高校圖書館圖書推薦系統(tǒng)中的稀疏性問題實證探析
2014-12-06 02:32:58張閃閃黃鵬
大學圖書館學報 2014年6期
□張閃閃 黃鵬
1 引言
在信息爆炸的時代,移動設備已成為人們獲取信息的重要工具。據(jù)移動互聯(lián)網(wǎng)第三方數(shù)據(jù)研究機構(gòu)Gartner發(fā)布的《2014年全球設備總銷量預測》,截止2013年12月,中國智能手機用戶數(shù)突破10億人[1]。智能移動設備日漸普及的同時,我國對電信基礎設施的投入不斷加大,3G網(wǎng)絡已經(jīng)普及,以中國移動領銜的4G網(wǎng)絡也開始試運行,移動網(wǎng)絡帶寬不斷加大,之前必須通過有線網(wǎng)絡才能實現(xiàn)的服務如今在移動網(wǎng)絡中就可以完成,移動信息服務成為可能。
面對圖書館用戶閱讀行為的轉(zhuǎn)變,即便圖書館擁有再豐富、再優(yōu)質(zhì)的資源,若不思索新的服務模式,也將難以更好地為用戶服務。在這樣的條件下,圖書館如何將正確的信息推送給正確的用戶是未來圖書館的一項重要課題,而個性化信息服務則可能是這道命題的答案。個性化信息服務是根據(jù)用戶使用偏好、個人特征以及其提出的明確要求等,滿足用戶對個體信息需求的一種服務方式。
2 圖書館個性化推薦系統(tǒng)的需求
圖書館雖然有良好的學習條件、豐富的印本資源,但是卻沒有為用戶提供與圖書相關的信息和建議。用戶在不知道該選擇何種圖書滿足自我的信息需求時,可能會根據(jù)自己所需要的類別在書架前尋找,也可能會在書目系統(tǒng)中搜索某一主題下的圖書并根據(jù)書名和作者進行選擇,這樣既浪費寶貴的時間,而且搜集到的圖書也可能并非是用戶所需要的。目前,雖然圖書館的網(wǎng)站上有各種圖書推薦服務(如“新書推薦”、“一周借閱排行榜”、“季度借閱排行榜”等),試圖達到幫助用戶尋找合適圖書的目的,但是在Web2.0環(huán)境下,用戶的需求越來越個性化和多樣化,而傳統(tǒng)的圖書館推薦系統(tǒng)是“把一類圖書推薦給所有用戶”,往往不能達到令用戶滿意的效果.用戶希望的是圖書館系統(tǒng)能夠提供“量身定做”的推薦,而不是“一攬子”推薦,這就要求圖書館的推薦系統(tǒng)更具有針對性、主動性、甚至是智能化。據(jù)不完全統(tǒng)計,亞馬遜網(wǎng)站上有35%的銷售額是得益于個性化推薦,有60%的銷售額間接受到推薦的影響[2]。學者瑪麗亞·索萊達·佩拉和尼科爾·康蒂等利用社交媒體數(shù)據(jù)構(gòu)建了基于社會互動和個人興趣的個性化圖書推薦系統(tǒng)(Personalized Book Recommendations System),通過分析相似用戶從而有針對性地為用戶推薦圖書,實驗證明該系統(tǒng)的精確度超過了亞馬遜[3]。由此可見,個性化推薦可以作為一種重要的方式應用到圖書館信息服務過程中,但是,目前它主要是在電子商務領域取得了巨大進展,在圖書館領域應用的還比較少。筆者試圖針對圖書館現(xiàn)有個性化推薦中存在的問題,提出一種具有圖書館特色的推薦方式,以期緩解目前推薦過程中的一些窘境。
3 圖書館個性化推薦服務中存在的問題
