基于Spark平臺(tái)的NetFlow流量分析系統(tǒng)
2014-02-28 06:31:14丁圣勇閔世武樊勇兵
電信科學(xué) 2014年10期
丁圣勇,閔世武,樊勇兵
(中國(guó)電信股份有限公司廣東研究院 廣州510630)
1 引言
NetFlow是由Cisco(思科)公司在1996年開發(fā)的內(nèi)置于Cisco IOS的一種網(wǎng)絡(luò)協(xié)議,目的是收集IP流量信息和監(jiān)控網(wǎng)絡(luò)的使用情況。NetFlow被廣泛應(yīng)用于Cisco的路由器和交換機(jī)中,類似技術(shù)也得到Juniper、華為等公司生產(chǎn)的路由器的支持,是網(wǎng)絡(luò)規(guī)劃、運(yùn)營(yíng)和優(yōu)化的重要依據(jù)。從路由器中發(fā)送出來(lái)的NetFlow記錄核心屬性包括源地址、目標(biāo)地址、IP地址類型、源端口號(hào)、目標(biāo)端口號(hào)、報(bào)文大小,本文中的NetFlow泛指能夠支持類似功能的網(wǎng)絡(luò)協(xié)議。
對(duì)于一個(gè)骨干網(wǎng)絡(luò),為了統(tǒng)計(jì)流量模式,需要在所有邊緣路由器入口開啟NetFlow采集,導(dǎo)致NetFlow系統(tǒng)每天需要處理數(shù)十TB甚至上百TB的原始記錄,并且隨著網(wǎng)絡(luò)規(guī)模的不斷擴(kuò)張,系統(tǒng)需要具有接近線性的擴(kuò)展能力。目前大型網(wǎng)絡(luò)一般使用第三方流量分析系統(tǒng),這類系統(tǒng)多采用私有分布式架構(gòu)支持大規(guī)模處理,通過將采集器和分析器分離實(shí)現(xiàn)容量擴(kuò)展。由于價(jià)格昂貴,這類系統(tǒng)在網(wǎng)絡(luò)持續(xù)擴(kuò)容時(shí)面臨較大的成本壓力,此外,開放性也相對(duì)較低,客戶很難實(shí)現(xiàn)特定的分析需求。
另一方面,伴隨著大數(shù)據(jù)技術(shù)的快速發(fā)展,新的分布式平臺(tái)為處理大規(guī)模NetFlow數(shù)據(jù)提供了契機(jī),尤其是Spark技術(shù)的出現(xiàn),大規(guī)模數(shù)據(jù)處理在通用服務(wù)器集群上能夠達(dá)到準(zhǔn)實(shí)時(shí)的性能。本文提出了一種基于Spark平臺(tái)的大規(guī)模NetFlow處理系統(tǒng),通過實(shí)驗(yàn)表明,該系統(tǒng)具有很強(qiáng)的擴(kuò)展能力,性能顯著優(yōu)于Hadoop MapReduce計(jì)算平臺(tái)。
2 Spark技術(shù)介紹
Apache Spark是由UC Berkeley開源的類MapReduce新一代大數(shù)據(jù)分析框架,擁有Hadoop MapReduce的所有優(yōu)點(diǎn),與MapReduce不同的是,Spark將計(jì)算的中間結(jié)果數(shù)據(jù)持久地存儲(chǔ)在內(nèi)存中,通過減少磁盤I/O,使后續(xù)的數(shù)據(jù)運(yùn)算效率更高。Spark的這種架構(gòu)設(shè)計(jì)尤其適合于機(jī)器學(xué)習(xí)、交互式數(shù)據(jù)分析等應(yīng)用,這些應(yīng)用都需要重復(fù)地利用計(jì)算的中間數(shù)據(jù)。在Spark和Hadoop的性能基準(zhǔn)測(cè)試對(duì)比中,運(yùn)行基于內(nèi)存的logistic regression,在迭代次數(shù)相同的情況下,Spark的性能超出Hadoop MapReduce 100倍以上。
