聯合時空特征的視頻分塊壓縮感知重構
2014-05-29 10:00:46干宗良崔子冠武明虎朱秀昌
電子與信息學報 2014年2期
關鍵詞:模型
李 然 干宗良 崔子冠 武明虎 朱秀昌
?
聯合時空特征的視頻分塊壓縮感知重構
李 然 干宗良 崔子冠 武明虎 朱秀昌*
(南京郵電大學江蘇省圖像處理與圖像通信重點實驗室 南京 210003)
為了提高視頻壓縮感知(CS)重構算法的率失真性能,該文提出利用視頻的時空特征進行聯合重構。為了不引入過多的復雜度,采集端以固定采樣率對幀內各塊進行測量;重構端則在最小全變差(TV)重構模型的基礎上,分別加入利用時空自回歸(AR)模型和多假設(MH)模型所形成的正則化項,以提高預測-殘差重構的性能。另外,考慮到視頻源的統計特性在時空域中是動態變化的,討論了5種不同的幀間預測模式對重構精度和重構計算復雜度的影響。仿真實驗表明,所提出的重構算法能夠以一定的計算復雜度為代價有效地改善視頻重構質量,且在關鍵幀采樣率高于非關鍵幀的情形下,幀間預測模式的改善也可一定程度上提高視頻重構質量。
壓縮感知;視頻重構;最小全變差;時空自回歸;多假設;預測-殘差重構
1 引言
壓縮感知(Compressed Sensing, CS)旨在以欠奈奎斯特(Sub-Nyquist)速率采樣信號,以降維方式實現在采樣信號的同時壓縮信號[1]。該理論表明,具有一定結構性的信號(例如,變換系數是稀疏或可壓縮的)可從少量隨機測量值中以極大概率無失真恢復原始信號[2,3]。將CS理論應用到圖像和視頻信號采集上可大大減少傳感器的數量,從而實現低成本、低能耗和低計算復雜度的數據采集。

考慮到計算復雜度,視頻壓縮感知采集端應盡量簡單。本文方法仍以固定采樣率測量幀內各塊,僅在接受端加入適當的正則化項來提高預測精度,從而改善預測-殘差重構的率失真性能。根據視頻信號的時空特征,分別將基于像素的時空AR模型和基于塊的MH模型與全變差(Total Variation, TV)模型相結合,形成兩種不同的聯合時空特征的預測-殘差重構模型,這兩種模型均能有效利用視頻信號的時間和空間相關性,提高視頻重構質量。另外,由于幀間統計相關特性隨時間變化,本文也討論了5種幀間預測模式對視頻重構質量和計算復雜度的影響。仿真實驗表明,本文提出的兩種算法均能以一定的計算復雜度為代價換取率失真性能的提高,而幀間預測模式的改善進一步提高了視頻重構的質量。
2 圖像分塊壓縮感知的全局重構模型
文獻[7]提出的BCS首先將I×I個像素的圖像分成個尺寸為×的塊,第個塊的列向量形式記為,然后使用相同的高斯隨機測量矩陣對進行測量,得到相應長度為M的觀測值向量,上述過程可記為

由式(1)可看出,觀測值向量并不是對整幅圖像作CS測量得到的,而是由各圖像塊相應的觀測值向量按列組合而成,因此接收端無法一次重構整幅圖像,而是獨立地重構各圖像塊。這種局部重構方式割裂了圖像的空間特征,導致了塊效應等問題。為了克服該缺陷,文獻[18]通過引入排序算子得到式(1)的等價形式如式(2):


其中(,)是圖像的像素坐標,1為垂直方向差分1=(,)–(–1,),2為水平方向差分2=(,) –(,–1)。因此,利用圖像梯度域的稀疏性,圖像CS重構問題可采用最小TV模型求解。

