基于詞共現的大數據研究主題分析*
2014-12-31 09:13:50王一博王繼民
圖書館論壇 2014年8期
關鍵詞:研究
王一博,郭 鑫,王繼民
0 引言
近幾年,移動互聯網、云計算、物聯網等新一代IT技術迎來了發展的高峰期,互聯網中的數據量正在以前所未有的速度不斷增長與積累。在此背景下,大數據(Big Data)吸引了越來越多的關注。在學術界,《Nature》雜志早在2008年就推出Big Data專刊,隨后《Science》在2011年推出《Dealing with Data》,對科學研究中的大數據問題進行了討論。在商業界,IBM 率先提出4V概念并于2013年在北京發布了白皮書《分析:大數據在現實世界中的應用》,為企業從大數據中獲取最大商業價值提供了五項關鍵建議。2012年3月份美國奧巴馬政府發布了“大數據研究和發展倡議”,投資2億美元以上,正式啟動“大數據發展計劃”,計劃在環境科學、生物醫學等領域利用大數據技術進行突破。目前,大數據已經得到多國政府和部門的高度關注[1]。大數據技術及相應的基礎研究已經成為科技界的研究熱點,大數據科學作為一個橫跨信息科學、社會科學、網絡科學、系統科學、心理學、經濟學等諸多領域的新興交叉學科正在逐步形成[2]。
迄今為止,業界對于大數據尚未有一個公認的定義。麥肯錫將大數據定義為:無法在一定時間內用傳統數據庫軟件和工具對其內容進行抓取、管理和處理的數據集合[3]。從大數據的特征出發,被廣泛應用的是“4個V”的定義:(1)規模性(Volume)。數據量級從TB級別發展到PB級別甚至是ZB級別,數據規模非常大。(2)多樣性(Variety)。數據類型繁多,包括了大量圖片、視頻、位置信息等半結構化或非結構化數據。(3)高速性(Velocity)。數據流具有高速、實時的特點,需要大量的在線數據處理。(4)價值密度低(Value)。以視頻信息為例,在不間斷的監控過程中,有用的數據可能只有幾秒鐘。
有學者提出,大數據未來對國家治理模式,對企業的決策、組織和業務流程,對個人生活方式都將產生巨大的影響[4]。因此,對國內大數據領域的研究現狀進行分析具有重要的現實意義。鑒于此,本文旨在通過收集中國知網(CNKI)中與大數據相關的高質量期刊論文,利用共詞分析與社會網絡分析方法,對大數據領域的研究主題進行梳理,探析該領域的研究熱點,以期能夠全面地對大數據的研究現狀和研究熱點進行揭示,為大數據理論與應用的深入研究提供一定的參考和借鑒。
1 研究過程
1.1 數據收集
定量分析方法需要大量的數據支持,可靠、準確的數據來源是研究可信的保證。我們選取CNKI學術期刊中的“SCI來源期刊”“EI來源期刊”“核心期刊”或“CSSCI”作為數據來源,選取這些期刊的原因是這些期刊所刊載的論文具有較高的質量。以“大數據”為檢索詞,檢索類型為“主題”,檢索時間不限,得到大數據領域的研究論文共2,281篇。之后,對數據進行清理,篩選出不含關鍵詞或含有無效關鍵詞的論文,最終獲得分析的論文總數為1,780篇。
1.2 數據處理
共詞分析方法是信息計量學中的一種內容分析方法,其原理是當兩個能夠表達某一學科領域研究主題或研究方向的專業術語(一般為主題詞或關鍵詞)在同一篇文獻中出現時,表明這兩個詞之間具有一定的內在關系,并且出現的次數越多,表明它們的關系越密切、距離越近。共詞分析方法最早在20世紀70年代由法國文獻計量學家提出,經過幾十年的發展,該方法已得到了逐步的完善和廣泛的應用。醫學、化學、人工智能等不同領域的研究者都利用共詞分析方法的原理對不同時期各領域的研究熱點進行了分析[5]。
