基于條件隨機場的敏感話題檢測模型研究
2014-09-29 10:32:28翟東海崔靜靜聶洪玉
計算機工程 2014年8期
翟東海,崔靜靜,聶洪玉,于 磊,杜 佳
(1.西南交通大學信息科學與技術學院,成都 610031;2.西藏大學工學院,拉薩 850000)
1 概述
敏感話題檢測是網絡輿情檢測技術中的重要子課題,通過敏感話題檢測能夠將網絡中涉及的暴力、色情和非法煽動等信息及時發現并監管,對于維護網絡健康發展和社會穩定有著極其重要的影響。因此,敏感話題的檢測對于及時把握輿情動態、積極引導健康的社會輿論有著重大的作用和意義。文獻[1]提出的話題識別與跟蹤算法能夠發現和追蹤文本流中的重要信息;文獻[2]提出一種基于衰老理論(aging theory)的熱點話題檢測方法,可以有效發現一段時間內BBS上的熱點話題;文獻[3]提出和實現的雙語Web內容過濾智能分類引擎,能夠識別包含色情信息的中文和英文網頁。文獻[4]在動態知識庫中構建了一顆動態層次語義樹,隨著敏感文本的不斷到來,動態更新語義樹。現階段國內外對敏感話題檢測的研究雖然已經取得了一定的進展,但是完全針對敏感話題檢測的算法還有待完善,精確度也有待提高。
敏感話題通常包含態度傾向性,且具有一定的先驗知識,因此,如何有效利用這些先驗知識來判斷網絡文本的敏感性是敏感話題檢測的研究難點和熱點。在充分利用條件隨機場強大的知識擬合能力的基礎上,本文提出了一種基于條件隨機場的敏感話題檢測模型。首先介紹敏感話題類別和待測文檔的表示方式,然后對敏感話題檢測的條件隨機場模型進行研究,在此基礎上實現待測文檔的的敏感性標注。
2 敏感話題檢測模型
在文獻[4]中,敏感話題被定義為不利于社會穩定的言論,一般包括暴力類、色情類和其他。敏感話題通常具有一定的先驗知識,并且包含態度傾向性的特點,因此,敏感話題檢測方法不同于傳統的話題檢測方法[5]。條件隨機場是一種概率圖模型,具有強大的知識擬合能力[6],可以將敏感話題的多個特征聯合考慮,實現網絡中敏感文本的快速發現。本文中敏感話題檢測主要包括2個部分,網絡文本的表示和敏感文本的識別,針對敏感話題已有的先驗知識,結合CRFs模型,本文提出了基于CRFs的敏感話題檢測模型。在獲取網絡文本后,結合敏感詞匯庫中的種子敏感詞完成網絡文本的表示,然后通過訓練好的基于CRFs的敏感話題識別模型來對文本的敏感度進行估計,當敏感度的可信度超過閾值θ時,就可以判定該文本是否為敏感話題以及其所屬敏感話題的類別。本文的整體實現框圖如圖1所示。