3 聯合時空特征的視頻重構
在重構視頻信號時,除了考慮幀內的空間相關性外,幀間的時間相關性也應被充分利用。時空AR模型能夠很好地描述時空域像素之間的相關性,在幀率提升算法(Frame Rate Up-Conversion, FRUC)和邊信息(Side Information, SI)估計算法中經常使用[19,20];MH模型充分利用了幀間塊與塊的結構相似性,應用到傳統視頻編碼的運動補償(Motion Compensation, MC)中獲得了很好的效果[21]。本文將上述兩種描述時間相關特征的模型分別與描述空間相關特征的TV模型相結合,提出了兩種聯合時空特征的預測-殘差重構模型。
3.1 時空AR模型與TV模型聯合重構
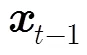
將時空AR模型與TV模型結合,可構造出式(5)所示的當前幀預測模型:

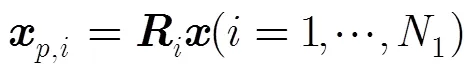
步驟1 初始化:令(0)=SI;設定初始迭代= 1和最大迭代次數maxiter。
步驟2 固定(k),求解:

該式具有閉式解如式(7):


其中為在鄰近幀相對應位置處的半徑為1的搜索窗,為搜索窗中的候選匹配塊,為權衡因子。由于中包含有圖像的全部信息,所以在式(8)中第1項較為重要,本文中值取為0.3。

該式的等價形式為
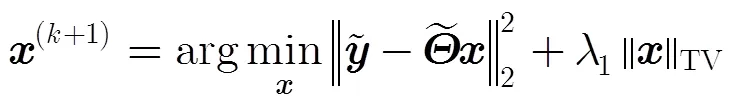
其中
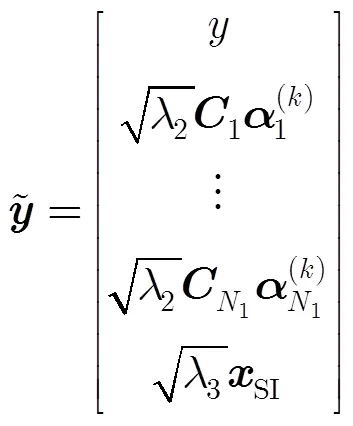
可使用TVAL3工具箱[23]求解式(10),需要注意的是,在該工具箱中需要設定的參數反比于正則化參數。
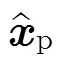


其中為當前幀的殘差幀。
3.2 MH模型與TV模型聯合重構
如圖2所示,在MH模型中,當前幀的每一個塊B,m可由鄰近幀相對應位置處的半徑為2的搜索窗內所有候選塊線性加權估計。與時空AR模型類似,MH模型也可分為P幀情形(圖2(a))和B幀情形(圖2(b))。
將MH模型與TV模型結合,可構造出如式(13)所示的當前幀預測模型:
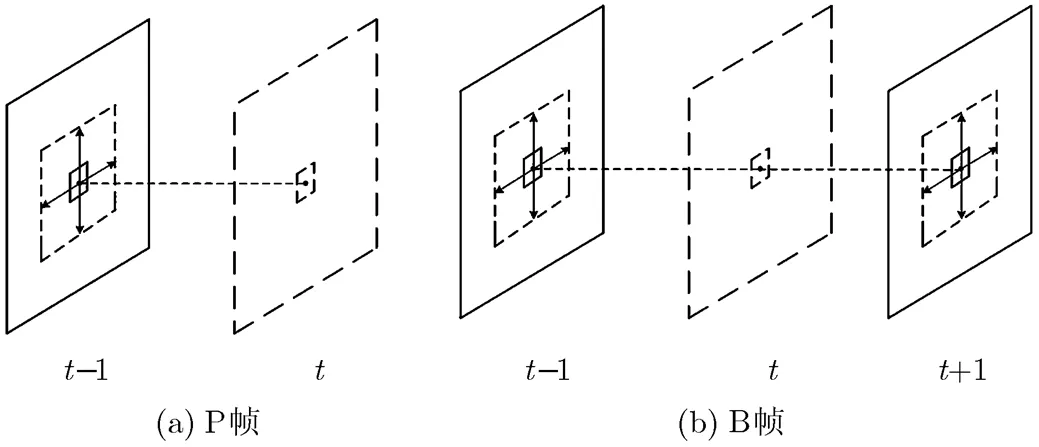
圖2 MH模型

