數據質量提高方案探究
2014-01-03 06:36:18蘇小會葛宇洲
電子測試 2014年8期
蘇小會,葛宇洲
(西安工業大學計算機科學與工程學院,陜西西安,710021)
0 引言
數據是為反映客觀世界而記錄下來的可以鑒別的數字或符號,表現為數字、文字、圖形、圖像、聲音等。數據是一種產品,作為產品的數據應該有質量。隨著社會信息化不斷發展,特別是在現在的大數據時代,數據質量問題不得不被認真考慮。
數據質量的概念有很多,一般認為數據質量是數據適合使用的程度,或者數據質量是數據滿足特定用戶期望的程度,這個概念的定義其實是站在用戶的角度給出的,體現出了與使用數據有關的要求。數據質量問題涉及三種情形,第一種是數據格式問題,如數據丟失導致不完整、超出元數據范圍導致數據無效等;第二種是業務邏輯問題,如由于數據庫模式設計不夠嚴謹而導致的數據之間邏輯矛盾、不正確、不合理等;第三種是數據源問題,如由于數據源分散、多次采集導致數據獲取困難、語義失效、信息冗余等。如今大多數項目或系統中,數據質量問題被集中于數據預處理階段解決,在整個項目進行過程中,缺乏對數據質量問題的持續關注。
因此在實際工作中,我們需要考慮和設計一種過程模型,對數據質量進行定義和評估,在每一個不同的過程或環節中,數據質量被定義為產品、服務、系統或者程序的一套基本特征去迎合有關各方的需要和期望,總之,數據質量代表了各方的契合點,應該用有效并可以反復執行的過程模型來評估和提高數據質量。
1 數據質量提高方案
1.1 戴明環理論
凡是涉及到質量問題的評估和管理,都離不開戴明環。戴明環又叫PDCA 循環,PDCA 是英文單詞Plan(策劃)、Do(實施)、Check(檢查)和Act(處置)的首字母,PDCA 循環就是按照這一順序進行質量管理,并且循環不止的反復進行下去的科學程序。PDCA 循環是美國質量管理專家休哈特博士率先提出,由戴明學習采納、宣傳,獲得普及,因此也被稱為“戴明環”。
1.2 數據生命周期
1999 年,Larry 在《Improving Data Warehouse and Business Information Quality》討論了一種通用資源生命周期,包含管理任何資源所需要的流程,文中將資源生命周期定義為五個階段,分別是規劃、獲取、維護、應用和報廢。例如對于資金來說,把它視為金融資源需要規劃金融資源,進行預算,通過銀行貸款或拋售股票來獲取金融資源,通過支付利息或者股息來維護金融資源,通過購買其他資源來應用金融資源,當還清貸款或者回購股票后,資金作為金融資源生命周期就完結了。同樣對于目前大量的數據來說,把其視為數據資源,為了從數據資源中獲益需要規劃數據資源,我們可以依照Larry 的思想定義數據資源生命周期,數據資源生命周期,是指從數據的需求規劃開始,生產、獲得、被存儲和利用,到消失或不再有利用價值、不再被傳播的一系列過程。
數據資源的生命周期模型如圖1 所示。圖1 呈現了數據生命周期的各個階段,這種生命周期不是線性過程而是反復迭代的。

圖1 數據生命周期示意圖Fig1 Data Life Cycle
任意一組數據的規劃,獲取,維護,應用,報廢都有很多種方法,而事實上,同樣的數據也可能存儲在多個地方。現實世界中對于數據的處理往往是單一的,只在某一環節進行的,因此針對數據生命周期的每個階段,設計一種循環反復的數據質量提高方案是非常有益的。
1.3 數據質量提高方案