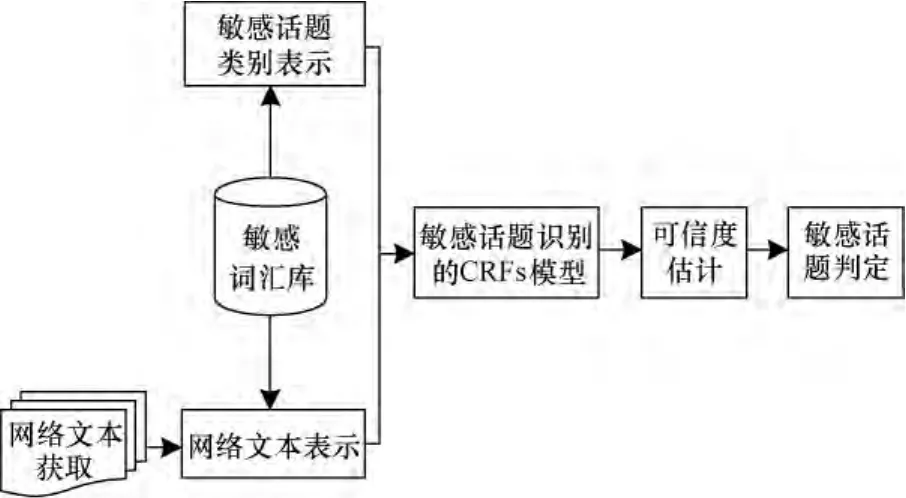
圖1 基于CRFs的敏感話題識別框圖
3 網絡文本和敏感話題類別的表示
3.1 網絡文本的表示
對通過特征提取后,在本文的CRFs敏感話題識別模型中,將待檢測的文本表示為CRFs模型中的觀察序列進行處理。在眾多話題表示方法中,VSM(Vector Space Model)和 TF-IDF(Term Frequency Inverse Document Frequency)是一種非常有效的話題表示方式。由于敏感話題通常會涉及一些固有的敏感詞匯,如“上訪”、“拆遷”等,和一些包含態度傾向性的詞匯,如“邪惡”、“屠殺”等,因此在對網絡文本進行話題表示時,需要盡量將一些重要的敏感詞匯和能代表作者態度的傾向詞提取到特征詞中。文獻[7]在傳統的TF-IDF公式中增加了傾向性因子來提高特征抽取的效率,本文借鑒這種思想,將該傾向性因子改造為敏感性因子。這樣,文本中第i個詞項(itemi)的權重(weighti)計算公式如下:
weighti=TF(itemi)·lb(IDF(itemi))·γi(1)其中,TF為詞頻;IDF為逆文檔頻率;γi為敏感性因子。文檔中的第i個詞項的敏感性因子γi被定義為該詞語與敏感詞匯庫中各個種子詞的點互信息(Pointwise Mutual Information,PMI)的平均值:
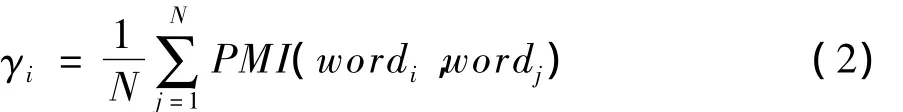
其中,N為敏感詞匯庫中種子敏感詞的總數。在該計算方法中,最主要的是計算詞語間的關聯度,即通過計算特征詞與敏感詞匯庫中種子詞的點互信息PMI得到:

其中,p(word1&word2)表示word1和word2在語料中同時出現的概率;p(word1),p(word2)分別表示word1和word2在語料中獨立出現的概率。
待檢測文本d中的每個特征詞項itemi由具有3個屬性的三元組表示,這3個屬性值包括該詞項權重(weighti)、敏感性(polarityi)、詞性(part-ofspeech,posi)。其中,敏感性(polarityi)的值等同于敏感性因子 γi,詞性(posi)的獲得方法參見文獻[8]:
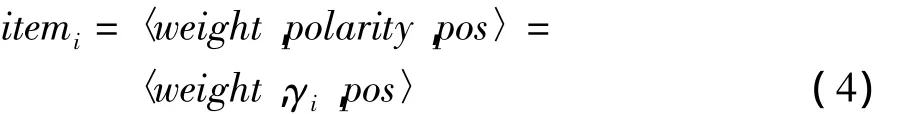
將所求得的待測文本d的特征項項依據其weight值的大小降序排列,并從中選取n個特征項組成一個特征詞項序列用來表示待測文本:
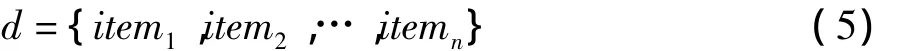
3.2 敏感話題類別的表示
在CRFs敏感話題檢測模型中,通過特征選擇的方法,結合敏感詞匯庫,選取敏感文本中區分能力較強的敏感特征詞項,從而將敏感話題的類別表示為CRFs模型中的狀態序列。根據描述內容的不同將敏感話題庫中的敏感話題分為若干類別{case1,case2,…,casek},并為每一類別選擇一組最能反映該類別特性的特征詞項,作為其狀態序列:
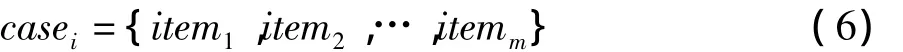
4 特征函數的構造
經過3.1節和3.2節的步驟后,CRFs模型中的觀察節點和狀態節點就與待檢測文檔和敏感話題類別建立了對應關系。然而,CRFs中另一個非常重要的任務是如何針對特定的需求為模型選擇合適的特征集合,并用集合中的特征來構造特征函數,用于敏感話題類別判定。
在構造特征函數之前,先在訓練集中構造觀察值序列即樣本文檔d′的真實特征集合b(item′x,i),所有i位置觀察值item′x的真實特征。每個特征函數表示為觀察序列真實特征b(item′x,i)集合中的一個元素,并為當前狀態(狀態特征函數)或前一個狀態和當前狀態(轉移特征函數)定義一個特定的值(通常用0和1來表示)。例如狀態特征函數抽取的具體過程如下:首先判斷訓練集中樣本文檔 d′={item′1,item′2,…,item′n}中的第 i個特征詞項是否具有敏感特征,如人名;然后再判斷該特征項是否為敏感詞匯庫中的種子詞:

4.1 狀態特征函數
4.1.1 關聯度特征函數
敏感詞匯的統計特征表明,文本的特征詞表示序列中包含敏感詞匯越多,該文本越有可能討論敏感話題[9],因此,待測文檔d屬于某一敏感話題類別的判定問題就可以轉化為待測文檔中的特征詞與敏感話題類別中特征詞的相關度判定問題。而如果2個詞在語料庫中所處的語言環境總是非常相似,則認為這2個詞的相關度很大。這樣,可以將詞間關聯度作為評估文檔和敏感話題類別相關度的一個特征。在CRFs模型中,待測文檔和敏感話題類別中特征詞之間的關聯度特征函數形式如下所示:
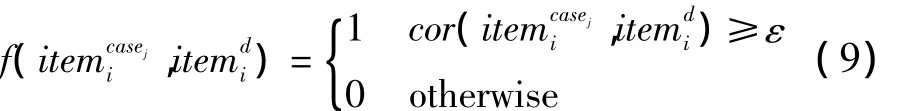
其中,ε為詞項間的關聯度閾值,當2個詞項之間的關聯度超過一定的閾值時就可以判定它們是相關的;cor(·)為待測文檔中的特征詞與敏感話題類別中的特征詞之間的關聯度,計算方法如下:
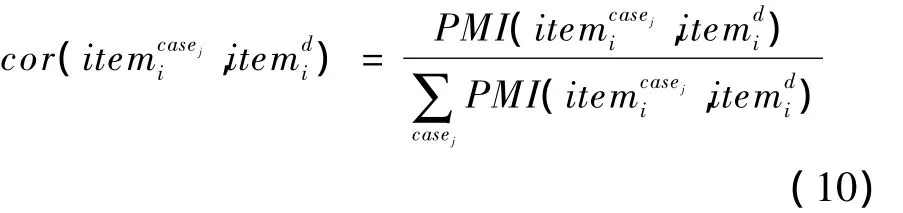
其中,分子部分為待測文檔中特征詞與敏感話題類別的某個特征詞的互信息;分母表示待測文檔中特征詞與敏感話題類別的所有特征詞互信息的總和。
4.1.2 詞項的屬性特征函數
一般的,同一個詞的不同詞性會使該詞具有不同的意義和不同的敏感性強度。通常情況下,命名實體和動詞成為敏感性詞匯的可能性要大于其他詞性,同時,情感詞匯也是敏感詞匯的一個重要組成部分。因此,就可以利用詞語的詞性和它的情感極性以及在文本中的位置來構造屬性特征函數。本文中用到的詞項屬性特征如表1所示。

表1 詞項屬性特征
4.2 轉移特征函數的定義
在待測文檔特征詞序列的敏感性標注過程中,前一詞項的敏感性標注對當前詞項的敏感性標注是有影響的,因此,本文定義了詞項間敏感性標注的轉移特征函數,例如,當觀察序列中的當前詞項xt在中國機構名詞典中,并且狀態序列中前一詞項的敏感性標記yi-1為極性詞,當前詞項的敏感性標記yi為敏感機構體時,特征函數應取值為1。本文中用到的轉移特征模板如表2所示。

表2 轉移特征函數
5 敏感話題檢測的CRFs模型
5.1 CRFs模型
條件隨機場是一種用于在給定輸入節點值時計算指定輸出節點值的條件概率的無向圖模型,能夠較好地解決序列標記問題。對于輸入序列x和輸出序列y,線性鏈式條件隨機場模型可以被定義為[10]:
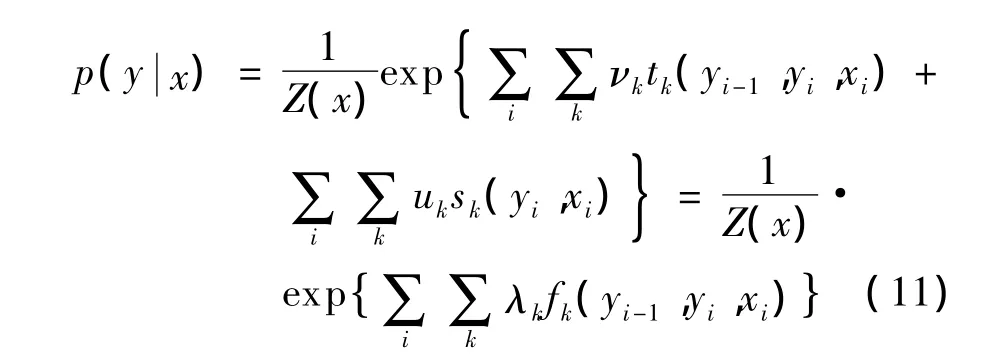
