基于擴展查詢表達式的XML關鍵字查詢
2014-06-07 05:53:21朱菁華王曉玲
計算機工程 2014年10期
朱菁華,王曉玲
(復旦大學計算機科學技術學院,上海200433)
基于擴展查詢表達式的XML關鍵字查詢
朱菁華,王曉玲
(復旦大學計算機科學技術學院,上海200433)
目前可擴展標示語言(XML)關鍵字查詢大多是基于最小公共祖先(LCA)語義子樹產生查詢結果,而未能加入除LCA語義子樹之外與用戶查詢意圖相關的結果。為解決該問題,提出一種基于擴展查詢表達式的XML關鍵字查詢方法。將用戶查詢日志作為查詢擴展統計模型,對其進行統計分析,并結合最佳檢索概念判斷是否需要擴展查詢表達式。使用XML TF-IDF方法計算候選屬性的權重,根據初檢結果的上下文信息,利用聚類方法獲得與查詢意圖最相關的擴展查詢關鍵字,從而擴展查詢表達式。實驗結果表明,與XSeek和基于語義詞典的查詢擴展方法相比,該方法的平均F度量值分別提高了7%和17%,具有較高的查詢質量。
信息檢索;可擴展標示語言;最小公共祖先語義;關鍵字查詢;查詢擴展;上下文信息
1 概述
信息檢索中的一個主要挑戰就是如何精確判斷用戶的查詢意圖,而關鍵字查詢方式由于缺乏足夠的結構和語義信息,使得其查詢結果往往無法令用戶滿意。如今,可擴展標示語言(eXtensible Markup Language,XML)由于其靈活性等優點,被廣泛應用于Web上。所以,如何幫助用戶產生精確的查詢表達式對于XML關鍵字查詢是很有必要的。
目前,XML關鍵字查詢的研究大多都是基于最小公共祖先(Lowest Common Ancestor,LCA)概念來確定相關語義片段子樹[1]。針對LCA存在嵌套的問題,文獻[2]提出了最近最小公共祖先(Smallest LCA,SLCA)。SLCA是一個最小LCA子樹,包含所有關鍵字且該子樹的任一子樹都不再包含所有關鍵字。
雖然現在多數的XML關鍵字查詢方法通過對LCA語義片段的裁剪能有效地去除不相關的信息,但它們都是只針對LCA子樹中的內容進行裁剪,而把LCA子樹外的內容認為是不相關的。顯然這樣的查詢結果未必能滿足用戶的查詢意圖。由于XML文檔層次特點與用戶查詢意圖相關的內容完全可能不在LCA子樹中,而基于多數LCA語義的XML關鍵字查詢方法,雖然可以過濾與查詢不相關的信息,但也會降低查詢的查全率。
為解決該問題,因此本文提出一種基于擴展查詢表達式的方法。總結了多數基于LCA語義的XML關鍵字查詢方法工作,并指出了它們的不足之處,即查詢結果受限于LCA語義子樹,未能加入LCA語義子樹外并與用戶查詢意圖相關的結果。本文主要解決了2個問題,即判斷查詢表達式是否需要擴展和查詢表達式如何進行擴展。新的查詢表達式的檢索結果與初檢結果相比,會添加未被LCA語義子樹包含但與用戶查詢意圖相關的信息,從而實現“內容+結構”的XML關鍵字查詢擴展。
2 相關工作
XSeek[3]是基于LCA語義子樹的XML關鍵字查詢的一個比較典型的方法。該方法借鑒關系數據庫中的ER模型思想為XML樹中的節點分類,同時用類似于XQuery的語法分析了關鍵詞查詢匹配模式,結合兩者生成的語義信息對SLCA子樹進行裁剪。圖1是一個eBay在線拍賣的數據的XML樹。對于查詢{Seller Tony},觀察查詢語義可以猜測用戶想了解賣家Tony的相關信息。XSeek方法只返回圖中以“Seller”為根節點的子樹,而把其他內容認為是不相關的。顯然這樣的查詢結果未必能滿足用戶的查詢意圖,用戶完全可能對Payment和Shipping等信息感興趣。

圖1 eBay在線拍賣的XML文檔樹
