基于Trace合并和寄存器分配的Dalvik優化
2014-06-07 05:53:21余超君李春強尚云海張培勇
計算機工程 2014年10期
余超君,李春強,尚云海,張培勇
(浙江大學超大規模集成電路設計研究所,杭州310027)
基于Trace合并和寄存器分配的Dalvik優化
余超君,李春強,尚云海,張培勇
(浙江大學超大規模集成電路設計研究所,杭州310027)
Dalvik虛擬機作為Android系統上運行所有應用程序的基礎,其性能瓶頸一直制約著Android系統的用戶體驗。通過研究Android系統中的Dalvik架構,分析其解釋器和JIT模塊的工作原理,發現熱Trace選擇過程中短Trace編譯損耗大以及即時編譯過程中寄存器分配不合理的情況。結合Java虛擬機技術和編譯器技術,在現有熱Trace選擇和寄存器分配機制的基礎上,提出基于Trace合并和寄存器分配的優化算法,在國產高性能嵌入式CPU CSKY體系下移植Dalvik虛擬機并實現了上述優化算法。通過實驗證明優化后Dalvik執行Java程序的性能提高了近10%。
Dalvik虛擬機;JIT技術;性能優化;Trace合并;寄存器分配;生命周期
1 概述
Android是Google公司針對嵌入式領域推出的操作系統,其Java虛擬機采用Dalvik VM。與PC機Java虛擬機相比,Dalvik針對內存和處理器速度有限的嵌入式設備進行優化,使其占用更少內存等硬件資源,運行效率更高。Dalvik工作于解釋執行模式,并根據運行情況通過基于Trace的JIT(Just in Time)技術將熱點代碼塊編譯成本地機器代碼并執行以加快程序運行[1]。
雖然基于Trace的JIT技術的Dalvik虛擬機提高了Java程序運行速度,但其Dalvik虛擬機的性能仍是Android系統運行速度的瓶頸。筆者在移植Dalvik到國產嵌入式CPU C-SKY平臺的過程中,通過對基于Trace的JIT技術的Dalvik虛擬機研究,發現Dalvik現階段基于Trace的JIT技術存在如下問題:(1)Hot-Trace的某些熱點代碼塊短導致編譯比執行代碼時間長,相應的編譯消耗大,而且編譯的本地機器碼短,代碼優化空間小[2];(2)Trace編譯時,寄存器分配策略簡單,導致Java虛擬寄存器的冗余載入和存回,即增加了冗余的 load/store操作[3]。第(1)個問題可以通過Trace合并來增加Trace代碼塊長度,第(2)個問題可以通過寄存器分配策略優化來減少冗余的load/sotre指令。
本文簡要介紹Dalvik虛擬機的特性并闡述其工作原理。在詳細分析基于Trace的JIT技術的Dalvik虛擬機基礎上,針對上述問題,設計并實現一種Trace合并和寄存器分配的優化方法,并用標準Benchmark程序對優化前后的Dalvik進行性能評測。
2 Dalvik虛擬機
Dalvik是一個標準的Java運行環境,但在內部實現上,和標準JVM存在差異,具有如下特點[4]:
(1)不同于標準JVM運行class文件,Dalvik虛擬機運行的是由dx工具封裝好的dex文件。這樣做不僅減少了整體的文件尺寸,也加快了I/O操作,提高了類的查找速度。
(2)不同于標準JVM的基于棧的構架,Dalvik虛擬機是基于寄存器的。基于寄存器的架構雖然每條指令占用較多空間,但總體上減少了字節碼總條數,即減少了指令分派次數及內存訪問次數。
