艦用語音云系統設計與實現
2015-03-27 07:18:34江蘇自動化研究所孫志宏
電子世界 2015年21期
江蘇自動化研究所 孫志宏
引言
語音交互的關鍵技術包括語音識別、語音合成。語音識別技術將用戶輸入的語音轉化為相應的文本或命令,語音合成技術將文本轉換成機器合成的語音。語音識別始于1950年代初,貝爾實驗室的Davis等人研究成功了第一個可識別10個英文數字的語音識別系統[1]。進入90年代后,語音識別在系統的自適應性、參數提取及優化等技術上取得了一些關鍵性的進展,開始走出實驗室走向市場化。2006年,Hint on提出了神經網絡的深度學習算法(DNN)[2],使得至少具有7層的神經網絡的訓練成為可能。2011年,微軟研究院的Fr ank Seide等人將DNN方法用于大詞匯量語音識別[3]研究中取得了重大突破,將非特定人語音識別錯誤率降低了30%。在語音合成技術的發展中,早期的研究主要是采用參數合成方法。1990年基音同步疊加(PSOLA)方法的提出,合成的語音的音色和自然度大大提高。今年來,基于數據庫的單元挑選及數據驅動建模技術的普遍應用,語音合成系統在可懂度、自然度上有了顯著提高[4]。
從產品的實現平臺上來看,當前市場上的語音系統主要分為3種:嵌入式的語音處理系統、服務器模式的語音系統及云計算模式的語音服務系統。嵌入式語音系統[5]是指應用微處理器在板級或是芯片級用軟件或硬件實現語音識別或合成技術,只適合做算法要求相對簡單,對資源的需求較少的語音處理。在服務器模式的語音系統中,終端只負責收集和傳導語音信號,由服務器負責完成識別及合成,隨著訪問量的增加,系統性能會達到瓶頸。云計算模式的語音識別系統和服務器模式的語音識別系統類似,但云[6]具有更好的擴展性,成本更加低廉,并且可以具有超大規模,給用戶提供前所未有的計算能力。云計算技術和語音識別相融合是一種新的趨勢。但現在市場上的產品只提供面向通用領域的語音處理服務,無法滿足特殊領域對語音服務的個性化需求及用戶極高的安全性要求。針對以上情形,本文提出并實現了一種面向艦用領域的語音云系統,針對該領域的武器裝備用戶的特殊需求,提供可定制的語音識別及合成服務,提高該領域的語音識別率及合成的可懂度,為用戶提供更自然更高效的人機交互方式。
本文首先研究了SOAP協議,并給出了基于SOAP協議的語音云服務流程。結合科大訊飛的語音識別及合成等API,實現了語音識別及合成技術與云計算技術的融合,即SSSCC (Speech Ser vice Syst em based on Cl oud Comput ing)系統。并在此基礎之上,給出了語音服務的可定制性方法,使得該系統能為艦用領域的用戶提供個性化服務。最后,通過實驗評估了系統的性能。
1 SOAP協議研究
1.1 SOAP協議介紹
近年來,隨著計算機技術的迅速發展,艦用電子信息系統運行環境越來越復雜,主要為跨平臺、多種操作系統的復雜系統。各系統之間的互聯、互通、互操作更加重要,對系統之間的通信和共享數據提出了更高的要求,要求各系統能夠通過網絡實現信息共享、進行數據交換,獲取一致性信息。而基于SOAP(Simpl e Obj ect Access Prot ocol)的通信協議能夠滿足以上需求。SOAP是一種在分散或分布式的環境中交換信息的簡單協議,它包括四個部分:SOAP封裝(envel op),SOAP編碼規則(encoding r ul es)SOAP RPC表示(RPC r epr esent at ion),SOAP綁定(binding),使用底層協議交換信息。
1.2 基于SOAP的語音服務流程