高校圖書館作為信息資源的集散地,在不斷滿足科研學者的信息需求的同時,也存在著信息量龐大和用戶特定需求難以匹配的矛盾。用戶如果想要搜索某一專題或領域的圖書,往往需要耗費大量的時間和精力。而現(xiàn)有的圖書館管理系統(tǒng)中已有一些可提供個性化信息服務,用戶可選擇自己關注的領域,一旦該領域有新到圖書,便會收到通知。比如美國康納爾大學的“我的圖書館”系統(tǒng),包括個性化鏈接、個性化更新、個性化內(nèi)容、個性化目錄和文獻傳遞服務,用戶可以定制圖書館資源及其他網(wǎng)絡資源,也可以接受最新資源通告、進行目錄查詢等,這都為用戶使用信息帶來了很大便利。
雖然圖書館的個性化推薦系統(tǒng)在圖書館已經(jīng)得到應用且為用戶帶來了一定的便利,也在一定程度上提升了圖書館的服務質(zhì)量,但是仍然存在一些問題:比如有一些系統(tǒng)是以充分挖掘用戶特征或信息資源特征為基礎的,在使用之前都需要用戶填寫個人興趣愛好方面的信息[4][5],不能根據(jù)用戶的特征主動地、動態(tài)地提供個性化推薦服務。而目前常用的個性化推薦系統(tǒng)多采用協(xié)同過濾技術,雖然無需獲取用戶的個人信息,但是可能會產(chǎn)生自動化和稀疏性問題。
3.1 自動化問題
百度文庫、豆瓣等都會在其頁面上設置一個用戶評分區(qū)域,一般包括“力薦、推薦、還行、較差、很差”等幾個不同級別。用戶必須積極主動地進行評價,推薦系統(tǒng)才能了解用戶的特征,從而進行相似性推薦。然而用戶往往屬于利益驅(qū)動者,所采取的行動一般都是和自己的利益掛鉤,如百度文庫,作者為文章評分便可獲得一定財富值,而財富值可以使其在該網(wǎng)站上下載更多的資料。但是圖書館屬于非盈利性機構(gòu),缺乏相應的利益驅(qū)動機制,在這種情況下,讀者評價圖書往往會缺少動力,這就造成評價信息過少,不利于圖書館收集用戶的信息[6]。如果能夠提高系統(tǒng)評價的自動化程度,那么可以在一定程度上解決用戶評價不足的問題。
3.2 稀疏性問題
在電商平臺中我們常常見到商家利用評價返現(xiàn)、評價返積分的方式鼓勵用戶對所購買的產(chǎn)品或服務進行評價,據(jù)調(diào)查,在缺乏物質(zhì)獎勵的情況下,電商銷售出的產(chǎn)品/服務所收到的評價還不足整體銷售總量的1%。用戶評價的主動性不高是造成數(shù)據(jù)稀疏性的一個重要原因。除此之外,暢銷書的借閱用戶往往較多,而非暢銷書的借閱相對較少,借閱數(shù)據(jù)存在大量的交錯,這兩個問題導致協(xié)同過濾系統(tǒng)尋找到的相似用戶不太可靠,計算出的待推薦項目評分也不太準確。大多數(shù)系統(tǒng)在處理數(shù)據(jù)稀疏性問題時,都以0或用戶平均分填充的方法來評價缺乏評分的項目,但這些做法在用戶興趣偏好描述方面有所失真。另外,若以圖書館的圖書評分矩陣作為尋找相似用戶的依據(jù),運算復雜度將會很大。
4 解決高校圖書館稀疏性問題的設計思路
