最小化多MapReduce任務總完工時間的分析模型及其應用*
2014-09-29 08:32:28田文洪王心陽薛瑞尼
計算機工程與科學 2014年4期
田文洪,陳 瑜,王心陽,薛瑞尼,趙 勇
(1.電子科技大學信息與軟件工程學院,四川 成都 610054;2.電子科技大學計算機科學與工程學院,四川 成都 611731)
1 引言
在云計算和大數(shù)據(jù)處理時代,MapReduce的開源實現(xiàn)Hadoop以其通用性和方便實用等特征得到了迄今為止最為廣泛的應用。在云計算研究中,MapReduce環(huán)境的作業(yè)調(diào)度帶來了一個新的課題和挑戰(zhàn),引起了越來越多的重視。最初,Hadoop默認的FIFO(先入先出)調(diào)度器是專為周期性執(zhí)行大規(guī)模批量作業(yè)而設計的。隨著MapReduce集群的用戶數(shù)量的增加,計算能力調(diào)度器[1]和Hadoop公平調(diào)度器HFS(Hadoop Fair Scheduling)[2]的出現(xiàn),提供了更高效的集群共享方式。業(yè)界已有少數(shù)研究Hadoop的調(diào)度原型的研究小組,旨在優(yōu)化一些明確給定的調(diào)度標準,例如FLEX[3]、ARIA[4]。MapReduce的模擬器SimMR[5]也被開發(fā)出用于模擬不同的工作量下MapReduce的性能。但是,正如文獻[6]中指出的,現(xiàn)有的調(diào)度器還不能提供對最小化作業(yè)集完工時間的支持。Tian等[7]針對離線多任務調(diào)度提出了幾種高效的最小化總完工時間的調(diào)度算法并進行了對比分析,文獻[8]針對在線多任務節(jié)能調(diào)度提出了一種高效動態(tài)劃分算法,以最小化總完工時間。Tian等[9]提出了一種云數(shù)據(jù)中心動態(tài)負載均衡調(diào)度算法,該算法同時考慮CPU內(nèi)存和網(wǎng)絡帶寬的利用率。
Herodotou H等[10]提出了一種工作流-感知調(diào)度器,通過把數(shù)據(jù)位置與任務調(diào)度相結(jié)合,優(yōu)化工作流完工時間。Moseley B等[11]將MapReduce調(diào)度轉(zhuǎn)化為經(jīng)典的具有相同機器的兩階段工作車間作業(yè)問題,在離線情況下,他們提出了一個對于最小化總完成時間近似比為12的近似算法。文獻[6,12]提出了一種通過在Hadoop集群中創(chuàng)建兩個資源池(pools)的啟發(fā)式算法—BalancedPools算法,以負載均衡并最小化任務的總完工時間。該算法當任務請求的資源低于系統(tǒng)可提供的最大資源時不進行動態(tài)資源分配調(diào)整,而是運行多個任務共享系統(tǒng)資源,因而不滿足經(jīng)典Johnson算法的條件。經(jīng)典Johnson算法[13]要求一個物品必須通過一個生產(chǎn)階段(或者一個機器),然后通過第二個階段,每個階段只有一個機器,一個機器上任何時刻一次最多處理一個物品,在此種情況下可以利用經(jīng)典Johnson算法安排出一批任務的執(zhí)行順序,并計算出最小總完工時間。
本文總結(jié)已有研究成果的優(yōu)缺點,旨在將MapReduce兩階段與經(jīng)典Johnson算法的兩階段條件完全匹配,從而利用Johnson算法計算出一批任務的最小總完工時間,并應用于集群節(jié)能、負載均衡等問題。
2 問題描述與建模
定義1 MapReduce時隙(MapReduce slots),是指在給定的一個Hadoop集群中,其總的MapReduce資源時隙,本文與文獻[5]一樣,設定一個Hadoop集群節(jié)點同時具有一個MapReduce slot,例如一個Hadoop集群具有60個節(jié)點,可以表示其總的MapReduce slots為60×60。當然這也可以依據(jù)具體情況動態(tài)設定。