對于語音識別服務的應用程序,服務器端提供語音識別API。客戶端首先發送一個SOAP請求給服務器,服務端接受請求后,分配一個服務節點給客戶端,客戶端發送錄音數據給服務端,服務器節點把識別結果通過SOAP應答傳給客戶端。語音云和服務請求客戶端之間的通信基于SOAP協議,采用WSDL描述對外調用接口。客戶端開發時解析WSDL生成服務框架,基于框架開發服務調用過程。基于SOAP的語音服務流程如圖1所示:
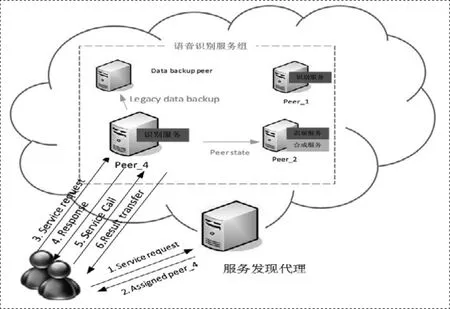
圖1 基于SOAP的語音服務流程
由上圖可知,客戶端通過SOAP發布語音識別服務請求后,服務發現代理分配Peer_4節點給該客戶端,客戶端語音識別請求傳給Peer_4節點,收到該節點的響應應答后,發起服務調用,將語音通過聲卡傳給Peer_4節點,該節點將識別結果返回給客戶端,一次語音識別過程結束。
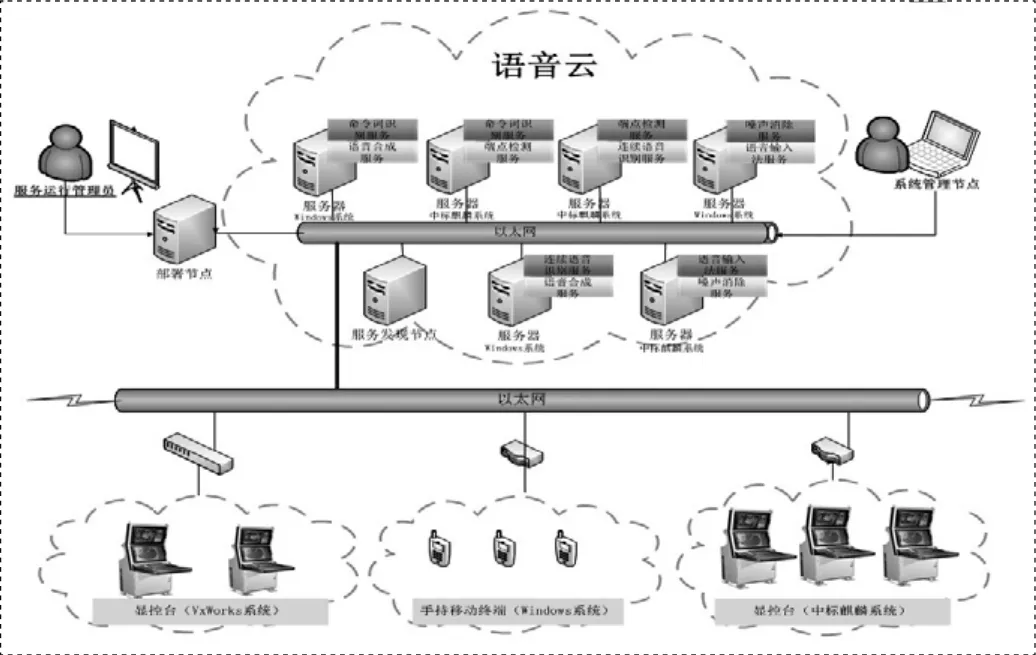
圖2 語音云服務拓撲結構
2 語音云服務系統(SSSCC系統)
2.1 語音云系統架構
云計算自底向上可以分為三個層次的服務:基礎設施即服務(IaaS),平臺即服務(PaaS)和軟件即服務(SaaS)。本文所做的語音服務是SaaS層次上的服務,把語音云發布出去,用戶通過網絡獲取語音交互服務。語音云服務拓撲結構如圖2所示:顯控臺或者手持終端發出語音服務請求,服務發現節點實時更新服務狀;服務部署節點按照用戶制定的部署策略將服務部署安裝到指定節點組成服務組,并實時監控所有節點的狀態;服務節點接受到請求之后,做出可提供服務應答,然后顯控臺或者手持終端發起語音服務調用,服務節點響應服務調用請求,返回語音識別或語音合成結果。
2.2 可定制性實現
所謂可定制性是指用戶可根據自身的需求,來定制自己所需要的產品和服務,以滿足自己的個性化需要。艦用語音服務的可定制性,是根據艦用裝備電子信息應用中專用系統應用需求不同提供合適的語音定制服務。可以通過兩種途徑來實現語音服務的可定制性。一種是針對應用情景形成專用的語法文檔,并開放給用戶可進行配置。第二種是針對專用系統對演算性能、響應時間、識別準確率及合成可懂度等需求不同,制定服務QoS策略,開放給用戶進行QoS配置,完成語音服務定制。
3 系統實現與評估
實驗室先前在PaaS層次搭建了一個云平臺,能提供服務的管理、部署等服務。下面通過實驗,分別測試云架構的語音識別系統和傳統的C/S架構的語音識別系統,對比二者在用戶請求數增長時對系統性能的影響。由于錄音環節會使得云端和服務端都處于閑置狀態,浪費大量時間和性能,所以本實驗通過直接上傳已經錄好的語音文件,使得云端和服務端滿負荷運行,達到測試云端和服務端的語音云性能的目的。
3.1 實驗環境
為了驗證SSSCC語音服務系統的性能,本文選擇了四臺一般的PC機搭建了一個較小的云計算平臺,配置為CPU是4核3.2Ghz,內存為4G,每臺PC機進行虛擬化,運行VxWor ks6.8操作系統或者window XP系統,提供語音識別、語音合成等服務。對于C/S架構的語音識別服務器,選擇任意一臺PC機充當。
3.2 性能對比