目前,已經(jīng)有很多學者針對上述問題提出了不同的解決對策,包括降維的方法[7]、項目聚類方法[8]等。如學者鄒永貴[9]利用項目及項目類別包含的評分次數(shù)來計算不同項目之間的興趣度,并結(jié)合傳統(tǒng)的相似度算法有效地減少了評分數(shù)據(jù)稀疏的負面影響。學者王桂芬[10]提出一種基于項目層次偏好的協(xié)同過濾推薦,減輕了數(shù)據(jù)稀疏性問題。歐文·金等人[11]通過結(jié)合用戶和項目兩方面的共同信息來對缺失評分進行預測,一定程度上解決了稀疏性問題。托恩·奎爾·李(Tong Queue Lee)[12]認為在預測時可以對那些沒有打分的產(chǎn)品賦予一些缺省的分值,這樣就會使得預測分數(shù)的準確性大幅度提升。如黃昝等[13]通過協(xié)同檢索框架及擴散算法來分析用戶之間的關聯(lián)性,解決打分稀疏性問題,實驗結(jié)果表明所提出的方法在推薦準確度、召回率、綜合評價指標和得分排名等方面都明顯優(yōu)于傳統(tǒng)的協(xié)同過濾方法;托恩·奎爾·李等[14]借助偽打分信息,安等[15]借助啟發(fā)式算法來分析用戶之間的相似性,他們指出,系統(tǒng)中的打分項目往往比較多,而如何根據(jù)現(xiàn)有已打分項目對未打分的項目做出預測,則變得非常重要。
缺乏用戶的主動評價是造成圖書推薦計算障礙的重要問題之一,而用戶評分的主動性不高及借閱行為的交錯性是導致數(shù)據(jù)稀疏性的兩大主要因素。要解決稀疏性問題,首先需要解決自動化評分問題;此外,正如科恩所提出的,我們還需要解決用戶主動評價所造成的打分不一的問題。而對于用戶借閱行為的交錯性所產(chǎn)生的稀疏性問題,可以通過一定的方法對未評分項目進行分值填充。本文結(jié)合圖書館的特點,提出通過用戶的借閱記錄形成自動化的評分標準,同時借助中圖法類目形成新的書目數(shù)據(jù)庫,把通過每本書尋找相似用戶轉(zhuǎn)換為通過“某一類”圖書尋找相似用戶,從而簡化計算流程,降低計算維度。以下就這些思路給予一一說明。
4.1 建立自動化評分體系
人工評分系統(tǒng)是個性化推薦系統(tǒng)的羈絆。根據(jù)齊普夫省力法則,人們總是會采取比較省力的方式來指導自己的行為,除非對某本書非常熱愛,用戶大都不會對借閱的圖書進行評價。因此,我們可以看到,大多數(shù)電商網(wǎng)站例如京東、易迅及當當?shù)榷际峭ㄟ^給用戶返利的方式鼓勵用戶評價,而公益性的圖書館沒有這筆經(jīng)費預算,采用付費模式鼓勵用戶評價是不現(xiàn)實的,必須針對圖書館自身的特點,設計一種能夠適合圖書館的自動化評分體系。綜合以上因素,圖書館可以利用用戶借閱記錄的特點設計一種標準化的評分體系,根據(jù)借還書記錄自動實現(xiàn)用戶對所借閱圖書的評分。
××大學的借閱日志主要包含借閱、續(xù)借、預約三項操作,以下根據(jù)這三項操作設定評分系統(tǒng)。通過查閱大量文獻以及進行專家訪談,最終根據(jù)文獻的對比分析并結(jié)合專家意見,得出三種不同操作的分值如下:
借閱:用戶只有對某本書感興趣或者因為客觀原因?qū)ζ溆行枨螅艜ソ栝喸摃梢苑譃槭状谓栝喤c非首次借閱。首次借閱雖然表明用戶對該書感興趣,但因為用戶并沒有詳細閱覽圖書的內(nèi)容,因此該書對用戶的作用可大可小。綜上所述,用戶初次借閱某本書的評分不能太高,可以將首次借閱的分值設為1。而非首次借閱,我們認為該書對用戶的用途較大,所以才會被多次借閱,同時為拉大分差強調(diào)再次借閱的重要性,因此可將分值設定為4。