定義2 一個作業(yè)在一個給定Hadoop集群中的執(zhí)行次數(shù),用waves來表示,例如一個任務請求使用30個Map slots和30個Reduce slots,在一個具有20×20MapReduce slots的Hadoop集群,其執(zhí)行Map階段的waves為2,其執(zhí)行Reduce階段的waves為2,其它的類推。圖1展示了一個MapReduce wordcount運行的例子。
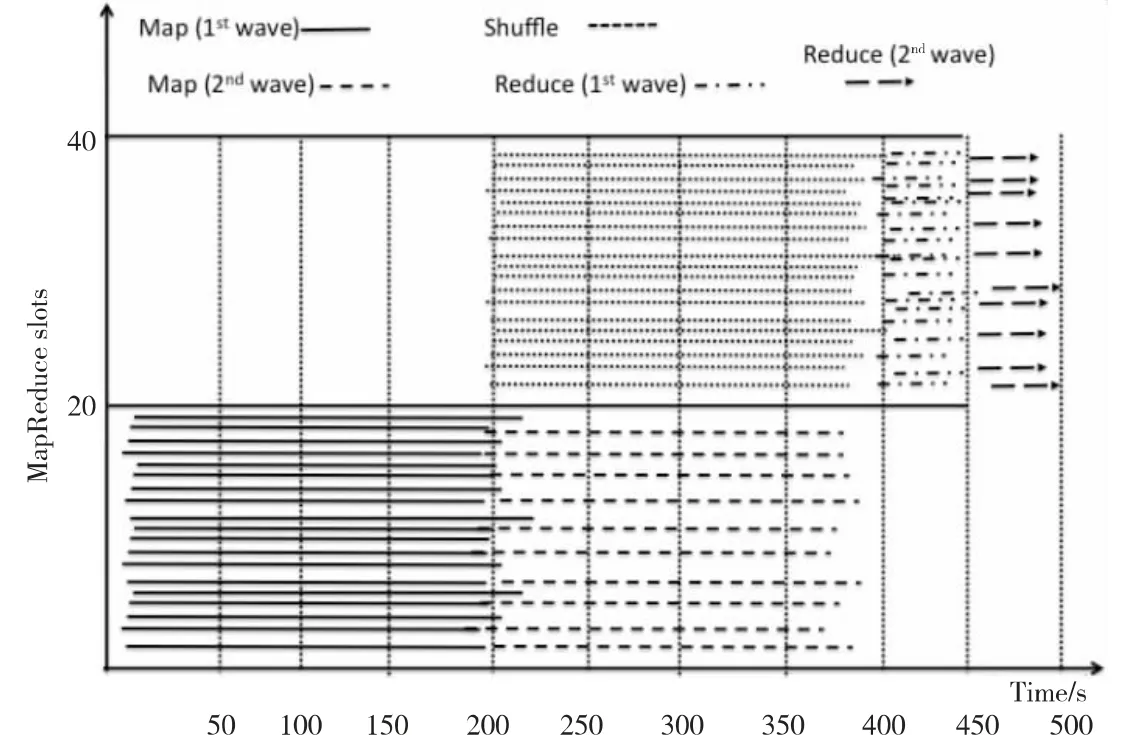
Figure 1 An execution example in 20×20MapReduce slots圖1 一個在20×20MapReduce slots執(zhí)行的例子
定義3 一批任務在Hadoop集群中的總完工時間(Total Makespan),是指按照一定的順序執(zhí)行完該批任務的所有Map/Reduce階段從第一個任務Map階段開始到最后一個任務Reduce結(jié)束所花的總時間。
文獻[4,6,12]介紹了一個Map/Reduce性能模型。該模型可通過輸入數(shù)據(jù)大小和分配資源作為函數(shù)的參數(shù),預測Map和Reduce階段的完工時間。考慮一個由n個任務組成的作業(yè),在k個MapReduce的slots中執(zhí)行的Hadoop環(huán)境,任務安排在slots中執(zhí)行時采用離線貪心算法:每次選擇完工時間最早的任務安排。設avg和max分別為n個任務的平均時間和最大時間,則在貪心算法下,作業(yè)的總完工時間最少為n×avg/k,最多為(n-1)×avg/k+max,每個作業(yè)由特定數(shù)量的Map和Reduce任務組成。該作業(yè)的執(zhí)行時間和具體的執(zhí)行依賴于分配所得的資源量(Map slots和Reduce slots)。我們采用文獻[6]中的一個簡單抽象,將一個MapReduce作業(yè)Ji的Map和Reduce過程定義為mi和ri,即Ji=(mi,ri),對于任何兩個獨立的MapReduce作業(yè)J1和J2,這兩個作業(yè)之間沒有數(shù)據(jù)依賴關系。只有當?shù)谝粋€作業(yè)完成Map階段并開始Reduce階段的處理時,第二個作業(yè)才可以開始使用釋放的資源來執(zhí)行Map,參見圖3。下一個作業(yè)的Map階段可能會與前一個作業(yè)的Reduce階段在時間上“重疊”(Overlapped)。我們進一步考慮以下問題:設J={J1,J2,…,Jn}是一個n個數(shù)據(jù)相互獨立的MapReduce作業(yè)。Ji需要Ni×Nr個MapReduce slots,Map和Reduce的時間分別是(mi,ri),系統(tǒng)調(diào)度器依據(jù)可用資源可以改變一個作業(yè)的MapReduce slots分配。假設T是所有n個作業(yè)的總完工時間,我們的目標是對于Ji∈J確定一個順序,使得所有作業(yè)的總完工時間最小。我們假設一個作業(yè)Ji,其Map結(jié)束時間和Reduce開始時間分別為,實際分配的MapReduce slots為Pi×Pi,而Hadoop集群中最大的MapReduce slots為P×P。因此,最小化總完工時間問題可以表示如下:

其中,不等式(2)由可用資源限定,實際分配的資源(Pi)不能超過系統(tǒng)可用資源(P);不等式(3)由單個作業(yè)Map和Reduce過程不能重疊限定,對于任何一個作業(yè),其Reduce開始時間不應比其Map的完工時間早。
3 最小化總完工時間問題解決方案:更新的經(jīng)典Johnson算法
經(jīng)典Johnson算法[13]描述有n個物品必須通過一個生產(chǎn)階段(或者一個機器),然后通過第二個階段,每個階段只有一個機器,一個機器上任何時刻一次最多處理一個物品。為了讓其能夠用于MapReduce模型,我們將Map和Reduce階段的資源看做一個整體,來表示MapReduce的slots資源。然后我們可以使用Johnson算法,考慮一個n個作業(yè)的集合,每個作業(yè)使用一個用Map和Reduce時間組成的數(shù)據(jù)(mi,ri)表示,每一個作業(yè)Ji=(mi,ri)的屬性Ai定義如下:
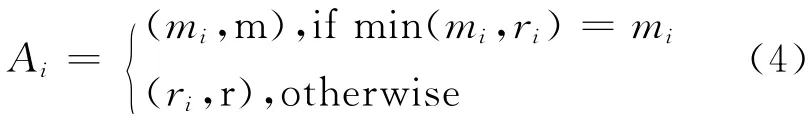
Ai的第一個參數(shù)稱為持續(xù)時間,表示為A1;第二個稱為階段類型(Map或Reduce),表示為A2。注意到如果當所有的ri=0時,Johnson算法簡化為短作業(yè)優(yōu)先算法(SPT),該算法是已知的可用于找到所有作業(yè)最小總完成時間的最優(yōu)值的方法。MapReduce改進的Johnson算法的偽代碼如下所示:
算法1 改進的Johnson算法
輸入 所有作業(yè)的Map和Reduce階段的持續(xù)時間mi、ri,Hadoop集群的機器數(shù)量,系統(tǒng)Map/Reduce slots總數(shù)P。
輸出 所有調(diào)度任務的安排順序和這批任務總的完工時間。
步驟1 將所有任務的Map和Reduce階段的持續(xù)時間列出;
步驟2 對于所有持續(xù)時間;
步驟3 找出其最短者;
步驟4 若出現(xiàn)多個最短者相同的情況,則按任務編號順序處理。
步驟5 若Map階段與Reduce階段持續(xù)時間相同,則優(yōu)先考慮為Map類型;
步驟6 若任務類型為Map型,則置于第一個位置處理;
步驟7 否則任務類型為Reduce型,則置于最后一個位置處理;
步驟8 移除已經(jīng)分配的任務;
步驟9 對剩余的任務重復步驟3~步驟8,直到所有任務分配完。
首先將在作業(yè)J中的n個作業(yè)按照下列方式排 序:Ji在Ji+1之 前 當 且 僅 當min(mi,ri)≤min(mi+1,ri+1)。它尋 找 的 是 持 續(xù) 時 間 最 短 的 作業(yè),如果階段類型Ai是m,它代表Map類型,則Ji被放置在調(diào)度表頭,否則Ji被放置在尾部。然后移除Ji,對剩下的作業(yè)采取同樣操作直到所有作業(yè)分配完。Johnson算法的時間復雜度主要在于排序n個任務,因而是O(nlogn)。
定理1 在兩階段生產(chǎn)系統(tǒng)中,如果所有作業(yè)經(jīng)歷相同階段,且任何時刻任何一個階段的資源只能由一個任務占用,則Johnson算法可以獲得系統(tǒng)總完工時間的最小值。
該定理的詳細證明參考文獻[13]。
使用Johnson算法我們可以通過如下方式計算出系統(tǒng)最小總完工時間。考慮有Map和Reduce階段的n個任務,設在給定的有P個節(jié)點的Hadoop集群中,mi為第i個任務Map階段持續(xù)時間,ri為Reduce階段的持續(xù)時間,則系統(tǒng)的最小總完工時間為:
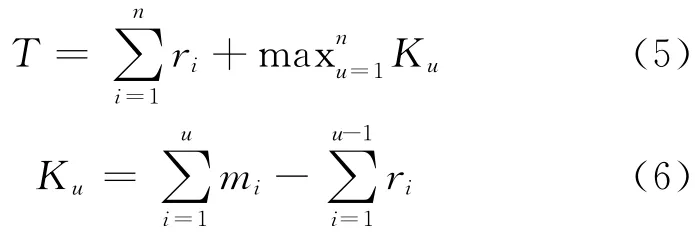
觀察結(jié)果1 如果每個工作能夠完全利用Map或者Reduce過程中的slots,那么MapReduce作業(yè)的處理可與經(jīng)典Johnson算法的兩階段生產(chǎn)系統(tǒng)完全匹配,則Johnson算法就可用來尋找所有MapReduce作業(yè)的最小總完工時間的最優(yōu)解。
例1 在文獻[2]中給定的五個MapReduce作業(yè)例子,我們重新繪制如圖2所示。
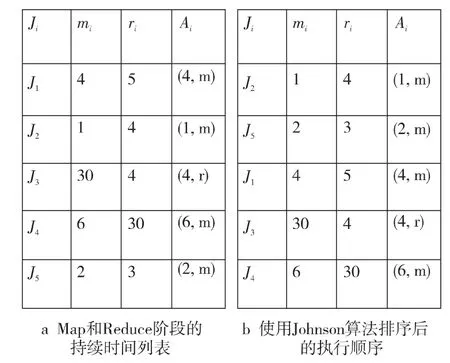
Figure 2 Example of five MapReduce jobs圖2 五個MapReduce作業(yè)例子
圖2a為五個作業(yè)Map和Reduce階段的持續(xù)時間列表,圖2b為五個作業(yè)使用Johnson算法由排序后的執(zhí)行順序。根據(jù)Johnson算法,最優(yōu)順序為δ=(2,5,1,3,4),由式(6)可計算出,此序列的總延遲時間為4個單位時間,總完工時間是47個單位時間(由式(5)計算出)。如果將此序列翻轉(zhuǎn),即(4,3,1,5,2),則得到最壞的結(jié)果(上限),為78個單位時間。
