面向節(jié)點(diǎn)異構(gòu)GPU集群的編程框架
2015-01-06 08:21:51盛沖沖胡新明李佳佳吳百鋒
計算機(jī)工程 2015年2期
關(guān)鍵詞:分配
盛沖沖,胡新明,李佳佳,吳百鋒
(復(fù)旦大學(xué)計算機(jī)科學(xué)技術(shù)學(xué)院,上海201203)
面向節(jié)點(diǎn)異構(gòu)GPU集群的編程框架
盛沖沖,胡新明,李佳佳,吳百鋒
(復(fù)旦大學(xué)計算機(jī)科學(xué)技術(shù)學(xué)院,上海201203)
基于異構(gòu)GPU集群的主流編程方法是MPI與CUDA的混合編程或者其簡單變形。因?yàn)閷Φ讓拥募杭軜?gòu)不透明,程序員對GPU集群采用MPI與CUDA編寫應(yīng)用程序時需要人為考慮硬件計算資源,復(fù)雜度高、可移植性差。為此,基于數(shù)據(jù)流模型設(shè)計和實(shí)現(xiàn)面向節(jié)點(diǎn)異構(gòu)GPU集群體系結(jié)構(gòu)的新型編程框架分布式并行編程框架(DISPAR)。DISPAR框架包含2個子系統(tǒng):(1)代碼轉(zhuǎn)換系統(tǒng)StreamCC,是DISPAR源代碼到MPI+CUDA代碼的自動轉(zhuǎn)換器。(2)任務(wù)分配系統(tǒng)StreamMAP,具有自動發(fā)現(xiàn)異構(gòu)計算資源和任務(wù)自動映射功能的運(yùn)行時系統(tǒng)。實(shí)驗(yàn)結(jié)果表明,該框架有效簡化了GPU集群應(yīng)用程序的編寫,可高效地利用異構(gòu)GPU集群的計算資源,且程序不依賴于硬件平臺,可移植性較好。
GPU集群;異構(gòu);分布式并行編程框架;代碼轉(zhuǎn)換;任務(wù)分配;可移植性
1 概述
面向通用計算的GPU(GPGPU)以其大規(guī)模數(shù)據(jù)級并行計算能力和極其出色的性能功耗比特性,在當(dāng)下已經(jīng)成為了低能耗超級計算機(jī)和計算機(jī)集群追捧的加速器。在計算機(jī)集群中,不斷加入不同類型的GPGPU導(dǎo)致了集群內(nèi)部計算資源多樣化。集群底層硬件計算部件不斷更新、節(jié)點(diǎn)間計算資源的異構(gòu)程度不斷加劇,使得僅僅依靠現(xiàn)有的一些較低抽象層面的編程模型(如MPI、CUDA混合編程)設(shè)計出高效應(yīng)用程序變得更加困難。對于異構(gòu)計算,高性能的獲得往往伴隨著軟件開發(fā)的高復(fù)雜度[1]。由于依賴于硬件計算資源,并且需要程序員人為制定分配方案,這樣的任務(wù)劃分在復(fù)雜度較高時,難以得到與各個節(jié)點(diǎn)的計算能力相匹配的解決方案,從而不能有效地利用GPU集群的計算能力。并且以這樣的方式編寫應(yīng)用程序不僅對程序員的要求甚高,而且開發(fā)的程序可移植性差。簡而言之,不在較高抽象層將應(yīng)用任務(wù)按GPU集群架構(gòu)進(jìn)行劃分就不能很好地有效利用GPU集群的計算資源。