(3)不同于標準 JVM運行的 Java字節碼, Dalvik運行根據基于寄存器的架構設計了專有Bytecode[5]。
Dalvik執行引擎采用基于Trace的JIT技術[6-7],其流程如圖1所示。

圖1 Dalvik的JIT流程
Dalvik虛擬機開始運行時由解釋器解釋執行Bytecode,并在各可能的Trace入口點記錄執行過的次數。當執行次數達到某個閾值(如armv7閾值為40次),會檢查在該Trace入口點是否在保存編譯結果的內存區域存在對應的已編譯好的機器碼,若存在則跳轉到該機器碼直接運行;否則繼續解釋執行并開始記錄執行軌跡(即Trace開始生成),直到Trace結束點,并提交這段Trace給編譯線程編譯。編譯好的機器碼會放入內存區域,當下次再執行這個Trace入口地址時,就可跳轉到該機器碼塊直接執行[6]。
3 JIT優化
本文針對基于Trace的JIT模式的Dalvik虛擬機的缺點,提出通過Trace合并和寄存器分配策略進行優化。作為基于Trace的JIT特性的Dalvik虛擬機,Trace的長度是影響其生成的機器碼的質量的一個決定性因素,若Trace的長度比較短,則會導致解釋器和編譯線程的通信消耗加大,且生成機器碼時的可優化空間變小[8],本文通過 Trace合并增加Trace長度,從而降低解釋器和編譯線程之間的通信消耗,同時使得在Trace編譯時可以通過更多的優化技術提高生成的機器碼質量[9]。本文還針對Dalvik在動態編譯時采用的基于輪詢機制的簡單寄存器分配策略,通過分析生命周期[10],減少虛擬寄存器中數據的載入和存回。
3.1 Trace合并
通過對標準 Java測試程序 CaffeineMark在Dalvik上運行時的分析,筆者發現作為Dalvik JIT在Trace劃分時的結束標志性Bytecode類型中,69%的類型是條件跳轉Bytecode(即Branch類)。因此,筆者提出當Trace以條件跳轉Bytecode結束時,選擇Branch Bytecode后的2個分支Trace中的1個和該Trace合并[11],從而加大Trace長度,提高編譯時優化的可能性[12]。
考慮到Branch的2個出口都可能是其他Trace的入口。如圖2所示,If_eq Bytecode所在的Trace1連接著2個Trace(Trace 2和Trace 3)的入口。對此可以將其中一個Trace(如Trace 2)和Trace 1合并,如圖2(b)所示,合并后的Trace 4變長。
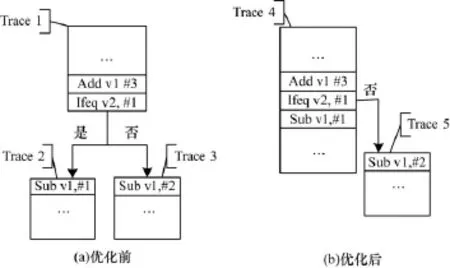
圖2 Trace合并
條件跳轉有2個分支,選擇哪個分支Trace合并到新的Trace將是一個問題。根據程序執行的可預測性,為降低內存開銷、減少Trace合并的性能損耗,采取如下預測算法:對于重復執行的字節碼代碼段,條件分支的跳轉具有重復性。也就是說,在重復的代碼段中,條件跳轉第n次跳轉出口很有可能也是第n+1次跳轉的出口(比如在循環體中有if語句,一般情況下2個跳轉出口中的一個執行的比較多)。筆者通過修改Dalvik解釋器,統計類似上述類型條件跳轉的跳轉出口,發現同一出口的執行概率有81%。此實驗也驗證了預測算法的可行性。所以,在重復執行代碼到達閾值后,其下一次跳轉的字節碼分支,作為合并的目標字節碼分支。