關鍵詞是作者從論文中摘出的能夠反映文章基本內容的詞。首先下載CNKI相關論文的題錄信息,利用計算機程序統計所有關鍵詞的詞頻并得到候選的高頻關鍵詞。這些候選關鍵詞中不乏有“數據”“變革”“算法”等通用性詞匯,而這些詞匯對于研究主題的發展幫助不大,故刪去。還有一些候選高頻詞雖然詞的表現形式不同,但表達的意思相同或非常相近,例如地理信息系統和GIS、互聯網與Web等。對于這類詞,我們制定了一些映射規則用于對相同含義的詞進行歸并。然后將這些意義相同的詞應用規則合并成一個規范詞,再反過來對原始
關鍵詞進行替換。之后再進行二次詞頻統計,得到相對準確的高頻關鍵詞列表。
粗略地看,關鍵詞的處理主要包含兩點:(1)同義詞合并,制定映射規則,并替換原題錄信息中的關鍵詞;(2)刪除無代表性、不能揭示學科主題的詞匯。
筆者制定的部分映射規則如表1所示。例如“粗集”映射為規范關鍵詞“粗糙集”。
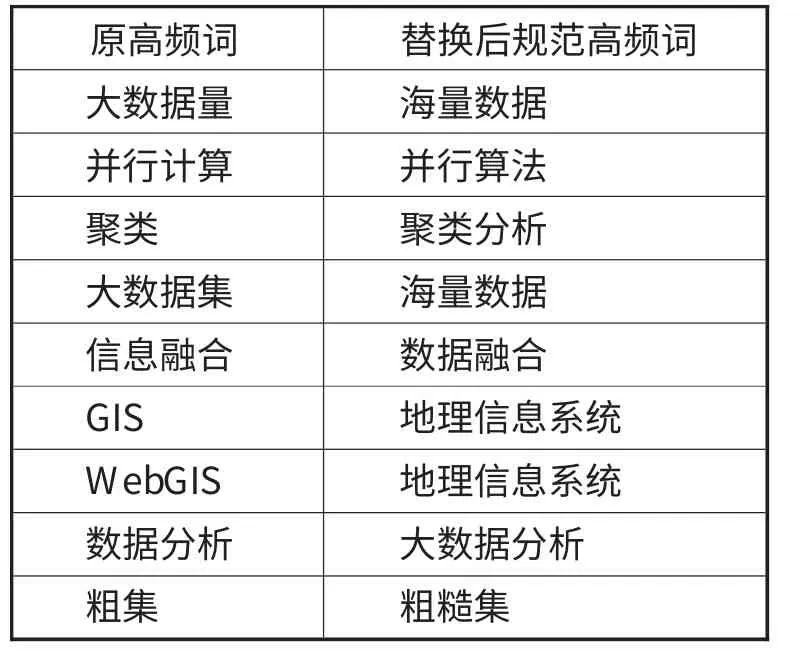
表1 映射規則
經過數據處理后,選取排名靠前的60個高頻關鍵詞(頻次大于等于6)作為研究對象,表2列出了排名靠前的部分高頻關鍵詞。
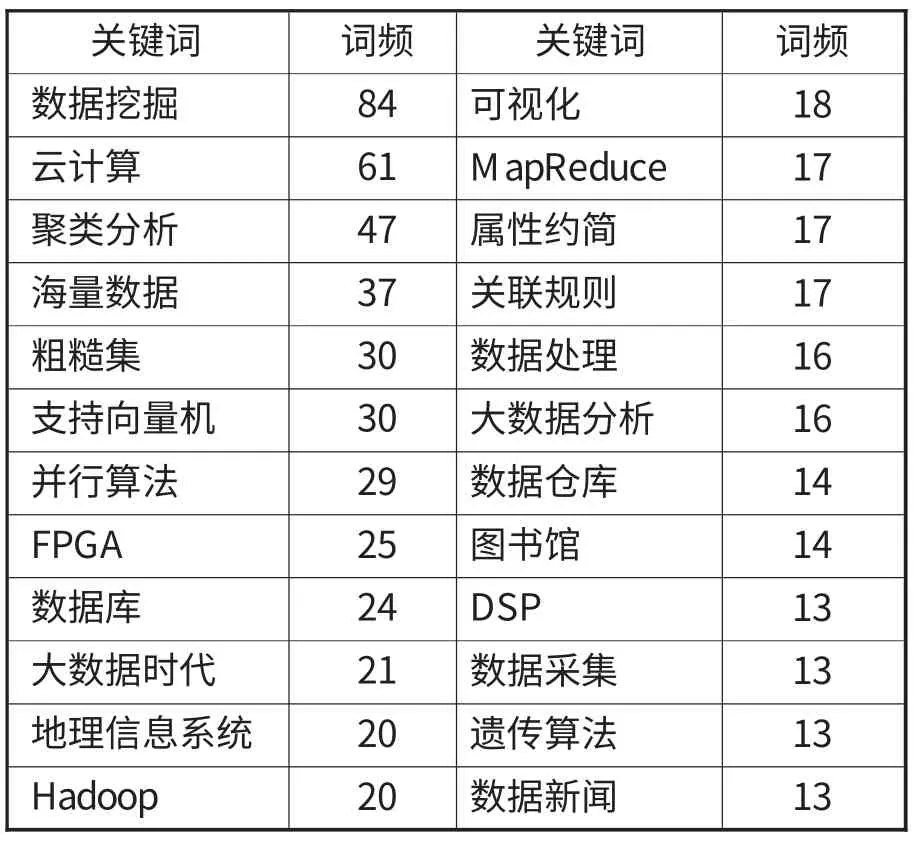
表2 高頻關鍵詞列表(部分)
1.3 共詞矩陣的建立
基于表2所示的關鍵詞表,利用筆者編寫的程序,得到高頻關鍵詞兩兩共現的矩陣,部分數據如表3所示。
共詞矩陣中,對角線上的數據為該詞出現的總頻次。在實際共詞分析過程中,關鍵詞共現頻次受到各自詞頻大小的影響,為了準確揭示關鍵詞之間的共現關系,本文采用Ochiia系數將共詞矩陣轉換為相關矩陣,結果如表4所示。

表3 高頻詞共現矩陣(部分)
Ochiia系數的計算公式如下:
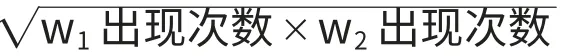

表4 相關矩陣(部分)
相關矩陣中的元素數值在0-1之間,數值越接近1表示兩個關鍵詞的相似度越大;相反,數值越小表明兩個關鍵詞相似度越小。通過上述方法計算得出的相關矩陣中0值過多,計算時誤差較大,為了減小誤差、方便進一步分析,用1與相關矩陣中的各個數字相減,得到表示兩詞相異程度的相異矩陣,部分結果如表5所示。

表5 相異矩陣(部分)
對應的相異矩陣中的元素越接近于0,相似度越大;數值越接近于1,相似度越小。
1.4 聚類分析
聚類分析是根據數據對象的特征對研究個體進行劃分,其原理是同一類中的個體具有較大的相似性,而不同類的個體之間存在不同程度的差異。將相異矩陣導入SPSS中進行層次聚類,得到聚類結果。根據聚類樹狀圖,在閾值為22.5處切割可將其分成10個類團,具體如圖1所示。
1.5 戰略坐標分析