目前,國內外的查詢擴展方法主要有3類:對語料庫或知識庫分析后的擴展,局部分析方法和全局分析方法。根據語料庫獲得的查詢擴展方法是利用語義知識詞典,然后甄選與初始查詢關鍵字概念相近或等同的詞來進行查詢擴展。如文獻[4-5]以WordNet為語義本體,能同時對查詢關鍵字的狹義詞、廣義詞、同義詞和近義詞等進行匹配,有效地提升查詢質量。但是,這種方法有著十分明顯的缺陷,即其擴展的查詢關鍵字往往受限于參考的語料庫,并且只是簡單地根據語義概念進行鏈接,從而導致很多無關的關鍵詞加入查詢表達式,進而影響查準率。文獻[6-7]以查詢日志作為語料庫進行分析和數據挖掘,能較好地保證擴展用詞和原查詢以及查詢結果是相關聯的。但是其未能考慮諸如XML文檔這樣的半結構化數據,只適用于傳統的文本文檔。
局部分析方法的核心思想是通過連續2次的查詢來解決查詢表達式擴展問題。通過初次查詢獲得最相關的K個結果作為查處擴展詞的來源,然后,將權值較高的N個詞加入查詢表達式進行新的查詢[8]。目前較流行的有相關反饋方法和偽相關反饋方法[9]。雖然局部分析方法是目前十分受歡迎和普通應用的查詢擴展方法,但其查詢質量十分依賴初檢結果的相關性。換言之,如果第一次查詢后獲得文檔與用戶查詢意圖相關度較小時,其查詢擴展的質量較差。
以相似性詞典[10]等為代表的全局分析方法是在用戶提交查詢前,對所有文檔中的詞或詞組進行統計分析,并計算各個詞或詞組間的關聯程度。當用戶提交查詢后,根據先前計算的詞或詞組間的相關關系,把與查詢相關的詞添加獲得擴展后的查詢表達式。全局分析方法的優勢是可以十分有效地探究數據集中的詞間關系,但是這種方法僅限與符號層面的匹配,而無視了查詢關鍵詞與目標文檔語義上的關聯程度。同時,當數據集大小逐漸增大后,該方法在時間和空間上的開銷也十分高昂。
文獻[11]提出了結合2種擴展方式的方法。該方法基于對初檢結果以及查詢日志的分類和數據分析,獲得相關的擴展詞。雖然該方法不僅面向XML數據,同時也取得了較優的查詢質量,但是其查詢擴展表達式仍舊是對LCA語義子樹的裁剪分類,未能有效考慮潛在的相關聯的信息。
3 數據模型
由于XSeek方法有較好的查詢質量,因此本文提及的查詢結果子樹均是指用XSeek方法產生的LCA子樹。通過分析大部分XML文檔樹,可以發現XML文檔樹都是具有一定的語義,可以把XML文檔樹的節點從語義角度分為3類節點:值節點,屬性節點和實體節點。
定義1(值節點) 稱XML文檔樹T中葉子節點為值節點。例如,圖 1中的“Tony”和“848”等節點。
定義2(屬性節點) 稱XML文檔樹T中值節點的父親節點為屬性節點。例如,圖 1中的“SellerName”節點。
定義3(實體節點) XML文檔樹T中的節點若既不是屬性節點也不是值節點,那么稱該節點為實體節點。例如,圖1中“Seller”和“HighBidder”等節點為實體節點。
對于XML文檔中既有葉子節點又有非葉子節點作為孩子節點的情況,認為該節點屬于實體節點。
定義4(查詢結果子樹) 對于一個查詢Q和XML文檔樹T,按XSeek方法獲得一顆子樹t稱作查詢結果子樹。
定義5(實體序列) 對于查詢結果子樹t,按先后次序遍歷并記錄其中的實體節點,所產生的序列稱作實體序列。
定義6(查詢上下文) 對于一個關鍵字查詢Q,其查詢上下文是:

其中,域ES為查詢結果子樹的實體序列;域WHE表示了查詢Q的限制條件,類似于SQL中的where集合;域SEL為查詢想要獲取的信息,類似于SQL中的select集合。