Spark在設(shè)計(jì)上參考了Hadoop MapReduce,完全和Hadoop生態(tài)系統(tǒng)相兼容,如Spark底層的數(shù)據(jù)持久化部分就完全重用了Hadoop的文件系統(tǒng),Spark也可以運(yùn)行在Hadoop Yarn資源管理系統(tǒng)上。從大數(shù)據(jù)生態(tài)系統(tǒng)的發(fā)展來(lái)看,Spark的出現(xiàn)不是對(duì)以Hadoop為中心的大數(shù)據(jù)生態(tài)系統(tǒng)的取代,而是補(bǔ)充,更多的是深耕于MapReduce不適用的應(yīng)用領(lǐng)域(如機(jī)器學(xué)習(xí)、流式計(jì)算、實(shí)時(shí)計(jì)算、交互式數(shù)據(jù)挖掘等)。但Spark又不局限于MapReduce簡(jiǎn)單的編程范式,Spark立足于內(nèi)存計(jì)算,同時(shí)在上層支持圖計(jì)算、迭代式計(jì)算、流式計(jì)算、內(nèi)存SQL等多種計(jì)算范式,因此相對(duì)于MapReduce更具有通用性。
為了支持在多次迭代計(jì)算過程中重復(fù)利用內(nèi)存數(shù)據(jù)集,Spark在借鑒傳統(tǒng)分布式共享內(nèi)存思想的基礎(chǔ)上,提出了一種新的數(shù)據(jù)抽象模型RDD(resilient distributed dataset),RDD是只讀、支持容錯(cuò)、可分區(qū)的內(nèi)存分布式數(shù)據(jù)集,可以一部分或者全部緩存在集群內(nèi)存中,以便在多次計(jì)算過程中重用。用戶可以顯式控制RDD的分區(qū)、物化、緩存策略等,同時(shí)RDD提供了一套豐富的編程接口,供用戶操作。RDD是Spark分布式計(jì)算的核心,Spark的所有計(jì)算模式都必須圍繞RDD進(jìn)行。
3 基于Spark的NetFlow流量分析
NetFlow作為一種通用的數(shù)據(jù)報(bào)文格式,是典型的結(jié)構(gòu)化數(shù)據(jù),隨著運(yùn)營(yíng)商網(wǎng)絡(luò)的擴(kuò)容與升級(jí),NetFlow數(shù)據(jù)的生成速率和數(shù)據(jù)規(guī)模都出現(xiàn)了大規(guī)模的增長(zhǎng),NetFlow的數(shù)據(jù)分析是天然的大數(shù)據(jù)處理。典型的NetFlow解決方案是使流量采集系統(tǒng)和流量分析系統(tǒng)相分離,本文只討論流量分析系統(tǒng)。
一種大規(guī)模的處理方法是使用MapReduce(以下簡(jiǎn)稱MR)方案。在該方案中,當(dāng)需要對(duì)NetFlow數(shù)據(jù)進(jìn)行多維度、多次數(shù)的統(tǒng)計(jì)時(shí),需要編寫多個(gè)MR任務(wù),這些任務(wù)被分別提交到集群上,以串行或者并行方式執(zhí)行,任務(wù)之間無(wú)法共享內(nèi)存數(shù)據(jù),數(shù)據(jù)需要反復(fù)在內(nèi)存和磁盤之間轉(zhuǎn)移,導(dǎo)致MR分析任務(wù)有性能低、分析時(shí)延長(zhǎng)、內(nèi)存占用大等缺點(diǎn)。
Spark的出現(xiàn)有效地解決了MR執(zhí)行過程中,中間數(shù)據(jù)不能緩存在內(nèi)存中的問題。在基于Spark的分析系統(tǒng)中,NetFlow流量數(shù)據(jù)只需要從磁盤加載到內(nèi)存一次,即可在該緩存數(shù)據(jù)上進(jìn)行多維度、多次數(shù)的分析和查詢,通過減少磁盤I/O,提高了分析性能,降低了分析時(shí)延,特別適合于NetFlow這種生成速率快、數(shù)據(jù)規(guī)模大的應(yīng)用場(chǎng)景。
4 基于Spark的NetFlow流量分析系統(tǒng)架構(gòu)