圖3表示了圖2所示的Bytecode編譯成機器碼(CSKY指令集)后的情況(假設分支都被編譯)。圖3(a)中左分支由bf指令跳至鏈接單元chaining celln-1(用于跳轉到解釋器或者其他已編譯好的Trace)再跳入Trace 2的代碼中,Trace 2需要將虛擬寄存器v1的值載入實際寄存器中;右分支由bt指令跳至chaining celln再跳入Trace 3的代碼中,Trace 3需要將虛擬寄存器v1的值載入實際寄存器中。而如果通過合并Trace,編譯出來的機器碼將如圖3(b)所示,編譯Trace 4代碼,而原Trace 2中需要載入的虛擬寄存器如在原Trace 1中載入過則不需要重新載入。相比較可以發現如下優點:bf指令和對應的chaining celln-1由于代碼流將直接在預測分支執行而不再需要,減少了整體內存占用;原Trace 2中將減少若干用于虛擬寄存器載入的load指令,這對性能提升作用很大。
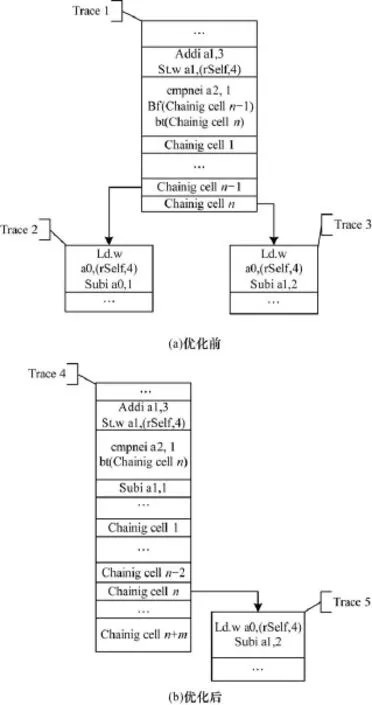
圖3 Trace合并后編譯的機器碼
3.2 寄存器分配
通過合并Trace來增加Trace長度,可以加大優化窗口,從而提升性能。鑒于load/store一直是嵌入式設備的性能瓶頸[13],本文提出基于生命周期分析的寄存器分配算法,以減少Dalvik虛擬寄存器(存在內存中)和物理寄存器之間的傳遞,從而有效減少load/store操作。特別是結合Trace合并優化,代碼塊越長,越容易提升性能[14]。
如圖4中Bytecode部分所示(v0,v17,v0’等表示Bytecode的虛擬寄存器,a0,a1等表示物理寄存器),開始時對v0進行運算,經過多條Bytecode后,又出現對v0運算的Bytecode。在Dalvik現有的寄存器分配策略下,生成如圖4中優化前部分所示的類似代碼:v0載入a0,在若干Bytecode后空閑物理寄存器用完,重新取a0用于v17的載入,當遇到add v0,#6,需要重新載入v0到a1。其實這條load指令可以通過分析寄存器生命周期,并用適當的寄存器分配策略消除。如圖4中優化后部分所示,當空閑寄存器全部用完時,優先分配那些生命周期已經結束的寄存器給接下來的Bytecode(比如此例中的l9)使用,這樣在編譯add v0,#6這條指令時不需要重新load虛擬寄存器v0,因為v0的值已經存在a0中,因而減少了load指令。實際應用中,這種情況會很多(特別是Trace增長后),優化后將有明顯效果。
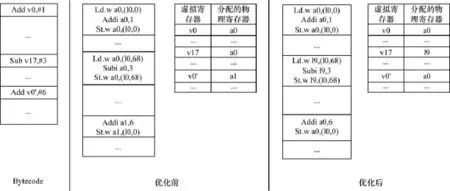
圖4 寄存器分配優化
3.3 優化算法的實現
現有基于Trace的JIT技術的Dalvik虛擬機中建立Trace的過程如圖5(a)所示,在建立Trace階段,對每個Bytecode判斷其是否符合Trace結束條件,即當前指令是否是Branch,Invoke,Switch,Return類指令或者當前Trace超過最大限定長度。當條件符合時,表示從前一個Trace入口到當前Bytecode為一個可以編譯為機器碼的 Trace,將收集到的Trace信息(包括當前Trace開始點位置,Trace中 Bytecode的數目等)以結構數組Trace[MAX_JIT_ RUN_LEN]的方式存儲,以等待compiler線程獲取并編譯。Trace合并優化流程如圖5(b)所示。在全局結構Thread中加入整型Combination變量,其初值設為COMBINE宏(表示合并的最大Trace數)。考慮到以Invoke,Switch,Return類Bytecode結束的Trace或超長Trace與后續Trace合并后對系統優化起到的比例較低,只針對以Branch類Bytecode結束的Trace與后續Trace進行合并。
