社交網絡中一種基于模塊化的社區檢測算法
2014-09-29 10:31:42崔泓
計算機工程 2014年7期
崔 泓
(渤海大學計算機教研部,遼寧 錦州 121013)
1 概述
許多社交網絡都具有社交結構這一屬性[1],假設頂點表示網絡用戶,連接線(鏈接)表示用戶的社交互動行為,則社交網絡可以很自然地分為多組頂點和少量連接線,其中,各組頂點的內部連接線非常密集,而各組間的連接線較少。各社交網絡社區的成員往往具有許多共性,如均對攝影、電影、音樂或其他討論主題感興趣;因此,他們彼此之間的交流頻率要比與社區之外成員的交流頻率高。檢測網絡社區可以提供關于社區內部結構及其組織的重要信息。此外,掌握網絡社區結構,可以提供網絡未知區域的有用信息,幫助預防病毒或蠕蟲擴散等潛在網絡威脅。文獻[2-3]對靜態網絡社區檢測進行了研究。
然而,現實世界的社交網絡并不總是靜態的。實際上,大多數社交網絡(如Facebook、Bebo和Twitter)處在發展變化中,隨著用戶數量的不斷上升,網絡規模和空間也在不斷發展,因此,這些網絡屬于動態網絡。動態網絡是一種非常特殊的進化類型復雜網絡,這種網絡會隨著時間的變化而不斷變化。動態社交網絡的拓撲結構變化太快且不可預測,大大增加了網絡社區結構檢測的難度和復雜性。
雖然網絡更新后,可以運行現有的各種靜態社區檢測算法[2-4]來確定新的社區結構,但是仍然會存在一些無法回避的問題:(1)面對大型網絡時,靜態算法耗時太長;(2)局部最優陷阱;(3)網絡發生局部微小變化時,算法響應幾乎完全相同。完成這一艱巨任務的效果更佳、效率更高、耗時更少的方法就是根據先前網絡結構對網絡社區進行自適應更新,避免重新計算,本文的研究正是圍繞這種自適應算法展開的,在保證社區檢測準確性的前提下,滿足社交網絡用戶的多樣化需求。
2 相關工作
人們對靜態網絡的社區檢測已經做了大量研究,并且針對這種網絡提出了多種高效的檢測算法。然而,對于動態網絡社區結構檢測方面的研究并不多。文獻[4]提出一種新的基于k-派系滲透的動態網絡社區檢測算法。該算法可以檢測重疊社區,但是耗時較長,對于大型網絡更是如此。文獻[5]提出一種基于網絡拓撲矛盾和拓撲概率的檢測算法,其中的拓撲概率是指一對節點參與某個社區的概率。該算法隨著網絡社區規模的增加,檢測的效率和效果急速下降,不適用于大規模社交網絡。文獻[6]提出一種基于信息論交互信息和熵函數的無參數算法,用于圖形進化時檢測聚類。文獻[7]提出一種分布式社區檢測算法,該算法使用模性代替目標函數作為檢測指標。文獻[8]試圖基于部分靜態網絡快照來跟蹤社區隨時間進化情況。然而文獻[6-8]中的方法都無法避免重新計算的問題,
另外,文獻[9]提出一種基于常量因子近似的動態社區檢測算法。但是,該算法需要事先定義的懲罰成本,而動態網絡往往無法知曉,因此該算法對現實世界的社交網絡不具有可行性。文獻[10]提出一種MANET網絡社交感知路由策略,該策略基于模性的處理步驟MIEN可以快速更新網絡結構。且MIEN可以生成/分解網絡社區以適應網絡變化,同時使用快速模性算法[11]以更新網絡社區。然而,該算法由于復雜度較高,應用于大型動態網絡時運行速度較慢。鑒于此,本文在已有工作的基礎上,提出一種用于社區結構檢測的自適應算法,并基于現實世界的動態社交網絡和MANET社交感知路由驗證其有效性。
3 問題建模
設 G=(V,E)為表示社交網絡的無向未加權圖,具有N個節點和M條鏈接。設 c={C1,C2,…,Ck}表示一組獨立的網絡社區,其中,Ci∈c是圖G的一個社區。對各個頂點u,用 du,C(u),N C(u)分別表示該頂點的度、包含該頂點的社區及其相鄰社區。此外,用分別表示總頂點集S內的鏈接數量、S的總頂點度,以及u至S間的鏈接數量。術語“社區”和“模塊”、“節點”和“頂點”、“鏈接”和“邊”可以互換使用。