由于XML文檔為半結構化數據且關鍵詞查詢方式不包含任何結構信息,一個明顯的問題是如何確定域WHE和SEL的值。觀察SQL語言可知,查詢限制條件往往是包含了具體數值信息,而查詢目的則往往只提供不帶數值信息的數據類型信息。根據定義1~定義3可知,實體節點和屬性節點對應于數據類型信息,而值節點則對應數據值類型。根據以上分析并結合文獻[12]對XML關鍵詞查詢匹配模式的研究,本文由以下2個原則分別確定域WHE和SEL的值:
(1)如果關鍵字查詢中的某個關鍵字k1匹配某個實體節點或者屬性節點,且不存在另一個關鍵字k2滿足:匹配某個值節點,且該值節點與k1匹配的節點存在祖先-后代關系。那么關鍵字k1表示該查詢想要獲取的信息內容,k1會被添加至SEL域中。
(2)未被添加至域SEL的關鍵字,即與值節點匹配的關鍵字,為查詢的限制條件,會被添加至域WHE。
4 擴展查詢表達式的判斷
顯然,不是所有的查詢表達式都要擴展,有些能完全滿足查詢意圖。因此,需要判斷哪些需要擴展。
4.1 查詢結果分析
通常,用戶提交了查詢Qi后,如果其查詢結果子樹是相關的但缺少部分感興趣的內容,會在Qi的基礎上提交新的查詢Qj。對于2個連續查詢Qi和Qj,如果Qj是對Qi的擴展,那么它們兩者有一定的聯系。
例如,對圖 1的 XML文檔樹,如果 Qi是{IBM},Qj是{IBM Seller},Qi的查詢結果子樹以“ItemInfo”為根節點,Qj的查詢結果子樹是Qi的查詢結果子樹加上以Seller為根節點的子樹。比較它們的查詢上下文可以發現:Qi的ES是Qj的ES的子集,即Qj的結果是Qi的結果的結構上的擴展;它們的查詢限制條件,即域WHE,均為“IBM”,都是想查詢和“IBM”相關的信息,可以說它們的查詢意圖有一定的交集。不同的是 Qj還指出想要獲取“Seller”的信息。因此,可猜測Qj的查詢結果是對Qi的查詢結果的擴充。換言之,查詢表達式Qj是對查詢表達式Qi的擴展,即{IBM Seller}才是真正能獲得滿足用戶興趣的查詢。因為如果Qi的結果是正確的但不能完全滿足查詢需求時,從語義上看,用戶不會改變他的查詢限制,但會加入新的查詢意圖,而從結構上看,Qj的查詢子樹會比Qi的“大”且包含Qi的整個查詢子樹。
另外一個例子,如果Qi是{Tony SellerRating}, Qj是{Seller Tony ItemInfo}。雖然Qj在結構上是對Qi的擴充,但顯然它們不是感興趣的查詢結果擴展。因為它們不存在任何語義連續性。顯然Qi只是對屬性“SellerRating”的值感興趣,而Qj則是對“Seller”為“Tony”所拍賣的物品信息感興趣。通過觀察它們查詢上下文的域WHE便可作出判斷。因此,在這種情況下,Qj不能作為Qi的查詢擴展表示式。
定義7(查詢表達式擴展) 對于2個連續的查詢Qi和Qj,如果Qj是對Qi的查詢表達式擴展,那么必須滿足以下條件:

4.2 查詢表達式擴展決策策略
本文中查詢表達式擴展的目的是為原本的查詢結果添加更多與查詢意圖相關的信息,即可等價看作查詢結果的擴展。本文對于每一個查詢表達式的擴展,等同于查詢結果子樹的擴展,同時也可看作是對該實體信息的擴展。
根據定義7對查詢日志進行分析和統計,可以得到每個實體信息的查詢結果擴展幾率。顯然,每一個查詢結果的擴展操作都會對搜索引擎帶來額外的開銷。眾所周知,用戶不僅要求搜索引擎可以返回相關的結果,同時也希望獲得良好的查詢處理時間。所以,對于確定哪些實體需要被擴展這個問題便轉換為確定哪些實體的結果擴展具有較高的收益和較低的代價。
定義8(查詢表達式擴展代價) 對于2個查詢Qi與Qj,及其相應的原始結果i和擴展結果j,從i擴展到j的代價是從i的根節點出發到j同時滿足如下2個條件的節點的路徑和:
(1)該節點只存在于j中而不存在于i中;
(2)該節點出現在Qj的查詢上下文中的域SEL內。
