傳統蒙古文與西里爾蒙古文相互轉換方法的研究
2014-08-03 15:23:46高光來閆學亮魏宏喜
計算機工程與應用 2014年23期
飛 龍,高光來,閆學亮,魏宏喜
內蒙古大學 計算機學院,呼和浩特 010021
傳統蒙古文與西里爾蒙古文相互轉換方法的研究
飛 龍,高光來,閆學亮,魏宏喜
內蒙古大學 計算機學院,呼和浩特 010021
1 引言
蒙古文是一個跨多國、多地區的語言,在世界上有廣泛影響,使用者分布在中國、蒙古國和俄羅斯聯邦等國家,尤其是中國和蒙古國使用的蒙古語言文字是“語同文不同”,即語言相同,文字不同。在中國使用的蒙古文叫“傳統蒙古文”,在蒙古國使用的蒙古文叫“西里爾蒙古文”(也叫新蒙古文,基立爾蒙古文,斯拉夫蒙古文等)。
隨著中國和蒙古國兩國之間的文化、教育和經濟的交流與合作不斷深入,兩國之間的文字轉換工作也變得極其重要。傳統蒙古文和西里爾蒙古文的相互轉換工作會給兩國蒙古族同胞的交流帶來更多的便利,并且對蒙古族的科學,文化和教育發展同樣具有重要的意義。
包薩日娜、烏日力嘎和Hao Li[1-6]等人采用基于詞典的方法和基于規則的方法對傳統蒙古文和西里爾蒙古文的相互轉換進行了一系列的研究,并取得了一定的成果。但是,蒙古文是通過詞根綴接多個后綴的方式生成新詞的,按照這種生成方式,可以構成近100萬的蒙古文單詞,詞典一般很難全部包含。而且,基于規則的方法很難歸納出所有的轉換規則,并且相當一部分單詞并不遵循轉換規則。所以,基于詞典和基于規則的方法有較大的局限性,很難達到實用要求。
本文提出了基于聯合序列模型[7-8]的傳統蒙古文和西里爾蒙古文的相互轉換方法,并優化了相關參數。實驗中,基于聯合序列模型的轉換方法對傳統蒙古文到西里爾蒙古文的轉換(Traditional Mongolian To Cyril Mongolian Conversion,T2C)和西里爾蒙古文到傳統蒙古文的轉換(Cyril Mongolian To Traditional Mongolian Conversion,C2T)都得到了較好的實驗效果。
2 傳統蒙古文和西里爾蒙古文的比較
西里爾蒙古文是從傳統蒙古文演變而成的,語法和詞匯基本相同。傳統蒙古文和西里爾蒙古文的字母對照如表1所示。傳統蒙古文和西里爾蒙古文之間有不可分割的聯系,但二者之間有一定的區別:
(1)傳統蒙古文有35個字母,其中包含8個元音字母和27個輔音字母[9]。西里爾蒙古文也有35個字母,其中包含13個元音字母,20個輔音字母,硬化字母和軟化字母各一個[10]。
(2)西里爾蒙古文字母區分大小寫,而傳統蒙古文字母不區分大小寫。西里爾蒙古文字母的大寫用法跟英語相似。傳統蒙古文字母不區分大小寫,并且每個字母在詞中變化有很多,在單詞中,字母在上、中、下位置不同將導致寫法也不相同[11]。
(3)西里爾蒙古文和傳統蒙古文書寫方向不同。西里爾蒙古文采用的是從左到右的書序,從上到下的行序,而傳統蒙古文采用從上到下的書序,從左到右的行序[12]。
(4)書面語和口語的差別程度在西里爾蒙古文與傳統蒙古文中并不相同。西里爾蒙古文中的書面語和口語基本保持一致,口語中怎么發音就基本上怎么拼寫,而傳統蒙古文的書面語與口語不是一一對應的,書面語轉口語時會出現元音和輔音的脫落、增加和變換等現象[13]。

表1 西里爾蒙古文和傳統蒙古文字母對照
傳統蒙古文和西里爾蒙古文相互轉換時單詞之間基本上是一一對應的,但是由于上述傳統蒙古文和西里爾蒙古文的區別,從而它們的字母不是一一對應,有一對多或多對一的現象。這些問題給傳統蒙古文和西里爾蒙古文的相互轉換工作帶來了一定的困難。
3 基于聯合序列模型的轉換方法
3.1 聯合序列模型
傳統蒙古文單詞和西里爾蒙古文單詞都是由字母串組成的,假設G為傳統蒙古文字母串的集合,西里爾蒙古文字母串集合為Φ。T2C轉換問題可表述為:

公式(1)表示對于傳統蒙古文單詞g∈G*尋找最有可能對應的西里爾蒙古文單詞?∈Φ*。*表示所有字符串的集合。與此相似,C2T轉換問題也可以表示成公式(1)的形式。本文以T2C轉換為例描述了基于聯合序列模型的轉換方法,而C2T轉換方法跟T2C轉換方法完全相同。
聯合序列模型的基本思想是輸入和輸出序列共同可以生成包含輸入和輸出符號的聯合單位的共同序列。簡單情況下,每個單位帶有零或一個輸入符號和零或一個輸出符號。這相當于有限狀態轉換器(FST)的傳統定義。這種可以由多個輸入和輸出符號組成的單位稱之為共同序列(Co-sequence)或聯合多元(Joint Multigram)[14]。本文把傳統蒙古文和西里爾蒙古文字母的聯合多元(Traditional-Cyril Mongolian joint multigram)簡稱為tracyone。
tracyone是一對不等長的傳統蒙古文字母和西里爾蒙古文字母序列的組合={g,φ}∈Q?G*×Φ*。使用gq和φq分別表示的第一和第二部分。如果tracyone最多包含一個傳統蒙古文字母和一個西里爾蒙古文字母,則稱之為單數tracyone。Q的列表可以從訓練數據中獲得,也可以通過手工指定。
傳統蒙古文字母和西里爾蒙古文字母序列被分成相等的段數,這樣的分組稱為聯合分割。對齊項是可以交換使用的。把這特殊的對齊類型稱為“m-to-n”。對于一個給定的輸入和輸出字符串對,分割tracyone的結果不是唯一的。對于可能有歧義的m-to-n對齊,可以對輸入的字母串進行自由的組合。例如,把傳統蒙古文單詞“轉寫:ebdegde,對應的西里爾蒙古文:эвдэгд)分割成3個或7個tracyone同樣是有效的,如圖1和圖2所示。

圖1 生成3個tracyone序列的結果圖

圖2 生成7個tracyone序列的結果圖
這種模糊的聯合概率是由所有相匹配的tracyone序列的總和來決定的:

其中,q∈Q*是tracyones的一個序列,S(g,φ)是 g和φ的所有聯合分割的集合:

這里∧表示序列的串聯,K=|q|表示tracyone序列q的長度。聯合概率分布 p(g,φ)成為了tracyone序列q= q1q2…qK上的概率分布 p(q),它可以用標準的M-gram模型近似表示:
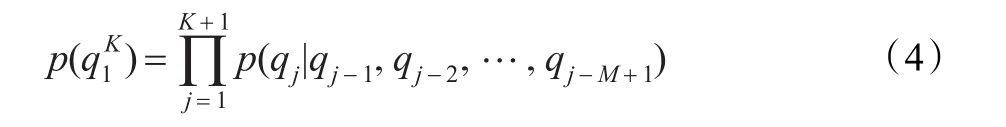
位置 j<1和 j>K是被視為特殊的邊界符號qj=⊥,它允許作為蒙古文單詞的開始和結束位置的特征現象來建模。下面介紹了對于這種模型的估計方法。
3.2 模型估計
3.2.1 Multigram的最大期望值
下面考慮在不是聯合分割的訓練數據中對可變長度單元的模型的推理問題。給定N個傳統蒙古文單詞和對應的西里爾蒙古文單詞的訓練樣本O1,O2,…,ON=(g1,φ1),(g2,φ2),…,(gN,φN),但是傳統蒙古文和對應的西里爾蒙古文字母沒有水平對齊。首先,由于一個聯合分割S定義唯一的聯合序列,發現如果有一個聯合序列模型,就可以計算每個訓練樣本的任何聯合分割概率:

因此,訓練數據的對數似然值可以用所有分割的總和來表示:

在聯合單位中分割S是一個隱藏的變量。最大似然率訓練可以采用期望最大化算法(EM)。首先考慮上下文獨立的unigram(M=1)情況,更新參數θ′的重估公式如下:

其中,n(q)是在序列q中tracyone出現的次數。把e(;θ)稱其為 q 的證據(evidence),它表示在當前的參數θ下訓練樣本中出現的期望值。e(;θ)可以通過前向后向過程計算得到。
對于高階模型(M>1),用h來表示在前邊的聯合單元序列 hj=(qj-M+1,qj-M+2,…,qj-1)。用 nq,h(q)來表示在序列 q 中 M-gram qj-M+1,qj-M+2,…,qj-1出現的次數。重估公式如下:
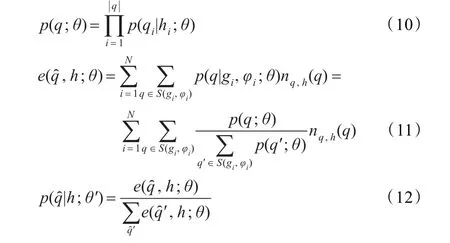
此外,默認序列q中已經包含了開始和結束邊界標志。
顯然,上述公式不允許新的tracyone出現的概率為零。所以通過人工設置比較滿意的長度約束,并均勻分布到所有tracyones來初始化模型參數。通常只使用一個簡單的上限 L,即 |gq|≤L 和 |φq|≤L,但排除了不會生成的情況|gq|=|φq|=0。所以,更復雜的約束是可想而知的,例如傳統蒙古文字母和西里爾蒙古文字母序列長度的不同范圍,或下限設置。一個被公認的初始分布是tracyones總數的倒數:

其中,l=r=0表示附加的序列結束標志。
tracyone的長度約束參數L對tracyone的數目有明顯的影響。序列模型的其他外部參數是最大極限的歷史長度M。M和L一起規定了模型的有效范圍,即在給定的位置字母或音素的數目影響估計的概率值。
一般情況下,用最大似然估計法訓練模型時,很可能會出現過擬合現象,并且在預測未出現的數據時效果不佳。同樣,從訓練樣本中分析得到的一些單調初始化的tracyone會達到某個概率聚集,而只有其中的小部分將有助于“正確”的模型估計。這兩個問題分別會通過下面討論的平滑和裁剪進行處理。
3.2.2 證據裁剪
證據裁剪可以解決過擬合問題。也就是說,修剪低于閾值的證據值,取代在方程(12)中的 p(|h;θ):

此過程不可能在迭代過程中使tracyones逐漸消失。證據裁剪同時有效地控制了tracyone列表的大小。在訓練數據上,閾值τ需要進一步調整。
3.2.3 減值證據
比較估計公式(12)和典型的N-gram語言模型,注意到,除了用證據值替代傳統的N-gram計數值,面臨著本質上是相同的建模問題。眾所周知,有效的平滑技術對建立好的語言模型是至關重要的。實證研究表明,用插值和邊緣保留回退分布作絕對減值,也被稱為Kneser-Ney平滑,比所有其他已知的平滑方法的效果都要好。不同于傳統語言模型的計數值,證據值是一個小數。所以采用從傳統的語言模型獲取的結果時必須謹慎,因為它們的推導可能依賴于整數計數的假設。絕對減值和插值估計方程如公式(15)所示:

為清楚起見,添加了一個下標M表示分布的階數。dM≥0 是減值參數。pM-1(|)是廣義的,低階(M-1)-gram 的分布使取決于減少的歷史i=(i-M+2,i-M+3,…,i-1)。λ(h)為歸一化參數,它使得所有的分布總和到1。
在語言模型中的最小計數值為1(除了未見過的事件),然而證據值可以變得任意小,實際上小于減值。所以減值的證據估計包含證據裁剪的一種形式:用低于減值參數的證據值的tracyones拒絕進入模型。證據裁剪這種形式和明確的形式(14)之間的一個顯著區別是在減值里對未見過的事件分配了減值證據,而在其余的證據有效地分配到了所有可見的事件。
仍然需要指定回退分布 pM-1。對減少歷史hˉ想利用一致性約束:

當然,公式(17)中的 pM-1()也需要平滑處理。平滑 pM-1的兩個方法看上去比較合理。第一是在公式(15)中“插入”減少的證據值(18),第二是平滑約束條件。
事實證明,除了對減值參數不同的解釋,這兩種方法會得到相同的結果。絕對減值遞歸地應用于低階分布 pM-2,pM-3,…,p0。零元分布 p0跟所有潛在的tracyone(13)相同。由于小數的證據值不適合它自己的運算,所以在持有集(the hold-out set)上優化減值參數d。
3.2.4 自底向上的模型建立和減值期望最大化
迭代過程中,用單調的概率分布初始化unigram模型(11),即所有可能的multigrams有相同的初始概率。在訓練集上,用不受約束的計數c(q)選擇性的初始化,即在每個詞中不管相鄰的tracyones的重復,計tracyone的出現次數。
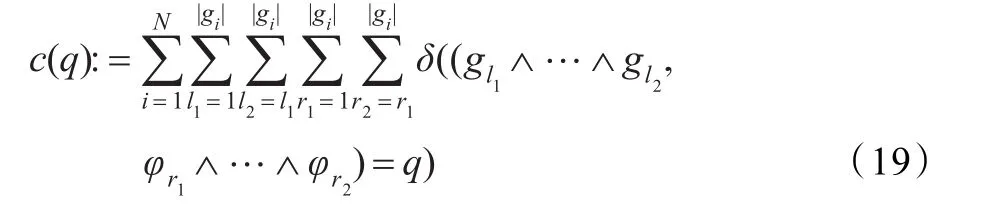
通過應用平滑方法,這些計數(受tracyone長度約束的限制)被用于計算初始的概率分布。高階的M-gram模型使用以前生成的(M-1)-gram模型進行初始化。這意味著,在低階模型中只允許與不減值的M-gram相符合的歷史。
現在要解決的是證據減值怎么樣與EM算法相互進行交互的問題。首先,優化減值需要數據集,這數據集獨立于計算證據值時的數據集。不分離這些數據集會導致減值的總值會低估。為此,從訓練數據中分離訓練集Ot和典型的較小的持有集Oh。訓練集用于計算證據值,而持有集用于調整減值參數。
在每個迭代中原始的EM算法確實提高了樣本出現的可能性,但這通常會導致過度擬合和在某個點上持有集的可能性將開始減小。因此,在減值EM算法中為了確保持有集的可能性不降低,會更新減值。
3.3 解碼
估計模型之后,公式(1)可以用于T2C轉換。從傳統蒙古文到西里爾蒙古文轉換時,通常用極大值來近似公式(2)中的總和。

具體來說,對給定的傳統蒙古文字母串尋找最有可能對應的tracyone序列,并轉換成對應的西里爾蒙古文字母串。

4 實驗
實驗采用的性能評價標準為詞誤識率(Word Error Rate,WER)和字母誤識率(Letter Error Rate,LER)。

其中,Ncorrect為轉換正確的單詞數目,Ntotal為所有需要轉換的單詞數,Nphtotal為所有需要轉換的單詞對應的字母個數總合,Nins為轉換時出現的插入錯誤個數,Ndel為轉換時所有出現的刪除錯誤總合,Nsub為轉換時所有出現的替換錯誤總合。
4.1 實驗1:基于聯合序列模型的轉換實驗
本文以從《新蒙漢詞典》[15]中搜集的65 232個傳統蒙古文和對應的西里爾蒙古文單詞作為數據集。在做基于聯合序列模型的T2C和C2T轉換實驗時,選用60 000個詞對作為訓練集,以5 232個詞對作為測試集。
訓練T2C和C2T轉換的聯合序列模型時,持有集的大小為訓練集的5%,平滑算法采用Kneser-Ney平滑算法。由于在聯合序列模型中tracyone的長度上限L和M-gram的階數M的大小會直接影響模型的復雜度和實驗的結果。因此,在做T2C和C2T轉換實驗時,本文通過一系列對比實驗獲得了最優參數。
圖3和圖4所示的是在不同的tracyone長度上限L和M-gram的階數M的情況下,T2C和C2T轉換的字母誤識率結果圖。從圖3和圖4中可以看出當M=1時,L=4的T2C和C2T轉換效果最好,L=1的效果最差,但是當M大于4時,L=1的T2C和C2T轉換結果都明顯要好于其他情況,并且隨著M的增加會越發明顯。
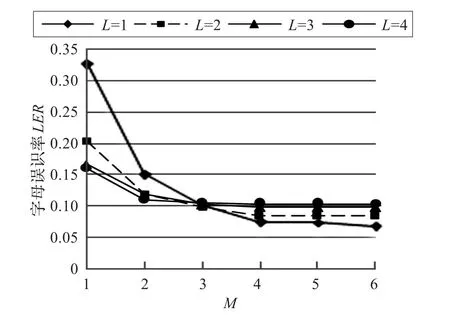
圖3 在測試集上L和M不同值時T2C轉換結果比較圖