定義1(動態社交網絡)設 Gs=(Vs,Es)表示時間S時的網絡快照,且網絡快照與時間相關。用 ΔVs、 ΔEs分別表示時間S時將要引入(或去除)的節點集和鏈路集,Δ Gs=(Δ Vs,Δ Es)表示整個網絡發生的變化。下一時刻的網絡快照 Gs+1是當前網絡快照和網絡變化的結合:Gs+1=Gs∪ ΔGs。動態網絡g是隨著時間變化而不斷進化的一組網絡快照序列:g=(G0,G1,…,Gs)。
定義2(目標函數)為了對網絡社區結構的品質進行定量描述,引用文獻[12]提出的最被廣泛接受的指標:模性?,定義為。一般地,?是社區所有鏈路比例減去圖中相同數量的期望值,該圖的節點具有相同的度數且鏈路隨機分布。模性?越高,網絡社區結構越優。于是,本文的目標就是針對網絡中的各個節點,確定一種社區分配使?最大。與社區檢測其他質量指標類似,指標?在局部性、標度[3]和分辨率等方面存在一定缺陷。但是?指標的魯棒性和可用性與人們對各種真實世界網絡的感知非常吻合,因此仍然得到廣泛應用。
問題描述:設有動態社交網絡 g=(G0,G1,…,Gs),G0是初始網絡,G1,G2,…,Gs是基于 ΔG1,Δ G2,…,Δ Gs獲得的網絡快照。需要確定一種自適應算法,以根據先前網絡快照高效檢測任意時刻的網絡社區結構,同時跟蹤網絡社區結構的進化情況。
4 改進的社區檢測算法
在此首先討論網絡拓撲結構進化時發生的變化對社區結構的影響。假設 G=(V,E)是當前網絡,c={C1,C2,…,Ck}是相應的社區結構。使用術語“區內鏈路”來表示2個端點均位于同一社區的鏈路,術語“區間鏈路”表示2個端點位于不同社區的鏈路。對G的各個社區C,將C與其他社區連接起來的鏈路數量,要遠低于C內鏈路數量;也就是說,C內節點的連接程度要比外部節點密集。可以看出,向社區內增加區內鏈接,或者是去除圖G的區間鏈接,均可以增加這些社區的強度,使圖G的結構更加清晰。反過來,去除區內鏈接或者增加區間鏈接將會弱化圖G的結構。然而,如果2個社區互相之間干擾較少,那么增加或者去除鏈接可以增加2個社區的吸引力,使得它們可以結合起來形成一個新的社區。于是,社區更新是一個非常復雜的過程,原因就是網絡拓撲中的任何微小變化都可能讓社區結構發生難以預料的變化。
為了反映社交網絡發生的變化,通過插入或刪除一個或一組節點、一條或一組鏈路,對圖進行持續更新。實際上,加入或刪除的節點(或鏈路)集合可以被分解成一組節點(或鏈路)的加入或刪除,其中,每次只加入或刪除一個節點(或鏈路)。這一結論可以把網絡變化看成是簡單事件的一個組合,其中的簡單事件是指加入節點、去除節點、加入鏈接、去除鏈接4種事件中的一種。具體內容如下:(1)加入節點(V +u):新節點u及其相關鏈接加入。連同u加入的鏈接數量可以是0條,也可以是多條。(2)去除節點(V -u):節點u及其相關鏈接從網絡中去除。(3)加入鏈接(E +e):連接現有2個節點的新鏈接e加入網絡。(4)去除鏈接(E -e):網絡現有鏈接e從網絡中去除。
4.1 新節點的加入
首先考慮第一種情況,新節點u及其相關鏈接加入網絡。注意,u可能沒有相鄰鏈接,也可能有多個鏈接連接了一或多個社區。如果u沒有相鄰鏈接,創建只包含u的一個新的社區,其余社區及總模性?保持不變。當u有多個鏈接連接一個或多個當前社區時,情況就會變得有趣起來。此時需要確定,u應該加入哪個社區,使獲得的模性最大。處理這一問題有多種局部算法[14]。本文算法受到文獻[15]的物理算法啟發,該算法中的每個節點受到2種力的影響:,使u保持在社區C內;社區C產生的使u屬于C的力。定義如下:其中,doutS與dS的含義相反。
具體過程見算法1。

4.2 新的鏈接
