基于話題標簽的微博主題挖掘
2015-01-02 02:00:50劉少鵬潘雅麗
計算機工程 2015年4期
李 敬,印 鑒,劉少鵬,潘雅麗
(中山大學信息科學與技術學院計算機科學系,廣州510006)
1 概述
微博是一種新興的社交網絡服務,用戶可以通過登錄微博客戶端來發布短文本消息,同時可以附帶鏈接、圖片和視頻等多媒體資源,與好友進行信息的及時分享。海量微博數據蘊含著豐富的信息,從中挖掘出有效的微博主題,對信息提取與用戶分析具有重要意義。
微博與傳統文本(新聞、論文等)不同,作為短文本消息,微博中詞項的共現信息匱乏,并且沒有特定的語法結構,因此簡單地套用傳統文本主題挖掘的方法很難挖掘有用的微博主題[1]。針對微博的稀疏性和非結構化特點,近年來學者在研究潛在狄利克雷分布(Latent Dirichlet Allocation,LDA)[2]的基礎上引入聯系人的關系[3]、新聞鏈接[4]和時間信息[5]等外部信息來挖掘微博主題,并取得了較好成效。研究結果表明,微博本身隱含的用戶信息與社交網絡信息可以促進微博主題挖掘。然而目前研究并沒有明確地從用戶興趣、用戶互動和話題微博3種微博類型上將微博主題進行劃分,無法同時挖掘出不同微博類型下的主題分布。
本文結合用戶興趣、會話標簽(@)、轉發標簽(RT@)和話題標簽(含有#hashtag),對不同微博類型進行主題劃分分析,提出一個新的在微博平臺下適用的話題標簽主題模型HC-ATM(Hash Tag Conversation Author Topic Model),并給出與 HCATM相對應的Gibbs抽樣推導結果。
2 相關工作
主題模型是近年來在文本挖掘領域最受關注的方法之一,是一種概率生成模型,它常被用于挖掘大規模文檔集的潛在主題。主題模型挖掘的主題與人類對文本的理解較接近,體現出文本間的語義關系。
2.1 主題模型
LDA[2]作為主題模型的典型代表,避免了pLSI[6]中由于參數過多而導致的過擬合問題,同時還可以對訓練集之外的文檔進行概率估計。LDA將每篇文檔看做是多個主題的概率分布,而其中的每個主題則是多個單詞的概率分布。在LDA中,一篇文檔內的單詞是可交換的,文檔與文檔之間也是條件獨立同分布的。在給定主題個數K的情況下,先生成每篇文檔中單詞的主題,然后再由主題分布生成該單詞。根據LDA對文檔生成過程的假設,可以使用參數估計方法反向推導概率模型,求得每個主題下的詞項分布和每篇文檔下的主題分布,進而揭示文檔主題結構。常用的推導方法有變分貝葉斯[2]、Gibbs抽樣[7]、期望值傳播[8]等。