為解決這個問題,本文以數(shù)據(jù)流模型[2-3]為基礎(chǔ),將計算過程進(jìn)行流處理,設(shè)計并實(shí)現(xiàn)一種新型的能夠適應(yīng)節(jié)點(diǎn)異構(gòu)GPU集群體系結(jié)構(gòu)的分布式并行編程框架(Distributed Parallel Programming Framework,DISPAR)。DISPAR框架包含2個子系統(tǒng),即代碼轉(zhuǎn)換子系統(tǒng)StreamCC和任務(wù)分配子系統(tǒng)StreamMAP。
2 GPU集群與現(xiàn)有編程模型的不足
GPU集群是一種同時包含CPU和GPU兩種計算機(jī)資源的分布式并行計算系統(tǒng),其中CPU負(fù)責(zé)執(zhí)行應(yīng)用程序中的串行部分,而GPU則負(fù)責(zé)數(shù)據(jù)級的并行計算部分。不同的GPGPU不斷加入集群中導(dǎo)致節(jié)點(diǎn)間的計算能力差異化,造成了GPU集群在節(jié)點(diǎn)層面的異構(gòu)。典型的節(jié)點(diǎn)異構(gòu)GPU集群系統(tǒng)如圖1所示。
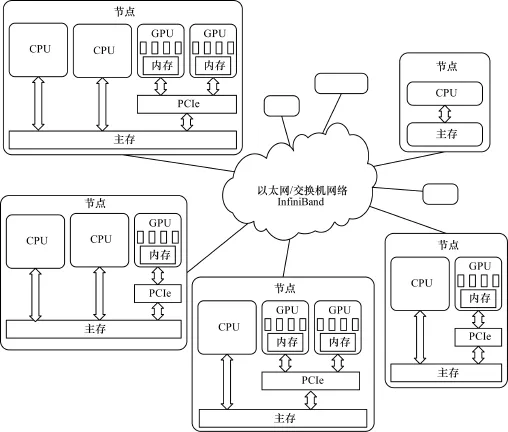
圖1 典型的節(jié)點(diǎn)異構(gòu)GPU集群系統(tǒng)
圖1反映了GPU集群在節(jié)點(diǎn)層次的異構(gòu)性。Intel最新推出的MIC架構(gòu)(Many Integrated Core Architecture)協(xié)處理器Xeon Phi也已經(jīng)開始作為加速器加入到GPU集群中[4],所以在可見的未來內(nèi),異構(gòu)集群將呈現(xiàn)多樣化、復(fù)雜化。
文獻(xiàn)[5-6]探討了基于MPI+OpenMP的對稱多處理器體系結(jié)構(gòu)的并行編程方法。但是對于GPU集群而言并不適用,因?yàn)镚PU集群的通信和內(nèi)存訪問特性并不同,這一點(diǎn)可以在文獻(xiàn)[7-8]中找到相關(guān)的論述。文獻(xiàn)[9-10]討論了對稱GPU集群的MPI+ CUDA模型。其中,MPI負(fù)責(zé)進(jìn)程的劃分和通信, CUDA負(fù)責(zé)面向數(shù)據(jù)級并行的GPU計算。它的不足之處主要在于,需要程序員了解底層的硬件拓?fù)湫畔硎謩油瓿扇蝿?wù)到節(jié)點(diǎn)的映射,比方說手動地將數(shù)據(jù)密集型的任務(wù)分配給含有GPU較多、計算能力較強(qiáng)的節(jié)點(diǎn)。顯然,當(dāng)集群規(guī)模較大、任務(wù)劃分更為復(fù)雜的時候,這種方法并不可取;另外手動分配需要適應(yīng)底層架構(gòu),影響程序的可移植性,這也是設(shè)計DISPAR時需要解決的問題。事實(shí)上也早有人在做基于GPU的數(shù)據(jù)流模型的研究[11],但大都還停留在模型描述上。
3 系統(tǒng)設(shè)計與實(shí)現(xiàn)
3.1 系統(tǒng)思想