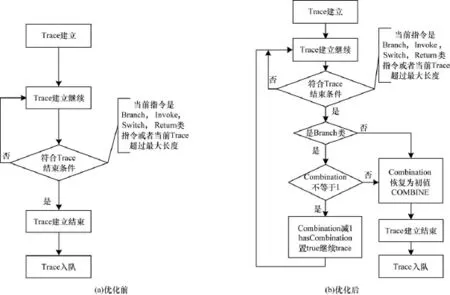
圖5 Trace合并優化
當Trace將以Branch指令結束,根據Combination變量是否已經等于1判斷其是否已經到了合并Trace數目最大值。若未等于1,對Combination值減1并將Trace信息放入結構數組Trace[MAX_JIT_RUN_LEN]下一個組成員中,繼續建立Trace。若已經等于1, Combination恢復為COMBINE并結束Trace的建立,將Trace[MAX_JIT_RUN_LEN]存儲等待編譯。
在編譯線程中,若 Trace[MAX_JIT_RUN_ LEN]指示的Trace最后一個字節碼是Branch類的,則它的跳轉目標為相應指令(即合并后的下一個塊),而不是 Chaining Cell,并不再建立相應的Chaining Cell。
Dalvik編譯過程中的寄存器分配策略比較簡單,如圖6(a)所示。寄存器分配優先分配那些當前Bytecode不用且之前也沒有分配過(即不在活動中)的寄存器,如果不存在,則只需保證當前Bytecode不用的寄存器即可。但是,當編譯單元長度增加,寄存器分配次數增多,就可能出現一個物理寄存器多次分配給不同的虛擬寄存器,導致虛擬寄存器內的值在其生命周期內會被多次存回和重載入,從而增加load/store指令。
為優化寄存器分配策略,本文在編譯階段使用靜態單一賦值(Static Single Assignment,SSA)法轉換時,為每個SSA寄存器存儲其生命周期消失點,以消失點的Bytecode距離Trace首的偏移值表示,并用變量useend_offset保存。然后在代表物理寄存器狀態的RegisterInfo結構中加入整型變量useend,用于對SSA寄存器分配物理寄存器時保存對應的useend_offset。

圖6 寄存器優化
在寄存器分配時,如圖6(b)所示,優先分配那些當前Bytecode不用、之前也沒有分配過的寄存器且寄存器RegisterInfo結構中useend的值小于當前編譯的Bytecode距Trace頭的偏移值(即表示該寄存器在后續不會被用到,也就減少了 load/store指令),然后再同原分配策略類似分配。
4 性能分析
CaffeineMark是常用的針對嵌入式設備進行性能評測的一款Java軟件,其分數高低體現了其性能的好壞,采用該軟件來測評優化的效果。
實驗硬件平臺是C-SKY公司的國產高性能嵌入式CPU CK810 16 MHz FPGA板,軟件平臺是Android 4.0.3。CaffeineMark包括 Sieve,Loop, Logic,String,Float,Method,Overall 7個組件。筆者針對未優化、僅Trace合并優化、僅寄存器分配優化、兩者都優化這4種情況進行測評,實驗結果如表1所示,表中數據表示相應測試項目的得分。
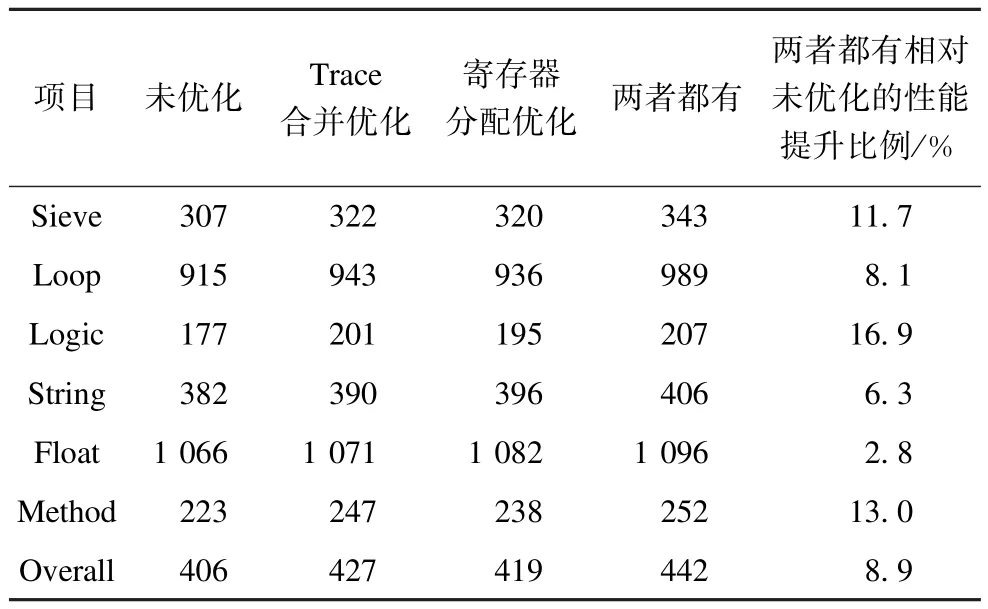
表1 性能測試數據