預約:××大學圖書館對已經(jīng)借出的圖書提供預約服務,用戶可以通過申請該服務,對借出圖書歸還后享有優(yōu)先借閱權(quán)。同樣根據(jù)省力法則分析,若非用戶有非常大的意愿去閱讀該本書,是不會通過賬號登陸系統(tǒng)去預約的,所以用戶申請預約服務,我們可以認為用戶已經(jīng)了解該書的詳細內(nèi)容并認為該書有用,分值可以比初次借閱該圖書高,但我們還要考慮到用戶也可能并沒有深入閱讀該書,可能會存在閱讀后感覺與自己之前的想法有所差距的情況,因此,分值不應該比再次借閱高。綜上,我們將預約行為的分值設定為2。
續(xù)借:關于續(xù)借情況的分析也應該分為兩種。一般來說,我們認為用戶在覺得該書有用同時又沒有讀完的情況下才會續(xù)借。另外,圖書館的借閱規(guī)則中有懲罰條款,圖書借閱超期會產(chǎn)生罰金,若用戶借閱的書到期,但湊巧這幾天沒有時間去還書,又不想被罰款,這時就會產(chǎn)生續(xù)借行為。綜合這兩種情況,續(xù)借的分值應該高于初次借閱,但是要低于非初次借閱,因此將分值設定為2。
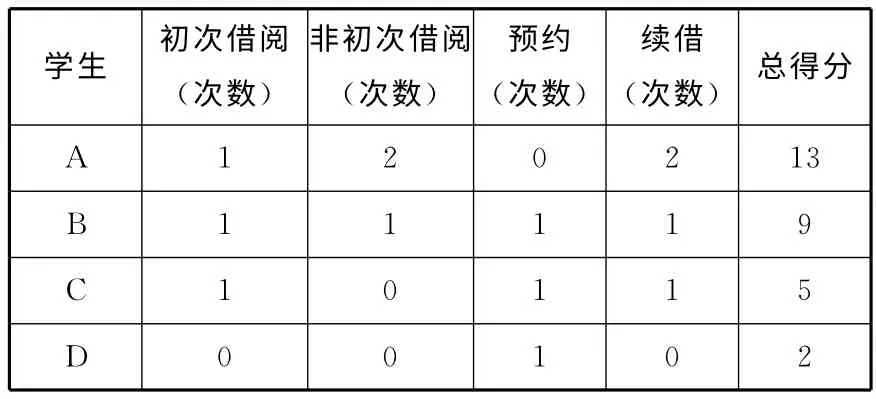
表1 圖書評分表
表1是某本圖書的評分表,每一行的2,3,4,5列是對某位同學借閱行為的統(tǒng)計,第6列是系統(tǒng)依據(jù)上述評分體系針對該同學的借閱行為所計算出來的圖書得分。例如:A同學對該本圖書的評分為1×1+2×4+0×2+2×2=13;B同學對該本圖書的評分為1×1+1×4+1×2+1×2=9;C同學對該本圖書的評分1×1+0×4+1×2+1×2=5;D同學對該本圖書的評分0×1+0×4+1×2+0×2=2。
4.2 借鑒中圖法目錄降低運算維度
對于借閱行為的交錯性問題,我們還應考慮圖書館自身特點:圖書館開架借閱的圖書都是專業(yè)人員編目過的圖書,其分類較為準確。我們可以借助書目數(shù)據(jù)對其進行合并處理,將通過對某本圖書的興趣度尋找相似用戶的問題轉(zhuǎn)化為通過對某一類圖書的興趣度尋找相似用戶的問題。即先根據(jù)借閱記錄計算用戶所借各書的分值,然后根據(jù)書目信息中該書所屬的類目,計算各“類”的分值,然后通過各“類”的分值尋找相似用戶。
下面以××大學圖書館文學庫圖書為例具體說明處理過程:
a)調(diào)研分析××大學依據(jù)中圖法編制的類目,對已有類目進行重新歸并。圖1以圖書最多的中國文學I2為例進行類目的重新劃分,比如“中國文學”類目下包含9類,根據(jù)收集文獻數(shù)量及相近性,將戲劇文學與詩歌、韻文合并為一類,以此類推將原來的九類重新整合為六類。另外,I3中由于日本文學的館藏數(shù)量占多數(shù),因此將其重新劃分為日本文學與亞洲其余各國文學;同理,將I7美洲各國文學重新劃分為美國文學與美洲其余各國文學。在重新劃分后,把原來的下級類目提前,替換原有上級類目,將文學庫重新劃分為18個類目(表2);
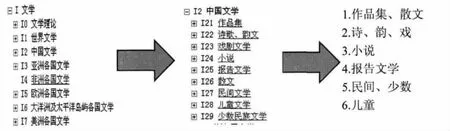
圖1 ××大學圖書館文學庫分類舉例
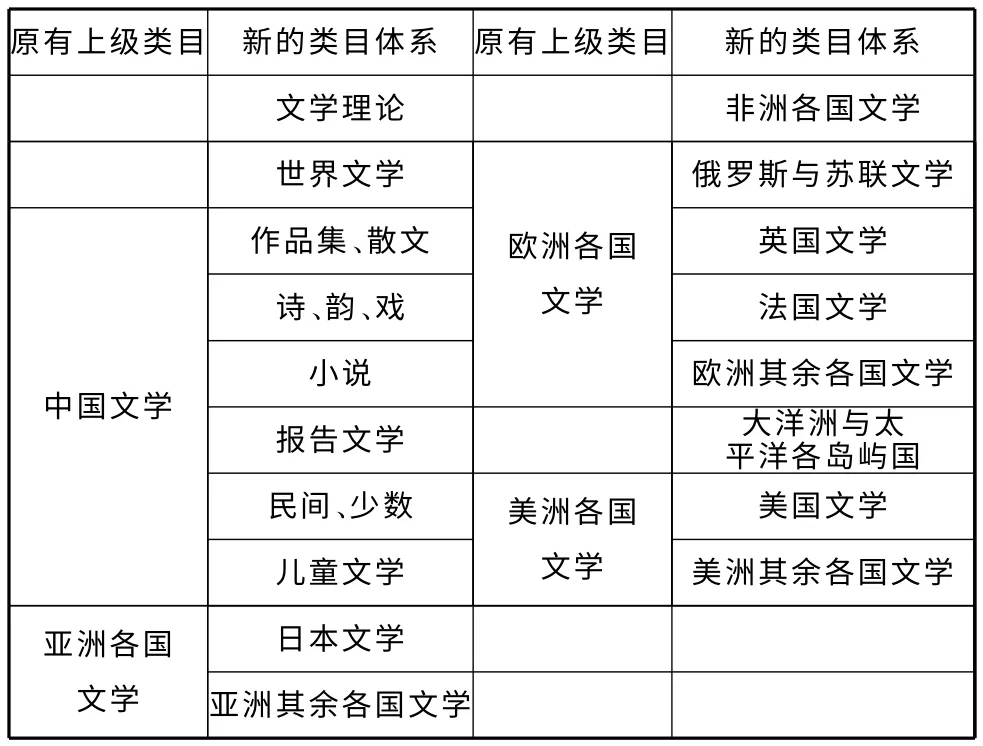
表2 文學庫重新構(gòu)建的分類體系
b)根據(jù)用戶的借閱行為,計算用戶對圖書的評分;