隨著對主題模型的深入研究,衍生出了適用于各類具體應用的主題模型。文獻[9]提出用于挖掘主題之間相關性的相關主題模型(Correlated Topic Model,CTM),文獻[10]通過引入文檔的作者信息,提出作者主題模型(Author Topic Model,ATM),此外還有結合時間信息對文檔進行建模分析的主題模型 ToT(Topics over Time)[11]和 DTM(Dynamic Topic Models)[12]等。
2.2 微博主題挖掘
相比于傳統文本,微博缺乏詞項共現信息,數據十分稀疏,直接使用傳統主題模型難以挖掘出有用的主題信息。研究者從不同角度出發,提出了適用于不同應用場景的微博主題模型。Labeled-LDA[13]是一個監督主題模型,它將微博內容映射到substance,style,status和 social 4 個維度,用以劃分不同主題下的用戶和微博。文獻[14]結合用戶興趣、時間信息和背景信息,構建出與時間片序列相關的主題分布,將微博主題挖掘的結果用來分析、探測爆發性的新聞話題。微博LDA(Microblog LDA,MBLDA)[3]利用微博會話引入聯系人關聯關系,用于改善微博的主題挖掘效果。文獻[13]通過最小化消息序列主題的預測誤差來求解主題轉移矩陣,用于預測用戶未來微博的主題分布。文獻[15]把每對詞項的共現模式融入到文本生成過程中,得到適用于挖掘問答系統和微博的主題模型。文獻[16]利用微博主題對用戶進行建模,根據用戶特征表示與微博特征的相似性程度對用戶進行微博推薦。
由于微博的特殊性,當前模型傾向于關注用戶內在興趣,并沒有充分利用微博中的會話、轉發和話題標簽,無法同時得到用戶興趣、用戶互動和話題微博下的主題分布。文獻[3]考慮了會話、轉發標簽,但是沒有考慮話題標簽,無法挖掘話題標簽下的主題分布,也無法發現描述相同話題的話題標簽。文獻[13]主要是偏向于利用話題標簽來對微博進行主題分析,無法獲取用戶之間互動的主題分布。
3 微博主題挖掘模型設計與實現
3.1 作者主題模型
作者主題模型[11]認為每篇文章中的單詞是由該篇文章的所有作者合力完成,其中每個作者都有自己的研究領域,因此不同作者擁有不同的主題分布。作者主題模型如圖1所示。
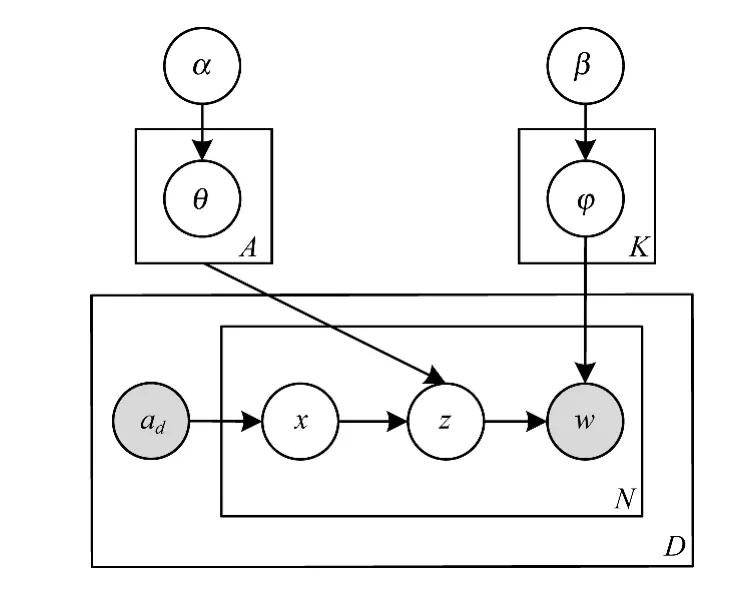
圖1 作者主題模型
在圖1中,α和β為Dirichlet超參數;作者集合ad和文檔單詞w為可觀察的變量。在ATM的文檔生成過程中,首先生成每個主題z下的詞項分布φz,然后對于文檔中的每一個單詞wi:從文檔合作作者集合ad中以均勻分布選取出一個作者x,然后再從該作者的主題概率分布θx中抽取一個主題zi,接著由該主題下的詞項分布φzi生成一個單詞wi,直至生成整篇文檔。ATM充分考慮了作者信息,挖掘出的作者主題分布在一定程度上代表了該作者的興趣愛好。