在DISPAR編程框架下,一個應(yīng)用的處理過程被劃分為2類模塊:VNODE(虛擬節(jié)點(diǎn))和PIPE(連接管道)。虛擬節(jié)點(diǎn)VNODE處理算術(shù)和邏輯運(yùn)算等,通過單向的PIPE連接一對VNODE,從而為數(shù)據(jù)傳輸提供通信接口。虛擬節(jié)點(diǎn)可以調(diào)用CUDA(直接或者間接),是DISPAR數(shù)據(jù)級并行計算的處理單位。虛擬節(jié)點(diǎn)的這一抽象可以使得程序員把應(yīng)用程序的設(shè)計重心放到功能單元的劃分上。VNODE之間的數(shù)據(jù)傳輸通過PIPE進(jìn)行,連接管道在邏輯上表示功能單元的連接,在物理上表示進(jìn)程之間的聯(lián)系(進(jìn)程間通信或內(nèi)存的拷貝)。DISPAR框架基于數(shù)據(jù)流模型,它表達(dá)應(yīng)用的一個示例如圖2所示。
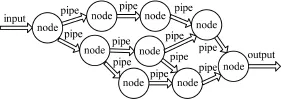
圖2 DISPAR表達(dá)應(yīng)用的示例
DISPAR的基本思想是為數(shù)據(jù)密集型計算的應(yīng)用提供一個任務(wù)劃分框架。在DISPAR框架下,開發(fā)人員可以從較高的抽象層出發(fā),采用自頂向下的設(shè)計方法進(jìn)行層次化的程序設(shè)計。按功能層次化方式劃分的功能處理單元(可以看成是VNODE)往往更具有數(shù)據(jù)并行性,適合利用GPU kernel程序加速。
開發(fā)人員將編寫好的DISPAR程序經(jīng)過StreamCC預(yù)處理器自動轉(zhuǎn)換為MPI,CUDA混合程序,然后通過運(yùn)行時系統(tǒng)StreamMAP進(jìn)行任務(wù)分析;根據(jù)StreamCC產(chǎn)生的VNODE信息和資源信息數(shù)據(jù)庫來自動生成任務(wù)映射配置文件,最終程序通過集群的MPI環(huán)境執(zhí)行。具體的流程見圖3。DISPAR框架的特點(diǎn):(1)高效性:從較高的抽象層出發(fā),采用自頂向下的設(shè)計方法,無需考慮硬件資源。(2)移植性:隱藏了進(jìn)程的顯式劃分,根據(jù)不同的集群系統(tǒng)自動生成程序配置文件,通過預(yù)編譯分析的手段提供一個虛擬層,運(yùn)行時確定任務(wù)映射。(3)透明性:通過VNODE和PIPE的定義,封裝了顯式的進(jìn)程劃分和通信,通過生成中間虛擬層(MPI程序配置文件)將虛擬節(jié)點(diǎn)與物理節(jié)點(diǎn)分離。
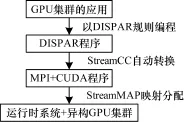
圖3 DISPAR處理流程
3.2 StreamCC預(yù)處理子系統(tǒng)
DISPAR框架通過定義一套新的以VNODE和PIPE為核心的語法,指導(dǎo)用戶編寫基于DISPAR框架語言的程序。然后StreamCC通過詞法分析和語法分析將其轉(zhuǎn)換為MPI,CUDA混合代碼。這樣一種引導(dǎo)用戶以數(shù)據(jù)流模型的思想來編寫程序的方式,避免原有MPI要求的進(jìn)程顯示劃分,簡化了應(yīng)用的描述和程序的設(shè)計。StreamCC主要實(shí)現(xiàn)了2個核心轉(zhuǎn)換:(1)VNODE到MPI/CUDA進(jìn)程的轉(zhuǎn)換。(2)將PIPE通信接口自動轉(zhuǎn)換為MPI相應(yīng)的MPI_ SEND和MPI_RECV調(diào)用。圖4為StreamCC的流程框架。
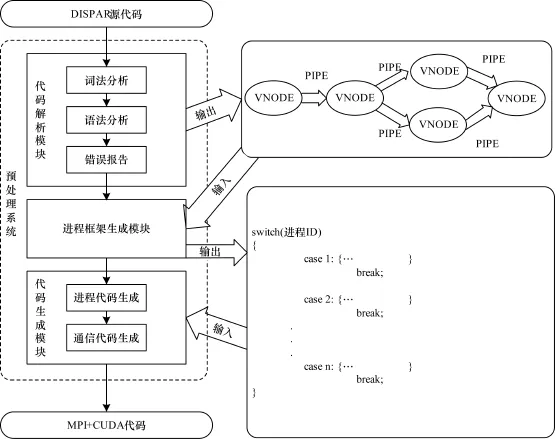
圖4 StreamCC流程圖框架
