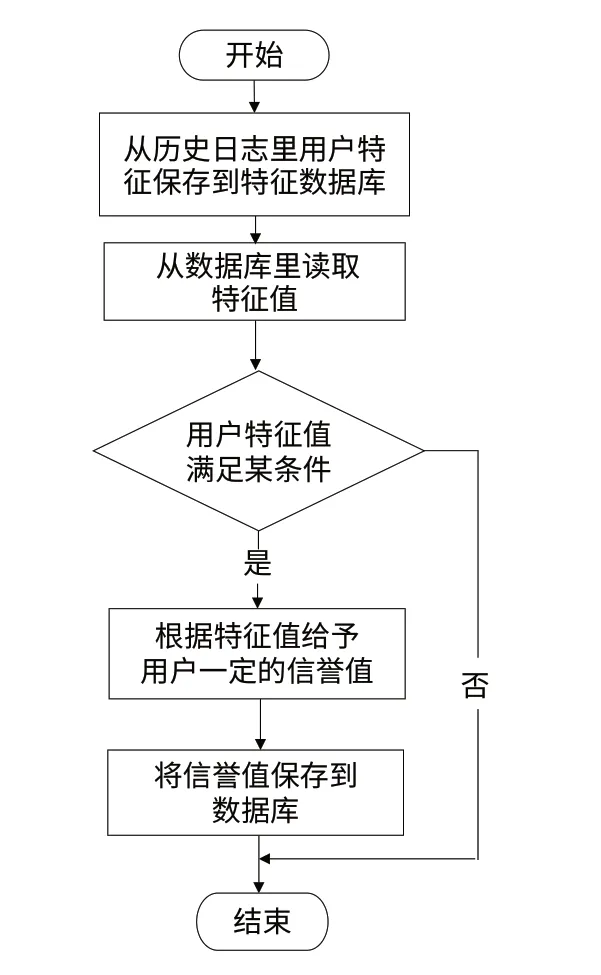
圖1 基于用戶行為分析生成發件人信譽值的流程圖
具體步驟如下:
(1)初始階段。初始化系統,加載配置文件,從日志信息中提取發信人特征值,連接特征數據庫等。
1)運行前準備,加載海量日志文件進行分析,從日志信息中提取郵件體大小、發信成功數、發信失敗數、發信總數、收件人回復數、郵件內容、發件人域名、IP發信成功數和失敗數等信息;
2)將日志提取的特征值保存到特征數據庫。
(2)發件人信譽值生成階段。本階段主要是通過對用戶歷史發信數、發信成功率、當天發信數、收件人是否回復以及郵件內容進行分析生成相應的信譽值,主要步驟如下:
1)從數據庫中提取特征值后進行判斷,如果發信人歷史發信總數小于3封,則數據量太少,無法生成信譽值,直接結束流程;
2)當歷史發信量超過3封,郵件發送成功率低于0.76時,設置信譽值為30分;
3)當發信成功率為100%,IP發信記錄成功率為100%,且收件人有回復、郵件內容匹配可信關鍵詞、郵件大小超過500KB或者有向可信域發信任何一個條件滿足時,設置信譽值為40分;
4)當發信量超過5封,發信失敗次數為0,收件人且總數超過3個,郵件含有可信關鍵詞時,設置信譽值為80分;
5)當發信量超過5封,發信失敗次數為0,如果當天發信量超過1封,且郵件匹配的可信關鍵詞超過2個、有向可信域發信、收件人有回信或者發送大小超過500KB的郵件超過2封任何一個條件滿足時,設置信譽值為80分;
6)當發信量超過5封,發信失敗數大于0到2封,是可信域發信,且當天發信量大于1封時,設置信譽值為70分;
7)當發信量超過5封,發信失敗數大于0到2封,有收件人回信,且當天發信量大于1封時,設置信譽值為70分;
8)當發信量超過5封,發信失敗數大于0到2封,郵件內容含有可信的關鍵詞,郵件內容匹配可信的關鍵詞超過2個,且當天發信量大于1封時,設置信譽值為70分;
9)當發信量超過5封,發信失敗數大于0到2封,郵件內容含有可信的關鍵詞,發送的郵件大小超過500KB至少為1封時,設置信譽值為70分;
10)當發信量超過5封,發信失敗數大于0到2封,郵件內容含有可信的關鍵詞,收件人有相同的且總數超過3個時,設置信譽值為70分;
11)當發信量超過5封,發信失敗數大于2到9封,發信失敗數為3且當天發信量小于3封時,設置信譽值為30分;