其中,tk是轉移特征函數,對應于 CRFs模型中邊〈yi-1,yi〉上的特征;sk是狀態特征函數,對應于 CRFs模型中第i個位置上輸入-輸出節點的特征;vk和uk是特征函數的權值,通常將tk和sk寫為統一形式fk;Z(x)是歸一化因子。CRFs可以將模型中各元素自身的屬性特征以及各元素之間的長距離依賴特征和重疊特征進行量化運用到模型中,因此,CRFs有強大的特征擬合能力,通過利用領域知識,能夠獲得全局最優標記[11]。
在本文中,待測文檔中的每個特征項被依概率標注為敏感話題類別中的詞項,其中,最大概率的狀態序列采用Viterbi算法[12]獲得。在Viterbi算法中,需要建立詞項之間的關系矩陣,如某類別的關系矩陣見表3,aij表示第i個詞和第j個詞之間的關系(如上下文關系),若2個詞之間無任何關系,則aij=0。

表3 詞項之間的轉移關系
5.2 CRFs模型的訓練
CRFs模型的訓練[11]是采用對數最大似然估計從訓練集中估計每個特征函數的權重參數Λ={λ1,λ2,…,λn},對于訓練集 D={〈x,y〉(1),〈x,y〉(2),…,〈x,y〉(i),…,〈x,y〉(N)},似然函數如下:
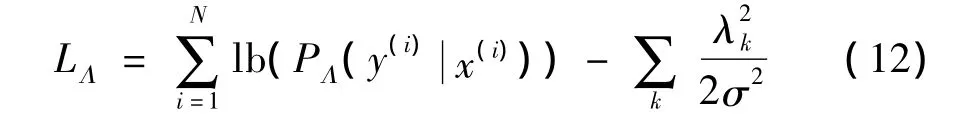
其中,第2項為高斯先驗值,是一個用于平滑處理的特征參數,其方差為σ2。本文使用L-BFGS(Limited Memory Broyden-Fletcher-Goldfarb-Shanno)算 法 實現對目標函數的優化求解,L-BFGS可以被簡單地看作一個黑盒優化過程,僅需要提供似然函數的一階導數,則訓練集的對數似然估計的一階導數為:
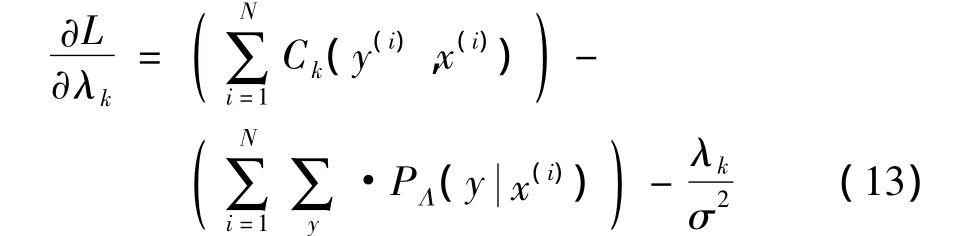
其中,Ck(y,x)是表示y中各位置i上的特征函數fk的和,上式中前2項的差對應于特征的經驗期望值與模型的期望值的差[fk]-EΛ[fk]N,第3 項為高斯先驗值的導數。
5.3 文本的敏感性標記
設話題類別集合 case={case1,case2,…,casen},按上文所述建立CRFs的敏感話題檢測模型,如圖2所示,具體檢測方法如下:
(1)獲取待測文檔,并表示為觀察序列d={item1,item2,…,itemn},作為 CRFs模型的輸入。
(2)在給定輸入序列(觀察序列)的條件下,計算每一個標記序列(狀態序列)的概率,將具有最大概率的標記序列對應的類別標簽作為待檢測文檔的候選話題類別casej。