假設有新的鏈接 e=(u,υ)加入網絡,該鏈接連接了當前2個節點u,υ。將這種情況再細分為2個子情況:e是區內鏈接(完全位于社區C內);e是區間鏈接(連接 C(u),C(υ)2個社區)。根據引理1,如果e位于社區C內,則會增強C的內部結構。此外,根據引理2可知,添加e不應該導致當前社區C被分割成多個小社區。因此,在這種情況下,讓當前網絡結構保持不變。
引理1對任意C∈c,如果 dC≤ M-1,則在C內加入一條鏈接可以增加C的模性貢獻度。
定理2如果C是圖G當前快照下的一個社區,則向C中加入任意區內鏈接不會導致社區C被分割成多個小社區。
引理2如果新加入的鏈接(u,υ) 連接2個社區 C(u),C(υ),則如果(u或υ)欲更新其社區隸屬,C(v()或 C(u))是其最佳社區選擇。
當鏈接e連接了社區 C(u),C(υ)時可以發現,e的存在有可能讓 u(或者υ)脫離當前社區而加入到新的社區。另外,如果 u(或者υ)決定改變其社區屬性,它可以把新的社區信息發送給所有相鄰節點,部分相鄰節點可能會因此試圖改變社區隸屬。根據引理2,如果u(或者υ)欲改變其聚類分配,則 C(v()或 者C(u))是各自新的最佳社區歸屬。那么,當鏈接e加入時,應該如何迅速確定u(或者υ)是否應該改變其社區隸屬以形成更優社區結構。為此,在定理3中提出一種節點u和υ隸屬更改測試指標。此時,如果Δqu,C,D和Δqv,C,D均沒有滿足該指標,則可以維持當前網絡社區結構,繼續前進(推論)。否則,通過局部搜索和交換技術實現獲得的模性最大化,進而讓節點u,υ隸屬新的社區,相鄰節點確定欲加入的最優社區。
定理3假設新的鏈接(u,v)加入圖G。設 C≡C(u)且D≡C(υ)。如果:

則把u加入D將會增加總模性。
推論 如果定理3中的條件沒有滿足,則不應該把u(或υ)及其相鄰節點加入到社區D中。
圖1描述了后一種情況的處理步驟。

圖1 網絡拓撲進化對社區結構的影響
在圖1中,連接 C(u)和C(υ)的鏈接(u,υ)加入網絡。對集合X和Y進行社區隸屬更改測試,具體過程見算法2。

4.3 節點的刪除
當在時刻t把社區C的當前節點u刪除時,該節點的所有相鄰鏈接也同時刪除。由于此時生成的社區非常復雜,因此這種情況處理起來難度很大:生成的社區可能沒有變化,也有可能劃分成多個子社區,或與其他社區結合。為了對此有進一步了解,考慮2個極端情況:刪除的某個節點的度為1,刪除的某個節點的度最大。如果度為1的節點被刪除,則刪除后的社區沒有變化(引理3)。然而,當度數非常大的節點被刪除時(如圖2所示),當前社區可能會被拆分為多個小社區,進而與其他社區融合。因此,當C中某個節點被刪除時,需要檢測刪除節點后C的結構。

圖2 新社區的形成
引理3如果C1和C2是G的2個社區,那么刪除連接這2個社區的區間鏈接將會增加C1和C2的模性貢獻值。
為了快速有效地處理這種情況,利用文獻[2]中提出的派系過濾算法。尤其當節點u從C中刪除時,對其個相鄰節點設置3-派系,實施派系過濾,直到C中沒有節點被發現(見圖3,當中央節點g刪除后,對a設置3-派系過濾,檢測到b,c,d,e。隨后 f落單)。然后,讓C剩余社區選擇各自最佳融合社區。具體算法見算法3。
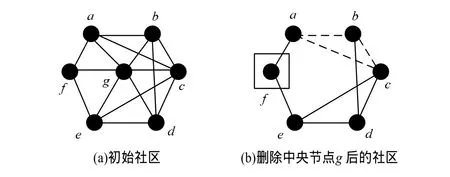
圖3 社區融合

4.4 鏈接的刪除
當欲刪除鏈接 e=(u,υ)時,可以具體分為4種子情況:(1)e是個只連接u和υ的單邊,其中,u和υ的度均為1;(2)u和υ中只有一個節點的度為1;(3)e是個連接 C(u)和C(υ)的區間鏈路;(4)e是個區內鏈接。如果e是個單邊,很明顯刪除e后的社區結構不會改變,同時生成2個單獨節點u和υ。同樣的結論適用于第2種子情況;根據引理4,u和υ中只有一個節點的度為1,使原先網絡結構附加上頂點u和υ。當節點e是區間鏈路時,刪除e將會加強當前網絡社區結構(引理3),不會對社區結構造成改變。
引理4將社區C內的(u,υ) 刪除,且u或υ的度為1,則不會導致C被分割。