從圖4可見,StreamCC依次包含3個模塊: (1)代碼解析模塊,對DISPAR代碼源程序進(jìn)行詞法、語法分析,解析VNODE和PIPE的關(guān)聯(lián)信息,并寫入HASH表,供下一個模塊使用。(2)進(jìn)程框架生成模塊,根據(jù)HASH表中的虛擬節(jié)點(diǎn)VNODE的使用情況(由模塊1來標(biāo)記)來確定將要生成的MPI程序中case語句(對應(yīng)各個進(jìn)程行為)的結(jié)構(gòu),從而為每個虛擬節(jié)點(diǎn)分配一個進(jìn)程ID。該模塊只完成一個轉(zhuǎn)換的框架,真正的代碼轉(zhuǎn)換由下一個模塊完成。(3)代碼生成模塊,讀取HASH表中連接管道PIPE的信息(也就VNODE的連接關(guān)系,用來表示DISPAR的數(shù)據(jù)輸入與輸出),將其轉(zhuǎn)化為MPI程序的通信原語。
3.3 StreamMAP任務(wù)分配子系統(tǒng)
DISPAR框架借鑒了OpenMP,OpenACC[12]等的編譯制導(dǎo)(Compiler Directive)特性,StreamMAP以擴(kuò)展C編譯器前端的方式提供對編譯制導(dǎo)指令的支持,從而引導(dǎo)開發(fā)人員在源程序中顯示地指明VNODE計算資源的需求。語法表示為:#pragma streamap directive[clause[[,]clause]…],其中directive可以為resource(表示計算資源,可以指明為CPU或者GPU),也可以為communication(表示通信關(guān)系)。
StreamMAP作為一個運(yùn)行時系統(tǒng)完成DISPAR框架下應(yīng)用程序的任務(wù)至計算資源(物理節(jié)點(diǎn))的映射。在安裝配置完DISPAR后,集群啟動時首先完成節(jié)點(diǎn)計算資源的自動發(fā)現(xiàn)(通過Linux的系統(tǒng)調(diào)用和CUDA的設(shè)備查詢語句),然后動態(tài)建立資源信息庫(包括CPU和GPU的配置信息,如數(shù)目、計算能力、內(nèi)存,以及各個物理計算節(jié)點(diǎn)的拓?fù)浣Y(jié)構(gòu))。DISPAR會開啟一個后臺進(jìn)程來維護(hù)這個資源信息數(shù)據(jù)庫。StreamMAP分析VNODE內(nèi)部計算資源的需求和PIPE通信的傳輸,詢問資源信息數(shù)據(jù)庫得到各個節(jié)點(diǎn)的物理計算能力和分配情況,然后動態(tài)地映射和分配任務(wù),以實(shí)現(xiàn)平臺無關(guān)性;也就是說當(dāng)集群拓?fù)浣Y(jié)構(gòu)改變時(如加入新節(jié)點(diǎn)、節(jié)點(diǎn)失效等),應(yīng)用程序不需要做任何改動就可以運(yùn)行在這個新集群上。StreamMAP處理過程可見圖5。