觀察結(jié)果2 假設當作業(yè)要求分配MapReduce的slots比系統(tǒng)可用的MapReduce的slots少,系統(tǒng)調(diào)度器不給MapReduce增加slots;同時,每一個階段若允許兩個或兩個以上的作業(yè)共享slots,例如文獻[6]所介紹的方法則違反了Johnson算法要求任何時刻在機器上只能有一個作業(yè)在執(zhí)行的條件。
圖3和圖4分別給出了一個不滿足和滿足Johnson算法條件的任務執(zhí)行情況。
例2 讓作業(yè)J1、J2和J5請求30個Map和30個Reduce slots任務,作業(yè)J3和J4請求20個Map和20個Reduce slots任務。圖3展示了這五個MapReduce作業(yè)依據(jù)Johnson算法的執(zhí)行順序δ=(J2,J5,J1,J4,J3)的 執(zhí) 行 過 程。當 可 用 的MapReduce的slots的數(shù)量比請求的MapReduce slots的數(shù)量大的時候,如果我們不把作業(yè)分為兩個池,同時不增加slots的數(shù)量為系統(tǒng)最大可用值(如J3和J4需要20×20個slots而系統(tǒng)作為整體有30×30個slots),如圖3所示,使用Johnson算法,調(diào)度總共的完工時間(Makespan)是44個單位,這比通過文獻[6]中兩個池的方法得到的結(jié)果(40)大了10%。注意到,J4用20×20個slots,Map和Reduce階段分別有6和30個單位的持續(xù)時間;J3的Map階段在時間段[7,13]使用10個Map slots與J4共享系統(tǒng)資源,在時間段[13,40]使用20個Map slots繼續(xù)執(zhí)行,然后J3的Reduce階段在時刻40開始,在時刻44結(jié)束。
觀察結(jié)果3 作業(yè)的階段持續(xù)時間取決于分配資源的數(shù)量(Map和Reduce的slots)。若系統(tǒng)調(diào)度分配MapReduce slots的數(shù)量不同,作業(yè)運行的總時間就可能不同。
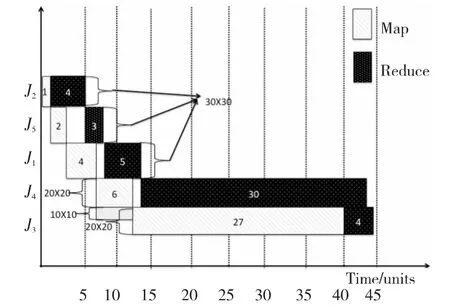
Figure 3 Execution result of five MapReduce jobs(not using max available slots)圖3 五個MapReduce作業(yè)在一個集群中執(zhí)行
例3 考慮在文獻[6]中的情景2:作業(yè)J1、J2和J5申請30個Map和30個Reduce slots,作業(yè)J3和J4申請20個Map和20個Reduce slots,且J3=(m3,r3)=(30,4),J4=(6,30)。我們在圖3中展示了這五個MapReduce作業(yè)根據(jù)生成的Johnson調(diào)度順序δ=(J2,J5,J1,J4,J3)的執(zhí)行過程。對于作業(yè)J3和J4,文獻[6]假設即使系統(tǒng)中有30×30個MapReduce slots可用的情況下,他們只用了20×20個MapReduce slots。然而,如果我們允許作業(yè)可以使用系統(tǒng)中所有可用的MapReduce slots來執(zhí)行(這在Hadoop中很容易實現(xiàn),如將大的輸入文件基于可用的MapReduce slots數(shù)量進行分片),得出的結(jié)果和文獻[1]中得出的很不相同。使用在文獻[1]的情景2中的同樣示例,則現(xiàn)在作業(yè)J3和J4可以使用所有可用的30×30個MapReduce slots,那么J3將有Map和Reduce的持續(xù)時間分別為(20,8/3),J4將有Map和Reduce的持續(xù)時間分別為(4,20),它們都比使用20×20個MapReduce slots用時少,如圖4所示的執(zhí)行結(jié)果。因此,總的Makespan將為其中X1=1。這個結(jié)果比通過兩個池[2]所得結(jié)果要小約12%。