c)將圖書依照條目信息歸類到新的類目體系中,并將計算出來的各種圖書的分值導入公式1中,得到各類目的分值。公式中P代表某用戶對某類圖書的打分,n為該類目下用戶借閱了n本書,Ri表示用戶借閱該類圖書中第i本圖書的得分。
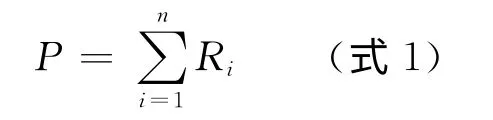
d)將計算出的每一類的分值當做一“本”書的分值帶入公式2中,計算用戶的相似性,將與每位用戶最為相似的前10位用戶挑選出來。R(u,i)及R(v,i)分別代表用戶u及用戶v對i類圖書的評分及分別表示用戶u及用戶v對文學庫18類圖書評分的平均值,sim(u,v)表示兩位用戶的相似性。
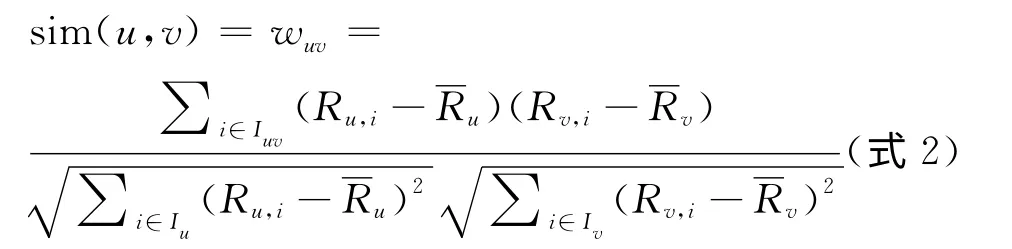
e)根據(jù)d)中計算出的相似用戶集合U及其所屬的用戶評分集合(每本書),對未評分的圖書進行預測,將預測分值排名前十的圖書列出,若出現(xiàn)得分相同的情況,則根據(jù)借閱記錄將相同得分的圖書按照借閱次數(shù)進行排列,如若仍出現(xiàn)相同的情況則全部進行推薦。P(u,k)表示預測用戶u對圖書k的評分,及代表用戶u和v對所有已評圖書的平均分,R(v,k)表示用戶v對圖書k的評分。
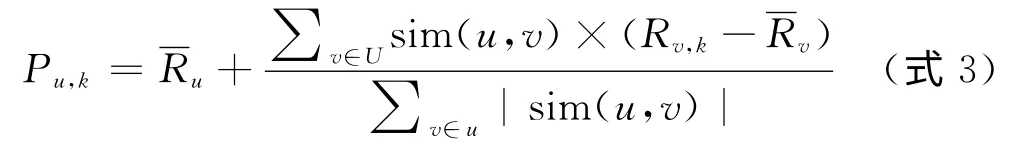
采用這種歸類轉(zhuǎn)化模式能夠有效降低借閱交叉造成的數(shù)據(jù)稀疏問題,將通過圖書組合尋找相似用戶的問題轉(zhuǎn)化為通過“類”的組合尋找相似用戶的問題。尋找相似用戶的本質(zhì)其實就是尋找對某一圖書組合都感興趣的用戶,而實際上我們可以將這一類圖書組合看成一類圖書,相似用戶是對某一類圖書感興趣而找到共同點的。在電商領域中,由于物品項目沒有經(jīng)過專業(yè)分類或聚類,需要以物品項目為單位采用傳統(tǒng)的協(xié)同過濾模式,而高校圖書館的館藏是經(jīng)過專業(yè)編目的圖書,直接采用“類”尋找相似用戶在理論上是合理的,而在后續(xù)的實驗中也證明了該種做法是可行的,采用“類”尋找相似用戶所推薦圖書的準確率比直接采用單位圖書尋找相似用戶進行推薦的準確率有明顯提升。同時還需注意在該步驟中對于每本圖書的預測采用的是相似用戶對于具體圖書的評分集合,而非相似用戶對于“某一類”圖書的評分集合。
5 個性化推薦數(shù)據(jù)實驗
5.1 研究假設
為了能夠更快更準確地給用戶推薦符合其需求的圖書,本研究假設系統(tǒng)只能為目標用戶推薦其所在書庫的圖書,即用戶到達文學庫時,系統(tǒng)會測算出用戶目前處于文學庫,并只為用戶推薦文學庫中的圖書。實驗將重點考察在推薦同一書庫中的圖書時,傳統(tǒng)的協(xié)同過濾與結(jié)合中圖法編目數(shù)據(jù)的協(xié)同過濾的推薦效果。
5.2 推薦數(shù)據(jù)來源及實驗設計
為了驗證以上所提出的設計思路的可用性,本文選取XX大學圖書館后臺借閱數(shù)據(jù)進行數(shù)據(jù)試驗,將數(shù)據(jù)的范圍尺度定位為文學庫的借閱記錄,樣本設定為以文學院為主的300名研究生的借閱記錄,數(shù)據(jù)的時間跨度從2011年9月至2013年12月,共37509條記錄,涉及7127本書。系統(tǒng)的操作流程如下:
(1)將得到的數(shù)據(jù)進行預處理,使之符合運算模式;
(2)通過設計的推薦體系進行數(shù)據(jù)處理;