最后一種子情況是刪除區內連接,最為復雜。如圖4所示,如果社區本身鏈接很密,則刪除這種類型的鏈接不會讓社區產生變化;然而,如果社區內的部分結構內凝力有限,互相之間連接不夠緊密,則該社區有可能會被分割。因此,檢測刪除之后剩余社區的結構,非常復雜。當區內鏈接從宿主社區C中刪除時,引理4為檢測社區進而將其一分為二提供了一個便捷工具。然而,它需要對C的所有子集加以詳細考察,這一過程非常耗時。請注意,在刪除(u,υ) 前,內含這一鏈接的社區C在其內部應該具有緊密的連接,因此刪除(u,υ)應該會在C的內部生成“準派系”結構。于是,在當前社區內確定所有最大“準派系”,讓這些“準派系”(及剩余的單個節點)確定加入哪些最優社區。具體過程見算法4。

圖4 鏈接的刪除


定理4(模性分割測試)對任意社區C,設α和β分別是C中度數最低的節點和度數第二高的節點。假設鏈接e從C中刪除。如果沒有子集C1?C和C2≡C C1滿足以下條件:
(1)e越過C1和C2
則將C一分為二并不會使總體?值上升。
4.5 本文算法
綜上所述,本文提出的動態社交網絡社區結構快速更新算法QCA的具體內容見算法5。


5 實驗結果與分析
本節給出動態社交網絡社區結構快速檢測和更新算法QCA的實驗結果。為了闡述本文算法的有效性,選用Facebook在線社交網絡[16]進行了實驗。比較對象是文獻[13]中提出的靜態檢測算法(或稱為Blondel算法)。除了靜態算法外,還將QCA與文獻[10]最近提出的動態自適應MIEN算法加以比較。MIEN算法將網絡社區壓縮或解壓為節點,以適應網絡變化,然后使用文獻[14]中的快速社區檢測算法對網絡結構進行更新。且在實驗中展現以下數值:(1)模性數值;(2)通過NMI分值衡量的網絡社區質量;(3)本文QCA算法相對其他算法的處理時間。上述網絡由于模性較高,因此包含的社區結構非常清晰,這也是本文選用上述網絡的主要原因。
為了對發現社區結構的質量(即檢測出來的社區與真實情況間的相似度)進行定量描述,采用信息理論領域常用的歸一化交互信息(NMI)指標。NMI指標可靠性高,文獻[2]將其應用于社區檢測算法評估中。如果社區結構U和V完全分開時完全相同且均等于0,則 NMI(U,V)等于1。由于篇幅限制,可以閱讀文獻[3]獲得NMI的完整表達式。
對各個網絡,使用不同的方法提取時間信息,收集部分網絡數據(往往是首個網絡快照)以形成基本的網絡社區結構。本文的QCA算法以此基本的社區結構為基礎,只有網絡發生變化時才會運行,此時必須在各時間點上針對整個網絡快照運行靜態算法。
Facebook網絡數據集包含2009年9月-2012年1月期間新奧爾良Facebook局部網絡的好友信息。為了收集信息,創建了幾個Facebook賬戶,每個賬戶均加入局部網絡,從單個用戶開始緩慢發展,用廣度優先搜索方式訪問所有好友。數據集含有60k以上的節點(用戶),150多萬條好友鏈接,節點度數平均達到23.5。在本文實驗中,2009年9月-2009年12月期間的節點和鏈接用于生成網絡基本社區結構;在2010年1月-2012年1月期間,每月生成一次網絡快照,共生成25個網絡快照。實驗結果如圖5所示。

圖5 Facebook社交網絡仿真結果
圖5(a)的評估結果表明,QCA算法的模性計算結果與靜態算法相當,但是遠高于MIEN算法。從總體趨勢來說,QCA曲線與靜態算法非常接近,且更加平穩。此外,實驗結束時2種算法的最終模性結果基本相同,這意味著本文算法與針對整個網絡的靜態算法性能相當。
圖5(c)描述了3種算法對Facebook數據集的運行時間。從圖中可以看出,QCA成功計算和更新每個網絡快照需要耗時至少3 s,最多4.5 s,而靜態算法的耗時是QCA的3倍。MIEN算法面對Facebook大型網絡時,耗時問題更加嚴重,所需時間是QCA算法的10倍以上。這一結果證明了本文算法應用于現實世界社交網絡上的有效性;面對現實世界的社交網絡,集中式算法往往無法在有限時間內有效檢測出高質量社區結構。