3.2 話題標簽主題模型
微博主題模型HC-ATM以ATM作為基模型,結合會話、轉發標簽和話題標簽,對微博生成過程進行統一建模分析,構建出不同微博類別下的主題分布。
微博具有不同于傳統文本的特性,其隱含的社交信息對微博主題發現具有一定的促進作用[3]。如含有會話標簽(@)和含有轉發標簽(RT@)的微博:“@mashableHow much does the app charge?”與“RT@mashable the onion launches a new iphone app”。如果將2條微博分別作為獨立的微博來分析微博主題,很難得出前一條微博中的“app”就是“a new iphone app”,而話題標簽和轉發標簽所對應的用戶mashable正是這2條微博的連接紐帶。會話標簽和轉發標簽揭示了微博之間的語義聯系,能幫助主題模型更好地發現用戶互動中的主題分布。
話題標簽(#hashtag)是用戶在發微博時給微博添加的自定義標記,表示該條微博的主題。話題標簽具有一定的混淆性,不同標簽可能指代相同的話題。不同用戶給主題相同的微博添加的話題標簽可以不同,因此提取出某一個無明顯語義特征的話題標簽(如話題“#tcot”)下的詞項分布有助于發現具有相同語義信息的話題標簽,進而可以對微博進行主題分析與標簽推薦。
HC-ATM將微博分為3類:用戶興趣微博,用戶互動微博和含有話題標簽的微博。HC-ATM模型如圖2所示,每條微博 d中每個單詞 wi的生成概率為:
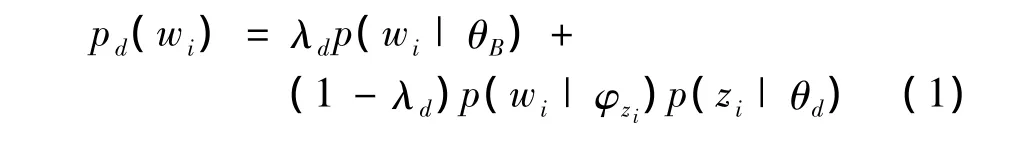
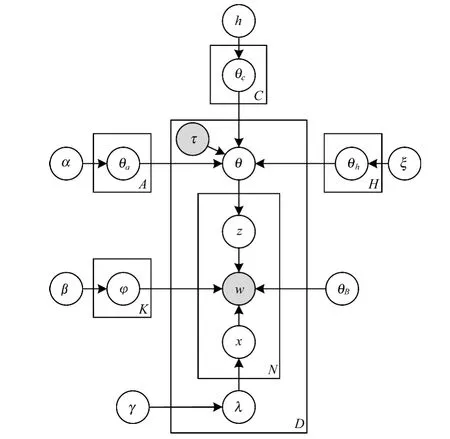
圖2 HC-ATM模型
在HC-ATM中,將詞頻作為模型的背景分布θB,用于平滑模型。用以λd為參數的伯努利分布來確定微博中每個單詞是否由背景分布生成。當xi=1時,則微博中的單詞wi由背景分布θB生成;否則首先由微博主題分布θd抽取出一個主題zi,然后再由主題zi下的詞項分布φzi生成該單詞wi。模型生成過程如下:
(1)對每個主題抽樣 φk~Dir(β),k∈[1,K];
(2)對每條微博 d∈[1,D]:
1)確定微博類型τd;
2)確定微博主題分布θd:
①若 τd=0,則微博主題分布為 θd= θh|θh~Dir(ξ);
②若 τd=1,則微博主題分布為 θd= θc|θc~Dir(η);
③否則微博主題分布為 θd=θa|θa~ Dir(α);
3)抽樣 λd~Beta(γ);
4)對于每個詞 wi∈[1,Nd]:
①抽樣 xi~Bern(λd);
②若xi=0,則從 θd中抽取出隱含主題 zi~Multi(θd),生成單詞 wi~Multi(φzi);
③若 xi=1,則生成單詞 wi~Multi(θB)。
在HC-ATM的微博生成過程中,先生成每個主題z下的詞項分布φz;接著判斷該條微博是否含有話題標簽#hashtag,若含有話題標簽,即τd=0時,該條微博的主題分布θd由話題標簽的主題分布θh決定;否則判斷該條微博是否含有會話標簽(@)或轉發標簽(RT@),若含有會話轉發標簽,即τd=1,該條微博的主題分布θd由用戶互動主題分布θc決定;若不含有任何標簽,即τd=2,則該條微博的主題分布θd由用戶興趣主題分布θa決定。然后從θd中抽取出單詞的主題zi,最后再從φzi生成單詞wi。
3.3 模型推導
Gibbs抽樣是馬爾科夫鏈蒙特卡羅方法(Markov Chain Monte Carlo,MCMC)的特例,每次迭代只對聯合分布中的一個維度進行抽樣,而其他維度保持不變。Gibbs抽樣常被用于概率模型的參數估計。HCATM的Gibbs抽樣后驗公式具體如下:
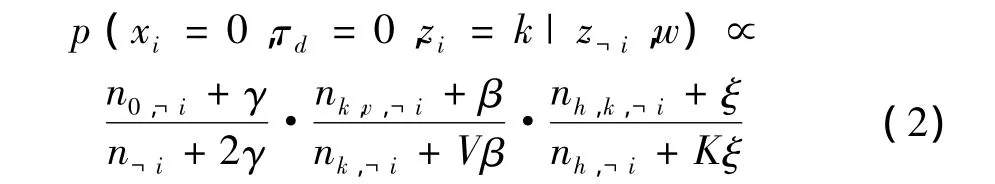
其中,V是詞項個數;K是主題個數;z?i表示除了單詞i外所有單詞的主題下標;w表示所有的單詞;n0,?i表示除了單詞 i外,屬于主題分布 θd的單詞個數;n?i表示除了單詞i外的單詞個數;假設wi=v,則nk,v,?i表示除了單詞 i外,詞項 v 被分配給主題 k 的次數;nk,?i表示除單詞i外被分配給主題k的詞的總數;nh,k,?i表示除單詞 i外,話題標簽 h 中出現主題 k的次數;nh,?i表示除單詞i外,話題標簽h中出現的所有主題總和。
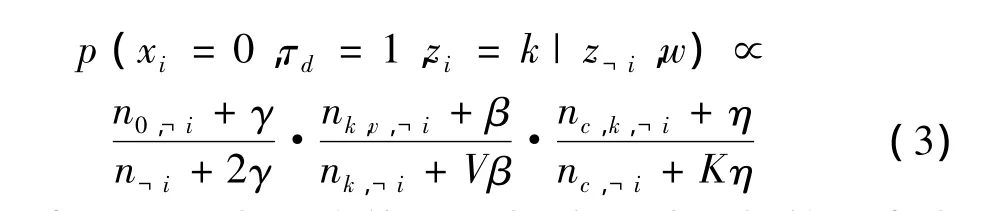
其中,nc,k,?i表示除單詞 i外,會話轉發標簽 c 中出現主題k的次數;nc,?i表示除單詞i外,會話轉發標簽c中出現的所有主題總和。式(4)中的 na,·,?i同理。
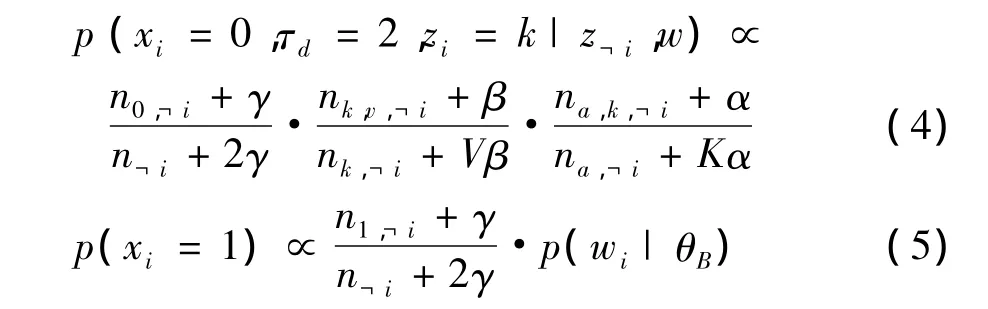
其中,n1,?i表示屬于背景分布中的單詞個數。Gibbs抽樣迭代直至收斂后,使用以下公式對 θh,θc,θa和φk進行估計:
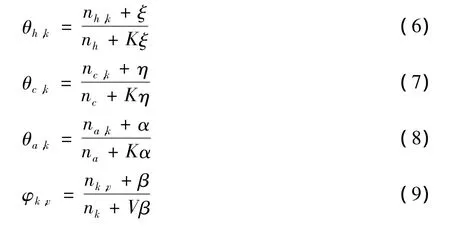
其中,nh,k,nc,k和 na,k分別表示話題標簽微博、會話轉發微博和用戶興趣微博中出現主題k的次數;φk,v表示詞項v被分配給主題k的次數;θh代表話題標簽微博下的主題分布;θc代表會話轉發微博下的主題分布;θa代表用戶興趣微博下的主題分布。