戰略坐標是Law等人1988年提出,用來描述研究領域內部聯系與領域間相互影響的情況。在本研究中,筆者使用戰略坐標描述聚類結果中各個類團的基本情況,用X軸表示向心度,Y軸表示密度。其中,密度用來度量各個類別內各主題詞間的聯系強度。密度越大,知識群維持和發展自身的能力越強,該領域研究越穩定和成熟。向心度用來度量各類別主題詞與其他類別主題詞之間的緊密程度,表示一個學科領域和其他學科領域的相互影響的程度。向心度越大,主題與其他知識群聯系越緊密,則該主題在學科中越趨于中心位置。戰略坐標可以概括地表現一個領域的結構,它把每一個研究主題放置到坐標的四個象限中,從而描述各主題的研究現狀[6]。
對類團密度和向心度的計算有不同的方法,本文采用的計算公式為:

其中,Eij是是關鍵詞i和關鍵詞j共現的次數,K代表通過聚類分析得到的某一類團,n是該類團所含關鍵詞的數目,N是共詞矩陣中所有關鍵詞的數目。
根據表3中得到的聚類結果與高頻詞共現矩陣,利用上述公式計算出每個類別的向心度和密度,并對數據作Z-score規范化,之后根據規范化的結果繪制出最終的戰略坐標圖,結果如圖2所示。
1.6 關鍵詞共現網絡核心-邊緣結構
基于表3的數據,以關鍵詞為頂點,以關鍵詞之間的共現次數為邊可以構建關鍵詞共現關系網絡。該網絡是一個加權的無向網絡。利用社會網絡分析方法,我們可以對該網絡的各項靜態幾何量進行定量分析,如節點的中心性及其分布、網絡的密度、平均路徑長度、凝聚子群等。網絡的“核心-邊緣”結構是由若干頂點相互聯系構成的一種中心緊密相連、外圍稀疏分散的特殊結構。利用社會網絡分析軟件UCINET與Pajek進行“核心-邊緣”網絡結構的計算與展示,結果如圖3所示。

圖1 聚類分析結果圖

圖2 戰略坐標圖
2 分析與討論
根據2.4節中的結果,高頻關鍵詞聚類結果劃分為10個類團較為合適。下面首先結合相關知識對10類主題進行分析。

圖3 核心— 邊緣結構圖
第一類:屬性約簡算法改進研究。這一類團只包括粗糙集和屬性約簡2個關鍵詞。粗糙集理論是由波蘭科學家Z.Pawlak在1982年提出的一種處理模糊和不確定知識的數學工具,已經成功應用于機器學習、模式識別、數據挖掘等領域。對高維數據對象進行降維處理,最核心的內容就是對基于粗糙集的屬性約簡算法進行研究。現有的屬性約簡算法已經難以適應大數據集的處理,針對這一問題,一些學者討論了對屬性約簡算法的改進,以保證算法的有效性。
第二類:從數據通信的角度對大數據的傳輸進行研究。這一類團包括DSP、以太網、數據傳輸和數據采集這4個關鍵詞。隨著互聯網中需要傳輸的數據量的不斷增加,互聯網的傳輸技術、處理技術等需要得到優化。一些學者從數據通信的角度,對大數據環境下的數據獲取方式與數據傳輸技術等問題進行了研究。
第三類:大數據處理技術與工具的研究。這一類團包括8個關鍵詞,其中代表性較強的包括云計算、物聯網、Hadoop和MapReduce等。隨著大數據研究與應用的不斷升溫,對大數據處理的具體技術與開發工具也越來越受到學者的關注。2006年谷歌提出了云計算的概念,并為大數據的處理提供了一個良好的平臺。現在,Hadoop已經成為大數據處理的最常用工具。物聯網技術的廣泛應用也為大數據的獲取、存儲與處理提供了解決方案。
第四類:機器學習算法的改進研究。這一類團包括9個關鍵詞,其中代表性較強的有支持向量機、神經網絡、機器學習等。近年來隨著數據量的激增,傳統的機器學習算法對于大數據量的處理普遍存在著處理速度慢、運行效率低等問題,一些學者從適應大數據處理的角度對某些算法進行改進。