為了對比SSSCC語音服務系統和C/S架構的語音服務系統性能,設計實驗如下:首先實驗室人員在噪音小于60dB環境下,錄制1000個艦用專用詞錄音文件作為實驗數據,其次每個系統有10個用戶并發上傳錄音文件到云端,云端對錄音文件進行處理,然后返回識別結果。實驗獲得用戶上傳的文件數量與每個系統對不同數目請求的處理時間變化趨勢之間的關系,如圖3所示。圖中橫軸為每個用戶上傳的錄音文件數,縱軸為總的處理時間(從上傳第一個文件開始,到最后一個文件返回結果結束)。TRA代表傳統的C/S架構的語音服務系統,NCC代表云計算架構的語音服務系統,即SSSCC服務系統。由圖可知,當用戶請求量較少時,二者服務總時間時間相差不大,而當每個用戶的語音文件上傳量達到1100個時,C/S架構語音服務系統時間增長速率大大增加,遇到了服務性能瓶頸。可見云架構的語音識別系統隨著用戶請求量的增加,服務時間基本呈線性增長,因此SSSCC語音服務系統對于用戶請求劇烈增加的情形能夠提供性能穩定的服務,更符合語音交互服務的發展趨勢。
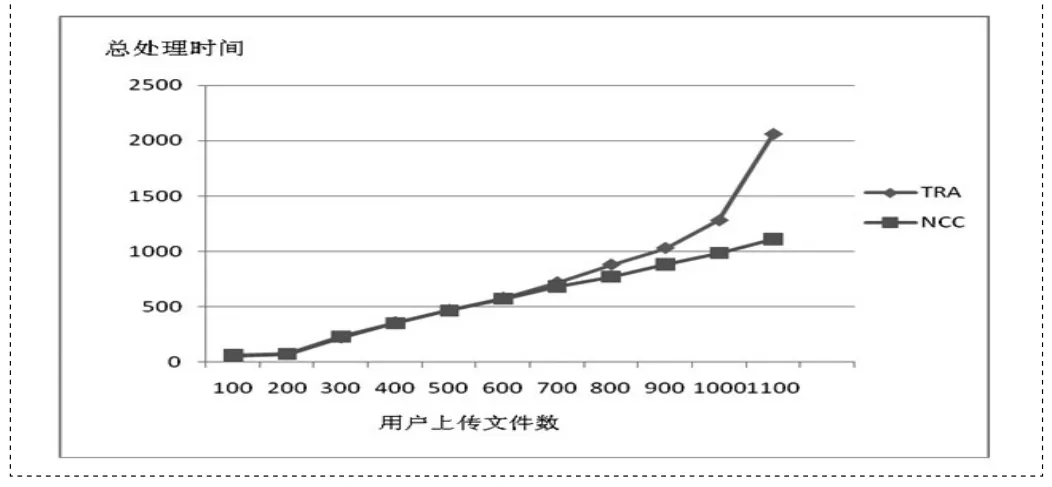
圖3 C/S架構與SSSCC語音服務系統性能比較
4 結束語
本文針對艦用電子信息系統對語音服務的個性化需求,研究了云計算架構及SOAP協議,構建了基于SOAP的艦用語音云服務平臺,實現了語音操控、語音輸入、語音合成等服務,并給出了語音服務的可定制性方法,使得該系統能為艦用領域的用戶提供個性化服務,為武器裝備系統提供了更自然、更高效的人機交互方式。
[1]Davis K H,Biddulph R,Balashek S.Automatic recognition of spoken digits[J].The Journal of the Acoustical Society of America,2005,24(6):637-642.
[2]Hinton,G.E.,Osindero,S.and Teh,Y.(2006) A fast learning algorithm for deep belief nets.Neural Computation,18, pp1527-1554.
[3]Frank Seide,Gang Li and Dong Yu.Conversational Speech Transcription Using Context-Dependent Deep Neural Networks.INTERSPEECH,2011.
[4]Black A.Perfect synthesis for all of the people all of the time[C].Proceedings of IEEE TTS Workshop 2002 Santa Monica,USA:2002:167-170.
[5]方敏,浦劍濤.嵌入式語音識別系統的研究和實現[J].中文信息學報,2004(6):73-75.
[6]Michael Armbrust,Armando Fox,Rean Grith et al.Above the clouds: A berkeley view of cloud computing[R].Technical Report UCB/EECS-2009-28:EECS Department,University of California,Berkeley,2009.
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
今日農業(2019年12期)2019-08-15 00:56:32
今日農業(2019年10期)2019-01-04 04:28:15
今日農業(2019年16期)2019-01-03 11:39:20
家庭影院技術(2017年9期)2017-09-26 03:41:45
商周刊(2017年9期)2017-08-22 02:57:56
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