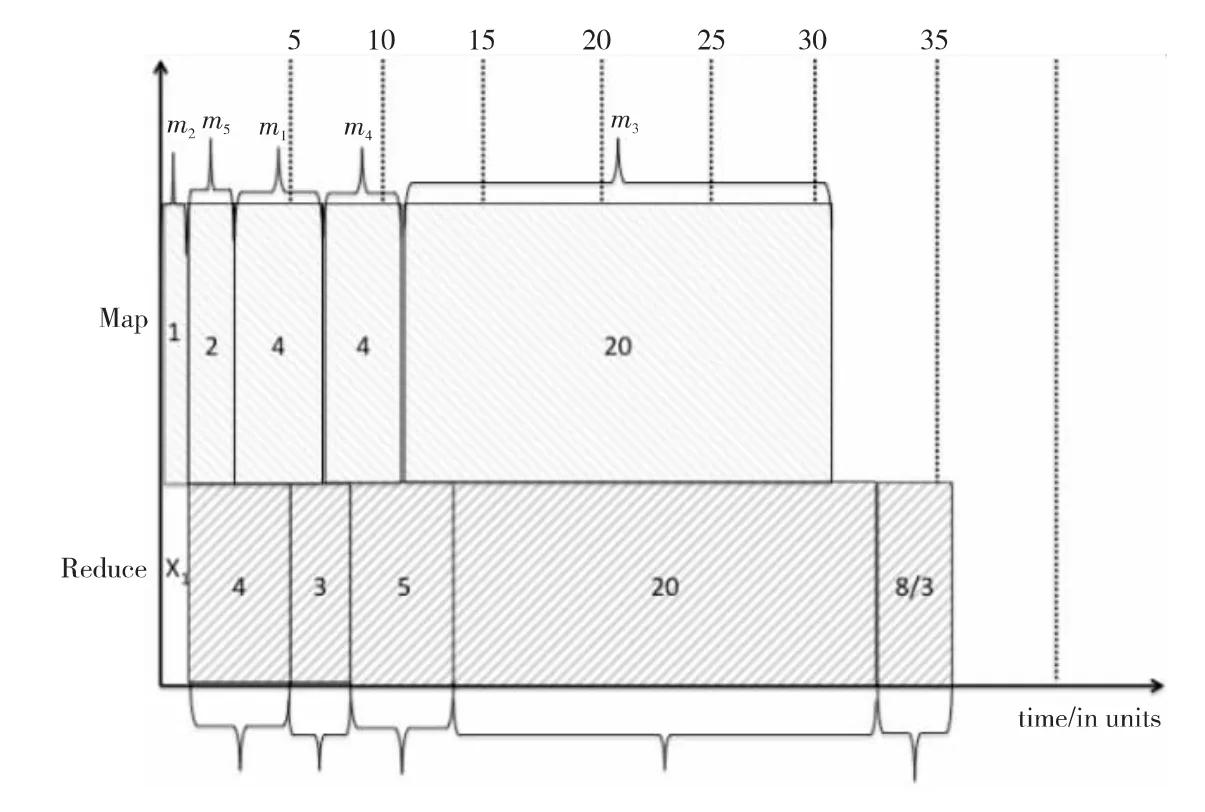
Figure 4 Execution result of five MapReduce jobs(using max available slots)圖4 五個MapReduce作業(yè)在一個集群中執(zhí)行(利用系統(tǒng)最大資源滿足經(jīng)典Johnson算法條件)
引理1 如果作業(yè)請求的MapReduceslots數(shù)量比系統(tǒng)中總的可用MapReduceslot數(shù)量多或少,調(diào)度系統(tǒng)可以減少或者增加分配給作業(yè)的MapReduceslots數(shù)量,以最大限度利用Hadoop資源,從而最小化系統(tǒng)總完工時間。
證明 這一動態(tài)調(diào)整滿足了經(jīng)典Johnson算法兩個階段的執(zhí)行條件,即任何時刻任何一個階段的資源只能由一個任務占用,所以我們可以使用經(jīng)典Johnson算法來安排任務執(zhí)行順序,并使用公式(5)~公式(6)計算出系統(tǒng)最小總完工時間。□
算法2依據(jù)引理1的動態(tài)分配系統(tǒng)MapReduce slots資源方法的偽代碼如下所示:
算法2 動態(tài)MapReduce slots分配方法
輸入 所有作業(yè)的Map和Reduce階段的持續(xù)時間mi,ri,Hadoop集群的機器數(shù)量,系統(tǒng)MapReduce slots總數(shù)P。
輸出 所有作業(yè)實際分配的MapReduce slots。
步驟1 將所有任務的Map和Reduce階段的持續(xù)時間列出;
步驟2 對于所有作業(yè)請求的MapReduce slots;
步驟3 若作業(yè)請求的slots與系統(tǒng)可分配的最大slots相同,則分配給其最大slots;
步驟4 若作業(yè)請求的slots大于系統(tǒng)可分配的最大slots,則按照系統(tǒng)可分配的最大slots分配(將大的輸入文件基于可用的MapReduce slots數(shù)量進行分片后執(zhí)行多個waves),并重新計算其各階段的持續(xù)時間;
步驟5 若作業(yè)請求的slots小于系統(tǒng)可分配的最大slots,則按照系統(tǒng)可分配的最大slots分配(將大的輸入文件基于可用的MapReduce slots數(shù)量進行分片),并重新計算其各階段的持續(xù)時間;
步驟6 將新的結(jié)果提交調(diào)度系統(tǒng)使用。
4 最小化多MapReduce任務總完工時間應用于Hadoop集群節(jié)能
利用前述結(jié)果,可以在調(diào)度系統(tǒng)設計時優(yōu)化多任務的總完工時間,從而提高響應速度和服務質(zhì)量。利用前述結(jié)果和能耗模型,我們還可以建立集群總能耗與多任務總完工時間的關系,從而進行能耗優(yōu)化設計。考慮CPU為主的能耗模型,一個節(jié)點一段時間內(nèi)的能耗可以表示如下[14,15]:

本文考慮Hadoop集群節(jié)點同構(gòu)的情況,其中Pi為Hadoop集群節(jié)點i(一個服務器)的功率,Pmin是節(jié)點的利用率為0時的功率,Pmax是節(jié)點利用率為100%時的功率,Ui為節(jié)點CPU的平均利用率。
節(jié)點i在一段時間[t0,t1]內(nèi)的總能耗Ei可表示為:
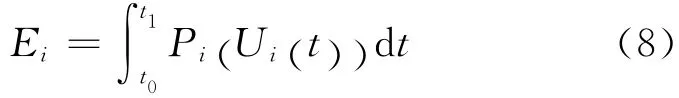
其中,Pi(Ui(t))為功率函數(shù);而Ui(t)為CPU在時刻t的利用率,若使用一段時間Ti(=t1-t0)內(nèi)的平均利用率,則公式(8)可以簡化為:
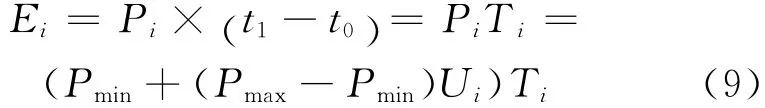