仍以圖1所示的XML文檔樹為例,如果Qi為{IBM},Qj為{IBM Seller}。由定義7可知,Qj的結果是Qi結果的擴展。此外,從定義6可知,域SEL的內容反映每個查詢的意圖,而查詢表達式擴展的目的是盡可能給用戶提供所有相關的信息。因此,如果要對當前的查詢表達式擴展只需添加最終結果中的域SEL中的節點信息。對Qi的查詢表達式擴展應該添加屬性“SellerName”和“SellerRating”。因此,根據定義8,對Qi查詢表達式擴展代價是從節點“ItemInfo”到節點“Tony”和“848”的路徑長度之和,為8。
結合文獻[13]中的最佳檢索概念和概率排序原則,得到確定是否對結果(即實體)進行擴展的決策策略:

其中,Pi,j表示從初始結果i到最終結果j的擴展概率;m為初始結果i有m種不同的最終結果;Tj表示生成結果j的代價,這里用該樹中邊的數目總和表示;Ei,k表示把初始結果i擴充到最終結果k的擴展代價。
由于對用戶查詢意圖猜測是一個概率問題,很難完全確定當前結果是否能完全滿足用戶的查詢意圖,因此該決策策略要求右半部分值小于左半部分值,即要求如果為i進行結果擴展,那么該操作帶來的收益應該大于該操作本身增加的系統負載。
5 擴展查詢表達式的上下文信息添加
定義9(候選屬性) 對于XML文檔樹中任意一個屬性節點a和任意一個實體節點e,如果a不在以e為根節點的子樹里,那么屬性a稱作是實體e的候選屬性。
對于給定的實體e,把其所有的候選屬性構成的集合稱為候選屬性集。如果要擴展當前查詢表達式,那么需要添加的上下文信息必定在該查詢結果子樹對應的實體的候選屬性集中。顯然,不同的候選屬性其權重也不同。根據 TF-IDF方法的思想[14],利用XML TF-IDF方法計算各候選屬性的權重,計算方法如下:
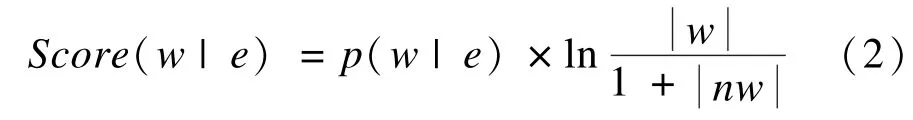
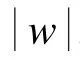
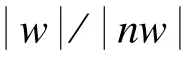
在完成了對候選屬性計算權重后,接下來是對不同的實體,確定添加多少候選屬性。本文使用非加權組平均法(Unweighted Pair Group Averaging Method, UPGMA)[15]為每個實體的候選屬性集進行聚類,聚成2類。然后計算2個聚類的平均權值,舍棄最低的那個。剩余的那個聚類中的候選屬性可作為該實體對應的查詢表達式的擴展部分。
6 系統實現
圖2顯示了基于擴展查詢表達式的系統結構,該系統分為在線和離線兩部分。

圖2 基于擴展查詢表達式的系統結構
在線部分的工作具體如下:
(1)當用戶提交一個查詢后,系統用XSeek方法生成初步結果;
(2)當前查詢表達式不需要被擴展時,則直接輸出結果;
(3)當前查詢表達式需要被擴展時,系統會從離線生成的索引系統中快速獲取需要添加的信息(即候選屬性值),然后根據新的查詢表達式用XSeek輸出結果;
(4)對于每一個查詢,系統輸出結果的同時會按照設定記錄該查詢的相關內容。
離線部分主要工作為:保存XML文檔和查詢日志,查詢日志統計分析和更新日志等信息。
值索引主要負責按照文檔順序存儲和關鍵字匹配的各個節點的Dewey編碼,以快速獲得和關鍵字匹配的節點,該索引類似于倒排索引。
當給定一個Dewey編碼時,Dewey索引負責提供給系統該節點的“入口”,包括該節點的名稱、孩子節點的數目、指向孩子節點和父親節點的指針以及該節點的類型(實體節點或屬性節點或值節點)。因為系統會經常遍歷連續的Dewey編碼,而B+樹的結構能夠改進局部地區數據檢索較為集中情況下的效率,所以Dewey索引通過B+樹的形式實現。