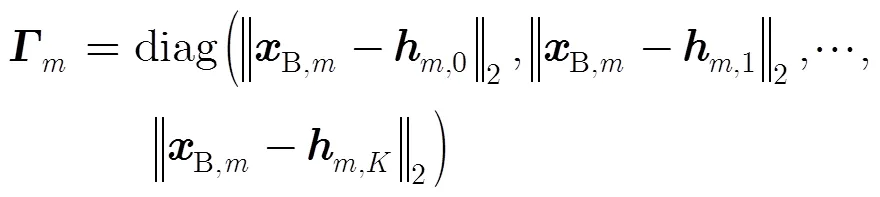

步驟1 初始化:令(0)=SI;設定初始迭代= 1和最大迭代次數maxiter。

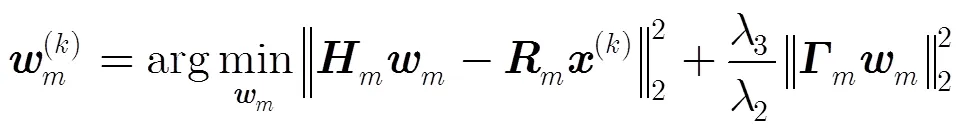
該式具有閉式解如式(16):


與時空AR模型相似,式(17)仍可等價為與式(10)相同的形式并采用TVAL3工具箱求解,不再贅述。
考慮計算復雜度,最大迭代次數maxiter設為3。與時空AR模型相同,重構殘差使用BCS-SPL- DDWT算法。
3.3 幀間預測模式
在預測-殘差重構模型中,視頻信號首先會被劃分為若干個長度為的圖片組(Group Of Pictures, GOP),接著對它們分別采樣和重構,最后合并成整個視頻信號。每組GOP均由關鍵幀和非關鍵幀組成:關鍵幀以較高的采樣率進行測量,而非關鍵幀則以較低的采樣率測量。由于關鍵幀采樣率較高,因此可采用靜止圖像CS算法進行重構,也稱之為I幀。然而,低采樣率的非關鍵幀必須通過參考相鄰幀才可達到與關鍵幀可比的重構質量:若僅參考前一重構幀,則稱之P幀;若參考前后兩重構幀,則稱之B幀。由于視頻源的統計特性在時空域中是動態變化的,所以不同幀間預測模式會對視頻重構質量造成一定影響。文獻[14]提出了兩種單向幀間預測模型(如圖3(a), 3(b)所示),雖然能夠滿足實時的視頻采集和重構,但并未引入B幀。適當地插入B幀,雖然會使視頻系統喪失實時性,但也能夠提升一定的重構精度。文獻[24]討論的多視點視頻的預測模式提出3種加入B幀的幀間預測模式(以= 4為例),如圖3(c), 3(d), 3(e)所示。