(3)將數(shù)據(jù)集分別代入傳統(tǒng)協(xié)同過濾模式和加入編目體系的推薦模式進行對照實驗;
(4)根據(jù)計算得出評分集合A與B;
(5)將兩種方式得到的推薦集合進行合并處理,并編制用戶推薦書目,通過校園郵箱向用戶進行推薦調(diào)研;
(6)根據(jù)用戶反饋的信息,結(jié)合推薦集合處理反饋結(jié)果;
(7)比較推薦集合的準確性,并作出分析。
5.3 數(shù)據(jù)實驗
(1)數(shù)據(jù)預處理。
系統(tǒng)的后臺日志僅是對借閱行為進行記錄,每一條目包括題名、索書號、學號、操作日期,其中部分后臺日志如表3所示。
從表3可以看出,數(shù)據(jù)是以時間序列進行排布的,而本文主要是通過借閱信息來分析相似用戶,并對其進行個性化推薦,因此需要將數(shù)據(jù)進行預處理,形成以用戶為單位的數(shù)據(jù)集合,包括用戶的初次借閱、續(xù)借、非初次借閱及預約行為的統(tǒng)計處理,形成如表4的數(shù)據(jù)。以圖書《詩性正義》為例,通過查詢原始后臺日志,發(fā)現(xiàn)學號尾號為220的用戶于2012年11月13日首次借閱該圖書,于2013年4月2日和2013年5月2日分別進行了兩次續(xù)借,并在2013年3月7日、5月22日和12月21日對該圖書又進行了三次借閱。
表3 ××大學圖書館文學庫借閱日志

表4 學號尾號為220學生的借閱記錄
(2)使用matlab進行推薦實驗。
根據(jù)處理步驟編寫matlab代碼(如圖2),將預處理數(shù)據(jù)矩陣代入進行運算,得到向用戶推薦的圖書集合A。同時,為了進行對照,不進行圖書的歸類處理,以每本書為單位采用傳統(tǒng)協(xié)同過濾的模式對數(shù)據(jù)集合進行處理,矩陣中的缺失值采用常用的處理方法以0填充,得到向用戶推薦的圖書集合B。

圖2 協(xié)同過濾matlab代碼片段
5.4 結(jié)果檢驗
(1)推薦郵件設計。

圖3 發(fā)送給學號尾號為046學生的推薦郵件

圖4 為學號尾號為046學生推薦的書目表片段
根據(jù)以上形成的推薦圖書集合A、B,可以得到每一位用戶的不同推薦書目。為方便用戶填寫反饋,將這兩個集合中相同的書目記錄進行去重合并,形成推薦書目表,將經(jīng)過計算且合并后的圖書以圖書館書目調(diào)研的名義發(fā)送至用戶的校園郵箱中。當然,在進行圖書推薦時,我們除了提供傳統(tǒng)的書目信息外,還會將索書號、圖書的基本信息以及本書的鏈接一并發(fā)送至用戶的郵箱,用戶打開鏈接后可直接查看到此書,同時網(wǎng)頁中還會呈現(xiàn)出其他用戶對該書的評價,以提供一定的參考。同時,考慮到數(shù)據(jù)的時滯性問題,需要用戶反饋的是選擇感興趣或已看過的書。因此,調(diào)研的問題是:假設你來到文學庫,以下文學類圖書你是否感興趣或是否看過,選出你感興趣或看過的圖書。推薦郵件如圖3所示。
為了測試推薦郵件的設計是否清晰明確,本研究先選擇5名同學進行小范圍測試,針對每位同學分別推薦兩種算法中排名前10的圖書,如對于學號尾號為046的學生,去重后,我們一共為其推薦14本書,具體書目列表如圖4所示。在其后的反饋郵件中,該同學選擇了《文學的邀請》、《鎖孔里的房間》、《徐志摩全集》、《莫言演講新編》、《魯迅雜文全編》和《張愛玲典藏全集》等書。