基于Spark的NetFlow數(shù)據(jù)分析數(shù)據(jù)流圖如圖1所示。NetFlow以文本記錄的形式保存在HDFS上,Spark計(jì)算引擎調(diào)用textFile方法從HDFS上加載NetFlow數(shù)據(jù)到集群內(nèi)存中,并將NetFlow數(shù)據(jù)轉(zhuǎn)換為HadoopRDD[string]的形式。然后即可調(diào)用RDD上的編程接口如map、filter、reduce、join等,對(duì)NetFlow數(shù)據(jù)進(jìn)行多維度統(tǒng)計(jì)分析。由于RDD的只讀特性,每次對(duì)RDD的操作都會(huì)生成新的RDD,整個(gè)分析流程便形成如圖1中所示的“管道”。計(jì)算過程中,可以根據(jù)需要對(duì)任意RDD通過調(diào)用persist的方法將該RDD緩存在集群內(nèi)存中,以便后續(xù)基于該RDD的分析效率更高。對(duì)于不再需要的RDD,調(diào)用unpersist方法即可將該RDD從集群內(nèi)存中清除,釋放該RDD占用的內(nèi)存空間。分析完成后,對(duì)于包含結(jié)果數(shù)據(jù)的RDD調(diào)用saveAsTextFile方法可將結(jié)果RDD中的數(shù)據(jù)持久化地存儲(chǔ)到HDFS上。
上述NetFlow分析任務(wù)在Spark集群上運(yùn)行時(shí)的圖解如圖2所示。整個(gè)分析任務(wù)由一個(gè)全局的用戶driver程序、機(jī)器主節(jié)點(diǎn)上的master和若干集群從節(jié)點(diǎn)上的worker共同組成。提交到集群的driver程序和master進(jìn)行通信,master內(nèi)的DAGScheduler根據(jù)分析任務(wù)的具體情況對(duì)RDD上的計(jì)算過程劃分階段,如圖1中分成了階段1和階段2。劃分完階段后,master內(nèi)的taskScheduler將這些階段包裝成task的形式調(diào)度到worker上運(yùn)行,worker在運(yùn)行任務(wù)時(shí)需要和driver保持通信,以進(jìn)行一些數(shù)據(jù)匯總的操作。在連續(xù)的多個(gè)分析任務(wù)運(yùn)行過程中,RDD始終保持在worker的內(nèi)存中,因此分析任務(wù)的執(zhí)行速度很快、效率更高。
5 實(shí)驗(yàn)驗(yàn)證
本實(shí)驗(yàn)以基于Hadoop的應(yīng)用構(gòu)成統(tǒng)計(jì)為例,對(duì)比Spark和MapReduce在實(shí)際運(yùn)行過程中的性能。應(yīng)用構(gòu)成統(tǒng)計(jì)根據(jù)應(yīng)用的目標(biāo)端口號(hào)對(duì)流量數(shù)據(jù)進(jìn)行分類,統(tǒng)計(jì)不同類型應(yīng)用流量的大小和占比情況。分別使用MR的編程接口和Spark的編程接口編寫統(tǒng)計(jì)分析作業(yè),并將作業(yè)代碼打包上傳到集群上執(zhí)行。集群配置情況見表1。在集群上同時(shí)搭建Hadoop 2.2和Spark 1.0分布式環(huán)境,選擇其中一臺(tái)服務(wù)器作為Hadoop和Spark的主節(jié)點(diǎn),其他7臺(tái)服務(wù)器作為從節(jié)點(diǎn)。

表1 集群配置
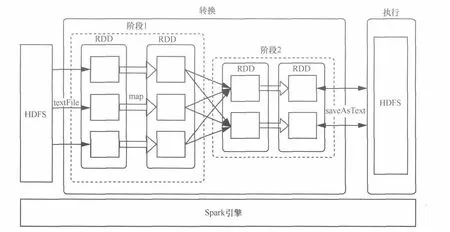
圖1 NetFlow分析流圖
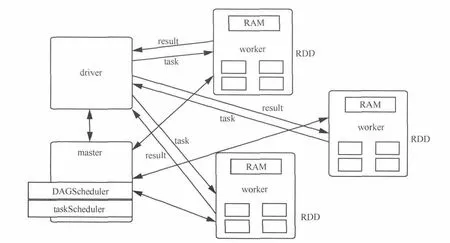
圖2 NetFlow分析運(yùn)行圖