圖3 5種幀間預測模式(方框右上角數字為預測順序)
雙向預測模式在連續兩個I幀中全部插入B幀,該模式充分利用了前后幀的相關特性,能夠提升一定的重構精度,但是B幀的重構計算復雜度過高,為了適當地減少計算復雜度,將其中兩個B幀替換成P幀,形成混合預測模式。在混合預測模式1中,考慮到采樣率較高的I幀,其重構質量較好,所以B幀參考前后I幀進行重構。然而,考慮到B幀與I幀間隔較遠,時間相關性減弱,所以混合預測模式2中的B幀使用前后P幀進行重構。5種幀間預測模式的優劣,將在第4.2節結合實驗數據進行分析。
4 實驗結果與分析
采用3組格式為CIF的標準視頻序列Foreman, Mobile和Football的前21幀(GOP的長度= 4,共5組GOP)分別測試本文提出的算法和幀間預測模式的性能。每個GOP的關鍵幀(I幀)采用文獻[10]提出的BCS框架下基于MH預測的SPL(MH-BCS- SPL)算法進行獨立幀內重構;對于非關鍵幀,采用3種對比算法與本文算法進行比較,它們分別是文獻[13]提出的分布式壓縮視頻感知(DIStributed Compressed Video Sensing, DISCVS)框架下的重構算法,文獻[14]提出的BCS框架下基于MC的SPL (MC-BCS-SPL)算法和文獻[15]提出的多假設預測-殘差重構(Multi-Hypothesis Prediction-Residual Reconstruction, MHPR)算法。所有算法的分塊尺寸=16,關鍵幀和非關鍵幀的采樣率分別用K和NK表示,所提出的兩種算法的參數設置如下:
(1)時空AR模型與TV模型聯合重構(AR+ TV):鄰域半徑= 1;,i的尺寸=/2;搜索窗半徑1=;正則化因子和分別取0.2和0.1;TVAL3的設定參數取為28。
(2)MH模型與TV模型聯合重構(MH+TV):Bm的尺寸=;搜索窗半徑2=;正則化因子和分別取0.1和0.01; TVAL3的設定參數取為28。
評價性能的指標分別為可反映客觀質量的峰值信噪比(Peak Signal-Noise Ratio, PSNR),可反映主觀視覺質量的結構相似性指數[25](Structural SIMilarity, SSIM)和可反映計算復雜度的重構時間。實驗的硬件平臺為主頻3.20 GHz的酷睿i5 CPU計算機,軟件平臺為Windows 7 64位操作系統和Matlab 7.6仿真實驗軟件。
4.1 本文算法的性能分析
4.2 幀間預測模式的性能分析
表2列出了各幀間預測模式下所有算法重構出不同視頻序列的平均PSNR值,SSIM值和重構時間。表2表明當K與NK均取0.3時,各種預測模式重構視頻質量相差無幾,性能最好的雙向預測模式的PSNR值僅比最差的單向預測模式1高了0.5 dB,這說明在關鍵幀與非關鍵幀采樣率相同的情形下,通過改變幀間預測模式并不能有效地改善重構視頻的質量,原因在于關鍵幀的重構質量較差,導致非關鍵幀無法依靠關鍵幀提高重構質量。當K= 0.7,NK= 0.3時,可看到重構視頻序列的平均PSNR值和SSIM值均得到了大幅提高,且性能最好的雙向預測模式的PSNR值比最差的單向預測模式1高出0.7~1.7 dB,這說明在關鍵幀采樣率高于非關鍵幀的情形下,幀間預測模式的改善可提高視頻重構質量。在所有預測模式中,可看出單向預測模式1的重構質量最差,但其計算復雜度低,所需的重構時間短;單向預測模式2的重構質量略優于單向預測模式1,但由于重構GOP組的中心幀時需要重構2次取平均,導致其重構時間最長;雙向預測模式中的非關鍵幀均為B幀,因此其重構精度最高,但B幀過多使得其計算復雜度較高;與雙向預測模式相比,混合預測模式1和混合預測模式2均縮短了一定的重構時間,但重構視頻質量有所下降;比較混合預測模式1與混合預測模式2,對于運動較慢的視頻序列Foreman和Mobile,其重構視頻的質量基本相同,然而,對于包含快速運動的視頻序列Football,混合預測模式2重構視頻質量高于混合預測模式1,其PSNR增益為0.3 dB,這說明對于快速運動的視頻序列,時間相關性更為重要。

圖4 SK = 0.7, SNK = 0.3時,Foreman視頻第2幀的重構結果(局部放大)
表1幀間預測模式為混合預測模式1時,不同采樣率下各種視頻重構算法的性能比較:PSNR(dB)/SSIM/重構時間(s)