12)當發信量超過5封,發信失敗數大于2到9封,發信量大于20封,郵件內容匹配可信的關鍵詞個數超過4個,收件人總數超過12個且同名的人數超過4個時,設置信譽值為70分;
13)當發信量超過5封,發信失敗數大于2到9封,發信量大于20封,郵件內容匹配可信的關鍵詞個數超過4個且當天發信量超過4封時,設置信譽值為70分;
14)當發信量小于5封,發信失敗數大于0到2封,大小超過500KB的郵件至少為1封且郵件內容含有可信的關鍵詞時,設置信譽值為70分。
(3)發件人信譽值入庫階段。具體步驟如下:
1)若發件人的特征值匹配了上述的某一規則,則將生成的信譽值保存到數據庫中;
2)若發件人的特征值未匹配上述的任意一種規則,則將特征值保存到數據庫,供下次再次分析。
數據挖掘[9]是從海量的數據中提取潛在的、有價值的信息。通過對用戶長期的發信行為進行分析可知,用戶歷史發信行為對將來所發郵件的性質(是否為垃圾郵件)有一定的預見性[10],即如果發件人曾經有發送垃圾郵件的歷史,以后再發一封郵件是垃圾郵件的概率很高。經智能算法對用戶的發信行為進行分析可知,垃圾郵件具備以下特性:
(1)郵件大小不會太大,太大則會影響垃圾郵件的投遞速度。
(2)發送的成功率不高,某些郵件被反垃圾系統攔截。
(3)發送量大,郵件一般通過群發工具發送。
(4)收件人不會回復。
(5)郵件內容多為廣告、政治或色情言論。
(6)發信域名多為陌生域名。
3.3 本方法的過濾效果
本方法綜合考慮了郵件體大小、發信成功數、發信失敗數、發信總數、收件人回復數、郵件內容、發件人域名、IP發信成功數和失敗數等信息,建立了較完備的特征數據庫,可以有效提高匹配準確度;同時,將此次尚未定性的用戶信息存入數據庫,待達到標準后重新篩選,這種方式使得垃圾郵件的判斷更加便捷、準確。
為評估文中提出的基于郵件用戶行為分析的發件人信譽值生成方法在提升過濾準確率方面的效果,本文將對2015年3月至5月使用該方法的某郵箱的收件量、垃圾郵件所占比、低信譽發信人數及所中信譽占垃圾郵件比例等數據進行分析。具體數據如表1所示:
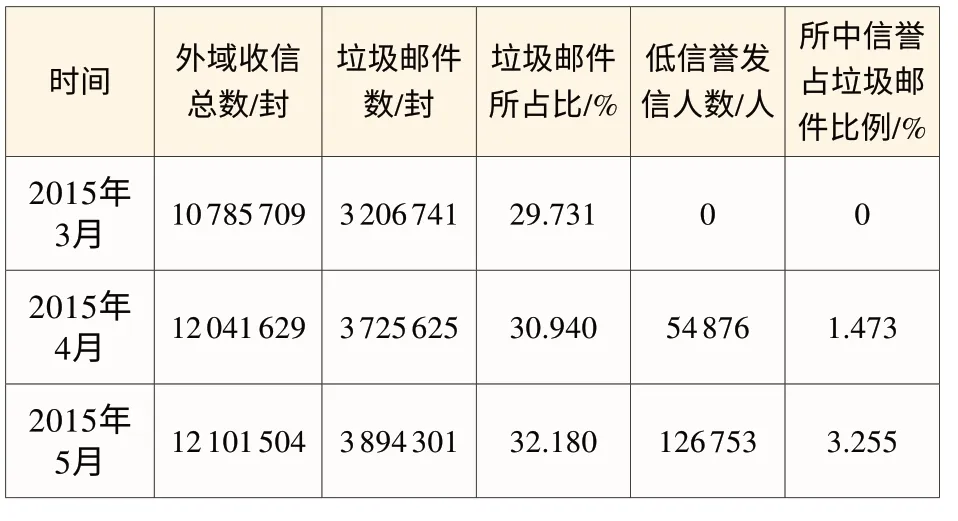
表1 某郵箱使用發件人信譽值生成方法前后的收件情況