則一段時間內(nèi)的Hadoop集群的總能耗可表示為:
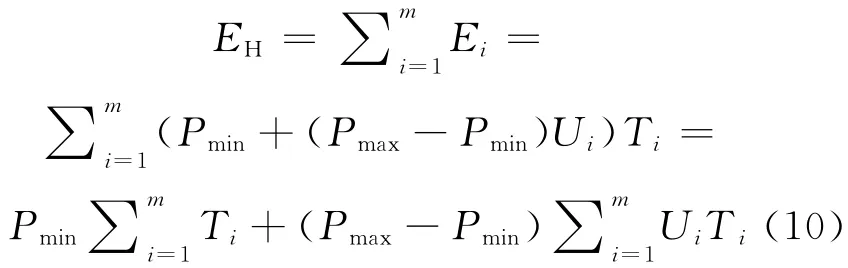
其中,m為Hadoop集群中的節(jié)點數(shù)。
定理2 對于給定的一組作業(yè),Hadoop集群的總能耗是由其運行總時間(總完工時間)決定的。
證明 設置α=Pmin,β=Pmax-Pmin,T=∑Ti,L是Hadoop集群的總負載,由公式(10)我們可以得到:
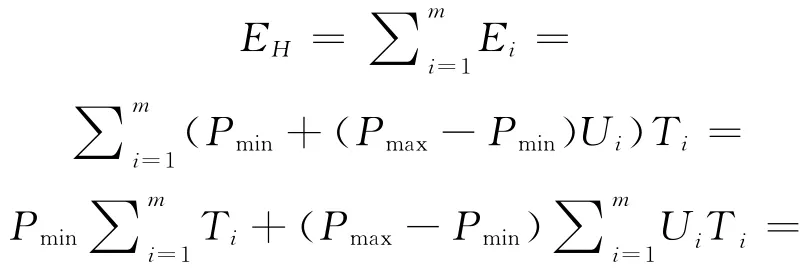

對于給定的一組任務,集群的總工作負載L是固定的,α和β都是常數(shù),那么集群的總能耗是由其總完工時間(總運行時間)確定的。 □
定理2告訴我們,在設計多MapReduce任務時,為了降低能耗,應盡可能降低所有任務的總完工時間,這正是本文提出分析模型的一個應用出發(fā)點。
5 資源池負載均衡問題的優(yōu)化解決方案
在文獻[6,12]中,作者提出了一個叫做BalancedPools的啟發(fā)算法。這個算法迭代地將任務分配到兩個池中,然后嘗試對每一個池進行適當?shù)馁Y源分配,以保證這些池的Makespan是均衡的。在每一個池中應用Johnson算法進行作業(yè)調(diào)度,此時Map和Reduce階段的持續(xù)時間被估算出來。一個池中的Makespan是通過模擬器SimMR[5]進行預估的,BalancedPools算法的時間復雜度為Ο(n2lognlogm),其中,n是任務總數(shù),m是在Hadoop中的節(jié)點數(shù)[6,12]。文獻[6]指出了在系統(tǒng)可分配slots資源大于作業(yè)請求的slots資源進行作業(yè)共享資源時,該問題是NP-h(huán)ard問題(關于NPhard問題參考文獻[16])。
定理3 使用引理1,對于兩個池中的MapReduce作業(yè)集,平衡系統(tǒng)的MapReduce slots以實現(xiàn)兩個池的Makespan平衡的問題不是NPhard,而是可在線性時間內(nèi)解決的。
證明 這是因為按照引理1,分配MapReduce slots可以基于系統(tǒng)中可用的MapReduce slots進行動態(tài)調(diào)整。假設在給定的Hadoop集群中有P×P個MapReduce slots,所有請求(作業(yè))可以根據(jù)池A和池B進行分組,每一個請求MapReduce slots(RA,RB),持續(xù)時間為(TA,TB)。注意到TA和TB可以通過Johnson算法很輕易地計算出來。假設整個Hadoop集群分為P1和P2slots兩個池,以達到負載均衡。在理想負載均衡條件下,對于池A和池B中平衡后的Makespan(完工時間),我們可建立以下關系:
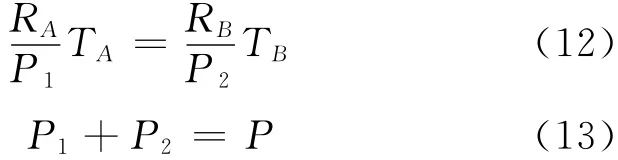
結(jié)合式(12)和式(13),我們可以解出P1和P2:

其中round()是就近取整函數(shù),根據(jù)定義round(X)可以取得離X最近的整數(shù)。這是兩組作業(yè)分配給兩個池的最優(yōu)化結(jié)果。注意到分配資源的數(shù)量(P1,P2)是基于負載均衡的,所以結(jié)果可能與它們請求的MapReduce slots數(shù)量不同。□
例4 假設有兩組請求,使用與例2相同的示例,我們知道R1=30,R2=20,P=30。對于每一個池(組),我們通過使用公式(5)計算出其總的完工時間,分別為T1=14,T2=40。通過式(12)和式(13),可以得到P1=10,P2=20,池1和池2的Makespan分別是39和40個單位時間。這與文獻[2]中得到的結(jié)果相一致。我們在下面提供另外一個示例。
例5 我們在兩個池中隨機生成4個任務,
A:J1=(mi,ri)=(3 ,5),J2=(7 ,11),R1=R2=10×10個MapReduce slots;