重構算法SNK(SK = SNK) 0.10.30.5平均 Foreman DISCOS27.7/0.769/14.333.3/0.881/15.037.0/0.936/13.832.7/0.862/14.4 MC-BCS-SPL28.2/0.817/47.533.9/0.915/37.437.6/0.959/28.733.2/0.897/37.9 MHPR28.3/0.826/13.334.1/0.928/14.137.5/0.957/12.733.3/0.904/13.4 AR+TV28.6/0.831/49.034.8/0.934/54.738.3/0.965/57.033.9/0.910/53.6 MH+TV28.9/0.843/45.235.0/0.939/46.038.6/0.968/44.834.2/0.917/45.3 Mobile DISCOS16.5/0.303/10.221.5/0.639/13.126.4/0.819/13.821.5/0.587/12.4 MC-BCS-SPL17.4/0.395/40.022.8/0.735/28.427.3/0.866/25.822.5/0.665/31.4 MHPR17.2/0.389/8.722.9/0.736/12.227.3/0.874/11.422.5/0.666/10.8 AR+TV17.8/0.420/47.423.2/0.745/55.827.9/0.887/61.423.0/0.684/54.9 MH+TV17.9/0.427/41.323.3/0.752/45.528.1/0.892/45.123.1/0.690/44.0 Football DISCOS21.3/0.485/12.026.7/0.737/13.630.7/0.859/13.426.2/0.694/13.0 MC-BCS-SPL22.1/0.568/54.128.1/0.815/42.932.6/0.918/31.027.6/0.767/42.7 MHPR22.3/0.593/9.728.2/0.818/11.631.5/0.903/11.027.3/0.771/10.8 AR+TV22.6/0.604/48.428.8/0.843/56.232.6/0.919/59.828.0/0.789/54.8 MH+TV22.8/0.616/42.929.1/0.852/45.533.1/0.926/44.928.3/0.798/44.4 重構算法SNK(SK =0.7) 0.10.30.5平均 Foreman DISCOS34.7/0.906/10.236.6/0.927/10.038.4/0.948/10.636.6/0.927/10.3 MC-BCS-SPL34.2/0.914/40.737.2/0.932/31.739.2/0.957/25.236.9/0.934/32.5 MHPR35.9/0.919/8.938.3/0.951/9.339.6/0.968/9.137.9/0.946/9.1 AR+TV36.2/0.939/44.538.9/0.964/49.440.5/0.974/53.938.5/0.959/49.3 MH+TV36.4/0.943/40.839.2/0.967/41.440.9/0.976/44.838.8/0.962/42.3 Mobile DISCOS25.0/0.796/14.827.5/0.853/14.929.3/0.887/15.427.3/0.845/18.4 MC-BCS-SPL24.5/0.796/47.728.2/0.896/33.830.4/0.921/29.027.7/0.871/36.8 MHPR25.3/0.822/12.828.4/0.903/12.930.5/0.933/13.028.1/0.886/12.9 AR+TV25.9/0.842/52.429.0/0.910/57.030.9/0.935/63.328.6/0.896/57.6 MH+TV26.0/0.848/46.829.2/0.916/48.431.1/0.940/47.628.8/0.901/47.6 Football DISCOS27.3/0.741/13.429.9/0.823/13.532.3/0.888/13.929.8/0.817/13.6 MC-BCS-SPL27.1/0.770/58.631.5/0.892/43.834.2/0.942/32.130.9/0.868/44.8 MHPR28.4/0.814/11.131.8/0.897/11.333.5/0.934/11.431.2/0.882/11.3 AR+TV28.8/0.824/47.332.2/0.911/53.934.3/0.942/59.431.8/0.892/53.5 MH+TV29.0/0.831/44.532.5/0.918/46.234.9/0.949/45.232.1/0.899/45.3