(3)判斷各候選話題類別對應的概率值,若大于閾值θ,則將該文檔歸入概率值最大的敏感話題類別中,若小于閾值,則認為該文檔不是敏感話題。
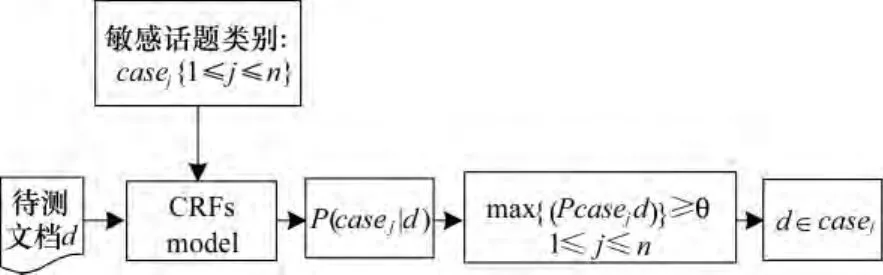
圖2 文檔敏感類別標記流程
如果待測文檔d的候選話題類別不止一個,則計算文檔d與各候選話題類別特征向量之間的Hellinger距離,并將文檔那個d歸入距離最短的那個類別。
6 實驗結果與分析
6.1 訓練數據
實驗采集2011年8月-2012年3月的國內各大新聞網站的100000個新聞網頁(大多數是論壇和博客的帖子)作為本文實驗的語料庫,所采集的數據信息包括標題、內容、發布時間等,如表4所示。敏感話題類別采用 ODP(Open Directory Project)網站(www.dmoz.org)定義的16個大的主題類別,包含暴力、色情等,訓練數據集是從語料庫中選取的包含敏感性話題的20000個網頁文本,它們被標注為16個敏感話題類別。

表4 詞項屬性特征列表
6.2 測試數據集
為了測試本文方法的有效性,仍采用在線網頁作為測試數據集,抽取2012年4月-2012年8月的100000個網頁作為測試數據集。
6.3 評價標準
在本文中,敏感話題檢測的評測標準采用信息檢索中廣泛使用的準確率(Precision)和召回率(Recall)及 F 度量值[13],算法如下:
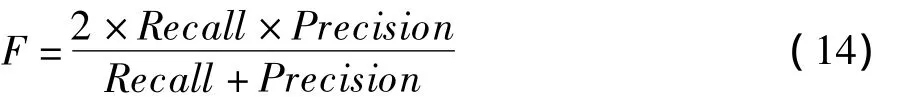
其中,準確率Precision是正確標記文本和標記文本總數的比值;召回率Recall是正確標記文本和實際正確標記文本總數的比值。
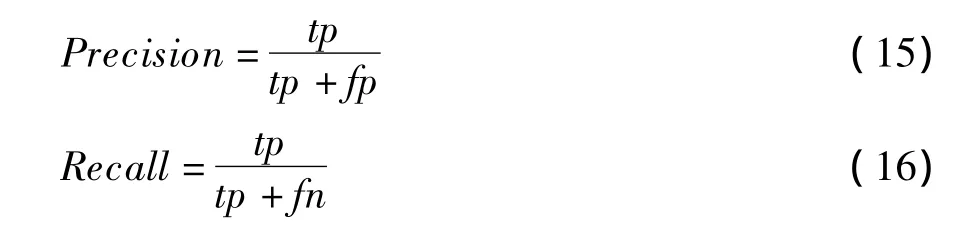
其中,tp為屬于敏感話題且被正確標記的文本數;fp為不屬于敏感話題但被標記的文本數,即錯誤標記數;fn為屬于敏感話題但未被標記出的文本數,即漏檢文本數。
6.4 結果分析
為了能夠客觀地評價本文提出的基于CRFs的敏感話題檢測模型的效果,根據訓練數據集與測試數據集的不同關系,本文實驗分別采用了封閉測試和開放測試來進行評測,并且以貝葉斯模型為對比實驗,雙方均以敏感詞作為文本的特征項。據此,本文一共做了4組敏感話題檢測實驗,前2組為封閉測試的基于CRFs的敏感話題檢測模型與貝葉斯模型2種方法的測試結果,后2組為開方測試的基于CRFs的敏感話題檢測模型與貝葉斯模型2種方法的測試結果,結果如表5和圖3所示。
