位置社交網絡的潛在好友推薦模型研究*
2014-02-28 02:06:26孫曉晨徐雅斌
電信科學 2014年10期
孫曉晨,徐雅斌,2
(1.北京信息科技大學計算機學院 北京 100101;2.網絡文化與數字傳播北京市重點實驗室 北京 100101)
1 引言
位置服務(location-based service,LBS)又稱定位服務,是通過GPS(global positioning system,全球定位系統)、WLAN(wireless local area network,無線局域網)等技術獲得移動終端的位置信息(如經緯度坐標數據),并將這些位置信息提供給移動通信用戶及通信系統,實現各種與位置相關的業務。位置服務與傳統在線社交網絡逐漸融合,從而產生了位置社交網站 (location-based online social network,LBSN)。國 外 典 型 的LBSN主 要 有Foursquare、Geolife等,國內發展比較好的LBSN主要有街旁、陌陌等。隨著位置服務的廣泛應用,傳統在線社交網絡也開始引入位置服務,如微博的“微領地”應用。
位置社交網絡不僅可以像傳統在線社交網絡那樣分享博客、照片、視頻進行信息交互,而且可以隨時隨地地定位和分享位置信息[1]。用戶可以通過電腦、手機及其他移動終端進行簽到,并將所處的位置信息及時告訴他的朋友。當簽到信息發生變化時,用戶能通過社交網站進行同步更新,這樣就可以方便快捷地與好友分享自己的最新動態。
位置社交網絡的意義在于分享與位置相關的內容,并借此結識朋友。因此,通過研究和分析位置社交網絡中與位置相關的歷史數據及用戶個人興趣信息,并建立位置社交網絡的潛在好友推薦模型,就可以為用戶推薦一些與他們行為、興趣相似的好友,從而幫助用戶結識更多在實際生活中未曾見面但卻與自己興趣相投的其他用戶,從而更好地發展自己的社交圈。同時,為用戶推薦潛在好友,使用戶體會到社交網絡應用的方便性,從而活躍于社交網絡中,有助于位置社交網絡的健康發展。
2 相關工作
迄今為止,國內外學者在用戶推薦服務方面做了大量工作。參考文獻[2]中根據好友的好友進行潛在用戶推薦,因為用戶的兩個朋友成為好友的概率比隨機兩個人成為好友的概率高。參考文獻[3]和參考文獻[4]都是通過對用戶的軌跡進行建模,以此來分析用戶的軌跡相似度,進而度量用戶之間的相似性。但是它們的建模方法有所不同,參考文獻[3]中的建模方法采用HGSM(hierarchical-graph-based similarity measurement,基于等級結構圖的相似度測量)算法,而參考文獻[4]中的建模方法采用PST(probabilistic suffix tree,概率后綴樹)。參考文獻[5]利用在線社交關系,并利用矩陣分解的方法進行潛在用戶推薦,取得了很好的效果。參考文獻[6]中通過用戶的歷史位置進行建模,可以分析出用戶的行為模式,然后根據用戶行為模式之間的相似性,向用戶推薦潛在好友或進行用戶行為的異常檢測。參考文獻[7]利用用戶的標簽信息和時間信息建立推薦模型,較好地分析了用戶的興趣愛好,具有很好的性能。參考文獻[8]采用改進協同過濾算法對交友網站中的用戶進行網上交友推薦,將交友雙方的興趣和吸引力等因素都考慮到推薦模型中,從而提高推薦效果。
綜合分析發現:參考文獻[1,2,5,7,8]主要是根據傳統的社交關系進行潛在用戶推薦;參考文獻[3,4]利用社交網站中的位置軌跡信息進行潛在用戶推薦;參考文獻[6]則利用社交網站中的歷史位置信息分析用戶的行為模式,然后利用用戶的行為模式相似性進行潛在用戶推薦及行為異常檢測。