4 實驗結果與分析
4.1 數據集與數據預處理
本文使用2009年9月-2010年1月的Twitter數據集[17-18],含有3 845 624條用戶微博。微博消息含有大量沒有實際意義的停用詞,因此需要對微博數據集進行預處理,先使用已有的停用詞表對微博數據進行去除停用詞處理,接著采用Snowball算法對單詞進行詞干提取,將不同時態的單詞歸為統一的表示形式,隨后去除低頻單詞和含有單詞數較少的微博。經過預處理后,得到約1×105條微博作為實驗數據集,數據集描述如表1所示。

表1 實驗數據集
4.2 實驗環境與參數設置
實驗環境為 Windows 7操作系統,Intel Core 3.2 GHz處理器,內存容量為8 GB。實驗選取ATM和MB-LDA作為比較實驗,3個模型的主題數K設為100、超參數 α 和 αc設為 0.5、β 設為 0.01。HCATM 中的超參數η,ξ和γ都設置為0.5。
4.3 主題困惑度
困惑度(Perplexity)指標常被用于度量主題模型的性能,表示模型預測數據時的不確定性。困惑度指標越小,模型性能就越好。困惑度計算公式如下:

其中,Nd表示微博d中的詞數;wd,i表示微博d中的第i個單詞。ATM,MB-LDA和HC-ATM的困惑度比較如圖3所示。可以看出,當迭代次數大于300時,3個模型的困惑度都趨于平穩狀態,并且HCATM具有比ATM和MB-LDA更小的困惑度,證明了HC-ATM的可靠性。
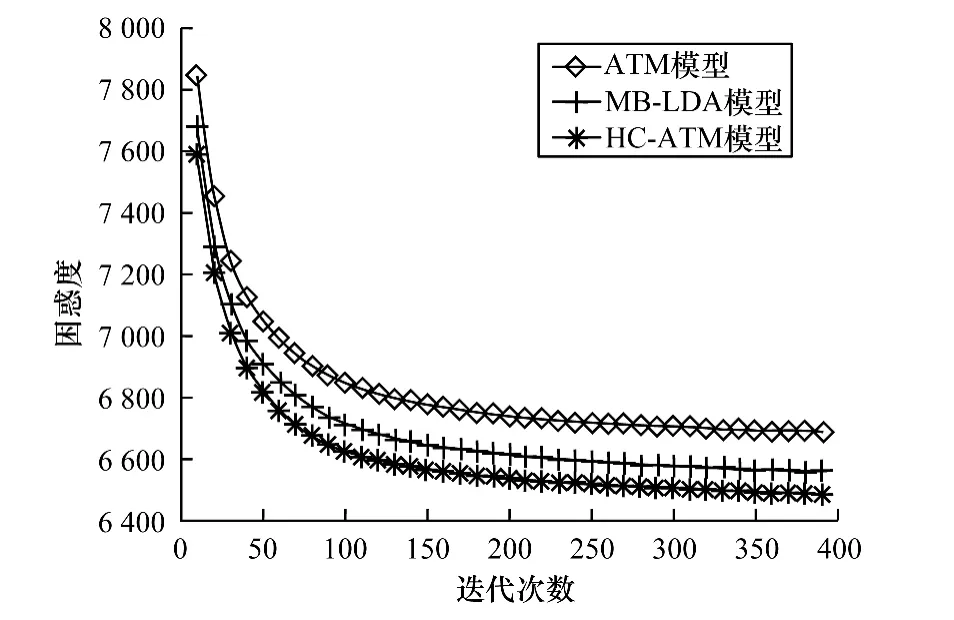
圖3 模型的主題困惑度比較
此外,主題模型的K值越大,模型越容易識別不同含義的潛在主題,具有更小的混惑度,但K值也不宜設置過大,否則會使模型挖掘出大量的垃圾主題,不利于在整體上把握微博數據的主要內容。
4.4 主題差異性
主題差異性是度量模型提取出的主題間的差異程度,抽取出的主題兩兩之間的差異性越大,說明主題越具有代表性。KL距離常用于度量2個概率分布間的差異程度,實驗中使用KL距離來計算主題差異性。2個主題的差異性越大,KL距離越大;反之,KL距離越小。在極端情況下,主題間的KL距離為0,表示2個主題完全一致。KL距離計算公式為:
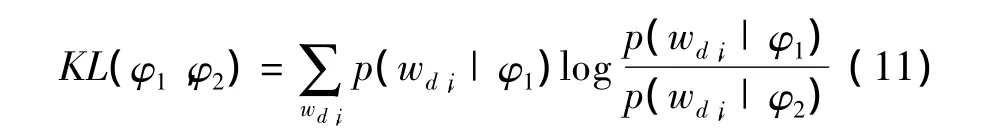
其中,wd,i表示微博 d中的第 i個單詞;φ1和 φ2表示不同的主題。ATM,MB-LDA和HC-ATM 3個模型中兩兩主題之間的KL平均距離比較如表2所示。可以看出,HC-ATM的KL值相對較大,具有更好的主題差異性,說明了對微博進行分類建模能夠幫助主題模型發現更具代表性的主題。