6 應用示例
最近,部分研究人員指出,MANET具有社交網絡特性,而具有社交感知功能的網絡路由算法具有巨大潛力。這是因為人們傾向于在通信網絡中形成多個群組或社區,各社區內個體互相之間的通信頻率要高于與社區外個體的交流頻率。網絡社區結構檢測對MANET移動自組網絡的路由策略具有重要作用。對以下5種路由策略進行評估:(1)WAIT策略:源節點處于等待狀態,不停發送或轉發消息,直到遇到目的節點;(2)MCP策略:節點不停轉發消息,直至達到跳躍最大值;(3)LABEL策略[17]:節點將消息發送或轉發給目的社區的所有成員;(4)QCA策略:使用QCA算法作為動態社區檢測技術的LABEL策略;(5)MIEN策略:對MANET網絡使用社交感知路由策略[10]。
使用MIT媒體實驗室提供的真實數據集[18]來測試本文算法。現實挖掘數據集包括MIT 100名學生在2011學年-2012學年的通信、附近、位置、活動信息。且該數據集還有相關學生350000 h(40年)期間的博客、附近藍牙設備、手機信號塔編號、應用程序使用、手機狀態(充電,空閑)信息。本文使用藍牙信息生成底層MANET網絡,對以上5種路由策略加以評估。
對各種路由策略,評估以下指標:(1)輸送比:成功發送的消息與總消息之比;(2)平均輸送時間:每條消息被發送的平均時間;(3)每條消息被發送時產生的消息副本平均數量。請注意,生成的1000條消息在實驗期間內均勻分布,每條消息存在時間不得超過生存時間閾值。
實驗結果如圖6所示。圖6(a)將輸送比看成是生存時間的函數。如圖所示,QCA的輸送比遠高于MIEN、LABEL和WAIT算法,這意味著QCA將消息從源節點成功發送至目的節點的數量高于其他算法。此外,當生存時間上升時,QCA算法的輸送比趨近于輸送比最高的MCP算法。如圖6(c)所示,對輸送時間比較后發現,QCA算法所需時間更少,消息成功傳輸速度高于LABEL算法。QCA算法的傳輸時間甚至要低于社交感知MIEN算法。具體原因如下:LABEL算法在實驗期間最終改變其社區歸屬時,會將消息發往錯誤的社區。另外,OCA和MIEN算法在網絡發生變化時可以迅速實現社區結構的檢測和更新,因此性能更優。由于MIEN在網絡進化時需要壓縮/解壓縮網絡社區,因此可能忽略新生成的社區,導致需要額外時間轉發消息。圖6(b)顯示的消息副本數量表明,QCA和MIEN在這方面性能最優。MCP算法的消息副本數量高于其他算法,此處沒有繪出。實際上,QCA和MIEN算法結果相對接近;生存時間上升時,兩者接近程度同步上升。總體來講,QCA算法的輸送比、輸送時間和冗余度均優于其他算法,只在消息冗余度較低時劣于MCP算法,因此是5種路由策略中性能最優的社交感知路由策略。QCA算法的性能遠高于基于靜態社區檢測的原始LABEL算法。以上結論證明本文自適應算法適用于MANET網絡的路由策略。
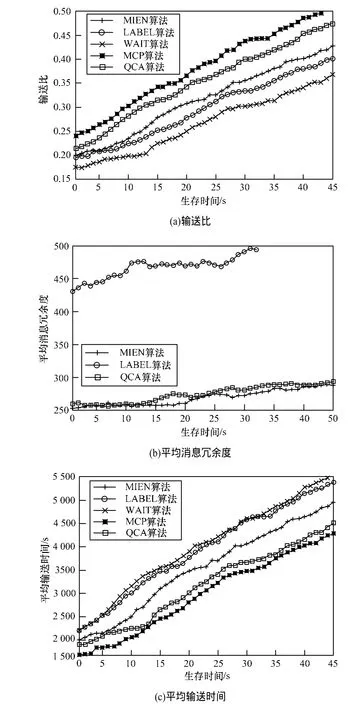
圖6 不同算法在真實數據集下的實驗結果
7 結束語
本文針對變化頻率較高的動態社交網絡,提出一種社區結構自適應檢測算法QCA。該算法不僅可以有效更新檢測高質量網絡社區結構,而且運行時間較小,適宜變化頻率很高的大型在線社交網絡。將本文算法應用于MANET社交感知路由策略中,證明了QCA算法可以集成為社區檢測內核,廣泛應用于移動計算領域。下一步工作的重點是考慮社區內用戶的共同興趣度和社區間用戶的興趣相似度,研究基于興趣感知的社區挖掘算法。
[1]喬秀全,楊 春,李曉峰,等.社交網絡服務中一種基于用戶上下文的信任度計算方法[J].計算機學報,2011,34(12):2403-2413.