(2)推薦反饋處理。
使用上述方法,根據(jù)不同用戶得到的推薦書目集合分別編輯推薦郵件,然后向300名學生發(fā)送,共收到217份回復,回收率為72.3%。我們將用戶的反饋和兩種推薦集合中的推薦書目進行對比,分別計算兩種推薦方法的準確性,最后匯總計算各個集合的平均準確率(如表5所示):
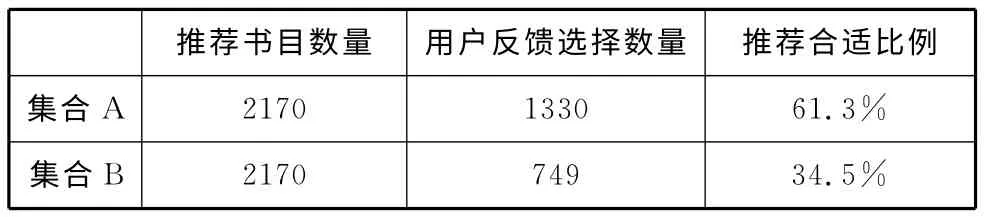
表5 兩種推薦方法的實驗結(jié)果對比
從表5所列出的兩種不同實驗結(jié)果我們可以看出,集合A中,有1330本是用戶反饋回來感興趣或者是已經(jīng)看過的圖書,推薦符合率為61.3%(1330/2170),集合B共有749本是用戶反饋回來感興趣或者是已經(jīng)看過的圖書,推薦符合率為34.5%(749/2170),該比例幾乎僅為集合A的1/2,這在一定程度上證明了結(jié)合圖書館編目數(shù)據(jù)的過濾推薦優(yōu)于傳統(tǒng)的過濾推薦。
通過該實驗可充分看出,相對于傳統(tǒng)協(xié)同過濾推薦來說,本文基于圖書館編目數(shù)據(jù)的協(xié)同過濾方法從推薦合適比例來說更加有效。
6 總結(jié)
本文分析了傳統(tǒng)協(xié)同過濾中存在的自動化和稀疏性問題,并提出了稀疏性問題的解決對策。通過借閱日志中的借閱、續(xù)借、預約三項操作設計了一個標準化的評分體系,根據(jù)借還書記錄自動實現(xiàn)用戶對所借閱圖書的評分,有效地解決了其評分主動性不高的問題;借鑒圖書館特有的編目體系,對圖書館現(xiàn)有文學庫中的圖書進行了重新歸類,將通過圖書組合尋找相似用戶的問題轉(zhuǎn)化為通過“類”的組合尋找相似用戶的問題。最后,以××大學圖書館文學庫為例,對本文中所提出的結(jié)合中圖法編目數(shù)據(jù)的協(xié)同過濾推薦算法進行了驗證,結(jié)果表明該方法較傳統(tǒng)的協(xié)同過濾具有更好的推薦效果。
1 Gartner.預計2014年全球設備總銷量.[2014-06-28].http://www.199it.com/archives/205633.html
2 亞馬遜公司(Amazon):世界上銷售量最大的網(wǎng)上書店.[2014-07-13].http://wiki.mbalib.com/wiki/Amazon
3 Pera M S,Condie N,et al.Personalized Book Recommendations Created by Using Social Media Data.WEB INFORMATION SYSTEMS ENGINEERING-WISE 2010 WORKSHOPS,2011,6724:390-403
4 唐秋鴻,曹紅兵.高校圖書館個性化專題推薦研究.圖書館學研究,2012,(13):53-59
5 李微娜,馬小琪.基于MADM方法的個性化推薦研究.現(xiàn)代情報,2011,31(4):20-23
6 李炎.電子商務推薦算法的研究與實現(xiàn),上海:復旦大學,2002
7 Leskovec J,Rajaraman A,Ullman J.Mining of Massive Data-sets,Cambridge University Press,2011