表2 模型KL距離比較
4.5 主題有效性
微博主題挖掘的目標是挖掘出有用的主題,主題是否有效,與主題下的詞項分布有關。
人工判斷詞項與描述主題的相關程度,是評價主題模型有效性的方法。限于篇幅,表3只給出3個模型中都能找到的3個相同主題:主題1(電影相關),主題2(醫療法案相關),主題3(音樂相關),每個主題給出前5個出現概率最大的單詞。可以看出,3個模型都能挖掘出具有一定代表性的主題,但HC-ATM具有更加接近人類對主題理解的表示。在主題1中,ATM得到概率最大的詞項為show,如果光從該詞出發,并不能很好地判斷主題1是與電影相關的主題,而MB-LDA中出現的mark同樣也不能顯著地表示出主題1與電影主題的關系。
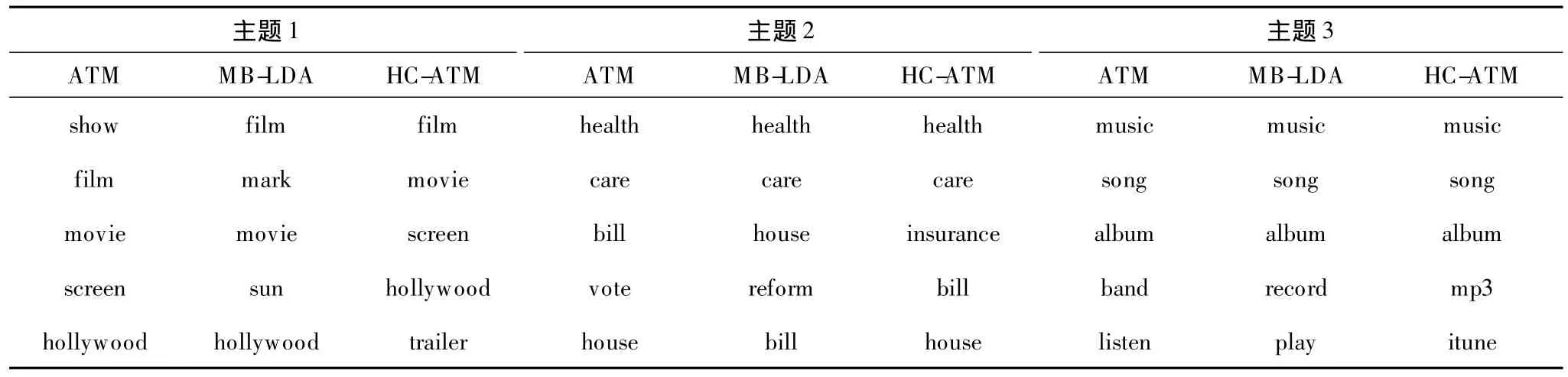
表3 主題有效性比較
4.6 多類型主題分析
由HC-ATM分析出不同的主題類型如表4所示。通過分析話題標簽下的主題可以發現微博中較熱門的話題,并且可以得到相似主題的話題標簽。不同用戶的知識背景不同,對相同話題的標簽描述頁不同。如#tcot和#hcr都是屬于醫療改革的話題標簽,但僅從2個標簽來看,無法確定這2個標簽所描述的主題是相似的。
分析會話轉發標簽下的主題,可以得到用戶之間互動的主題。如用戶jennaldewan經常參與一些與電影相關的討論,當有多條與用戶jennaldewan進行互動的微博出現時,可以根據分析結果將與電影相關的微博評論排在靠前的位置,提高閱讀評論的效率。

表4 多類型主題分析
由用戶興趣的主題分布,可以挖掘出用戶的興趣愛好,如用戶ID:19 671 932的興趣愛好為音樂,對該用戶進行與音樂相關的微博推薦,并結合用戶互動主題分布,擴展用戶興趣愛好,提供更為廣泛的微博推薦。
5 結束語
本文對用戶興趣、用戶互動和話題標簽3種類型微博進行統一建模,提出一個新的主題模型HCATM。利用HC-ATM可以同時挖掘出不同微博類型下的主題分布,并能獲得較好的主題質量。
由于本文主題個數確定,然而在實際應用中找到合適的主題個數需要一定人工經驗,因此今后將對主題個數的自動獲取進行研究,提高主題挖掘效率。
[1] Yan Xiaohui,Guo Jiafeng,Lan Yanyan,et al.A Biterm Topic Model for Short Texts[C]//Proceedings of the 22nd International Conference Companion on World Wide Web.Rio de Janeiro,Brazil:IW3C2 Press,2013:1445-1456.