提高數據質量常常被看成是一次性的工作,有人會說“我的項目里已經校正過數據了”,即使人們意識到數據質量工作需要持續關注,但由于缺乏系統的認識,造成數據質量工作隨時間進展逐漸淡化,這也是很多應用程序開發項目出現數據質量問題的原因,一旦進入實踐生產,就無法保持項目所需數據質量,因此本文在戴明環理論和數據生命周期思想的基礎上總結出一種數據質量提高方案。

圖2 數據質量提高方案示意圖Fig2 the improvement plan of data quality
如圖2 所示,該方案分為預先評估,認知,處置三個頂層步驟,每一個頂層步驟中都包含了具體細化的工作。
在預先評估中,首先應該做的是分析數據環境。這一工作需要收集,匯總分析關于當前項目的數據環境信息,定義項目業務的需求和方法,為業務問題相關的數據提供資料,制定獲得數據的初步方案,并要弄清楚待處理問題的相關協議,文件,以及它們和數據質量的關系,這些工作主要通過一些訪談,預研究,溝通協調完成。無論涉及到哪種類型的數據質量工作,都要避免在不了解基本環境的情況下直接抽取和分析數據,否則往往需要進行重復勞動,效率低下。
接下來是確定數據的規范,數據規范主要包括數據模型,數據標準,業務規則等。數據模型是數據結構,數據操作,數據約束的統稱,是數據庫中的形式構架。數據標準是數據中表,字段等命名的規則,錄入的規則,使用時要遵循的標準等。業務規則是指在項目使用該數據的時期內,數據應該何時以及如何被處理的聲明。數據規范的確定是一步重要工作,很多時候是通過數據模型的建立或定義數據庫中的元數據來完成的。一個良好的數據模型,能夠在恰當的細節層反應與項目相關的問題,呈現整個系統的范圍,描述數據,實體和關聯關系。元數據是關于數據庫的數據,指在數據庫建立過程中所產生的有關數據源的定義,目標定義,轉換規則等相關的關鍵數據,可以說是描述數據的數據。同時元數據還包含對于數據含義的商業信息,所有這些信息都應當妥善構建,并很好地管理。為數據庫的發展和使用提供便利。元數據的管理是初始階段控制數據質量的重要方法,元數據管理主要有元數據的添加、刪除、修改屬性等維護功能;元數據之間關系的建立、刪除和跟蹤等關系維護功能;進行元數據發布流程管理,可以更好地管理和追蹤元數據的生命周期;元數據自身質量核查、元數據查詢、元數據統計、元數據使用情況分析、元數據變更等功能。
完成了預先評估的工作,就要進入下面的認知階段,認知階段要進行的工作與評估息息相關。預先評估階段建立了數據規范,分析了背景問題,認知階段就要確定所需衡量的數據質量維度。維度本身是一種數學概念,是在一定前提下描述一個數學對象所需要的參數的個數,這里的維度是可以理解為一種視角,而不是一個固定的數字參數,是一個判斷、說明、評價和確定一個事物的多方位、多角度、多層次的條件和概念。國內外關于數據質量維度的研究比較廣泛,劃分也比較細致,總結起來,數據質量的維度主要有以下幾個方面:數據完整性,數據重復性,數據準確性,數據一致性,數據及時性等等。數據完整性是指數據的存在,內容結構和其它基本特征是否符合元數據標準,是否有缺失。數據重復性是指對存在于系統內或者系統之間的特殊字符或數據集意外重復的測量標準。數據準確性是指數據內容是否被按照精確度要求來描述。數據一致性,就是當多個用戶試圖同時訪問一個數據庫,它們的事務同時使用相同的數據時,可能會發生丟失更新、未確定的相關性、不一致的分析等。數據及時性是指數據的生命周期是否符合項目需求的時間段。在不同的領域還有更多的數據質量維度劃分,這里就不再一一贅述。研究數據質量維度應該注意一個方面,就是在一個項目中該維度的評估是否可行或者代價過大,如果評估該質量維度很難實現,也就沒有評估的必要了。