考慮用戶簽到歷史信息、用戶影響力等因素,本文提出了一種利用用戶對位置的隱性評價計算用戶之間位置相似度的方法,進行潛在用戶推薦。該方法首先對用戶簽到的位置興趣點進行聚類,得到位置興趣區域;然后利用用戶的好友關系、用戶影響力、簽到特性來計算用戶在各個位置興趣點的位置權重,再利用向量空間模型計算用戶位置相似性及好友相似度;最后根據用戶綜合相似度進行潛在好友推薦。
3 用戶影響力分析與計算
本文對Gowalla、Brightkite等LBSN的簽到數據進行挖掘分析,發現53%左右的LBSN用戶完成了85%的簽到,如圖1所示,而且統計得到1年內35%的用戶簽到次數少于10次,由此可以看出LBSN中存在核心用戶。這些核心用戶在LBSN中處于領導地位,他們在LBSN中很活躍,擁有很多LBSN好友,并且分享位置信息的意愿很強。

圖1 Gowalla和Brightkite簽到數據分析
位置社交網絡的用戶影響力是指用戶在位置社交網絡中對其他用戶的影響和帶動能力。它是用戶在社交網絡中所處重要程度的判斷標準,反映了用戶之間的交互關系和親密程度,同時對社交網絡的發展產生一定的推動力。用戶的影響力越大,別人對他的關注度就越高,對網絡信息的傳播推動作用也就越強。也就是說,在位置社交網絡中如果一個用戶的影響力很高,那么他所推薦的事物(無論是位置信息還是各類網絡廣告、網絡應用)都很容易被傳播,很容易被別人接受。因此,位置社交網絡的用戶影響力是影響推薦服務的重要因素之一。
在LBSN中用戶影響力受到很多因素的影響,其中包括發揮自身影響力的意愿、自身活躍程度、好友數量、好友質量、好友活躍程度等。綜合考慮各方面因素,本文的用戶影響力考慮了用戶自身發揮影響力的意愿和用戶影響度,計算方法如式(1)所示:

其中,Ii表示用戶i的影響力,Ni表示用戶i在時間T內的簽到次數,Ni/T表示用戶發揮自身影響力的意愿,可以理解為:用戶在單位時間內簽到的次數越多,用戶發揮其影響力的意愿就越高。LIR(i)表示用戶的影響度,關于它的計算,借鑒PageRank的思想,其值應介于0和1之間,在包括自身影響度的同時,也要包括其好友對他的影響度,計算方法如式(2)所示:
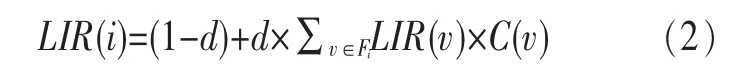
其中,LIR(i)、LIR(v)分別表示用戶i和用戶v的影響力;d是權重系數,表示用戶好友對其影響所占的比重(本文選取0.85);C(v)=Pi/(Pi+Pv),表示用戶v的影響能力分配給用戶u的比例因子,Pi=∑v∈FiNv,Fi是用戶u的好友集合,Nv是用戶v在LBSN中的等級。用戶等級可以通過用戶的簽到次數來衡量,因為在位置社交網站上,如果用戶在某一位置簽到次數最多,那么他會成為這一位置的地主,具有很強的號召力和說服力。將所有LIR的初始值設為0.1,通過迭代到收斂為止,可以得到所有用戶的LIR。該方法涉及的數據隨著用戶數量的不斷增加可以進行增量更新。
4 潛在好友推薦模型
位置社交網絡中的簽到數據包含用戶簽到位置的經度和緯度這一新維度,記錄了用戶訪問的關鍵地點,形成了用戶的離散化行為軌跡。位置社交網絡的用戶行為軌跡由一系列離散的時空點組成,雖然它不像GPS那樣記錄用戶行為的連續軌跡,但是其記錄的離散化軌跡更能體現用戶強烈的目的性。每一個簽到位置對于用戶來說都有一定的意義,能夠表現出用戶的興趣愛好等,同時,每個位置對用戶的重要程度是不一樣的。因此,本文根據用戶之間的位置相似度和好友相似度,計算用戶的綜合相似度,從而進行潛在好友推薦。
根據實際情況可知,用戶的兩個朋友成為好友的概率比隨機兩個人成為好友的概率要高,同時,相近的位置一般屬于同一個區域,因而當用戶訪問相近或相同位置時,他們可能有相似或相同的行為目的。例如,當兩個用戶都經常在雍和宮這類古代寺廟簽到時,說明他們具有一定的相似性或相同性,進而可以進行好友推薦。此外,每個位置對于用戶來說重要程度是不一樣的,如果兩個用戶對于很多位置持有相同的位置權重,那么可以認為他們具有一定的相似度。因此,本文判斷用戶相似性基于幾條經驗,包括:用戶之間擁有共同的好友、用戶具有相同或相似的位置簽到歷史記錄、用戶持有相同位置權重的位置等的數量,這些數量越多,用戶之間的相似度越高。