[2] Blei D M,NgA Y,Jordan M I.LatentDirichlet Allocation[J].Journal of Machine Learning Research,2003,3(1):993-1022.
[3] 張晨逸,孫建伶,丁軼群.基于MB-LDA模型的微博主題挖掘[J].計算機研究與發展,2011,48(10):1795-1802.
[4] Zhao Xin,Jiang Jing,He Jing,et al.Comparing Twitter and Traditional Media Using Topic Models[C]//Proceedings of the 33rd European Conference on IR Research.Berlin,Germany:Springer-Verlag,2011:338-349.
[5] Hong Liangjie,Dom B,Gurumurthy S,et al.A Timedependent Topic Model for Multiple Text Streams[C]//Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.New York,USA:ACM Press,2011:832-840.
[6] Deerwester S C,Dumais S T,Landauer T K,et al.Indexing by Latent Semantic Analysis[J].Journal of American Society for Information Science,1990,41(6):391-407.
[7] Griffiths T L,Steyvers M.Finding Scientific Topics[J].National Academy of Sciences of the United States of America,2004,101(S1):5228-5235.
[8] Minka T P,Lafferty J.Expectation-propagation for the Generative Aspect Model[C]//Proceeding of the 18th Conference on Uncertainty in Artificial Intelligence.Boston,USA:AUAI Press,2002:352-359.
[9] Blei D M,Lafferty J D.Correlated Topic Models[C]//Proceedings of NIPS’05.Cambridge,USA:MIT Press,2005:147-155.
[10] Steyvers M,Smyth P,Griffiths T.Probabilistic Authortopic Models for Information Discovery[C]//Proceedings of the 10th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.New York,USA:ACM Press,2004:306-315.
[11] Wang X,Mccallum A.Topics Over Time:A Non-Markov Continuous-time Model of Topical Trends[C]//Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.New York,USA:ACM Press,2006:424-433.
[12] Blei D M,Lafferty J.Dynamic Topic Models[C]//Proceedings of the 23rd International Conference on Machine Learning.Pittsburgh,USA:IEEE Press,2006:113-120.
[13] Ramage D,Dumais S,Liebling D.Characterizing Microblogs with Topic Models[C]//Proceedings of the 4th International AAAI Conference on Weblogs and Social Media.Menlo Park,USA:AAAI Press,2010:130-137.
[14] Diao Q,Jiang J,Zhu F,et al.Finding Bursty Topics from Microblogs[C]//Proceedingsofthe50th Annual Meeting of the Association for Computational Linguistics.New York,USA:ACM Press,2012:536-544.
[15] Wang Y,Agichtein E,Benzi M.TM-LDA:Efficient Online Modeling of Latent Topic Transitions in Social Media[C]//Proceedingsofthe 18th International Conference on Knowledge Discovery and Data Mining.Beijing,China:[s.n.],2012:123-131.
[16] Khalid E A,Min X,Emily B F.Representing Documents Through Their Readers[C]//Proceedings of the 19th International Conference on Knowledge Discovery and Data Mining.New York,USA:ACM Press,2013:14-22.
[17] Cheng Z,Caverlee J,Lee K.You Are Where You Tweet:A Content-based Approach to Geo-locating Twitter Users[C]//Proceedings of the 19th ACM International Conference on Information and Knowledge Management.NewYork,USA:ACM Press,2010:759-768.
[18] 王 莎,張連明.基于標簽的微博人脈網絡挖掘算法和結構分析[J].計算機工程,2014,40(5):7-11.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
閱讀(快樂英語高年級)(2020年8期)2020-01-08 02:21:16
智慧少年·故事叮當(2018年11期)2018-05-14 11:48:18
商用汽車(2016年11期)2016-12-19 01:20:16
光學精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創業家(2015年5期)2015-02-27 07:53:25