圖4 在測試集上L和M不同值時C2T轉換結果比較圖
當L=1時,在測試集和訓練集上對M做了進一步的T2C和C2T實驗,實驗結果如表2和表3所示。從表2和表3中可以看出M=8時T2C和C2T結果都為最優。當T2C轉換時,測試集上的詞誤識率達到了18.38%,字母誤識率達到了6.75%,訓練集上的詞誤識率達到了3.24%,字母誤識率達到了0.64%。當C2T轉換時,測試集上的詞誤識率達到了18.77%,字母誤識率達到了7.14%,訓練集上的詞誤識率達到了3.24%,字母誤識率達到了0.94%。實驗中,T2C和C2T轉換都得到了較好的實驗效果。

表2 在L=1時不同M值的T2C轉換結果

表3 在L=1時不同M值的C2T轉換結果
4.2 實驗2:基于規則的C2T轉換方法和基于聯合序列模型的C2T轉換方法比較
本文對基于規則的C2T轉換方法和基于聯合序列模型的C2T轉換方法進行了比較。基于規則的方法采用了蒙古文詞干綴接構形后綴的轉換方法[1,3]。本文采用的基于規則的轉換方法中西里爾蒙古文和傳統蒙古文的對應詞干庫包含52 830個蒙古文詞干,西里爾蒙古文和傳統蒙古文的對應靜詞后綴庫包含336個構形后綴,西里爾蒙古文和傳統蒙古文的對應動詞后綴庫包含498個構形后綴。本文結合傳統蒙古文和西里爾蒙古文的構詞規則,并利用詞干庫和后綴庫建立了基于規則的轉換系統。實驗中,基于聯合序列模型的C2T轉換方法采用了 L=1,M=8時的聯合序列模型進行了C2T轉換。本文對包含11 365個西里爾蒙古文單詞的文檔集(TestSet1)和包含9 932個西里爾蒙古文單詞的文檔集(TestSet2)進行了C2T轉換實驗,實驗結果如圖5所示。
從圖5可以看出基于聯合序列模型的C2T轉換結果明顯好于基于規則的C2T轉換結果。并且,通過對實驗結果進行分析,發現基于規則的C2T轉換方法存在對于詞干不包含在詞干庫中的西里爾蒙古文單詞無法進行轉換,而且部分蒙古文單詞不遵守轉換規則等問題。然而,基于聯合序列模型的轉換方法較好地解決了這些問題。