[2]陳 瓊,李輝輝,肖南峰.基于節點動態屬性相似性的社會網絡社區推薦算法[J].計算機應用,2010,30(5):1-5.
[3]Fortunato S.Community Detection in Graphs[J].Physics Reports,2010,486(3):75-174.
[4]Ahn Y Y,Bagrow J P,Lehmann S.Link Communities Reveal Multiscale Complexity in Networks[J]. Nature,2010,466(7307):761-764
[5]Zhang Yuzhou,Wang Jianyong,Wang Yi,et al.Parallel Community Detection on Large Networks with Propinquity Dynamics[C]//Proc.of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.[S.l.]:ACM Press,2009:997-1006.
[6]Sun Jimeng,Faloutsos C,Papadimitriou S,et al.Graphscope:Parameter-free Mining of Large Time-evolving Graphs[C]//Proc.of the 13th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.[S.l]:ACM Press,2007:687-696.
[7]Capocci A,Servedio V D P,Caldarelli G,et al.Detecting Communities in Large Networks[J].Physica A:Statistical Mechanics and Its Applications,2005,352(2):669-676.
[8]Hopcroft J,Khan O,Kulis B,et al.Tracking Evolving Communities in Large Linked Networks[J].Proceedings of the National Academy of Sciences of the United States of America,2012,101(S1):5249-5253.
[9]Tantipathananandh C,Berger-wolf T.Constant-factor Approximation Algorithms for Identifying Dynamic Communities[C]//Proc.of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.[S.l.]:ACM Press,2009:827-836.
[10]Dinh T N,Xuan Ying,Thai M T.Towards Social-aware Routing in Dynamic Communication Networks[C]//Proc.of the 28th IEEE International on Performance Computing and Communications Conference.[S.l.]:IEEE Press,2009:161-168.
[11]Chen Duanbing,Fu Yan,Shang Mingsheng.A Fast and Efficient Heuristic Algorithm for Detecting Community Structures in Complex Networks[J].Physica A:Statistical Mechanics and Its Applications,2009,388(13):2741-2749.
[12]NewmanM E J,GirvanM.Finding and Evaluating Community Structure in Networks[J].Physical Review E,2004,69(2):261-269.
[13]Blondel V D,Guillaume J L,Lambiotte R,et al.Fast Unfolding of Communities in Large Networks[J].Journal of Statistical Mechanics:Theory and Experiment,2008,8(10):1742-1754.
[14]Newman M E J.Fast Algorithm for Detecting Community Structure in Networks[J].Physical Review E,2004,69(6):66-73.
[15]Ye Zhenqing,Hu Songnian,Yu Jun.Adaptive Clustering Algorithm for Community Detection in Complex Networks[J].Physical Review E,2008,78(4):461-468.
[16]馬昱欣,徐佳逸,彭帝超,等.基于可視分析的多上下文移動社交網絡社區發現[J].計算機科學與技術學報,2013,28(5):797-809.
[17]Pan Hui,Crowcroft J.How Small Labels Create Big Improvements[C]//Proc.of the 5th Annual IEEE International Conference on Pervasive Computing and Communications Workshops.[S.l.]:IEEE Press,2007:65-70.
[18]Eagle N,Pentland A.Reality Mining:Sensing Complex Social Systems[J].Personal and Ubiquitous Computing,2011,10(4):255-268.
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
哲學評論(2021年2期)2021-08-22 01:53:34
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中華詩詞(2019年7期)2019-11-25 01:43:04
模具制造(2019年3期)2019-06-06 02:10:54
影視與戲劇評論(2016年0期)2016-11-23 05:26:01
海峽科技與產業(2016年3期)2016-05-17 04:32:12