預測模式SK = SNK = 0.3 ForemanMobileFootball 單向預測模式134.1/0.917/27.222.7/0.717/25.028.1/0.806/27.7 單向預測模式234.3/0.921/78.022.8/0.722/74.828.5/0.821/83.9 雙向預測模式34.6/0.925/44.223.3/0.746/41.028.6/0.823/46.1 混合預測模式134.2/0.919/33.422.7/0.721/31.028.2/0.813/34.0 混合預測模式234.3/0.920/32.522.7/0.721/30.428.4/0.820/33.4 預測模式SK =0.7, SNK = 0.3 ForemanMobileFootball 單向預測模式137.4/0.940/22.127.3/0.864/27.131.3/0.874/27.4 單向預測模式238.0/0.946/72.128.1/0.888/78.531.9/0.893/84.7 雙向預測模式38.5/0.952/39.229.0/0.907/44.332.0/0.895/46.1 混合預測模式138.0/0.948/28.428.5/0.896/33.431.6/0.888/33.7 混合預測模式238.0/0.947/27.828.3/0.890/32.631.9/0.893/33.7
5 結束語
本文分別將基于像素的時空AR模型和基于塊的MH模型與TV模型相結合,提出了兩種聯合時空特征的預測-殘差視頻壓縮感知重構算法。為了避免不必要的計算復雜度,采集端以固定采樣率測量幀內各塊;重構端則在最小TV重構模型的基礎上,通過分別加入利用時空AR模型與MH模型所形成的正則化項來提高視頻的預測精度。另外,考慮到視頻源的統計特性在時空域中動態變化的特點,討論了5種不同的幀間預測模式對重構精度和重構計算復雜度的影響。仿真實驗表明,本文提出的聯合時空特征的重構算法能夠以一定的計算復雜度為代價有效地改善視頻重構質量,且在關鍵幀采樣率高于非關鍵幀的情形下,幀間預測模式的改善也可一定程度上提高視頻重構質量。
[1] Eldar Y C and Kutyniok G. Compressed Sensing: Theory and Applications[M]. Cambridge: Cambridge University Press, 2012: 1-5.
[2] Candes E J, Romberg J, and Tao T. Stable signal recovery from incomplete and inaccurate measurements[J]., 2006, 59(8): 1207-1223.
[3] Baraniuk R C, Cevher V, Duarte M F,.. Model-based compressive sensing[J]., 2010, 56(4): 1982-2001.
[4] Oechard G, Zhang J, Suo Y,.. Real time compressive sensing video reconstruction in hardware[J]., 2012, 2(3): 604-614.
[5] Holloway J, Sankaranarayanan A C, Veeraraghavan, A,.. Flutter shutter video camera for compressive of videos[C]. IEEE International Conference on Computational Photography, Seattle, WA, 2012: 1-9.
[6] Sankaranarayanan A C, Studer C, and Baraniuk R G. CS-MUVI: video compressive sensing for spatial-multiplexing cameras[C]. IEEE International Conference on Computational Photography, Seattle, WA, 2012: 1-10.
[7] Gan L. Block compressed sensing of natural images[C]. International Conference on Digital Signal Processing, Cardiff, UK, 2007: 403-406.
[8] Tramel E W. Distance-weighted regularization for compressed sensing video recovery and supervised hyperspectral classification[D]. [Ph.D. dissertation], Mississippi State University, 2012.
[9] Mun S and Fowler J E. Block compressed sensing of images using directional transforms[C]. International Conference on Image Processing, Cario, Egypt, 2009: 3021-3024.
[10] Chen C, Tramel E W, and Fowler J E. Compressed sensing recovery of images and video using multihypothesis predictions[C]. Conference Record of the 46th Asilomar Conference, Pracific Grove, CA, 2011: 1193-1198.
[11] Chartrand R. Nonconvex splitting for regularized low-rank + sparse decomposition[J]., 2012, 60(11): 5810-5819.
[12] Shu X and Ahuja N. Imaging via three-dimensional compressive sampling (3DCS)[C]. IEEE International Conference on Computer Vision, Barcelona, 2011: 439-446.
[13] Do T T, Chen Y, Nguyen D T,.. Distributed compressed video sensing[C]. IEEE International Conference on Image Processing, Cario, Egypt, 2009: 1393-1396.
[14] Mun S and Fowler J E. Residual reconstruction for block- based compressed sensing of video[C]. Data Compression Conference, Snowbird, UT, 2011: 183-192.
[15] Tramel E W and Fowler J E. Video compressed sensing with multihypothesis[C]. Data Compression Conference, Snowbird, UT, 2011: 193-202.
[16] 李星秀, 韋志輝. 基于局部自回歸模型的壓縮感知視頻圖像遞歸重建算法[J]. 電子學報, 2012, 40(9): 1795-1800.
Li Xing-xiu and Wei Zhi-hui. Compressed sensing video images recursive reconstruction algorithm based on local autoregressive model[J]., 2012, 40(9): 1795-1800.