接下來是確定產生數據質量問題的原因和提出具體改進方法。根據以上的分析評估就可以確定產生數據質量問題的原因,現實的情況是一個問題通常都有多個原因,因此要需要對產生的原因進行優先級劃分,以便更好的處理問題,比如產生問題的原因是開發工具的問題,還是信息采集的問題,還是人為造成的問題等等。有了具體原因,才能制定改進的方法,工具問題,能否由更新工具來改善,人為問題,是否應該進行更好的溝通和責任劃分來改善等等。
完成前兩個階段工作之后就要進入處置階段。處置階段主要要做兩方面工作,糾正當前錯誤數據和預防未來錯誤數據,這里的“錯誤”是一個廣義概念,即不符合質量需求的數據。糾正當前數據錯誤和預防未來數據錯誤都要應用到具體算法,目前大多數數據質量分析處理方法也都是在做這些工作。比如在數據缺失的情況下通常使用回歸分析的方法進行填補,在有大量數據冗余的情況下使用固有或非固有頻率的數據歸約算法進行篩選,還有利用數據清洗工具進行識別和合并重復記錄等等。數據的糾正和預防其實都是對已有原始數據的大規模更新,這些變更應該進行詳細的歸檔記錄,更新的結果也應該及時與技術團隊或相關數據利益者進行溝通,這樣有助于隨時檢查可能發生的問題。這種變更的復雜性和時間性也需要慎重考慮,畢竟,數據質量分析工作是為其它后續的挖掘工作做準備。
2 應用舉例
本文采用西安市交通信息中的浮動車GPS 數據作為示例。浮動車是指安裝有GPS 發送裝置,在道路上運行的車輛,大多數為公交車或出租車。
首先是對浮動車GPS 數據進行預先評估。現代交通服務信息的核心是對交通參數的檢測,傳統檢測法如感應線圈檢測等都屬于固定檢測,已經很難滿足交通服務的需求,隨著全球衛星定位系統的應用,浮動車技術已經漸漸成為現代交通參數檢測的主流,一般用于車輛軌跡描繪和擁堵分析等。通過調查研究,我們可以總結GPS 數據有以下特點:
①GPS 數據覆蓋的面積較大,可以對多個路段的交通狀況進行監控。
②定位精度較高,能夠進行實時信息的交互。
③浮動車產生的GPS 數據量樣本極大,多數發送裝置的頻率可達到1 秒鐘發送一次。
接下來是針對GPS 原始數據進行分析,GPS 原始數據如下表所示。
從該表可以看出,GPS 浮動車數據有車輛編號,GPS 時間,經度數據,緯度數據,方向角五種主要數據項,有的浮動車數據還包含瞬時速度,行駛距離等,基本數據質量的分析清洗應從GPS浮動車數據的這五個屬性展開。而與具體應用需求相關的GPS 數據,還需要有具體的算法進行篩選。
第三步是根據前面的分析設計具體的數據篩選算法選取符合需求的數據。

表1 原始數據Chart1 original data
VehicleID 表示車輛ID 編號,每個浮動車應該有唯一編號,本文中,車輛編號為7 位正整數,且該數據不能為空。gpstime表示GPS 定位時刻,該數據不能為空,時間為24 小時制,數據格式應該符合yyyy/mm/dd hh:mm:ss,精確到秒。lng 表示GPS 定位的經度信息,該數據不能為空,取值范圍為0-180 的東經經度,要求精確到小數點后6 位。lat 表示GPS 定位的緯度信息,該數據不能為空,取值范圍為0-90 的北緯緯度,要求精確到小數點后6 位。direct 表示車輛運行的方向角,該數據不能為空,取值范圍為0-360 的正整數。
有些原始數據缺乏車輛行駛速度,在進行擁堵分析時需要計算車輛在某點的瞬時速度或某路段的平均速度,在進行某車輛軌跡繪制時,并不要求大量樣本數據,因此需要按照一定得歸約方法來選取數據,比如將GPS 發送裝置的固有頻率從1 秒擴大到10 秒來篩選,也可以選取車輛行駛方向角發生較大偏轉時的數據作為記錄點,最后將該車輛發送的GPS 數據按時間順序排列。經過篩選后的數據如表2