B:J3=(13 ,17),J4=(23 ,29),R3=R4=20×20個MapReduce slots;P=30。通過對每個池使用Johnson算法,我們可以計算出T1=21和T2=65。通過式(12)和式(13),我們可以得到P1=4,P2=26,池A和池B的Makespan在平衡過后分別為53和50個單位時間。如果我們應用引理1,對所有的作業(yè)增加MapReduce slot到30×30個slots(這也是所有可用的slots的總數(shù))。這樣它們的Map和Reduce持續(xù)時間將為J′1=(1,5/3),J′2=(7/3,11/3),J′3=(26/3,34/3),J′4=(46/3,58/3)。現(xiàn)在我們再應用Johnson算法,將得到所有的Makespan為,這個結(jié)果比用兩個池所得出的結(jié)果(53)小。
例6 讓我們使用文獻[6]中的示例。考慮兩個相同的作業(yè)J1和J2,J1=J2=(10,10),他們在Hadoop集群中請求30×30個Map和Reduce slots。假設兩個作業(yè)都可使用集群上最大可用的30×30個Map和Reduce slots。
(1)使用兩個池:通過對池1和池2進行負載均衡,應用式(12)和式(13),我們可以得到T1=T2=10,P1=P2=15;每一個池的Makespan是40個單位時間,這和文獻[6]中使用HFS調(diào)度器得到的結(jié)果相一致。
(2)在單個集群上使用引理1和Johnson算法,J1先執(zhí)行,J2緊接其后,我們可以輕松計算出總Makespan為30個單位時間。這和文獻[2]中應用FIFO調(diào)度器得出的結(jié)果相一致。這個例子再一次說明,通過Johnson算法和引理1得出的總的Makespan比文獻[6]中使用兩個池方法得出的結(jié)果小。通過大量的例子和研究,我們得出下面的觀察結(jié)果。
觀察結(jié)果4 使用資源池可以使兩組池的完工時間更加平衡,但未必會讓所有作業(yè)的總完工時間最少,使用引理1和Johnson算法在單個Hadoop集群中總能保證總完工時間最小。
引理1、定理1、定理2、定理3和觀察結(jié)果4告訴我們:
(1)在滿足Johnson算法的條件下,我們?nèi)匀豢梢詫蜨adoop集群使用Johnson算法來獲取總完工時間的最小值;
(2)針對兩個池完工時間的平衡,可以在線性時間內(nèi)解決,遠低于文獻[6]中模擬方法的復雜度(其計算復雜度為O(n2lognlogm),其中n為任務數(shù),m為Hadoop集群節(jié)點數(shù))。
6 結(jié)束語
本文通過分析經(jīng)典Johnson算法與MapReduce模型兩個階段的特征,改進MapReduce調(diào)度系統(tǒng)設計使其與經(jīng)典Johnson應用條件相互匹配,因Hadoop為開源軟件,這使得引理1容易實現(xiàn),從而使用該算法來準確求解一批任務的最小總完工時間。為此,我們提出一個更好的調(diào)度策略,依據(jù)系統(tǒng)總的可用資源動態(tài)調(diào)整分配給不同任務的資源,以便最大化利用系統(tǒng)資源和滿足用戶請求。該模型可以非常方便地應用于提高系統(tǒng)總的響應效率、降低總體能耗、實現(xiàn)多個資源池的負載均衡等領域。
針對提出的模型,我們正在進行一些拓展研究:
(1)在真實Hadoop集群環(huán)境下,使用真實或模擬產(chǎn)生的數(shù)據(jù)進行大量分析測試,以修正理論模型與實踐經(jīng)驗之間可能存在的差異;
(2)分析不同種類MapReduce任務的特征,對Hadoop集群多任務調(diào)度進行更好的管理,提高服務質(zhì)量并兼顧節(jié)能以及負載均衡等策略;
(3)本文主要考慮Hadoop集群節(jié)點同構(gòu)的情況,當集群節(jié)點不同構(gòu)時,如何修正完善分析模型是另一個拓展方向。
[1] http://hadoop.apache.org/common/docs/ro.20.1/capacityscheduler.htm.