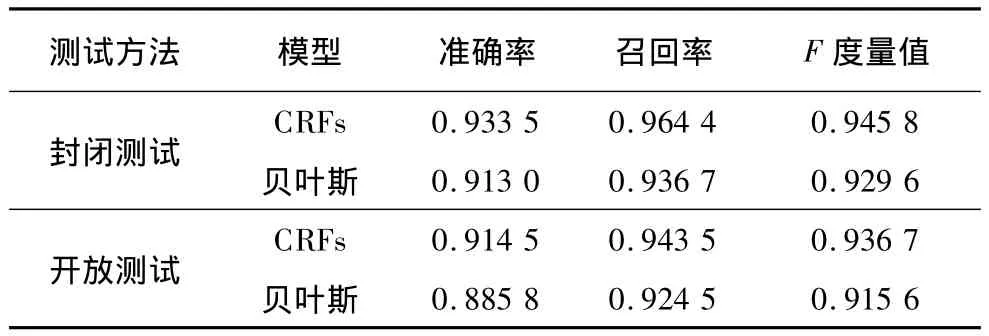
表5 CRFs模型與貝葉斯模型的實驗結果對比
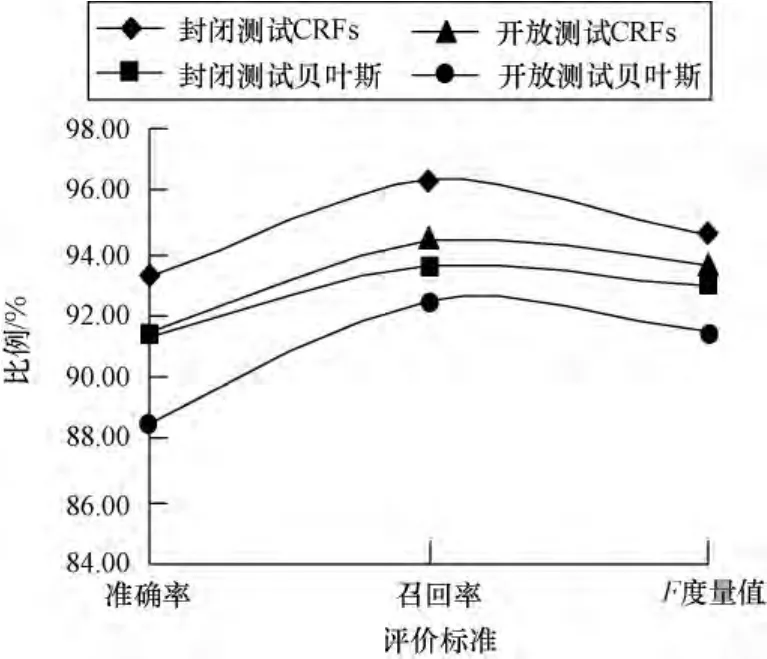
圖3 CRFs模型與貝葉斯模型的實驗結果對比
從表5和圖3中可以看出,同樣是概率模型,由于基于CRFs的敏感話題檢測模型考慮了所有詞語間的相關性,能夠將更多的信息納入到文本中來,因此,在F度量值、準確率(Precision)和召回率(Recall)上取得了更好的效果。
為了分析特征對CRFs模型的影響,本文實驗對不同的特征數量進行了實驗,基于CRFs模型的敏感話題檢測的F值隨CRFs模型中特征數量的變化趨勢見圖4。由圖4可知,隨著選擇特征數量的增加,F值不斷增加,算法有效性提高,當特征數量超過一定值后(num(features)>14)后,F值先是變化不大,然后有所下降,因為特征的引入帶來了一定的噪聲,系統的效率也會隨特征的增加而不斷降低。
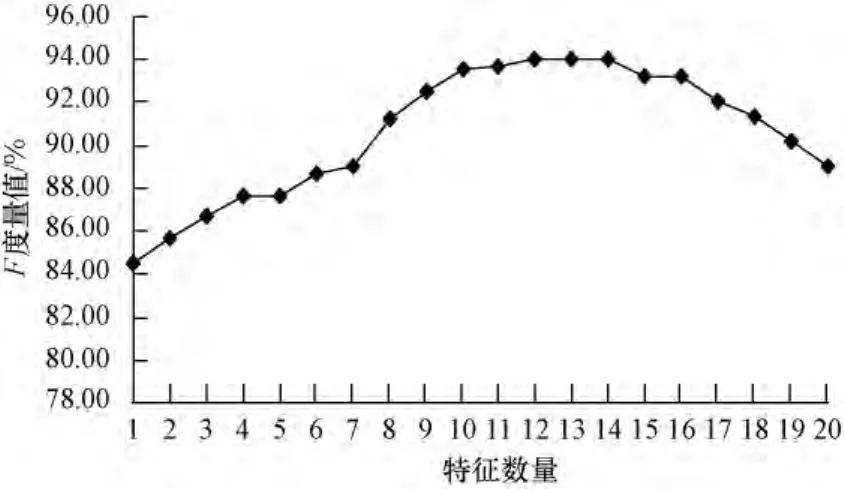
圖4 CRFs模型中特征數量對F值的影響
7 結束語
本文在充分分析敏感話題特點的基礎上,提出了基于條件隨機場的敏感話題檢測模型。在文本表示方面,本文利用了敏感性因子加權的特征詞提取方法;在敏感性檢測時,充分分析了敏感話題所具有的敏感性特征,利用條件隨機場概率圖模型對各種敏感特征知識進行擬合和推斷。最后通過實驗證明,該方法與傳統的貝葉斯方法相比,在敏感話題識別方面具有較好的性能,下一步將考慮時間因素對敏感話題檢測的影響,并在此基礎上對條件隨機場模型進行擴展。
[1]Wayne C L.Multilingual Topic Detection and Tracking:Successful Research Enabled by Corpora and Evaluation[C]//Proc.of Language Resources and Evaluation Conference.Athens,Greece:[s.n.],2000:1487-1494.