4.1 位置聚類
在位置社交網絡中,用戶會在自己感興趣的地方進行簽到,每一個簽到位置稱為位置興趣點[9](location point of interest,LPOI)。LPOI中包含位置的唯一標識號、經緯度和名稱,即LPOI=(lcationID,latitude,longitude,name)。用戶在位置興趣點簽到時,位置社交網絡會留下用戶的簽到記錄(checkin),其中包括用戶ID、用戶訪問的LPOI、簽到時間、對位置興趣點的評價或此時的心情,表示為checkin=(userID,LPOI,time,text)。其中,text是可選內容。
因為在某一個實際位置附近可能有很多不同的LPOI,所以在用戶訪問相近位置時可能在不同的LPOI上簽到。如果只是簡單地通過判斷用戶是否訪問同一個LPOI來得到用戶之間的位置相似度,那么這種數據是很稀疏的。因此,本文采用聚類的方法將相近的LPOI聚到同一區域,然后再根據用戶訪問的各個聚類區域,計算用戶之間的位置相似性。利用聚類的方法,可以將用戶經常訪問的LPOI聚集到一塊,而用戶偶爾訪問或很少有人訪問的位置將被視為噪音而過濾掉。
本文采用DBSCAN算法[10,11]對用戶訪問的位置興趣點進行聚類。該算法是一種基于密度的空間聚類算法,與層次聚類方法不同,它將簇定義為密度相連的點的最大集合,能夠把達到一定高密度的區域劃分為簇,并可以在有噪聲的空間數據庫中發現任何形狀的聚類。也就是說,該算法可以將一些高密度的LPOI劃分為簇,并且將LPOI數據庫中的噪聲LPOI排除在外。本文將聚集的LPOI集合定義為位置興趣點區域 (regional point of interest position,RPIP)。
對LPOI的DBSCAN聚類需要給出鄰域ε和minPts兩個對象參數,它們可以根據區域含LPOI的密度來決定。
LPOI的DBSCAN聚類算法描述如下。
(1)輸入LPOI集合L={L1,L2,…,Ln};
(2)通過計算每平方千米含有LPOI的個數,選取適合的鄰域參數ε和聚類簇內最少包含LPOI的個數minPts;
(3)遍歷LPOI整個集合,計算從Li到Lj在平面坐標上的距離,是否滿足密度可達的條件;
(4)若密度可達點的數量大于minPts,則構成一個RPIP;否則,繼續遍歷LPOI集合;
(5)遍歷完LPOI集合,輸出RPIP集合R={R1,R2,…,Rn}。
4.2 位置權重表示
定義1位置權重(position weight)就是用戶對聚類后的位置興趣點區域(RPIP)的重視程度,也可以理解為用戶對RPIP的評分。
在位置社交網絡中,用戶對某一地理位置的重視程度可以用在某位置的簽到次數來衡量,在一定程度上反映了用戶對該位置的興趣,是一種隱式評價。但是不能準確地表示用戶對位置的興趣度,僅表明用戶自身對位置興趣點的評價,忽略了用戶好友對用戶的影響。在位置社交網絡中,用戶在某一位置興趣點簽到不僅要考慮自身的意愿,還要考慮用戶好友對他的影響,因為在現實生活中用戶去一個新位置進行活動時經常會考慮自己好友所給的意見或者好友的經歷。基于此思想,本文給出了計算用戶位置權重的方法。
位置權重用Wij表示,即用戶i在位置j的位置權重,Wij的數值越大則表示位置j對于用戶i越重要,其計算式為:
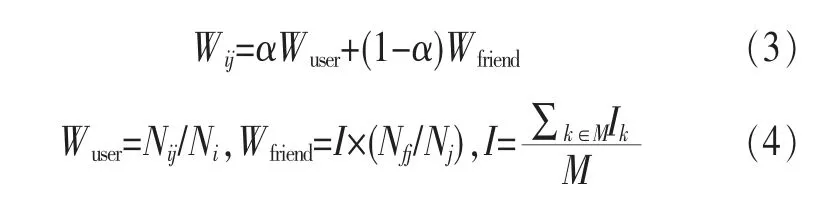