通過調(diào)整輸入數(shù)據(jù)量的規(guī)模大小,測(cè)試MR和Spark作業(yè)的完成時(shí)間,性能對(duì)比結(jié)果如圖3所示。從圖3中可以看到,在輸入數(shù)據(jù)規(guī)模相同的情況下,Spark作業(yè)的完成時(shí)間比MR更少,而且隨著數(shù)據(jù)量的增大,Spark的性能超出了Hadoop 2倍以上。通過分析Spark和MR運(yùn)行原理,可知Spark將HDFS上的數(shù)據(jù)抽象成RDD,并在計(jì)算過程中緩存在計(jì)算節(jié)點(diǎn)的內(nèi)存中,加快了計(jì)算速度。同時(shí)Spark由于RDD的引入,每個(gè)節(jié)點(diǎn)上的計(jì)算任務(wù)以多線程的方式執(zhí)行,相對(duì)于MapReduce為每個(gè)任務(wù)啟動(dòng)單獨(dú)的Java虛擬機(jī),效率更高。因此可知,在同等條件下Spark的計(jì)算性能要明顯優(yōu)于MapReduce。

圖3 Spark和MapReduce性能對(duì)比
6 結(jié)束語(yǔ)
本文在研究Spark大數(shù)據(jù)平臺(tái)基本原理的基礎(chǔ)上,結(jié)合NetFlow數(shù)據(jù)規(guī)模大、生成速度快等特征,提出了使用Spark大數(shù)據(jù)平臺(tái)對(duì)NetFlow數(shù)據(jù)進(jìn)行統(tǒng)計(jì)分析的基本方法,并在具體的實(shí)驗(yàn)中對(duì)比了Spark和MapReduce在NetFlow數(shù)據(jù)處理上的性能差異。驗(yàn)證了Spark在NetFlow數(shù)據(jù)分析方面相對(duì)MapReduce,處理速度更快,效率更高。
1 White T.Hadoop:the Definitive Guide.O’Reilly Media Inc,2012
2 Zaharia M,Chowdhury M,Das T,et al.Resilient distributed datasets:a fault-tolerant abstraction for in-memory cluster computing.Proceedings of the 9th USENIX Conference on Networked Systems Design and Implementation,San Jose,CA,USA,2012
3 Rossi D,Silvio V.Fine-grained traffic classification with NetFlow data.Proceedings of the 6th International Wireless Communications and Mobile Computing Conference,Shenzhen,China,2010
猜你喜歡
工業(yè)設(shè)計(jì)(2022年8期)2022-09-09 07:43:20
軍民兩用技術(shù)與產(chǎn)品(2021年10期)2021-03-16 06:05:30
民用飛機(jī)設(shè)計(jì)與研究(2020年4期)2021-01-21 09:15:02
北京測(cè)繪(2020年12期)2020-12-29 01:33:58
裝備制造技術(shù)(2019年12期)2019-12-25 03:06:46
中國(guó)洗滌用品工業(yè)(2019年4期)2019-05-11 09:27:34
電子制作(2018年18期)2018-11-14 01:48:24
家庭影院技術(shù)(2017年9期)2017-09-26 03:41:45
山東工業(yè)技術(shù)(2016年15期)2016-12-01 05:31:22
中國(guó)中醫(yī)藥現(xiàn)代遠(yuǎn)程教育(2014年11期)2014-08-08 13:23:44