第五類:大數據對新聞業的影響。這一類團只含2個關鍵詞,分別是可視化和數據新聞。大數據時代的數據新聞報道改變了新聞的生產傳播方式,加速新聞行業的角色轉換。大數據對于新聞行業的影響引起了新聞學及傳播學學者的關注。
第六類:大數據在圖書情報領域帶來的變革。這一類團包含6個關鍵詞,代表性較強的有競爭情報、知識服務、信息服務、圖書館等。圖書館作為存儲、傳播知識的重要場所,在大數據時代將會發生深刻的變化。一些學者研究了大數據給圖書館信息服務帶來的變化,以及大數據對企業競爭情報未來發展的影響等等。
第七類:數據挖掘技術在大數據處理方面的應用。這一類團包含8個關鍵詞,其中代表性較強的有數據挖掘、聚類分析、關聯規則等。數據挖掘是指從大量數據中揭示出隱含的、新穎的并有潛在價值的信息的非平凡過程。在大數據時代中,借用數據挖掘技術對海量數據進行分析是最基本的研究途徑。
第八類:數據壓縮技術的研究。這一類團只包括2個關鍵詞,分別是小波變換與數據壓縮。隨著互聯網中多媒體數據量的激增,如何對數據進行壓縮和存儲,是大數據需要解決的問題之一。為保證數據的傳輸質量并提高數據的存儲效率,利用小波變換的方法對數據壓縮技術進行優化,是眾多學者關注的問題之一。
第九類:對海量圖像數據進行實時傳送與處理的研究。這一類團包括5個關鍵詞,分別為海量數據、圖像處理、自適應、擁塞控制、實時。在大數據時代中,“數據”不僅僅包括簡單的字符串或文本流,還包括圖像、音頻、視頻等,而諸如此類的數據往往具有較大的數據量,對海量圖像數據傳送與處理的研究是有必要的。
第十類:與物聯網技術及其應用相關的研究。這一類團包括13個關鍵詞,其中代表性較強的有無線傳感器網絡、信號處理、遙感、嵌入式系統、負載均衡等。物聯網利用各種傳感器將物理世界中的各種信息傳送到計算機系統中,也勢必導致互聯網中的信息總量爆炸式增長。目前,物聯網對于大數據的采集和分析仍然面臨諸多挑戰。
戰略坐標圖(圖2)顯示,K1,K3和K7是學者們在大數據領域中研究的核心內容,它們都具有較高的密度,其中K1和K7還具有很高的向心度。這說明屬性約簡算法與數據挖掘技術在大數據領域的研究較為成熟,且與其他類團的研究主題密切相關。由此可見,對于大數據處理技術的研究是迄今為止較為核心的研究內容。對于大數據處理技術及其工具而言,這一類團在十個類團中是密度最高的,說明其研究內容具有一定規模且較為成熟,諸如云計算、物聯網、hadoop等均已成為時下的熱點研究領域。相比之下,這一類團的向心度較低,但仍為正值,說明大數據處理技術與工具這一主題與其他研究分支具有一定的聯系,但密切程度不高。
此外,其余七個類團則均位于第三象限,密度和向心度都低于平均水平,但其中一些類團距離原點較近,仍具有一定的發展潛力,如海量圖像數據的處理,大數據在圖書情報領域中的應用等等。值得注意的是,無論是向心度還是密度,K10這一類團都處于很低的水平,這也說明這一類團中的內部成員間聯系比較松散,其中的成員很可能被分解、演化到其他類團中。如前所述,K10類團主要包括與物聯網技術及其應用相關的研究。可以認為,隨著大數據科學的不斷發展,物聯網技術將會逐漸內化到大數據領域的研究中。