7 實驗結果與分析
7.1 實驗設置
實驗運行在一臺操作系統是64位Windows 7企業版的計算機上,CPU為Intel i5 2.50 GHz處理器,物理內存為8.0 GB。實驗中的XML文檔均來自于文獻[16]:關于UWM大學課程信息和關于eBay在線物品拍賣交易的數據。
將本文方法與XSeek和基于語義詞典的查詢擴展[5]方法進行比較,包括查準率、查全率和 F度量值[17]。
7.2 查詢質量對比
實驗首先用XSeek方法生成系統,以用戶一個月內用該系統產生的4 982條記錄作為日志進行分析統計工作。
對于評價查詢的效果,最終用戶通常最有發言權。因此,邀請5位志愿者參與到實驗評估中。由于XML數據查詢結果信息的主要載體是屬性名稱和其屬性值,因此對于XML關鍵字查詢,查詢結果是否能滿足查詢需求就是判斷其感興趣的屬性是否出現在結果中。為了引導他們為每個查詢結果定義一個可用于評估的基準,該5位用戶獲悉了2個數據集所有的屬性名稱和其相關的語義。除此之外,他們并不知曉DTD和屬性層次分布等信息,從而保證實驗的真實性與可靠性。這些用戶為每個數據集提供了5個查詢測試用例,如表1所示。限于篇幅,表2、表3顯示了部分查詢測試用例使用本文方法后擴展的查詢表達式以及用戶給出的查詢意圖。

表1 查詢測試用例

表2 原始查詢與擴展查詢

表3 QA1和QA4查詢
7.2.1 查準率與查全率
查準率與查全率的計算方法如式(3)和式(4)所示:


表4顯示了查準率實驗數據。對于QA1,本文方法的查準率遠低于XSeek方法,可以發現原因是QA1想查找滿足條件 SellerName為 wenaxion的SellerRating屬性值,可猜測該用戶只對該屬性內容感興趣。在這種情況下,對實體SellerInfo的擴展是多余的,因此,導致了本文方法對于QA2查準率數值偏低。而對于和QA1相似的查詢QA2,可判斷QA2的查詢意圖是尋找售賣Sony電腦的賣家Mary的相關信息。對于QA2,本文查詢擴展添加的屬性多數都是和查詢相關的,所以本文方法對于QA2的查準率比QA1高的多。從表4可知,在多數情況下本文方法的查準率與XSeek、基于語義詞典的查詢擴展方法較接近。

表4 查準率結果對比
表5顯示了查全率實驗數據。對于QA2,XSeek方法產生的結果僅限于LCA子樹。由上文分析可知,該查詢意圖顯然不止該子樹,而本文方法的查全率數據明顯較優。從表5可以發現,本文方法在查全率方面優于XSeek和基于語義詞典的查詢擴展方法,說明了本文方法對于改進查詢質量的有效性。

表5 查全率結果對比
7.2.2 F度量值
為同時考慮查全率和查準率,使用F度量值作為查詢質量評價的標準,計算方法如下所示:
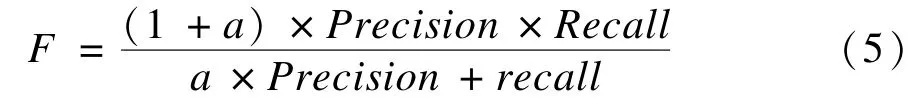
其中,a用于衡量兩者的權重。如果a=1則認為兩者同樣重要;如果a=0.5,則認為查準率更重要;如果a=2,則認為查全率更加重要。本文認為兩者同樣重要,因此a=1。
表6顯示了F度量值實驗數據。基于語義詞典的查詢擴展方法由于其擴展詞來源過度依賴知識庫,而忽略了用戶查詢用詞與XML文檔間的語義聯系,因此其查準率、查全率和F度量值均未優于本文方法。綜合衡量所有查詢測試用例的查全率和查準率實驗數據,可以發現,本文方法在多數情況下都要優于XSeek方法,由此證明本文方法的有效性。

表6 F度量值結果對比
8 結束語
本文重點研究了如何通過查詢表達式擴展的方法改進XML關鍵字查詢技術。通過擴展查詢表達以及添加查詢表達式的上下文信息,實現本文方法,并對查詢日志進行數據挖掘,減少了表達式擴展方法對知識庫或初檢結果的依賴。實驗結果表明,本文方法對查詢質量,尤其是查全率和F度量值,起到了一定的優化作用。今后將考慮如何更加準確地判斷查詢意圖和解決LCA查詢語義二重性問題,使本文方法具有更好的普適性。