StreamMAP主要包括編譯制導(dǎo)解析模塊、計算資源發(fā)現(xiàn)模塊和任務(wù)映射分配模塊;前2個模塊分別實(shí)現(xiàn)了應(yīng)用程序資源需求(產(chǎn)生需求拓?fù)鋱D)和各個物理節(jié)點(diǎn)計算資源(產(chǎn)生節(jié)點(diǎn)資源表)的分析與發(fā)現(xiàn),而最后一個模塊給出任務(wù)分配方案(需求拓?fù)鋱D和節(jié)點(diǎn)資源表建立匹配,生成配置文件)。虛擬節(jié)點(diǎn)VNODE有2種可能的資源需求:CPU-only(用CO表示)或CPU+GPU(用CG表示),通過掃描VNODE的源代碼,尋找有無針對GPU的CUDA kernel調(diào)用,來判定需求類型。以資源需求作為頂點(diǎn),管道連接作為弧的圖就是需求拓?fù)鋱D(Require Topology Graph,RTG)。
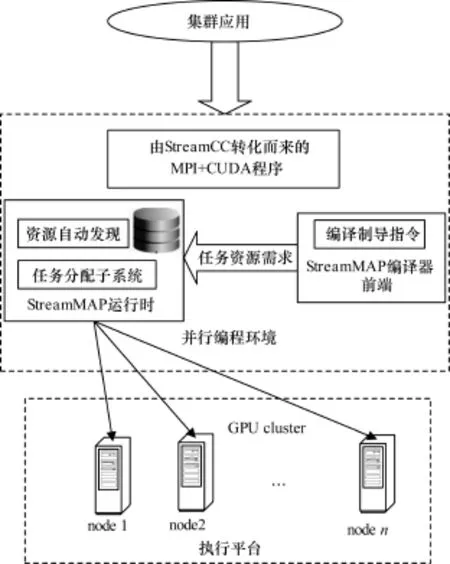
圖5 StreamMAP處理過程
為了更好地描述分配算法,用符號CRT表示只含CPU節(jié)點(diǎn)的資源表,GRT表示同時含有CPU, GPU節(jié)點(diǎn)的資源表。CRT={n1,n2,…,nk},GRT= {n1,n2,…,nm}。ni=(ID,total,available)。其中, ID表示節(jié)點(diǎn)標(biāo)識;total表示節(jié)點(diǎn)計算資源(CPU或CPU-GPU對)數(shù)量;available表示當(dāng)前可用的數(shù)量。各個節(jié)點(diǎn)在初始階段total與available相等,可以在total和available變量之后加_co或_cg的后綴以區(qū)分不同計算資源。CRT和GRT各有一個指向表內(nèi)第一個節(jié)點(diǎn)的指針,算法的具體過程如下:
Step 1選取RTG起始頂點(diǎn)作為當(dāng)前頂點(diǎn)。
Step 2若當(dāng)前頂點(diǎn)的類型為CG,執(zhí)行下一步,否則跳至Step4。
Step 3檢查GRT節(jié)點(diǎn)表指針是否為NULL,若是則跳至Step5;若不是則把當(dāng)前節(jié)點(diǎn)分配給當(dāng)前頂點(diǎn),相應(yīng)的available_cg減1(如果變?yōu)?則指針移到GRT中下一個節(jié)點(diǎn)),跳至Step7。
Step 4檢查CRT節(jié)點(diǎn)表指針是否為NULL,若是則跳至Step3;若不是則把當(dāng)前節(jié)點(diǎn)分配給當(dāng)前頂點(diǎn),相應(yīng)的available_co減1(如果變?yōu)?則指針移到GRT中下一個節(jié)點(diǎn)),跳至Step7。
Step 5若當(dāng)前頂點(diǎn)為CG類型,檢查相鄰的頂點(diǎn)是否CG類型并已被分配,若是則分配到同一節(jié)點(diǎn)并跳至Step7,否則執(zhí)行Step6。若當(dāng)前頂點(diǎn)為CO類型,檢查相鄰的頂點(diǎn)是否已被分配,若是則分配到同一節(jié)點(diǎn)并跳至Step7,否則執(zhí)行Step6。
Step 6若當(dāng)前頂點(diǎn)為CG類型,則分配到任意CG節(jié)點(diǎn)(低負(fù)載節(jié)點(diǎn)優(yōu)先)并跳至Step7。若當(dāng)前頂點(diǎn)為CO類型,則分配到任意節(jié)點(diǎn)(低負(fù)載節(jié)點(diǎn)優(yōu)先)并跳至Step7。