[17] 練秋生, 田天, 陳書貞, 等. 基于變采樣率的多假設預測分塊視頻壓縮感知[J]. 電子與信息學報, 2013, 35(1): 203-208.
Lian Qiu-sheng, Tian Tian, Chen Shu-zhen,.. Block compressed sensing of video based on variable sampling rates and multihypothesis predictions[J].&, 2013, 35(1): 203-208.
[18] 李然, 干宗良, 朱秀昌. 基于分塊壓縮感知的圖像全局重構模型[J]. 信號處理, 2012, 28(10): 1416-1422.
Li Ran, Gan Zong-liang, and Zhu Xiu-chang. A global reconstruction model of images using block compressed sensing[J]., 2012, 28(10): 1416-1422.
[19] Zhang Y, Zhao D, Ma S,.. A motion-aligned auto- regressive model for frame rate up conversion[J]., 2010, 19(5): 1248-1258.
[20] Zhang Y, Zhao D, Liu H,.. Side information generation with auto regressive model for low-delay distributed video coding[J].&, 2012, 23(1): 229-236.
[21] Sullivan G J. Multi-hypothesis motion compensation for low bit-rate video coding[C]. International Conference on Acoustics, Speech and Signal Processing, Minneapolis MN, 1993: 437-440.
[22] Elad M and Aharon M. Image denoising via sparse and redundant representations over learned dictionaries[J]., 2006, 15(12): 3736-3745.
[23] Li Cheng-bo, Yin W, and Zhang Yin. TV minimization by augmented Lagrangian and alternating direction algorithms [OL]. www.caam.rice.edu/~optimization/L1/ TVAL3/, 2010, 12.
[24] Merkle P, Smolic A, Muller K,.. Efficient prediction structures for multiview video coding[J]., 2007, 17(11): 1461-1473.
[25] Wang Z, Bovik A C, Sheikh H R,.. Image quality assessment: from error visibility to structural similarity[J]., 2004, 13(4): 600-611.
李 然: 男,1988年生,博士生,研究方向為圖像處理與多媒體通信.
干宗良: 男,1979年生,講師,研究方向為分布式視頻編碼、圖像(視頻)信號處理.
崔子冠: 男,1982年生,講師,研究方向為視頻編碼.
武明虎: 男,1975年生,博士生,研究方向為分布式視頻編碼、多媒體通信、信息安全.
朱秀昌: 男,1947年生,教授,博士生導師,長期從事圖像通信方面的科研和教學工作.
Block Compressed Sensing Reconstruction of Video Combined with Temporal-spatial Characteristics
Li Ran Gan Zong-liang Cui Zi-guan Wu Ming-hu Zhu Xiu-chang
(&,,210003,)
To improve the rate-distortion performance of video Compressed Sensing (CS) reconstruction, the temporal-spatial characteristics of video are used to jointly recover the video signal in this paper. At the collection terminal, each block in a single-frame is measured at the fixed sampling rates to advoid excessive complexity. At the reconstruction terminal, two regularization terms are respectively added to the minimum Total Variation (TV) reconstruction model to advance the performance of prediction-residual reconstruction, and the terms are constructed in terms of temporal-spatial Auto-Regressive (AR) model and Multiple Hypothesis (MH) model. In addition, considering that the statistics of video source are dynamically varying in spatial and temporal domain, it is discussed how the five different inter-prediction modes impact on precision and computational complexity of reconstruction. Simulation results show that the proposed algorithms effectively improve the quality of reconstructed video at the cost of the computational complexity , and the improvement of inter-prediction mode enhances reconstruction quality in some extent.
Compressed Sensing (CS); Video reconstruction; Minimum Total Variation (TV); Temporal-spatial Auto Regressive (AR); Multiple Hypothesis (MH); Prediction-residual reconstruction
TN911.73
A
1009-5896(2014)02-0285-08
10.3724/SP.J.1146.2013.00396
朱秀昌 zhuxc@njupt.edu.cn
2013-03-28收到,2013-07-18改回
國家自然科學基金(61071091, 61271240),江蘇省研究生創新計劃(CXZZ12_0466, CXZZ11_0390),江蘇省高校自然科學研究項目(12KJB510019),南京郵電大學校科研基金(NY212015)和湖北省教育廳科研重點項目(D20121408)資助課題
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