由表1可知,3月該郵箱尚未使用文中所述的垃圾郵件過濾方法;4月時該方法正式投入使用,從3 206 741封垃圾郵件中累計識別低信譽發信人數為54 876人,該方法為垃圾郵件的判別作出1.473%的貢獻;5月時,隨著特征數據庫的不斷豐富,識別能力加強,在垃圾郵件數基本不變的情況下識別低信譽發信人數為126 753人,數量是4月的兩倍,該方法對垃圾郵件的判別貢獻也增至3.255%。可以看出,隨著使用時間的增加,該方法對垃圾郵件過濾的貢獻也會增加,這是因為海量郵件為數據庫提供了大量的垃圾郵件特征,極大地豐富了特征庫,有利于該方法對垃圾郵件的準確判斷。
4 結束語
隨著網絡的日趨復雜,反垃圾郵件技術的重要性和迫切性日益凸顯,垃圾郵件過濾技術作為處理垃圾郵件的主流技術之一,在處理垃圾郵件領域有著至關重要的作用。本文提出的解決方案主要是對海量日志進行用戶行為分析,綜合考慮垃圾郵件的主要特性如發件人發信總數、當天發信數量、發信成功率、郵件大小、郵件內容、可信域發信等信息生成發件人的信譽值。本方案避免了垃圾郵件的誤判或因某單一特征造成的信譽值偏差,可以更高效地過濾垃圾郵件,是現有垃圾郵件處理技術的有益補充。
但是該方法在垃圾郵件處理的初期表現欠佳,因為收件數量有限導致特征值數據庫有限,所以尚不能快速完成垃圾郵件的判斷。下一步將在算法方面做更多的探索,旨在通過優化算法來提高過濾初期的精確度。
[1] 黃國偉,劉云霞,陳志. 基于用戶反饋的個性化垃圾郵件過濾方法[J]. 電子設計工程, 2014,22(15): 53-56.
[2] 李璇. 基于行為識別的垃圾郵件過濾技術的研究與應用[D]. 武漢: 武漢理工大學, 2013.
[3] 詹川. 反垃圾郵件技術的研究[D]. 成都: 電子科技大學, 2005.
[4] 帖凱瑩. 垃圾郵件判決器的研究與設計[D]. 成都: 四川大學, 2006.
[5] 劉英戈. 一種可信的反垃圾郵件網格體系研究與實現[D]. 無錫: 江南大學, 2007.
[6] 陳渝,黃楚亮,吳志豪,等. 企業信息化中的反垃圾郵件技術[J]. 廣東科技, 2007(7): 63-64.
[7] 張啟宇. 基于貝葉斯算法的垃圾郵件過濾系統的研究與設計[D]. 曲阜: 曲阜師范大學, 2006.
[8] 閆龍,王文杰. 基于貝葉斯方法的一種垃圾郵件過濾的實現[J]. 微電子學與計算機, 2006,23(2): 86-88.
[9] 柳景超,宋勝鋒. 基于參考度的有效關聯規則挖掘[J]. 火力與指揮控制, 2011(5): 79-81.
[10] 董建設. 協作式垃圾郵件過濾關鍵技術研究[D]. 蘭州: 蘭州理工大學, 2009.★