[1] Vagelis H,Nick K,Yannis P,et al.Keyword Proximity Search inXML Tree[J].IEEE Transactionson Knowledge and DataEngineering,2006,18(4): 525-539.
[2] Xu Yu,Papakonstantinou Y.Efficient Keyword Search for Smallest LCAs in XML Databases[C]//Proceedings of 2005 ACM InternationalConferenceonSpecial Interest Group on Management of Data.New York, USA:ACM Press,2005:529-538.
[3] Liu Zhiyang,ChenYi.IdentifyingMeaningfulReturn Information for XML Keyword Search[C]//Proceedings of 2007 ACM International Conference on Special Interest Group on Management of Data.New York,USA:ACM Press,2007:329-340.
[4] Snasel V,Moravec P,Pokorny J.WordNet Ontology Based Model for Web Retrieval[C]//Proceedings of 2005 International Workshop on Challenges in Web Information Retrieval and Integration.[S.l.]:IEEE Computer Society,2005:220-225.
[5] 王水利,黃廣君,霍亞格.基于語義分析的查詢擴展方法[J].計算機工程,2011,37(16):77-79.
[6] Cui Han,Wen Jirong,Nie Jianyun,et al.Probabilistic Query Expansion Using Query Logs[C]//Proceedings of the 11th International Conference on World Wide Web.New York,USA:ACM Press,2002:325-332.
[7] Chirita P A,Firan C S,Nejdl W.Personalized Query Expansion for the Web[C]//Proceedings of the 30th International Conference on ACM Special Interest Group on Information Retrieval.New York,USA:ACM Press, 2007:7-14.
[8] Xu J,Croft W.Improving the Effectiveness of Information Retrieval with Local Context Analysis[J]. ACM Transactions on Information Systems,2000,18 (1):79-112.