[2] Zaharia M,Borthakur D,Sarma J S,et al.Delay scheduling:A simple technique for achieving locality and fairness in cluster scheduling[C]∥Proc of EuroSys,2010:265-278.
[3] Wolf J,Rajan D,Hildrum K,et al.FLEX:A slot allocation scheduling optimizer for MapReduce workloads[C]∥Proc of ACM/IFIP/USENIX International Middleware Conference,2010:1-20.
[4] Verma A,Cherkasova L,Campbell R H.ARIA:Automatic resource inference and allocation for MapReduce environments[C]∥Proc of ICAC’11,2011:235-244.
[5] Verma A,Cherkasova L,Campbell R H.Play it again,Sim-MR![C]∥Proc of Intl.IEEE Cluster’11,2011:253-261.
[6] Verma A,Cherkasova L,Campbell R H.Orchestrating an ensemble of MapReduce jobs for minimizing their makespan[J].IEEE Transactions on Dependable and Secure Computing,2013,10(5):314-327.
[7] Tian Wen-h(huán)ong,Yeo C S,Xue Rui-ni,et al.Power-aware scheduling of real-time virtual machines in cloud data centers considering fixed processing intervals[C]∥Proc of IEEE CCIS’12,2012:337-341.
[8] Tian Wen-h(huán)ong,Xue Rui-ni,Xiong Qing,et al.An energyefficient online parallel scheduling algorithm for cloud data centers[C]∥Proc of IEEE Services 2013,2013:1.
[9] Tian Wen-h(huán)ong,Zhao Yong,Zhong Yuan-liang,et al.Dynamic and integrated load-balancing scheduling algorithms for cloud data centers[J].Journal of China Communications,2011,8(6):117-126.
[10] Herodotou H,Babu S.Profiling,what-if analysis,and cost based optimization of MapReduce programs[J].Proc of the VLDB Endowment,2011,4(11):1111-1122.
[11] Moseley B,Dasgupta A,Kumar R,et al.On scheduling in Map-Reduce and flow-shops[C]∥Proc of SPAA’11,2011:289-298.
[12] Verma A,Cherkasova L,Campbell R H.Two sides of a coin:Optimizing the schedule of MapReduce jobs to minimize their makespan and improve cluster performance[C]∥Proc of MASCOTS’12,2012:11-18.
[13] Johnson S.Optimal two-and three-stage production schedules with setup times included[J].Naval Research Logistics Quarterly,1954,1(1):61-68.
[14] Beloglazov A,Abawajy J,Buyya R.Energy-aware resource allocation heuristics for efficient management of data centers for cloud computing[J].Future Generation Computer Systems,2012,28(5):755-768.
[15] Chen Y,Keys L,Katz R H.Towards energy efficient MapReduce[R]∥Technical Report No.UCB/EECS-2009-109,Berkeley:University of California,2009.
[16] Garey M,Johnson D.Computers and intractability:A guide to the theory of NP-completeness[M].USA:WH Freeman&Co,1979.
猜你喜歡
工業(yè)設計(2022年8期)2022-09-09 07:43:20
新作文·小學低年級版(2021年9期)2021-11-27 07:57:46
軍民兩用技術與產(chǎn)品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
學生天地(2020年17期)2020-08-25 09:28:54
少年博覽·初中版(2020年6期)2020-06-12 11:42:23
裝備制造技術(2019年12期)2019-12-25 03:06:46
中國洗滌用品工業(yè)(2019年4期)2019-05-11 09:27:34
家庭影院技術(2017年9期)2017-09-26 03:41:45
故事大王(2016年7期)2016-09-22 17:30:08