由實驗數據可見,優化實現后性能提高接近10%。可以看出,僅有Trace合并優化時效果一般,僅有寄存器分配優化時效果不明顯,而當兩者同時使用時,優化效果比較明顯。這也說明了Trace合并的優化使Trace長度增加,基于其上的寄存器優化的效果更加明顯。
5 結束語
在已經移植好的Android4.0.3基礎上,本文描述了對其Dalvik虛擬機的優化,包括Trace合并和寄存器分配優化,并通過實驗對Dalvik優化前后的性能進行了對比,結果表明Dalvik的優化效果比較明顯。下一步工作包括確定Trace合并數目的最優解以及嘗試一些其他傳統編譯器的優化方法。
[1] Bornstein D.The Dalvik VM Internals[C]//Proc.of Google I/O Developer Conference.San Francisco,USA: [s.n.],2008:1-8.
[2] Hiroshi I.A Trace-based Java JIT Compiler for Large-scale Applications[C]//Proc.of the 6th ACM Workshop on Virtual Machines and Inter-mediate Languages.New York, USA:ACM Press,2012:1-2.
[3] Hsu Wei-Chung,Charles N F,Goodman J R.On the Minimization of Load/stores in Local Register Allocation[J].IEEE Transactions on Software Engineering, 1989,15(10):1250-1260.
[4] Security Engineering Research Group.Analysis of Dalvik Virtual Machine and Class Path Library[EB/OL]. (2009-07-12).http://imsciences.edu.pk/serg/wp-content/ uploads/2009/07/Analysis-of-Dalvik-VM.pdf.
[5] 葉 云,李春強,胡軍山.基于CK610的Dalvik虛擬機移植與優化[J].計算機工程,2011,37(16):291-292.
[6] Ben C,Bill B.A JIT Compiler for Android’s Dalvik VM [EB/OL].(2010-05-19).http://www.google.com/intl/ zh-CN/events/io/2010/sessions/jit-compiler-androidsdalvik-vm.html.
[7] 周毅敏,陳 榕.Dalvik虛擬機進程模型分析[J].計算機技術與發展,2010,20(2):83-86.
[8] Hiroshi I,Hiroshige H,Peng W.A Trace-based Java JIT Compiler Retrofitted from a Method-based Compiler[C]// Proc.of the 9th AnnualIEEE/ACM International Symposium on Code Generation and Optimization. Chamonix,France:IEEE Press,2011:246-256.