[9] Ricardo Y B,Berthier N R.Modern Information Retrieval[M].[S.l.]:Pearson Education Limited, 1999:16-65.
[10] Qiu Yonggang,Frei H.Concept Based Query Expansion [C]//Proceedings of the 16th International Conference on ACM SpecialInterestGroup on Information Retrieval.New York,USA:ACM Press,1993:160-169.
[11] Liu Ziyang,NatarajanS,ChenY.QueryExpansion Based on Clustered Results[J].Proceedings of the VLDB Endowment,2011,4(6):350-361.
[12] Bao Zhifeng,Ling T W,Chen Bo,et al.Effective XML Keyword Search with RelevanceOriented Ranking [C]//Proceedings of 2009 IEEE International Conference on Data Engineering.Washington D.C., USA:IEEE Computer Society,2009:517-528.
[13] Chauduri S,Das G,Hristidis V,et al.Probabilistic Ranking of Database Query Results[C]//Proceedings of the 30th International Conference on Very Large Data Bases.[S.l.]:ACM Press,2004:888-899.
[14] Paik J H.A NovelTF-IDF WeightingSchemafor Effective Ranking[C]//Proceedings of the 36th International Conference on ACM Special Interest Group on Information Retrieval.New York,USA:ACM Press, 2013:343-352.
[15] Helmer S.Measuring the Structural Similarity of Semistructured Documents Using Entropy[J].The VLDB Journal,2012,21(5):1022-1032.
[16] UW XML Data Repository[EB/OL].(2012-05-17). http://www.cs.washington.edu/research/xmldatasets.
[17] Croft B,Metzler D.Search Engines:Information Retrieval in Practice[M].[S.l.]:Addison-Wesley,2009:286-287.
編輯 陸燕菲
XML Keyword Search Based on Extended Query Expression
ZHU Jing-hua,WANG Xiao-ling
(School of Computer Science,Fudan University,Shanghai 200433,China)
Most existing eXtensible Markup Language(XML)keyword searches are based on Lowest Common Ancestor(LCA)semantics tree to generate search result,but they do not consider the data which is not included in LCA semantics tree while is relevant with user search intention.To solve this problem,an XML keyword query method based on extended query expression is proposed.The query expansion statistical model is based on user query log.Through analyzing query log and combined with optimal retrieval concept,it can judge whether the query expression should be expanded.After that,an XML TF-IDF method is employed to calculate the weight of candidate attribute.According to the context information and using cluster method,it gets the query expression keywords which are most relevant with search intention.Then the expanded query expression is generated.Compared with XSeek and semantics dictionary based query expression method,experimental result shows this method can improve the query quality by average 7%and 17%in F-measure respectively.
information retrieval;eXtensive Markup Language(XML);Lowest Common Ancestor(LCA)semantic; keyword search;query expansion;context information
1000-3428(2014)10-0025-07
A
TP391
10.3969/j.issn.1000-3428.2014.10.006
國家自然科學基金資助項目(60773075)。
朱菁華(1985-),男,碩士研究生,主研方向:XML信息檢索,數據庫技術;王曉玲,教授、博士。
2013-11-05
2013-11-27E-mail:jh_zhu@fudan.edu.cn
中文引用格式:朱菁華,王曉玲.基于擴展查詢表達式的XML關鍵字查詢[J].計算機工程,2014,40(10):25-31.
英文引用格式:Zhu Jinghua,Wang Xiaoling.XML Keyword Search Based on Extended Query Expression[J]. Computer Engineering,2014,40(10):25-31.
猜你喜歡
開放教育研究(2020年2期)2020-03-31 01:54:14
兒童故事畫報(2019年5期)2019-05-26 14:26:14
現代語文(2016年21期)2016-05-25 13:13:44
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
大連民族大學學報(2015年2期)2015-02-27 08:28:11
當代修辭學(2011年6期)2011-01-29 02:49:50
外語學刊(2011年1期)2011-01-22 03:38:33