Step 7取與之相鄰的未分配頂點(diǎn)為當(dāng)前頂點(diǎn),跳至Step2;若相鄰的未分配頂點(diǎn)不存在,則隨機(jī)任取一個未分配頂點(diǎn)作為當(dāng)前頂點(diǎn),進(jìn)入Step2,若所有頂點(diǎn)均被分配,算法結(jié)束。
該算法中有4個原則:(1)一個頂點(diǎn)只能分配到一個節(jié)點(diǎn);(2)CG頂點(diǎn)只能分配給CG節(jié)點(diǎn),CO頂點(diǎn)可分配給CO或CG節(jié)點(diǎn);(3)盡可能保證負(fù)載平衡;(4)相鄰頂點(diǎn)優(yōu)先分配到同一節(jié)點(diǎn),以減少通信代價。
4 實(shí)驗(yàn)及結(jié)果分析
4.1 實(shí)驗(yàn)環(huán)境
本文實(shí)驗(yàn)采用了一個節(jié)點(diǎn)異構(gòu)的小型GPU集群,集群包含4個節(jié)點(diǎn),通過交換機(jī)網(wǎng)絡(luò)InfiniBand QDR相連。所有節(jié)點(diǎn)安裝的Linux系統(tǒng)均為Ubuntu Server10.04 LTS,MPI采用開源的MPICH。采用數(shù)字信號處理領(lǐng)域常見的FIR數(shù)字濾波程序。集群配置詳單如表1所示。
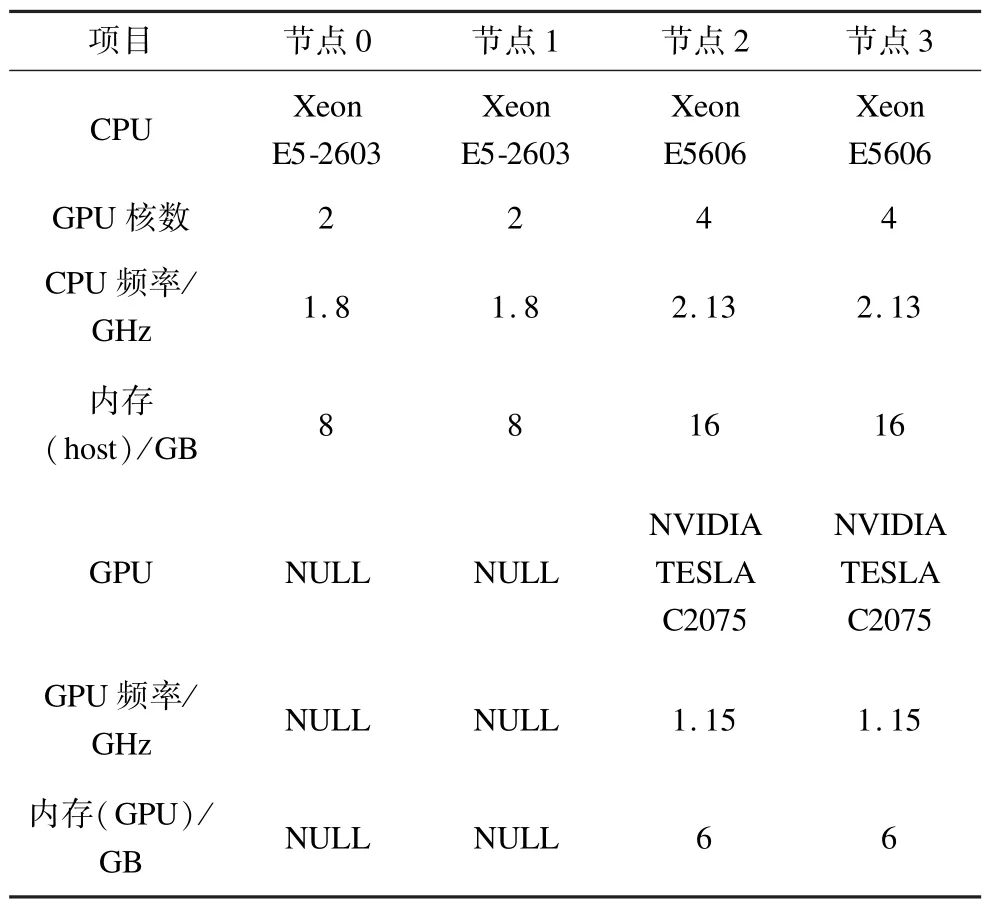
表1 集群配置
4.2 實(shí)驗(yàn)方法
分別采用3種方法實(shí)現(xiàn)上述例程:(1)MPI與CUDA直接混合編程,任務(wù)映射由MPI以隨機(jī)的方式完成。(2)MPI與CUDA人工優(yōu)化編程,由程序員分析出最優(yōu)的任務(wù)映射,寫入MPI程序配置文件。(3)在DISPAR框架下以數(shù)據(jù)流模型實(shí)現(xiàn)代碼,并由StreamCC實(shí)現(xiàn)代碼轉(zhuǎn)換后由StreamMAP自動產(chǎn)生適應(yīng)集群架構(gòu)的MPI程序配置文件。分別以上述3種方式實(shí)現(xiàn)并運(yùn)行,得出實(shí)驗(yàn)數(shù)據(jù)并分析。
4.3 實(shí)驗(yàn)結(jié)果
3種方法編寫同一個應(yīng)用程序時,代碼規(guī)模和運(yùn)行時間的如圖6和圖7所示。
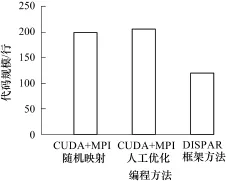
圖6 代碼規(guī)模比較
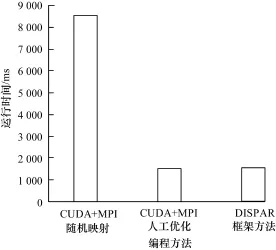
圖7 運(yùn)行時間比較
從代碼規(guī)模比較來看,方法(3)采用DISPAR描述應(yīng)用最為簡單,方法(1)和方法(2)代碼規(guī)模幾乎沒有差異,但僅僅從代碼規(guī)模看并不能完全體現(xiàn)代碼實(shí)現(xiàn)復(fù)雜度,方法(2)人工找出最優(yōu)的分配方案,需要程序員付出更多的時間代價。從運(yùn)行時間角度看,方法(3)和人工優(yōu)化過的方法(2)具有相近的運(yùn)行時間,比隨機(jī)映射的方法(1)有明顯的加速,這是因?yàn)镸PI的隨機(jī)映射完全不考慮節(jié)點(diǎn)的計算能力,當(dāng)任務(wù)分配不合理時,不能有效地利用GPU加速。所以由此可知,DISPAR編程框架方法可以以較低的實(shí)現(xiàn)難度得到理想的加速效果。
5 結(jié)束語