[2]Zheng Donghui,Li Fang.Hot Topic Detection on BBS Using Aging Theory[C]//Proc.of International Conference on Web Information Systems and Mining.Shanghai,China:[s.n.],2009:129-138.
[3]Lee P,Hui S,Fong A C M.An Intelligent Categorization Engine for Bilingual Web Content Filtering[J].IEEE Transactions on Multimedia,2005,7(6):1183-1190.
[4]Zhao Liyong,Zhao Chongchong,Pang Jingqin,et al.Sensitive Topic Detection Model Based on Collaboration of Dynamic Case Knowledge Base[C]//Proc.of the 20th IEEE International Workshops on Enabling Technologies:Infrastructure for Collaborative Enter-prises.Athens,Greece:[s.n.],2011:156-161.
[5]Zhao Liyong,Li Aimin.A Novel System for Sensitive Topic Detection and Alert Assessment[C]//Proc.of the 8th International Conference on Fuzzy Systems and Knowledge Discovery.Shanghai,China:[s.n.],2011:1751-1755.
[6]Settles B.Biomedical Named Entity Recognition Using Conditional Random Fields and Rich Feature Sets[C]//Proc.of the International Joint Workshop on Natural Language Processing in Biomedicine and Its Applications.Stroudsburg,USA:[s.n.],2006:1279-1288.
[7]劉 霽,周亞東,高 峰,等.一種基于文本語義的網絡敏感話題識別方法[J].深圳信息職業技術學院學報,2011,9(3):33-37.
[8]李軍輝,周國棟,朱巧明,等.中文名詞性謂詞語義角色標注[J].軟件學報,2011,22(8):1725-1737.
[9]Budanitsky A,HirstG.Evaluating Word Net-based Measures of Lexical Semantic Relatedness[J].Computational Linguistics,2006,32(1):13-47.
[10]Lafferty J,McCallum A,Pereira F.Conditional Random Fields:Probabilistic Models for Segmenting and Labeling Sequence Data[C]//Proc.of the 18th International Conference on Machine Learning.San Francisco,USA:Morgan Kaufmann Publishers Inc.,2011:282-289.
[11]周俊生,戴新宇,尹存燕,等.基于層疊條件隨機場模型的中文機構名自動識別[J],電子學報,2006,34(5):804-809.
[12]Viterbi A J.Error Bounds for Convolutional Codes and an Asymptotically Optimum Decoding Algorithm[J].IEEE Transactions on Information Theory,1967,13(2):260-269.
[13]Wikipedia.Information Retrieval[EB/OL].(2013-07-05).http://en.wikipedia.org/wiki/Information_retrieval.
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年18期)2018-11-14 01:48:06
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
海峽科技與產業(2016年3期)2016-05-17 04:32:12
小學教學參考(2015年20期)2016-01-15 08:44:38