[9] Gal A,Eich B,Shaver M,et al.Trace-based Just-in-time Type Specialization for Dynamic Languages[C]//Proc. ofACM SIGPLAN Conferenceon Programming Language Design and Implementation.New York,USA: ACM Press,2009:465-478.
[10] Byung-Sun Y,Junpyo E,SeungIl L,et al.Efficient Register Mapping and Allocation in LaTTe,An Open-Source Java Just-in-time Compiler[J].IEEE Transactions on Parallel and Distributed Systems,2007,18 (1):57-69.
[11] Bebenita M,Brabdner F,Fahndrich M,et al.SPUR:A Trace-based JIT Compiler for CIL[R].Microsoft Corporation,Technical Report:MSR-TR-2010-27,2010.
[12] Cramer T,Richard F R,Miler T.Compiling Java Just in Time[Z].1997.
[13] Suganuma T,Yasue T,Nakatani T.A Region-based Compilation Technique for Dynamic Compilers[J]. ACM Transactions on Programming Languages and Systems,2006,28(1):134-174.
[14] Gal A.Efficient Bytecode Verification and Compilation in a Virtual Machine[D].Long Beach,USA:University of California,2006.
編輯 陸燕菲
Optimization of Dalvik Based on Trace-combination and Register Allocation
YU Chao-jun,LI Chun-qiang,SHANG Yun-hai,ZHANG Pei-yong
(Institute of VLSI Design,Zhejiang University,Hangzhou 310027,China)
As the basics of running application on Android system,performance of Dalvik virtual machine restricts the Android’s user experience.By researching Dalvik architecture in the Android system and analyzing some key techniques of the interpreter and Just in Time(JIT)module,it finds that short Trace’s compiler dissipation is large and there are some irrational situations on register allocation in JIT.Combining nowadays JVM technology with modern compiler technology,and based on the Trace selection strategy and register allocation mechanism of Dalvik,this paper proposes algorithms of combining Trace and optimizing strategy of register allocation.These algorithms are implemented in high performance embedded CPU CSKY architecture.The experiments prove that this Dalvik can improve the performance by about 10%.
Dalvik virtual machine;Just in Time(JIT)technology;performance optimization;Trace-combination; register allocation;life cycle
1000-3428(2014)10-0061-05
A
TP314
10.3969/j.issn.1000-3428.2014.10.012
國家自然科學基金資助項目(61204111);“核高基”重大專項(2010ZX01030-001-001-002)。
余超君(1989-),男,碩士,主研方向:虛擬機技術與應用;李春強、尚云海,碩士;張培勇,副教授、博士。
2013-09-13
2013-11-30E-mail:67146172@qq.com
中文引用格式:余超君,李春強,尚云海,等.基于Trace合并和寄存器分配的Dalvik優化[J].計算機工程,2014, 40(10):61-65,70.
英文引用格式:Yu Chaojun,Li Chunqiang,Shang Yunhai,et al.Optimization of Dalvik Based on Trace-combination and Register Allocation[J].Computer Engineering,2014,40(10):61-65,70.
猜你喜歡
科普童話·神秘大偵探(2023年1期)2023-05-30 12:48:10
鐵道通信信號(2020年9期)2020-02-06 09:15:22
數學大王·趣味邏輯(2019年5期)2019-06-13 20:27:43
小學科學(學生版)(2019年5期)2019-05-21 01:00:18
測控技術(2018年5期)2018-12-09 09:04:26
經濟技術協作信息(2018年30期)2018-11-22 06:20:24
電子測試(2018年18期)2018-11-14 02:30:34
鐵道通信信號(2018年2期)2018-04-18 12:18:23
電鍍與環保(2016年3期)2017-01-20 08:15:32
單片機與嵌入式系統應用(2014年9期)2014-03-11 15:35:13