本文論述一種新型的面向節(jié)點(diǎn)異構(gòu)GPU集群的編程框架DISPAR。通過代碼轉(zhuǎn)化和自動任務(wù)分配改進(jìn)原有的MPI,CUDA混合編程模型。DISPAR編程框架方法實(shí)現(xiàn)了在異構(gòu)計算時以較低的編程難度得到理想加速效果的目標(biāo)。后續(xù)研究可以考慮將DISPAR框架與GPU虛擬化技術(shù)[13]相結(jié)合,從而更好地利用集群的計算資源。
[1] Diamos G,Yalamanchili S.Harmony:An Execution Model and Runtime for Heterogeneous Many Core Systems[C]//Proceedings of the17th International Symposium on High Performance Distributed Computing.[S.l.]:ACM Press,2008:197-200.
[2] Whiting P G,Pascoe R S V.A History of Data-flow Languages[J].IEEEAnnalsoftheHistoryof Computing,1994,16(4):38-59.
[3] Keller R M.Data Flow Program Graphs[J].Computer, 1982,15(2):26-41.
[4] Dokulil J,Bajrovic E,Benkner S,et al.High-level Support for Hybrid Parallel Execution of C++ ApplicationsTargetingIntelXeonPhiCoprocessors[C]//Proceedings of International Conference on Computational Science.[S.l.]:Springer,2013.
[5] 王惠春,朱定局,曹學(xué)年,等.基于SMP集群的混合并行編程模型研究[J].計算機(jī)工程,2009,35(3): 271-273.
[6] 陳 勇,陳國良,李春生,等.SMP機(jī)群混合編程模型研究[J].小型微型計算機(jī)系統(tǒng),2004,25(10): 1763-1767.
[7] Wu Yongwen,SongJunqiang,LuFengshun,etal. Communication and Memory Access Latency Characteristics of CPU/GPU Heterogeneous Cluster[C]//Proceedings of International Conference on Computational and Information Sciences.Chongqing,China:[s.n.],2012: 958-961.
[8] Kindratenko V V,Enos J J,Shi Guochun,et al.GPU ClustersforHigh-performanceComputing[C]// Proceedings of IEEE International Conference on Cluster Computing.[S.l.]:IEEE Press,2009:1-8.