其中,Nij表示用戶i在位置興趣點區域j的簽到次數;Ni表示用戶i在各個位置興趣點區域的總簽到次數;Nfj表示用戶i的朋友f在位置興趣點區域j的總簽到次數;Nj表示所有用戶在位置興趣點區域j的簽到總數;Wuser表示用戶在某一位置興趣點區域的自身位置權重;Wfriend表示用戶的好友在某一位置興趣點區域的位置權重;α是權重因子(本文選擇0.85);I為影響因子,表示用戶的好友對用戶在某位置興趣點區域的平均影響力;Ik表示用戶的朋友k對用戶的影響因子,是用戶好友的影響力,其值通過對式(1)迭代到收斂取得;M表示用戶的好友個數。
4.3 用戶相似度計算
位置社交網絡上包含3種關系:人與人的關系、人與位置的關系及位置之間的關系,這些關系會影響用戶相似度的計算。LBSN用戶之間擁有共同好友,在一定程度上說明用戶之間具有相似度,用戶之間共同好友的個數越多,說明他們越相似;用戶的簽到位置一般會選在自己喜歡的位置或者對自己有意義的位置,位置記錄能夠表現用戶的愛好及行為習慣,因此,簽到位置的相似性也能體現用戶之間的相似度,用戶之間所選擇的簽到位置越相似,他們越相似。綜合以上兩點,本文計算相似度的方法采用兩種相似度的加權之和,如式(5)所示:

其中,SimL表示位置相似度,SimF表示好友相似度,b為加權系數。
4.3.1 位置相似度計算
本文利用空間向量模型計算用戶之間的位置權重相似度,即用戶的位置相似度。向量Li表示用戶在各個位置興趣點區域的位置權重向量,其中Li=[Wi1,Wi2,…,Wij],Wij表示用戶i在位置興趣點區域j的位置權重。用戶之間位置權重相似的位置越多,可以理解為他們的相似度越高,也可以說他們成為好友的可能性越大。所有用戶訪問的位置興趣區域的位置權重構成用戶位置權重矩陣,然后用余弦相似性方法計算用戶之間的相似度。
用戶位置權重矩陣表示為:

其中,m為位置社交網絡的用戶數,n為位置興趣區域的總數,Wij為用戶i在位置興趣點j的位置權重。
把用戶在各個位置興趣區域的位置權重看成n維向量空間上的向量,用向量余弦夾角度量用戶之間的相似度。設用戶X與用戶Y在n維向量空間中表示為WX和WY,通過式(7)計算用戶之間相似度:

4.3.2 好友相似度計算
根據六度分割原理可以知道,通過一定次數的傳遞,人能通過朋友的朋友認識社交網絡中的任何人。因此,兩個用戶具有共同好友,他們成為朋友的概率比兩個沒有任何關系的陌生人成為朋友的概率大。本文利用共同好友比重度量好友相似度,如式(8)所示:

其中,UX為用戶X的好友集合,UY為用戶Y的好友集合。
4.4 產生TopK推薦
根據前文所述,本文分別計算出任意用戶之間位置相似度和好友相似度,再計算用戶的綜合相似度,并根據綜合相似度進行TopK推薦,得到最終的推薦列表。通過位置相似度和好友相似度進行好友推薦可以看成兩個屬性的TopK推薦問題,位置相似度是一個屬性,好友相似性是另一個屬性,通過前文的計算得到各自對應的值,最后綜合計算最優值,從而得到最適合推薦的K個好友。
5 實驗數據與實驗結果
5.1 實驗數據集
本文采用LBSN網站Gowalla的2009-2010年的簽到數據集[12],其中包含640萬條簽到記錄、70萬個簽到位置、19萬個用戶的200萬條好友關系。實際上對位置數據中的無效用戶(即注冊后很少簽到的用戶)和很少有人簽到的位置興趣點(即到訪人數很少的點)進行挖掘是沒有意義的,因此需要對數據進行預處理,移除無意義點,減少數據量。本文將一些很少訪問的位置和具有很少好友的用戶進行清理,清洗過程中設定用戶在規定時間ΔT內的最小簽到頻率Fmin(本文Fmin=1)和最大簽到頻率Fmax(本文Fmax=8),如果用戶簽到頻率小于Fmin,則該用戶的相應數據視為無效;如果用戶簽到頻率大于Fmax,則視為虛假簽到,將其相應的數據進行清除。