8 鄧愛林,左子葉,朱揚勇.基于項目聚類的協(xié)同過濾推薦算法.小型微型計算機系統(tǒng),2004,25(9):1665-1670
9 鄒永貴,望靖,劉兆宏,等.基于項目之間相似性的興趣點推薦方法.計算機應用研究,2012,29(1):116-118,126
10 Wang G F,Ren Y,Duan L Z,et,al.An Optimized Collaborative Filtering Approach with Item Hierarchy-Interestingness.in:International Conference on Business Computing and Global Information(BCGIN),2011:633-636
11 Ma H,King I,Michael R.Lyu.Effective Missing Data Prediction for Collaborative Filtering.in Proceedings of the 30th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval,New York:ACM,2007,39-46
12 Lee TQ,Park Y,Park YT.A Time-Based Approach to Effective Recommender Systems Using Implicit Feedback.Expert Systems with Applications,2008,34(4):3055-3062
13 Huang Z,Chen H,Zeng D.Applying Associative Retrieval Techniques to Alleviate the Sparsity Problem in Collaborative Filtering.IEEE Trans Information Systems,2004,22(1):116-142
14 同12
15 Ahn HJ.A New Similarity Measure for Collaborative Filtering to Alleviate the New User Cold-Starting Problem.Information Sciences,2008,178(1):37-51
猜你喜歡
文苑(2019年20期)2019-11-16 08:52:12
文苑(2018年17期)2018-11-09 01:29:40
小太陽畫報(2018年1期)2018-05-14 17:19:25
商用汽車(2016年11期)2016-12-19 01:20:16
少年博覽·小學低年級(2016年10期)2016-11-24 06:48:23
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
漫畫月刊·炫版(2015年4期)2015-05-27 07:52:10
創(chuàng)業(yè)家(2015年10期)2015-02-27 07:55:08
創(chuàng)業(yè)家(2015年10期)2015-02-27 07:54:39