[9] 許彥芹,陳慶奎.基于SMP集群的MPI+CUDA模型的研究與實(shí)現(xiàn)[J].計算機(jī)工程與設(shè)計,2010,31(15): 3408-3412.
[10] 滕人達(dá),劉青昆.CUDA、MPI和OpenMP三級混合并行模型的研究[J].微計算機(jī)應(yīng)用,2010,31(9):63-69.
[11] 鄭楊楊.基于GPU的數(shù)據(jù)流通用處理模型[D].大連:大連理工大學(xué),2011.
[12] OpenACC.OpenACC.1.0.pdf[EB/OL].(2013-11-09).http://openacc.org/Downloads.
[13] Shi Lin,ChenHao,SunJianhua.vCUDA:GPU Accelerated High Performance Computing in Virtual Machines[J].IEEE Transactions on Computers,2009, 61(6):408-416.
編輯 顧逸斐
Programming Framework for Node Heterogeneous GPU Cluster
SHENG Chongchong,HU Xinming,LI Jiajia,WU Baifeng
(School of Compute Science,Fudan University,Shanghai 201203,China)
The mainly used programming method for heterogeneous GPU cluster is hybrid MPI/CUDA or its simple deformation.However,because of its transparency to underlying architecture when using hybrid MPI/CUDA to write code for heterogeneous GPU cluster,programmers tend to need detailed knowledge of the hardware resources,which makes the program more complicated and less portable.This paper presents Distributed Parallel Programming Framework (DISPAR),a new programming framework for node-level heterogeneous GPU cluster based on data flow model. DISPAR framework contains two sub-systems,StreamCC and StreamMAP.StreamCC is a code conversion tool which coverts DISPAR code into hybrid MPI/CUDA code.StreamMAP is a run-time system which can detect heterogeneous computing resources and map the tasks to appropriate computing units automatically.Experimental results show that the methods can make efficient use of the computing resources and simplify the programming on heterogeneous GPU cluster. Besides,it has better portability and scalability as the code does not rely on the execution platform.
GPU cluster;heterogeneous;Distributed Parallel Programming Framework(DISPAR);code conversion; task assignment;portability
盛沖沖,胡新明,李佳佳,等.面向節(jié)點(diǎn)異構(gòu)GPU集群的編程框架[J].計算機(jī)工程,2015,41(2):292-297.
英文引用格式:Sheng Chongchong,Hu Xinming,Li Jiajia,et al.Programming Framework for Node Heterogeneous GPU Cluster[J].Computer Engineering,2015,41(2):292-297.
1000-3428(2015)02-0292-06
:A
:TP391
10.3969/j.issn.1000-3428.2015.02.056
復(fù)旦大學(xué)ASIC和系統(tǒng)國家重點(diǎn)實(shí)驗(yàn)室基金資助項(xiàng)目;華為創(chuàng)新研究計劃基金資助項(xiàng)目。
盛沖沖(1988-),男,碩士研究生,主研方向:嵌入式系統(tǒng),并行計算;胡新明、李佳佳,碩士;吳百鋒,教授。
2014-03-12
:2014-04-03E-mail:11210240001@fudan.edu.cn
猜你喜歡
天水行政學(xué)院學(xué)報(2022年4期)2022-11-18 09:02:36
艦船科學(xué)技術(shù)(2022年13期)2022-08-11 09:30:02
鐵道通信信號(2020年9期)2020-02-06 09:15:22
漢語世界(The World of Chinese)(2019年3期)2019-07-01 02:37:48
數(shù)學(xué)大王·趣味邏輯(2019年5期)2019-06-13 20:27:43
小學(xué)科學(xué)(學(xué)生版)(2019年5期)2019-05-21 01:00:18
中學(xué)生數(shù)理化·中考版(2018年10期)2018-12-07 00:44:52
經(jīng)濟(jì)技術(shù)協(xié)作信息(2018年30期)2018-11-22 06:20:24
中央社會主義學(xué)院學(xué)報(2017年1期)2017-04-16 05:34:07
中國衛(wèi)生(2014年12期)2014-11-12 13:12:40