經過數據清洗后,最終得到2 689個用戶的5萬多條好友關系、135萬多條簽到記錄、23萬多個簽到位置。從所清洗的數據集中隨機選取500個用戶進行實驗研究,這些用戶的平均好友數為20個,平均簽到次數為689次。將所選取的數據集存儲在MySQL數據庫中,建立新的數據庫表,分別為用戶好友表(user_friend)、用戶簽到 表(user_checkin)、RPIP表(location_PRIP)、位置用戶簽到表(location_user),其中用戶好友表記錄用戶的好友,用戶簽到表記錄用戶訪問位置興趣區域,RPIP表記錄每個RPIP具體包含的LPOI,位置用戶表記錄在每個RPIP簽到的用戶。
5.2 方法評測標準
本文的推薦效果由召回率和精確度進行度量[13]。將數據集中的好友關系劃分為訓練集(training set)與測試集(test set),訓練集用于建立潛在好友推薦模型,測試集用于對潛在好友推薦模型進行驗證。L(u)是對訓練集上的用戶做出的推薦列表,即推薦結果,R(u)是測試集上已存在的真實關系。推薦結果可能包括相關結果(relevant result,RR)和 不 相 關 結 果(irrelevant result,IR),即L(u)=RR+IR,其中相關結果就是實際存在的好友關系,不相關結果則是在測試集中不存在的好友關系。測試集中應該包含所有存在的結果,即包括推薦結果中相關結果和未推薦的相關結果(no relevant result,NRR),則R(u)=RR+NRR。
定義2召回率(recall)就是推薦結果中相關結果占好友總數的比重,如式(9)所示:
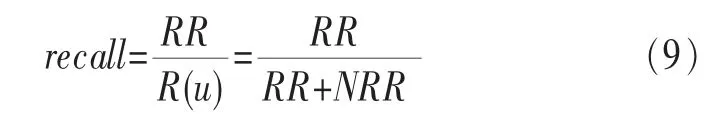
定義3精確度(accuracy)就是推薦結果中相關結果占所有推薦結果的比重,如式(10)所示:
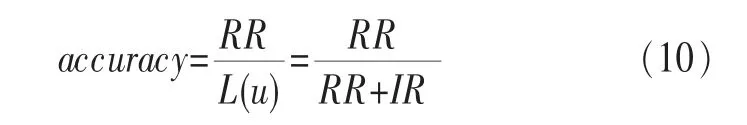
定義4 F指標是一種綜合考慮召回率和精確度的指標,如式(11)所示:
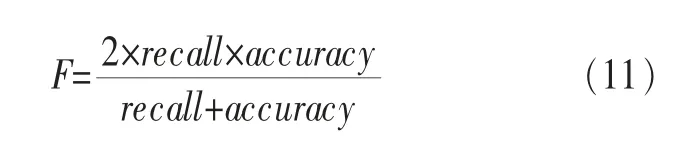
在本文中,如果算法A的召回率和精確度總體高于算法B,認為算法A比算法B具有更高的推薦性能[14]。
5.3 實驗結果及分析
本文根據LPOI的密度,將DBSCAN聚類的鄰域ε取300,minPts取10,圖2為聚類結果中部分RPIP顯示結果,橫縱坐標分別為LPOI的緯度和經度,由圖2可知聚類效果還可以。
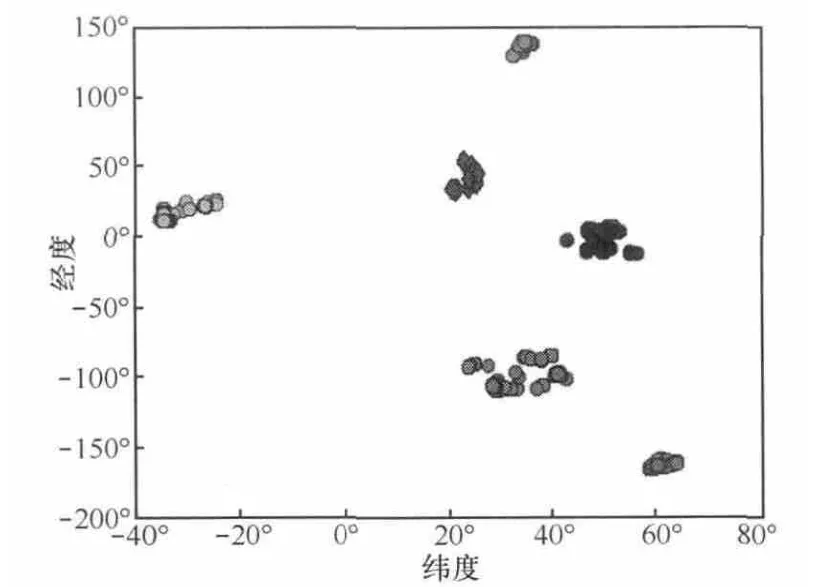
圖2 部分RPIP結果
在本實驗中將數據集的90%作為訓練集,10%作為測試集。式(5)中的系數b∈{0,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1}。當b=0時,推薦方法為只考慮用戶好友相似性,而不考慮用戶的位置簽到信息,所得推薦列表僅與社交網絡好友相似度有關。當b=1時,推薦方法為只考慮位置相似性,所得推薦列表僅與用戶的簽到位置信息有關。其余幾組數據表示綜合考慮用戶好友相似度和用戶位置相似度,這就是本文提出的結合好友相似度和簽到位置相似度的推薦算法。通過上述參數設置,可以對比得出本文算法中好友相似度和位置相似性所占比重對推薦結果產生的影響。推薦列表大小N取值為25,系數b作為橫軸,計算此推薦模型中所有用戶的召回率和精確度,進而計算其平均F指標,如圖3所示。
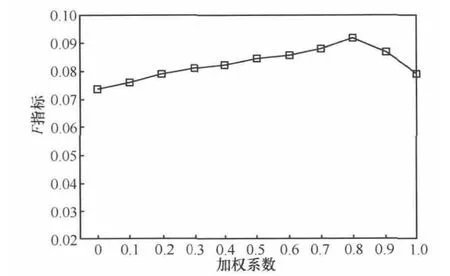
圖3 不同系數下的F指標
F指標綜合考慮了召回率和精確度,其大小可以衡量推薦算法的性能。由圖3可知,完全基于位置相似度的推薦算法(即b=1時)性能要略高于完全基于好友相似度的推薦算法(即b=0時),同時,本文推薦算法的效果隨著系數b的增加而先增加后下降,當b=0.8時本算法的推薦質量最高。