根據圖3(核心—邊緣結構圖),可以看到國內大數據研究領域的核心關鍵詞有12個,分別為:數據挖掘、云計算、聚類分析、海量數據、支持向量機、并行算法、Hadoop、MapReduce、數據處理、大數據分析、信息服務、分布式等。這12個核心關鍵詞大多具有較高的詞頻,詞間的關系也相對緊密,反映了這些詞所指向的研究內容已形成了一定的規模,而相應邊緣結構中的關鍵詞雖然數量眾多(48個),其所代表的研究內容還略顯薄弱。這個核心結構是在一定時間內逐漸形成的,暫時處于一個穩定的狀態。但隨著時間的推移,相關研究的不斷深入,這種結構關系會發生一定的變化:邊緣結構中的關鍵詞可能會進入核心結構,而核心結構中的詞也可能會退出,進入邊緣結構[7]。
3 結語
本文使用共詞分析方法,對以大數據為主題的優質期刊文獻進行了直觀、科學的分析,并進行了一些討論與解讀,具有一定的現實意義。從關鍵詞共詞矩陣出發,將其轉化為相關矩陣和相異矩陣,利用SPSS進行層次聚類分析,最終獲得10個主題類團。在此基礎上,根據聚類結果,利用共詞矩陣繪制了戰略坐標圖,對每一個主題的成熟程度、重要程度等進行了分析。最后,通過“核心-邊緣”結構分析得到了大數據研究領域的核心關鍵詞。
本文的研究仍然存在著一定局限性。首先,收集數據時將“大數據”作為主題字段,檢索出的內容較為繁雜。其次,由于期刊論文的發表存在時滯,一些低頻的關鍵詞可能也是未來的研究熱點,但在本研究中沒有考慮。最后,本次研究搜集的數據主要是一些高質量期刊論文,并非全部的期刊論文,同時也不包括報紙、學位論文等數據,故文本中得到的結論并不能完全代表大數據領域的研究成果。
[1] 孟小峰,慈祥.大數據管理:概念、技術與挑戰[J].計算機研究與發展,2013(1):146-169.
[2] 李國杰,程學旗.大數據研究:未來科技及經濟社會發展的重大戰略領域—大數據的研究現狀與科學思考[J].中國科學院院刊,2012(6):647-657.
[3] 嚴霄鳳,張德馨. 大數據研究[J]. 計算機技術與發展,2013(4):168-172.
[4] 孟薇薇.信息爆炸時代的新概念:大數據[J].商品與質量,2012(9):9.
[5] 朱慶華,彭希羨,劉璇.基于共詞分析的社會計算領域的研究主題[J].情報理論與實踐;2012(12):7-11.
[6] 崔鵬,孫寶文,王天梅,等.基于共詞分析的網絡虛擬社會領域熱點及演進態勢研究[J]. 情報雜志,2013(2):41-44.
[7] 魏瑞斌,王三珊. 基于共詞分析的國內Web2.0 研究現狀[J].情報探索,2011(1):1-5.
猜你喜歡
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
天津外國語大學學報(2021年3期)2021-08-13 08:32:18
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
科技傳播(2019年22期)2020-01-14 03:06:54
遼金歷史與考古(2019年0期)2020-01-06 07:45:20
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
電子制作(2018年11期)2018-08-04 03:26:04
汽車工程學報(2017年2期)2017-07-05 08:13:02
國際商務財會(2017年8期)2017-06-21 06:14:14
電子制作(2017年23期)2017-02-02 07:17:19