圖5 基于規則和基于聯合序列模型的C2T轉換結果比較
5 結束語
本文首先對傳統蒙古文和西里爾蒙古文進行了比較,然后根據它們的特點提出了基于聯合序列模型的傳統蒙古文和西里爾蒙古文的相互轉換方法,并建立了對應的相互轉換系統。為了獲得聯合序列模型相關參數的最優值,做了一系列實驗。實驗結果表明,持有集為訓練數據的5%,tracyone的長度上限 L=1,M-gram的階數M=8時,T2C和C2T轉換的誤識率都為最低。本文提出的基于聯合序列模型的相互轉換方法很好地解決了傳統蒙古文和西里爾蒙古文的相互轉換問題,并且基本達到了實用要求。
[1]包薩日娜.傳統蒙古文到新蒙文轉換中名詞及其格附加成分轉換的研究[D].呼和浩特:內蒙古大學,2009.
[2]烏日力嘎.傳統蒙古文、西里爾蒙古文-漢文電子詞典的建立[D].呼和浩特:內蒙古大學,2009.
[3]Li Hao,Sarina B.The study of comparison and conversion about traditional Mongolian and Cyrillic Mongolian[C]// 2011 4th InternationalConference on IntelligentNetworks and Intelligent Systems,2011:199-202.
[4]高紅霞,馬小蕾.西里爾蒙古文網頁向傳統蒙古文自動轉換系統的文字轉換研究[J].內蒙古民族大學學報,2012,18(5):17-18.
[5]明玉.基于詞典、規則與統計的蒙古文詞切分系統的研究[D].呼和浩特:內蒙古大學,2011.
[6]Zhao Lili,Men Jia,Zhang Congpin,et al.A combination of statistical and rule-based approach for Mongolian lexical analysis[C]//2010 International Conference on Asian Language Processing,Harbin,2010:7-10.
[7]Bisani M,Ney H.Joint sequence models for grapheme-tophoneme conversion[J].Speech Communication,2008,50(5):434-451.
[8]Wang D.Out-of-vocabulary spoken term detection[D].[S.l.]:University of Edinburgh,2010:85-110.
[9]確精扎布.蒙古文編碼[M].呼和浩特:內蒙古大學出版社,2000.
[10]嘎拉桑朋斯格.基立爾蒙古文學習讀本[M].呼和浩特:內蒙古教育出版社,2006.
[11]清格爾泰.蒙古語語法[M].呼和浩特:內蒙古人民出版社,1992.
[12]圖門吉日嘎拉.現代蒙古語[M].呼和浩特:內蒙古大學出版社,2009.
[13]舍·卻瑪.蒙古文、基里爾文正字法比較研究[M].呼和浩特:內蒙古教育出版社,2010.
[14]Bisani M,Ney H.Multigram-based grapheme-to-phoneme conversion for LVCSR[C]//Proc Eurospeech’03,Geneva,2003:933-936.
[15]張志忠.新蒙漢詞典[M].北京:商務印書館,2011.
BAO Feilong,GAO Guanglai,YAN Xueliang,WEI Hongxi
College of Computer Science,Inner Mongolia University,Hohhot 010021,China
Traditional Mongolian and Cyrillic Mongolian are both Mongolian languages and are widely used in China and Mongolia respectively.With almost the same pronunciations,their written forms are totally different.According to the characteristic of the two languages,this paper proposes a joint sequence model based approach and depicts in detail the corresponding experiments performed.In the experiments,the word error rate and letter error rate for the traditional Mongolian to Cyrillic Mongolian conversion system are 18.38%and 6.75%,and that for Cyrillic Mongolian and traditional Mongolian conversion system are 18.77%and 7.14%.Experimental results show that the proposed approach can meet the basic requirements for practical use.
traditional Mongolian;Cyrillic Mongolian;joint sequence models;joint multigram
傳統蒙古文和西里爾蒙古文分別是在中國和蒙古國使用的蒙古文,它們的口語基本相同,但是書寫形式完全不同。結合傳統蒙古文和西里爾蒙古文的構詞特點,提出了基于聯合序列模型的傳統蒙古文和西里爾蒙古文相互轉換方法,并做了大量的相互轉換實驗。實驗中,傳統蒙古文到西里爾蒙古文轉換系統的詞誤識率和字母誤識率分別達到了18.38%和6.75%,西里爾蒙古文到傳統蒙古文轉換系統的詞誤識率字母誤識率分別達到了18.77%和7.14%,基本達到了實用要求。
傳統蒙古文;西里爾蒙古文;聯合序列模型;聯合多元
A
TP391.1
10.3778/j.issn.1002-8331.1301-0314
BAO Feilong,GAO Guanglai,YAN Xueliang,et al.Research on conversion approach between traditional Mongolian and Cyrillic Mongolian.Computer Engineering and Applications,2014,50(23):206-211.
國家自然科學基金(No.61263037,No.71163029);內蒙古自然科學基金(No.2014BS0604);內蒙古大學高層次人才引進科研項目資助。
飛龍(1985—),男,博士,講師,主研方向為蒙古文信息處理、語音識別與語音檢索;高光來(1964—),男,教授,博士生導師,主研方向為蒙古文信息處理、模式識別與人工智能;閆學亮(1984—),男,碩士生,主研方向為蒙古文信息處理、信息檢索;魏宏喜(1981—),男,博士,副教授,主研方向為蒙古文信息處理、文字識別。E-mail:csfeilong@imu.edu.cn
2013-01-28
2013-06-24
1002-8331(2014)23-0206-06
CNKI網絡優先出版:2013-08-22,http://www.cnki.net/kcms/detail/11.2127.TP.20130822.1408.002.html
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
閱讀(快樂英語高年級)(2020年8期)2020-01-08 02:21:16
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
智慧少年·故事叮當(2018年11期)2018-05-14 11:48:18
光學精密工程(2016年6期)2016-11-07 09:07:19
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