由上述實驗可知:b=0.8時,本推薦方法效果最好,因此以下實驗中取b=0.8。以下為本方法分別與基于Jaccard系數的推薦方法(利用Jaccard系數[15]求位置相似度,從而得到用戶間相似度,再根據用戶間相似度的高低進行潛在好友推薦)和基于好友相似度的推薦方法(簡稱UserRec,其方法是利用第3.3節計算用戶間的相似度,再根據用戶間相似度的高低進行潛在好友推薦)的對比試驗。其中推薦列表個數N分別為3、5、10、15、20、25,其精確度和召回率結果如圖4、圖5所示。通過實驗結果可以看出,本文提出的推薦算法的精確度和召回率比其他兩種方法都高。雖然召回率在N=3和N=5時沒有表現出很好的優越性,但是N>10時開始明顯優于上述其他兩種方法。總體來說,本文推薦方法具有較好的性能。
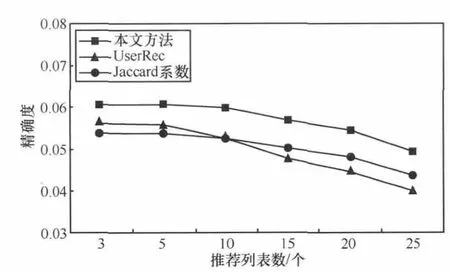
圖4 精確度結果
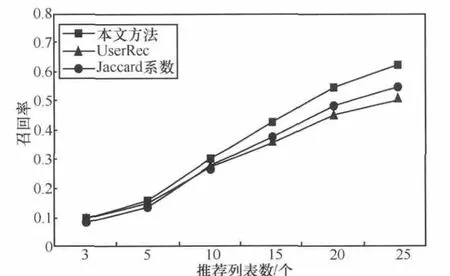
圖5 召回率結果
6 結束語
本文對潛在好友推薦模型進行了研究,旨在主動為用戶提供有效信息,解決信息過載等問題,有效地為用戶推薦合適的潛在好友,更好地發展用戶的社交圈,同時為位置社交網絡的健康發展貢獻一份力量。首先,本文利用基于密度聚類的DBSCAN算法,將各個位置興趣點聚類為不同的位置興趣區域,這樣比只用位置興趣點進行相似度計算更加快捷準確;然后,再計算所有用戶在各個位置興趣區域的位置權重,如果用戶在很多位置興趣區域的位置權重相似,那么用戶之間的相似度就很高;最后,得到用戶間的位置相似度及好友相似度,再對它們進行權重疊加,進而得到潛在好友推薦列表,實現TopK推薦。利用真實數據對潛在好友推薦模型進行實驗驗證,結果表明,本文方法的推薦性能相比基于Jaccard系數的推薦方法和基于社交網絡關系的推薦方法有明顯提高,由此證明了該方法的有效性。
1 翟紅生,于海鵬.在線社交網絡中的位置服務研究進展與趨勢.計算機應用研究,2013,30(11):3221~3227
2 Hruschka D J,Henrich J.Friendship,cliquishness,and the emergence of cooperation.Journal of Theoretical Biology,2006,239(1):1~15
3 Li Q,Zheng Y,Xie X,et al.Mining user similarity based on location history.Proceedings of the 16th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems,New York,USA,2008:31~34
4 Hung C C,Chang C W,Peng W C.Mining trajectory profiles for discovering user communities.Proceedings of the International Workshop on Location Based Social Networks,New York,USA,2009:1~8
5 Ma H,Zhou D,Liu C.Recommender systems with social regularization.Proceedings of the 4th ACM International Conference on Web Search and Data Mining,New York,USA,2011:287~296