經過分析篩選后的數據可以用于進一步的交通信息挖掘,為城市交通服務提供更準確的依據。
3 小結
本文的研究,為數據質量分析提供了一種與具體業務無關的流程方法,將認識數據質量的概念框架與提高數據質量的技術結合起來,在不同的領域,都可以結合具體算法進行應用。現今的時代是大數據的時代,更加強調的是數據信息的獲取和分析,而不是創造數據,而數據質量分析控制,也不再是由IT 部門單獨能夠勝任的,需要各學科的人才,充分利用各類信息數據和方法策略來完成,數據質量問題的挑戰,也從逐漸從技術層面上向思維方式層面拓展,這也是數據質量分析的魅力所在。
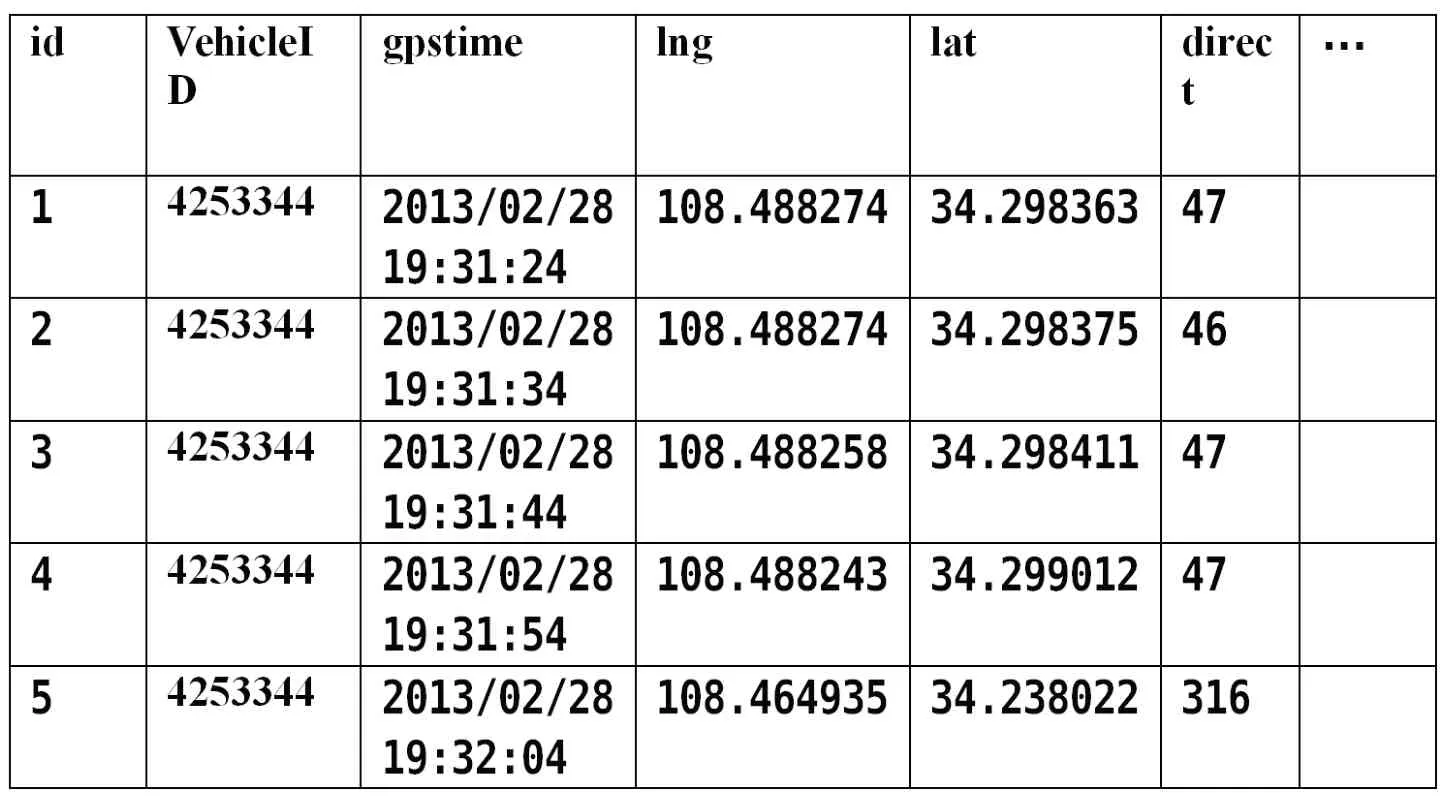
表2 改進后的數據Chart2 improved data
[1] Monge A,Elkan C.An efficient domain-independent algorithm for detecting approximately duplicate database records[C].In:Proceedings of the ACM- SIGM OD Workshop on Research Issues on Know ledge Discovery and Data Mining,Tucson, AZ,1997
[2] Huang K-T,Lee YW,Wang RY.Quality information and knowledge management.New Jersey:Prentice Hall, 1998
[3] Kahn BK,Strong DM.Product and Service Performance Model for Information Quality:An Update.IQ 1998.
[4] Aebi D, Perrochon L.Towards improving data quality [C].In:Proc.of the International Conference on Information Systems and Management of Data,1993.
[5] Larry.Improving Data Warehouse and Business Information Quality.In:Springer:1999:200-209.
[6] 劉慧,劉敏,韓兵。基于維度的信息系統數據質量評估指標體系研究。信息系統工程,2010(6):102-105
猜你喜歡
中學生數理化·八年級物理人教版(2021年12期)2021-12-31 03:23:08
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
中學生數理化·中考版(2020年10期)2020-11-27 01:59:48
中國生殖健康(2019年2期)2019-08-23 08:12:08
電子制作(2018年18期)2018-11-14 01:48:24
產品可靠性報告(2017年7期)2017-09-05 09:49:12
山東工業技術(2016年15期)2016-12-01 05:31:22
汽車觀察(2016年3期)2016-02-28 13:16:26
中國中醫藥現代遠程教育(2014年11期)2014-08-08 13:23:44
中國質量與標準導報(2014年1期)2014-02-28 22:21:28