6 Zhang D,Li N,Zhou Z H,et al.IBAT:detecting anomalous taxi trajectories from GPS traces.Proceedings of the 13th International Conference on Ubiquitous Computing,New York,USA,2011:99~108
7 Zheng N,Li Q.A recommender system based on tag and time information for social tagging systems.Expert Systems with Applications,2011,38(4):4575~4587
8 Zha o K,Wang X,Yu M,et al.User recommendation in reciprocal and bipartite social networks——a case study of online dating.IEEE Intelligent Systems,2013,17(3):29~30
9 Liu B,Xiong H,Liu B,et al.Point-of-interest recommendation in location based social networks with topic and location awareness.Proceedings of SIAM International Conference on Data Mining,Austin,Texas,USA,2013:396~404
10 邢冬麗,趙美紅,陳文成.基于密度的DBSCAN算法.計算機工程與應用,2007,43(20):216~221
11 Dunham H M.數據挖掘教程.郭崇慧,田鳳占,靳曉明譯.北京:清華大學出版社,2005
12 Cho E,Myers S A,Leskovec J.Friendship and mobility:user movement in location-based social networks.Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,New York,USA,2011:1082~1090
13 Yang T,Cui Y,Jin Y.BPR-UserRec:a personalized user recommendation method in social tagging systems.The Journal of China Universities of Posts and Telecommunications,2013,20(1):122~128
14 Spertus E,Sahami M,Buyukkokten O.Evaluating similarity measures:a large-scale study in the orkut social network.Proceedings of the Eleventh ACM SIGKDD International Conference on Knowledge Discovery in Data Mining,New York,USA,2005:678~684
15 Tan P N,Steinbach M,Kumar V.數據挖掘導論.范明,范宏建譯.北京:人民郵電出版社,2010
猜你喜歡
兒童故事畫報(2019年5期)2019-05-26 14:26:14
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
